




百度2018年出品,霸榜wider face一段时间,性能小怪兽。
对于遮挡、小、模糊的人脸,仅仅靠人脸那点信息较为判别那是人的脸,得借助头啊,上半身这些上下文信息来辅助判别才能较好判定那些很难看出来的人脸。这就是本文作者提出的pyramidanchors的核心思想,如下图所示,借助人头,上半身能较好判别人脸。

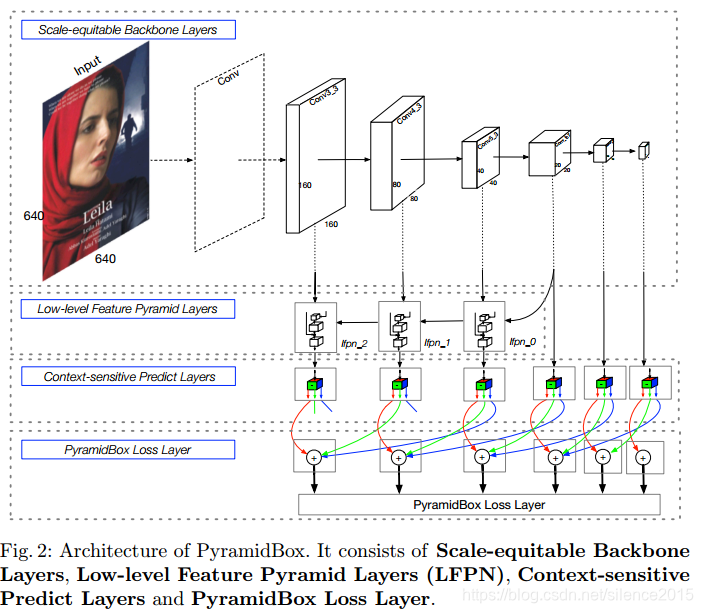
作者主要有以下贡献:
-
提出一个FPN的改进版,LFPN。作者分析较高层的特征可能不适合辅助低层特征检测小人脸,主要因为感受野不匹配的问题,而在中间开始融合特征效果更好,这就是LFPN。
-
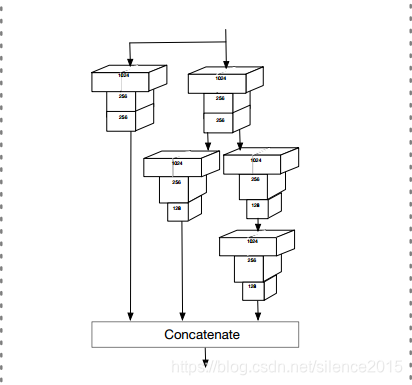
上下文感知模块。作者融合SSH和DSSD模块,在深度和宽度上同时发力增强预测能力。
-
max-in-out,max out的改进版,不光对负样本玩多个预测,也对正样本来。在浅层,预测负样本多些,而高层预测正样本多些。在浅层想减少误检,在高层减少漏检?
-
pyramidanchors(简称PA)
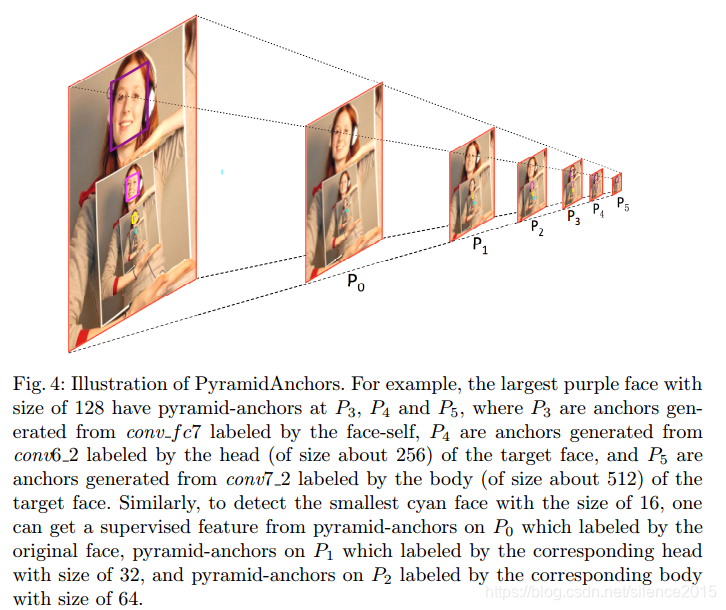
针对每一个人脸,PA都生成三个target anchor,分别对应预测人脸、人头和人身。当然这里面有个先验假设:所有人的人脸、人头和人身比例都差不多的,他们特征都类似。作者公式写的比较正规,对着上图来看啊,最大的人脸在P3,P4,P5分别有对应的PA,分别预测人脸,人头和人身,尺度依次翻倍。对应到网络结构图,可以看出来conv3_3只预测face,而conv4_3负责预测conv3_3层的head,而conv5_3负责预测conv3_3层的body(红线face,绿线head,蓝线body)。
- data-anchor-sampling策略。训练策略作者也花了不少心思,考虑到小的那些人脸不是难预测嘛,那就多搞一些来训练。怎么搞呢?大脸缩小变小脸。假设有某人脸大小为140,依据大小找到最匹配的anchor大小为128,然后在更小的anchor里随机确定一个尺度的anchor(假设32),那么原图的缩放因子即32/140=0.23。缩小原图,然后随机裁剪出640大小的patch去训练模型,这就叫基于数据和anchor的采样策略,简称DAS。

















 5076
5076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









