








 超级会员免费看
超级会员免费看

 本文全面回顾了数据集蒸馏和学生-教师学习方法,讨论了知识转移、模型压缩和在视觉任务中的应用,包括持续学习、神经架构搜索和隐私保护等领域。
本文全面回顾了数据集蒸馏和学生-教师学习方法,讨论了知识转移、模型压缩和在视觉任务中的应用,包括持续学习、神经架构搜索和隐私保护等领域。
本文是蒸馏学习综述系列的第三篇文章,《A Comprehensive Survey of Dataset Distillation》的一个翻译。
数据集蒸馏综述
摘要
近年来,深度神经模型在几乎每个领域都取得了成功,甚至解决了最复杂的问题陈述。然而,这些模型规模巨大,有数百万(甚至数十亿)个参数,需要大量计算能力,而且无法部署在边缘设备上。此外,性能提升高度依赖于冗余标记数据。为了实现更快的速度并处理由于缺乏标记数据而引起的问题,已经提出了知识蒸馏(KD)来将从一个模型学习到的信息迁移到另一个模型。KD通常以所谓的“学生-教师”(S-T)学习框架为特征,并在模型压缩和知识迁移中得到了广泛应用。本文是关于近年来积极研究的KD和S-T学习。首先,我们旨在解释KD是什么以及它是如何/为什么工作的。然后,我们对KD方法的最新进展以及通常用于视觉任务的S-T框架进行了全面的综述。总的来说,我们综述了推动这一研究领域的一些基本问题,并全面总结了研究进展和技术细节。此外,我们还系统地分析了KD在视觉应用中的研究现状。最后,我们讨论了现有方法的潜力和挑战,并展望了KD和S-T学习的未来方向。
1. 引言
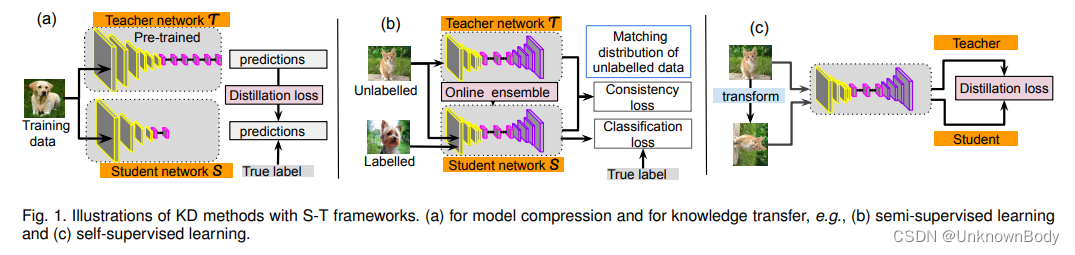
深度神经网络(DNN)的成功通常取决于DNN架构的精心设计。在大规模机器学习中,特别是对于图像和语音识别等任务,大多数基于DNN的模型都被过度参数化,以提取最显著的特征并确保泛化。这种繁琐的模型通常非常深入和广泛,需要大量的计算来进行训练,并且很难实时操作。因此,为了实现更快的速度,许多研究人员一直试图利用经过训练的繁琐模型来获得轻量级DNN模型,该模型可以部署在边缘设备中。也就是说,当繁琐

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











