







url: https://www.bilibili.com/video/BV1du17YfE5G?spm_id_from=333.788.videopod.sections&vd_source=7a1a0bc74158c6993c7355c5490fc600&p=3
现代多核处理器2
如上堂课,超线程技术通过储存不同线程的 execution context,能够在一个线程等待 IO 的时候低成本切换到另一个线程去执行。
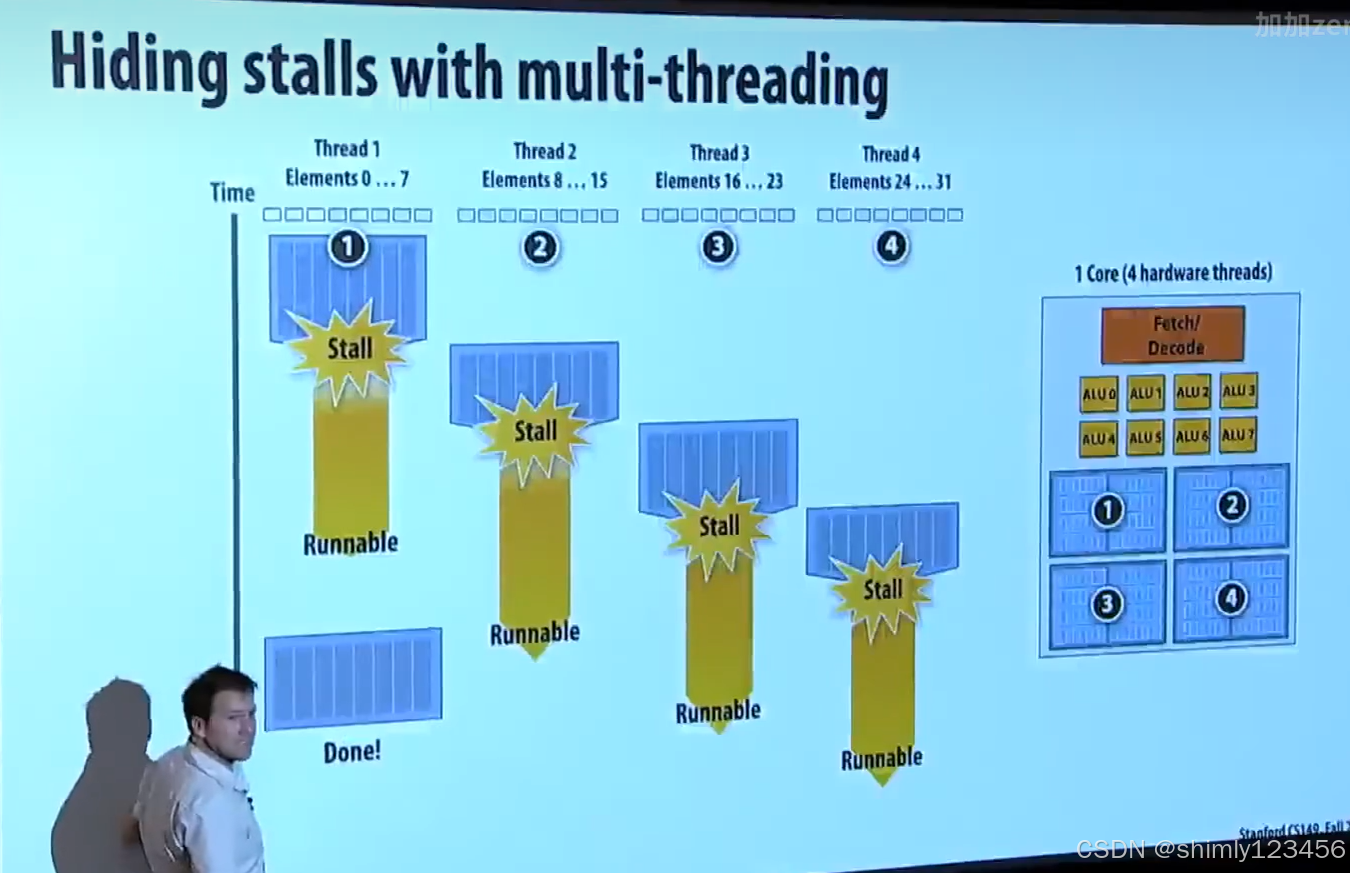
当然,超线程技术有两个成本:
1.CPU内需要有存储空间来储存不同线程的 execution context
2.虽然总体overhead降低了,但对于每个线程各自来说overhead增加了
可以把CPU内的 execution context 分为许多的小份来获得更多的超线程,也可以分为少量的大分来获得更大的 “cache”
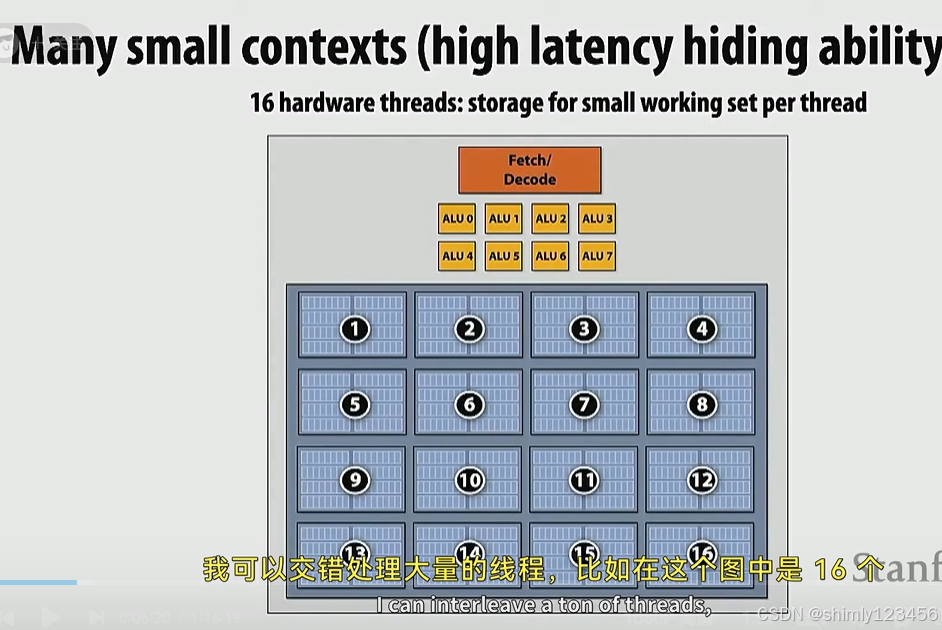
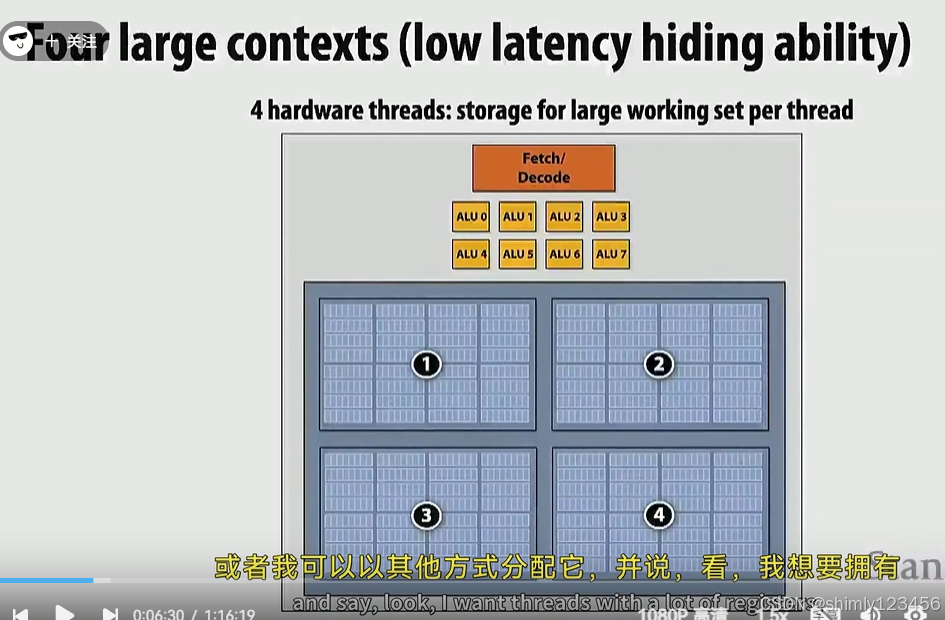
接下来看一个例子:
但计算时间为 3 个周期,IO延迟为12个周期时,一个仅具备超线程的单核处理器需要 5 个线程才能达到 100% 的 CPU 利用率。
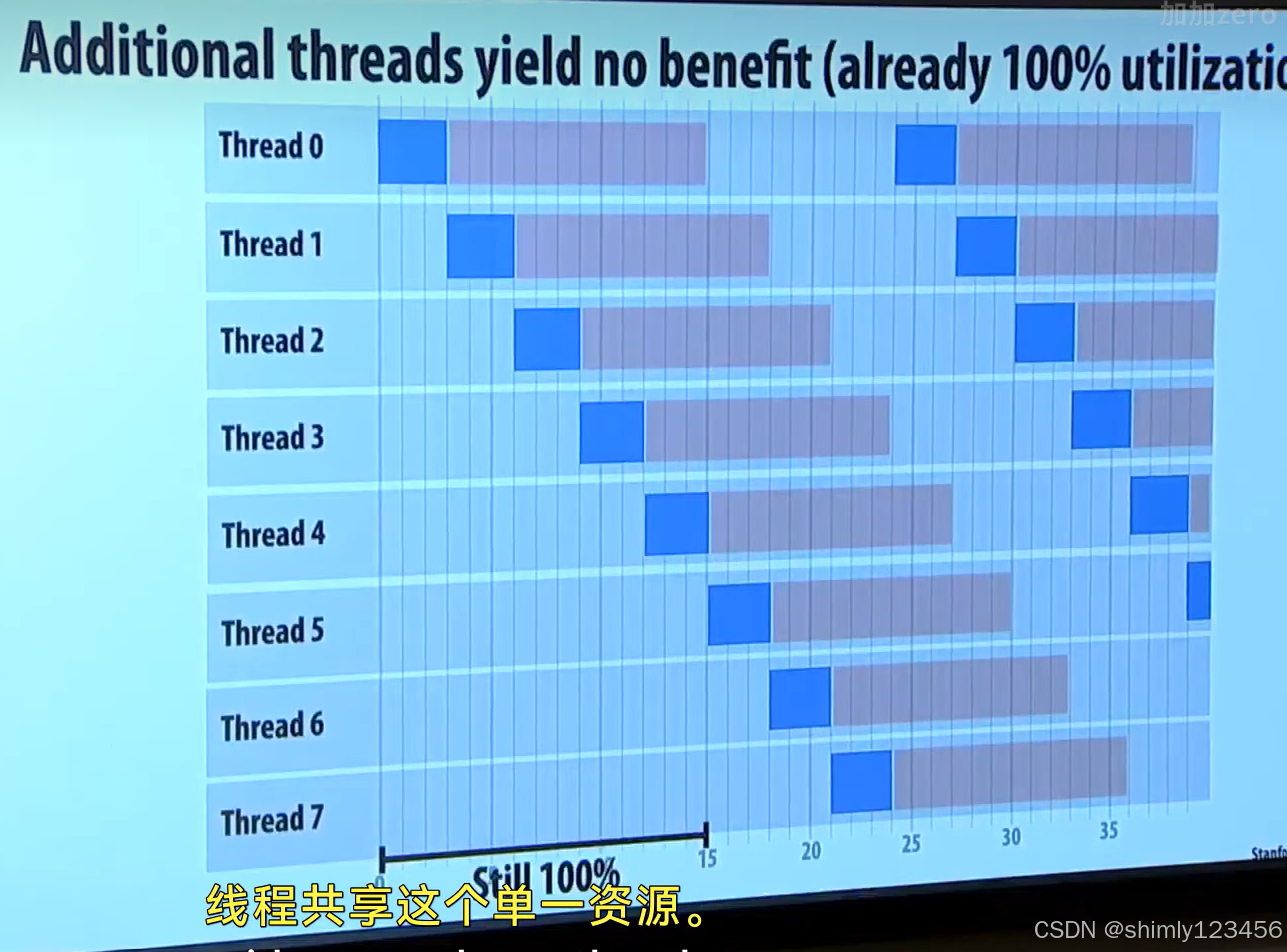
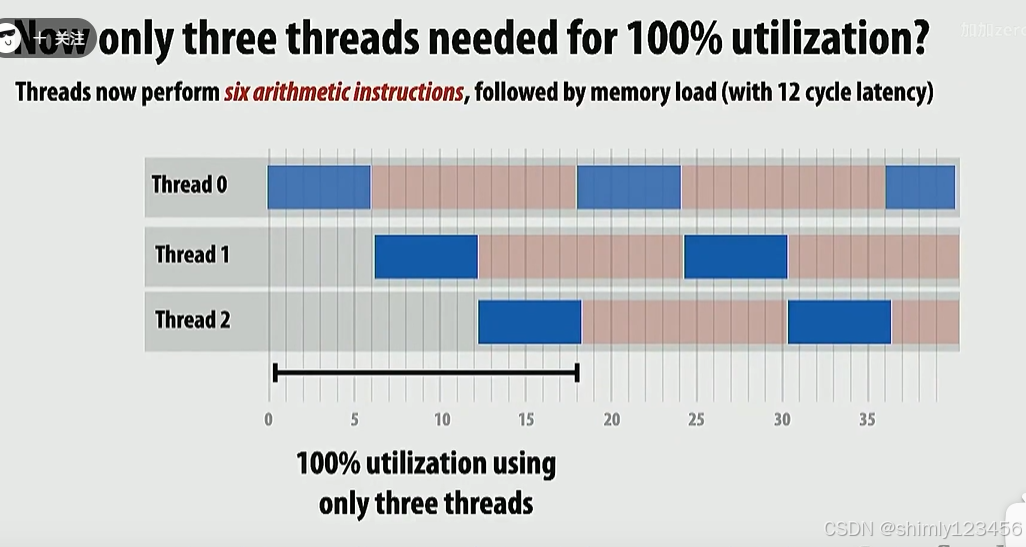
通过改变程序,把计算时间延长到 5个周期,IO延迟缩短为10个周期。
此时,只需要 3 个线程就能让 CPU 利用率达到 100%。
可见,对于超线程技术来说,程序的计算overhead 和 IO overhead 的比例很关键。
缩短IO访问时间的方式:cache
一个现实的例子:
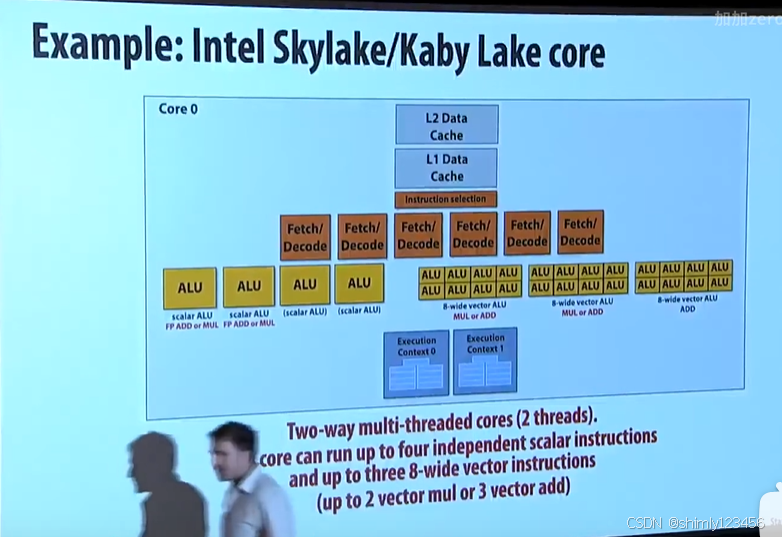
超标量+SIMD+超线程
一个能很好利用现代并行处理器的程序有以下特点:
1.有足够的可并行任务去使用所有可用的执行单元
2.这些并行任务应该拥有相同的执行序列
3.并行的任务线程数应该比 ALU数量更多,这样在发生 IO(比如内存IO)时,处理器才能切换到其它线程上来隐藏 stalls

29min ~ 34min 回顾了之前所学的知识,并把它们和实际案例结合讲解
如下,最简单单核处理器,一次执行一个指令

超标量core,一次执行两个无依赖的指令

SIMD core,可执行
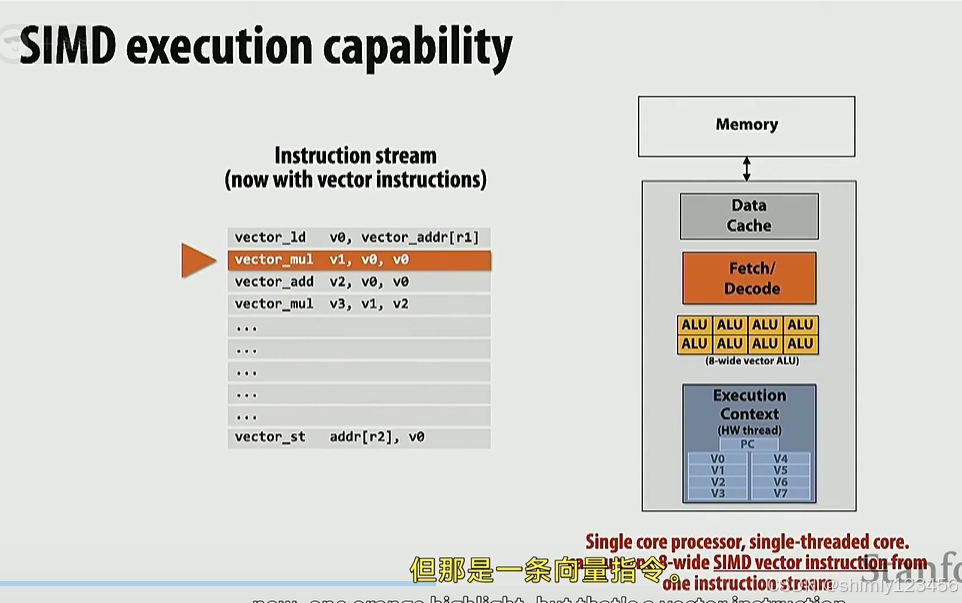
异构处理器,标量+SIMD,可以同时执行一个标量计算和一个SIMD指令,只要这两个指令之间没有依赖。

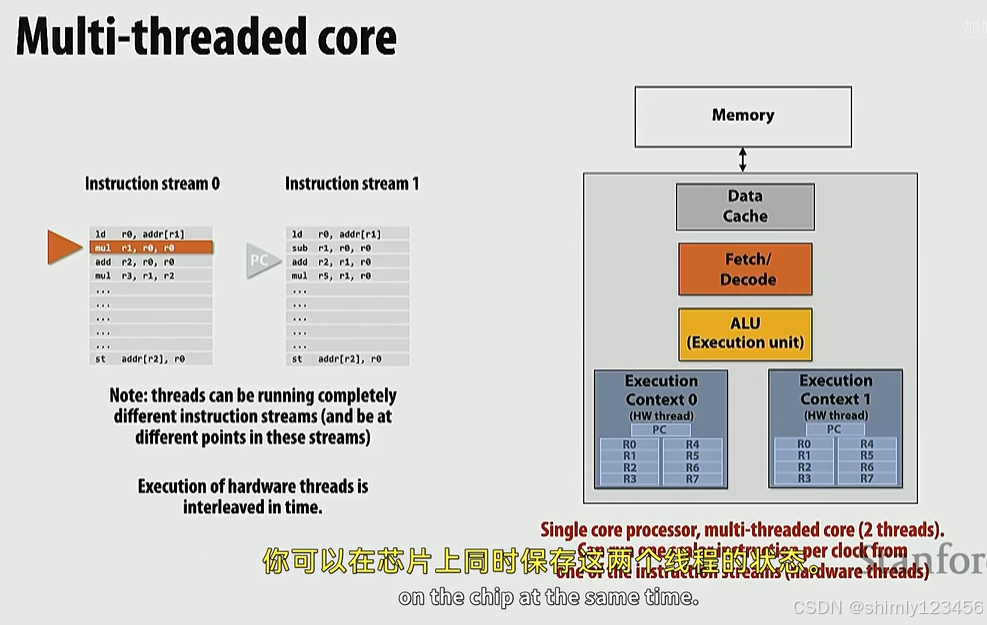
超线程核,可以低成本地在两个线程之间切换
如下是超线程+超标量+SIMD+异构处理器
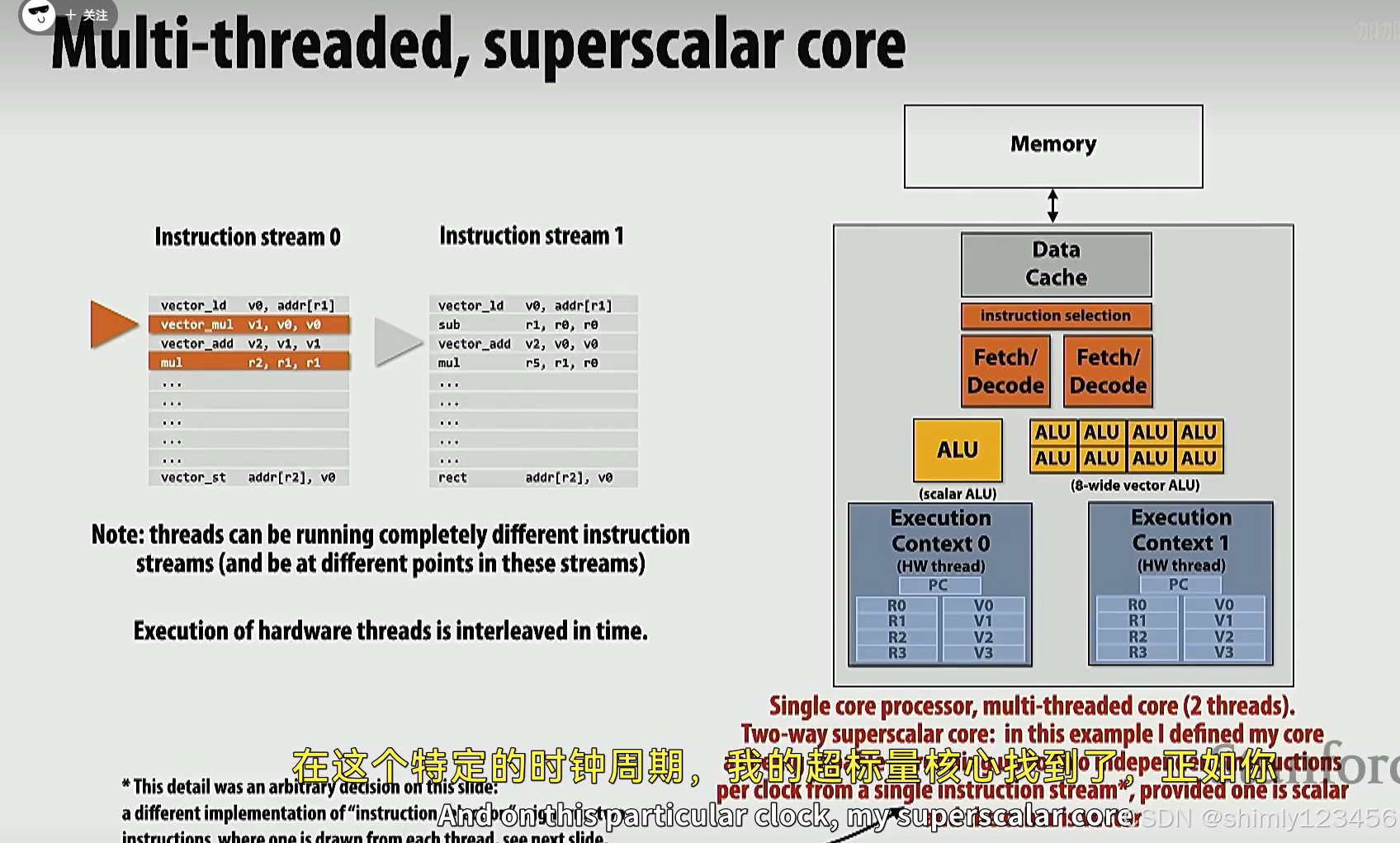
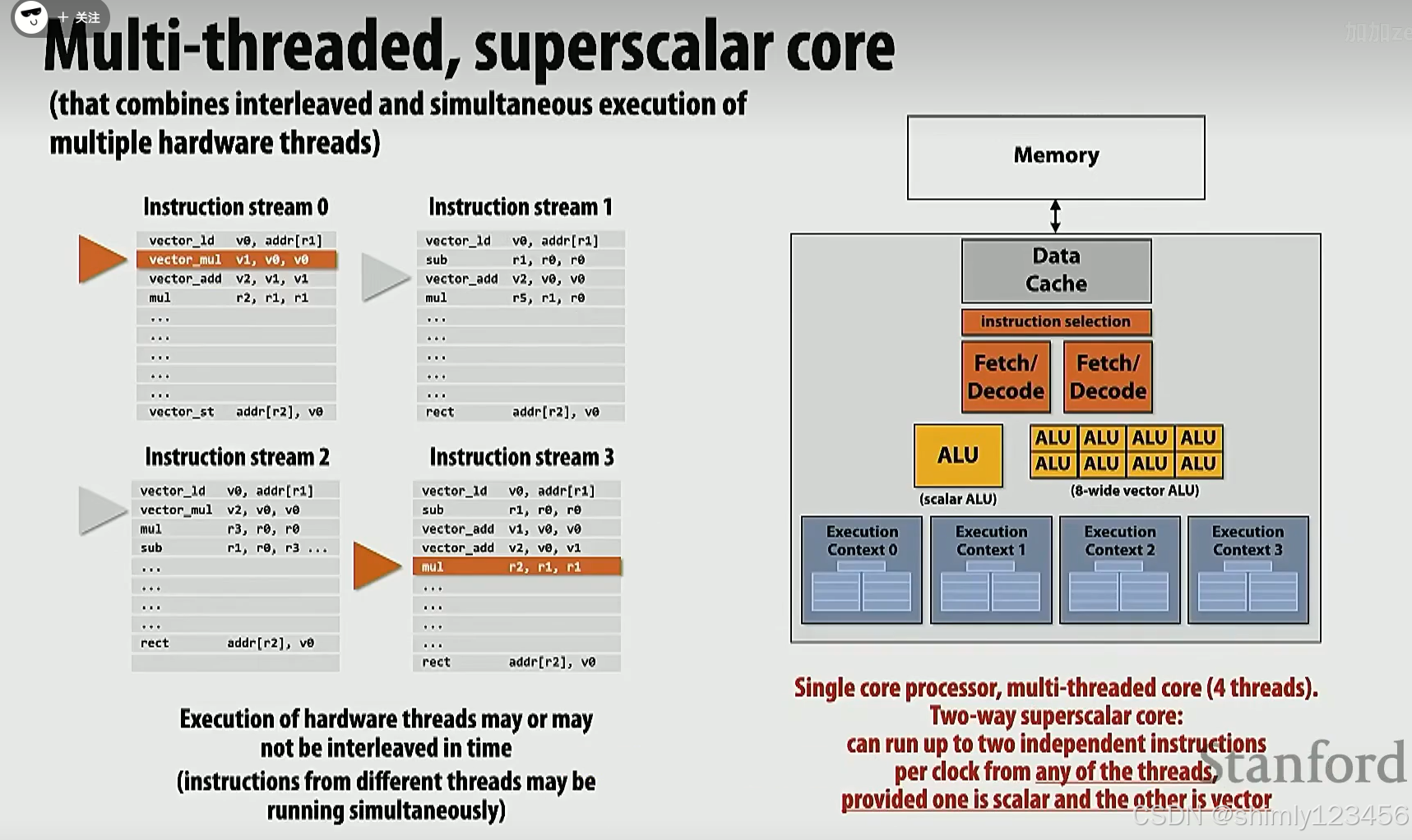
能够同时执行两个 thread 的单核处理器
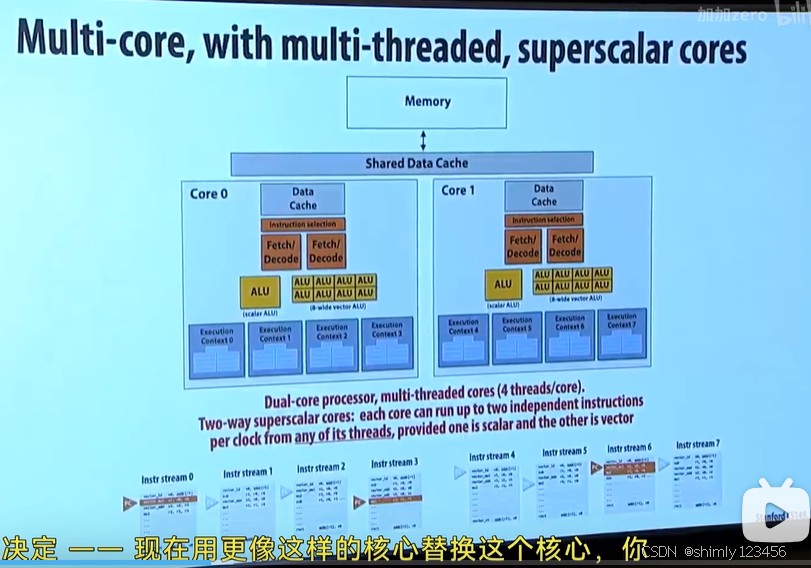
多核+SIMD+异构+超标量+超线程处理器
需注意,0,1,2,3 这四个线程可能会同时有两个被执行,但绝不可能四个同时被执行
GPU 的原理和CPU稍有不同
英伟达GPU的原理是,是使用 SIMD ALUs 去执行 标量指令。
当所有线程的 PC 一致时,GPU 会使用 SIMD ALUs 同时执行所有线程。
如下图,线程6的 PC 和其它线程不一致,此时 GPU 会忽略掉线程6的执行。
所以,GPU 是使用 SIMD ALUs 执行标量指令,从而达到和 CPU 执行矢量指令相同的效果。

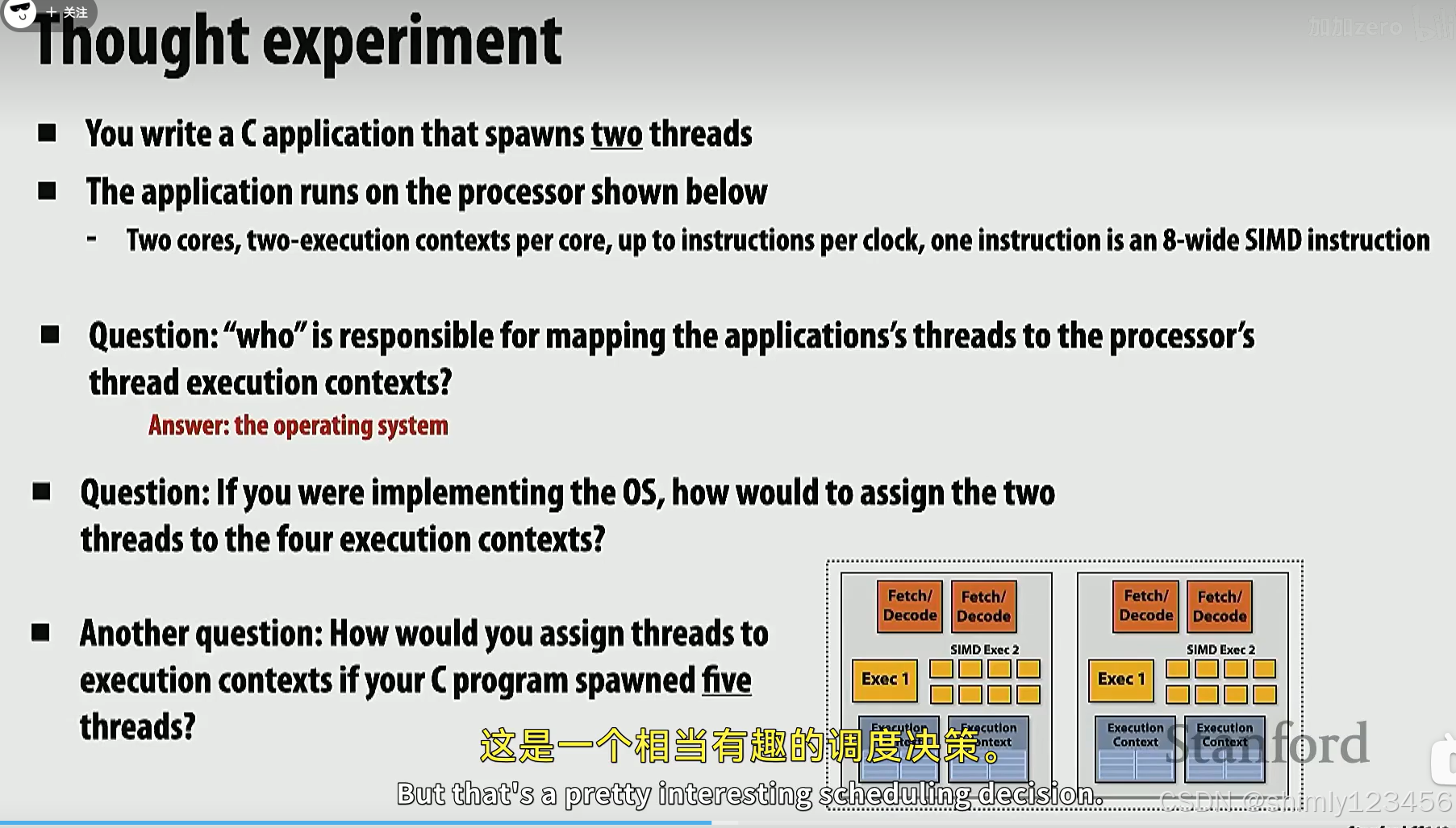
操作系统负责把应用程序的线程分配给各个执行单元
做一个思想实验说明内存IO是并行计算的主要瓶颈 ------------------ start
如下图是一个很容易并行的程序,因为它的计算向量化了,可以轻易用 SIMD 指令加速

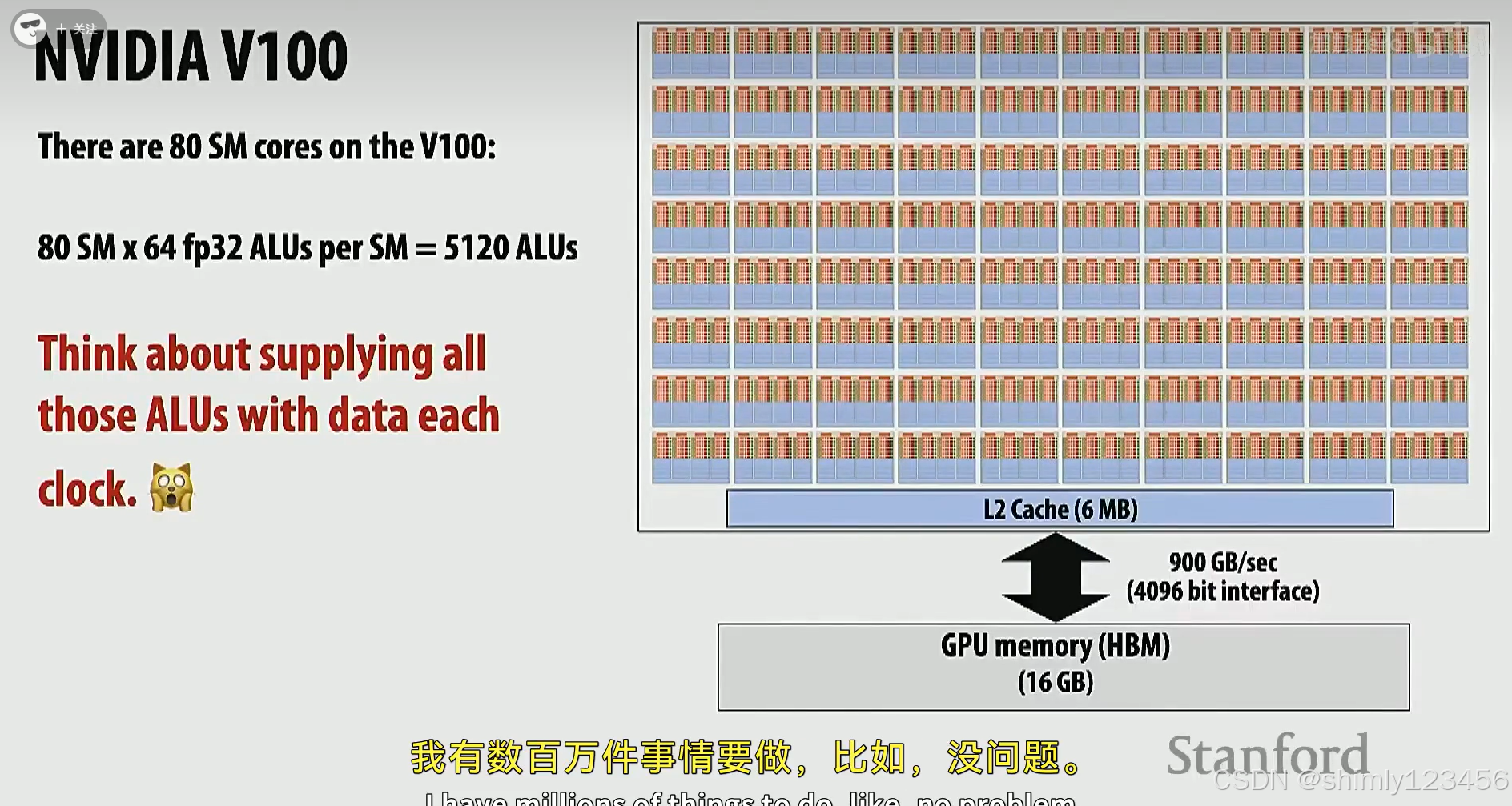
下面是英伟达 V100 GPU,拥有总共 5120个 ALUs,也就是理论上一次能做 5120 宽度计算。
然而,要达到理论上的计算速度,需要大量数据被加载到 GPU 的 内存和 cache 上。
这里补充点知识:
- 流水线结果的整体速率取决于流水线结构中最慢的那个结构
- 内存的延迟 latency: 数据从内存到执行单元的时间
- 内存的带宽 bandwidth: 类似 Throughput,每秒有多少数据到达计算单元
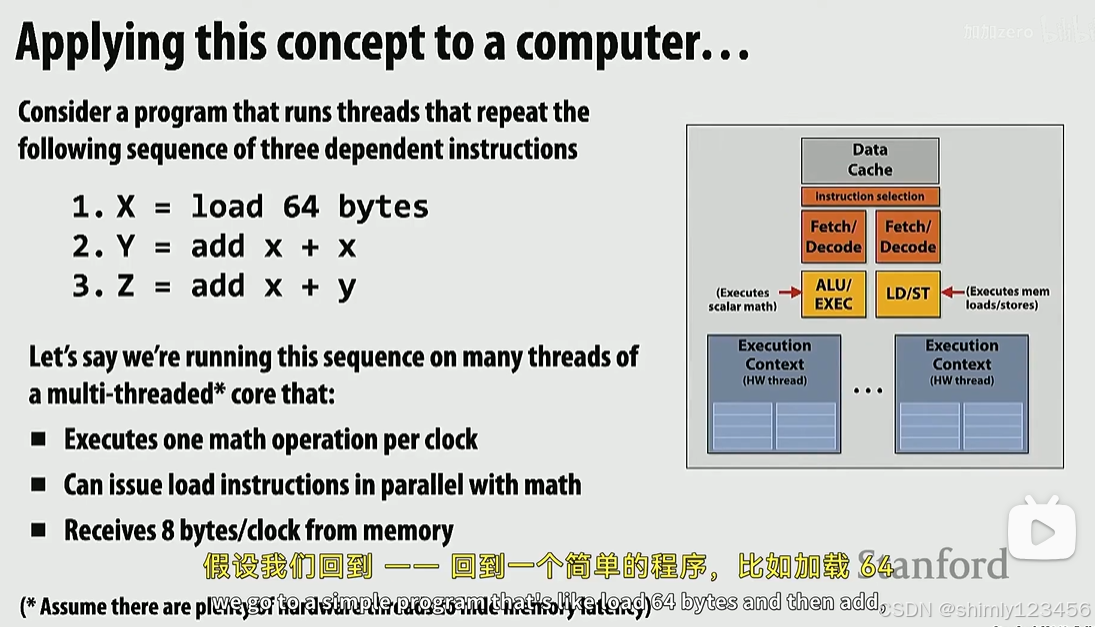
让我们考虑一个案例,一个仅有一个 ALU 和一个 MEM 单元的处理器,如下:
它要执行重复的 ADD, ADD, LOAD 指令序列
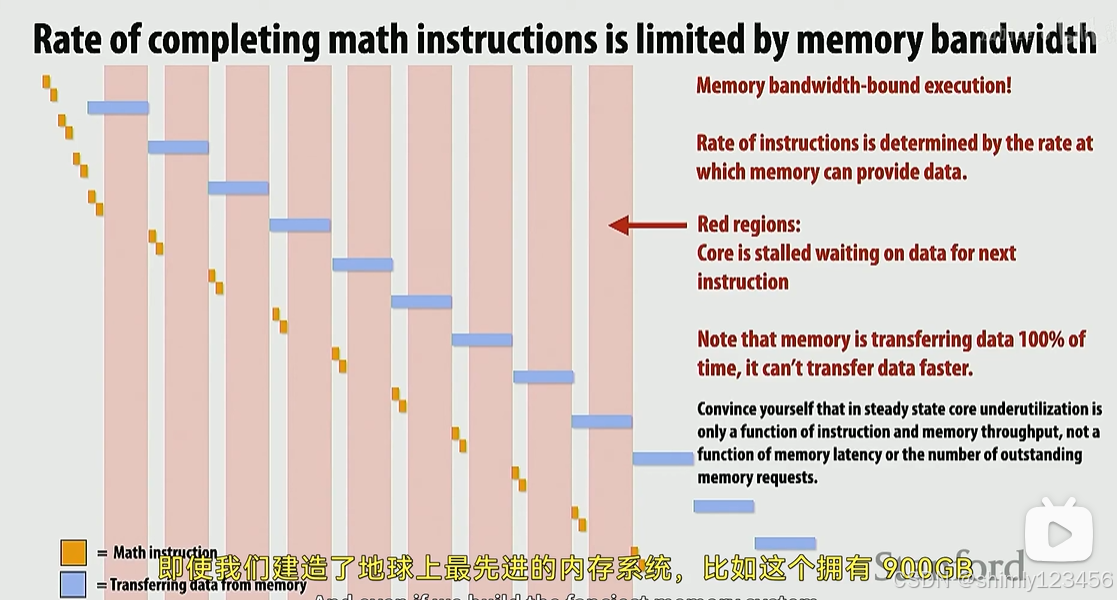
那么,在执行完一开始的几个 ADD, ADD, LOAD 序列后,LOAD 指令会塞满内存控制器的一个指令 buffer,随后内存会一直全速加载内存,而CPU则必须等待内存被加载进寄存器才能继续运算。

在上面的例子中,CPU利用率非常低,如下,红色的部分就是 core 等待内存IO的时间
回到英伟达GPU V100 的案例中,5120 个 ALUs 可以每秒做大约 100TB 的运算。
然而,世界上目前最先进的内存系统仅有约 900GB/s,也就是 1TB/s 的带宽

也就是说,在 GPU 和内存都全速执行的时候,英伟达 GPU 仅有不到 1% 的利用率。
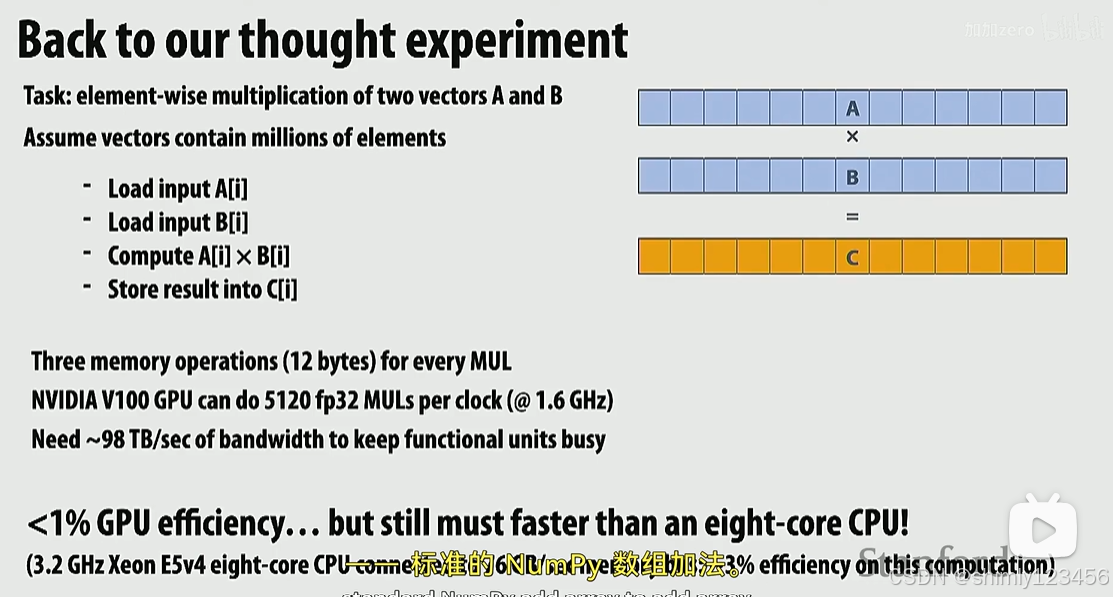
注意,上述案例与 cache 无关,因为 cache 只有当同一个数据被重复使用的时候才有用,上述案例里每次 LOAD 指令加载的都是不同的数据。
此时,只有改变我们的代码/程序,或者等待新的内存系统出现才有用。
代码/程序的 计算/访存 指令比例非常重要!
幸运的是,现实中,英伟达GPU V100 执行的指令序列通常不是 ADD ADD LOAD 这种序列。
做一个思想实验说明内存IO是并行计算的主要瓶颈 ------------------ end
ISPC 编程抽象
感觉这玩意儿不如 openMP

如图,是一个原始程序:
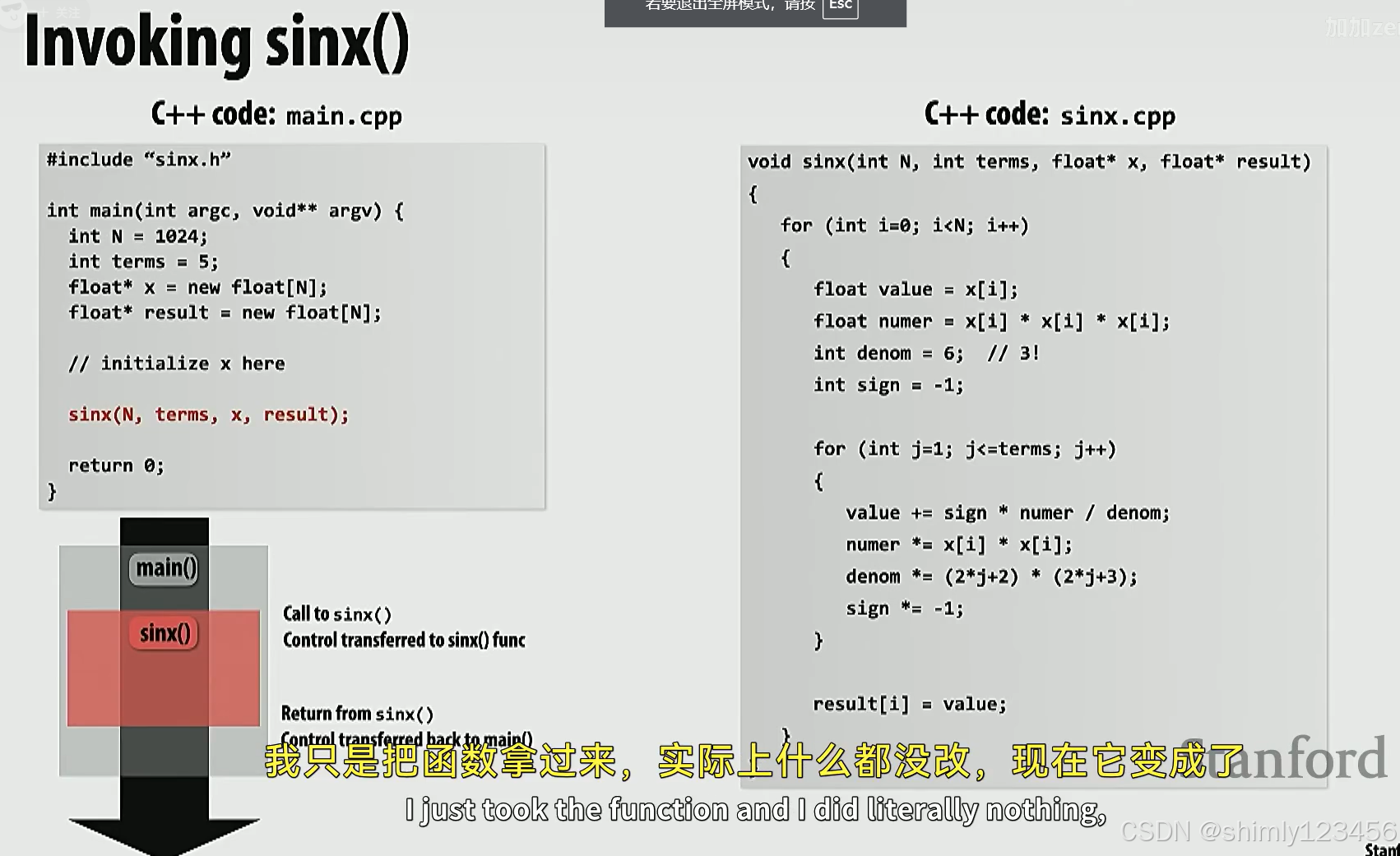
可以使用 ISPC 修改如下,ISPC 底层会使用线程或者 SIMD 的方式去实现并行:

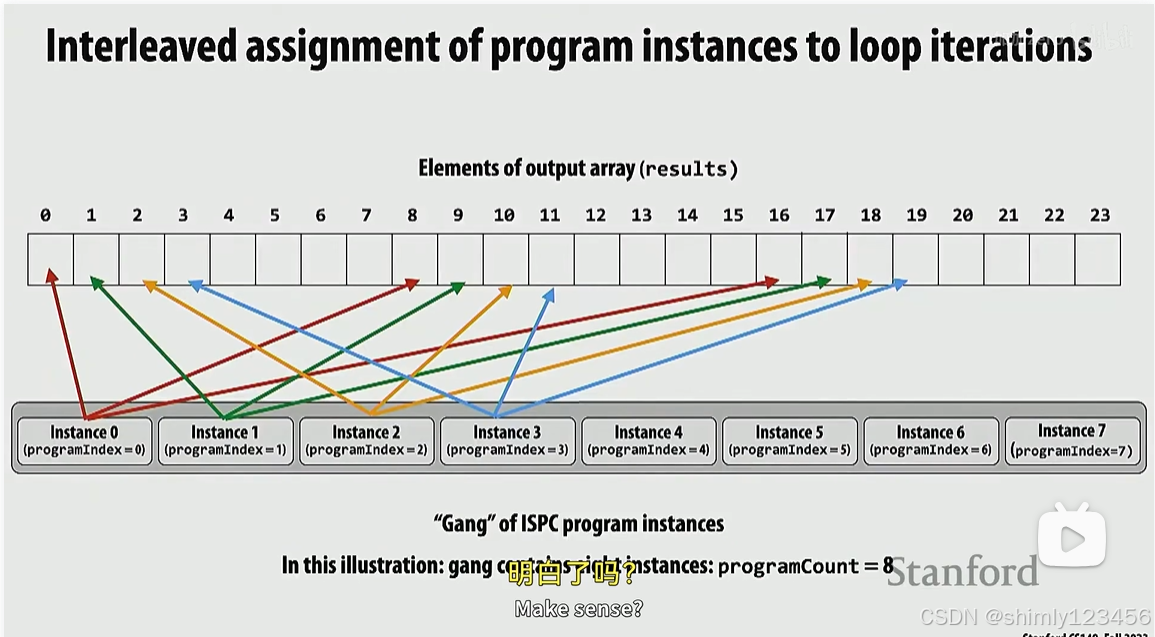
上述实现,每个 instance 访问的内存块是分散的
下面是 ISPC 的另一个版本:
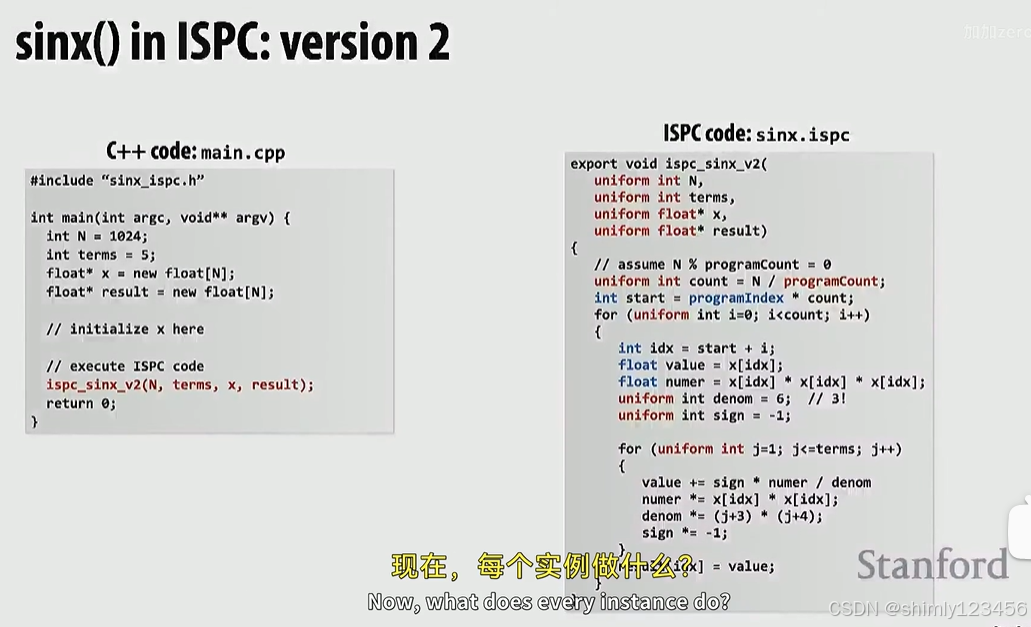
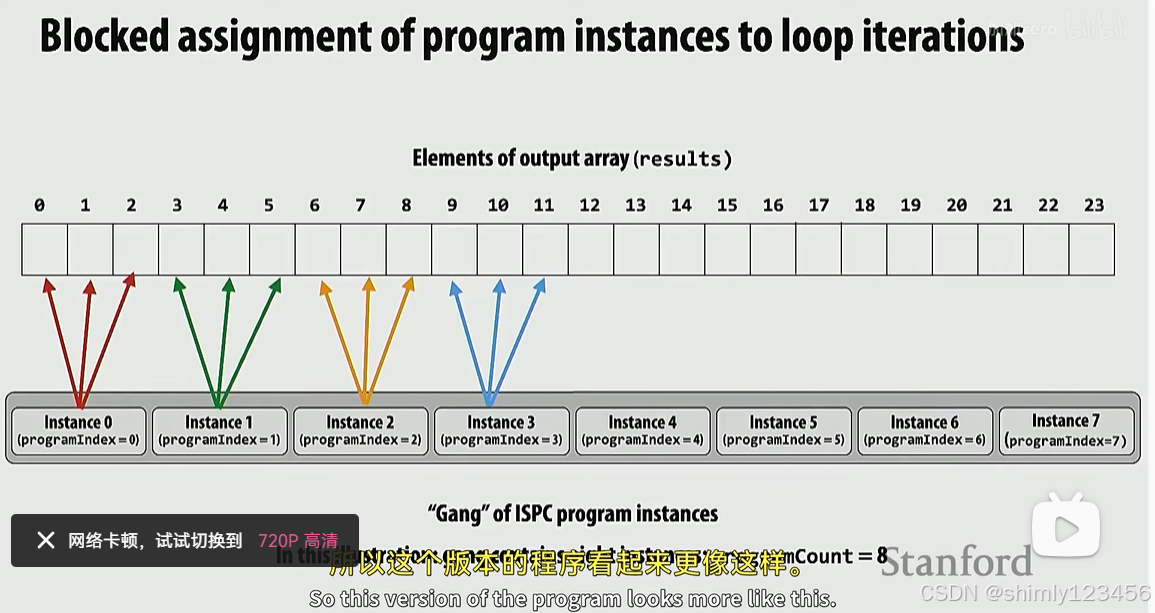
这个实现会引导 ISPC 生成的每个 program instance 去访问连续大块的内存,如下:
事实上,我们可以不去管这些细节,直接用如下的抽象语句 foreach:

下图中,每一个灰色框都是粉色框的正确实现,ISPC 编译器需要聪明地选择最高效的版本



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









