







 本文介绍了如何使用Python进行网络爬虫,包括指定URL、设置UA伪装来绕过反爬机制、通过URL携带参数、发起GET请求获取网页数据,以及将数据持久化存储为HTML文件。示例代码展示了如何实现这一过程。
本文介绍了如何使用Python进行网络爬虫,包括指定URL、设置UA伪装来绕过反爬机制、通过URL携带参数、发起GET请求获取网页数据,以及将数据持久化存储为HTML文件。示例代码展示了如何实现这一过程。
1. 指定URL
通过指定URL链接,爬取链接对应数据。
2. 反爬技术——UA伪装
让爬虫对应的请求载体伪装成浏览器进行爬取数据。
具体实现方式主要通过设置headers的值,设置User-Agent,将爬虫伪装成浏览器,进而进行数据的爬取。
3. URL携带参数
通过url携带参数,获取指定页面中对应的页面信息。
4. 发起GET请求
通过导入requests模块,对服务器发起GET请求,获取响应数据。
5. 持久化存储
将爬取的数据存储到对应的HTML文件中,通过字符串拼接的方式对爬取内容进行存储。
6. 实现方式
import requests
# UA伪装:让爬虫对应的请求载体身份标识伪装成一个浏览器。
if __name__ == "__main__":
# headers请求头信息
headers={
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 爬取的url
url = 'https://sogou.com/web?'
# url携带的参数:封装到字典中
kw = input("请输入你要查询的内容:")
param={
'query':kw
}
# 发起get请求,并且在这个请求中含有参数
response = requests.get(url=url,params=param,headers=headers)
page_text = response.text
filename = kw +'.html'
with open(filename,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(filename,"爬取成功!!!!")
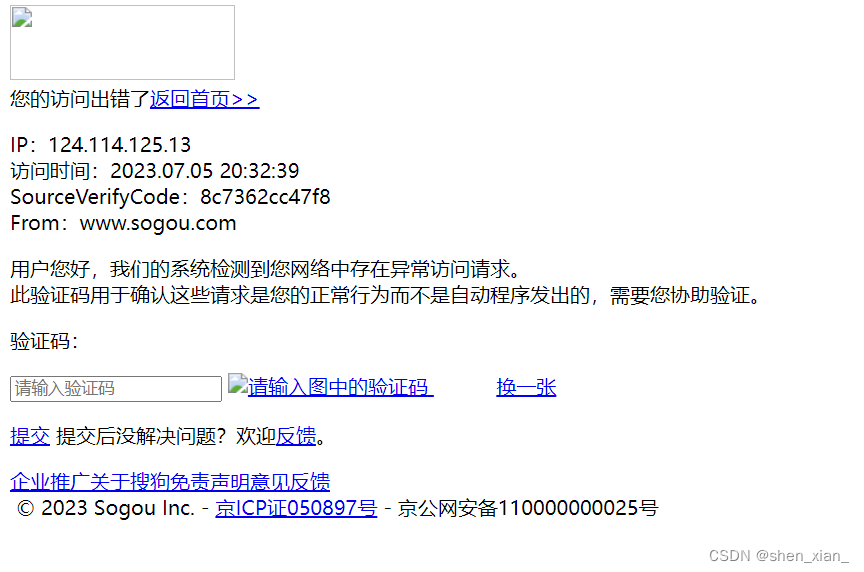
7. 不用反爬技术的结果
8. 采用UA伪装爬虫爬取结果
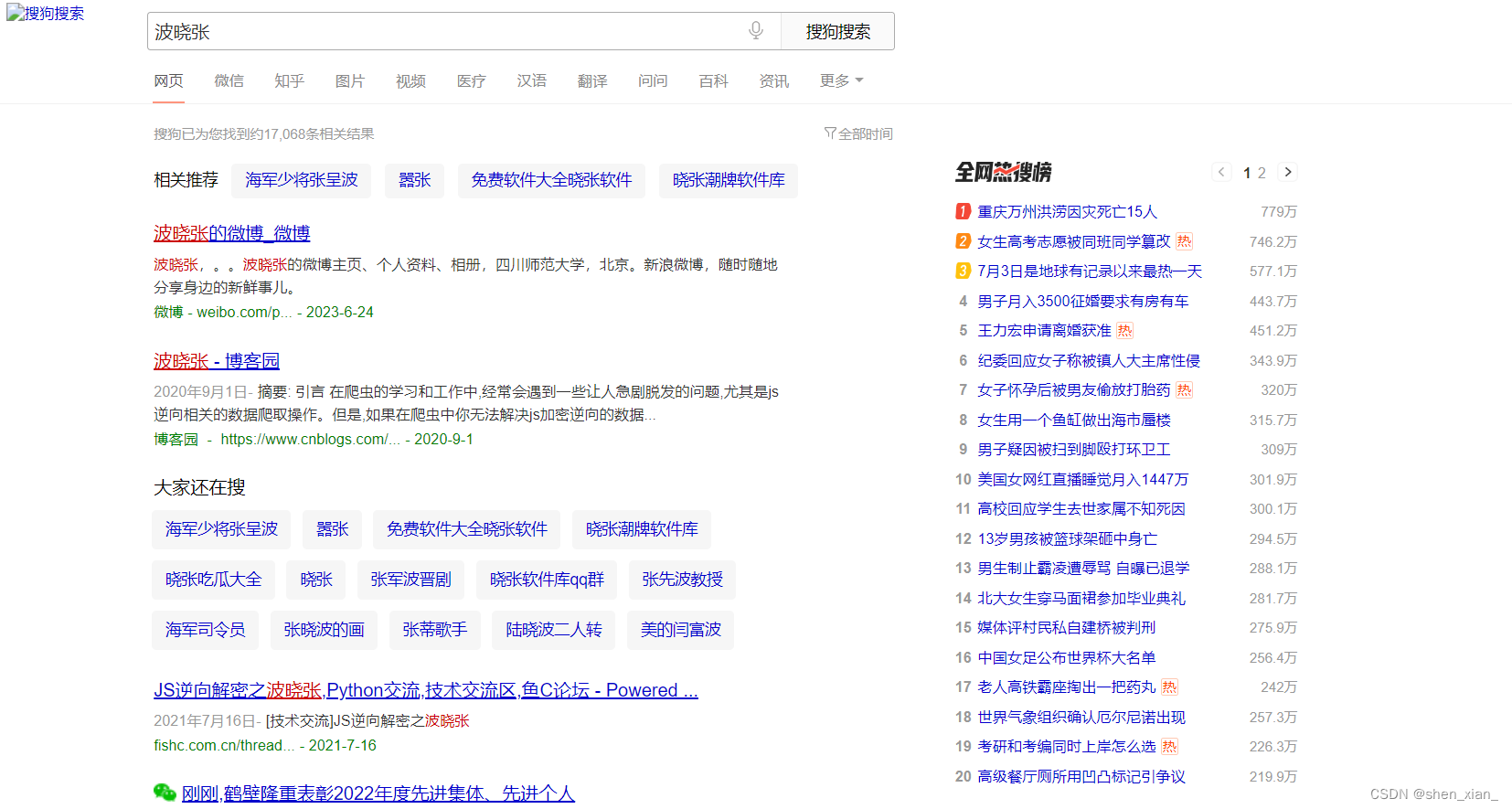
代码执行结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









