




第二章 RAG第一部分:索引您的数据
在前一章中,您了解了使用LangChain创建大型语言模型应用程序的重要构建块。您还构建了一个简单的AI聊天机器人,由发送给模型的提示和模型生成的输出组成。但是这个简单的聊天机器人有很大的局限性。
如果您的用例需要模型没有训练的知识,该怎么办?例如,假设您想使用AI询问有关公司的问题,但信息包含在私有PDF或其他类型的文档中。虽然我们已经看到模型提供者丰富了他们的训练数据集,以包括越来越多的世界公共信息(无论它以何种格式存储),但大型语言模型的知识语料库仍然存在两个主要限制:
-
私人数据
根据定义,不公开的信息不包括在大型语言模型的训练数据中。
-
时事
训练大型语言模型是一个昂贵且耗时的过程,可能会持续数年,而数据收集只是第一步。这导致了所谓的知识截止日期,即大型语言模型对现实世界事件一无所知的日期;通常这是训练集完成的日期。这可以是过去几个月到几年的任何时间,取决于所讨论的模型。
在任何一种情况下,模型都很可能产生幻觉(发现误导或错误的信息),并以不准确的信息作出反应。调整提示也不能解决问题,因为它依赖于模型当前的知识。
目标:为大型语言模型选择相关背景
如果大型语言模型用例所需的唯一私有/当前数据是一到两页的文本,那么本章将会短得多:要使大型语言模型获得该信息,您所需要的就是在发送给模型的每个提示中包含整个文本。
向大型语言模型提供数据的挑战首先是数量问题。你发送给大型语言模型的每一个提示都包含了太多的信息。每次调用模型时,您将包含大量文本集合中的哪个小子集?或者换句话说,您如何(在模型的帮助下)选择与每个问题最相关的文本?
在本章和下一章中,你将学习如何通过两个步骤来克服这个挑战:
-
索引您的文档,也就是说,以一种您的应用程序可以轻松地为每个问题找到最相关的方式对它们进行预处理
-
从索引中检索这些外部数据,并将其用作大型语言模型的上下文,以便根据您的数据生成准确的输出
这一章的重点是索引,这是第一步,它涉及到将你的文档预处理成一种可以被大型语言模型理解和搜索的格式。这种技术称为检索增强生成(RAG)。但在我们开始之前,让我们讨论一下为什么您的文档需要预处理。
假设您想使用大型语言模型来分析特斯拉2022年年报中的财务业绩和风险,该报告以PDF格式存储。你的目标是能够提出这样的问题:“特斯拉在2022年面临哪些主要风险?”,并根据文档的风险因素部分的上下文获得类似人类的回应。
为了实现这一目标,你需要采取四个关键步骤(如图2-1所示):
-
从文档中提取文本。
-
将文本分成易于管理的小块。
-
将文本转换成计算机能理解的数字。
-
将文本的这些数字表示形式存储在某个地方,以便轻松快速地检索文档的相关部分以回答给定的问题。
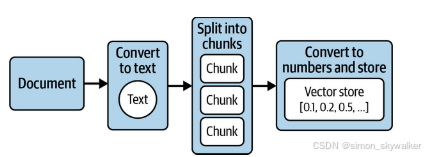
图2-1预处理文档以供大型语言模型使用的四个关键步骤
图2-1说明了文档的预处理和转换流程,这个过程称为摄取。摄取就是将文档转换为计算机可以理解和分析的数字,并将其存储在特殊类型的数据库中以便有效检索的过程。这些数字在形式上被称为嵌入,这种特殊类型的数据库被称为向量存储。让我们从一些比llm驱动的嵌入更简单的东西开始,更仔细地看看什么是嵌入以及它们为什么重要。
嵌入:将文本转换为数字
嵌入指的是将文本表示为一个(长)数字序列。这是一种有损表示——也就是说,您无法从这些数字序列中恢复原始文本,因此通常要同时存储原始文本和这种数字表示。
那么,为什么要麻烦呢?因为你获得了与数字打交道所带来的灵活性和力量:你可以用单词做数学!让我们看看为什么这是令人兴奋的。
在大型语言模型之前的嵌入
早在大型语言模型之前,计算机科学家就在使用嵌入——例如,在网站上启用全文搜索功能,或将电子邮件分类为垃圾邮件。让我们来看一个例子:
-
以这三个句子为例:
-
多么晴朗的一天。
-
今天的天空真明亮。
-
我已经好几个星期没见过晴天了。
-
-
列出其中所有独特的单词:what, a, sunny, day, such, bright等等。
-
对于每个句子,一个单词一个单词地进行分析,如果没有出现,则将数字赋值为0,如果在句子中出现一次,则赋值为1,如果出现两次,则赋值为2,以此类推。
结果如表2-1所示。
表2-1 三个句子的词嵌入
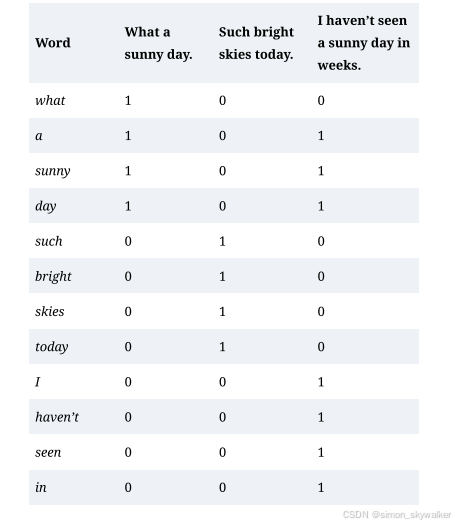

在这个模型中,我几周没有看到一个晴天的嵌入是数字序列0 1 1 1 1 0 0 0 0 1 1 1 1 1 1。这被称为词袋模型,这些嵌入也被称为稀疏嵌入(或稀疏向量-向量是数字序列的另一个词),因为很多数字将为0。大多数英语句子只使用现有英语单词的一小部分。
您可以成功地将此模型用于:
-
关键词搜索
您可以找到哪些文档包含一个或多个给定的单词
-
文件分类
您可以计算先前标记为电子邮件垃圾邮件或非垃圾邮件的示例集合的嵌入,将它们取平均值,并获得每个类(垃圾邮件或非垃圾邮件)的平均单词频率。然后,将每个新文档与这些平均值进行比较,并进行相应的分类。
这里的限制是,模型没有意义意识,只有实际使用的单词。例如,sunny day和bright skies的嵌入看起来非常不同。事实上,它们没有共同的词汇,尽管我们知道它们有相似的意思。或者,在电子邮件分类问题中,潜在的垃圾邮件发送者可以通过用同义词替换常见的“垃圾邮件词”来欺骗过滤器。
在下一节中,我们将看到语义嵌入如何通过使用数字来表示文本的含义而不是文本中找到的确切单词来解决这一限制。
基于大模型的嵌入
我们将跳过其间的所有机器学习开发,直接跳到基于大模型的嵌入。要知道,从上一节中概述的简单方法到本文中描述的复杂方法是一个逐渐演变的过程。
您可以将嵌入模型视为大型语言模型训练过程的一个分支。如果您还记得前言中的内容,大型语言模型训练过程(从大量书面文本中学习)使大型语言模型能够以最合适的延续(输出)完成提示(或输入)。这种能力源于对周围文本上下文中单词和句子含义的理解,并从训练文本中如何将单词一起使用中学习。这种对提示符含义(或语义)的理解可以提取为输入文本的数字表示(或嵌入),也可以直接用于一些非常有趣的用例。
在实践中,大多数嵌入模型都是为此目的单独训练的,遵循与大型语言模型类似的体系结构和训练过程,因为这样更有效,并产生更高质量的嵌入。
因此,嵌入模型是一种算法,它接受一段文本并输出其含义的数字表示形式——从技术上讲,是一长串浮点(十进制)数,通常在100到2000个数字或维度之间。这些也被称为密集嵌入,与前一节的稀疏嵌入相反,因为这里的所有维度通常都不等于0。
提示
不同的模型产生不同数量和大小的列表。所有这些都是特定于每个模型的;也就是说,即使列表的大小匹配,您也不能比较来自不同模型的嵌入。应该始终避免组合来自不同模型的嵌入。
解释语义嵌入
想想这三个词:狮子、宠物和狗。直观地看,哪一对单词乍一看具有相似的特征?最明显的答案是宠物和狗。但计算机没有能力利用这种直觉或对英语语言的细微理解。为了让计算机区分狮子、宠物或狗,你需要能够将它们翻译成计算机的语言,也就是数字。
图2-2说明了将每个单词转换为保留其含义的假设数字表示。
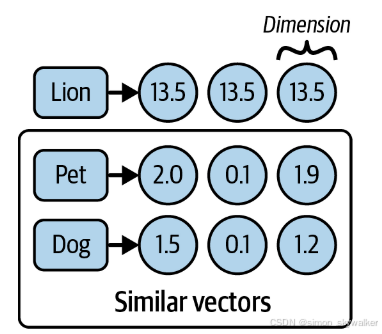
图2-2 词的语义表示
图2-2显示了每个单词及其相应的语义嵌入。请注意,数字本身没有特别的含义,但是两个含义相近的单词(或句子)的数字序列应该比不相关的单词的数字序列更接近。正如您所看到的,每个数字都是一个浮点值,每个数字都代表一个语义维度。让我们看看我们说的更近是什么意思:
如果我们在三维空间中绘制这些向量,它看起来像图2-3。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1326
1326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









