




 本文提出了一种数据集蒸馏方法,通过固定模型参数,将大型数据集的知识蒸馏到小数据集中,使得小数据集训练的模型性能接近原数据集。文章分析了线性模型下数据集蒸馏的必要条件,并在MNIST和CIFAR10上验证了有效性,同时探讨了不同初始化方式和目标对象的蒸馏。实验结果表明,数据集蒸馏可用于快速微调预训练模型并抵抗恶意数据攻击。
本文提出了一种数据集蒸馏方法,通过固定模型参数,将大型数据集的知识蒸馏到小数据集中,使得小数据集训练的模型性能接近原数据集。文章分析了线性模型下数据集蒸馏的必要条件,并在MNIST和CIFAR10上验证了有效性,同时探讨了不同初始化方式和目标对象的蒸馏。实验结果表明,数据集蒸馏可用于快速微调预训练模型并抵抗恶意数据攻击。
数据集蒸馏
作者:Tongzhou Wang、Jun-Yan Zhu、Antonio Torralba、Alexei A. Efros
机构:Facebook、MIT CSAIL、UC Berkeley
目录
背景
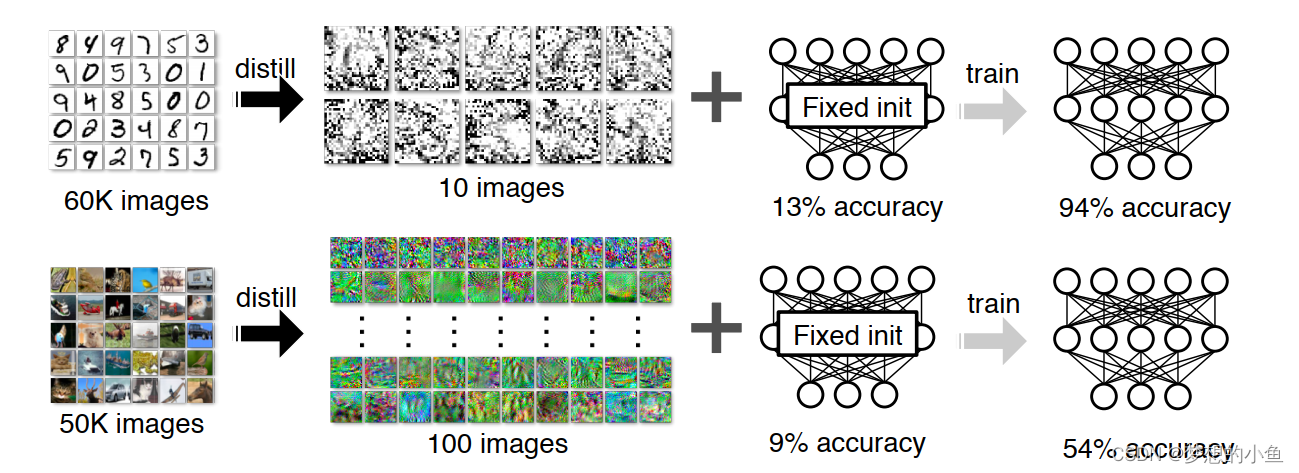
训练最先进的神经网络模型需要的数据集规模越来越庞大,这对于内存以及训练资源的需求越来越高,所以,将庞大的数据集高效地进行压缩是一个十分重要的研究方向。
传统的数据集压缩方法是将原数据集去掉不重要的部分,提炼为子集,这一方法的实际效果欠佳。
作者从知识蒸馏中得到启发,传统的知识蒸馏目的是从复杂模型中蒸馏出知识让简单模型进行学习,从而让简单模型的性能能够接近复杂模型,类比提出了数据集蒸馏。数据集蒸馏定义为:固定训练的模型,从大型训练数据集中蒸馏知识让小型训练集学习,从而让小型数据集训练的模型性能能够接近在大型数据集上训练的模型。
目前存在的问题
为什么数据集蒸馏是有效的呢?/是否能将一个数据集压缩成一小组合成数据样本?
传统观点认为数据集蒸馏是不行的,因为合成训练数据不遵循真实数据的分布,理论上认为合成数据样本无法训练一个好的分类器。
贡献
1.提出了数据集的蒸馏方法
2.推导了在线性网络下,达到与完整数据集训练相同性能所需的蒸馏数据大小的下界;
3.在MNIST、CIFAR10上验证了合成数据训练分类器的有效性;
4.通过蒸馏数据集完成预训练模型的快速微调工作;
5.完成有害数据攻击应用,通过蒸馏图像快速攻击训练好的分类器对某一个类的识别准确率。
方法介绍
3.1 数据集的蒸馏方法:单步迭代蒸馏
真实数据集 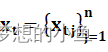 ,期望能得到一个合成数据集
,期望能得到一个合成数据集 ![]() ,
,![]()
随机初始化模型参数![]()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6470
6470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











