



摘要
在陌生环境中为机器人规划路径,是一个充满挑战的任务。无论是自主探索还是导航到指定目标,机器人都必须在信息不完整、动态更新的地图中做出决策,并实时评估潜在的信息增益。然而,现有的规划方法大多依赖规则化的边界(frontier)选择策略,或深度强化学习策略网络的隐式空间记忆,缺乏在不确定性下对环境结构进行主动推测与多假设推理的能力。
受人类“认知地图”启发,作者提出了 CogniPlan——一种融合生成式布局预测与图注意力规划的全学习型框架。它使用轻量化的 Wasserstein 生成对抗网络(WGAN) 对部分可观测地图进行条件补全,生成多种可能的环境布局假设;再通过图注意力网络在多假设下进行推理,评估不确定性和信息增益,选择最优路径。
实验结果表明,在数百个仿真地图和真实平面图数据集上,CogniPlan 相比现有最优方法在探索和导航任务中显著减少了行程长度,并在高保真仿真与真实机器人测试中展现了强大的泛化与落地能力。这一方法让机器人能够在“看不见”的地方提前推测、合理规划,向类人导航迈进一步。
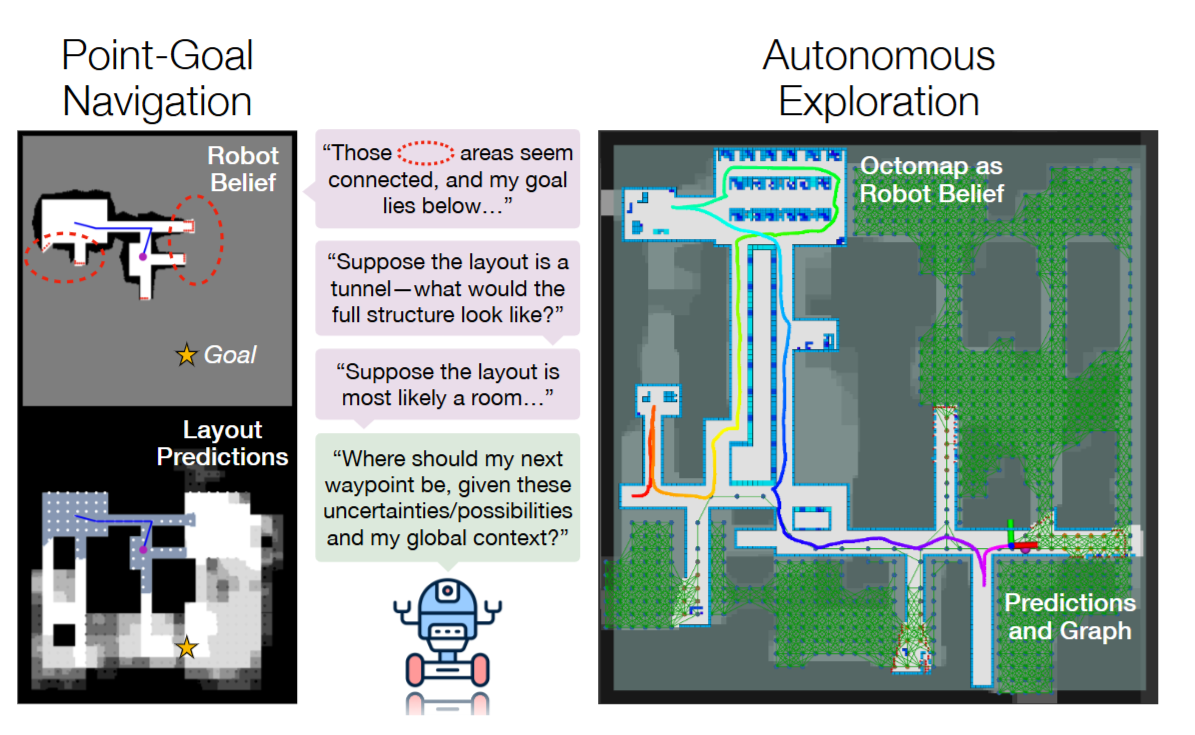
图1|CogniPlan能够通过对未知区域的地图进行“想象”,从而提前规划路径,利用不确定性来保证路径的一致性和准确性,提升机器人在导航与探索任务中的表现
论文出处:CoRL2025
论文标题:CogniPlan: Uncertainty-Guided Path Planning withConditional Generative Layout Prediction
论文作者:Yizhuo Wang, Haodong He, Jingsong Liang, Yuhong Cao1, Ritabrata Chakraborty, Guillaume Sartoretti

路径规划是机器人智能的核心能力,使移动机器人能够计算通往指定目标的高效路线以完成任务。然而在现实中,环境通常事先未知,这给决策带来了固有挑战。本文聚焦于两项相互关联的任务:自主探索与点目标导航。两者都要求机器人在未知环境中规划,以最短路线完成全局建图或到达目标。
在这种不确定性下进行有效推理,机器人必须基于部分且动态更新的地图信念行事,同时评估潜在信息增益——一些表面相似的选择可能带来截然不同的长期结果。现有大多数规划策略仍是基于规则的方法,通过接近度或预期未映射体积的贪婪启发式来选择边界(frontier)。这类方法在简单场景中有效,但对观测被动响应,缺乏对更广泛布局的主动推测能力,难以实现非贪婪、空间一致性的规划。
数据驱动方法包括两类:一类是将空间知识隐式编码于策略网络的深度强化学习(DRL);另一类是显式预测布局后再进行传统规划。然而,这两种范式很少结合,未充分探索它们的协同潜力。本文提出的问题是:能否将布局预测显式用于不确定性下的规划,使学习型规划器能在多种可能的空间假设上进行推理?
受到人类在导航中构建“认知地图”的能力启发,作者提出了 CogniPlan:一个由多种可能布局预测引导的全学习型路径规划框架。该框架首先采用轻量化 Wasserstein 生成对抗网络(WGAN) 在真实布局类型的条件下生成多种可能预测,捕捉布局不确定性,并输出二值化的自由空间/障碍物地图。在前向推理时,通过输入多组布局条件向量生成多假设预测,每个假设对应部分观测环境的不同结构推测。随后,CogniPlan 的图注意力网络利用这些假设进行推理,结合不确定性与信息增益,实时决定下一步的探索或导航目标点。
现有研究显示,基于图注意力的路径规划方法具有良好的灵活性与可扩展性,能在不同规模的环境中保持全局上下文。然而,这类方法往往仅依赖图表示,无法捕捉占据地图中细微而重要的结构细节,例如形状各异的边界在图中编码相似,丢失关键信息。CogniPlan 通过生成式模型预测布局,将这些结构细节放大并传递到图层,引导更加信息丰富的规划决策。与将布局生成器用于传统规划器及当前最优 DRL 规划器相比,CogniPlan 在探索任务中平均减少 17.7% 和 7.0% 的行程长度,在导航任务中减少 3.9% 和 12.5%,且无需额外训练或微调即可在真实平面图数据集上保持高效。最终,CogniPlan 在高保真 Gazebo 仿真与真实机器人测试中均展示了高质量路径规划与实际可行性。
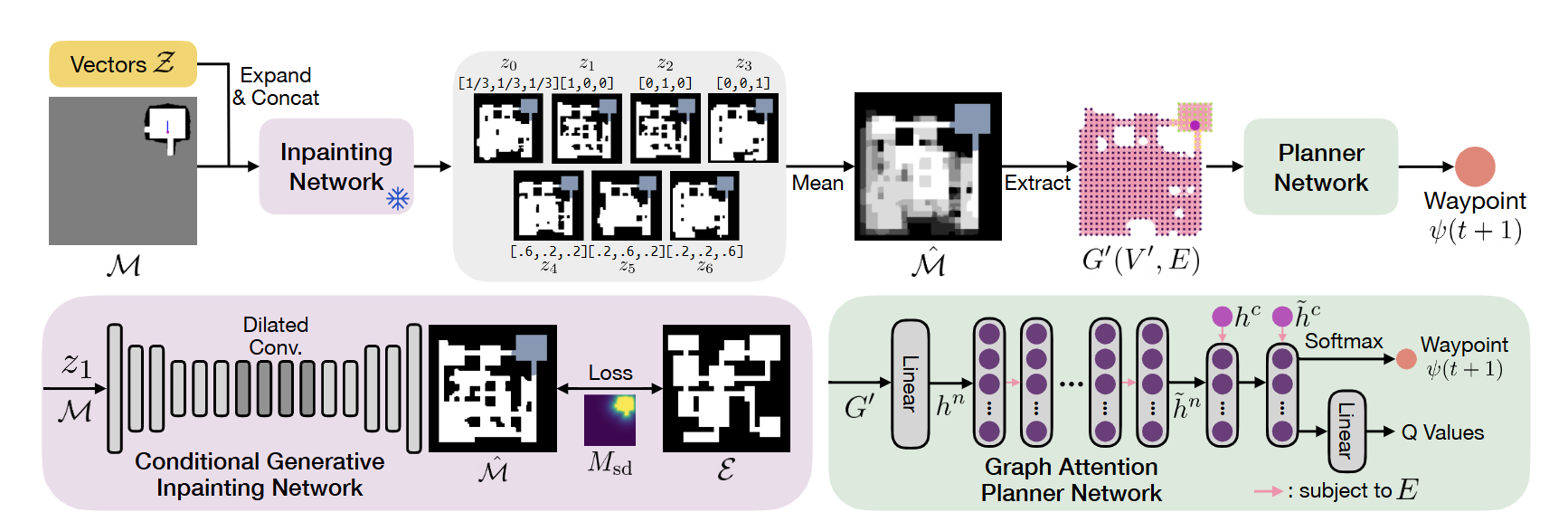
图2|全文方法总览

框架设计概述
CogniPlan 框架如图 2 所示,由条件生成式图像修补网络(Conditional Generative Inpainting Network)与图注意力规划器(Graph Attention Planner)协同组成。核心思路是:利用生成的布局预测结果,对包含丰富结构细节的信念地图进行信息增强;再从中提取与规划相关的要素(如前沿点、连通性、不确定性引导等),编码成图结构表示,用于后续路径规划决策。
问题形式化
环境被划分为可通行空间和被占据空间,机器人维护环境的空间信念,并将其表示为二维占据栅格地图,用于布局预测与路径规划。机器人根据策略在可通行空间中导航,生成无碰撞的轨迹点列。通过车载传感器(本文为 LiDAR)逐步揭示未知区域,并将其分类为自由空间或障碍物。
探索任务在障碍物边界完全闭合时结束;导航任务在机器人到达目标位置时结束。两类任务的目标都是最小化完成代价,例如行驶距离或总时间。
条件生成式图像修补
图像修补的目标是根据周围已知区域预测缺失部分的内容。现有方法多采用编码-解码架构(如 VAE 或 U-Net)生成局部补丁,主要用于地图细化或信息增益估计。本文假设:只要能生成一组多样化的布局预测,即便单次预测不完全准确,规划器也能学会在探索与利用之间取得平衡,并推理潜在信息增益与环境拓扑,从而实现非贪婪路径规划。
布局修补训练
为生成多样化预测,作者在三类地图数据集(房间、隧道、室外)上训练了带梯度惩罚的 Wasserstein GAN(WGAN-GP)。每个样本配有真实布局类型的条件向量(采用 one-hot 编码)。该条件向量被扩展到与输入地图相同的空间尺寸,并与机器人的占据地图信念及未知区域掩码拼接后输入生成器。生成器输出预测的自由空间与障碍物分布。
生成器的训练目标包含:
● 对抗损失(来自判别器);
● 全局重构的 L1 损失;
● Dice(F1-score)损失用于衡量预测与真实的重叠精度;
● 空间折扣掩码损失,用于对接近已知区域的未知像素赋予更高权重,重点关注影响可通行性的关键位置,并适应不规则掩码形状。
推理阶段的不确定性
在推理时,真实布局类型未知。作者设计了多组条件向量,包括 one-hot 和 soft one-hot 形式,用于生成多样化的布局预测。输出经过二值化处理,并通过形态学闭运算与开运算去除小噪声。多次预测的平均结果被用作不确定性估计,从而捕捉占据图中图结构难以反映的细节,例如未闭合的走廊、新发现的墙角、多分支前沿结构等。
该生成器参数量不足 35 万,可在 CPU 上实时完成多次推理,从而高效地进行不确定性估计与规划器训练。相比 LaMa 修补模型(参数量超过 5000 万),计算开销显著降低。
不确定性引导的规划网络
图构建
相比直接在占据图上规划,基于图的表示更易扩展且能保留全局上下文。CogniPlan 在每个决策时刻,根据预测布局构建无碰撞图。在自由区域内均匀布置节点,并依据距离和可见性连边。每个节点附加以下属性:
节点位于已知区域或预测区域的标识;
1. 预测自由空间的概率(取多次预测的平均值);
2. 基于可观测前沿数量计算的归一化效用值,在预测区域中设置为最低值;
3. 导向点标识,用于死胡同时回溯,计算基于预测图而非仅已知区域。
4. 在导航任务中,还会为节点增加指向目标点的方向向量。
策略网络
策略网络采用图注意力结构,包括编码器和解码器:
编码器将节点属性映射为特征向量,通过多层掩码自注意力聚合邻居信息,逐层扩大感受野,实现局部与全局信息融合;
解码器以机器人当前位置特征为查询,与邻居节点特征进行注意力计算,注意力分数直接作为动作概率分布,从而选择下一步移动的节点。
价值网络
价值网络用于估计状态-动作价值(Q 值),采用特权学习,即直接使用来自真实环境的真值图作为输入。其结构与策略网络一致,但输出为 Q 值而非注意力分数。
网络训练细节
由于 GAN 容易出现模式崩溃与梯度爆炸,作者采用 WGAN-GP,并引入预热机制:前一阶段仅训练生成器,使用纯重构损失以获得初步的布局预测;在此基础上进入完整的对抗训练阶段,判别器的损失为真实样本与生成样本输出的差异,并加上梯度惩罚项。

模拟实验
在 150 张不同布局类型的地图上进行探索任务测试,CogniPlan 相比最近前沿法、基于效用法、NBVP、TARE Local、ARiADNE+ 及基于修补预测的 TARE 方法,均实现显著性能提升。在导航任务中,它甚至略微超越了近似最优的 D*Lite 搜索规划器(见图3)。
结果显示,CogniPlan 在探索中可减少 17.7% 的行驶距离,在导航中减少 3.9%~12.5%,且优势明显高于直接使用修补预测与传统规划器的组合方案(Inpaint+TARE)。作者指出,这一优势来自 CogniPlan 在下游规划中对预测布局的不确定性进行建模,从而避免了预测误差导致的低效 zig-zag 行为(见图4)。
实验进一步分析了推理时布局预测的数量,发现从 1 个增加到 4~7 个能显著减少行驶距离,但收益在 4 个后趋于饱和,说明少量多样化的假设就足以为规划提供可靠指导。
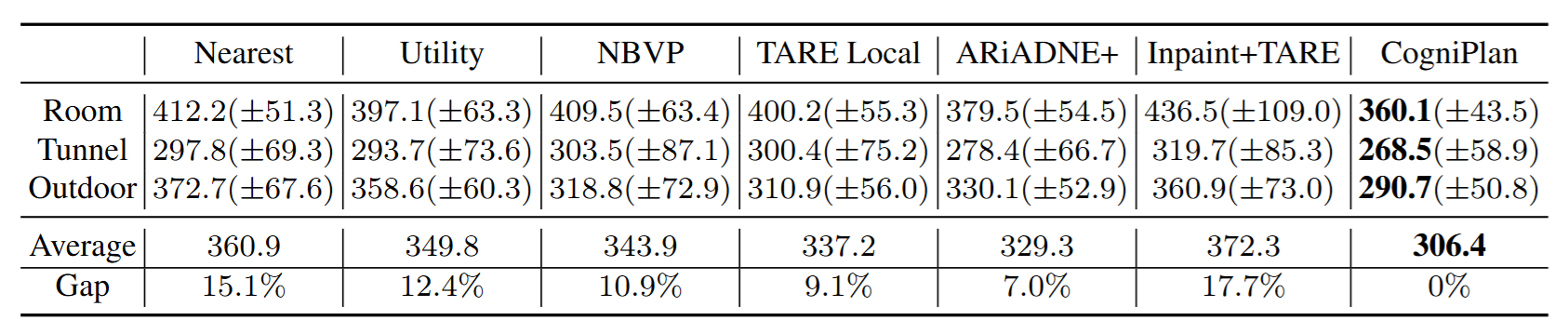
图3|模拟实验量化结果(探索)

图4|模拟实验量化结果(导航)
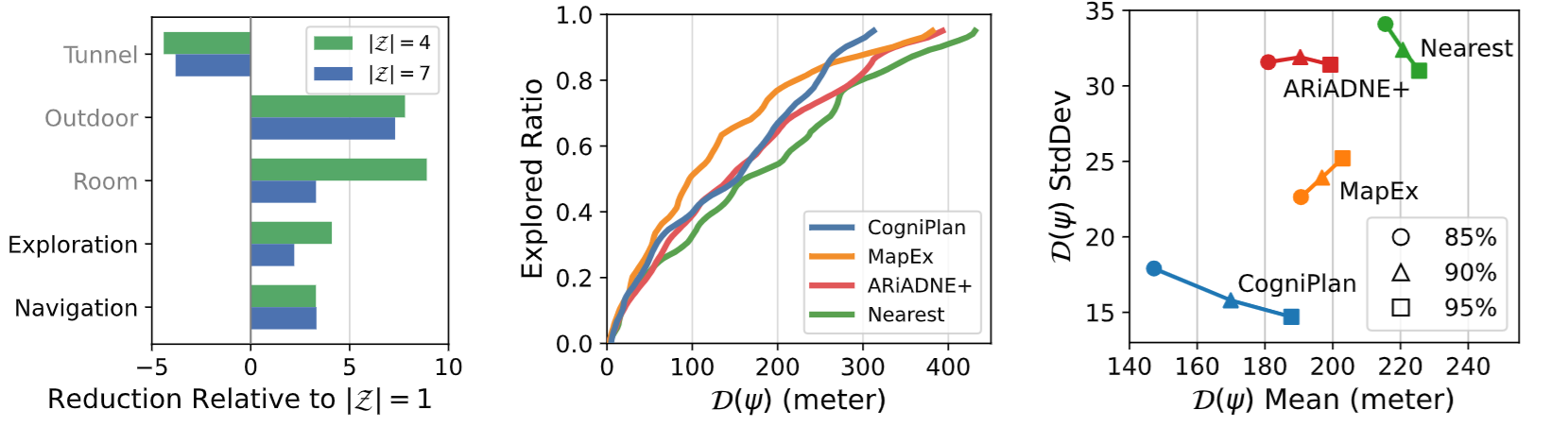
图5|轨迹长度;探索规划;对于起点的稳健性综合实验结果
真实机器人实验
在 KTH Floor Plan 数据集和 Gazebo 仿真环境中,CogniPlan 在零样本条件下与 Nearest、ARiADNE+、MapEx 等方法对比。
结果显示,MapEx 在早期(80% 覆盖率前)占优,但后期趋于停滞;CogniPlan 则能保持稳定推进,在 90% 覆盖率后反超,展现出更好的长程规划能力(见图5)。
此外,在不同起点位置的鲁棒性测试中,CogniPlan 在 85%、90%、95% 覆盖率下均获得最短平均路径和最低方差,起点敏感性显著低于对比方法。这归功于其预测布局提供的全局结构先验,使路径规划更一致、回溯更少(见图5)。
作者在一个 30m × 10m 室内实验室 部署四轮全向机器人,场景中布满桌椅、设备和移动行人。机器人搭载 Livox Mid-360 3D LiDAR,使用 0.2m 分辨率的 Octomap 构建地图,0.8m 的路径节点间距规划路径。测试结果表明,CogniPlan 能在 约 6 分钟内完成探索,总行驶约 100 米。可视化结果显示,它能在探索过程中持续生成并利用布局预测,引导机器人高效覆盖全局(见图6)。

图6|真实机器人实验结果

CogniPlan 的实验结果非常全面,从模拟到真实硬件都验证了它在未知环境探索与导航上的优势。其关键亮点在于:不仅生成多样化的环境布局预测,还能利用不确定性引导下游规划器,从而减少冗余移动、提升全局一致性。这种“带着假设去规划”的思路,使它在长程任务中表现尤为突出,尤其适合真实场景的快速部署。

















 1327
1327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









