



villa-X是由微软研究院、清华大学等机构联合提出的一种新型ViLLA框架,目的是改进机器人操作的潜在动作建模,从而提升模型在复杂场景中的泛化能力。然而现有ViLLA模型的主要问题是:生成的潜在动作可能不符合机器人物理动力学基础,为解决此问题,villa-X提出了2个主要改进点:
(1) 在潜在动作模型中引入本体感知前向动力学模块(FDM)作为辅助解码器,通过预测未来机器人本体感知状态和动作,促使学习到的潜在动作不仅能反映观察到的视觉变化,也能更准确的表征智能体的行为本质。
(2) 通过联合扩散过程同步建模潜在动作与机器人动作分布,从而实现从潜在动作到机器人动作更高效、更具结构化的信息传递。
项目地址:https://microsoft.github.io/villa-x/

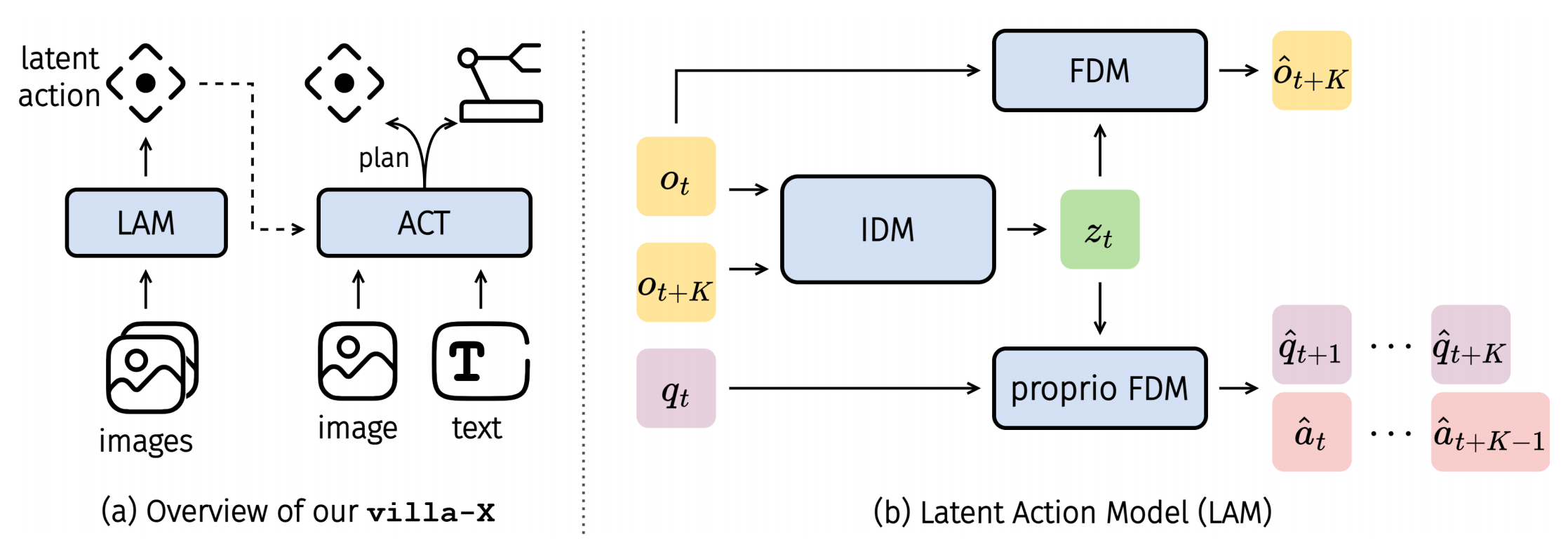
▲说明:(a)villa-X架构图,(b)LAM的结构组成
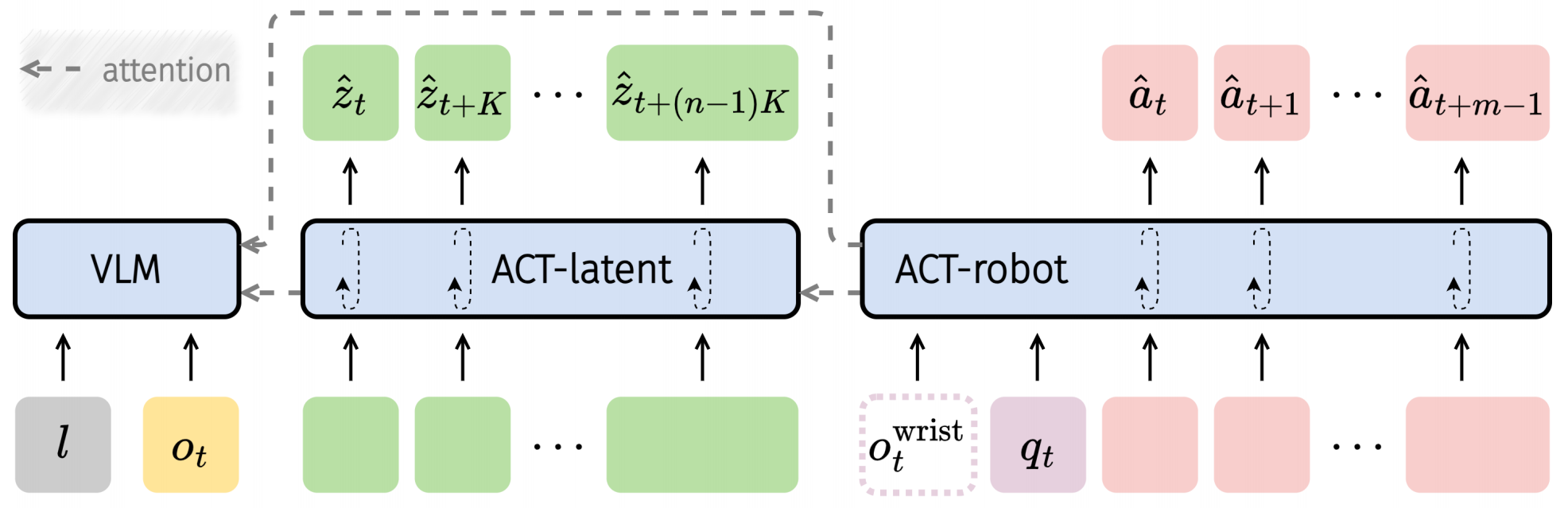
▲说明:ACT的结构组成
villa-X的核心设计围绕潜在动作建模与动作整合机制展开,通过两个核心组件(Latent Action Model, LAM和Actor Module, ACT)实现机器人操作策略的学习,并分为三个训练阶段逐步优化。
一、核心组件设计
(1) 潜在动作模型(LAM)
LAM的核心功能是从连续观测帧中提取潜在动作,并确保与机器人物理行为对齐。其设计亮点包括:
逆动力学模型 (IDM): 通过时空 Transformer 编码输入的帧序列 (长度为 ),经量化后生成
个潜在动作
,用于捕捉帧间运动语义信息。
增强的动力学监督: 引入两个辅助解码器:
视觉前向动力学模型 (FDM): 基于当前帧 和潜在动作
预测未来帧
,确保潜在动作捕捉到视觉变化;
本体感知前向动力学模型 (proprio FDM): 以当前机器人状态 和潜在动作
为输入, 预测未来
步的机器人本体感知状态和动作,并通过上下文嵌入分离机器人特异性特征,增强跨机器人泛化能力。
(2) Actor模块(ACT)
ACT基于VLM模型将潜在动作作为中阶桥梁,连接视觉-语言提示与低级别机器人动作,设计包括3个组件:
● VLM:采用预训练的PaliGemma模型提取视觉和语言特征;
● ACT-latent:基于扩散模型,以VLM特征为条件,生成未来潜在动作序列,支持长horizon规划;
● ACT-robot:同样基于扩散模型,以VLM特征和ACT-latent生成的潜在动作为条件,预测低级别机器人动作序列,同时可融合腕部相机输入(经ResNet-18 编码),通过注意力机制实现潜在动作对机器人动作的显式控制。
二、训练流程
villa-X的训练分为三个阶段:
(1) 预训练LAM:在机器人轨迹和人类视频数据上训练IDM、FDM和proprio FDM,学习通用潜在动作表示;
(2) 预训练ACT:联合训练VLM、ACT-latent和ACT-robot,优化潜在动作生成与机器人动作预测损失;
(3) 微调ACT:针对目标机器人平台,初始化新的上下文嵌入,并在目标数据上进行微调,以适配具体硬件特性。

(1) 逆动力学IDM的代码部分
class IgorEncoder(IgorPretrainedModel):
def __init__(self, config: IgorConfig) -> None:
...
# Spatial–Temporal Transformer,用于IDM捕捉帧间运动语义信息
self.pe_spatial = nn.Parameter(
torch.from_numpy(
get_2D_position_embeddings(config.encoder_embed_dim, config.grid_size)
)
.float()
.unsqueeze(0),
requires_grad=False,
)
self.pe_temporal = nn.Parameter(
torch.from_numpy(
get_1D_position_embeddings(config.encoder_embed_dim, config.d_t)
)
.float()
.unsqueeze(0),
requires_grad=False,
)
...
@torch.inference_mode()
def idm(
self,
clips: torch.Tensor | list[torch.Tensor],
mask: torch.Tensor | None = None,
padding_side: str = "left",
):
...
# 前面是对输入tensor做预处理的工作,这里省略
# 这里对图像做一些增广处理
clips = self.preprocess(clips, augment_type="no")
...
# 预测d_t帧latent actions
for i in range(t - self.config.d_t + 1):
clips_ = clips[:, i : i + self.config.d_t] # [B d_t C H W]
mask_ = mask[:, i : i + self.config.d_t] # [B d_t]
action = self.forward(clips_, mask_.sum(dim=1).tolist())
if i == 0:
actions = torch.split(
action,
split_size_or_sections=(mask_.sum(dim=1) - 1).tolist(),
dim=0,
) # list of [T 1 nd]
else:
new_actions = torch.split(
action,
split_size_or_sections=(mask_.sum(dim=1) - 1).tolist(),
dim=0,
) # list of [T 1 nd]
new_action = [xi[-1].unsqueeze(0) for xi in new_actions] # [1 1 nd]
actions = [
torch.cat([x, y], dim=0) for x, y in zip(actions, new_action)
] # [T+1 1 nd]
return actions
上述代码通过输入视频流,提取视频中的潜在动作,如何使用IDM呢,下面给出一个例子:
from lam import IgorModel
def read_video(fp: str):
from torchvision.io import read_video
video, *_ = read_video(fp, pts_unit="sec")
return video
lam = IgorModel.from_pretrained("LOCAL_MODEL_DIRECTORY").cuda()
video = read_video("path/to/video.mp4").cuda() # Load your video here
latent_action = lam.idm(video)
(2) 前向感知动力学模型FDM的代码部分
class IgorDecoder(IgorPretrainedModel):
@torch.inference_mode()
def apply_latent_action(self, images: torch.Tensor, la: torch.Tensor):
single_image = False
if len(images.shape) == 3 or (len(images.shape) == 4 and images.shape[0] == 1):
single_image = True
if len(images.shape) == 3:
images = images.unsqueeze(0)
la = la.unsqueeze(0)
images = self.preprocess(images, augment_type="no")
x = self.fdm(la, images=images)
x = self.patch2image(x)
if single_image:
return x.squeeze(0)
return x
def fdm(
self,
la: torch.Tensor,
images: torch.Tensor | None = None,
embeddings: torch.Tensor | None = None,
):
# images: [B C H W], la: [B 1 nd]
if embeddings is None:
x = self.embed(images) # [B N D]
else:
x = embeddings
x = x + self.pe # [B N D]
x = torch.cat([self.action_embed(la), x], dim=1) # [B N + 1 D]
for layer in self.layers:
x = layer(kv=x, q=x)
x = self.norm(x)
x = x[:, 1:] # [B N D]
output = self.pred_head(x) # [B N D]
return output
上述代码基于当前帧和潜在动作
预测未来帧
,确保潜在动作捕捉到视觉变化,至于如何使用FDM,下面给出一个例子:
frames = []
for i in range(len(latent_action[0])):
pred = lam.apply_latent_action(video[i], latent_action[0][i])
frames.append(pred)
(3) ACT模块代码(暂未开源,思路供参考)
先导入一些三方库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from transformers import AutoModelForVision2Seq # 参考PaliGemma
from diffusion import GaussianDiffusion # 参考Transfusion扩散实现
from flow_matching import FlowMatchingLoss # 参考Flow Matching论文
import numpy as np
from typing import Dict
# 参考代码库:
# HPT: https://github.com/liruiw/HPT (模态Token处理)
# Transfusion: https://github.com/lucidrains/transfusion-pytorch (扩散Transformer)
# Moto: https://github.com/TencentARC/Moto (注意力掩码)
# PaliGemma: https://github.com/google-research/big_vision (V
class ActorModule(nn.Module):
def __init__(self, latent_dim=128, action_dim=8, vision_dim=768, lang_dim=768):
super().__init__()
# 1. VLM特征提取 (PaliGemma)
self.vlm = AutoModelForVision2Seq.from_pretrained("google/paligemma-3b-vision-text")
self.vision_proj = nn.Linear(vision_dim, latent_dim) # 视觉特征投影
self.lang_proj = nn.Linear(lang_dim, latent_dim) # 语言特征投影
# 2. ACT-latent (潜在动作扩散模型)
self.act_latent = GaussianDiffusion(
model=TransfusionTransformer( # 参考Transfusion的扩散Transformer
dim=latent_dim,
depth=6,
heads=8,
input_dim=latent_dim + vision_dim + lang_dim # 融合特征
),
loss_type="flow_matching" # 流匹配损失
)
# 3. ACT-robot (机器人动作扩散模型)
self.act_robot = GaussianDiffusion(
model=TransfusionTransformer(
dim=action_dim,
depth=6,
heads=8,
input_dim=latent_dim + vision_dim + lang_dim # 含潜在动作特征
),
loss_type="flow_matching"
)
# 4. 本体感觉上下文嵌入 (适配不同机器人)
self.embodiment_emb = nn.Embedding(num_embeddings=10, embedding_dim=latent_dim) # 机器人类型嵌入
def forward(self, vision_inputs, lang_inputs, proprio, embodiment_id, actions=None):
# 1. VLM特征提取
vlm_output = self.vlm(
pixel_values=vision_inputs.pixel_values,
input_ids=lang_inputs.input_ids,
return_dict=True
)
vision_feat = self.vision_proj(vlm_output.vision_outputs.last_hidden_state.mean(dim=1))
lang_feat = self.lang_proj(vlm_output.language_outputs.last_hidden_state.mean(dim=1))
# 2. 融合特征 (视觉+语言+本体感觉嵌入)
emb = self.embodiment_emb(embodiment_id) # 机器人结构嵌入
fused_feat = torch.cat([vision_feat, lang_feat, emb], dim=-1)
# 3. ACT-latent生成潜在动作序列
latent_actions = self.act_latent(fused_feat, cond=fused_feat, labels=actions)
# 4. ACT-robot生成机器人动作
robot_actions = self.act_robot(
torch.cat([latent_actions, fused_feat], dim=-1),
cond=fused_feat,
labels=actions
)
return latent_actions, robot_actions
def train_actor(module: ActorModule, dataloader: DataLoader, is_pretrain=True):
optimizer = optim.AdamW(
module.parameters(),
lr=3e-4,
weight_decay=0.05,
betas=(0.9, 0.95)
)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10000)
loss_fn = FlowMatchingLoss() # 流匹配损失函数
module.train()
for epoch in range(100):
total_loss = 0.0
for batch in dataloader:
# 输入解析
vision = batch["vision"]
lang = batch["lang"]
proprio = batch["proprio"]
actions = batch["actions"]
embodiment_id = torch.zeros(len(batch), dtype=torch.long) # 机器人ID
# 前向传播
latent_actions, robot_actions = module(
vision, lang, proprio, embodiment_id, actions
)
# 损失计算 (联合潜在动作和机器人动作损失)
loss_latent = loss_fn(latent_actions, actions)
loss_robot = loss_fn(robot_actions, actions)
loss = loss_latent + loss_robot # 联合损失
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
total_loss += loss.item()
print(f"Epoch {epoch}, Loss: {total_loss/len(dataloader):.4f}")
# 预训练后冻结trunk,微调仅更新stem和head
if not is_pretrain:
for param in module.vlm.parameters():
param.requires_grad = False

实验设计从以下4个疑问出发进行验证说明:
(1) 改进的LAM模型是否学习了更高质量的潜在动作?
(2) ACT-latent能否成功预测未来的动作?
(3) ACT-latent能否有效利用预训练的潜在动作?
(4) 在模拟基准测试和真实机器人任务中,villa-X与现有VLA基线相比表现又如何?
(一) 验证改进的LAM模型质量
(1) 在探测实验中,带本体感知前向动力学模型(proprio FDM)的LAM变体(w/pp)在LIBERO数据集上预测机器人动作时,低误差样本数量显著多于不带proprio FDM 的变体(wo/pp),最大L1误差更小。
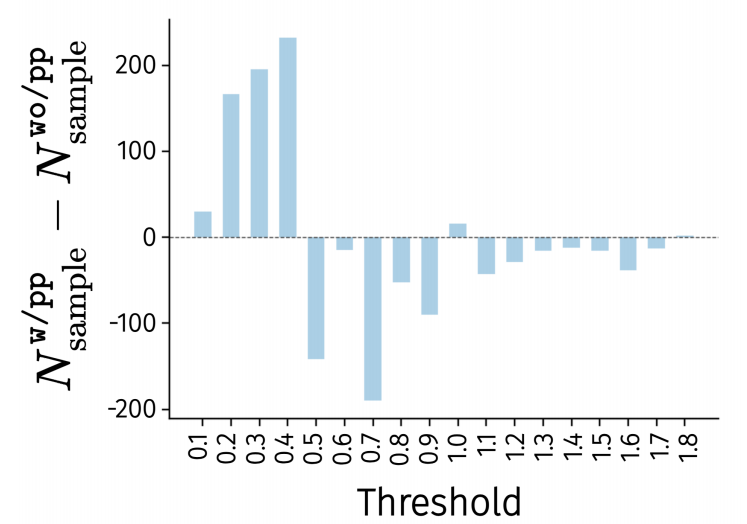
▲说明:探测实验结果,在不同误差threshold下,w/pp减wo/pp的误差样本数量差值
(2) 在决策预训练对比中,w/pp变体在SIMPLER环境的8项任务中性能显著优于wo/pp,并且没有LAM的基线(wo/LAM)表现最差。
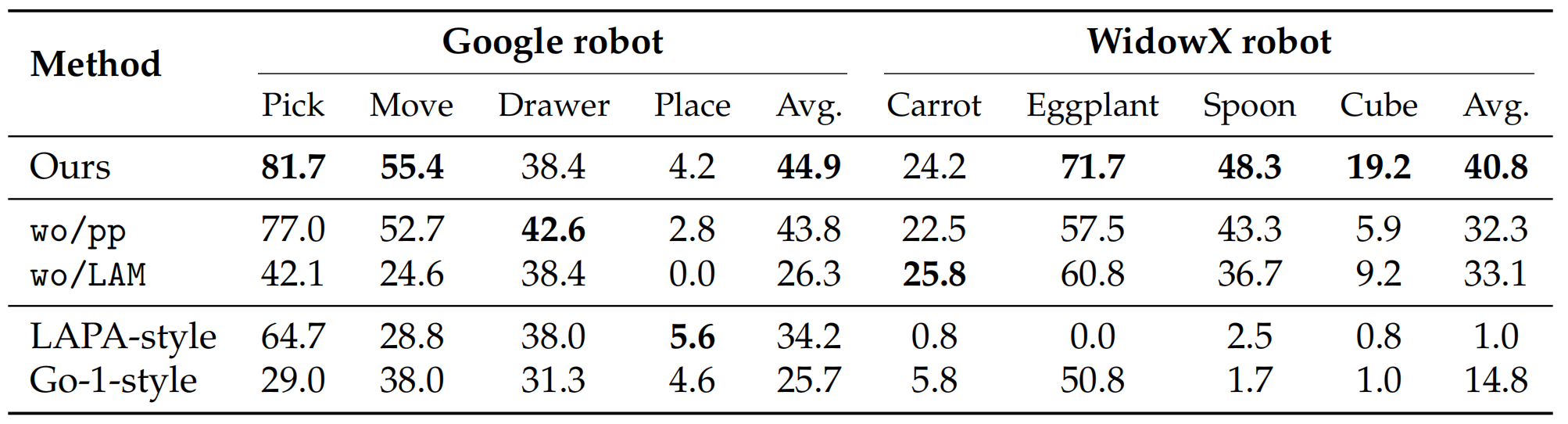
▲说明:不同villa-X变体(上半部分)以及整合潜在动作的其他方法(下半部分)在SIMPLER上的评估结果
(二) ACT-latent的未来动作规划能力验证
基于初始图像和语言指令,ACT-latent生成的潜在动作序列经世界模型渲染后,在分布内任务(如“移动银锅到左炉”、“打开抽屉”)和分布外任务(如“触摸表情符号”、“拾取新物体”)中均能准确识别目标并生成符合指令的动作。(分发内是指样本来自训练数据的验证集,而分布外是指样本来自Realman机械臂,这是训练中从未见过的新实施例)

▲说明:分布内和分布外数据,可以跳转到项目地址中查看完整功能:点击图片中的数字展示模型规划效果
(三) ACT-latent对预训练潜在动作的利用有效性验证
在SIMPLER环境中,villa-X通过联合扩散和注意力机制实现潜在动作到机器人动作的显式传递,性能显著优于LAPA(两阶段预训练)和GO-1(自回归潜在规划)。
(四) 模拟与真实环境中的综合性能评估
(1) 模拟环境:在SIMPLER中,villa-X在Google机器人(平均59.6%)和 WidowX机器人(平均62.5%)上优于RT-1-X、OpenVLA等VLA模型以及 GR00T等潜在动作方法;在LIBERO的4个任务套件中平均成功率90.1%,显著优于Diffusion Policy等基线。
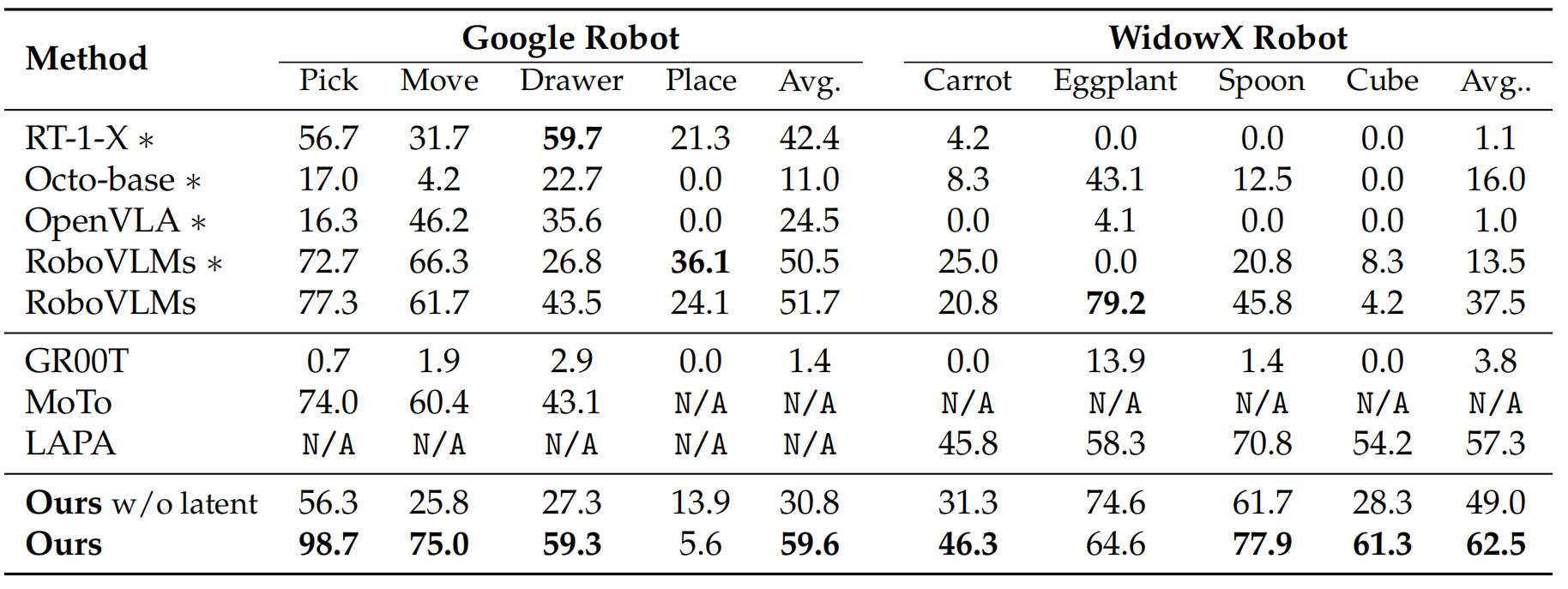
▲说明:villa-X与现有方法在SIMPLER上的对比结果。标有∗的方法是在预训练后直接进行评估的,而其他方法则是在对应数据集上进行后训练(微调)后再评估的
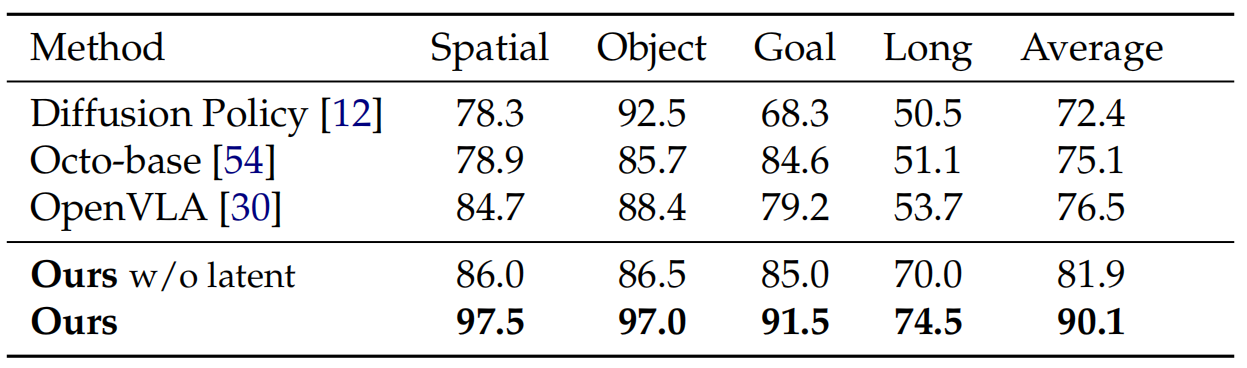
▲说明:villa-X与现有方法在LIBERO四个任务套件上的评估结果
(2) 真实世界:在Realman机械臂任务中,villa-X在Pick-out、Unstack等任务成功率达100%,对场景变化的泛化(改变积木颜色/桌布)表现更优;在Xarm灵巧手任务中,对seen和unseen的场景成功率均高于GR-1和GR00T。

▲说明:villa-X与现有方法在Xarm上的评估结果

▲说明:villa-X与现有方法在Realman上的评估结果

villa-X是一种新型的视觉-语言-潜在动作(ViLLA)框架,其目的是改进VLA模型中的潜在动作建模,提升机器人操作的泛化能力和性能。为解决现有方法中潜在动作不符合机器人物理动力学基础以及潜在动作向机器人动作信息传递效率不足的问题,villa-X提出了两项关键改进:一是在潜在动作模型(LAM)中引入本体感感知前向动力学模型(proprio FDM),使潜在动作向机器人物理行为对齐;二是通过联合扩散过程建模潜在动作与机器人动作分布,从而借助注意力机制实现更结构化的信息传递。相较于现有的方案,villa-X能够获得更优的潜在动作、更强的未来动作规划能力、更有效的动作整合机制,在SIMPLER、LIBERO等模拟环境以及Realman机械臂、Xarm灵巧手等真实世界场景中均展现出更高的成功率和泛化能力,为通用机器人操作研究提供了强有力的基础框架。

















 2718
2718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









