



——前言——
本篇文章由原paper一作Zhenxin Li(李臻欣)全权翻译写作,李臻欣是一位非常优秀的年轻学者,目前复旦大学硕士在读,提出过BEVNeXt、Hydra-MDP工作;Hydra-MDP方法在CVPR2024 Navsim挑战赛中获得第一名。
论文标题:
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
论文作者:
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, Yu-Gang Jiang, Jose M. Alvarez
Github:
https://github.com/NVlabs/Hydra-MDP
NVIDIA博客:
https://blogs.nvidia.com/blog/auto-research-cvpr-2024/
导读:
端到端规划(End-to-end planning)被认为是实现自动驾驶的一个极富前景的方向。但最近的研究表明该类方法与所采用的数据集本身存在种种问题。在我们的Hydra-MDP中,我们利用来自人类和基于规则的教师的知识蒸馏来训练学生模型,从而学习在各种闭环评估指标下模型应如何决策。凭借基于规则的教师的知识,Hydra-MDP能够学习环境如何以端到端的方式影响规划。该方法在今年的CVPR Navsim挑战赛中获得第一名,展示了在不同驾驶环境和条件下的优异表现。本次介绍分为三部分:NAVSIM挑战赛背景、Hydra-MDP框架以及实验与分析。©️【深蓝AI】
1. NAVSIM挑战赛背景

NAVSIM挑战赛(大规模端到端自动驾驶,End-to-end Driving at Scale)是今年CVPR 2024 Autonomous Grand Challenge中举办的一项新比赛,比赛的目标在于评估端到端自动驾驶模型的性能。在先前的端到端自动驾驶数据集中,研究者或是采用了模拟器进行闭环的驾驶评估,或是在真实数据中进行开环的评测。前者往往因为巨大的计算开销而在可扩展性上受限,同时驾驶场景难以体现真实世界的多样性;后者则采用了开环的指标评测模型,但无法真正反映端到端模型的驾驶安全性。结合以上两点,此次比赛所使用的NAVSIM数据集采用了现实世界真实数据,并且在评测时使用了模拟器来计算车辆的行驶路线是否安全可靠,有效地提升了开环指标的可靠性。

在这次的比赛中,一共有143个团队参与,我们英伟达团队的Hydra-MDP方案在这些方案中脱颖而出,获得了比赛的第一名与创新奖。
2. Hydra-MDP框架
在介绍Hydra-MDP框架之前,我们先来回顾之前的模型范式并对它们的问题进行总结,以此来说明为什么需要一个新的范式。随后Hydra-MDP具体的模型架构展开介绍。
2.1 端到端范式

如上图,先前的端到端模型主要分为两种范式:
● 单模式规划+单目标学习(UniAD、VAD、Transfuser、……):
在这一类范式中,模型会有感知、规划等神经网络模块,最后的规划模块一般会使用一个回归头预测一条轨迹。
● 多模式规划+单目标学习(VADv2、QuAD、……):
相比于第一种范式,第二种范式会在模型中预测多条轨迹,并通过一些后处理的方式从中筛选出最佳轨迹,以此解决规划时的不确定性问题。
这两种范式都使用了唯一的轨迹回放作为正样本进行训练,因此模型从每一个样本中所学习到有关规划的知识是有限的。其次,第二种范式一般会使用一些打分策略对各个轨迹进行打分,并根据分数挑选出最好的轨迹。打分的过程一般会依赖于模型的感知预测,例如轨迹是否会模型所预测到的其他车辆发生碰撞,因此这个过程往往是难以进行端到端学习的,同时如果模型的感知性能不佳,也会影响到后续的规划性能。
● 为了应对这些问题,我们提出了第三种范式:多模式规划+多目标学习。
我们不仅将轨迹回放作为训练中的正样本,同时引入模拟器来生成多条符合当前场景的正样本轨迹。由于模拟器使用的是感知的真值标注,因此这个过程并不会由于模型的错误预测而损失信息。同时我们将感知真值以一种端到端可学习的方式运用到规划的训练中。
2.2 模型架构

上图是Hydra-MDP的模型结构,总共分为三个部分:
● 感知网络:
Hydra-MDP的感知网络使用了NAVSIM挑战赛所提供的Transfuser模型,该模型会接受LiDAR点云以及三张前视图作为输入。通过一系列Transformer模块进行多模态信息的融合,生成后续规划中会使用到的token。
● 轨迹解码器:
这里我们使用到了VADv2所提出的轨迹“词表”的概念。首先我们会从一个更大的数据集中使用聚类算法采样出4096、8192条轨迹。通过这个离散的词表,我们能够将轨迹规划,也就是一个在连续空间的回归问题离散化,转为对这些轨迹的分类。在训练中我们会使用人类专家的回放轨迹进行监督,并使用轨迹之间的距离来计算损失函数:
L i m = − ∑ i = 1 k y i log ( S i i m ) y i = e − ( T ^ − T i ) 2 ∑ j = 1 k e − ( T ^ − T j ) 2 \mathcal{L}_{i m}=-\sum_{i=1}^{k} y_{i} \log \left(\mathcal{S}_{i}^{i m}\right) \quad y_{i}=\frac{e^{-\left(\hat{T}-T_{i}\right)^{2}}}{\sum_{j=1}^{k} e^{-\left(\hat{T}-T_{j}\right)^{2}}} Lim=−i=1∑kyilog(Siim)yi=∑j=1ke−(T^−Tj)2e−(T^−Ti)2
●多目标、多头蒸馏模块:
这个模块的作用是给模型的规划引入更多的正样本,让模型从感知真值所包含的信息去学习如何规划。这个模块在训练时主要进行两个步骤:
○使用基于规则的模拟器、感知真值对轨迹词表中的每条轨迹进行模拟,生成一系列基于规则的“教师”轨迹。这些轨迹和先前的回放轨迹共同作为训练过程中的正样本。
○我们会使用一组多头MLP去拟合每一个基于规则的“教师”轨迹。
由于模型无法完美地拟合每一个教师轨迹(人类教师or基于规则的教师),在模型推理过程中,我们会对各个MLP的头部网络的输出进行加权处理,来挑选出最好的轨迹:
f ~ ( T i , O ) = − ( w 1 log S i i m + w 2 log S i N C + w 3 log S i D A C + w 4 log ( 5 S i T T C + 2 S i C + 5 S i E P ) ) \tilde{f}\left(T_{i}, O\right)= -\left(w_{1} \log \mathcal{S}_{i}^{i m}+w_{2} \log \mathcal{S}_{i}^{N C}+w_{3} \log \mathcal{S}_{i}^{D A C}+w_{4} \log \left(5 \mathcal{S}_{i}^{T T C}+2 \mathcal{S}_{i}^{C}+5 \mathcal{S}_{i}^{E P}\right)\right) f~(Ti,O)=−(w1logSiim+w2logSiNC+w3logSiDAC+w4log(5SiTTC+2SiC+5SiEP))⬅️左右滑动查看完整公式➡️
2.3 多目标、多头蒸馏的优势
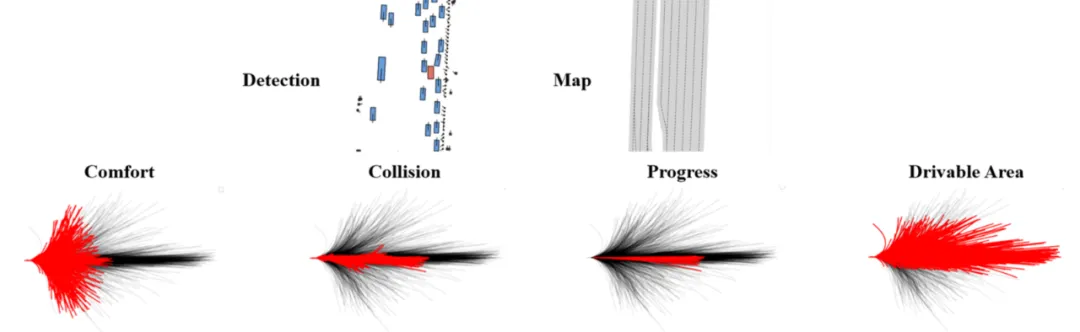
上图进一步说明了教师轨迹生成的过程:给定一系列的3D物体检测标注与地图信息,我们能够通过基于规则的模拟器来对轨迹词表中的候选轨迹进行模拟,来区分不同指标下哪些轨迹是安全合适的,哪些是违反交通规则的。使用多目标、多头蒸馏能为规划带来以下的优势:
○Hydra-MDP并不依赖于模型的感知预测进行后处理,而是在训练过程中直接使用感知的真值来引导模型的轨迹规划。
○这种方式能够使感知真值以一种端到端可训练的方式让模型学习到面对不同的场景时该如何进行规划。
○通过引入这种多目标、多头的蒸馏,我们能在模型的训练过程中为整个轨迹词表带来充分的监督。
3. 实验与分析
最后,我们通过实验以及可视化来说明Hydra-MDP方案的有效性。
3.1 实验结果
●消融实验

在上表中,我们首先使用了NAVSIM比赛所提供Transfuser作为基线模型进行比较,Transfuser使用了较小的骨干网络(ResNet-34)对图像信息进行编码。在实验过程中,我们有以下几个发现:
1.更大的轨迹词表会产生更好的规划性能。
2.如果我们将整个PDM Score作为模型学习的目标,模型的性能会反而下降,因此说明多目标学习的必要性。
3.如果引入一个新的学习目标(如Ego Progress),那么模型可以在对应指标上有更好的性能。这说明了我们方法的可扩展性,通过引入新的规则教师,Hydra-MDP能在新的规则上表现更出色。
4.Hydra-MDP最终能够在PDM Score上超越基线模型8.5分,大大提升了规划的性能。
●模型的可扩展性

相比于前一张表格,该表中的模型使用了更大的骨干网络进行实验。先前的一些工作(如UniAD)在使用更大的骨干网络时,对规划性能的提升比较有限。这里我们将感知网络中的ResNet-34扩大为ViT-L、V2-99这类更大规模的网络时,可以看到较为显著的性能提升。
3.2 可视化
为了更好观察模型在种种驾驶情况下的表现,我们对Hydra-MDP做了一些可视化的分析供大家参考:
●理解地图结构

●面对长尾物体时的超车

●应对驾驶员意图的不确定性

4. 总结
在这次的NAVSIM挑战赛中,我们提出了Hydra-MDP框架。这个框架是一种通用的端到端规划范式,能使模型以一种可扩展的方式从人类专家和基于规则的教师模型中学习和规划有关的知识。同时,Hydra-MDP在NAVSIM数据集上达到了最先进的规划性能。
移步公众号【深蓝AI】,第一时间获取自动驾驶、人工智能与机器人行业最新最前沿论文和科技动态👇
深蓝AI·赋能AI+智驾+机器人

















 1519
1519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









