




将prefiling阶段的句子,和decoding阶段的句子,混合到一个batch里,为什么能增大throughput?
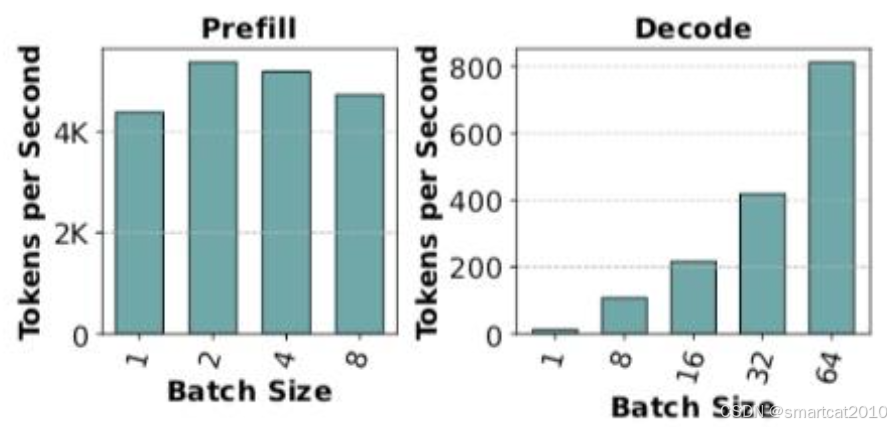
左图,Prefill阶段,因为是Compute-bound的,计算单元已经打满了,再增大batch也不会增大吞吐量了。
右图,Decode阶段,因为是Memory-bound的(实际是memory-latency-bound),增大batch几乎没有增大延迟,而计算单元远远没打满,因此可以随batch增大而线性增长。
将处于这2个阶段的句子,混合到同一个batch里,好处:
prefill搭上decode的便车,能用上decode阶段被浪费的算力。
decode搭上prefill的便车,合并数据的读取次数,做到1次读取,大家共享。
Chunked-prefills
将prefill阶段的句子,拆分成多个block,每个block包含一部分tokens的计算。
目的:
1. 单卡执行时,降低decode阶段的token的延迟。(如果和整个长句子的prefill阶段样本捆绑,则decode阶段的句子本token延迟显著增大;如果前者切分的短些,则后者延迟可显著减少)。
2. pipeline并行时,可减少气泡。
pp并行的气泡问题:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 983
983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









