







在爬虫爬取数据的过程中,往往我们需要的只是网页中的一部分数据,而不是整张页面数据,因此在这个过程中就需要我们用到数据解析,通过数据解析获取我们想要爬取的内容。
常用的数据解析的方式大概分为三种:
1.正则表达式
匹配:
- re.match(pattern,string,flags=0)
参数:pattern匹配的正则表达式,string要匹配的字符串,flags=0从字符创开头进行匹配,匹配成功回返回一个匹配的对象。类型是<class’_sre.SRE_Match’> - re.search(pattern,string,flags=0)
参数同上
**注意:**match方法和search方法最大的区别是,match如果开头就不和正则表达式匹配,则直接返回None,而search则是匹配整个字符串。
检索与替换:
- re.findall(pattern ,string ,flags=0)
遍历字符串,找到正则表达式匹配的所有位置,并以列表的形式返回。 - re.finditer(pattern ,string ,flags=0)
遍历字符串,找到正则表达式匹配的所有位置,并以迭代器的形式返回。 - re.sub(pattern ,repl,string ,count=0,flags=0)
repl为替换的字符串,可以使函数,count为替换的最大次数,默认值0代表替换所有的匹配。 - re.split(pattern ,string ,maxsplit=0,flags=0)
maxsplit为设置分割的数量,默认值0对所有满足匹配的字符串进行分割,并返回列表。
正则规则:
| 字符 | 作用 |
|---|---|
| . | 匹配任意一个字符(除了\n) |
| [ ] | 匹配[ ]中列举的字符 |
| [^…] | 匹配不在[ ]中的字符 |
| \d | 匹配数字0到9 |
| \D | 匹配非数字 |
| \s | 匹配空白,空格和tab |
| \S | 匹配非空白 |
| \w | 匹配字母、数字、下划线:a-z ,A-Z ,0-9 ,_ |
| \W | 匹配非字母数字,下划线 |
| - | 匹配范围,如[a-f] |
- 字符匹配
可以匹配字母数字符号等。在正则表达式中,可以使用字符来匹配文本中响应字符。 - 字符集合
字符集合可以匹配文中的任何一个字符。在正则表达式中,字符集合用[ ]表示。例如,可以使用[abc]匹配文本中的abc。 - 范围
范围是一组连续的字符,可以用来匹配文本中的任何一个字符。在正则表达式中,范围用连字符-表示。例如,正则表达式[a-z]可以匹配文本中的任何一个小写字母。使用{m,n} 表示出现次数的范围m表示至少出现m次,n表示最多出现n次 - 量词
在正则表达式中,量词用花括号{}表示。例如,正则表达式a{3}可以匹配文本中连续出现三个字母a的字符串。 - 通配符
在正则表达式中,通配符用句点.表示。例如,正则表达式a.b可以匹配文本中包含一个字母a和一个字母b的字符串。 - 转义字符
在正则表达式中,转义字符用反斜杠\表示。例如,正则表达式.可以匹配文本中的句点。 - 分组
分组用于将多个字符或字符集合组合在一起。在正则表达式中,分组用圆括号()表示。例如,正则表达式(a|b)可以匹配文本中的字母a或字母b。 - 锚点
锚点用于指定匹配的位置。在正则表达式中,锚点有两种:^和$。^用于匹配文本的开头,$用于匹配文本的结尾。例如,正则表达式^a可以匹配以字母a开头的字符串,正则表达式a$可以匹配以字母a结尾的字符串。 - 模式修饰符
模式修饰符用于修改正则表达式的匹配规则。在正则表达式中,模式修饰符用字母表示。例如,i修饰符用于忽略大小写,g修饰符用于全局匹配。例如,正则表达式/a/i可以匹配文本中的字母a或A。 - 出现次数的表示符号 * + ?
* 表示出现 0次 或者 至少1次
+ 表示出现 至少1次
? 表示出现 0次 或者 1次 - 附
* 和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。
贪婪:匹配尽可能多的字符串
<.*>
非贪婪:只需要匹配到就可以
<.*?>
2.bs4(BeautifulSoup4了解)
它的作用是能够快速方便简单的提取网页中指定的内容,给我一个网页字符串,然后使用它的接口将网页字符串生成一个对象,然后通过这个对象的方法来提取数据。
Tag对象:是html中的一个标签,用BeautifulSoup就能解析出来Tag的具体内容,具体的格式为‘soup.name‘,其中name是html下的标签。
BeautifulSoup对象:整个html文本对象,可当作Tag对象
NavigableString对象:标签内的文本对象
Comment对象:是一个特殊的NavigableString对象,如果html标签内存在注释,那么它可以过滤掉注释符号保留注释文本最常用的还是BeautifulSoup对象和Tag对象
3.xpath表达式(重点)
常用且便捷高效
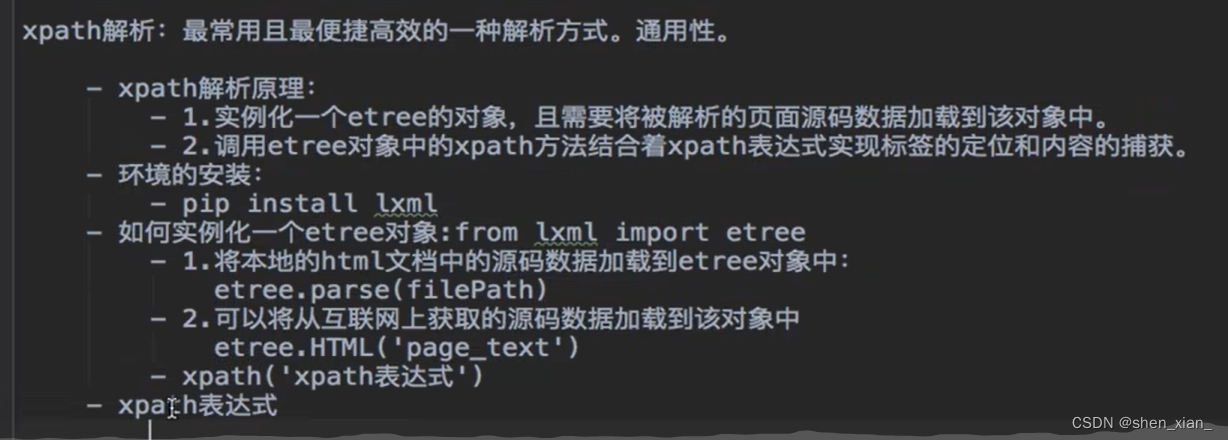
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
提示:如果 XPath 的开头是一个斜线(/)代表这是绝对路径。如果开头是两个斜线(//)表示文件中所有符合模式的元素都会被选出来,即使是处于树中不同的层级也会被选出来。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<4] | 选取最前面的三个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=‘eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |

















 3179
3179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









