






前言
由于工作任务原因,需要了解模型部署完成任务,因此简单解了一下模型部署的方法。就深度学习模型来说,模型完成训练后,需要将模型及参数持久化成文件,但由于不同的训练框架导出的模型文件中存储的数据结构不同,这给模型的推理系统带来了不便。为了方便推理系统支持不同的训练框架得到的模型,则需要将模型文件中的数据转换成统一的数据结构,因此提出模型部署方法。模型部署指让训练好的模型在特定环境中运行的过程。但模型部署会面临更多的难题:
1)运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。
2)深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。模型的运行效率需要优化。
因为这些难题的存在,模型部署不能靠简单的环境配置与安装完成。经过工业界和学术界数年的探索,模型部署有了一条流行的流水线1:
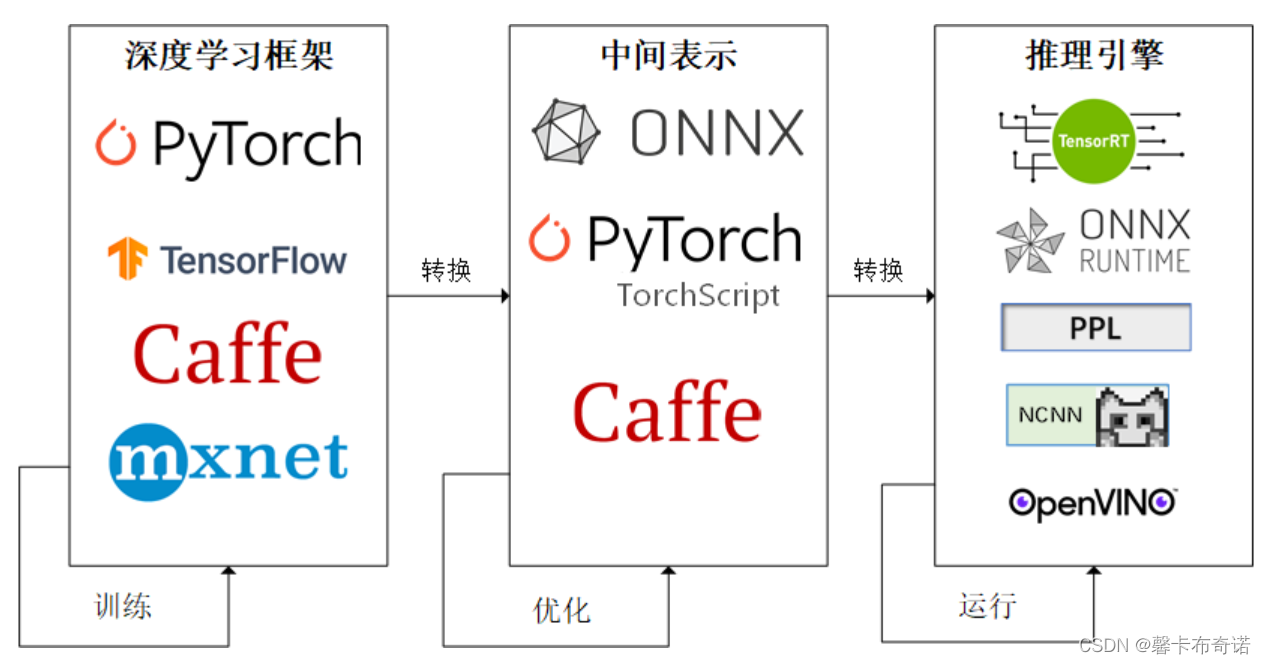
为了让模型最终能够部署到某一环境上,开发者们可以使用任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。之后,模型的结构和参数会被转换成一种只描述网络结构的中间表示,一些针对网络结构的优化会在中间表示上进行。最后,用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写,能高效执行深度学习网络中算子的推理引擎会把中间表示转换成特定的文件格式,并在对应硬件平台上高效运行模型。
这一条流水线解决了模型部署中的两大问题:使用对接深度学习框架和推理引擎的中间表示,开发者不必担心如何在新环境中运行各个复杂的框架;通过中间表示的网络结构优化和推理引擎对运算的底层优化,模型的运算效率大幅提升。
下面内容均以pytorch模型为例子, python== 3.8.0,构建应用网页
1.常规方法(无需转换中间表示)
该方法适用于设备条件充足、无需考虑算力。
Flask + torch.load(‘model.pth’)
Flask 是一个使用 Python 编写的轻量级 Web 应用程序框架。用于python网页开发,相当于执行Java中前后端交互的ajax方法。Flask 简单了解即可,高级用法参考Flask 教程2 ;torch.load(),pytorch自带加载模型函数,安装、函数参考教程3。
序列标注模型 代码示列
from flask import Flask, request, Response, render_template
from flask_cors import CORS
import torch
import json
from Datasets import Datasets
def ctpn():
‘’‘模型加载函数
‘’’
PATH = './model.pth'
device = torch.device("cpu")
model = torch.load(PATH, map_location=device)
return model
def bi_type_list(tag_lists,text_list):
''' 标签转换函数 BIO2标注方法 可自定义(仅供参考)
tag_lists:标签list; text_list: 文本list
entities: 实体list
'''
entities = []
entity = None
for idx, st in enumerate(tag_lists):
if entity is None:
if st.startswith('B'):
entity = {}
entity['start'] = idx
entity['label'] = st.split('-')[-1]
else:
continue
else:
if st == 'O':
entity['end'] = idx
word = text_list[entity['start']:entity['end']]
entities.append((entity['label'], entity['start'], entity['end'],''.join(word)))
entity = None
elif st.startswith('B'):
entity['end'] = idx
word = text_list[entity['start']:entity['end']]
entities.append((entity['label'], entity['start'], entity['end'],''.join(word)))
entity = {}
entity['start'] = idx
entity['label'] = st.split('-')[-1]
elif st.startswith('I') and entity['label'] == st.split('-')[-1]:
continue
elif st.startswith('I') and entity['label'] != st.split('-')[-1]:
entity['end'] = idx
word = text_list[entity['start']:entity['end']]
entities.append((entity['label'], entity['start'], entity['end'],''.join(word)))
entity = None
else:
entity = None
if entity:
entity['end'] = idx
word = text_list[entity['start']:entity['end']]
entities.append((entity['label'], entity['start'], entity['end'],''.join(word)))
return entities
@app.route("/deidentification", methods=['POST'])
def recognize():
'''模型执行序列标注
'''
#标签字典
tag2id = {'<pad>': 0, 'O': 1, 'B-LOC': 2, 'I-LOC': 3, 'B-PER': 4, 'I-PER': 5,
'B-ORG': 6, 'I-ORG': 7}
id2tag = dict((ids, tag) for tag, ids in tag2id.items())
pred = []
text = request.form['context'] #前端获取输入
#数据处理
config = torch.load("models-config.pth") #词表等参数加载
test_set = Datasets(text, config)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=32, shuffle=False,
collate_fn=test_set.collate)
#模型识别
with torch.no_grad():
for test_batch in test_loader:
sorces = model(test_batch['ohots']) #预测logits
_, batch_tagids = torch.max(sorces, dim=2) #预测logits转化tag_ids
for i in range(len(test_batch['ohots'])):
text_list = [char for char in test_batch['tokenized_text'][i]]
mask = test_batch['mask'][i]
pre_tagids = batch_tagids[i].masked_select(mask).contiguous() #恢复序列原本长度
pred_lable = [id2tag[int(j)] for j in pre_tagids] #预测结果
pred.append({"source": text, "result": bi_type_list(pred_lable,text_list)}) #预测结果对应字典
rep = Response()
sj = {"source":text,"data": pred[0]["result"]} #后端传向前端 预测结果json格式化
rep.set_data(json.dumps(pred, ensure_ascii=False))
return render_template('base.html', rep = sj) #后端传向前端页面base.html
@app.route('/')
def adddemo1():
return render_template('base.html') #跳转前端页面base.html
if __name__ == "__main__":
model = ctpn() #模型加载
app = Flask(__name__)
CORS(app, supports_credentials=True) #进行跨域处理
app.run(host="127.0.0.1", port=8008)
base.html页面不做展示。
2.ONNX方法(转换中间表示)
第一步: 安装 ONNX Runtime、 ONNX
# 安装 ONNX Runtime, ONNX
pip install onnxruntime onnx
第二步: 了解torch.onnx.export、onnx.load、onnx.checker.check_model 函数
(1)torch.onnx.export () 是 PyTorch 自带的把模型转换成 ONNX 格式的函数。
torch.onnx.export(
model, #待导出模型
x, #输入
"model.onnx", #导出名称
opset_version=11, #onnx版本
input_names=['input'], #输入名称
output_names=['output'], #输出名称
dynamic_axes={ #动态化输入 动态输入batch_size
'input': {0: 'batch_size'}
'output':{0: 'batch_size'}
)
(2)onnx.load () 是函数用于读取一个 ONNX 模型。onnx.checker.check_model ()是检测ONNX是否正确。
import onnx
onnx_model = onnx.load("model.onnx")
try:
onnx.checker.check_model(onnx_model)
except Exception:
print("Model incorrect")
else:
print("Model correct")
第三步: 构建自己的模型并导出ONNX
#构建模型
import torch
class JustReshape(torch.nn.Module):
def __init__(self):
super(JustReshape1, self).__init__()
def forward(self, x):
return x
#导出ONNX模型
net = JustReshape()
model_name = 'just_reshape.onnx'
dummy_input = torch.rand(5, 3)
print(dummy_input)
symbolic_names = {0: 'batch_size', 1: 'max_seq_len'}
torch.onnx.export(
net,
dummy_input,
model_name,
opset_version=11,
input_names=['input'],
output_names=['output'],
dynamic_axes={
'input': symbolic_names,
'output': symbolic_names
}
)
第四步:运行ONNX
onnxruntime .InferenceSession(‘model.onnx’, providers=[‘CPUExecutionProvider’])
providers=[ ‘CUDAExecutionProvider’, ‘CPUExecutionProvider’] 指定服务支持
import onnxruntime as ort
import torch
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
if __name__ == '__main__':
sess = ort.InferenceSession('./just_reshape.onnx', providers=['CPUExecutionProvider'])
with torch.no_grad():
input = {
'input': to_numpy(torch.randn(3, 5)),
}
outs = sess.run(['output'], input)[0]
print(outs.shape)
就如此简单,导出模型。但是自定义模型往往不是如此简单。
Netron(开源的模型可视化工具)来可视化 ONNX 模型 在线网址: https://netron.app/
3.ONNX导出常见错误
(1)TracerWarning: Converting a tensor to a Python XXXX cause the trace to be incorrect. We can’t record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
ONNX导出时,ONNX输入是动态化输入,但是在后续操作中,出现将动态化tensor转成python 常量。例如 .item() 操作,将tensor转化为常量。虽能正常导出,但在运行ONNX阶段出现错误(onnxruntime.capi.onnxruntime_pybind11_state.Fail: [ONNXRuntimeError] : 1 : FAIL : Non-zero status code returned while running Concat node. Name:‘Concat_1203’ Status Message: concat.cc:154 PrepareForCompute Non concat axis dimensions must match: Axis 1 has mismatched dimensions of 500 and 490) 维度固定,无法动态化输入。
解决方法:
参考导出CRF模型的ONNX4
import torch
# Trace-based only
class LoopModel(torch.nn.Module):
def forward(self, x, y):
for i in range(y):
x = x + i
return x
model = LoopModel()
dummy_input = torch.ones(2, 3, dtype=torch.long)
loop_count = torch.tensor(5, dtype=torch.long)
torch.onnx.export(model, (dummy_input, loop_count), 'loop.onnx', verbose=True)
#修改为
@torch.jit.script
def loop(x, y):
for i in range(int(y)):
x = x + i
return x
class LoopModel2(torch.nn.Module):
def forward(self, x, y):
return loop(x, y)
model = LoopModel2()
dummy_input = torch.ones(2, 3, dtype=torch.long)
loop_count = torch.tensor(5, dtype=torch.long)
torch.onnx.export(model, (dummy_input, loop_count), 'loop.onnx', verbose=True,
input_names=['input_data', 'loop_range'])
用@torch.jit.script封装固定变化,可解决问题
在固定封装过程中y必须是tensor的形式,已经不能转化成 int 表示,否则依旧报错。
(2)新算子的更新速度往往快于 ONNX 维护者支持的速度
详情参考5
解决方法:自定义新算子
何为算子? 神经网络的结构往往能用计算图表示,而其通常识利用ONNX 表示成更容易部署的静态图。在静态图中的节点,被称之为算子。深度学习的发展会不断诞生新算子,为了支持这些新增的算子,ONNX 会经常发布新的算子集,目前已经更新 15 个版本,详情5。
自定义新算子未仔细研究,详情参考6
(3)后续将持续补充
参考文献
https://mmdeploy.readthedocs.io/zh_CN/latest/tutorial/01_introduction_to_model_deployment.html ↩︎
https://www.w3cschool.cn/flask/ ↩︎
https://pytorch.org/ ↩︎
https://glaringlee.github.io/onnx.html#tracing-vs-scripting ↩︎
https://github.com/xboot/libonnx/blob/master/documents/the-supported-operator-table.md ↩︎ ↩︎
https://mmdeploy.readthedocs.io/zh_CN/latest/tutorial/02_challenges.html ↩︎

















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









