







前言
最近因为需要做一些redis-cluster-operator的故障演练,新搭建了一个k8s集群,新的k8s集群需要搭建一套监控告警系统,对于Prometheus,之前自己在虚拟机上练过手,比较麻烦,需要先后安装Prometheus、Grafana、AlertManager,还需要修改各种配置,今天一想,现在都2202年了,肯定有更简单的方法,于是在社区找到了kube-prometheus-stack
部署
GitHub地址:https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack
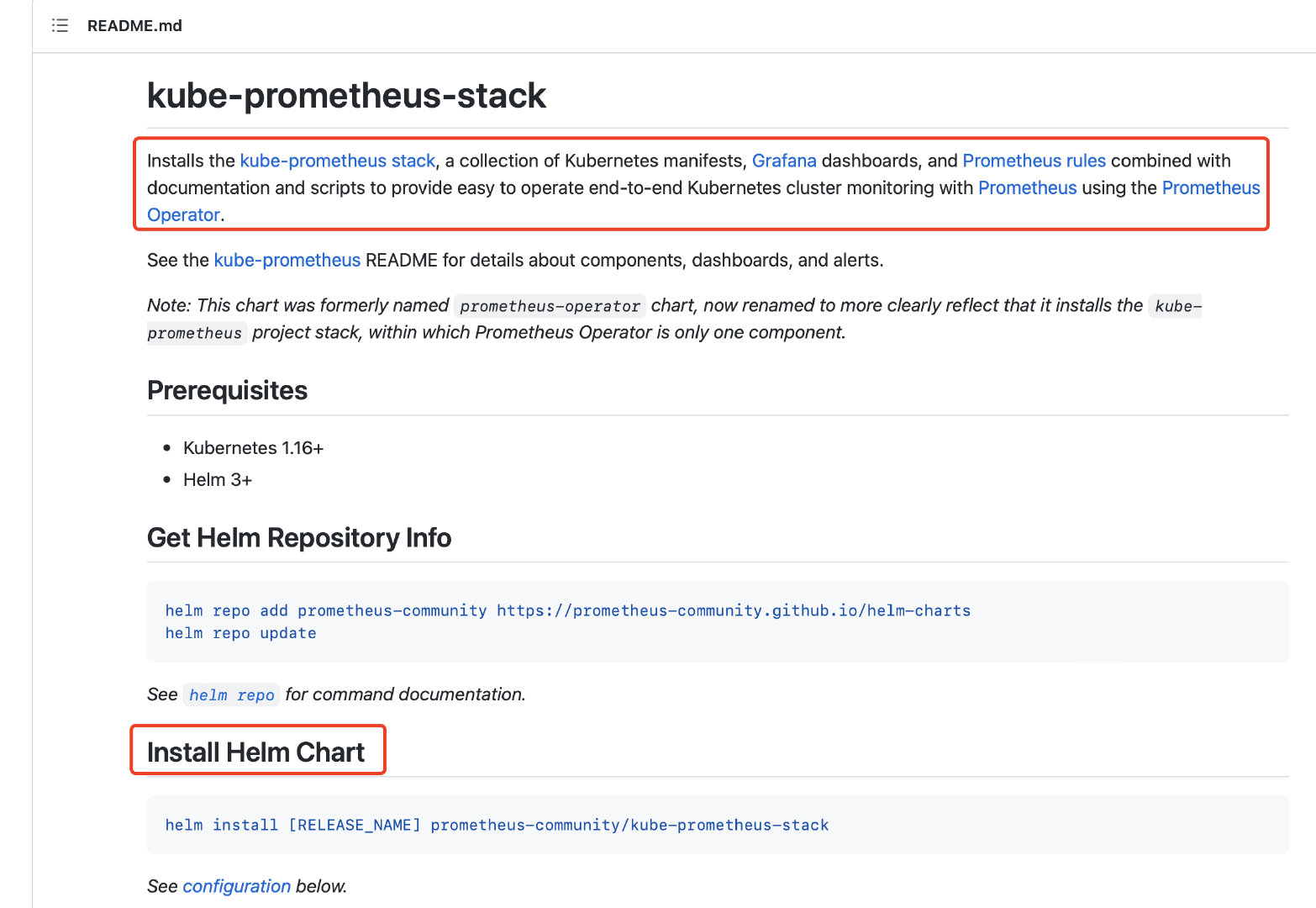
简单看了下,有两种方法进行部署:
第一种方法是下载manifests包里的yaml,再通过kubectl部署;
第二种方法是通过Helm打包部署;
依次执行下面的命令:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install prometheus-community/kube-prometheus-stack --generate-name
我使用的是第一种方法,因为用helm时,拉取镜像timeout,试了几次都没有成功,第一种方法需要先下载yaml文件,上传到服务器再部署,虽然麻烦点,但是相较于手动创建,可以节省很多时间,而且所有相关的资源都是自动创建关联,可以很省心,最主要的是试了一次就成功了。
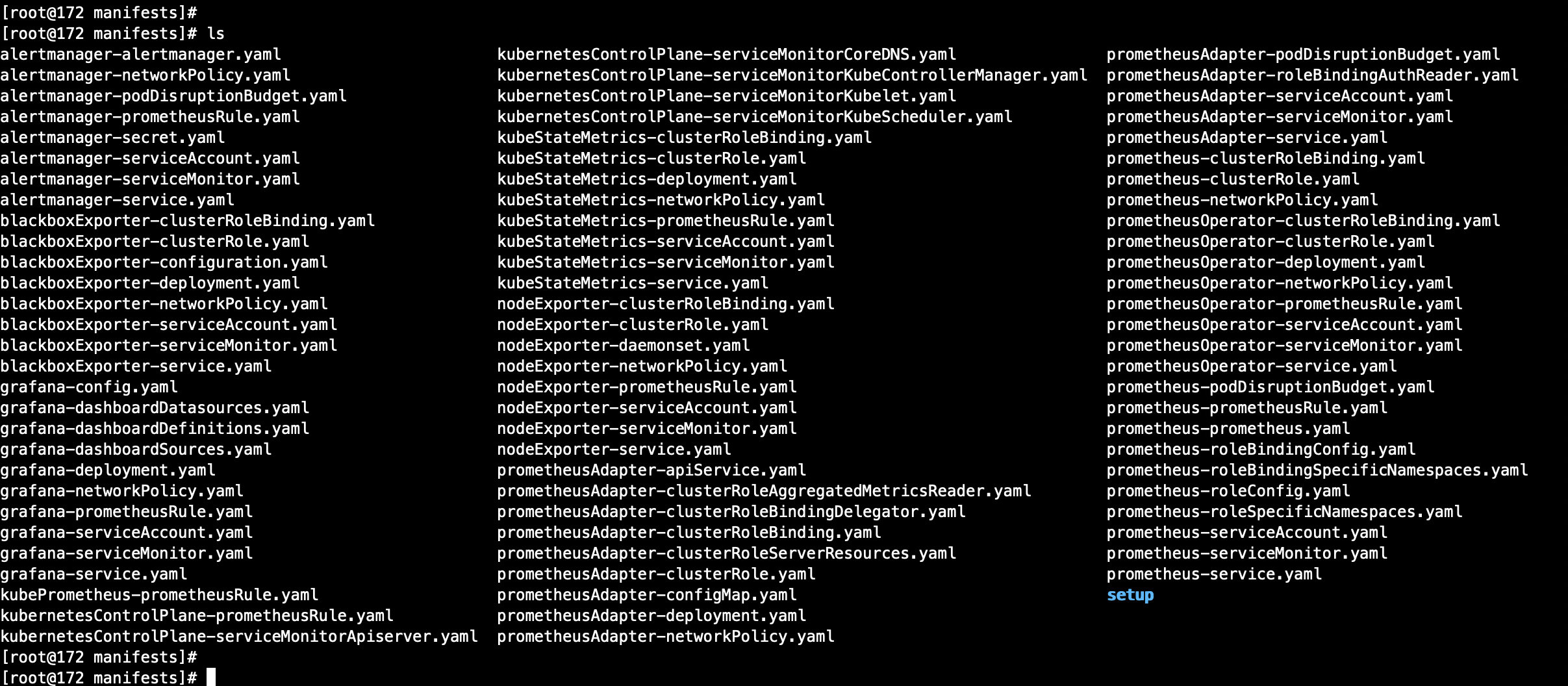
下载好的代码包解压后,将manifests文件夹打包,上传到k8s服务器,解压之后就是下面这一堆yaml文件:
再根据GitHub上的指示,执行代码即可
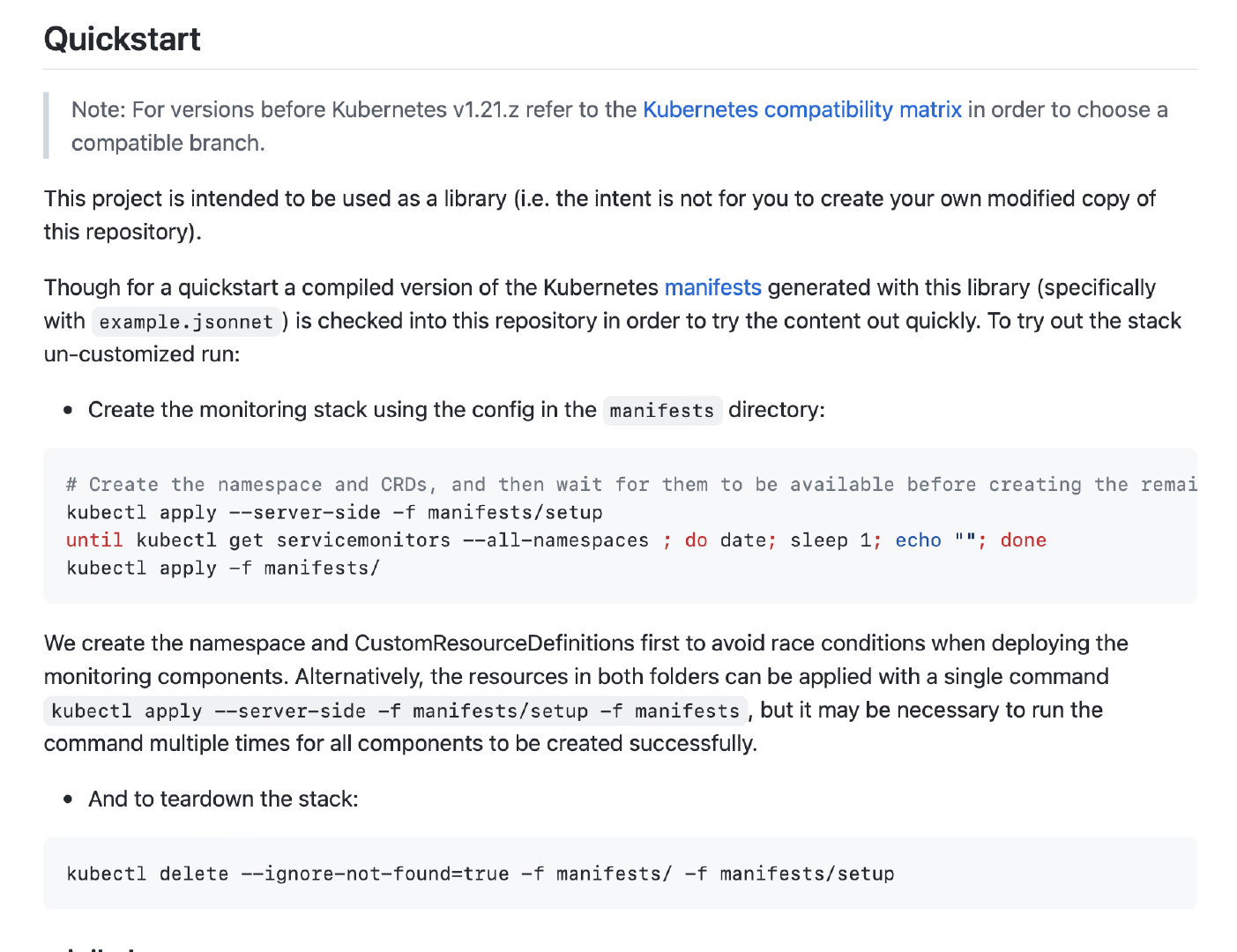
执行命令:
kubectl apply --server-side -f manifests/setup
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl apply -f manifests/
稍作等待之后,查看k8s集群内,创建了一个新的namespace:monitoring,还有所需的CRD、service、StatefulSet、Deployment、Secret、ConfigMap等等…
需要注意的是,这一套是基于operator去管理的,通过创建CRD定义各类资源,Operator会监听CRD的创建、修改,去管理对应的资源。
我在部署的时候,有两个pod拉取镜像一直失败,替换了镜像地址之后部署成功(圈红的为替换后的,之前的镜像应该是内网下载不了,需要魔法,我就找了个之前用的镜像)
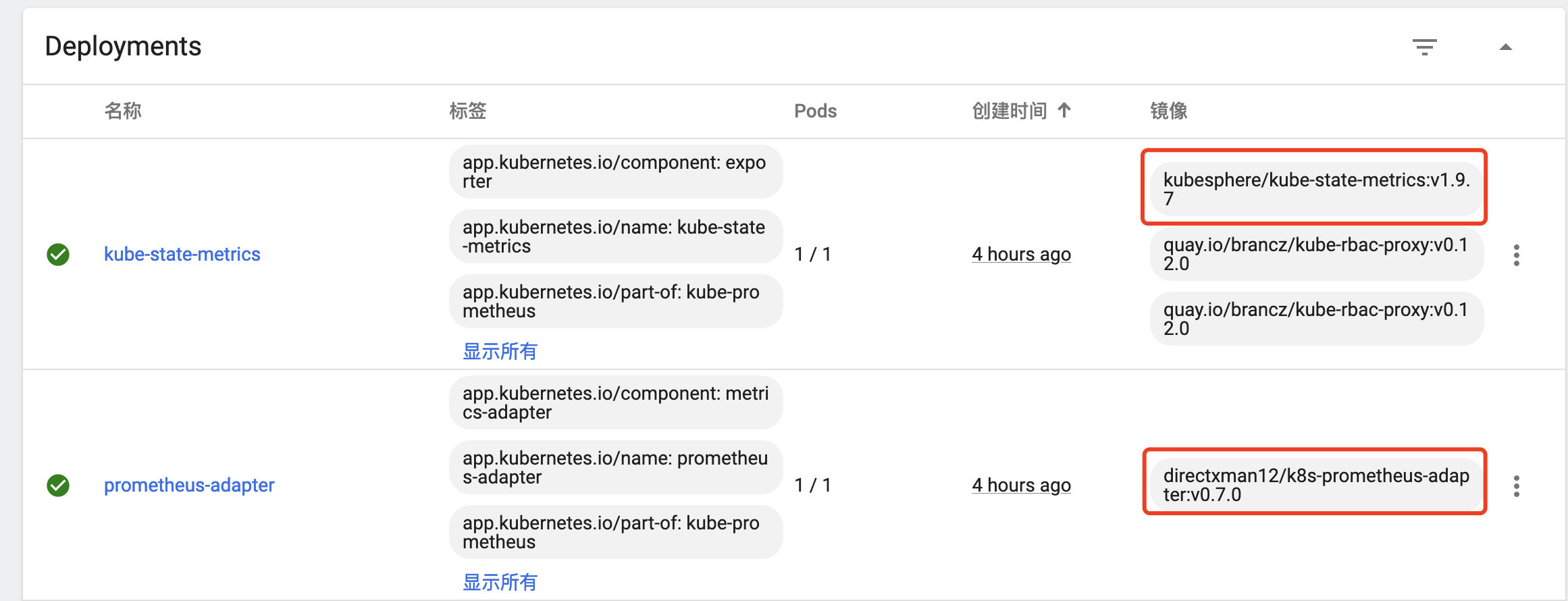
kube-state-metrics:kubesphere/kube-state-metrics:v1.9.7
prometheus-adapter:directxman12/k8s-prometheus-adapter:v0.7.0
在部署过程中就没遇到其他问题了,通过Service的ClusterIP就可以访问了:
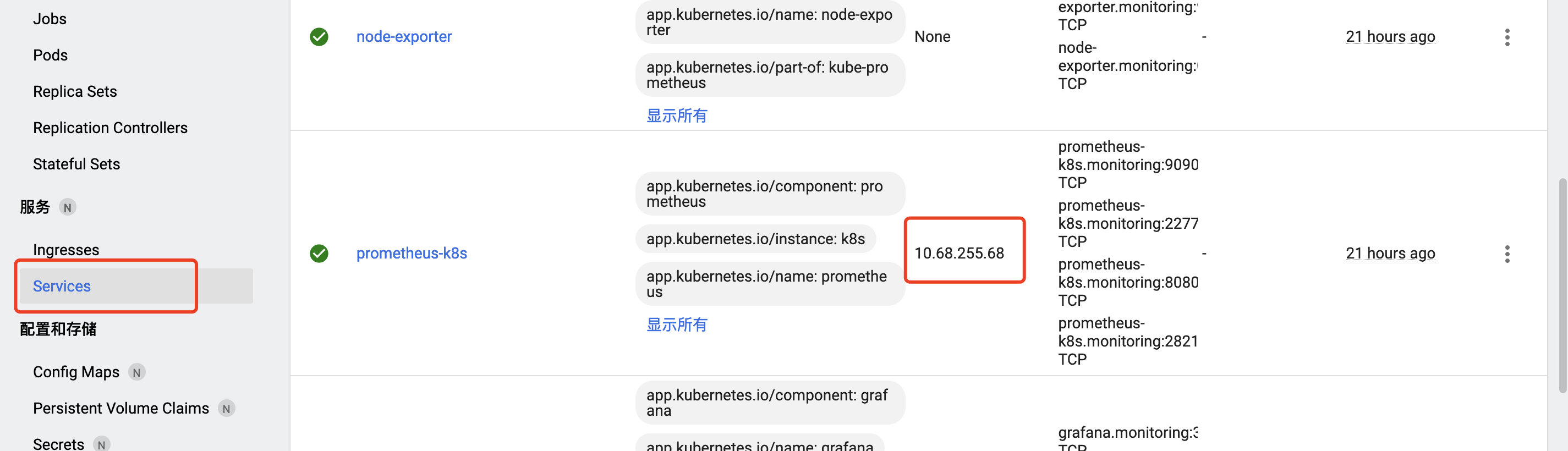
可以看到部署完成之后,所有相关的组件,都自动部署了exportor,并配置好了,还有各个组件的告警规则,也配置好了
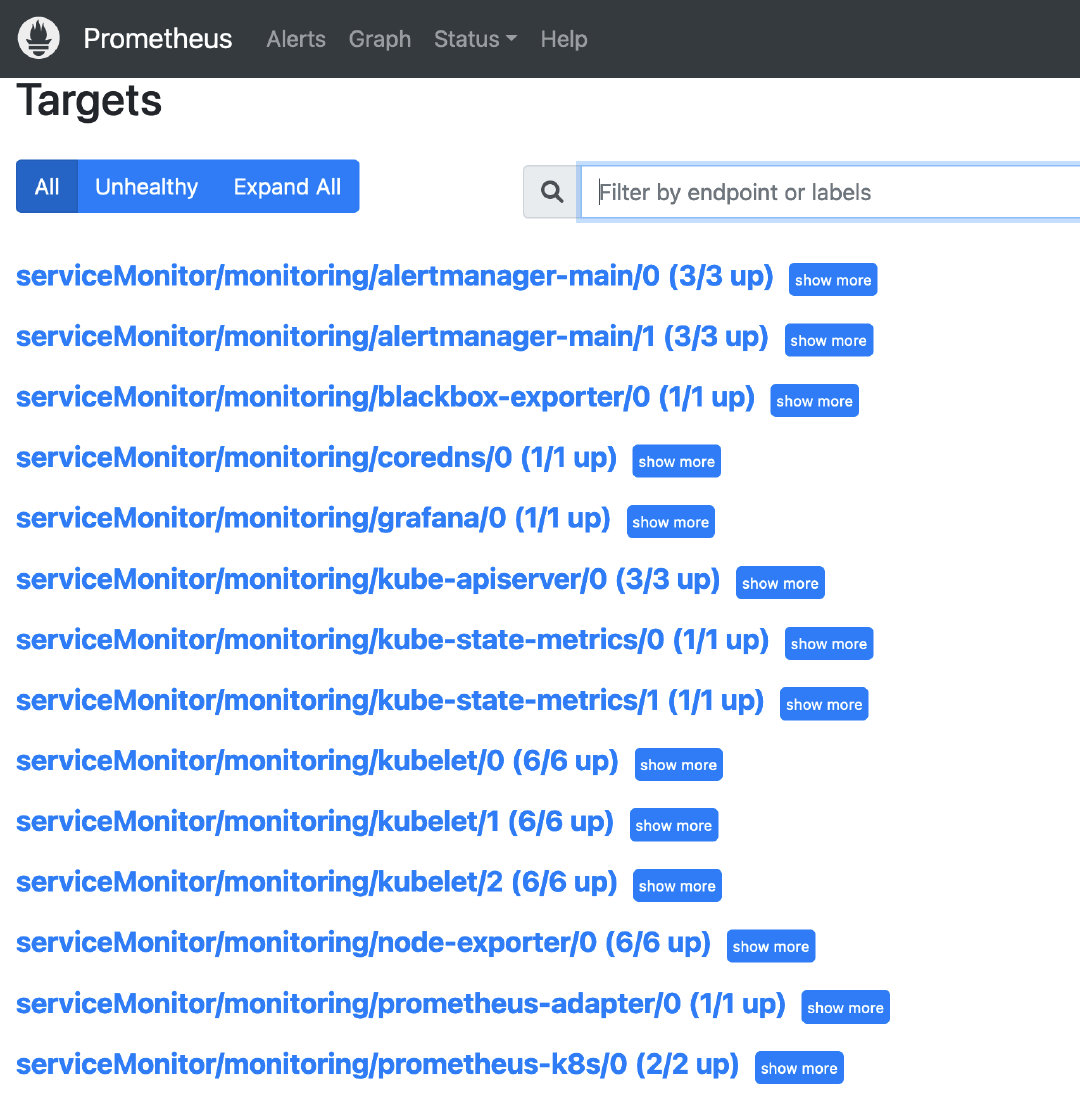
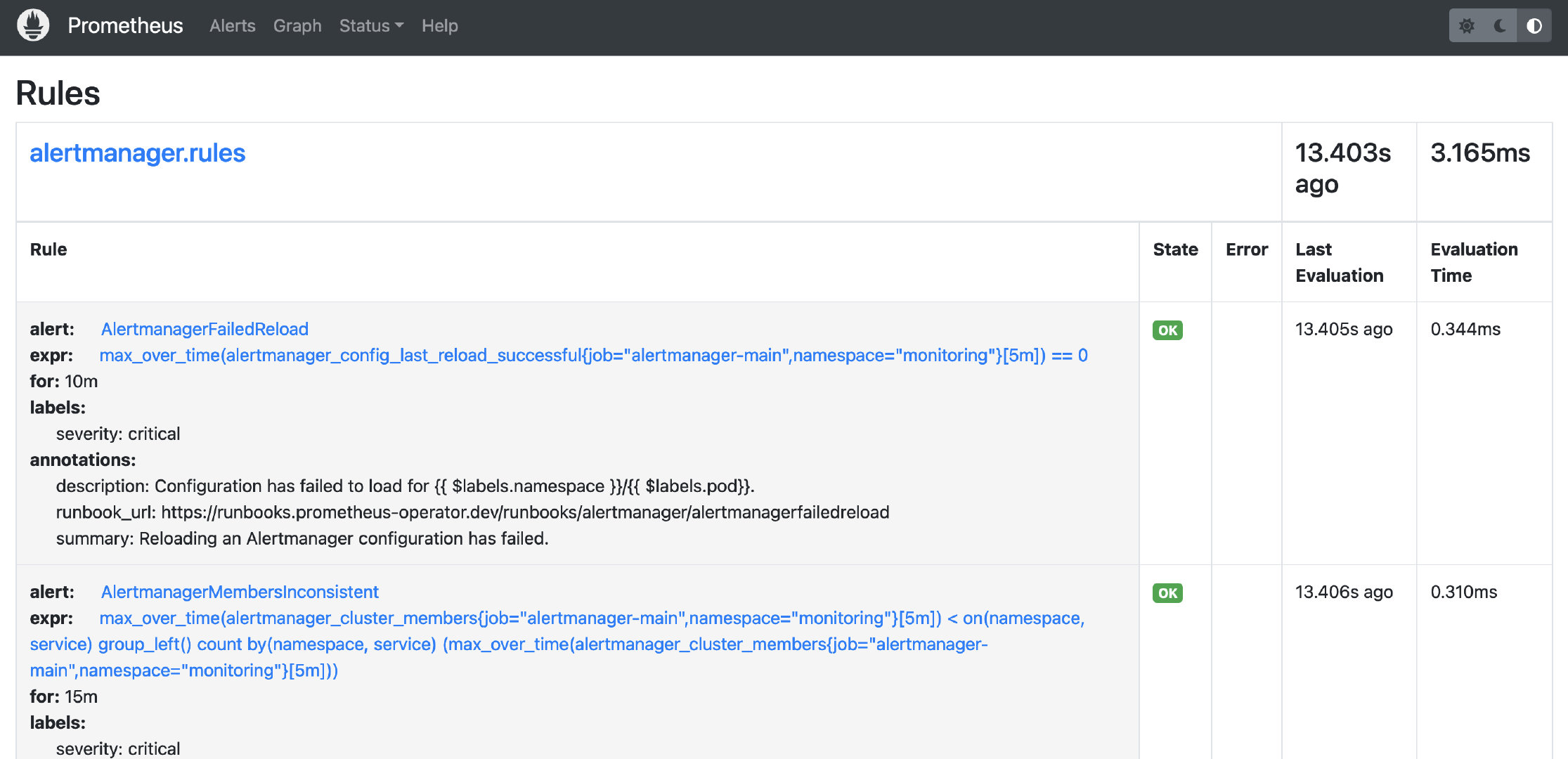
不得不说,很方便,一气呵成,后续可以根据自己的需要,进行增减。
实践
添加告警规则

可以看到,告警规则也是一个CRD,所以只需要创建一个类型为Prometheus Rule的资源就行:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: redis
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.24.0
prometheus: k8s
role: alert-rules
managedFields:
- apiVersion: monitoring.coreos.com/v1
fieldsType: FieldsV1
name: redis-rules
namespace: monitoring
spec:
groups:
- name: redis-rules
rules:
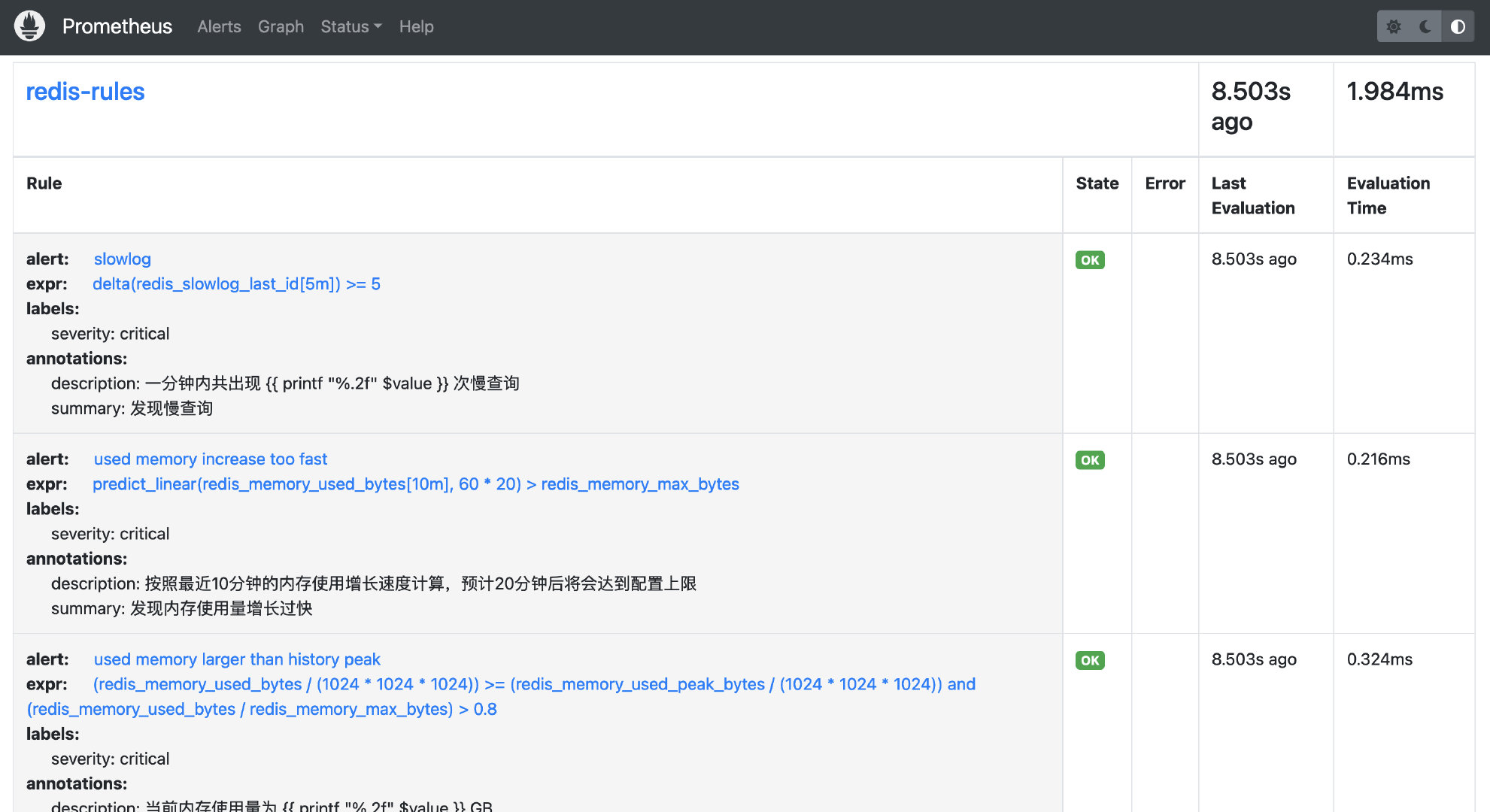
- alert: slowlog
annotations:
description: 一分钟内共出现 {{ printf "%.2f" $value }} 次慢查询
summary: 发现慢查询
expr: delta(redis_slowlog_last_id [5m]) >= 5
labels:
severity: critical
- alert: used memory increase too fast
annotations:
description: 按照最近10分钟的内存使用增长速度计算,预计20分钟后将会达到配置上限
summary: 发现内存使用量增长过快
expr: predict_linear(redis_memory_used_bytes [10m], 60 * 20) > redis_memory_max_bytes
labels:
severity: critical
- alert: used memory larger than history peak
annotations:
description: 当前内存使用量为 {{ printf "%.2f" $value }} GB
summary: 内存使用量超过历史峰值
expr: (redis_memory_used_bytes / (1024 * 1024 * 1024)) >= (redis_memory_used_peak_bytes / (1024 * 1024 * 1024)) and (redis_memory_used_bytes / redis_memory_max_bytes) > 0.8
labels:
severity: critical
- alert: option-memory usage in hight ratio
annotations:
description: 内存使用超过90%,将开启自动扩容
summary: 内存使用超过redis最大设置内存的90%
expr: (redis_memory_used_bytes / redis_memory_max_bytes) * 100 > 90 and redis_memory_max_bytes >= (1024 * 1024 * 1024)
labels:
severity: critical
- alert: memory usage in high fragmentation ratio
annotations:
description: 当前内存碎片率为 {{ printf "%.2f" $value }},理想值为1至1.4之间
summary: 内存碎片率高
expr: redis_memory_used_rss_bytes / redis_memory_used_bytes > 1.4 and redis_memory_used_bytes >= 1024 * 1024 * 1024
for: 1w
labels:
severity: warning
- alert: memory usage in low fragmentation ratio
annotations:
description: 当前内存碎片率为 {{ printf "%.2f" $value }},理想值为1至1.4之间
summary: 内存碎片率小于1,redis-server进程可能正在使用swap区,导致响应速度降低
expr: redis_memory_used_rss_bytes / redis_memory_used_bytes < 1 and redis_memory_used_bytes >= 512 * 1024 * 1024
for: 1w
labels:
severity: warning
- alert: rdb bgsave too slow
annotations:
description: 最近一次持久化时间为 {{ $value }} 秒,建议降低该节点内存使用量至4GB以内
summary: rdb持久化时间过长
expr: redis_rdb_last_bgsave_duration_sec > 120 and time() - redis_rdb_last_save_timestamp_seconds < 3600
labels:
severity: critical
- alert: redis instance maybe down
annotations:
description: redis实例可能出现故障
summary: redis实例宕机
expr: redis_up == 0
for: 5m
labels:
severity: critical
- alert: redis master slave failover
annotations:
description: redis集群发生主从切换
summary: redis主从切换
expr: changes(redis_instance_info[5m]) > 1
labels:
severity: critical
- alert: state of cluster is unnormal
annotations:
description: 集群中发现节点的状态异常,并持续2分钟,触发此告警。
summary: 检测到集群:{{$labels.redis_kun_name}}不可用,已持续2分钟。
expr: redis_cluster_state != 1
for: 2m
labels:
group: xadd-redis
severity: critical
- alert: slots of cluster assigned unnormally
annotations:
description: 发现集群槽位分配小于16384,触发此告警。
summary: 集群:{{$labels.redis_kun_name}} 的槽位未完全分配,当前分配槽位数量为:{{value}}。
expr: redis_cluster_slots_assigned < 16384
for: 2m
labels:
group: xadd-redis
severity: critical
- alert: slave lag too long
annotations:
description: Slave节点滞后时间超过10秒,触发此报警,集群cluster-node-timeout配置的是15秒。
summary: 集群:{{$labels.redis_kun_name}} 中Master节点:{{$labels.kubernetes_pod_name}} 的Slave节点滞后超过10秒,Slave IP为{{$labels.slave_ip}}。
expr: redis_connected_slave_lag_seconds > 10
labels:
group: xadd-redis
severity: warning
- alert: cluster known nodes decreased
annotations:
description: 在两分钟内,集群的已知节点数量减少,触发此报警。
summary: 集群:{{$labels.redis_kun_name}} 在两分钟内节点数减少了{{value}}个,请检查集群状态是否正常。
expr: redis_cluster_known_nodes offset 2m - redis_cluster_known_nodes > 0
labels:
group: xadd-redis
severity: critical
- alert: redis exporter maybe down
annotations:
description: 3分钟内,若up状态的exporter数量减少,则认为减少的exporter存在宕机可能,触发此告警。
summary: 集群:{{$labels.redis_kun_name}} 的exporter可能宕机,exporter实例地址为:{{$labels.instance}}。
expr: up{namespace="redis"} unless up{namespace="redis"} offset 6m
for: 5m
labels:
group: xadd-redis
severity: warning
保存好之后,创建成功
修改配置
有一个需求,对于k8s内新创建的pod,如果需要采集指标,希望可以自动添加到prometheus配置的target中,或者在需要手动添加采集目标时,不需要去prometheus的pod中修改的配置文件,单不说麻不麻烦,找到配置文件都比较繁琐。
基于这个需求,可以借助additionalScrapeConfigs来实现,这应该是prometheus-operator提供的能力,目的是通过维护一个外部的配置文件,来导入到prometheus内部的配置中。
先以Secret的方式创建好一个配置文件:
kind: Secret
apiVersion: v1
metadata:
name: prometheus-additional-scrape
namespace: monitoring
data:
additional_pods.yaml: ''
type: Opaque
配置文件的内容先随便填,创建好之后,点击修改按钮:
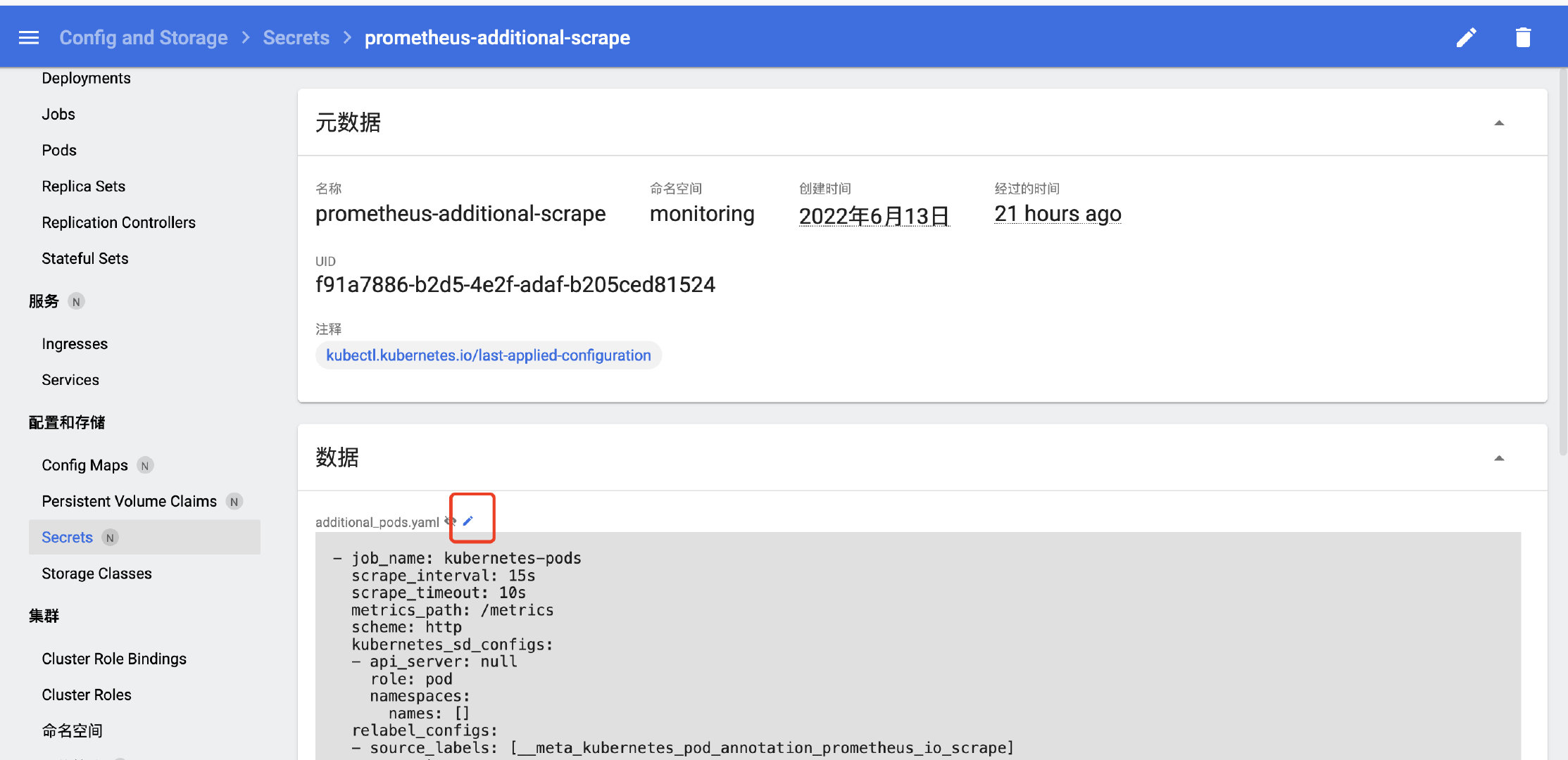
填入以下内容:
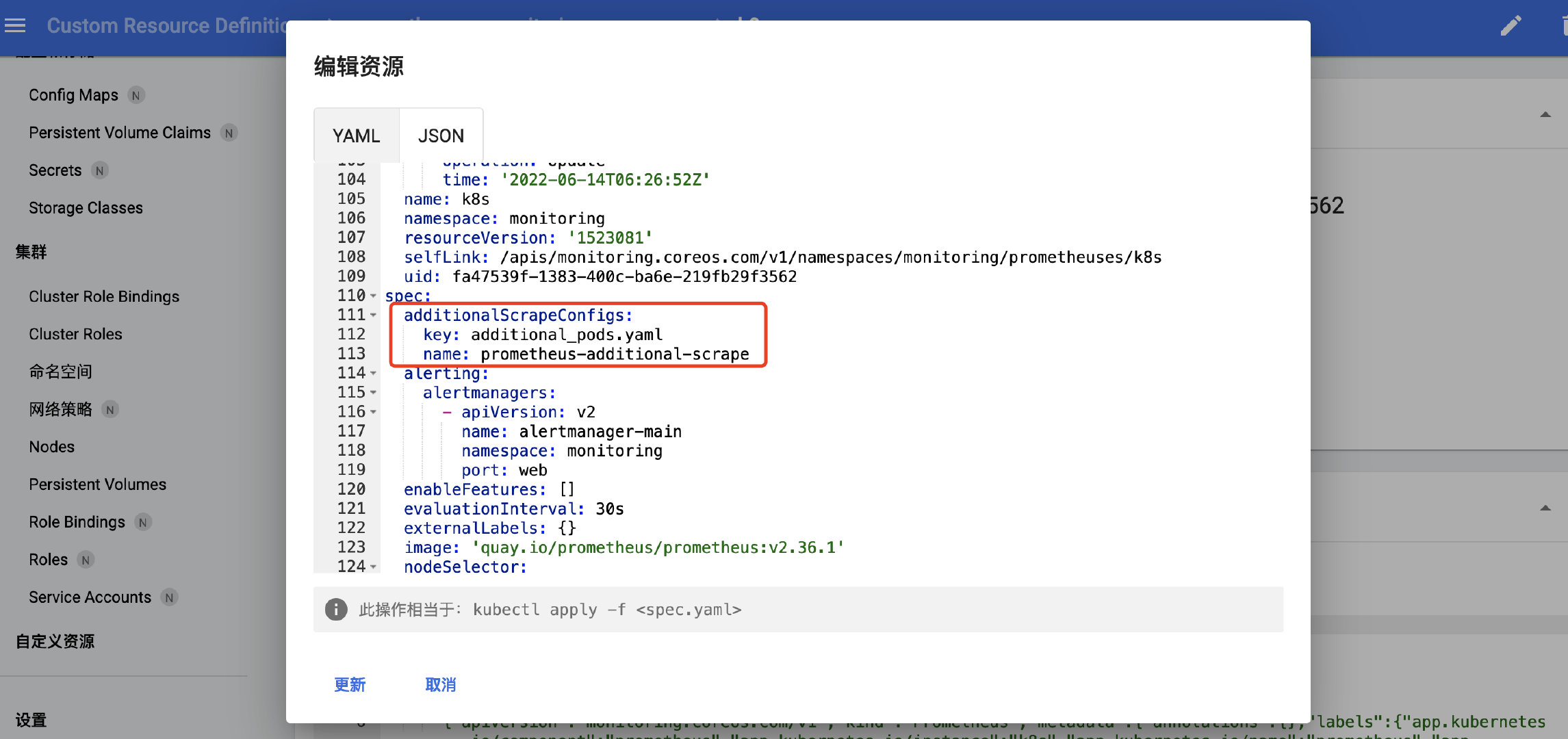
- job_name: kubernetes-pods
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- api_server: null
role: pod
namespaces:
names: []
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: $1
action: replace
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
separator: ;
regex: ([^:]+)(?::\d+)?;(\d+)
target_label: __address__
replacement: $1:$2
action: replace
- separator: ;
regex: __meta_kubernetes_pod_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
target_label: namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_pod_name]
separator: ;
regex: (.*)
target_label: kubernetes_pod_name
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_namespace, redis_kun_name]
separator: /
regex: (.*)
target_label: alias
replacement: $1
action: replace
- source_labels: [redis_cluster_size]
separator: ;
regex: (.*)
target_label: cluster_size
replacement: $1
action: replace
我们找到prometheus的定义文件,添加additionalScrapeConfigs相关配置:
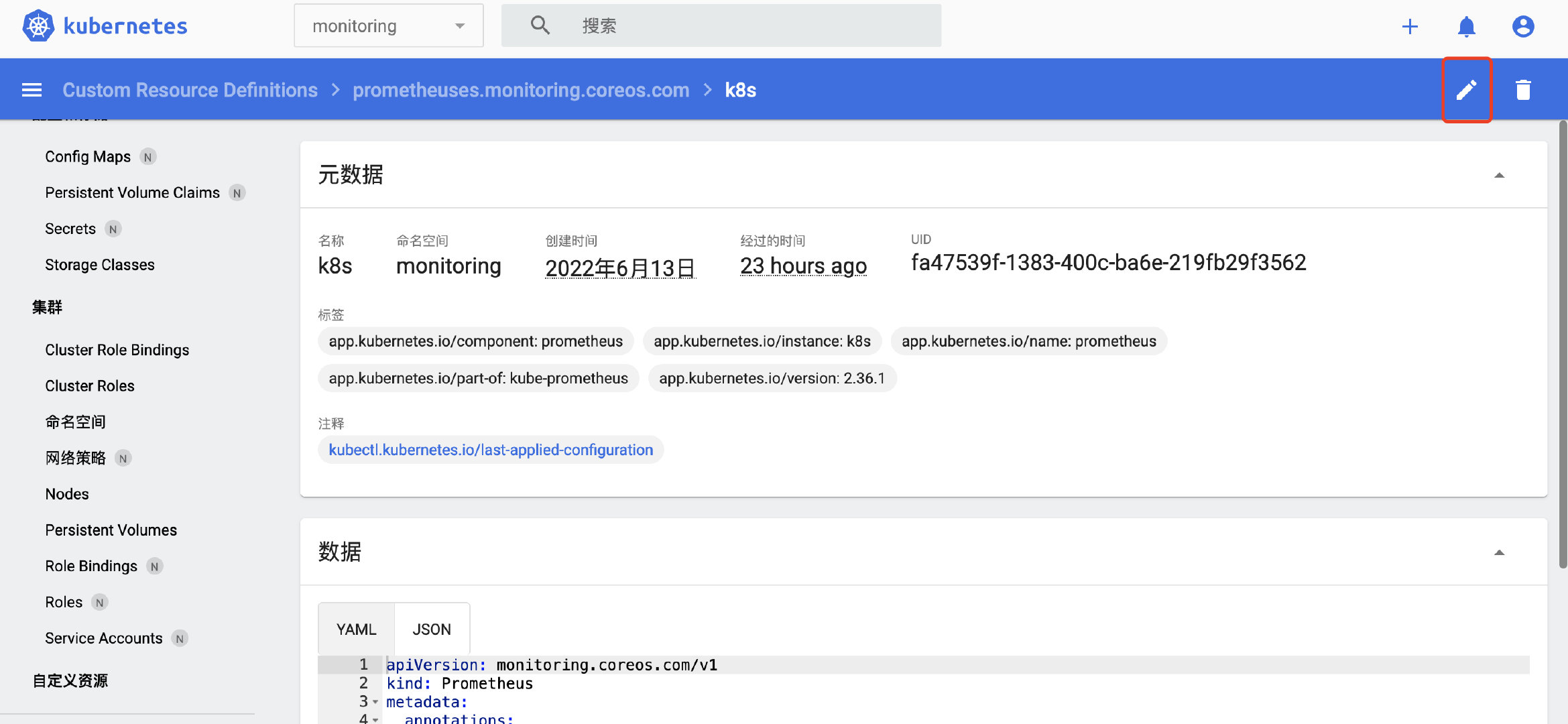
在spec下添加:
additionalScrapeConfigs:
key: additional_pods.yaml
name: prometheus-additional-scrape
需要和之前创建的Secret对应上。
此时通过页面查看prometheus的配置,发现这段配置已经加上去了
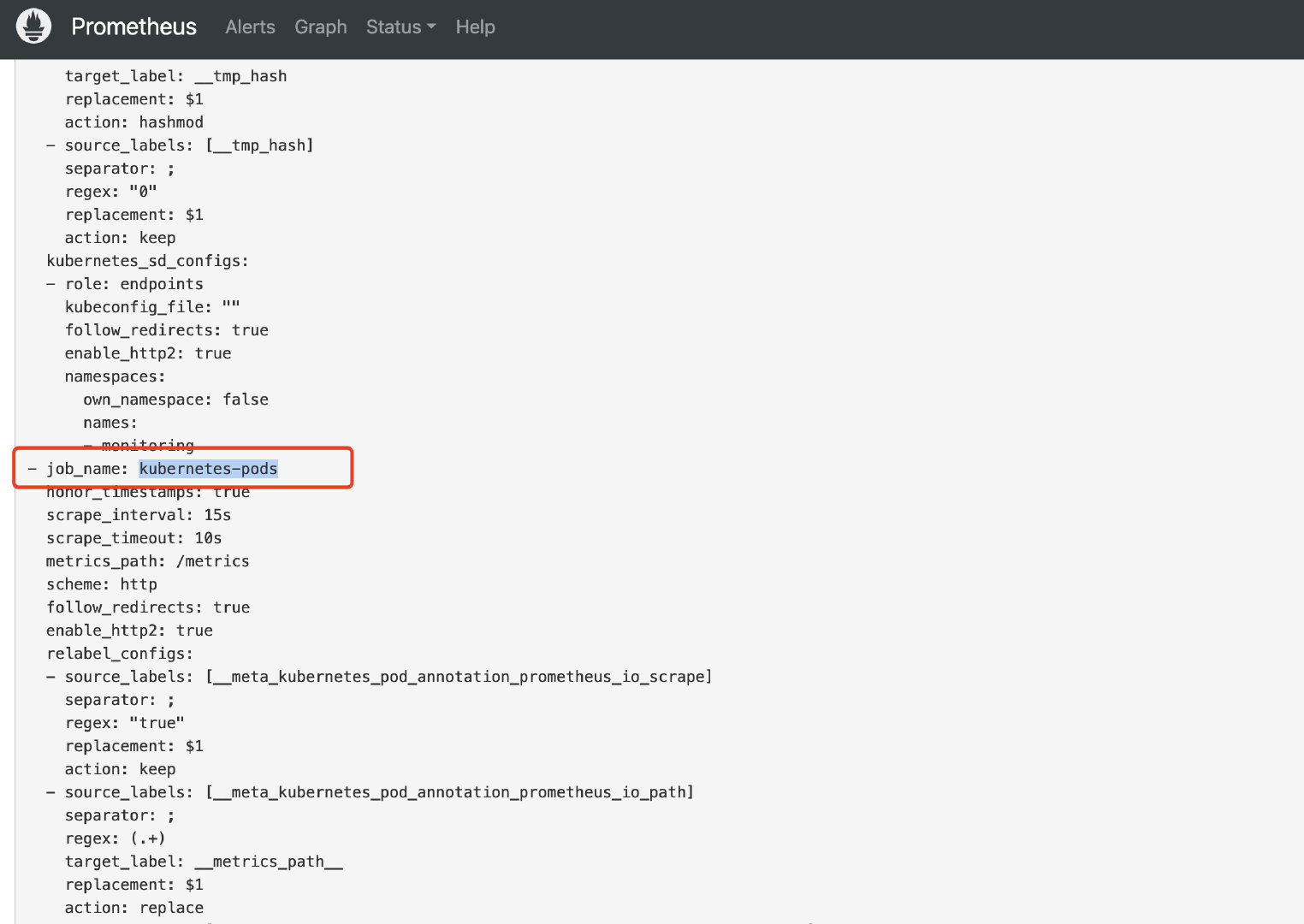
在需要被prometheus自动发现的pod上,只需要添加以下注解即可:
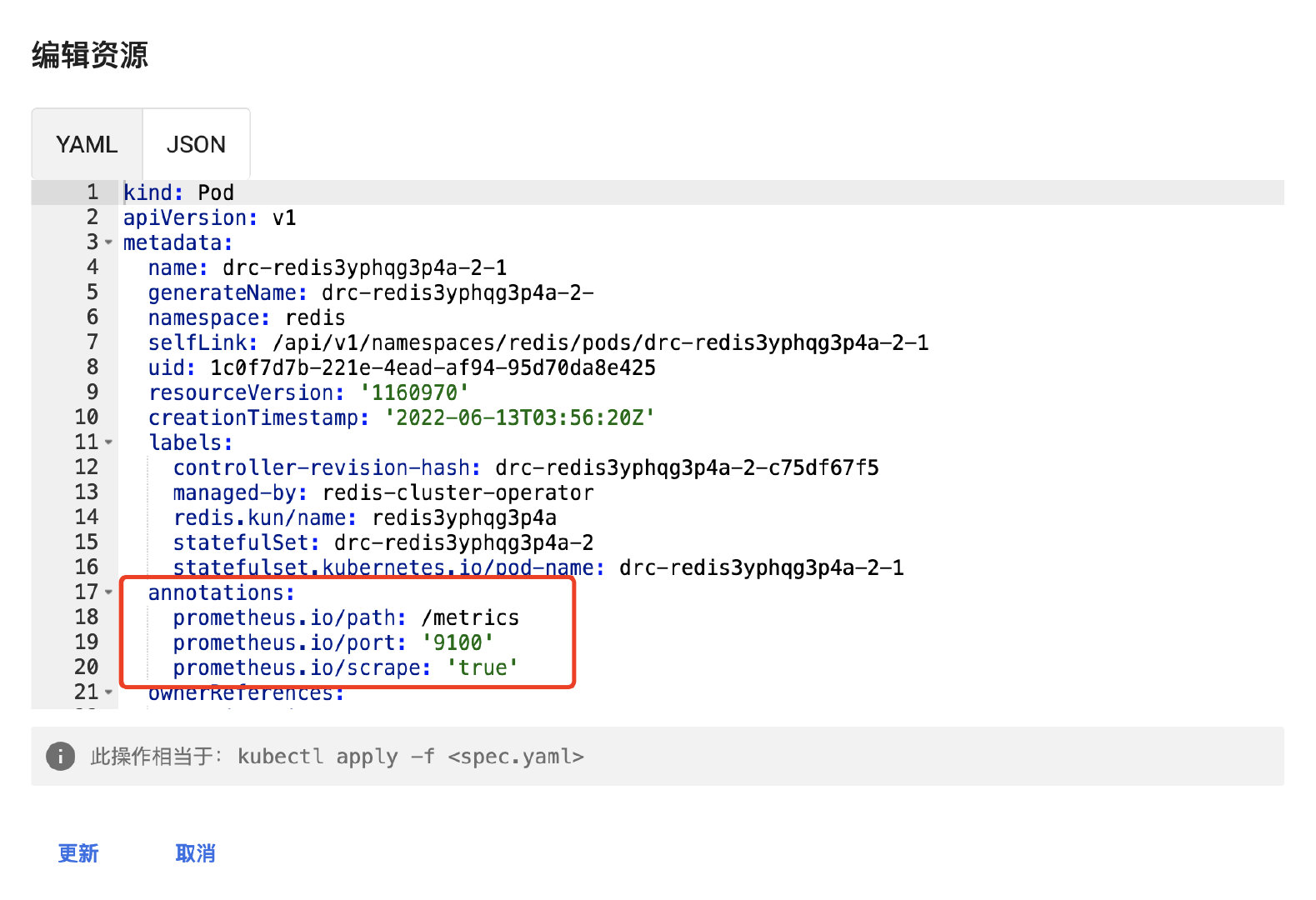
annotations:
prometheus.io/path: /metrics
prometheus.io/port: '9100'
prometheus.io/scrape: 'true'
Prometheus Operator会自动去发现并监控具有prometheus.io/scrape=true这个annotations的pod。
如果发现以下报错:
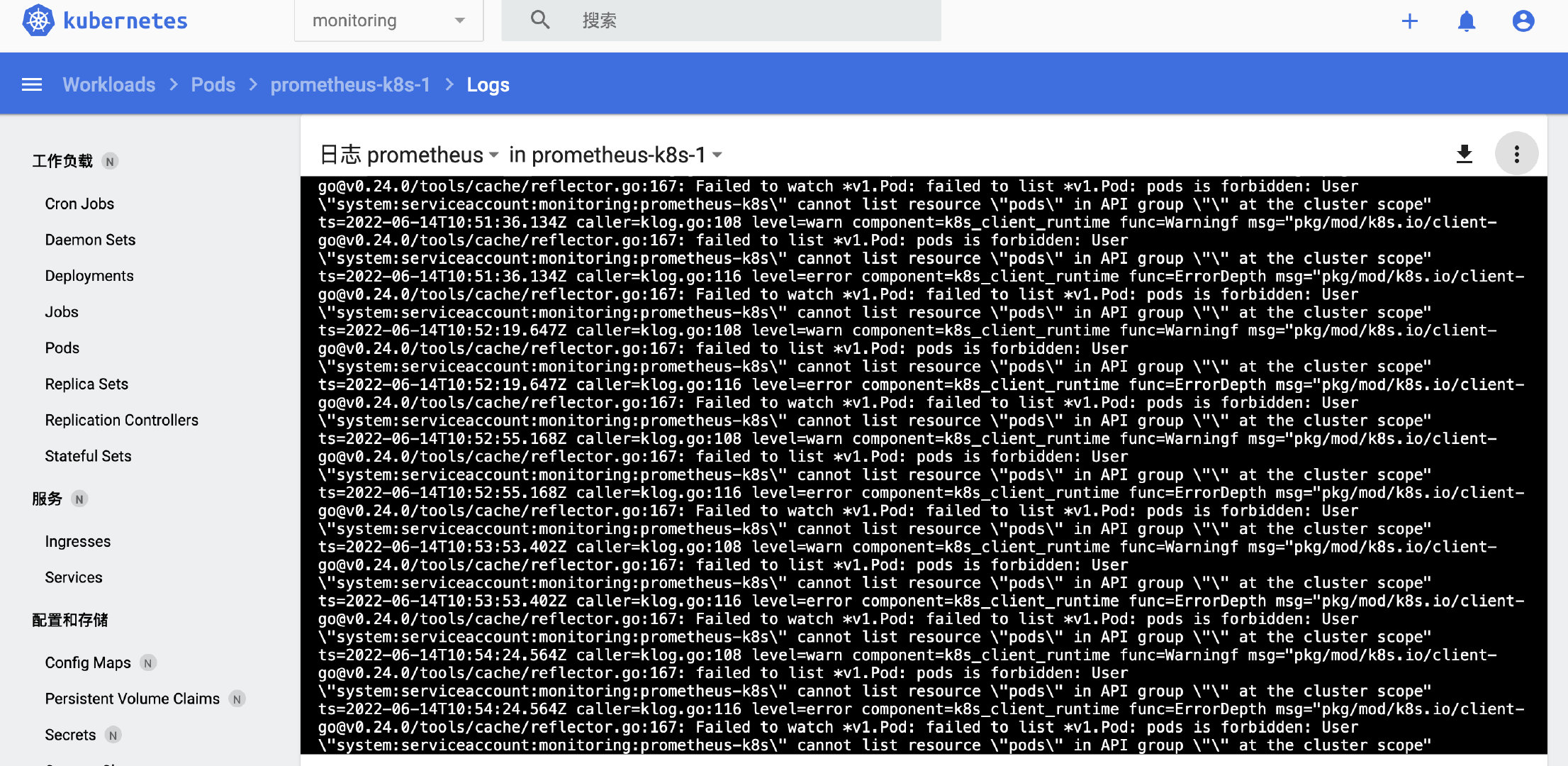
failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"pods\" in API group \"\" at the cluster scope"
ts=2022-06-14T09:46:55.087Z caller=klog.go:116 level=error component=k8s_client_runtime func=ErrorDepth msg="pkg/mod/k8s.io/client-go@v0.24.0/tools/cache/reflector.go:167: Failed to watch *v1.Pod: failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"pods\" in API group \"\" at the cluster scope"
这是因为没有权限导致的,此时prometheus是拉取不到pod的指标的,看报错是没有对pod的list、watch权限,加上即可,需要修改名为prometheus-k8s的ClusterRole:
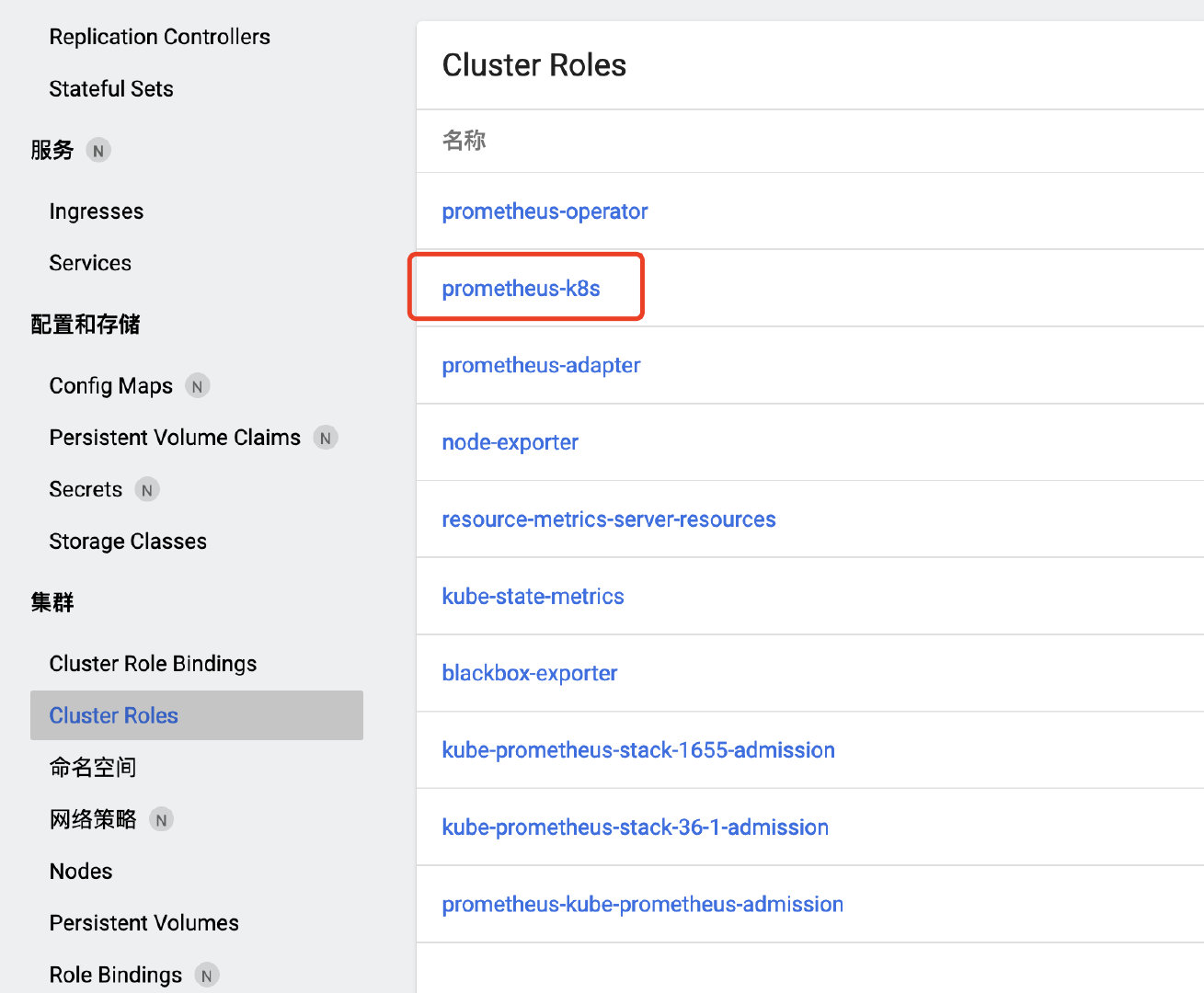
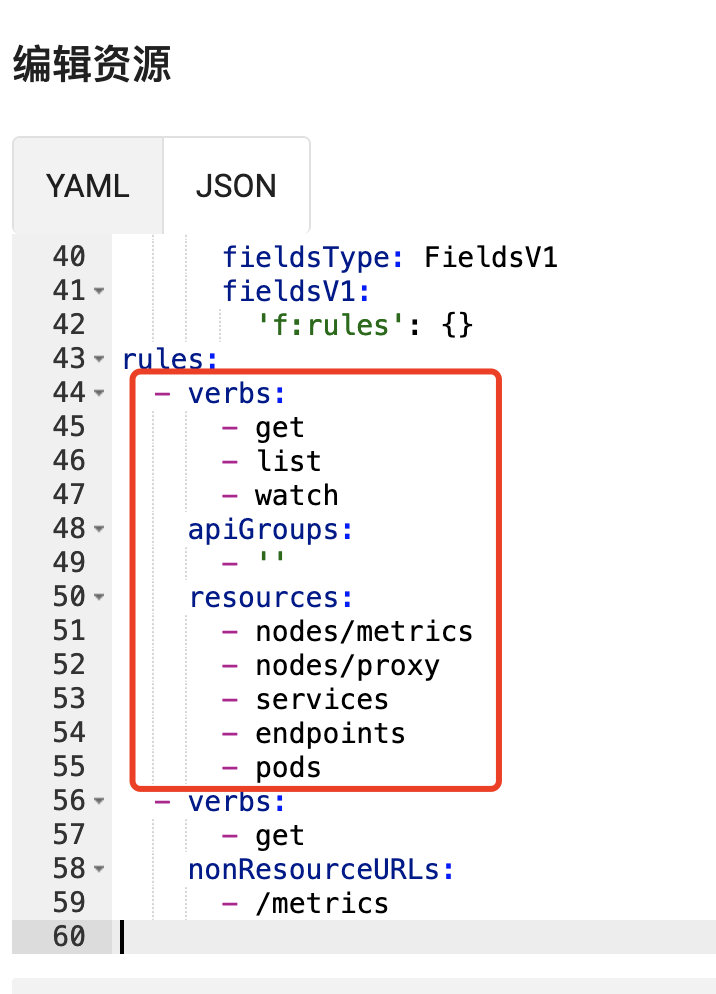
rules:
- verbs:
- get
- list
- watch
apiGroups:
- ''
resources:
- nodes/metrics
- nodes/proxy
- services
- endpoints
- pods
- verbs:
- get
nonResourceURLs:
- /metrics
保存之后,规则已生效:
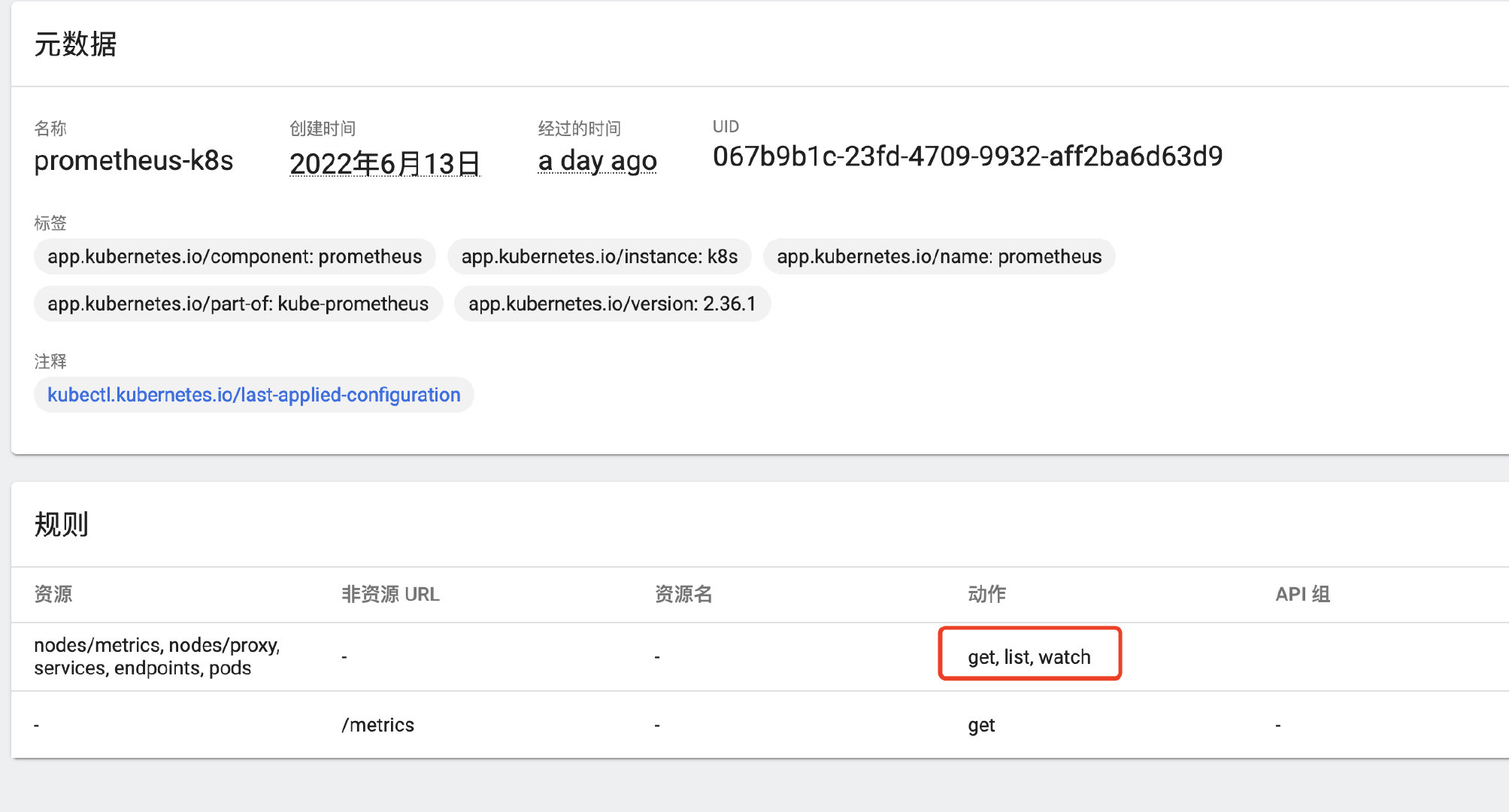
这样一来,权限就加完了,也不再报错了,再看prometheus的web页面,相关的pod已经自动拉取到了
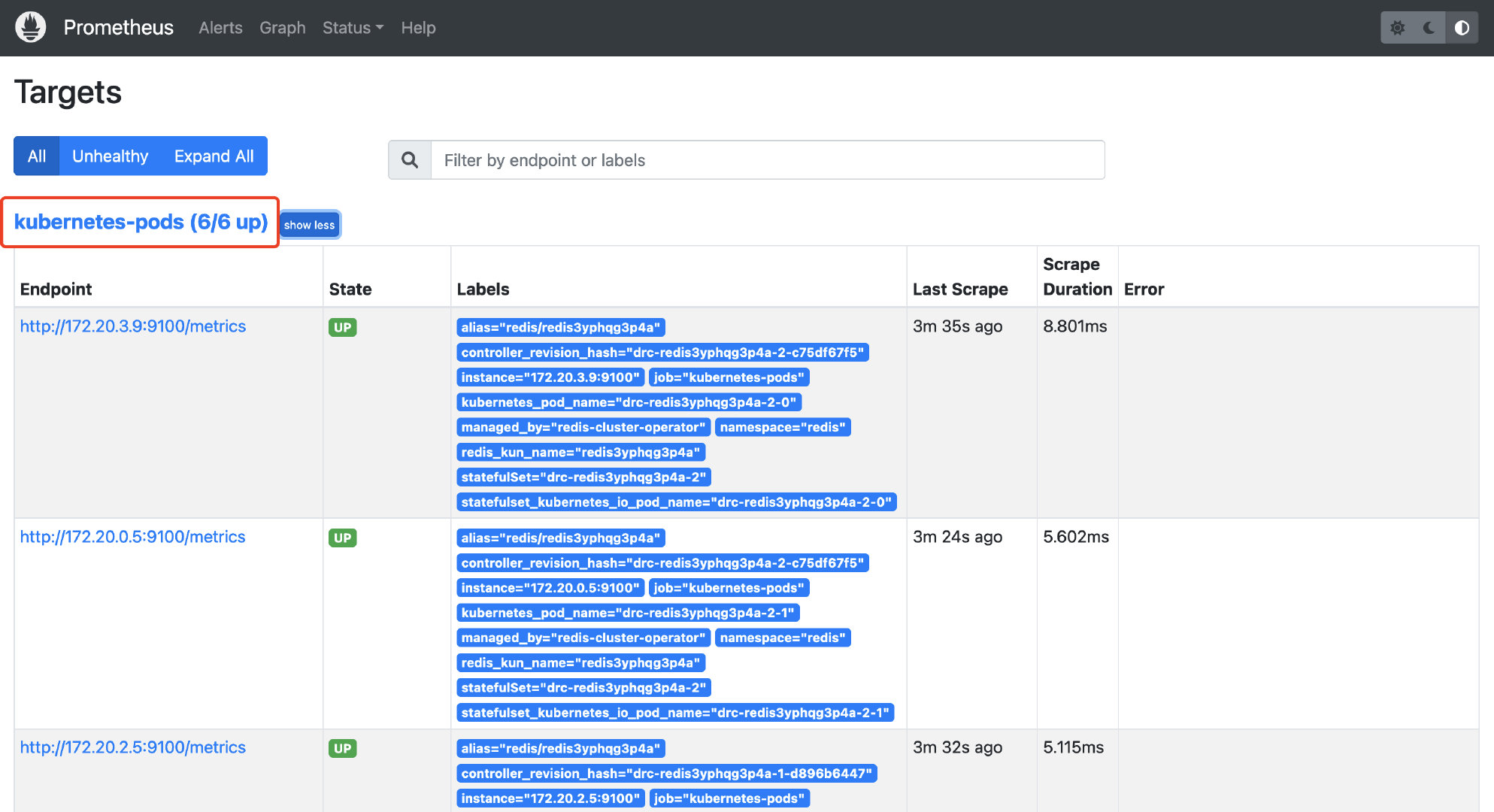
大功告成!

















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









