




1. 简介
在数字化时代,创意与技术的结合不断推动着艺术和媒体的边界。DiffSensei,一个创新的框架,正是这一趋势的前沿代表。它巧妙地融合了多模态大型语言模型(MLLM)与扩散模型,为定制化漫画生成提供了一个强大的工具。DiffSensei不仅能够理解文本提示,还能根据这些提示动态调整角色特征,生成具有丰富细节和一致性的漫画面板。
DiffSensei能将文本描述转化为视觉叙事,同时保持角色之间的互动和场景的连贯性。通过精确控制角色的外观和布局,DiffSensei能够创造出既符合文本描述又具有视觉吸引力的漫画内容。
随着人工智能技术的发展,DiffSensei展示了AI在创意产业中的潜力,尤其是在视觉故事讲述方面的应用。它不仅能够辅助艺术家和设计师,提高创作效率,还能够为观众提供个性化和沉浸式的阅读体验。随着技术的不断进步和完善,我们有理由相信,DiffSensei将在未来的内容创作和媒体展示中扮演越来越重要的角色。
-
目录
项目主页:DiffSensei: Bridging Multi-Modal LLMs and Diffusion Models for Customized Manga Generation
论文地址:https://arxiv.org/abs/2412.07589
权重地址:https://huggingface.co/jianzongwu/DiffSensei/tree/main
数据集地址:https://huggingface.co/datasets/jianzongwu/MangaZero
colab版本:https://colab.research.google.com/drive/1f_VQfHzBGSIBgE9g21GYKGuZSh_SMRpK
-
-
2.效果展示
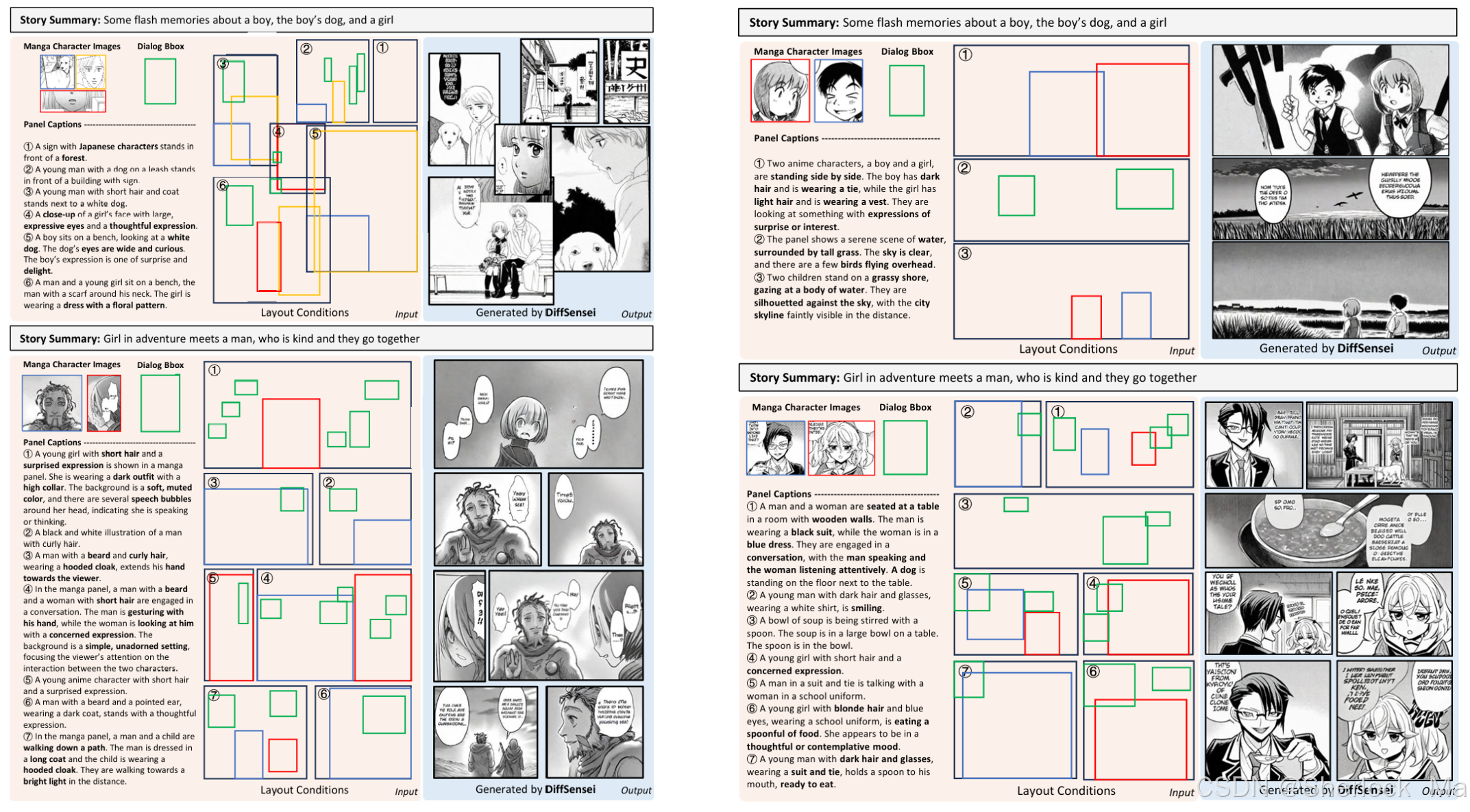



-
-
3.论文解析
介绍
漫画因其流行性和独特的叙事要求而具有特殊的意义,与其他的故事可视化不同,漫画要求跨面板的角色保持一致,还需要定位多个角色的精确布局控制,以及以连贯、视觉上引人入胜的方式无缝地嵌入对话。
目前,漫画生成仍然是一个未充分开发的领域。大多数现有的研究集中在低级别的图像到图像任务,主要是将一般图像转换为漫画风格。虽然这些任务增强了静态图像的视觉吸引力,但它们并没有扩展到从头开始生成完全定制的漫画内容。另一个研究方向探索了zero-shot的角色定制,然而,这些方法往往会导致僵化的“复制粘贴”效果,这限制了表现人物的变化,这种限制主要源于数据集的稀缺性,这些数据集中同一角色在不同表情和姿势中的多次出现,模型难以学到新知识。
这篇论文的贡献:
- 简单来说引入一个新任务:定制漫画生成,重点是生成具有多个人物的漫画图像,每个人物都动态地适应文本提示并根据布局规范定位。
- 推出了MangaZero数据集,这是第一个专门为多角色、多状态漫画生成而设计的大规模数据集,解决了故事可视化训练数据的巨大缺口。该数据集将发布给图像生成社区。
- 推出了DiffSensei,它是第一个将扩散模型和MLLM联系起来的定制漫画生成框架。MLLM作为一个自适应的字符特征适配器,使字符能够动态地响应文本提示。
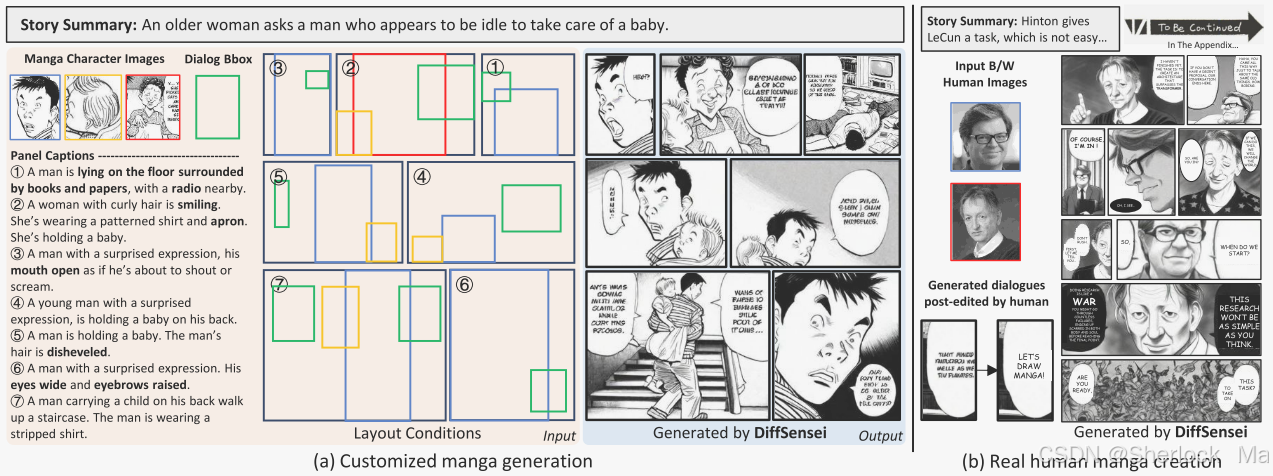
-
相关工作
故事可视化 Story visualization
故事可视化,即基于给定故事生成视觉叙事的过程,目前正在迅速发展。尽管这一领域最近取得了较大进展,但该领域仍面临着重大限制。大多数现有方法仅从文本和图像级提示生成故事图像,这种方法对角色的控制效果十分有限,降低了故事可视化的灵活性和深度。
一个关键因素是当前的训练数据集缺乏特定的注释。为了应对数据限制,最近的工作探索了使用现有物体保存技术(如IP适配器)的免训练方法进行多角色控制。其他工作试图训练扩散模型以实现多角色定制生成。然而,这些方法通常会导致“复制-粘贴”效应,严重限制了动态故事讲述所需的表达能力和动作的多样性。另外,组合多个模型还显着降低了推理速度。
-
用于个性化图像生成的MLLM
MLLM在个性化图像生成方面表现出了巨大的潜力,特别是对于涉及图像编辑和定制的任务。
然而,MLLM驱动的多角色叙事图像生成仍然是一个开放的挑战,主要是由于在保持人物之间的关系和场景的连续性的困难。我们的框架提出了一个基于MLLM的身份适配器(identity adapter),提高了动态故事的多角色一致性。与以前的作品相比,我们的框架将多角色特征作为输入,并在文本提示后集体编辑这些特征,从而实现跨多个角色的灵活主题编辑。
-
MangaZero数据集
问题定义
为了跨N个面板(panel)生成漫画故事,输入包括:针对每个面板的文本提示,k个角色图像
,每个面板的角色边界框
,以及每个面板的对话边界框
。模型输出表示为
,其中Φ是整个模型函数,θ表示模型的学习参数。
这个任务不同于现有的故事可视化和延续任务。
- 具体来说,在故事可视化任务中,面板是使用
生成的,而在故事延续任务中,面板的生成取决于先前的面板,即
,i > 0。两者都缺乏明确的角色控制(I),而这是讲故事的关键因素。
- 此外,所提出的任务不同于主题驱动(subject-driven)的图像生成方法,因为它要求模型不仅生成准确的角色表示,而且还修改角色的属性以响应面板标题和布局,从而产生变化和连贯的叙事视觉效果。
-
数据集构建
与当前的漫画和故事可视化数据集相比,作者所提出的MangaZero数据集尺寸更大,数据源更新,注释更丰富,漫画系列多样,面板分辨率多样化。与著名的黑白白色漫画数据集Manga 109 相比,Manga Zero数据集包含更多2000年之后出版的漫画系列,这也是它的命名由来。此外,MangaZero还收录了2000年以前的著名系列,而这些系列在Manga109中没有出现,例如哆啦A梦(1974)。
为了构建数据集:
- 作者首先从MangaDex上下载漫画页面。需要注意的是,所有数据仅用于学术研究,而不是商业目的。作者选择了48个漫画系列,每个系列最多下载1,000页,从而生成43264张双页图像。(下图1)
- 然后作者使用最近的漫画理解模型Magi对这些图像进行注释。对于漫画特定的注释,包括面板边界框,角色边界框,角色ID和对话框边界框。应该注意的是,角色ID标签仅在单个页面内是一致的,这足以给连贯的角色生成提供参考。(下图2)
- 一旦获得面板边界框,我们就利用LLaVA-v1.6-34 B为每个面板生成字幕。(下图2)
- 然而,作者观察到角色ID标记的准确性相对较低,这对训练目的构成了重大挑战。为了解决这个问题,人类注释者对机器生成的标签进行了细化,从而产生了准确和干净的注释。(下图3)
- 最后,将96页(每个系列2页)作为评估集,剩余的43168页作为训练集。

-
方法
动机
在图像生成过程中定制对象和布局有两个关键问题:
- 在避免直接从源角色图像复制粘贴的同时保持对象的特征;
- 在训练和推理过程中以最小的计算代价确保可靠的布局控制。
为了避免复制粘贴效应,该模型将角色图像特征转换为tokens,避免了直接传递细粒度的像素细节。此外,作者还集成了一个MLLM作为角色图像特征适配器。MLLM适配器接收源角色特征和面板标题作为输入,生成与文本兼容的目标角色特征。
对于布局控制,对角色和对话布局都采用了轻量级掩码技术。
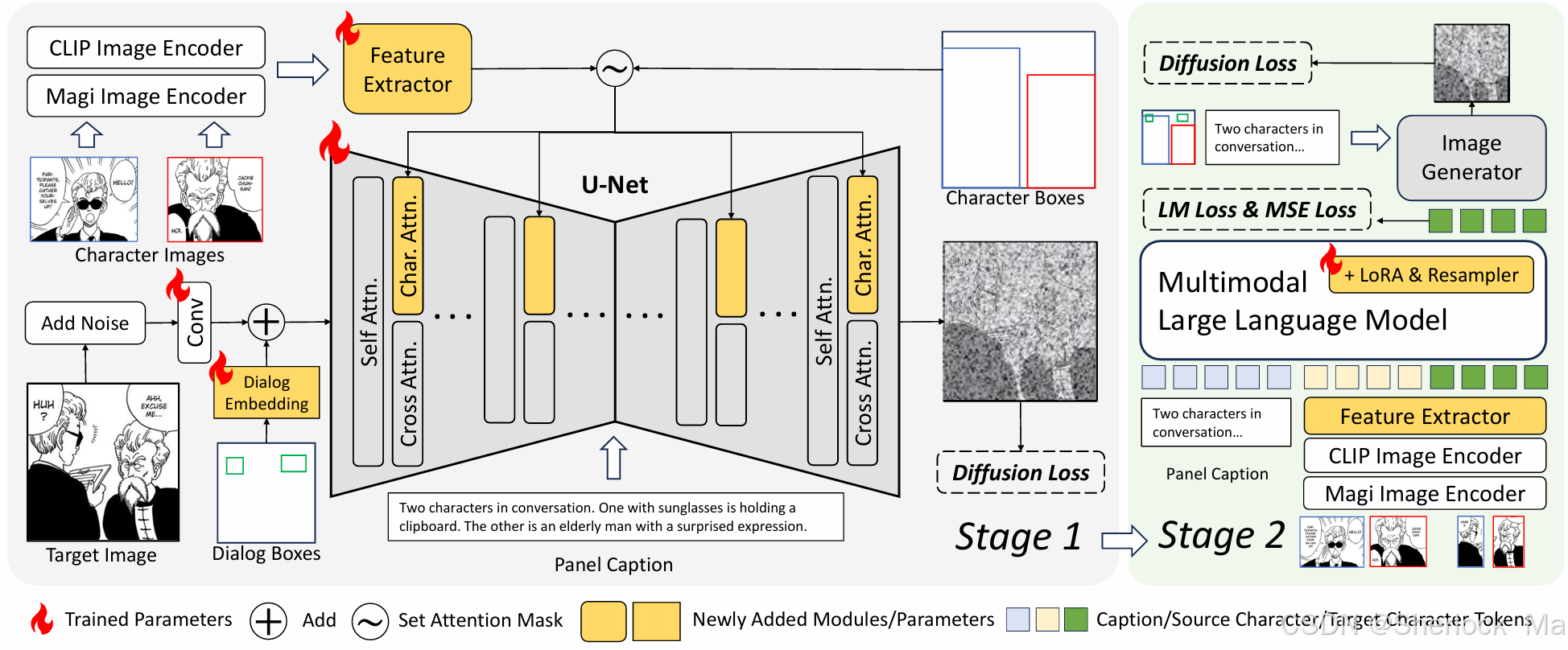
-
多角色特征提取
作者使用CLIP和一种漫画图像编码器(Magi Image Encoder)来提取局部图像特征。获取这两组特征后由特征提取器(即重采样器模块)处理。该过程可以形式化为:其中,
表示漫画图像编码器。q和
分别是有角色和无角色特征的可训练query向量。q将图像特征重新采样到U-Net的交叉注意维度中,而
则在布局中没有角色的区域中引导交叉注意。
是所有角色的输出特征,其中B是批量大小,Nc是每个面板的最大角色数(根据需要填充全零特征),Nq是每个角色的query标记数,C是U-Net的交叉注意维度。
通过将角色图像压缩为几个token,DiffSensei避免将参考图像的细粒度空间特征编码到模型中。这使得能够专注于角色的语义表示,而不是固定的像素分布。
-
掩码交叉注意力
作者通过复制原交叉注意力的key和value矩阵来创建单独的角色交叉关注层。这允许图像query特征独立地关注文本和角色的交叉注意力,然后将来自这两种注意力的结果结合起来。
在角色交叉注意中,作者采用了一种掩码的交叉注意注入机制来控制每个角色的布局。在这里,每个角色特征只关注其指定边界框区域内的query特征。在没有角色的区域中,query特征处理占位符向量。
这可以表示为:,其中
,
,
,
,
。Q是query,
,
,
是文本交叉注意力的query,key和value投影矩阵。
、
是用于角色交叉注意的key和value投影矩阵,从
和
初始化。d是key的维度。ct、ci分别是文本和角色特征。z、
是输入和输出图像特征。α是控制角色注意力权重的超参数。M是一个注意力掩码,用于管理角色的布局。其值定义如下:
其中i表示query tokens的位置,j ∈ {0,1,.,Nc}是角色索引。第Nc个角色特征表示占位符向量。
是第j个角色的边界框。掩码注意力机制确保每个角色只关注其指定的边界框区域,而没有角色的区域关注占位符向量。该技术以最小的计算开销实现了对每个角色的高效和精确的布局控制。
简单来说,角色特征被提取后加上掩码后提供KV,而文本提供KV,噪声加上对话框嵌入和掩码提供Q,角色特征KV和噪声Q计算一次角色交叉注意力,文本KV和噪声Q计算一次交叉注意力。
-
对话框布局编码
带有对话框的面板是漫画图像的显著特征。然而,大多数当前的文本到图像模型都难以生成连贯、可读的文本。虽然最近的一些模型可以产生稳定的文本,但它们在文本长度方面仍然有限。生成扩展文本,如对话,继续构成挑战。
因此,作者建议控制对话框的布局,而不是文本内容。在这种方法中,人类艺术家可以手动编辑对话框中的文本,将图像生成留给模型。
具体来说,作者引入了一个可训练的embedding来表示对话框布局。首先扩展对话框embedding以匹配噪声的空间形状,然后用对话框布局掩码掩蔽其他区域。通过将掩蔽的对话embedding与潜在噪声相加,就可以在图像生成器内对对话位置进行编码。此过程表示为:,其中
是可训练对话嵌入,
是时间步长t中的噪声,Expand是将
扩展到潜在形状的函数,并且
是从输入对话边界框
导出的对话区域掩模。输出结果是一个包含对话框布局信息的潜在噪声。然后将其输入到U-Net中进行噪声预测。对话框嵌入有效地编码了对话框布局,在空间和时间上实现了最小的计算开销。
整个阶段一如图所示:
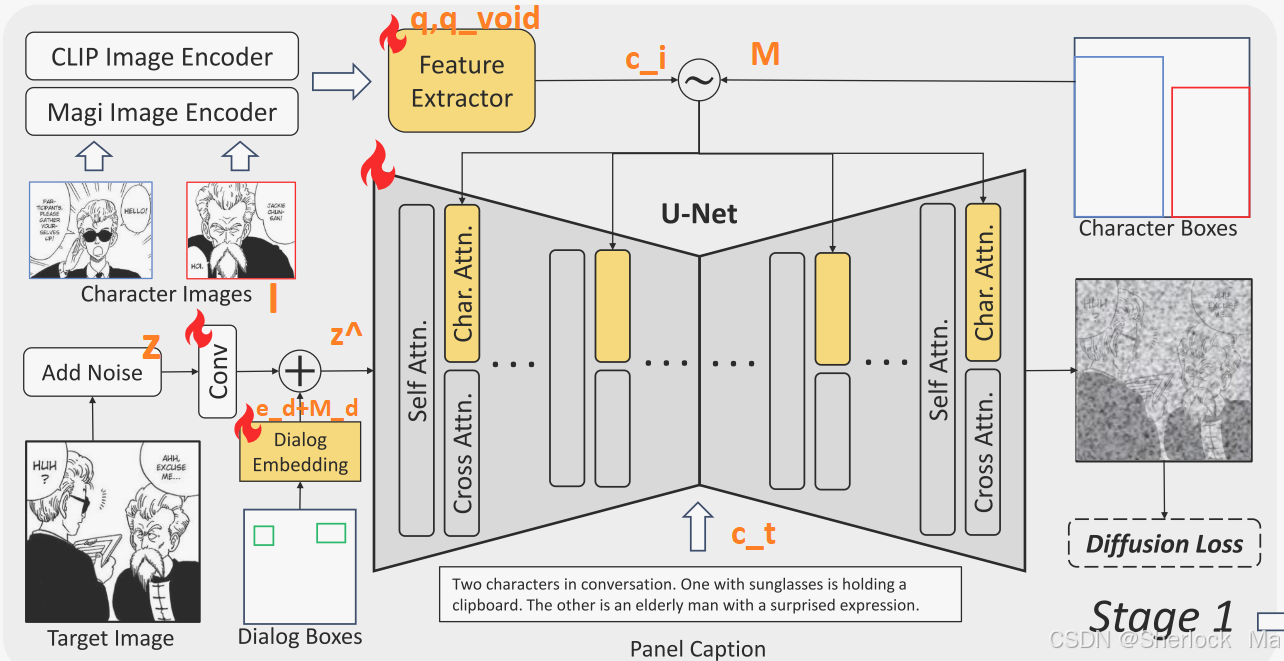
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3244
3244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









