







当我们完成了一个RAG系统的开发工作以后,我们还需要对RAG系统的性能进行评估,如何评估呢?
可以用 <RAGAs>
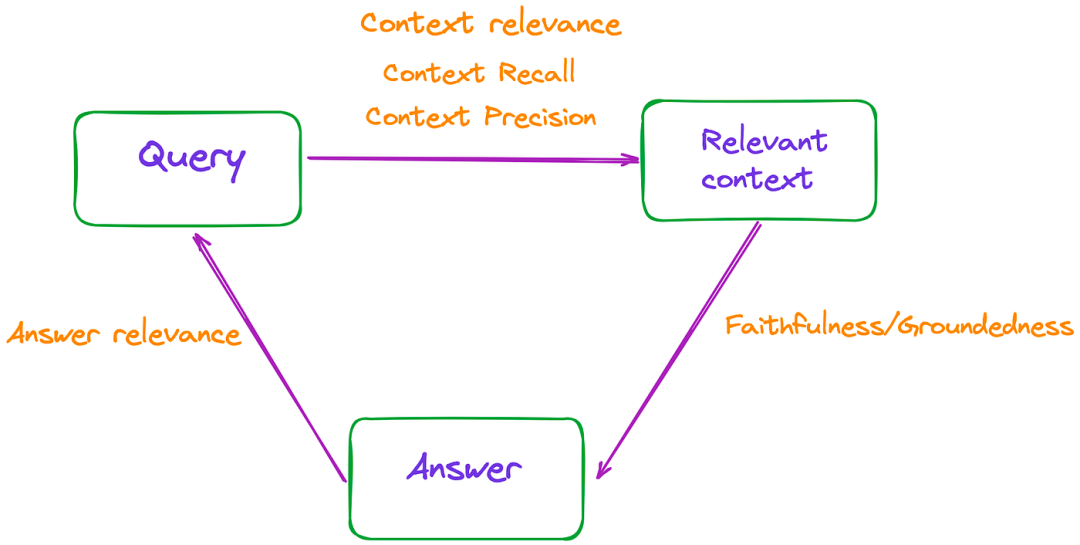
RAGAs (Retrieval-Augmented Generation Assessment) 它是一个框架 GitHub文档,它可以快速评估 RAG系统 两个方面的性能: <生成> 和 <检索>

一、RAG评估指标
常用的五个指标如下:
生成的两个指标:
- 忠实度(faithfulness)
- 答案相关性(Answer relevancy)
检索的三个指标:
- 上下文精度(Context precision)
- 上下文召回率(Context recall)
- 上下文相关性(Context relevancy)
这些指标都啥关系啊?
1.1 忠实度/可信度
忠实度(faithfulness):衡量了生成的答案(answer)与给定上下文(context)的事实一致性。取值范围是 (0,1) 越高越好。
- 上下文:中华人民共和国,简称“中国”,成立于1949年10月1日,是工人阶级领导的的社会主义国家
- 问题:中国的成立时间?
- 回答1:中国成立于1949年10月1日(可信度 高)
- 回答2:中国成立于1949年10月3日(可信度 低)

回答错误,可信度直接降为0.
1.2 答案相关性
答案相关性(Answer relevancy):评估生成的答案(answer)与用户问题(question)之间相关程度。越是不完整或包含冗余信息的答案,得分越低,得分越高表示相关性越好。取值范围是 (0,1) 。
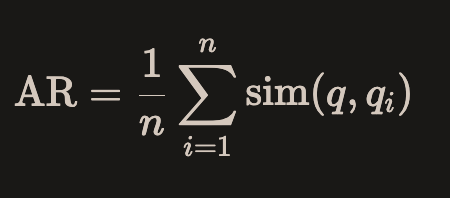
- 上下文:中华人民共和国,简称“中国”,成立于1949年10月1日,是工人阶级领导的的社会主义国家
- 问题:中国的成立时间?
- 回答1:中国成立于1949年10月1日(相关性 高)
- 回答2:成立于1949年,是社会主义国家(相关性 低)

回答不完整&多回答了国家的性质,相关性降低。
1.3 上下文精度
上下文精度(Context precision):评估所有在上下文(contexts)中呈现的与基本事实(ground-truth)相关的条目是否排名较高。该指标使用question和计算contexts,值范围在 0 到 1 之间,其中分数越高表示精度越高。

1.4 上下文召回率
上下文召回率(Context recall):衡量检索到的上下文(Context)与人类提供的真实答案(ground truth)的一致程度。
根据gr
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2034
2034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











