



github代码:https://github.com/diningphil/CGMM
1. Introduction
结构域学习处理不同大小和拓扑结构、数量的数据,来在模型中识别、合成、嵌入结构化关系。传统方法是对结构预处理、以获得手工设计的特征的固定向量的表示,并将其输入标准学习模型,但这样会导致丢失许多携带有用信息的关系。循环、递归模型通过对有向无环结构(序列、树和DAGs)施加拓扑顺序,来学习这种编码,这种拓扑顺序称为因果关系假设,然而,它限制了可以处理的数据类。如果没有expensive扩散机制和对模型状态的转移函数的约束,状态空间的递归定义就不能应用于循环输入。
本文提出了一种新的学习无监督编码循环结构的生成模型,借鉴前人SD处理方法,即自底向上生成隐藏树马尔科夫模型(Bacciu et al., 2012a)和图数据神经网络的构造方法(Micheli, 2009)。实现了生成模型可以处理可变大小的图形。它的概率特性允许模型标记不确定性,以及对图顶点和弧进行推理。无监督生成编码器可以在不依赖于当前问题的数据中捕获丰富的模式,允许在不同的任务之间广泛重复使用编码,并最终利用未标记的示例来提高半监督设置的准确性。
此外,该模型以增量方式进行训练,允许在监督任务中自动构建体系结构。信息扩散是通过深度学习方式中的分层实现的。每个层中的计算是完全局部的,高度可伸缩的,不需要迭代过程或收敛条件。深度对上下文的形成有深远的影响,因为它允许每个顶点收集其周围环境的更广泛的图像,其中有许多层对生成上下文编码起作用。
我们将重点讨论需要将图域转换为离散或连续空间的分类任务。与固定的内核函数相比,这种映射具有自适应的优点,它是由编码函数Tenc和输出函数Tout组成的。前者以图g为输入,输出隐藏表示z(g),后者以编码为输入,输出预测。
我们将考虑通过支持向量机(SVM)实现输出函数,将生成模型的潜在变量所学习到的隐藏表示z(g)作为输入。
我们的模型称为上下文图马尔可夫模型(CGMM),它的表示能力在树分类的流行基准(与递归和核方法直接比较)和生物化学数据集(其中化合物自然表示为无向图)上进行了测试。
2.Background
3.Contextual Graph Markov Model
接下来介绍CGMM的形式化,总结运行模型的主要过程,即参数学习、顶点编码推理、增量分层策略。
3.1The model
CGMM是一种学习对结构信息进行编码的概率图模型,它采用了一种模块化的方法,即利用一组基本模块和分层的池策略来提高识别效率(Fahlman & Lebiere, 1990)。正如预期的那样,CGMM架构借鉴了NN4G,而每一层的实现都受到树的递归概率模型的强烈影响,如自底向上的隐藏树马尔科夫模型(BHTMM) (Bacciu et al., 2012a)。
基本的CGMM组件使用离散的隐藏状态变量对图进行建模,这些状态变量对顶点及其上下文的信息进行编码。因此,每个顶点u与一个多项式随机变量Qu相关联,Qu的值在有限字母表{1。..,C}中,其中C是隐藏状态大小。
然而,与标准的隐马尔可夫模型不同的是,当前的隐状态分配,即在体系结构的第I层,不是通过从同一层的另一组隐状态的转换来确定的,相反,层l处的顶点状态Qu由先前层l'<l处的相邻顶点Ne(u)的frozen状态的赋值确定。这是一个关键的区别,因为这样的赋值可以被认为是在level l是完全可观察的,从而避免了层之间的相互因果依赖,并防止由于循环而陷入不确定的推理循环中。
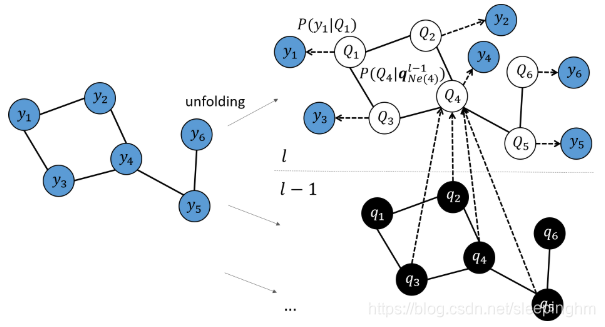
表示为CGMM的第l层在左侧图形结构上展开的图形模型。通常,空节点对应未观察到的变量,而完整节点表示观察到的顶点标签(阴影部分)和上一层的状态分配(黑节点)。粗无向边表示弧,而虚线箭头表示概率因果关系。
图2以图形模型的形式展示了该方法,重点放在目标层l上。当前级别的隐藏状态由大写Qu术语表示,它们是图形模型的空节点,因为它们没有被观察到。顶点标签是可以观察到的节点yu,概率模型在图的结构上展开,就像隐马尔可夫模型在序列的结构上展开一样。
图2还描述了节点u = 4的隐藏状态是如何通过分布![]() 来确定的,该分布由其上一层l−1上的邻居(maybe自己)的状态。这种状态是由另一种概率模型确定的,事先经过训练,然后加以冻结。结果的状态分配用小写的qu项标记,相应的节点用黑色表示它们必须被观察。
来确定的,该分布由其上一层l−1上的邻居(maybe自己)的状态。这种状态是由另一种概率模型确定的,事先经过训练,然后加以冻结。结果的状态分配用小写的qu项标记,相应的节点用黑色表示它们必须被观察。
图2中描述的方案在许多层中迭代,每个层都相对于前一层进行独立训练,但是使用它们以隐藏状态标签的形式提取的知识。图3显示了CGMM在四层结构上的展开。
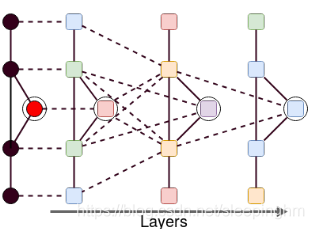
这个过程从第一层开始,隐藏状态的分配没有考虑任何上下文,除了顶点标签。在下一个迭代中,顶点可以访问关于它们的直接邻居的信息。在第三级,他们开始从邻居的邻居那里接收信息。此过程的迭代允许从图的每个节点有效地传播上下文(假设使用了足够数量的层)。该体系结构中的上下文传播是对称的,不需要隐藏状态之间的因果依赖关系。因此,CGMM可以有效地处理任意维度的图,而无需对拓扑属性进行假设,这与需要限制顶点邻域大小或添加填充来处理固定大小表示的模型形成了对比。
3.2
3.3
3.4 CGMM supervision, layering and pooling
前几节描述的过程用于学习一个图结构化信息的概率无监督编码器。为了应用在监督环境中,需要找到一种方法在隐藏状态空间获得知识。根据((Bacciu et al., 2012b)提出的方法,我们可以将图中的编码定义为每个层的状态频率计数向量,然后汇总所有层的贡献,连接在一个固定大小的向量中。图4显示了流程high level图。
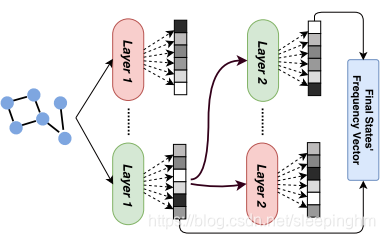
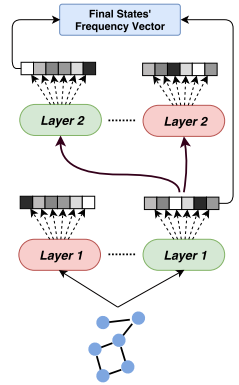
final深度为2的结构的训练过程框架。每层训练一个CGMMs池,根据监督标准选择其中一个(绿色)。第二层利用了推断出最有可能性的隐藏状态。每层计算的状态频率向量可以被串联起来成结构的fingerprint.从无监督CGMM获得的编码可以被用来执行监督任务的标准分类器/ 回归器的输入。本文中,使用SVM来测试CGMM编码在图数据分类器中的作用。如何确定正确的层数->取决于模型选择,允许它做决定多少层来实现最佳泛化性能,CGMM实施过程很简单:在添加锌层后,第一层使用EM方程进行训练,然后使用当前的图数据编码作为输入,对监督模型进行训练和测试。如果新生成的层对性能有积极的影响,那么我们尝试添加另一个层,否则就停止。
最后一个模型实施的特性是池的应用,(Fahlman & Lebiere, 1990),如图4,每层我们不训练单独的概率模型,而是训练不同随机初始化模型,测试各自编码。然后对于每个level,选择池中表现最好的模型最为下一层结构的输入。
4.Experiments
本节提供了CGMM从数据中提取有意义的结构模式的能力的经验评估。因为我们模型是深度扎根于树的隐藏马尔可夫模型,我们首先在树结构化数据分类器上进行测试,将其性能与最先进的树的概率模型和内核(kernels)进行对比。然后,我们将分析扩展到更一般的结构测试CGMM的图分类任务。
4.1 Tree Classifications Tasks
以前的工作试图通过自顶向下或自底向上递归展开结构来处理树分类,即从根到叶或从边界到根节点。INEX2005和INEX2006 (diryer & Gallinari, 2007)是在这种背景下深入研究的基准。它们只涉及两个IEEE结构语料库中XML格式文档的分类。这些数据集的特征是大量的不平衡类和离散节点标签。这种树一般很浅,外缘很大。表1总结了这两个数据集的特征。
(These datasets are characterized by a large number of unbalanced classes and discrete node labels. Such trees are generally shallow and with large out-degree. )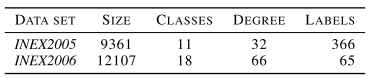
INEX2005和INEX2006数据集的详细信息。节点总数分别为124,359和218,537。训练和测试分割是由基准定义的,分别包含大约50%的数据。模型选择决策是使用20%的训练数据进行的。在这些任务中,我们考虑了一个没有池的CGMM,它的层数从1到4不等,考虑到INEX结构通常很浅,这是一个合理的选择。在本实验中,我们将重点评估分层对信息扩散的影响,而不是确定最佳层数。CGMM隐藏状态大小C是在{20,40}中选择的,而对于上下文传播,我们只考虑当前层的前层的影响。无向树边被转换为两个有向边,一个传入的和一个传出的,以解释上下方向的上下文传播(由于向上-向下的推论,在隐藏树Markov模型中出现)。(as occurs in the Hidden Tree Markov Model thanks to the upwards-downwards inference).用父节点的子树的相对位置标记边缘。
树分类器是通过在CGMM隐藏状态编码上放置SVM来实现的,如3.4节所述。为了计算这些表示之间的相似性,我们考虑了标准RBF kernel和Jaccard kernel,例如(Bacciu et al., 2018)在其unigram或bigram变体中引入的Jaccard kernel。
SVM hyperparameters Csvm和γsvm从{5、50、100}选择,他们的选择对模型性能几乎没有影响。表2报告了CGMM的性能,并将其与最先进的树分类方法的性能进行了比较。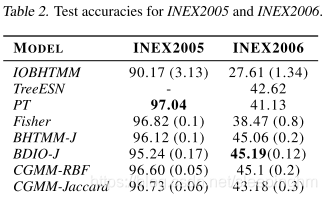
包括相关的输入驱动的树的生成模型(IOBHTMM) the related input-driven generative model for trees (IOBHTMM) ,the syntactic PT kernel,the generative tree kernels IOBHTMM-J, AM-GTM and Fisher和 the bi-directional BDIO-J kernel.对于INEX 2006的数据,我们还提供了TreeESN 的结果,基于储层计算范式的递归神经网络模型。
CGMM在两个数据集上都显示了竞争性的性能,与文献中两个最佳模型的结果相匹配,值得注意的是,CGMM放松了基于BHTMM的模型中的因果关系假设,这些假设是捕获构成树的子结构之间关系的基础。尽管有这样的简化,上下文传播机制允许CGMM捕获、总结足够的结构模式以与专门处理树的方法相竞争,这通常会导致高的计算复杂性,例如对于部分树(PT)(MoSkiTi,2006)。
CGMM通过检查隐藏状态的激活在不同的层和不同的树中的行为,可以观察状态空间的组织结构。图5展示了INEX 2005类的这种隐藏状态fingerspint的一个示例,它是通过对组合树的隐藏状态激活进行平均得到的。可以清楚地理解第一层和第二层之间的上下文扩散的效果,其中一定数量的状态似乎调整为特定于类的结构模式。虽然使用更多的层对精度有积极的影响,但层间fingerptint的差异在l>2时消失。这并不奇怪,考虑到INEX树的浅层特性,对于这种情况,几个层就足以完全传播上下文。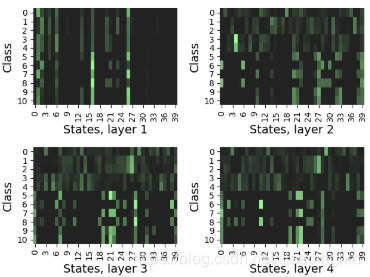
INEX2005每个目标类的平均fingerprints。模型经过C=40的训练。图中较亮的区域表示较“受欢迎”的状态。4.2 Graph Classification Tasks
实验分析的第二部分展示了CGMM如何有效地处理比树更一般的一类结构。为此,我们考虑了一组来自生物领域的标准图分类基准,分别是MUTAG (Debnath et al., 1991)、CPDB (Helma et al., 2004)和AIDS (Smola & Vishwanathan, 2003)。所有的基准测试都是二进制分类任务,其中图顶点用表示原子符号的离散值进行标记。边是无向的,它们的标签编码了原子键的类型:表3总结了数据集的统计数据。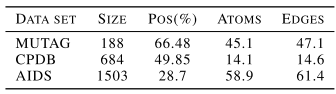
生物数据集中图形的统计:“Pos”列报告正类成员的百分比,而节点和边值是平均值。我们再次测试了具有不同levels(从1到8)的CGMM模型,并且只考虑来自直接前层的状态信息。RBF神经网络和Jaccard神经网络都经过了测试,并给出了两种不同的fingerprints构造策略:一种是使用最后一层生成的编码;另一个使用所有层产生的编码的连接。隐藏状态大小在{20,40}中选择。池大小为10时使用池策略。
根据两种模型选择的方案,按照文献方法对实验进行评估。第一种是在数据集提供的标准十倍分割的基础上使用单一交叉验证(CV)来评估性能,即报告在10-fold验证错误上确定的最佳模型的性能。第二种方法在文献中较少使用,但更可靠,它使用一个嵌套CV,5-fold的CV用于外部10-fold的每层训练fold(a 5-fold CV is applied to each training fold of the outer 10-fold):在这种情况下,根据内部5-fold的CV性能来进行模型选择决策。表4描述了两种评估方案的分类准确性:请注意,我们面对的模型集在各自论文中使用的方法的功能上有所不同。
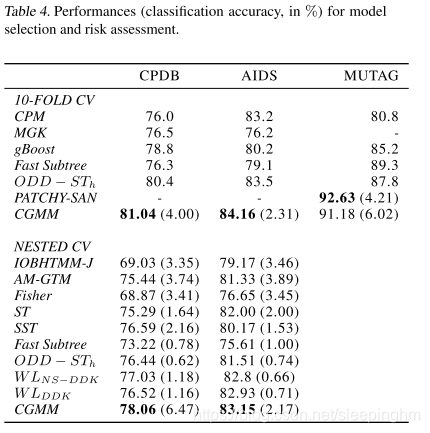
为了提供比较,我们引用了相关方法的结论:FS kernel (Shervashidze & Borgwardt, 2009), WL-DDK kernels (Da San Martino et al., 2014), ODD-ST kernel (Da San Martino et al., 2012), Marginalised Graph Kernel (MGK) (Kashima et al., 2003), Correlated Pattern Mining (CPM) (Bringmann et al., 2006) gBoost (Saigo et al., 2009), Convolutional Neural Network for Graphs (PATCHY-SAN) (Niepert et al., 2016).
我们还提供了将树kernels应用于每个图顶点生成的所有生成树的结果,使用来自(Bacciu et al., 2012b)的生成树kernels以及语法树kernels,如ST (Smola & Vishwanathan, 2003)和SST (Collins & Duffy, 2002)的生成树kernels。
MUTAG数据集的结果只提供了单一的10-foldCV,因为在文献中没有模型使用嵌套CV评估(嵌套CV评估时,CGMM的准确率为85.3%)。
实验结果强调了CGMM使用评估方案在CPDB和AIDS上获得了最高的准确性,相比于许多不同性质的最先进的图形内核(语法、卷积、生成)。CGMM在CPDB数据集上的标准偏差相对较高,因为它看起来像是一次不好的folds分离split (10次fold中只有2次的精度大大高于或低于平均值,因此具有较高的方差)。MUTAG的结果也很好,基本上与patch - san神经模型的最新技术相匹配。通过观察在不同层数的CGMM fingerprint上训练的线性SVM的精度,可以评估叠加stack对CGMM学习的表示质量的影响。图6描述了3个图形分类基准的此信息,考虑一个没有池的CGMM模型,以折扣其对模型性能的影响。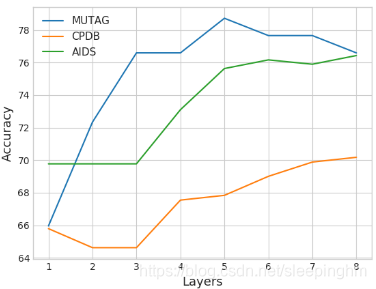
CGMM测试精度与层数的函数关系。在这个实验中,我们使用了一个不带池的CGMM和一个vanilla支持向量机分类器来训练隐藏状态fingerprint到当前层l的连接。我们可以清楚地注意到,深度depth允许信息结构上下文的传播,这对所有数据集的准确性都有有利的影响,并最终实现性能平衡。在MUTAG上,添加新层会在某个点上导致性能的轻微下降,这是因为贪婪的层和无监督的方法。如第3.4节所述,使用提前停止可以很容易地进行对比。(This can be easily contrasted using early stopping as in Section 3.4.)
5.Conclusions
我们提出了一个新的框架,通过结合生成和区别的方法,解决了在结构化领域的学习。它可以处理任何大小和形状的图,利用丰富的概念集,如全平稳性、分层的增量深度和池策略。重要的是,CGMM并没有在学习之前将图形压缩成更简单的表示形式。分层的状态结构对松弛因果依赖起作用,允许对称的上下文在表示顶点的状态之间传播,并优雅地处理循环。实验分析表明,该模型与目前最先进的树递归模型和图核递归模型都具有较强的竞争力。作者希望,该框架的开发,可以扩展到许多方向,可以促进生成和鉴别方法的广泛使用,以自适应处理结构化数据。



















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











