



混合精度训练:
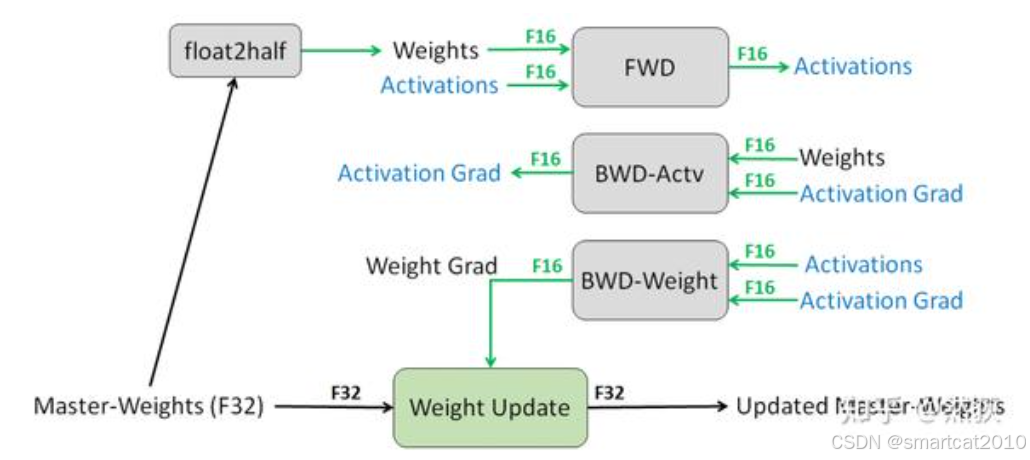
为什么不全都用FP16?
FP16精度的范围比FP32窄了很多,这就会产生数据溢出和舍入误差两个问题(全网最全-混合精度训练原理),这会导致梯度消失无法训练,所以我们不能全都用FP16,还需要FP32来进行精度保证。BF16不会产生数据溢出了,业界的实际使用也反馈出比起精度,大模型更在意范围。
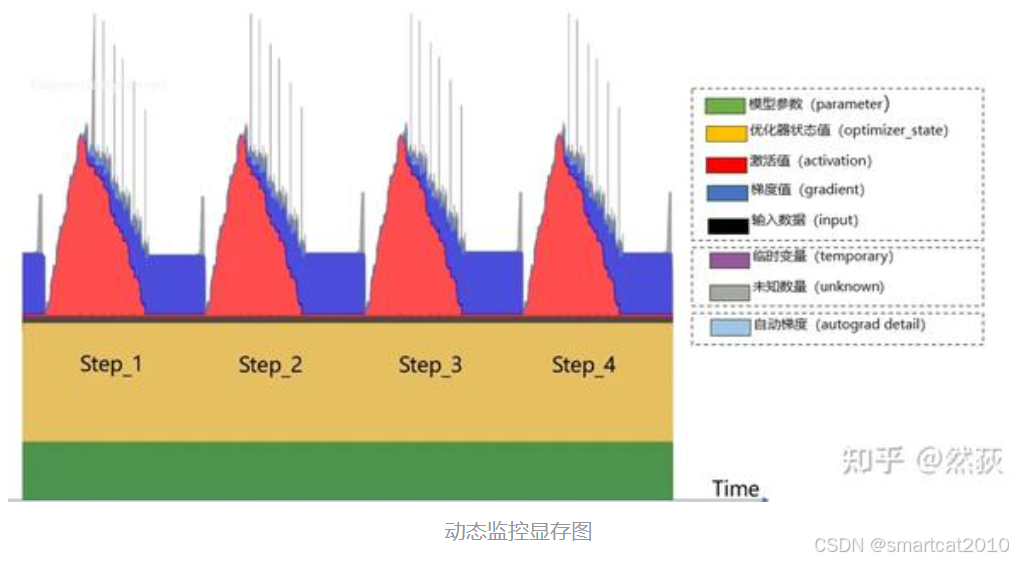
例子(暂时不看激活值占用 )
对于llama3.1 8B模型,FP32和BF16混合精度训练,用的是AdamW优化器,请问模型训练时占用显存大概为多少?
解:
模型参数:16(BF16) + 32(PF32)= 48G
梯度参数:16(BF16)= 16G
优化器参数:32(PF32) + 32(PF32)= 64G
不考虑激活值的情况下,总显存大约占用 (48 + 16 + 64) = 128G
KVCache动图:
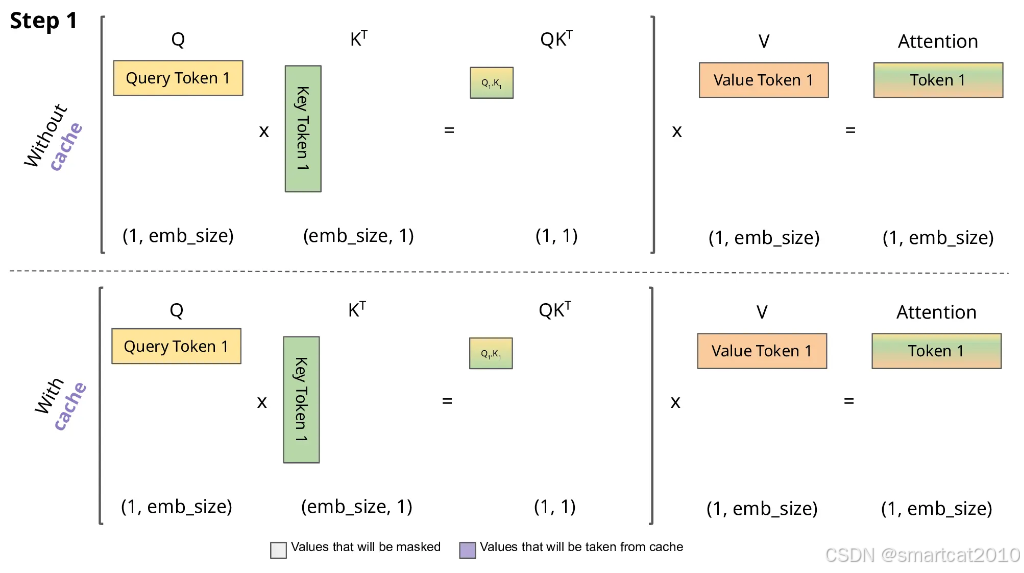
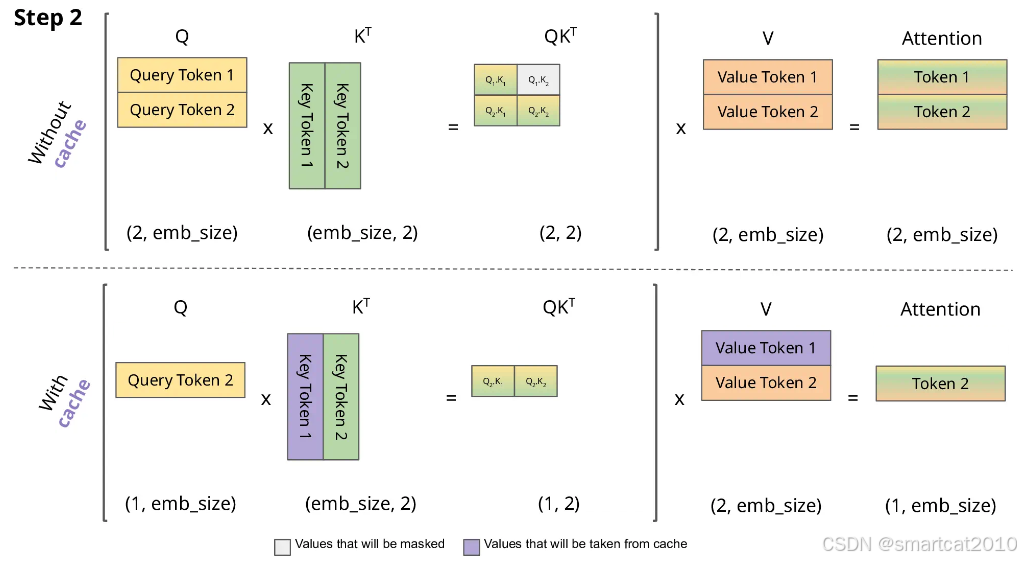
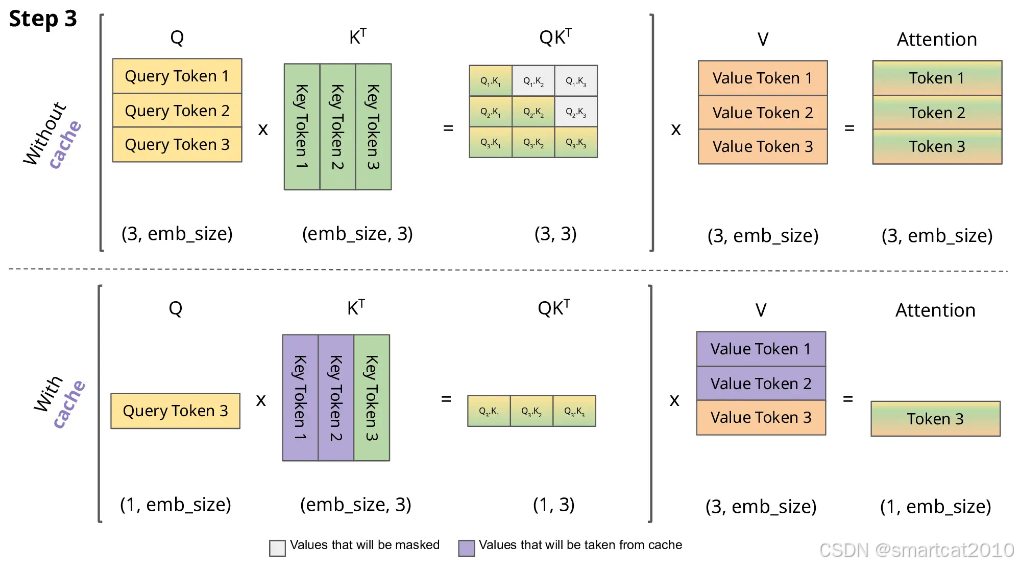
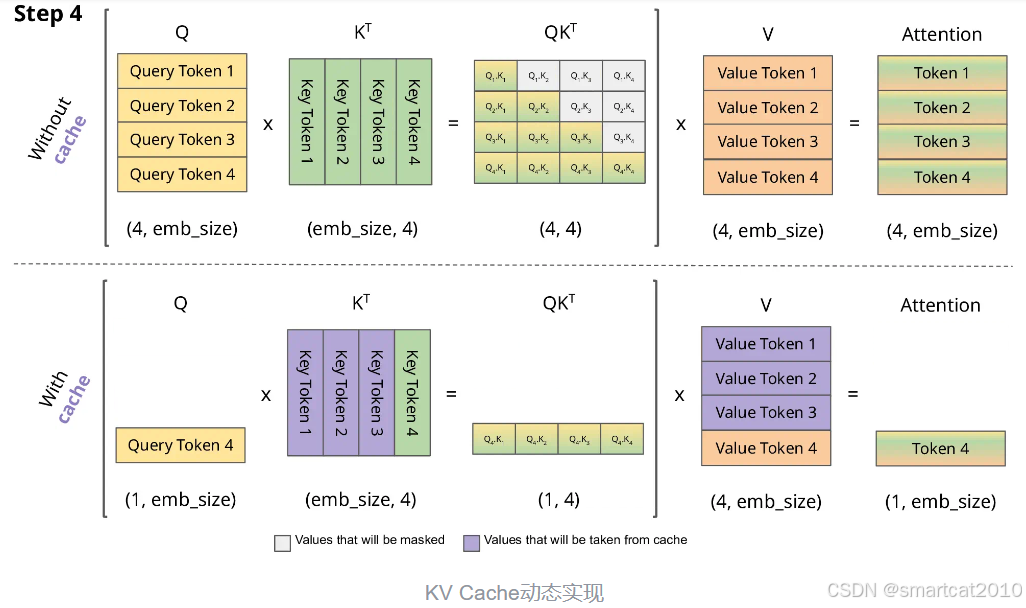
KV cache的目的是减少延迟,也就是为了推理的速度牺牲显存。
我们推理就是在不断重复地做”生成下一个token“的任务,生成当前token 仅仅与当前的QKV和之前所有KV有关,那么我们就可以去维护这个KV并不断更新。
KVCache计算公式:
(第1个2是K+V,第2个2是BP16 2个字节)
举例,对于llama7B,hiddensize = 4096,seqlength = 2048 , batchsize = 64,layers = 32:
降低显存最直观的方式:减少batch-size,由64降至1,显存降至约1GB了。
MQA&GQA:
把上式的hiddensize,换成heads_num * head_dim
对于普通MHA,heads_num*head_dim就等于hiddensize
对于GQA, heads_num从64变为8 (每8个heads共享1个KV)
对于MQA, heads_num变为1
LoRA
用了LoRA之后,
模型权重本身的权重, BF16的话,是2W;LoRA矩阵占用显存量,很小,可忽略;
全参模型和Optimize的状态,不需要了,因为梯度更新不更新全参模型;梯度更新只更新LoRA矩阵,很小,可忽略;
梯度,不需要计算原始模型部分的梯度,也基本不占用显存。LoRA矩阵的梯度,很小,可忽略;
LLama Factor给的表格:
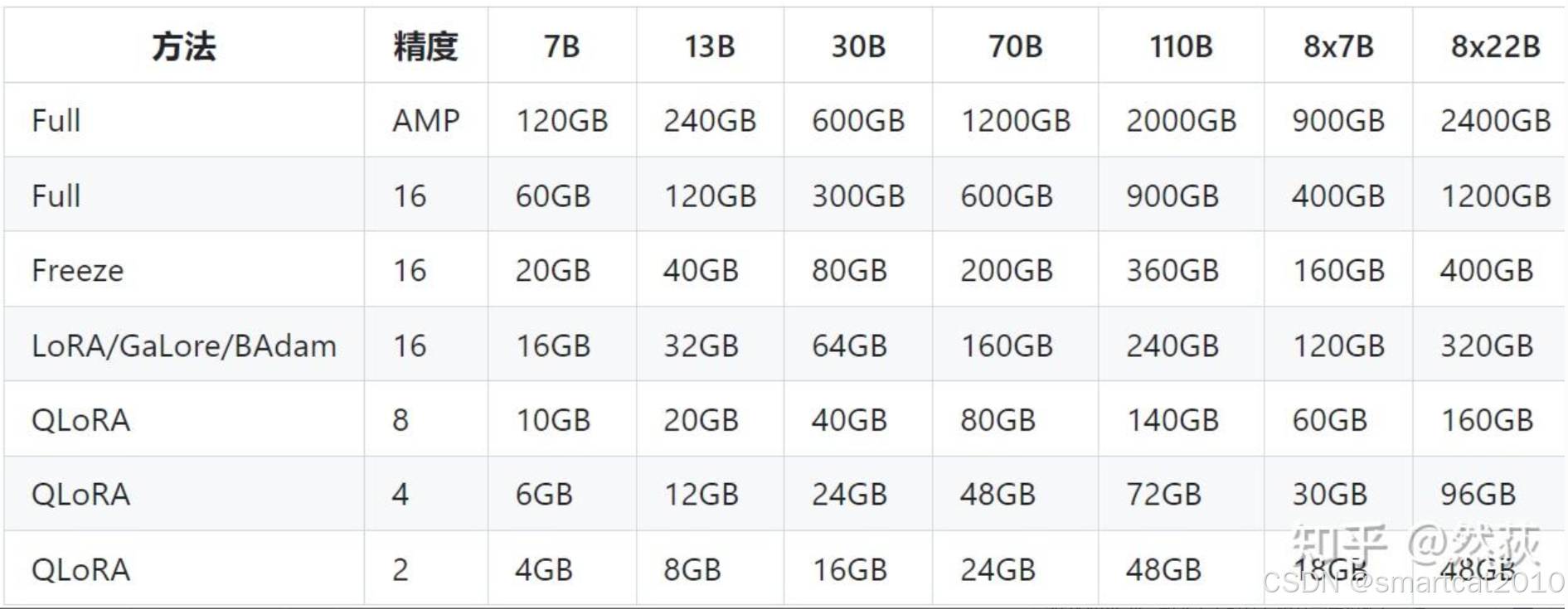
QLora在训练计算时用到的精度仍是16bit,只是加载的模型是4bit,会进行一个反量化到16bit的方法,用完即释放。前面说到的都是模型原始参数本身,不包括lora部分的参数,Lora部分的参数不需要量化,一直都是16bit。
比Lora多了一个反量化的操作,训练时间会更长,一般Qlora训练会比Lora多用30%左右的时间。


















 2214
2214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









