







爬虫
1.定义
爬虫,即网络爬虫,又称网络蜘蛛(Web Spider),是一种按照一定规则获取万维网数据的程序。在FOAF社区中间,更经常的称为网页追逐者。
通过编写程序,模拟浏览器上网,然后去互联网上抓取数据。并不是只有Python语言可以编写爬虫程序,java,php等都有对应的爬虫框架,如java有WebMagic爬虫框架,PHP有phpspider爬虫框架,C# 有DotnetSpider爬虫框架。
2.爬虫分类在日常使用过程中的分类?
通用爬虫:抓取系统的重要组成部分,抓取的是一整张页面的数据。
聚焦爬虫:建立在通用爬虫的基础上。抓取页面中特定的内容。
增量式爬虫:检测网站中数据更新情况。只会抓取最新更新的数据。它能够在一定程度上保证所爬行的页面是尽可能新的页面。
Deep Web 爬虫:Web 页面按存在方式可以分为表层网页(Surface Web)和深层网页(Deep Web,也称 Invisible Web Pages 或 Hidden Web)。 表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 页面。Deep Web 是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。
3.爬虫的工作流程
爬虫的工作流程主要通过url队列对相应的网址进行网页获取,然后通过网页分析获取对应的内容,最后进行数据的存储。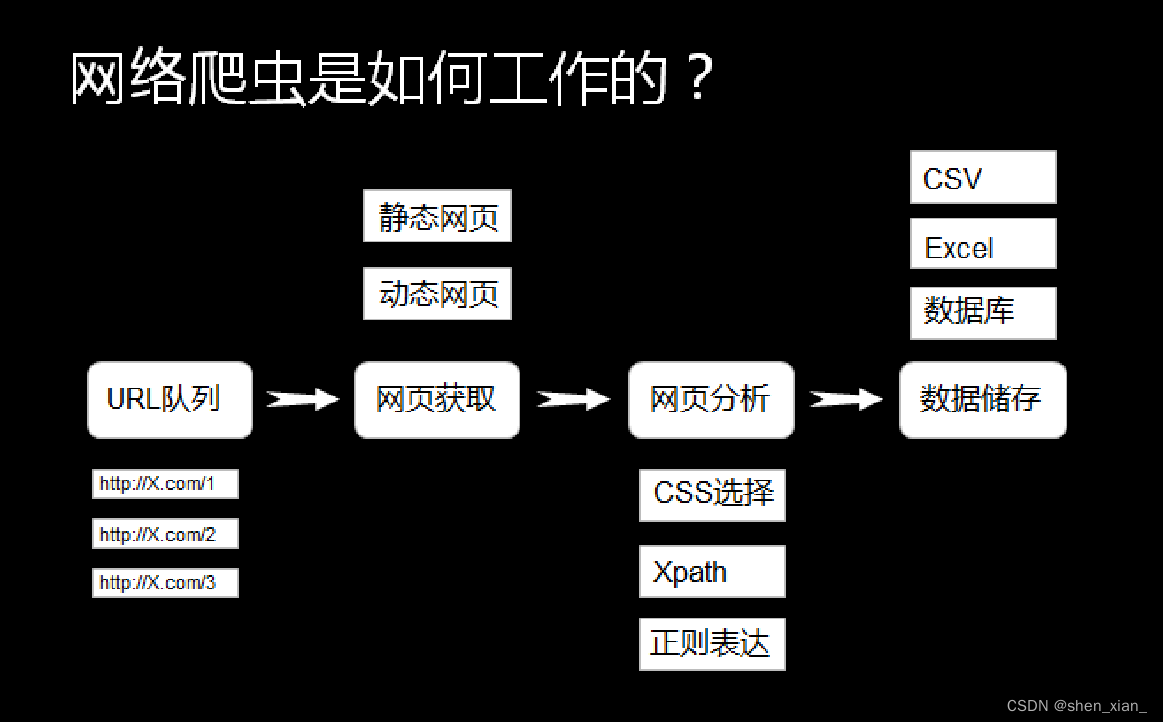
4.反爬机制
门户网站通过制定相关的策略,防止爬虫程序对网站数据进行爬取。
5.反反爬策略
爬虫程序制定相关的策略,破解门户网站中的反爬机制,从而获取门户网站中的相关数据。
6.http协议
定义:服务器和客户端进行数据交换的一种形式。
常用请求头信息:
- User-Agent : 请求载体的身份标识。
- Connection:请求完毕后是断开链接还是保持链接。
常用响应头信息:
- Content-Type:服务器响应回客户端的数据类型。
7.https协议
安全的http协议。
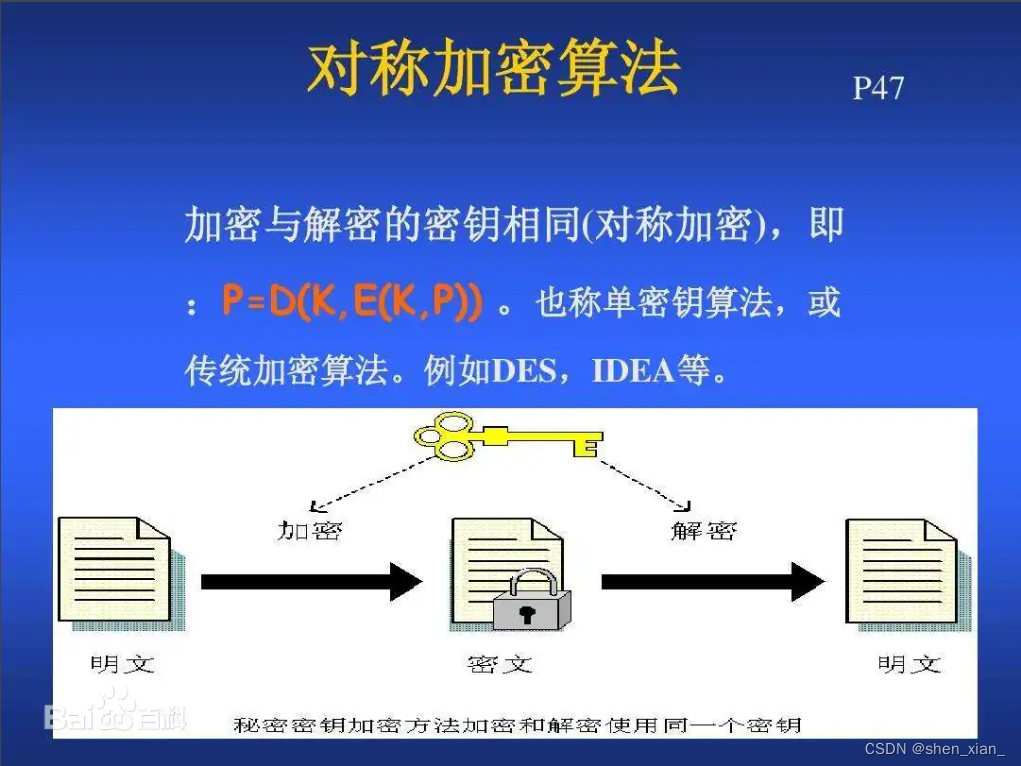
加密方式:
-
对称密钥加密。
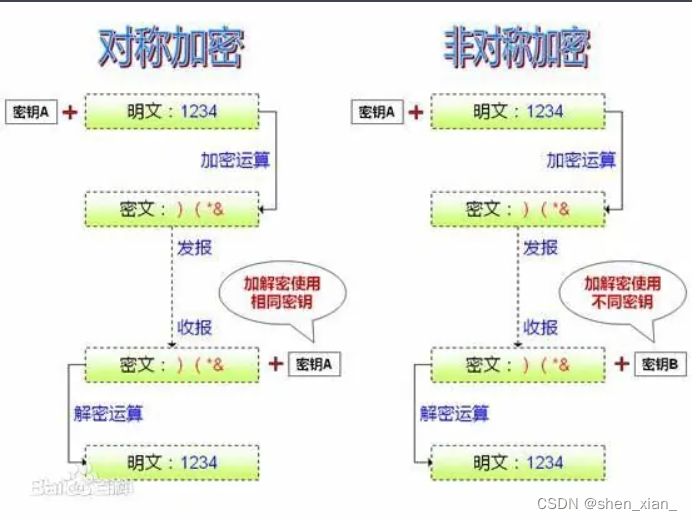
-
非对称密钥加密。
-
证书密钥加密。
CA证书能够帮助我们鉴别某一个网站的合法性,原理如下:
一、生成我的公钥
二、CA机构用自己的私钥加密我的公钥以及相关信息
三、客户信任CA,并拥有CA的公钥,客户就可以使用公钥解密加密后的证书,并从证书中得到我的公钥
四、如果能用CA的公钥解密出数据,说明我的证书是经过CA认证过的,客户就可以放心访问了,如果系统发现证书不是权威CA机构颁发的,会警告用户
五、客户使用我的公钥解密数据,然后进行信息交换

















 2933
2933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









