



原文:
将更大的网络安装到内存中。|by 雅罗斯拉夫·布拉托夫 |张量流 |中等 (medium.com)
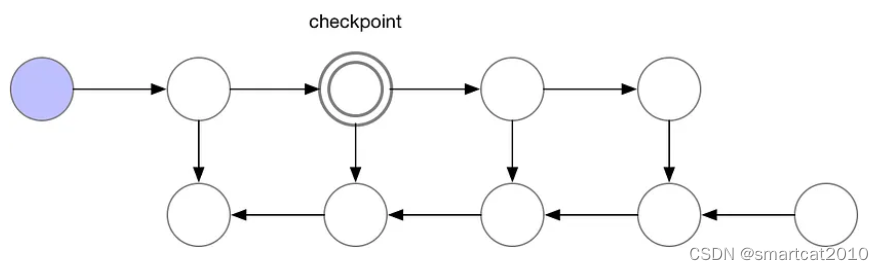
前向传播时,隔几层就保留一层activation数据,其余层的activation都释放掉;
反向传播时,从最近的checkpoint去重新跑forward,这次跑的不删除;计算梯度每用完一层,才释放掉该层的activation;
N层网络,使用sqrt(N)个checkpoint,activation内存峰值是2*sqrt(N),计算额外增加N层的forward计算;
一般大模型中,该功能增加20%计算时间,减少20%显存占用;
更激进的做法:如果有SSD等高速存储,可以将所有activation层落盘,backward时从SSD中load进显存,每次只load一层用完即删;
最激进的做法:model weights、optimizer states、lr等,也落盘;随用随读;

















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









