解释一下class Agent:
def __init__(self):
self.n_games = 0
self.epsilon = 0 # randomness
self.gamma = 0 # discount rate
self.memory = deque(maxlen=MAX_MEMORY) # popleft()
self.model = Linear_QNet(11, 256, 3)
self.trainer = QTrainer(self.model, lr=LR, gamma=self.gamma)
def get_state(self, snakegame):
head = snakegame.snake[0]
point_l = Point(head.x - 20, head.y)
point_r = Point(head.x + 20, head.y)
point_u = Point(head.x, head.y - 20)
point_d = Point(head.x, head.y + 20)
dir_l = snakegame.direction == Direction.LEFT
dir_r = snakegame.direction == Direction.RIGHT
dir_u = snakegame.direction == Direction.UP
dir_d = snakegame.direction == Direction.DOWN
state = [
# Danger straight
(dir_r and snakegame.is_collision(point_r)) or
(dir_l and snakegame.is_collision(point_l)) or
(dir_u and snakegame.is_collision(point_u)) or
(dir_d and snakegame.is_collision(point_d)),
# Danger right
(dir_u and snakegame.is_collision(point_u)) or
(dir_d and snakegame.is_collision(point_d)) or
(dir_l and snakegame.is_collision(point_l)) or
(dir_r and snakegame.is_collision(point_r)),
# Danger left
(dir_d and snakegame.is_collision(point_d)) or
(dir_u and snakegame.is_collision(point_u)) or
(dir_r and snakegame.is_collision(point_r)) or
(dir_l and snakegame.is_collision(point_l)),
# Move direction
dir_l,
dir_r,
dir_u,
dir_d,
#Food Location
snakegame.food.x < snakegame.head.x, # food left
snakegame.food.x > snakegame.head.x, # food right
snakegame.food.y < snakegame.head.y, # food up
snakegame.food.y > snakegame.head.y, # food down
]
return np.array(state, dtype=int)
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done)) #popleft if MAX_MEMORY is reached
def train_long_memory(self):
if len(self.memory) > BATCH_SIZE:
mini_sample = random.sample(self.memory, BATCH_SIZE) #List of tuples
else:
mini_sample = self.memory
states, actions, rewards, next_states, dones = zip(*mini_sample)
self.trainer.train_step(states, actions, rewards, next_states, dones)
# for state, action, reward, next_state, done in mini_sample:
# self.trainer.train_step(state, action, reward, next_state, done)
def train_short_memory(self, state, action, reward, next_state, done):
self.trainer.train_step(state, action, reward, next_state, done)
def get_action(self, state):
# random moves: tradeoff eploration / exploitation
self.epsilon = 80 - self.n_games
final_move = [0, 0, 0]
if random.randint(0, 200) < self.epsilon:
move = random.randint(0, 2)
final_move[move] = 1
else:
state0 = torch.tensor(state, dtype=torch.float)
prediction = self.model(state0)
move = torch.argmax(prediction).item()
final_move[move] = 1
return final_move





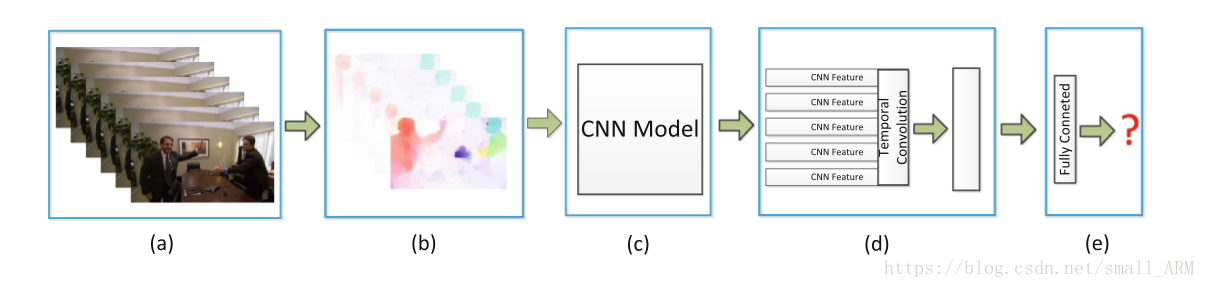
 项目从Action Recognition转向Action Prediction,因为后者能在行为未完全发生时进行识别,适合实时在线异常行为检测。研究了Human Interaction Prediction的两种方法,一种利用深度时序特征,另一种结合结构上下文模型和评分融合。这两种方法都结合了空间和时间信息来预测行为。
项目从Action Recognition转向Action Prediction,因为后者能在行为未完全发生时进行识别,适合实时在线异常行为检测。研究了Human Interaction Prediction的两种方法,一种利用深度时序特征,另一种结合结构上下文模型和评分融合。这两种方法都结合了空间和时间信息来预测行为。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 482
482





 到【灌水乐园】发言
到【灌水乐园】发言







