



引言
在人工智能的发展历程中,自然语言处理(NLP)与计算机视觉(CV)的飞速发展已深刻重塑了人机互动的图景。如今,这股变革的浪潮正汹涌澎湃地涌入机器人技术领域,特别是具身智能的崭新篇章。清华大学的研究团队近期取得了具有里程碑意义的突破——揭示了data scaling laws的奥秘。这一发现不仅惊人地揭示了机器人领域与语言模型之间的深刻相似性,更为我们预测数据规模与模型性能之间的关系提供了坚实支撑。
1 研究方法
1.1 数据收集
研究团队借助便携式手持夹爪UMI,在丰富多样的真实环境中精心收集了超过4万条人类演示数据。这些数据广泛覆盖了火锅店、咖啡厅、公园等多种日常场景,更不乏喷泉旁、电梯内等独特环境,为模型训练提供了丰富的素材。

1.2 策略学习方法
研究者们采用了Diffusion Policy方法来从收集的数据中学习机器人控制模型。这种方法是一种模仿学习策略,它通过模拟人类的行为来训练机器人执行特定的任务。Diffusion Policy的核心思想是将动作预测问题转化为一个去噪过程,其中模型需要从噪声中恢复出正确的动作序列。
1.3 实验设计
为深入探究数据规模法则,研究团队精心设计了多维度实验。实验涵盖物体泛化、环境泛化及环境-物体组合泛化三大维度,通过系统调整训练数据规模,全面评估模型在未见环境中的表现。

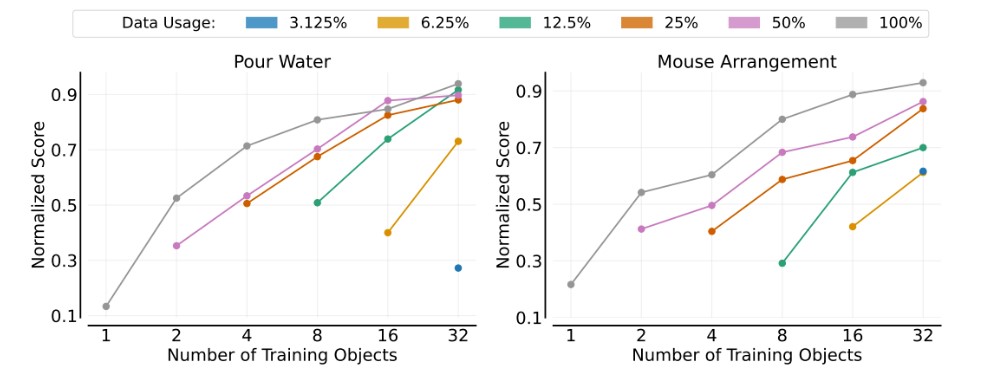
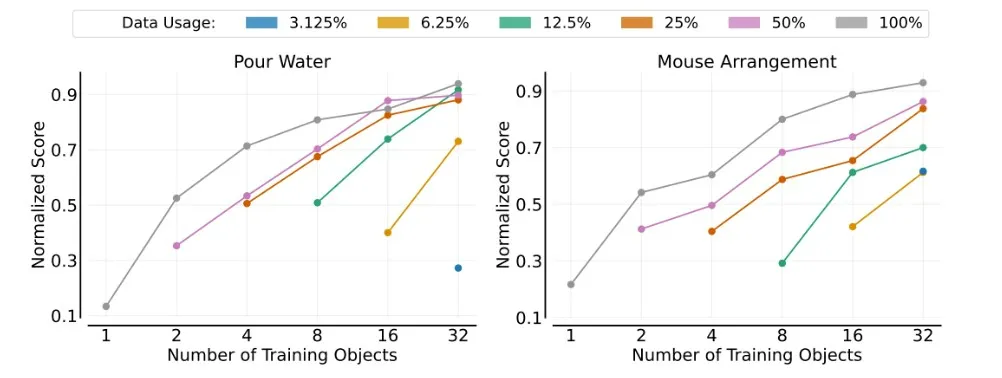
物体泛化
在物体泛化实验中,研究者固定训练环境数量,逐步增加训练物体数量,细致观察模型在未见物体上的表现。此实验旨在揭示模型对新物体的泛化能力如何随训练物体数量的增加而提升。
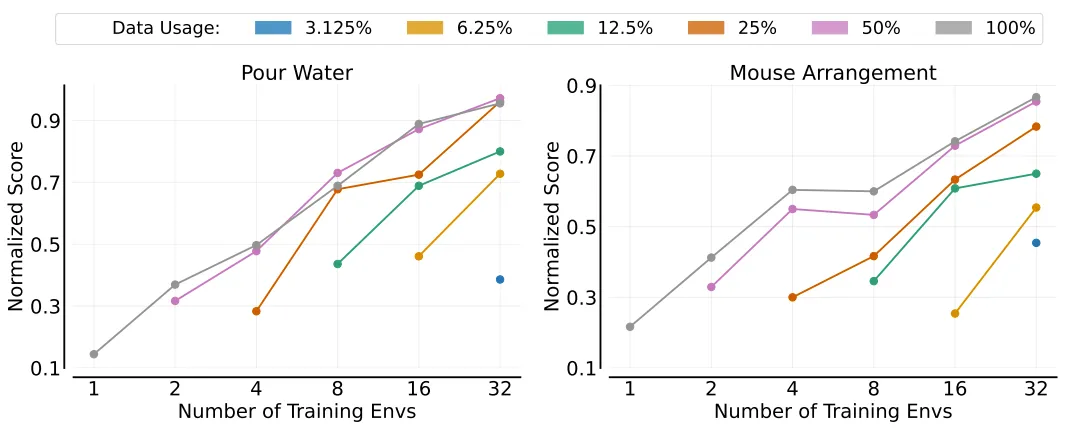
环境泛化
在环境泛化实验中,研究者固定训练物体数量,逐步增加训练环境数量,并深入评估模型在未见环境中的表现。此实验旨在探究模型对新环境的泛化能力如何随训练环境数量的增加而增强。
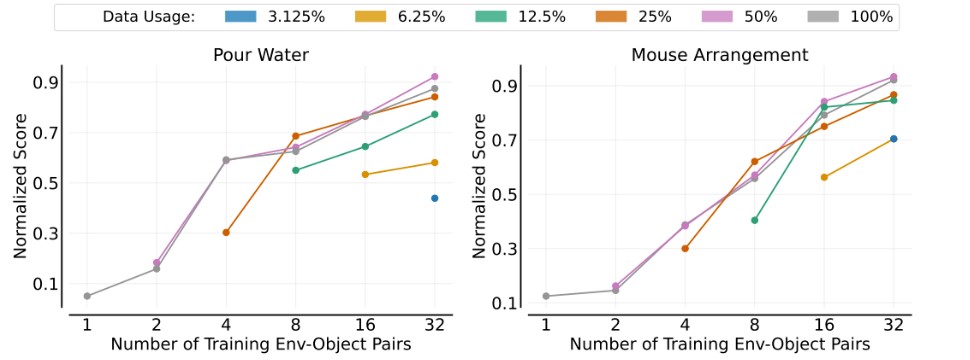
环境-物体组合泛化
在环境-物体组合泛化实验中,研究者同时调整训练环境和训练物体的数量,全面评估模型在未见环境-物体组合上的表现。此实验旨在深入剖析模型对新环境-物体组合的泛化能力如何随训练环境-物体对数量的增加而提升。
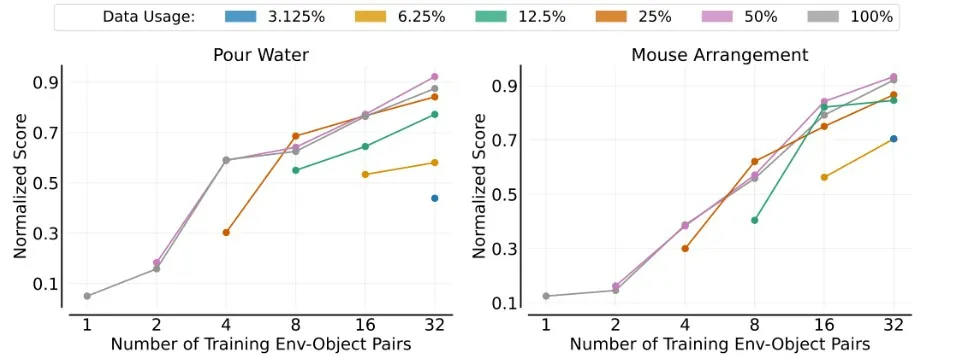
1.4 研究发现
研究团队取得了三项开创性的幂律关系发现:
模型对于新物体的泛化能力,与其训练时所接触的“物体”数量之间,呈现出显著的幂律关系。
同样地,模型对于新环境的泛化能力,也与训练时所经历的“环境”数量遵循幂律分布。
更为复杂的是,模型在应对环境-物体组合时的泛化能力,与训练中所接触的“环境-物体对”的数量之间,亦遵循幂律关系。
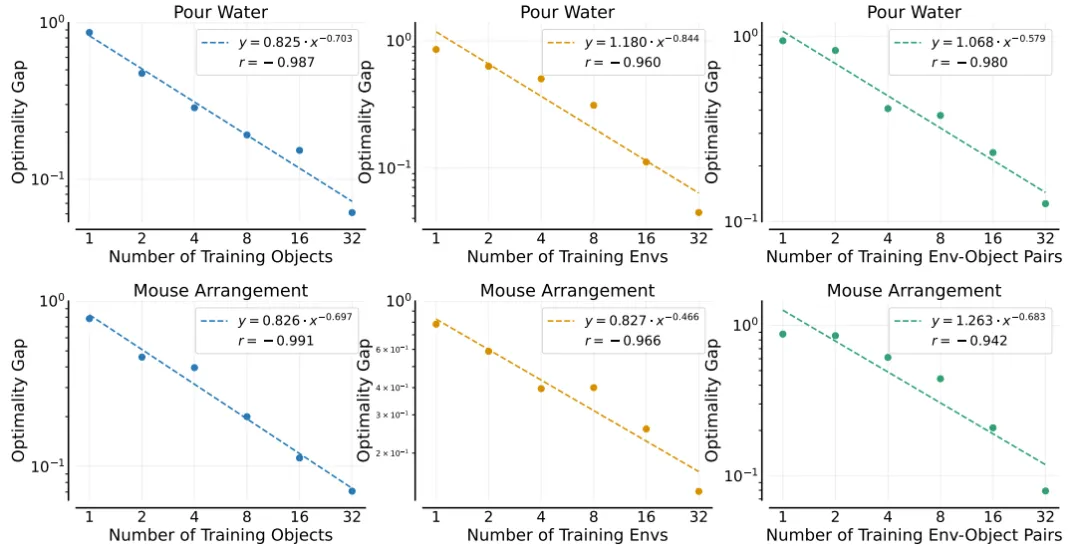
这些发现表明,只要数据量足够庞大,机器人将能够自然而然地理解并适应物理世界的复杂多样性。
2 数据收集策略的突破
研究团队还成功攻克了业界长期以来的一个难题:在给定操作任务的前提下,如何科学合理地选择环境数量、物体数量以及每个物体的演示次数?
当环境多样性足够丰富时,在单一环境中过度采集不同操作物体的数据,其收益将变得微乎其微。 这意味着,每个环境仅需一个代表性操作物体的数据即可满足需求。 单个物体的演示数据在达到一定量后,会出现明显的饱和现象。 以倒水和摆放鼠标等任务为例,当总演示次数达到800次时,性能提升已趋于平缓。因此,每个物体仅需约50次演示即可达到较为理想的效果。
3 模型规模化探索的意外发现
除了数据规模,研究团队在模型规模化方面也取得了三项重要发现:
视觉编码器必须经过充分的预训练以及精细的微调,二者缺一不可,共同构成了高性能模型的基础。
通过扩大视觉编码器的规模,可以显著提升模型的性能表现。
尽管在视觉编码器上取得了显著成效,但扩大扩散模型的规模却并未带来明显的性能提升。这一现象仍需进一步深入研究,以探索其背后的原因。
4 未来展望
数据规模化正引领机器人技术步入一个全新的时代。但研究团队也提醒我们,盲目追求数据量的增长并非明智之举。相较于单纯增加数据量,提升数据质量可能更为关键。未来的挑战在于,如何准确识别出真正需要扩展的数据类型,并探索最高效的数据采集策略,以获取这些高质量的数据资源。
Ref:
Data Scaling Laws inImitation Learning for Robotic Manipulation
编译|sienna
审核|fafa
第二届线下自主机器人研讨会(ARTS)即将召开👇
第二届ARTS报名入口即详情须知
第二届ARTS奖学金通知
ARTS 2024 学术辩论通知抢“鲜”发布

















 7193
7193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









