




 该博客详细介绍了分类器评估的各种指标,包括混淆矩阵、准确率、ROC曲线、AUC、KS曲线、CAP和AR值、模型稳定性PSI以及Lift和Gain图的原理和Python实现。通过这些指标,可以全面评估模型的性能和稳定性,指导模型优化。
该博客详细介绍了分类器评估的各种指标,包括混淆矩阵、准确率、ROC曲线、AUC、KS曲线、CAP和AR值、模型稳定性PSI以及Lift和Gain图的原理和Python实现。通过这些指标,可以全面评估模型的性能和稳定性,指导模型优化。
目录
2、准确率(Accuracy)、精确率(Precision)、灵敏度(Sensitivity)、召回率(Recall)、特异度(Specificity)、F1 Score等指标
1、混淆矩阵
混淆矩阵是最简单、最基础的分类的评估指标,在这里只讲二分类的混淆矩阵,多分类与二分类类似。
混淆矩阵原理

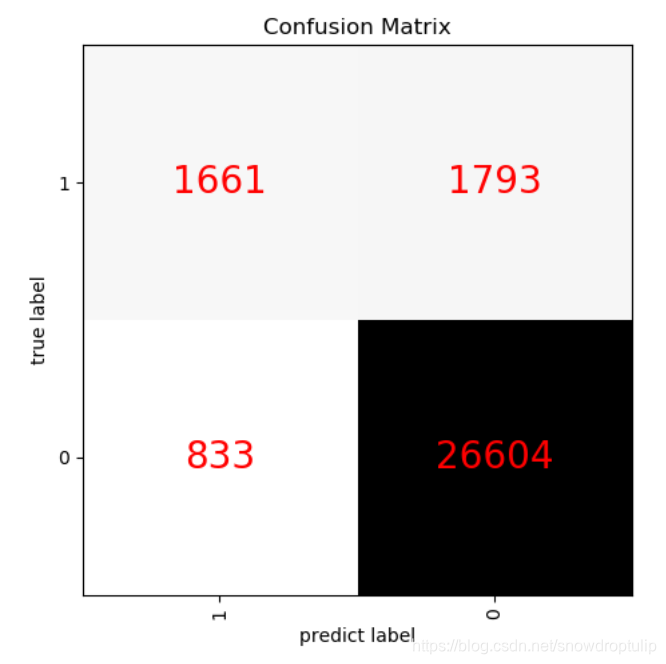
真实值是positive,模型认为是positive的数量(True Positive=TP)
真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第一类错误(Type I Error)
真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第二类错误(Type II Error)
真实值是negative,模型认为是negative的数量(True Negative=TN)
混淆矩阵的python代码
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import numpy as np
def plot_confusion_matrix(y, y_hat, labels = [1,0]):
# y是真实的标签,y_hat是预测的标签,labels表示label的展示顺序
cm = confusion_matrix(y,y_hat,labels = labels)
plt.figure(figsize=(5, 5))
plt.imshow(cm, interpolation='nearest',cmap=plt.cm.binary)
plt.xticks(np.array(range(len(labels))), labels, rotation=90) # 将标签印在x轴坐标上
plt.yticks(np.array(range(len(labels))), labels) # 将标签印在y轴坐标上
plt.title('Confusion Matrix') # 标题
plt.xlabel('predict label') # x轴
plt.ylabel('true label') # y轴
ind_array = np.arange(len(labels))
x, y = np.meshgrid(ind_array, ind_array)
for x_val, y_val in zip(x.flatten(), y.flatten()):
c = cm[y_val][x_val]
plt.text(x_val, y_val, "%s" % (c,), color='red', fontsize=20, va='center', ha='center')
plt.show()图形结果:
2、准确率(Accuracy)、精确率(Precision)、灵敏度(Sensitivity)、召回率(Recall)、特异度(Specificity)、F1 Score等指标
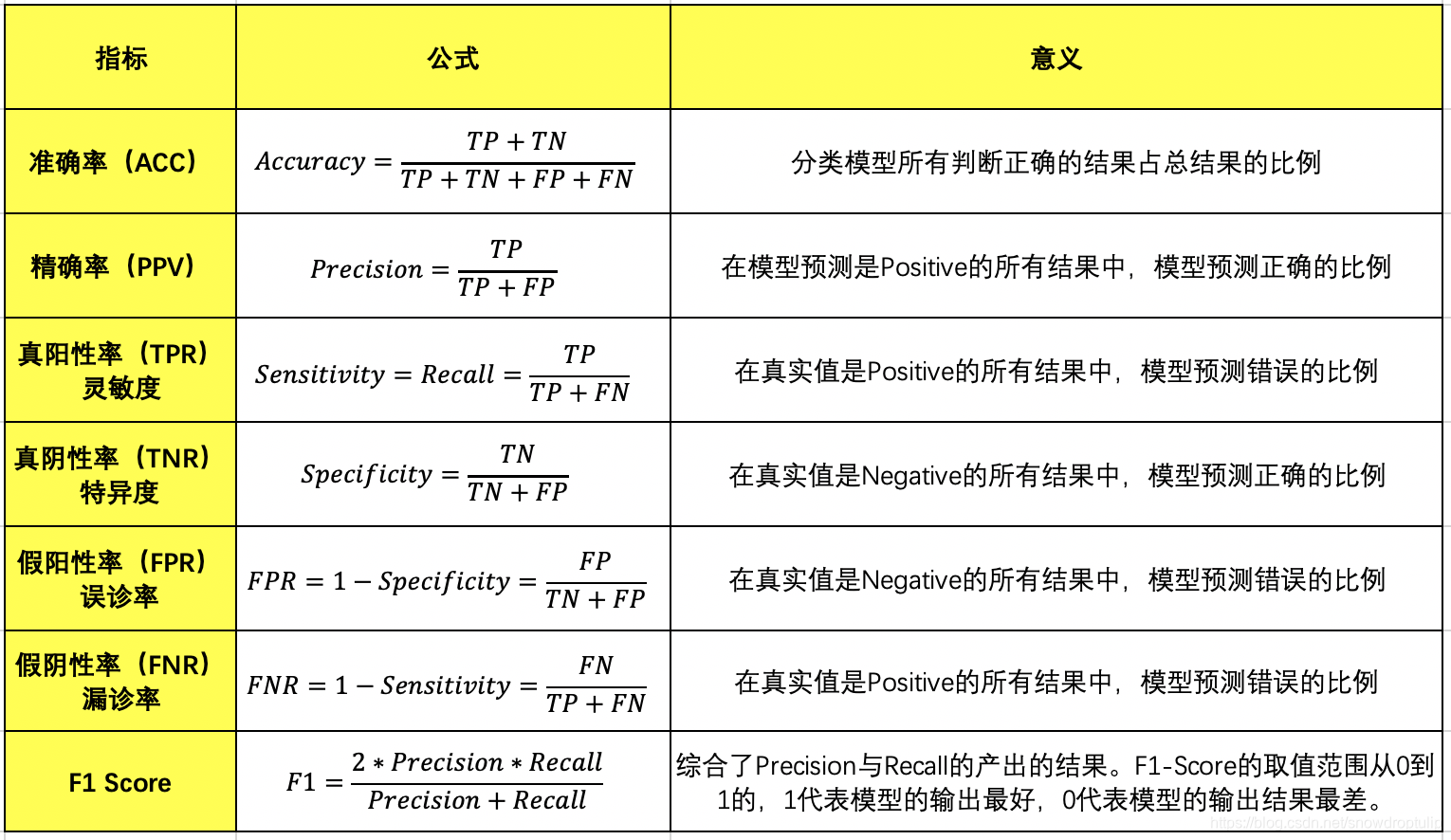
使用较多的指标通常为精确率和召回率。
精确率描述模型预测结果准确度的衡量指标,表示模型预测结果有多准。
召回率描述模型预测结果全面性的衡量指标,表示模型预测结果涵盖有多全。
一般来说:
阈值越大,召回率(TPR)越低,精确率(PPV)越高,假阳性率(FPR)越低。
当阈值为0时,召回率(TPR)等于1,假阳性率(FPR)等于1(因为所有的样本都预测为正样本,所以真阳性率为1,假阳性率也为1)
当阈值为1时,召回率(TPR)等于0,假阳性率(FPR)等于0(因为所有的样本都被预测为负样本,所以真阳性率为0,假阳性率为0)
假设:全行下个月信用卡用户共1,000,000,其中实际逾期的客户数为10,000;模型预测出15,000个客户会出现逾期,其中8000个客户为真实逾期用户。
从而:精确率=TP/(TP+FP)=8000/15000=0.53
召回率=TP/(TP+FN)=8000/10000=0.8
3、ROC曲线、AUC、GINI系数
ROC曲线原理
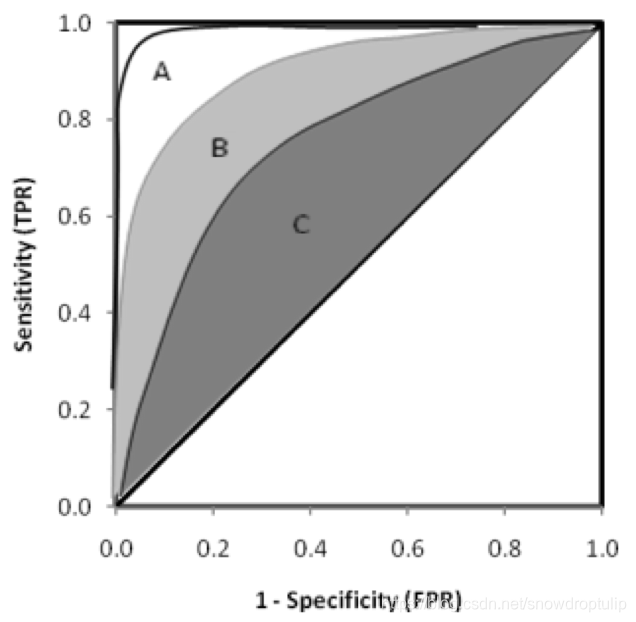
ROC的全称是Receiver Operating Characteristic Curve,中文名字叫“受试者工作特征曲线”,顾名思义,其主要的分析方法就是画这条特征曲线。
ROC曲线的横轴是FPR(假阳性率、误诊率)、纵轴是TPR(真阳性率、灵敏度)。
这条曲线代表的是在不同的阈值下,FPR和TPR的一个变化曲线,通常,我们希望FPR尽可能的小,而TPR尽可能的大,所以曲线越靠近左上角,模型的效果越好。
如下图,模型效果A>B>C
AUC原理
AUC(Area Under Curve)被定义为ROC曲线下的面积,取值范围一般在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
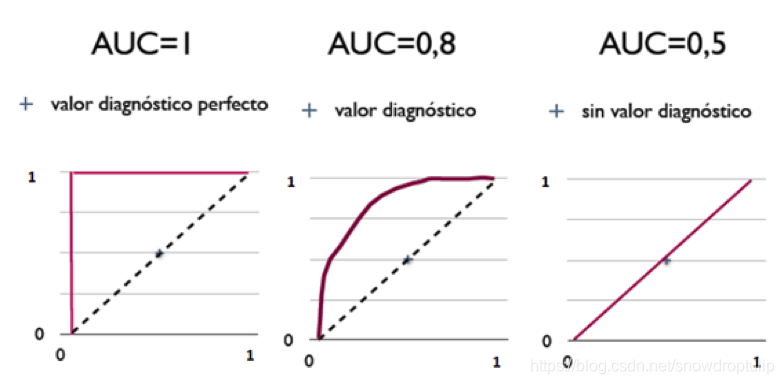
AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
GINI系数
Gini coefficient 是指绝对公平线(line of equality)和洛伦茨曲线(Lorenz Curve)围成的面积与绝对公平线以下面积的比例,即gini coefficient = A面积 / (A面积+B面积) 。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1006
1006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









