



一、概述
在前面几篇文章,介绍了RAGflow Agent,实现了text-to-sql功能,以及RAGflow Agent api接口调用。
文章链接如下:
https://www.cnblogs.com/xiao987334176/p/18816166
https://www.cnblogs.com/xiao987334176/p/18816547
二、dify对接
dify对接很简单,直接调用RAGflow Agent api接口,就可以了。
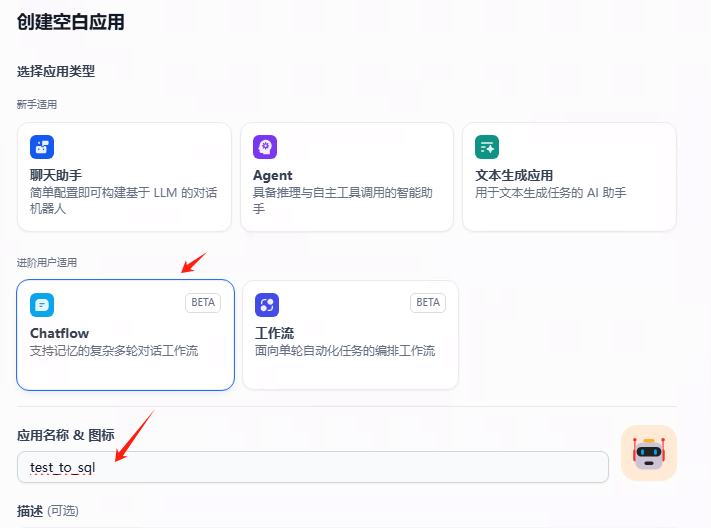
新建工作流
新建一个工作流,选择chatflow
修改流程,效果如下:
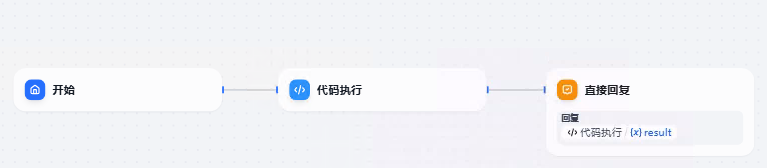
重点看代码执行
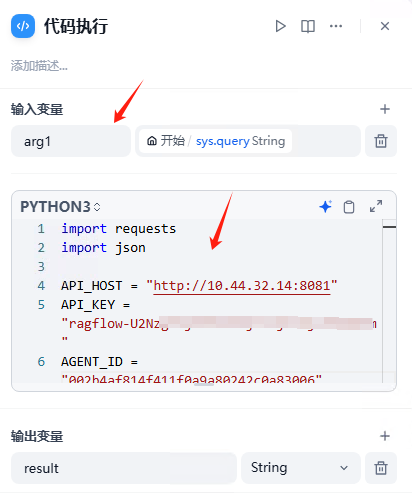
完整代码如下:
import requests
import json
API_HOST = "http://10.44.32.14:8081"
API_KEY = "ragflow-U2N***"
AGENT_ID = "002b4af814f411f0a9a80242c0a83006"
question = ""
# 请求url
url = API_HOST + "/api/v1/agents/" + AGENT_ID + "/completions"
# print(url)
# 自定义请求头
headers = {
"Authorization": "Bearer %s" % API_KEY,
"Content-Type": "application/json",
}
class AgentStreamResponse:
def __init__(self, arg1):
self.arg1 = arg1
def get_session_id(self):
"""
获取会话 ID
"""
data = {"id": AGENT_ID}
response = requests.post(url, data=data, headers=headers)
try:
line_list = []
with requests.post(
url, json=data, headers=headers, stream=True, timeout=30
) as response:
if response.status_code == 200:
for line in response.iter_lines():
if line: # 过滤掉空行
# print(line.decode("utf-8"))
line_list.append(line.decode("utf-8"))
else:
print(f"请求失败,状态码: {response.status_code}")
return False
# print("line_list",line_list)
first_line = line_list[0]
# 提取data内容
line_row = first_line.split("data:")[1]
# json解析
line_dict = json.loads(line_row)
# 获取session_id
session_id = line_dict["data"]["session_id"]
return session_id
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
return False
def get_stream_data(self):
"""
获取流式数据
"""
try:
session_id = self.get_session_id()
data = {
"id": AGENT_ID,
"question": self.arg1,
"stream": "true",
"session_id": session_id,
}
with requests.post(
url, json=data, headers=headers, stream=True, timeout=30
) as response:
if response.status_code == 200:
list_data = []
for line in response.iter_lines():
if line: # 过滤掉空行
print(line.decode("utf-8"))
list_data.append(line.decode("utf-8"))
last_data = list_data[-2]
# 提取data内容
line_row = last_data.split("data:")[1]
# json解析
line_dict = json.loads(line_row)
# 获取session_id
answer = line_dict["data"]["answer"]
return answer
# return list_data[-2]
else:
print(f"请求失败,状态码: {response.status_code}")
return False
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
return False
def main(arg1: str) -> dict:
agent_stream_response = AgentStreamResponse(arg1)
result = agent_stream_response.get_stream_data()
return {
"result": result,
}
注意修改变量:API_HOST ,API_KEY,AGENT_ID
发布应用,效果如下:
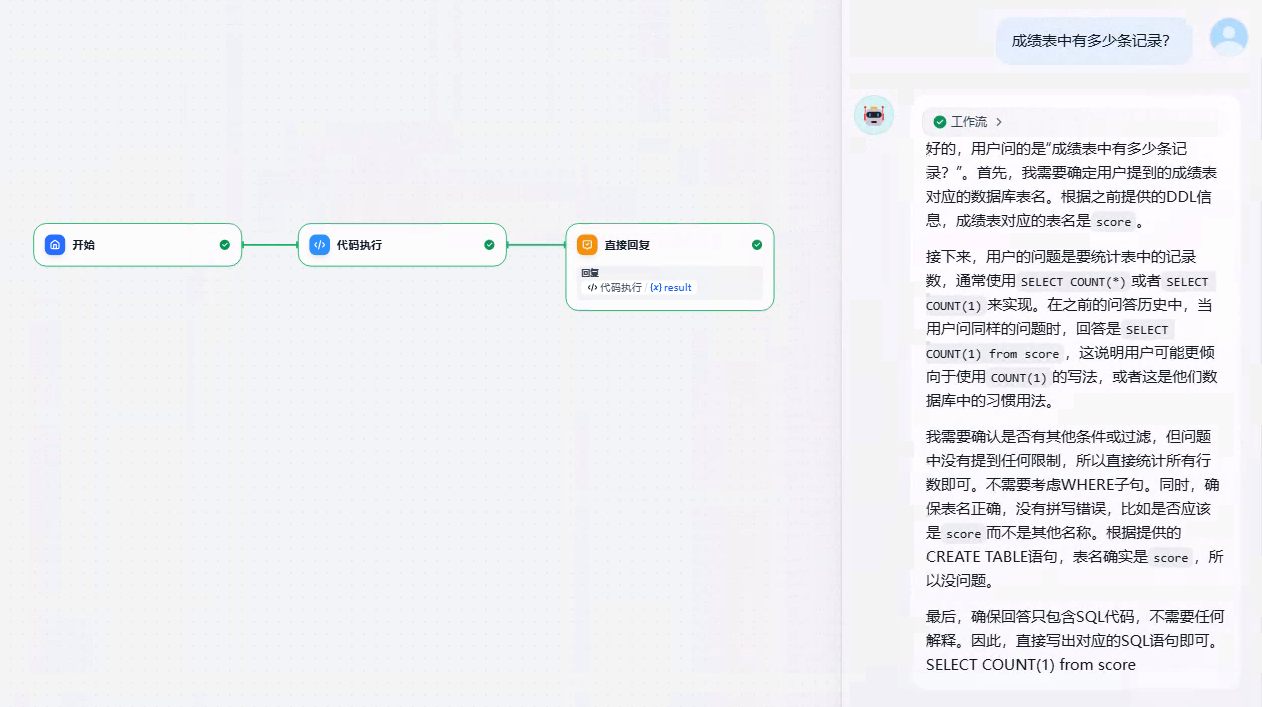
执行代码,会出现超时:Run failed: error: timeout

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









