







视频 url: https://www.bilibili.com/video/BV1du17YfE5G?spm_id_from=333.788.videopod.sections&vd_source=7a1a0bc74158c6993c7355c5490fc600&p=2
大佬笔记 url: https://zhuanlan.zhihu.com/p/8129089606
先看视频:
Lecture 0 ~ 28min 的内容基本就是 cache,本科体系结构学过的东西。
sinx例子:串行版本
一个例子贯穿全课(使用泰勒展开计算 sinx):
该程序使用泰勒展开实现 sinx() 函数。为每一个 x (x数组中的每一个元素) 计算一个 y (y 数组中的每一个元素)。这是一个串行程序
void sinx(int N, int terms, float* x, float* y)
{
for (int i = 0; i < N; i++)
{
float value = x[i];
float numer = x[i] * x[i] * x[i];
int denom = 6; // 3!
int sign = -1;
for (int j = 1; j < terms; j++)
{
value += sign * numer / denom;
numer *= x[i] * x[i];
denom *= (2 * j + 2) * (2 * j + 3);
sign *= -1;
}
y[i] = value;
}
}
sinx例子:C++ thread 双线程版本
上面这个程序可以通过改变程序的方式来实现并行,比如,我们可以通过 C++ thread,增加一个线程帮助我们实现并行:(下面这个代码应该是有 bug 的,但是无伤大雅)
但下面的代码有个问题:如果我的硬件有4个 CPU cores,那么下面的代码只能利用到我的两个 CPU cores,而非四个。
#include <thread>
void sinx(int N, int terms, float* x, float* y)
{
for (int i = 0; i < N; i++)
{
float value = x[i];
float numer = x[i] * x[i] * x[i];
int denom = 6; // 3!
int sign = -1;
for (int j = 1; j < terms; j++)
{
value += sign * numer / denom;
numer *= x[i] * x[i];
denom *= (2 * j + 2) * (2 * j + 3);
sign *= -1;
}
y[i] = value;
}
}
typedef struct {
int N;
int terms;
float* x;
float* y;
} my_args;
void my_thread_func(my_args* args)
{
sinx(args->N, args->terms, args->x, args->y); // do work
}
void parallel_sinx(int N, int terms, float* x, float* y)
{
std::thread my_thread;
my_args args;
args.N = N/2;
args.terms = terms;
args.x = x;
args.y = y;
my_thread = std::thread(my_thread_func, &args); // launch thread
sinx(N - args.N, terms, x + args.N, y + args.N); // do work on main thread
my_thread.join(); // wait for thread to complete
}
sinx例子:高级语言循环并行化版本
事实上,现代高级编程语言几乎都有这么一种抽象语义,来表示一个循环的每次迭代都是相互独立的,比如 C+OpenMP, pyTorch 等等,如下:
高级编程语言会根据硬件 cores 的数量,自动创建合适数量的线程去并行执行下面的代码。也就是说,如果我有 16 个 CPU cores,那么通常高级编程语言会帮助我把计算任务平均地分配给 16 个 CPU cores。

sinx例子:SIMD 版本
这个课堂给出的 SIMD 例子需要硬件和编译器的支持。
硬件上,要求一个 core 里有多个 ALU 元件,如下:

使用一个 ALU 的程序叫做 scalar program (标量程序)。
如下,使用 AVX 指令的代码则叫做 vector program (矢量程序)
#include <immintrin.h>
void sinx(int N, int terms, float* x, float* y)
{
float three_fact = 6; // 3!
for (int i = 0; i < N; i += 8)
{
__m256 origx = _mm256_load_ps(&x[i]);
__m256 value = origx;
__m256 numer = _mm256_mul_ps(origx, _mm256_mul_ps(origx, origx));
__m256 denom = _mm256_broadcast_ss(&three_fact);
int sign = -1;
for (int j = 1; j < terms; j++)
{
// value += sign * numer / denom
__m256 tmp = _mm256_div_ps(_mm256_mul_ps(_mm256_set1_ps(sign), numer), denom);
value = _mm256_add_ps(value, tmp);
numer = _mm256_mul_ps(numer, _mm256_mul_ps(origx, origx));
denom = _mm256_mul_ps(denom, _mm256_set1_ps((2*j+2) * (2*j+3)));
sign *= -1;
}
_mm256_store_ps(&y[i], value);
}
}
上面的 SIMD 源码会被编译器编译成下面的 SIMD 汇编指令,一个指令处理 256-bit 数据,从而加速

一个问题是,为什么选择在单核中增加 ALU,而不是直接增加核数?
回答:一个 ALU 相比一个完整的 CPU core 便宜很多
SIMD遇到分支判断结构怎么办?(使用掩码滤除)
如下图,当 SIMD 代码遇到分支判断结构时,可能无法同时执行 SIMD 指令。因为每次循环执行的指令流并不一致。(这种情况也叫做 “线程分化”)
此时有一种很直接的做法:让 CPU core 使用 SIMD 指令同时执行 if-else 中的所有代码,随后根据 if 判断的结果掩盖掉部分计算结果。

一个具体的例子如下:
源码:
// 伪代码:每个线程处理一个元素
if (data[i] > 5) {
data[i] *= 2; // 分支导致线程分化
}
生成掩码:
mask = (data > 5) # 例如:mask = [1, 0, 1, ...]
应用掩码:
// 伪代码:所有线程执行相同指令,但仅掩码为1的通道生效
data = data * (2 * mask + (1 - mask)) // 满足条件时乘2,否则乘1(即不变)
更具体的例子:
Intel AVX512 指令集的掩码操作
// 示例:Intel AVX512 指令集的掩码操作
__mmask16 mask = _mm512_cmp_ps_mask(vec, threshold, _CMP_GT_OS);
result = _mm512_mask_mul_ps(vec, mask, vec, factor); // 仅掩码为1的通道执行乘法
CUDA 中使用掩码选择活跃线程
// 示例:CUDA 中使用掩码选择活跃线程
unsigned int mask = __ballot_sync(0xFFFFFFFF, data[i] > 5);
if (threadIdx.x % 32 < __popc(mask)) {
// 仅满足条件的线程执行后续操作
}
在课堂例子中,极端情况下只有 1/8 的效率。
比如,只有线程1执行 if-True 的情况,其它7个线程执行 if-False的情况。
而 if-True 包含 expensive 的代码,if-False 包含 cheap 的代码。
那么,哪怕使用了上述掩码技术,效率仍然接近 1/8
指令流一致性和发散执行
指令流一致性:多个计算单元执行的指令序列是一致的
对于SIMD并行来说,指令流一致性是必要的
但对于多核并行来说,指令流一致性不必要,因为每个 core 有自己的 IFU 和 IDU。
发散执行:指的是一个程序中缺少 “指令流一致性”

SIMD 需要 CPU硬件支持、编译器支持、以及程序员的参与

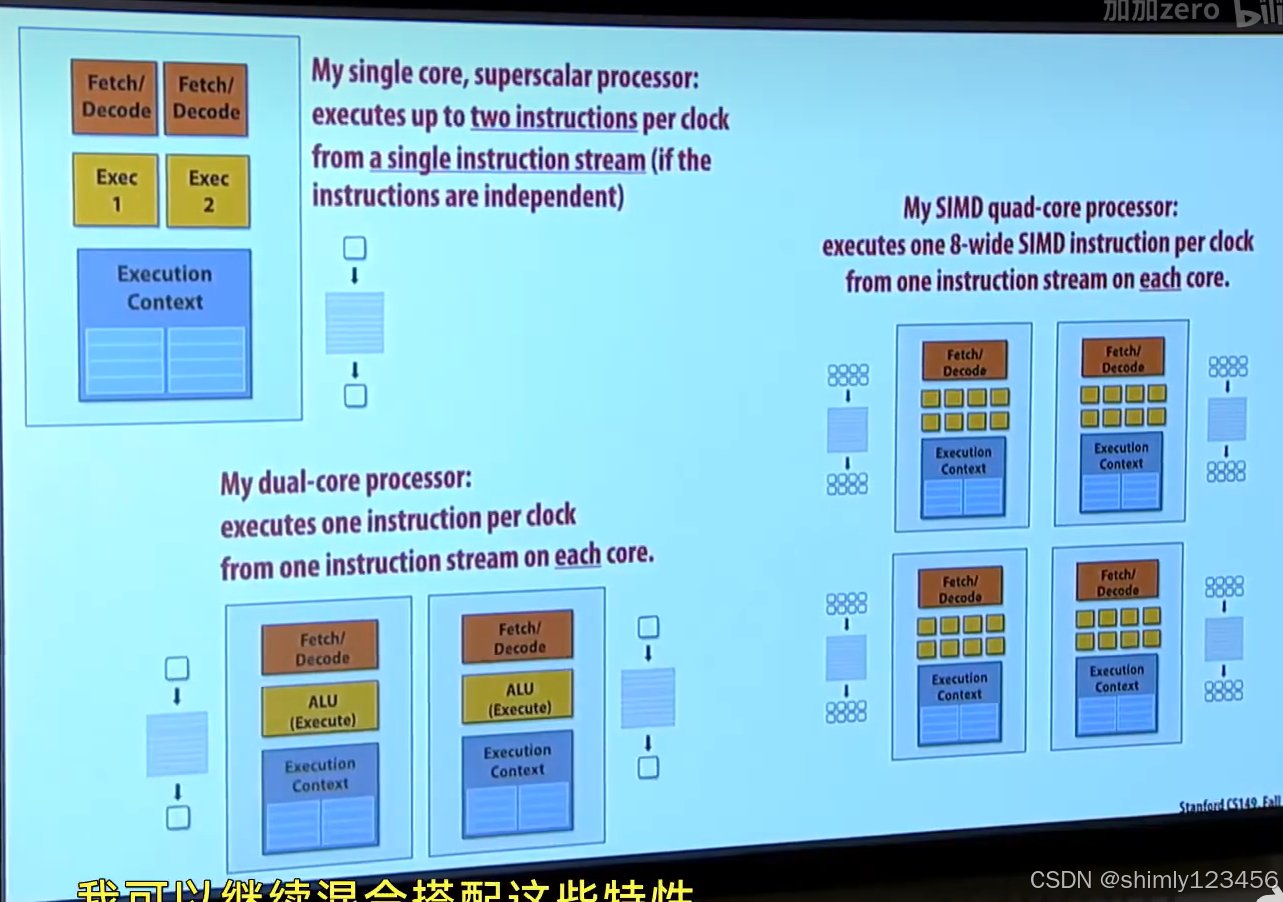
三种不同的并行形式
1.超标量:例如 nutshell 的顺序双发、以及BOOM的乱序多发处理器,这种并行由CPU自己执行,没有编译器和程序员的参与。
2.SIMD:利用一个 CPU core 上多个 ALU,需要硬件、编译器和程序员的支持。
3.多核:在多个 CPU core 上运行同一个程序的多个线程。需要硬件、编译器和程序员的支持。

下图很好地介绍了三种并行的区别
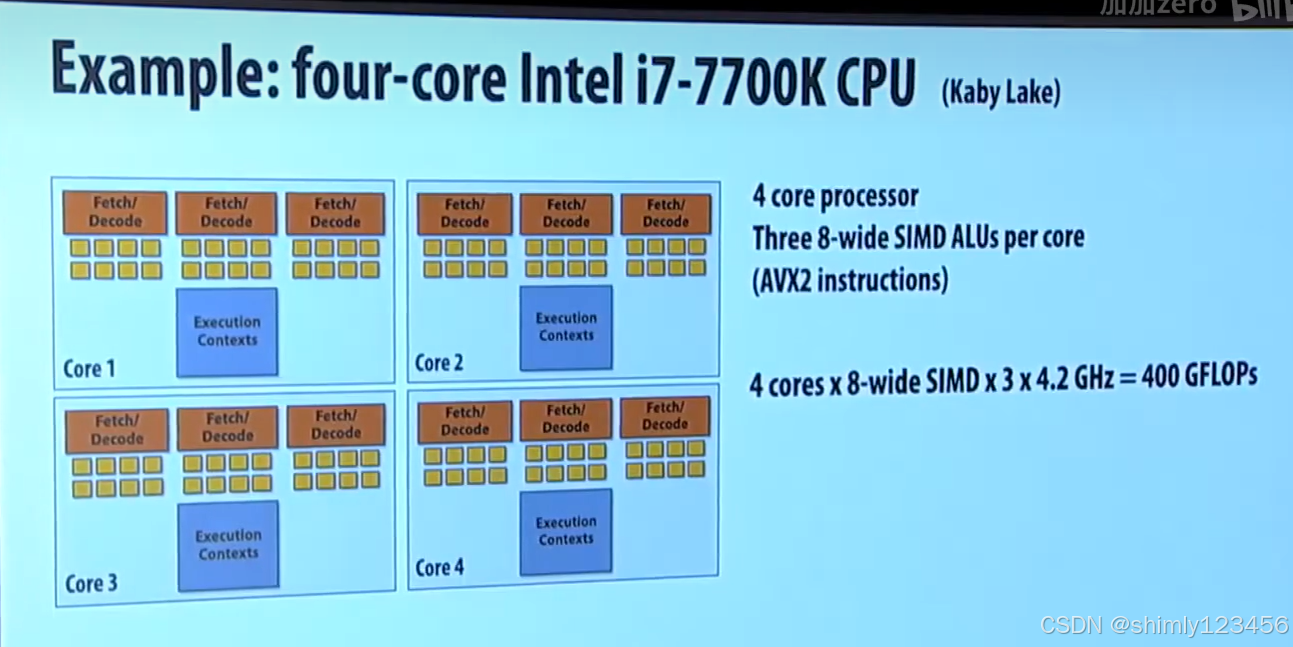
这些并行形式可以混合,如下:

数据预取(缓解内存IO开销)
内存访问仍然是一个大的性能瓶颈,除了缓存外,还有数据预取,如下

超线程技术(缓解IO开销)
还有一种解决内存瓶颈的方式:在 CPU core 里实现多个 execution context。(也叫超线程技术)
当遇到内存读取 cache miss 时,CPU 知道自己要等待很久,于是切换到第二个 thread 的 execution context 去执行第二个 thread
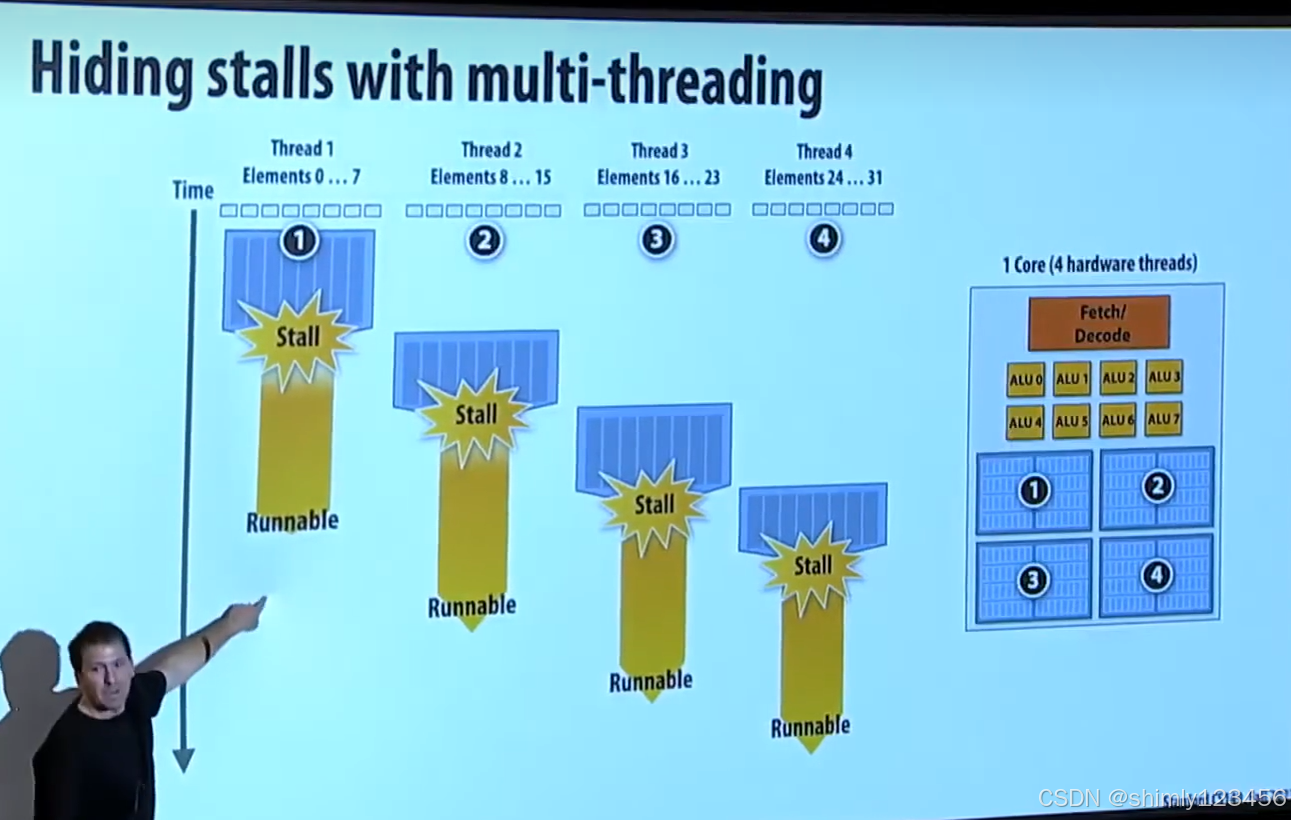
需要注意的是,上述方法提高了 overall system throughput,但实际上降低了单个线程的执行速度。(因为单个线程在内存数据读取完毕后,CPU core 并没有立刻切换回来执行)

再来看大佬笔记补充
3 实现SIMD的AVX2案例代码
SIMD这一思想对应的指令集就是我们常常在硬件评测类视频或文章中提到的AVXxxx系列指令集。AVX2是目前使用最广泛的SIMD指令集。AVX512支持的SIMD指令集的宽度更大, 但是目前还没有普及, 而且因为发热过大还在Intel最近几代CPU被移除了, 这里的案例代码也是基于AVX2的, 其支持的SIMD指令宽度为256位。
查看个人PC是否支持AVX2指令集的方法:
cat /proc/cpuinfo | grep avx2
3.1 中常用的函数总结
3.1.1 浮点运算函数
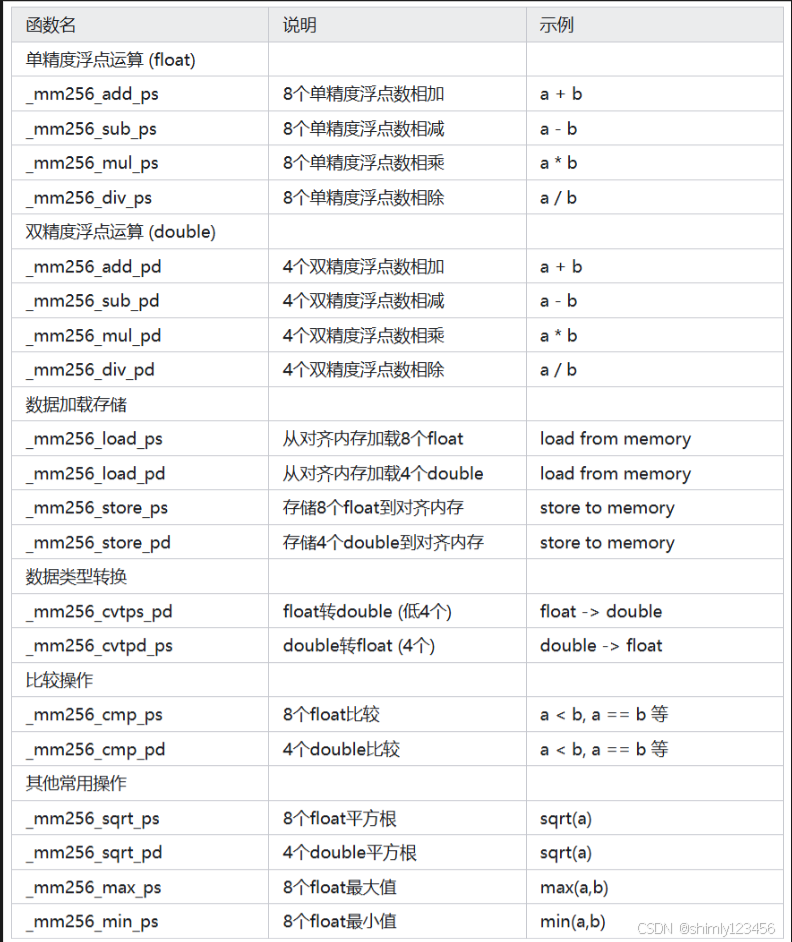
注意事项: 1. 函数名中的 ps 表示 packed single (单精度浮点) 2. 函数名中的 pd 表示 packed double (双精度浮点) 3. 256 表示使用 256 位寄存器 4. 单精度运算一次处理 8 个数 (256/32=8) 5. 双精度运算一次处理 4 个数 (256/64=4)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









