




作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。

我们上一章介绍了Docker基本情况,目前在规模较大的容器集群基本都是Kubernetes,但是Kubernetes涉及的东西和概念确实是太多了,而且随着版本迭代功能在还增加,笔者有些功能也确实没用过,所以只能按照我自己的理解来讲解。
我们上一些小节介绍Pormetheus的安装,已经可以通过查看监控项目&报警等信息,但是这些监控信息是怎么来的,又有哪些监控指标,今天我们这小节就来介绍这些信息。
1.监控项目
#他就通CRD 注册的资源kubectl get servicemonitor -n monitoring
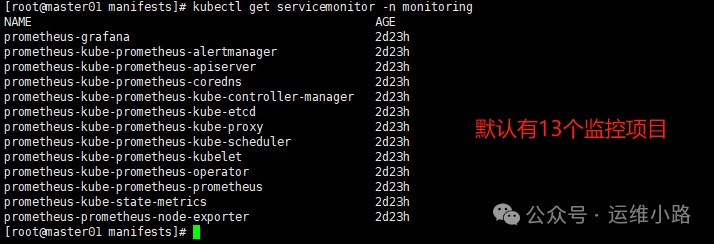
但是在默认的 Prometheus Targets 页面只有12个选项,其中prometheus-grafana这个监控项目未自动监控,那是因为这个资源未添加对应的标签,给这个资源添加这个标签以后,就会进入监控项目,包括其他项目也可以通过添加标签进入监控。

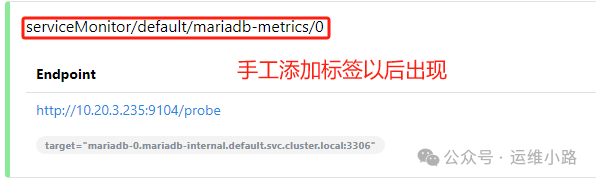
如果是第三方暴露mariadb-metrics,也可以通过添加这个标签进行Prometheus监控。
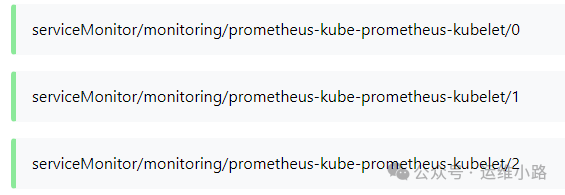
当然这里还有监控项目存在多个暴露地址的情况,比如下图的Kubelet。
这里就包括kubelet自身的监控,节点Pod的等监控。
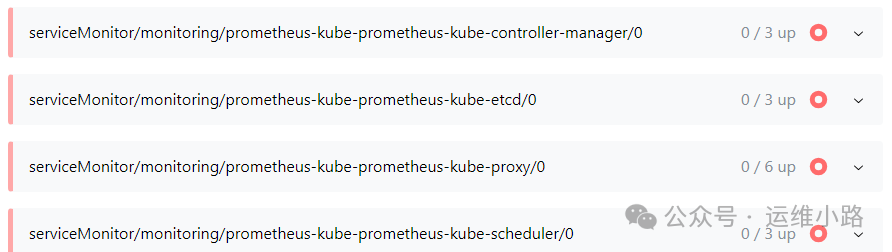
2.异常的监控项目
默认只有下面几个是异常状态,其中除了kube-proxy其他3个都是都是静态Pod,通过修改静态Pod的yaml文件即可。
#kube-proxy修改这个cm即可,然后把所有Pod重启。metricsBindAddress: "0.0.0.0"
3.监控项目介绍
这10多个监控项目,每个监控项目都有很多监控子项,下面就是关于每个监控项目的介绍:
3.1prometheus-grafana:监控grafana组件的健康状态。
3.2prometheus-kube-prometheus-alertmanager:监控告警组件的状态。
3.3prometheus-kube-prometheus-apiserver:监控 Kubernetes APIServer 的性能和健康状态。
3.4prometheus-kube-prometheus-coredns:监控 CoreDNS 的 DNS 解析性能。
3.5prometheus-kube-prometheus-kube-controller-manager:监控 Kubernetes 控制器管理器(Controller Manager)。
3.6prometheus-kube-prometheus-kube-etcd:监控 etcd 集群的健康状态和性能。
3.7prometheus-kube-prometheus-kube-proxy:监控 kube-proxy 的网络代理性能。
3.8prometheus-kube-prometheus-kube-scheduler:监控 Kubernetes 调度器(Scheduler)的性能。
3.9prometheus-kube-prometheus-kubelet:监控 kubelet 和节点资源及Pod状态。
3.10prometheus-kube-prometheus-operator:监控prometheus的opterator的状态。
3.11prometheus-kube-prometheus-prometheus:监控prometheus自己的监控。
3.12prometheus-kube-state-metrics:将 Kubernetes 资源状态(如 Deployment、Pod、Service)转换为 Prometheus 指标
3.13prometheus-prometheus-node-exporter:Node Exporter,收集节点级硬件和操作系统指标。
4.监控指标介绍
上面涉及到13个监控项目,每个监控项目下面都有很多指标,通过https方式暴露,我们可以通过访问https地址进行查看(客户端请求也需要带上证书才可以)。并且这里的监控指标和prometheus的查询的指标就可以进行重叠。如果监控其他项目也支持http方式监控,只是这里集成的云集都是https监控。
# 提取客户端证书
grep 'client-certificate-data' ~/.kube/config | awk '{print $2}' | base64 -d > client.crt
# 提取客户端私钥
grep 'client-key-data' ~/.kube/config | awk '{print $2}' | base64 -d > client.key
# 提取集群 CA 证书
grep 'certificate-authority-data' ~/.kube/config | awk '{print $2}' | base64 -d > ca.crt
#当然也可以获取其他监控指标,这里以kubelet指标为例
curl --cert client.crt --key client.key --cacert ca.crt -k \
"https://<节点IP>:10250/metrics/"
然后这里的指标可以和prom查询的指标重合。
后面的数据类型代表了不同类型的指标。
这样我们通过Prometheus完成了监控来源(监控项目)和监控指标的汇聚,这样我们的Pormetheus里面就会存在很多监控指标,我们可以基于这些指标做告警和图表展示。

运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。

















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









