






 本文深入讲解BoostedTree的原理,从监督学习的概念出发,详细解析回归树和集成方法,重点阐述BoostedTree的模型与参数,及GradientBoosting的学习过程。
本文深入讲解BoostedTree的原理,从监督学习的概念出发,详细解析回归树和集成方法,重点阐述BoostedTree的模型与参数,及GradientBoosting的学习过程。
工作了好多年,从最开始使用xgboost,到后来的lightGBM,它们的底层原理都是Boosted Tree,之前一直没有做过总结,今天我就把陈天奇的Boosted Tree翻译一下,让大家从原理了解什么是Boosted Tree,如果有任何理解或者描述错误的地方,欢迎大家批评指正。
如果涉及到我自己的理解的内容,我会用绿色的字来表示。
建议大家直接看原文档,链接为:https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
1 监督学习中的一些重要概念
在开始介绍boosted Tree之前,我们先来回顾一下机器学习中的一些重要的概念。
1.1 监督学习的要素
- 符号(Notations):
表示训练集中的第
个样本。
- 模型(Model):对于已知的
如何预测
?
- 线性模型(Linear Model):
(包括线性模型和逻辑回归)
- 预测值
- 线性回归(Linear Regression):
- 逻辑回归(Logistic Regression):
预测了实例为正的概率
- 其他:例如在排名任务中
- 线性回归(Linear Regression):
- 线性模型(Linear Model):
- 参数(Parameters):需要从数据中学习的东西:
- 线性模型(Linear Model):
- 线性模型(Linear Model):
- 目标函数(Objective function):
- 其中:
代表训练损失函数(Training Loss),表示模型多好的拟合了训练数据;
为正则化项(Regularization)衡量了模型的复杂程度
- 其中:
- 训练数据损失函数(Training Loss):
- 平方损失(Square Loss):
- 逻辑损失(Logistic Loss):
- 平方损失(Square Loss):
- 正则化项(Regularization):描述了模型的复杂程度:
- L2 norm:
- L1 norm (lasso):
- L2 norm:
1.2 监督学习的进阶
- Ridge回归:
- Ridge是线性模型(Linear Model),用的是平方损失(Square Loss),正则化项是L2 norm
- Lasso:
- Lasso是线性模型(Linear Model),用的是平方损失(Square Loss),正则化项是L1 norm
- 逻辑回归(Logistic Regression):
- 逻辑回归是线性模型(Linear Model),用的是逻辑损失(Logistic Loss),正则化项是L2 norm
1.3 目标与偏差方差的权衡
回顾一下目标函数,为什么目标函数需要两部分组成呢?
- 优化训练损失函数(Training Loss)有助于建立预测模型,很好地拟合训练数据至少能让你更接近潜在的训练数据的分布;
- 优化正则化项(Regularizaion)有助于建立简单的模型:模型越简单,未来预测的方差越小,预测越稳定
2 回归树(Regression Tree)和集成(Ensemble)
本小结主要讲述我们学习什么。
2.1 回归树(Regression Tree)
回归树,也就是分类回归树(Classification and Regression Tree):
- 决策规则和决策树一样
- 每个叶子结点有一个值
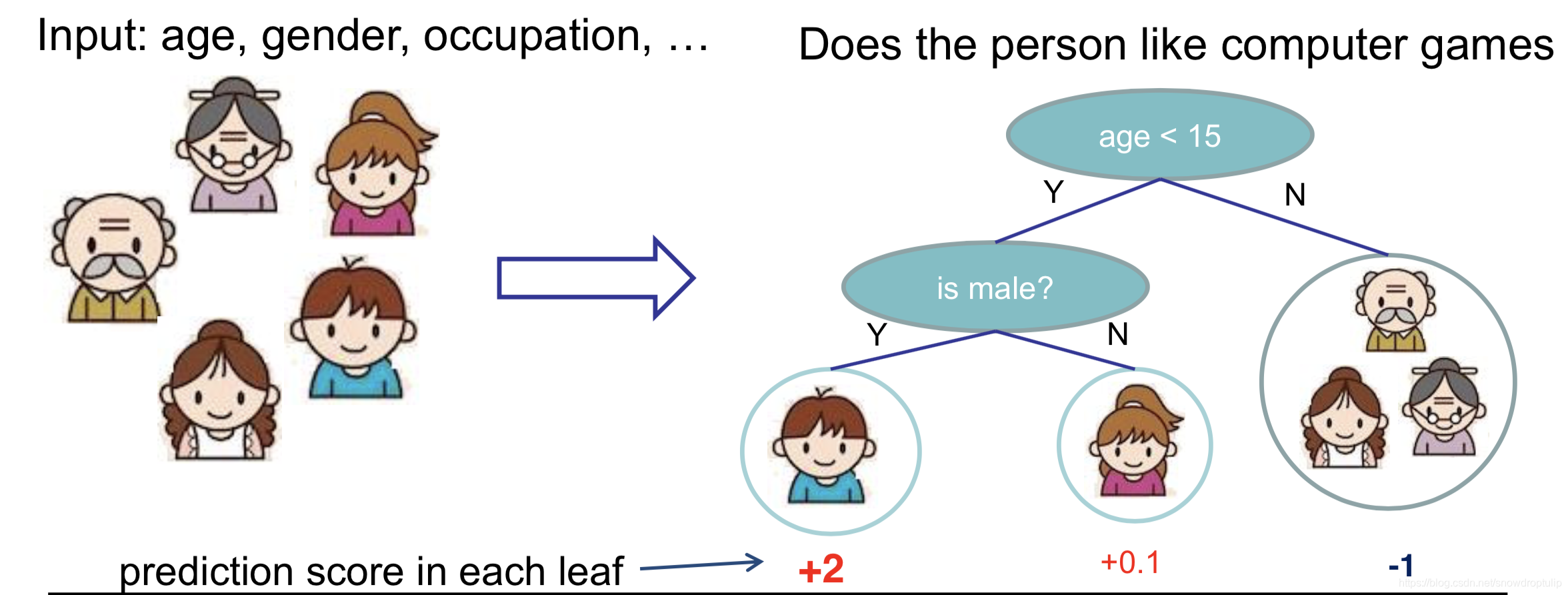
从上图的左图可以看出,共有5个训练样本。
从上图的右图可以看出,每个叶子节点都有预测值,第一个叶子结点的预测值是2,第二个叶子结点的预测值是0.1,第三个叶子结点的预测值是-1。小男孩被分到第一个叶子结点中,所以小男孩的预测值是2,小女儿被分到第二个叶子结点,她的预测值是0.1,剩余的三个人(样本)被分到第三个叶子结点中,他们的值都是-1。
2.2 回归树集成(Regression Tree Ensemble)
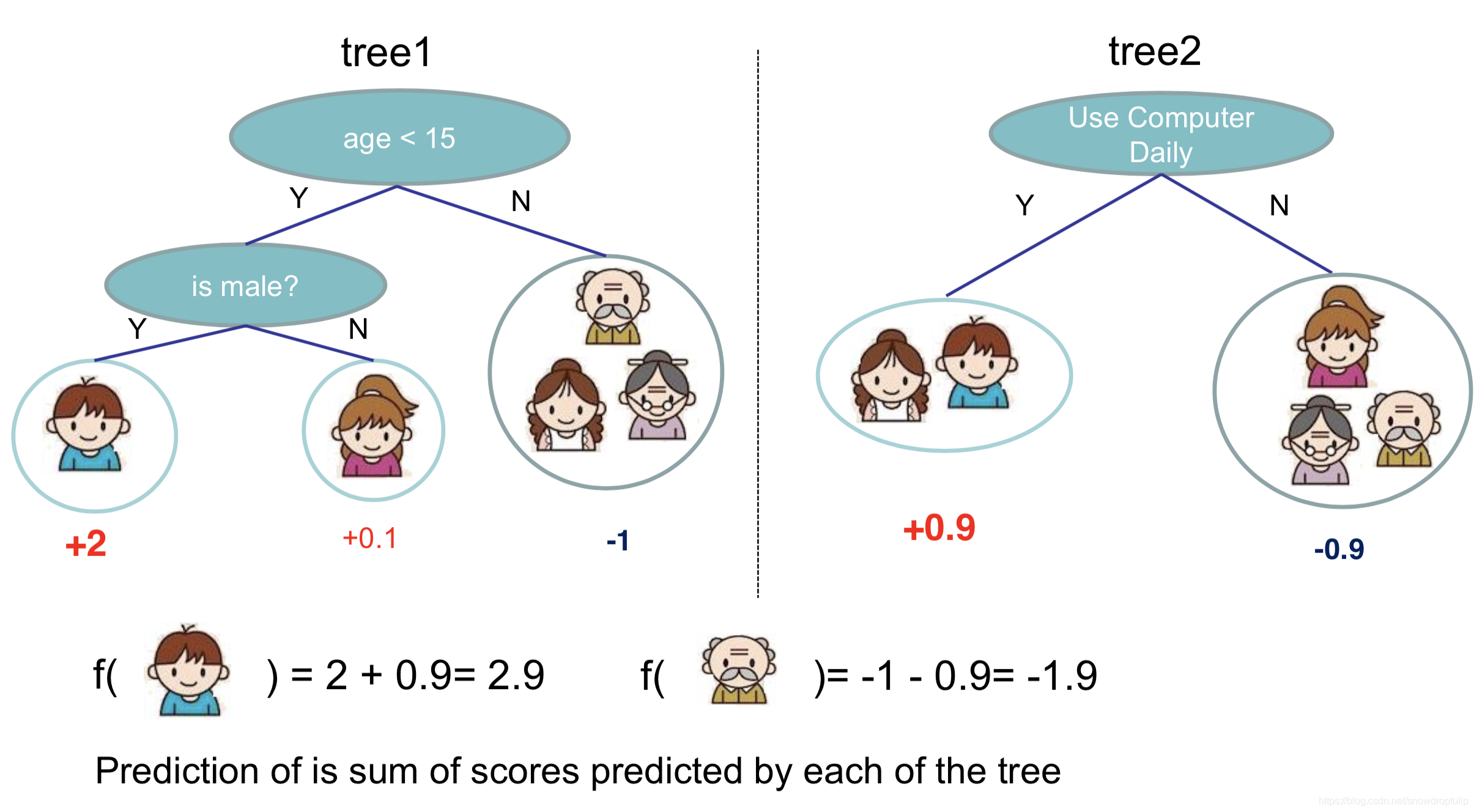
最终的预测值就是样本在每颗树中所在的叶子结点的预测值的和
2.3 树集成方法
- 树集成的方法使用非常广泛,像GBM、随机森林等。
- 多达半数的数据挖掘竞赛通过使用各种各样的树集成方法而获胜
- 不受输入量纲的影响,因此不需要对特性进行细致的标准化
- 学习特征之间的高阶交互(翻译的不准,不知大家有好的建议不)
- 可以扩展,用于不同的行业
2.4 Boosted Tree的模型和参数
- 模型:假设我们有K颗树:
- 其中,F为包含所有回归树的函数空间。回归树是一个将属性映射到分数的函数。
- 参数:包括每棵树的结构和叶子结点中的分数
- 或者简单的使用如下函数当作参数:
- 这里我们不学习
的权重,我们在Boosted Tree中学习函数(树)
- 或者简单的使用如下函数当作参数:
2.5 在单变量上学习Boosted Tree
单变量也就是单个特征,通过了解如何在单变量上学习Boosted Tree,我们可以对Boosted Tree的学习模式有个简单的概念。
举例:假设回归树只有一个输入变量t(时间),我希望预测我在t时刻有多喜欢浪漫音乐。
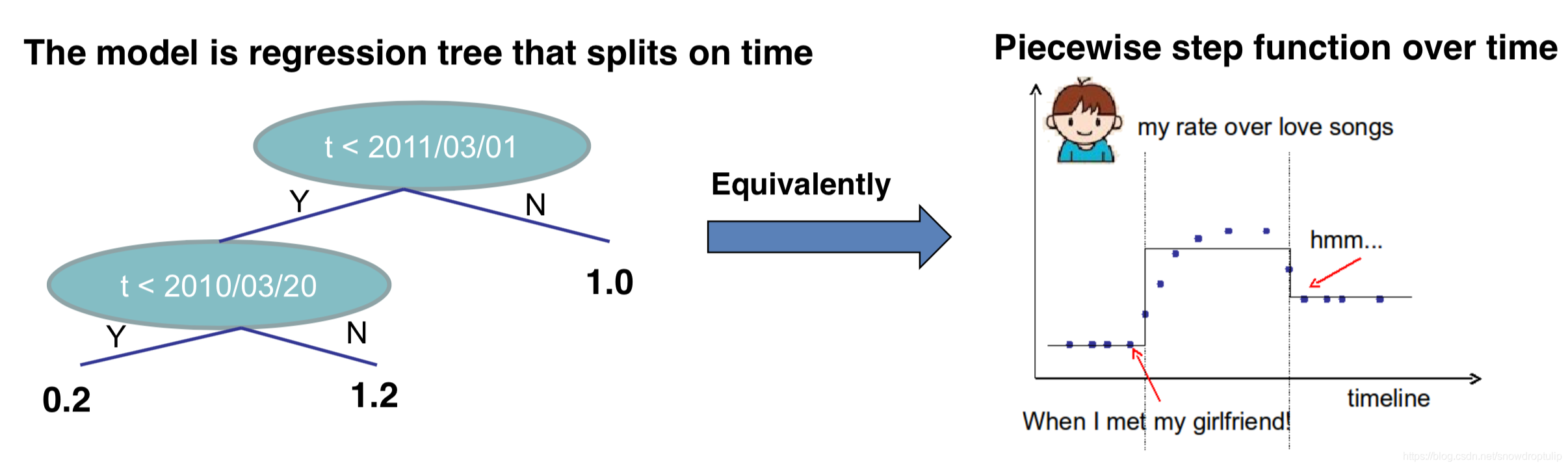
从上右图可以看到,这位小哥在单身的时候,对浪漫音乐的喜欢程度很低;但是当他遇到了女朋友,随着体内荷尔蒙的分布增加,他对浪漫音乐的喜欢程度增加了;但是有一天女朋友甩了他,他对浪漫音乐的喜欢程度又变低了。
当然,我们也可以发现,上左图的回归树很容易能表达上右图。
为了构建左上图的树,我们需要学习两个东西:1、分裂的点;2、每个分段上的高
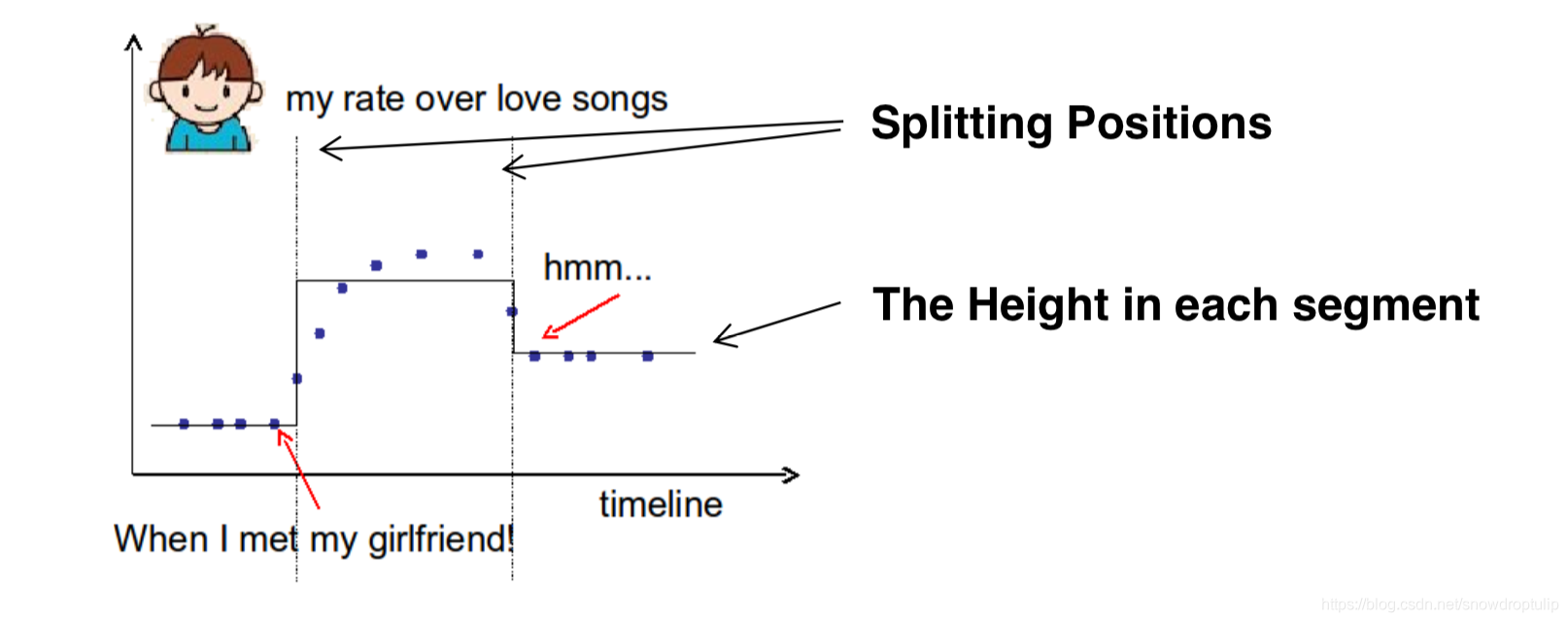
- 单变量回归树的目标(阶跃函数)
- 训练损失:函数如何拟合点?
- 正则化:如何定义函数的复杂度?
- 分裂点的个数和L2 norm如何影响每个分段上的高?
下面我们分析下图:
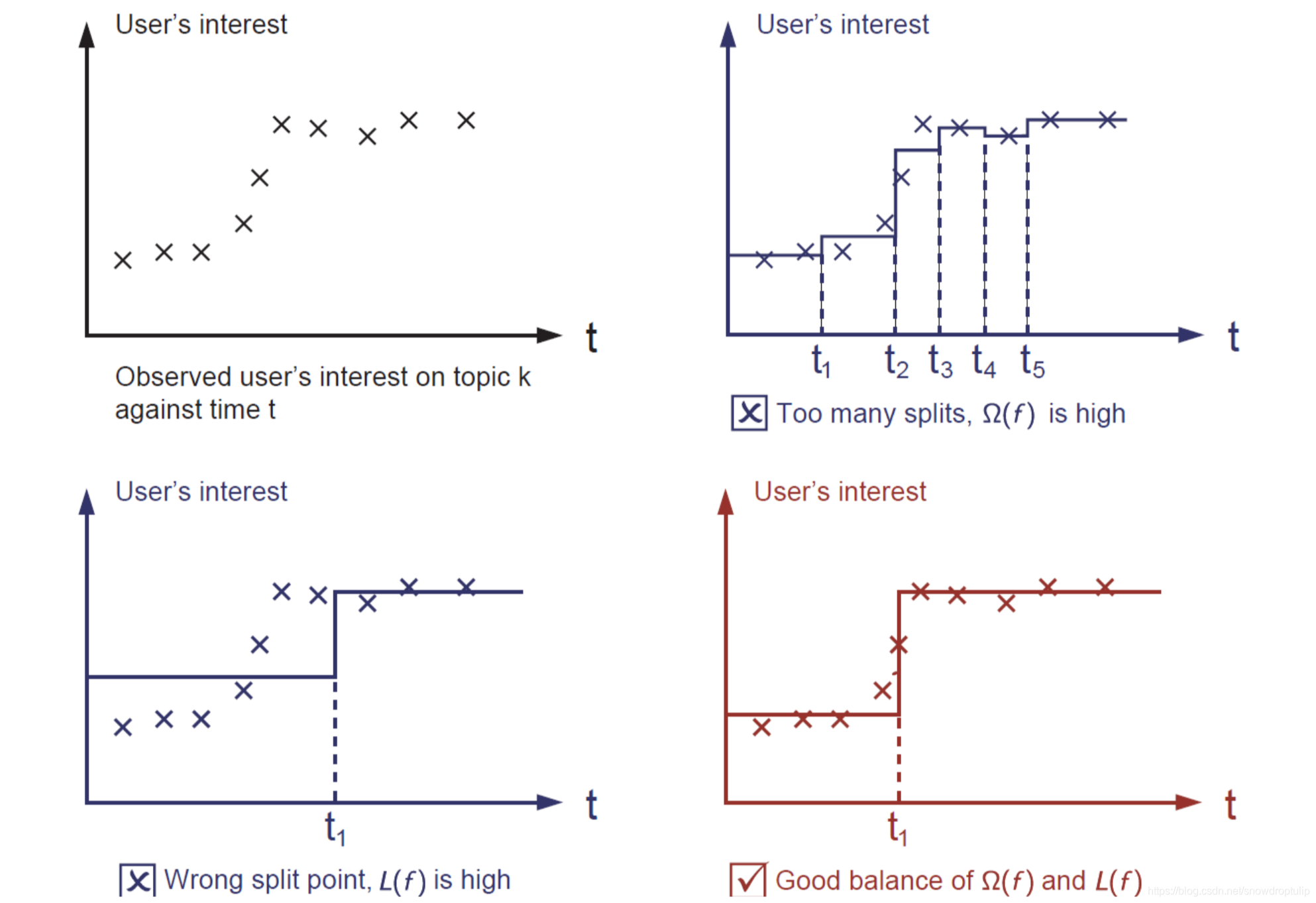
左上角的图是小哥在每个时间上对浪漫音乐的喜欢程度的散点图;
右上角的图可以看到有太多的分割,模型的复杂度很高,所以模型的很高
左下角的图可以看到模型的拟合程度很差,所以很高
右下角的图是最好的,无论是拟合程度和复杂程度都非常合适
2.6 一般情形的Boosted Tree
首先回顾上面我们对Boosted Tree的定义:
- 模型:假设我们有K颗树:
- 目标函数:
- 其中
是成本函数;
是正则化项,代表树的复杂程度,树越复杂正则化项的值越高(正则化项如何定义我们会在后面详细说)。
- 其中
当我们讨论树的时候,通常是启发式的:
- 通过信息增益来做分裂;
- 修剪树木;
- 最大深度;
- 平滑叶值;
大多数启发式算法都能很好地映射到目标函数,采用形式(目标)视图让我们知道我们正在学习什么:
- 信息增益->训练损失
- 修剪->对节点的正则化
- 最大深度-函数空间上的约束
- 平滑叶片值-> L2正则化对叶片的权重
回归树集成定义了如何得到预测值,它不仅仅可以做回归,同样还可以做分类和排序;
3 Gradient Boosting(如何学习)
在这一节中我们将正式学习Gradient Boosting。
3.1 解决方案
目标函数:
在做GBDT的时候,我们没有办法使用SGD,因为它们是树,而非数值向量。也就是说从原来我们熟悉的参数空间变成了函数空间。参数空间:学习模型中的权重;函数空间:学习函数f,包括函数的结构和其中的权重
解决方案:初始化一个预测值,每次迭代添加一个新函数():
其中:是第
次迭代的预测值,
是
次迭代的预测值,
是第t颗树,也就是我们第
次迭代需要得到的树。
3.2 目标函数变换
第一步:根据上面的公式,目标函数可以做如下变形:
这里我们考虑平方损失,此时目标函数又可以变形为:
第二步:所以我们的目的就是找到使得目标函数最低,然而经过上面初次变形的目标函数仍然很复杂,目标函数会产生二次项,在这里我们引入泰勒展开公式:
泰勒展开式:
令,
,目标函数利用泰勒展开式就可以变成:
其中,,
第三部:把常数项提出来,目标函数可以简化为:
思考:为什么要做这么多变化而不直接生成树?
- 理论好处:知道我们在学习什么,收敛
- 工程好处:回顾监督学习的要素
都来自损失函数的定义
- 函数的学习只通过
- 当被要求为平方损失和逻辑损失实现Bootsted Tree时,可以考虑如何分离代码模块
3.3 重新定义树
在前面,我们使用代表一颗树,在本小节,我们重新定义一下树:
我们通过叶子结点中的分数向量和将实例映射到叶子结点的索引映射函数来定义树:(有点儿抽象,具体请看下图)
其中代表树中叶子结点的权重,q代表的是树的结构
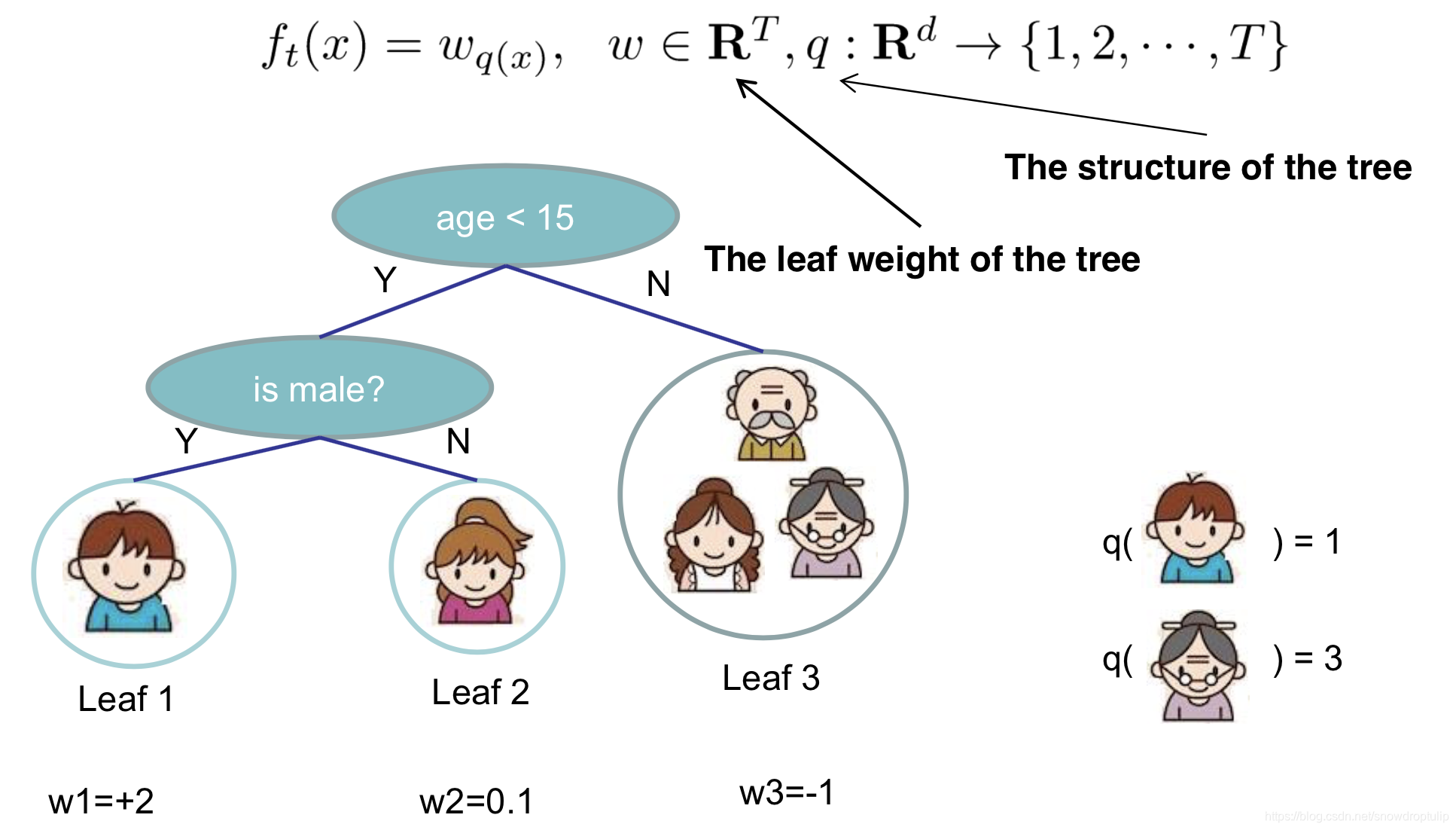
从上图可以看出,共有3个叶子结点,第一个叶子结点的权重为+1,第二个叶子结点的权重为0.1,第三个叶子结点的权重为-1;
其中,小男孩属于第1个叶子结点,老奶奶属于第3个叶子结点。
3.4 定义树的复杂程度
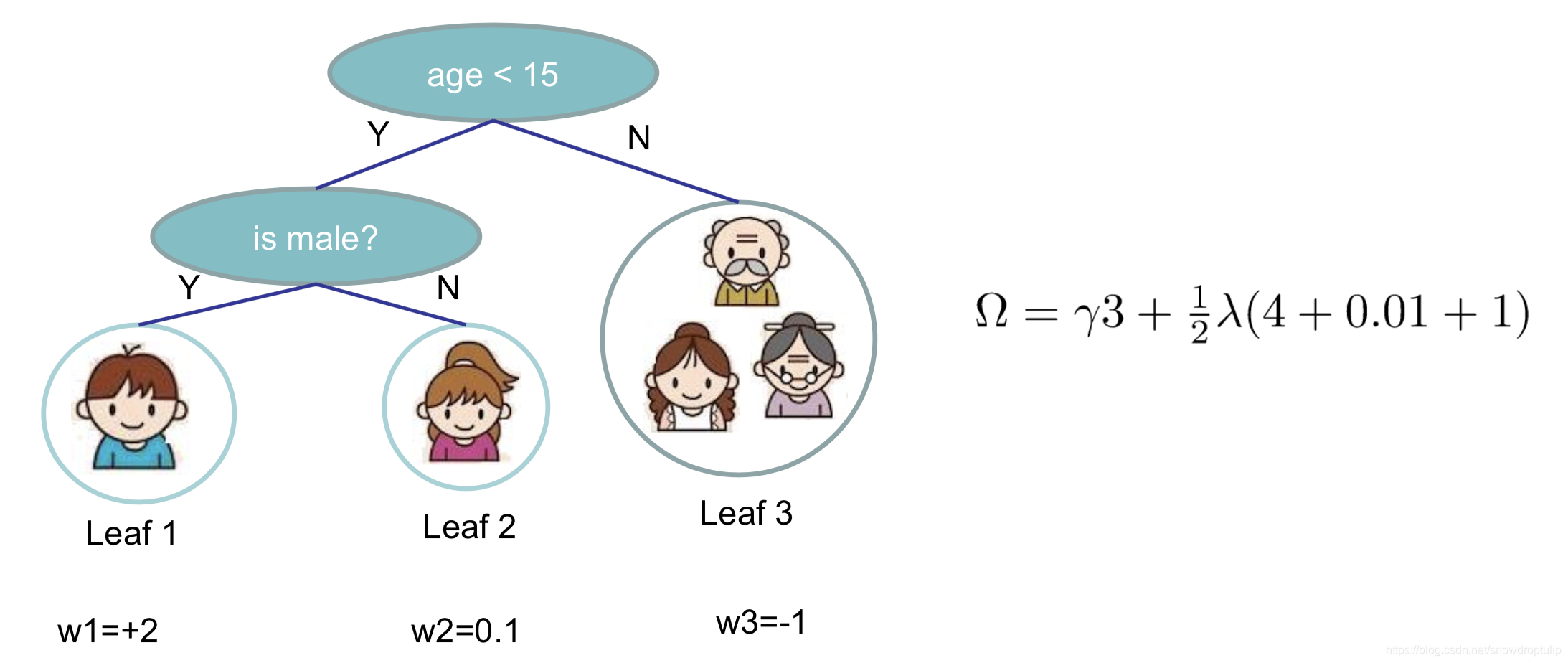
通过下面的式子定义树的复杂程度(定义并不是唯一的):
其中代表了叶子结点的个树,
叶子结点分数的L2 norm
3.5 重新审视目标函数
定义在叶子结点j中的实例的集合为:
根据每棵叶子重新定义目标函数:
上式是T个独立二次函数的和。
3.6 计算叶子结点的值
一些知识需要先了解:
对于一元二次函数:,我们很容易得到这个函数的最小值和最小值对应的x
最小值对应的x相当于求的导数,使导数等于0时的值,即
,所以
当,对应的
的值为:
也就是:
如何求叶子结点最优的值:
接着继续变化目标函数:定义,
:
假设树的结构()是固定的,那么每一个叶子结点的权重的最优值为:
目标函数的最优值为:
下面是一个例子:

3.7 贪婪算法生成树
3.6节中我们假定树的结构是固定的,但是树的结构其实是有无限种可能的,本小节我们使用贪婪算法生成树:
- 首先生成一个深度为0的树(只有一个根结点,也叫叶子结点)
- 对于每棵树的每个叶子结点,尝试去做分裂(生成两个新的叶子结点,原来的叶子结点不再是叶子结点)。在增加了分裂后的目标函数前后变化为(我们希望增加了树之后的目标函数小于之前的目标函数,所以用之前的目标函数减去之后的目标函数):
- 其中
是左面叶子结点的值,
是右面叶子结点的值,
是未分裂前的值,
是引入了多一个的叶子结点增加的复杂度。
接下来要考虑的是如何寻找最佳分裂点。
例如,如果是年龄,当分裂点是
的时候的增益gain是多少?
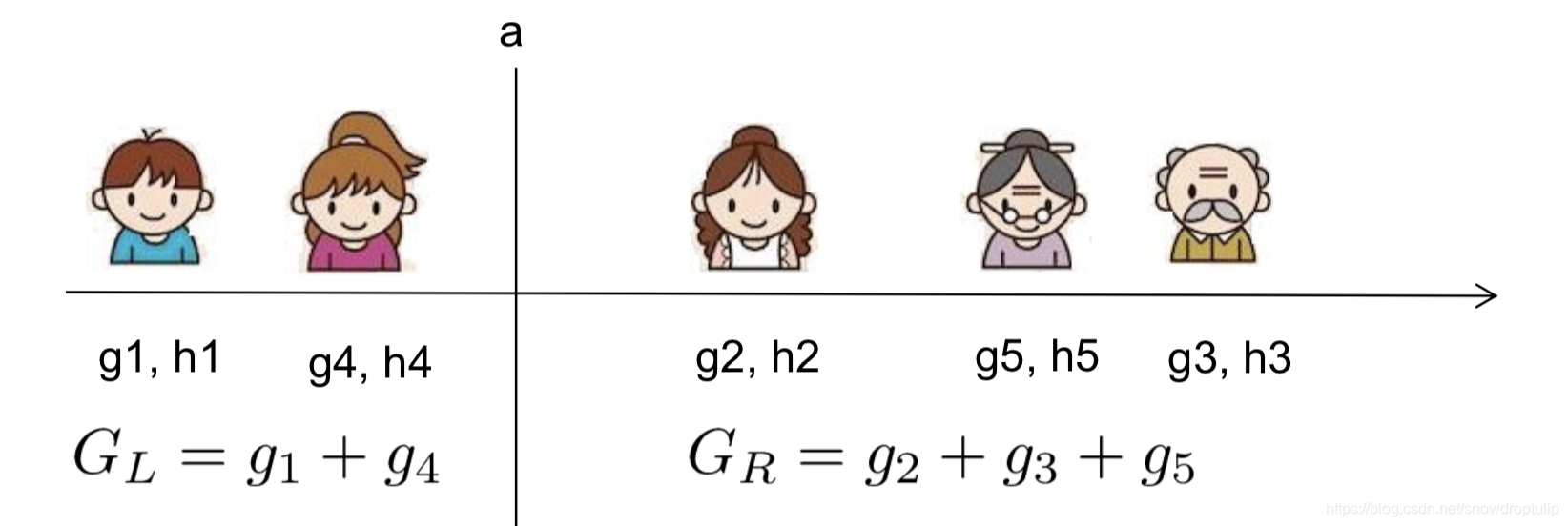
- 我们需要做的仅仅只是计算每一百年的g和h,然后计算
- 对排序后的实例进行从左到右的线性扫描就足以决定特征的最佳分裂点。
所以,分裂一个结点的方法是:
- 对于每个节点,枚举所有特性:
- 对于每个特性,按特性值对实例排序
- 使用线性扫描来决定该特征的最佳分裂点
- 采用所有特征中最好的分裂方案
时间复杂度:
- 对于一个有d个特征,深度为K的树,计算的时间复杂度为:O(d*K*n*log n)。其中每一层需要花费O(n*log n)的时间做排序。
- 可以进一步优化(例如使用近似或缓存排序的特性)
- 可以扩展到非常大的数据集
3.8 如何处理分类型变量
一些树学习算法分别处理分类变量和连续变量,我们可以很容易地使用我们推导出的基于分类变量的评分公式。但事实上,我们没有必要单独处理分类变量:
我们可以使用one-hot方式处理分类变量:
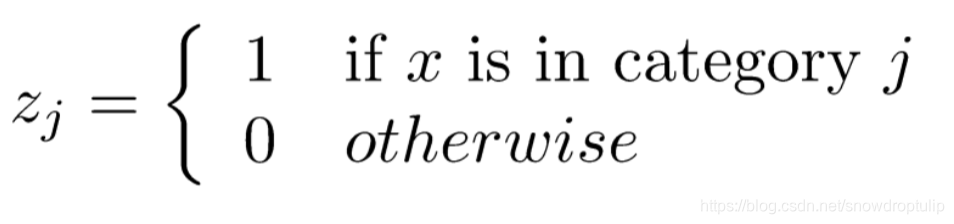
如果有太多的分类的话,矩阵会非常稀疏,算法会优先处理稀疏数据。
3.9 修剪和正则化
回顾之前的增益,当训练损失减少的值小于正则化带来的复杂度时,增益有可能会是负数:
此时就是模型的简单性和可预测性之间的权衡。
- 前停止(Pre-stopping):当最佳分裂是负数时,停止分裂;但是一个分裂可能会对未来的分裂有益;
- 后剪纸(Post-Pruning):把一颗树生长到最大深度,递归修剪所有分裂为负增益的叶子。
4 总结 Boosted Tree 算法
- 每次迭代新增一颗树
- 每次迭代时,计算:
和
- 贪婪的生成一颗树
:
- 增加
。但是通常我们使用
来替代,
被称作步长,通常设为0.1;这意味着我们不会在每一步都做充分的优化,并为未来的回合保留机会,这有助于防止过度拟合。

















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









