




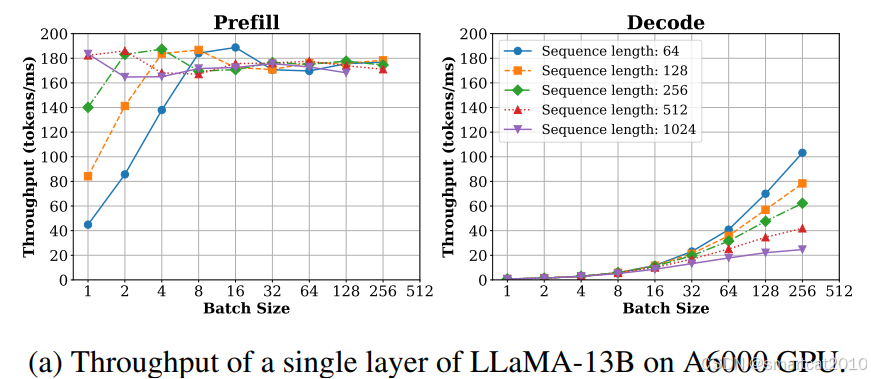
decode网络结构:
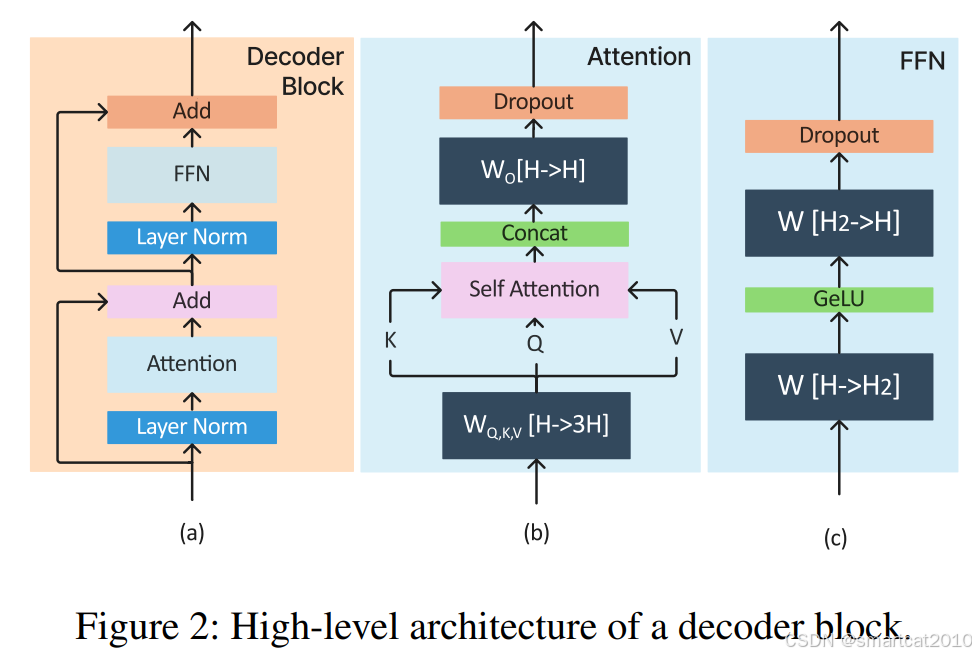
各部分,在各个Batch Size下,耗时:
上图可以看到:
1. Prefill阶段,batch size为1时,GPU算力已满(saturate),所以提高batch size不能减少单个request的耗时。
2. Decode阶段,因为是memory-bound,提高batch size几乎可以让单个request的耗时线性减少。
3. 耗时大的部分:2个FFN,preproj,postproj。因为这几个是大矩阵计算。attention计算和other(dropout、nomalization、relu等),耗时小。
4. 它的实验里,batch-size为1时,1个decode的平均耗时,是1个prefill的平均耗时,的200倍。(我的实验里是50~100倍)。
5. decode阶段的attention,没有随着batch size增大而减少。(似乎没有打成batch,是一个一个独立计算的)。
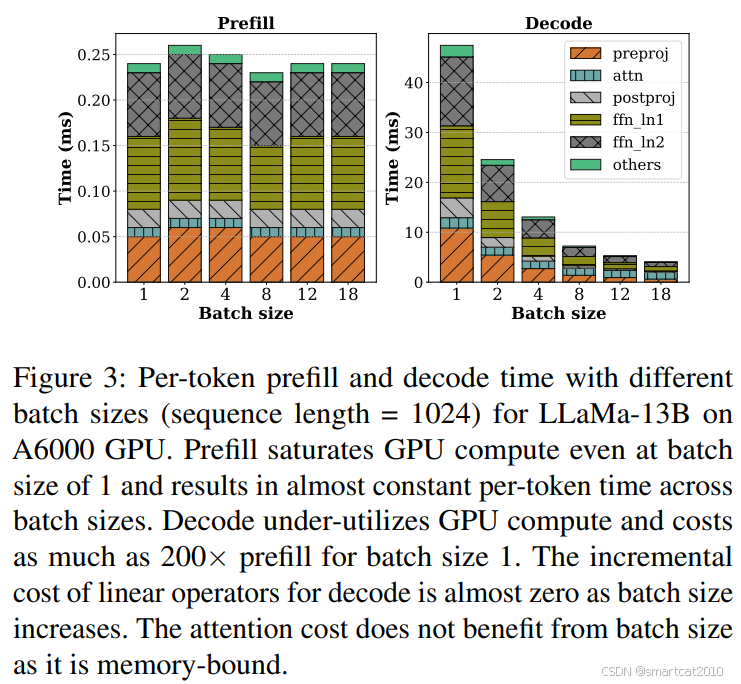
吞吐量和batch-size、sequence-length的关系:
1. prefill阶段,B*L>=512 tokens时,GPU算力饱和,吞吐量达到最高,再上不去了。
2. decode阶段,batch-size小的时候,吞吐量随batch-size线性增长。增长到256~512时,GPU算力接近饱和,也涨不上去了。
3. deocde阶段,seq越长,吞吐量越小,因为attention部分耗时和seq长度有关。
计算密度
arithmetic intensity,the amount of compute per memory read/write。
计算次数,除以,<读+写>显存的次数。用来观察是compute bound还是memory bound。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









