



【基本信息】
论文标题:Online Multi-Contact Receding Horizon Planning via Value Function Approximation
发表期刊:IEEE Transactions on Robotics (TRO)
发表时间:2024年4月22日
【访问链接】
论文:https://ieeexplore.ieee.org/document/10506550
代码:暂无
【科学问题】
足式机器人在地面行走的过程中往往存在多个接触点,这些与地面的直接接触会影响整个机器人的稳定性和控制效果。所以,如果想要适应复杂动态的地形场景,如何实现多接触情况下的自适应运动控制成为一个现实问题。
传统机器人控制方法通常采用离线规划多接触运动,然后用控制器来跟踪。但在现实世界中部署会面临环境变化和状态漂移,这些扰动会造成预先规划的运动变得无效,需要重新规划。

滚动时域规划(RHP)是一个有前景的解决方案,这种方法旨在根据机器人的状态和环境不断更新可立即执行的最优动作。
传统滚动时域规划框架通常使用精确的动态模型来计算整个规划视界,但是使用准确的模型规划预测视界可能会带来高昂的计算成本,特别是当需要考虑较长的规划视界和复杂动力学时。
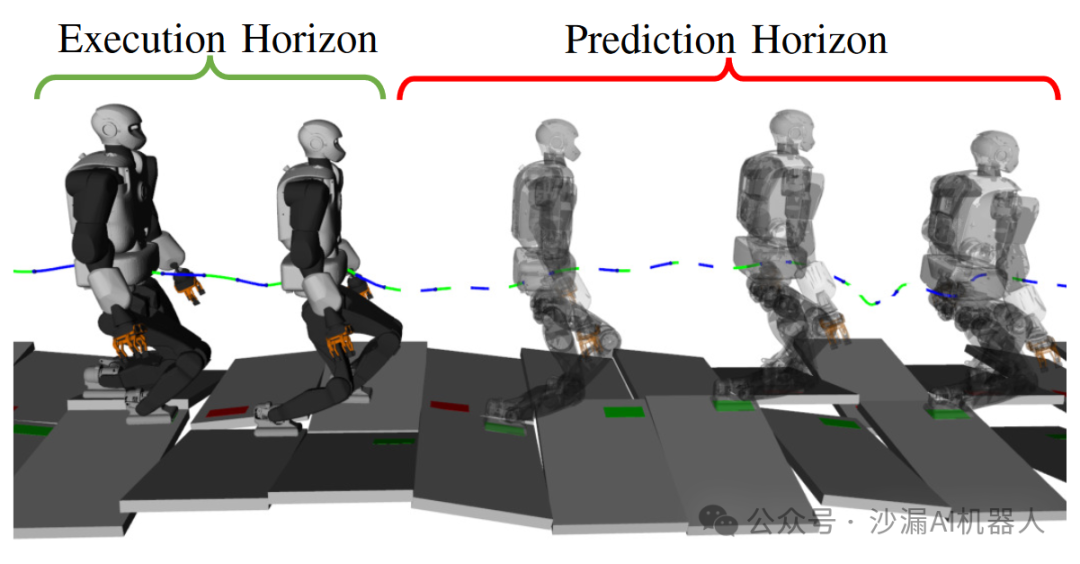
如上图所示,滚动时域规划(RHP)的规划视界通常由两部分组成:1)执行视界,用于规划立即执行的运动;2)预测视界(未执行),用于展望未来。预测视界是价值函数的近似值,它通过告知执行视界中做出的决策是否有助于完成任务来指导执行视界。
【核心思路】
本文提出了两种实现多接触运动质心轨迹在线滚动时域规划的方法,核心思想是通过寻找计算效率高的值函数近似值来降低计算复杂度。
主要创新部分如下:
具有多级模型保真度的滚动时域规划:通过在考虑凸松弛模型的同时计算预测视界中的轨迹来近似值函数;
局部引导的滚动时域规划(LG-RHP):根据当前机器人状态、目标位置和环境模型学习一个预言机来预测局部目标(完成给定任务的中间目标状态),基于局部目标构建局部值函数来指导短期RHP规划执行视界以实现预测的局部目标。
下面是核心过程的详细介绍:
1.多级模型保真度的滚动时域规划
相比于传统RHP方法,具有多级模型保真度的滚动时域规划方法在预测视界内采用凸动力学模型和固定接触时间甚至是考虑单点接触的脚来降低复杂度。
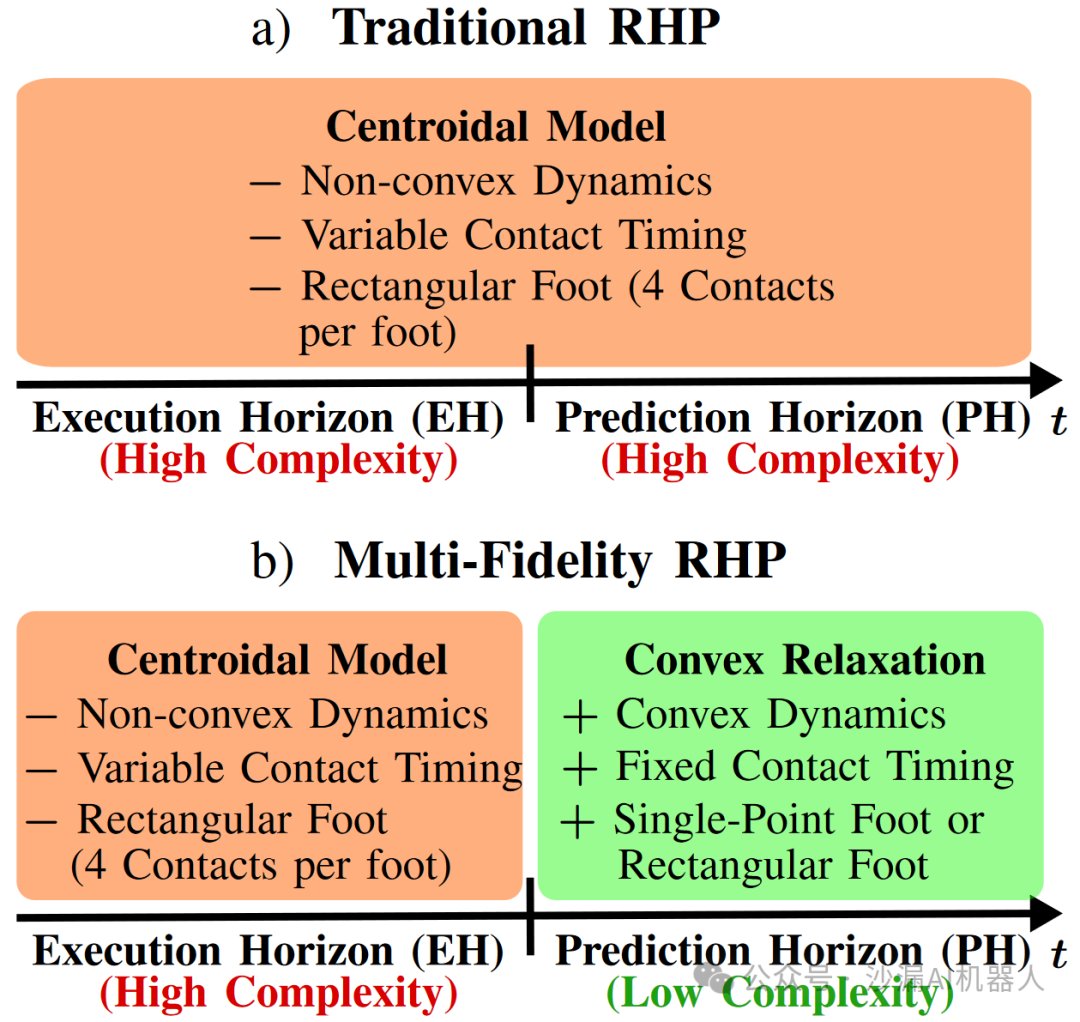
采用质心动力学模型的凸松弛来进行值函数的逼近,下面是三种具有不同凸松弛的候选多保真RHP:
1)线性质心动力学:预测视界仅考虑线运动定义的线性质心动力学,消除角动力学引入的非凸性;
2)具有矩形接触的凸角动力学:仅考虑角动力学的凸近似。非凸性主要来自于接触力矢量与其力臂叉乘所产生的双线性项,将每个双线性项近似为两个有界二次项的差以及两个凸信赖域的约束即可变为凸近似(虽然额外引入了两个辅助变量增加了维度);
3)点接触的凸角动力学:为了减少角动力学凸松弛的维度,将矩形脚表示为点接触的脚,并应用与2中同样的凸松弛方法。
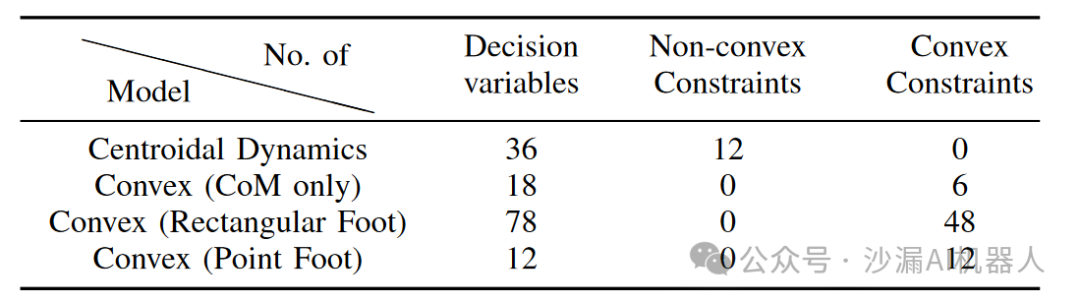
下图是质心动力学模型和三种凸松弛模型的复杂性:
2.局部引导的滚动时域规划
局部引导的RHP,用一个学习模型来近似值函数。核心思想是学习一个预言机,它可以根据机器人的初始状态、最终目标和环境模型来预测完成给定任务的局部目标。然后这些目标用于构建指导执行视界规划的局部值函数。
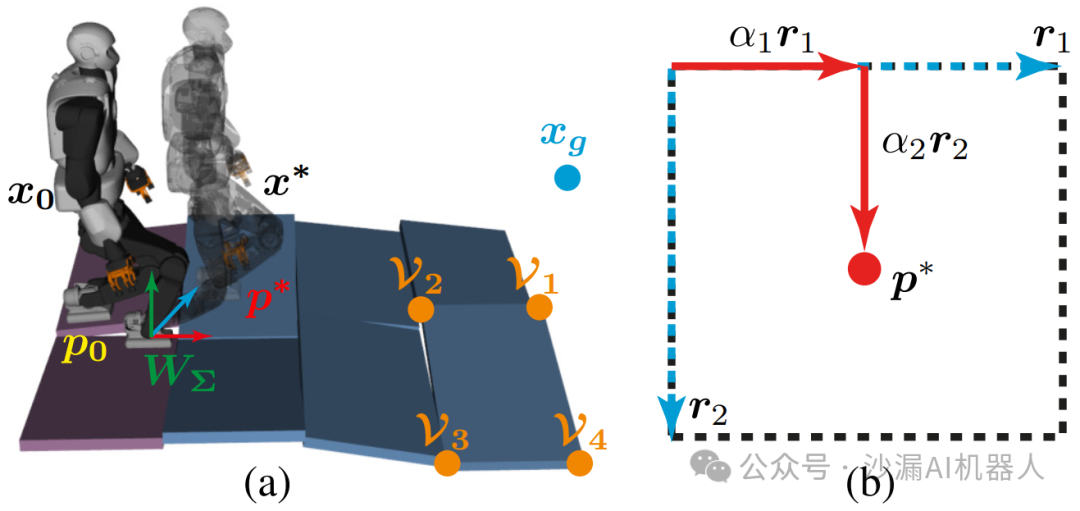
预言机旨在预测迈出一步的目标配置,其中包括:目标质心状态、摆动脚要达到的目标接触位置、构成一个迈步的三种相位目标相位切换时间。
预言机考虑的输入包括:摆动脚指示器(告诉哪只脚将重新定位其位置)、初始质心状态、摆动脚的初始接触位置、环境模型的局部预览(即当前迈步到未来n个迈步将着地的接触面顶点的位置)、最终目标状态。
使用具有4个隐藏层的紧凑型神经网络模型对预言机进行建模,每层包含256个具有ReLu激活函数的神经元。
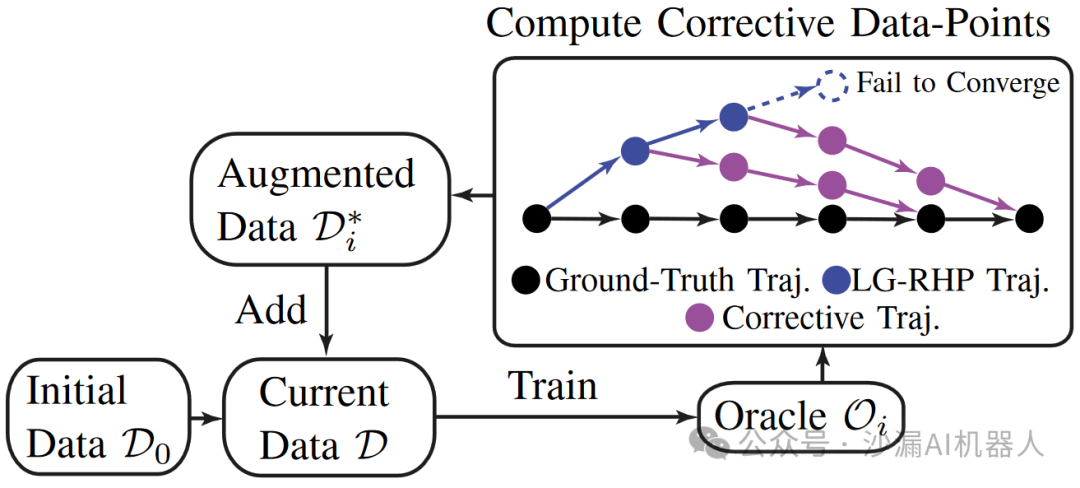
采用增量训练方案,通过逐步增加数据点来提高预测精度,以展示从导致收敛失败的状态中恢复的行动。具体过程为:每次迭代训练中,基于整合了初始数据集和增强数据集的数据集来训练预言机。
增强数据集添加了由长视距RHP计算的恢复动作(紫色节点),从LG-RHP(蓝色虚线)未能收敛之前1到3个周期的发散状态(蓝色节点)开始,直到周期与真实轨迹(黑色节点)对齐。增量训练方案的流程如下图所示:
【实验结果】
实验分为仿真实验和真机实验。在一组多接触场景中评估多保真RHP和局部引导RHP的计算性能,考虑中等坡度地形(5-12度)和大坡度地形(17-25度)的两种地形。
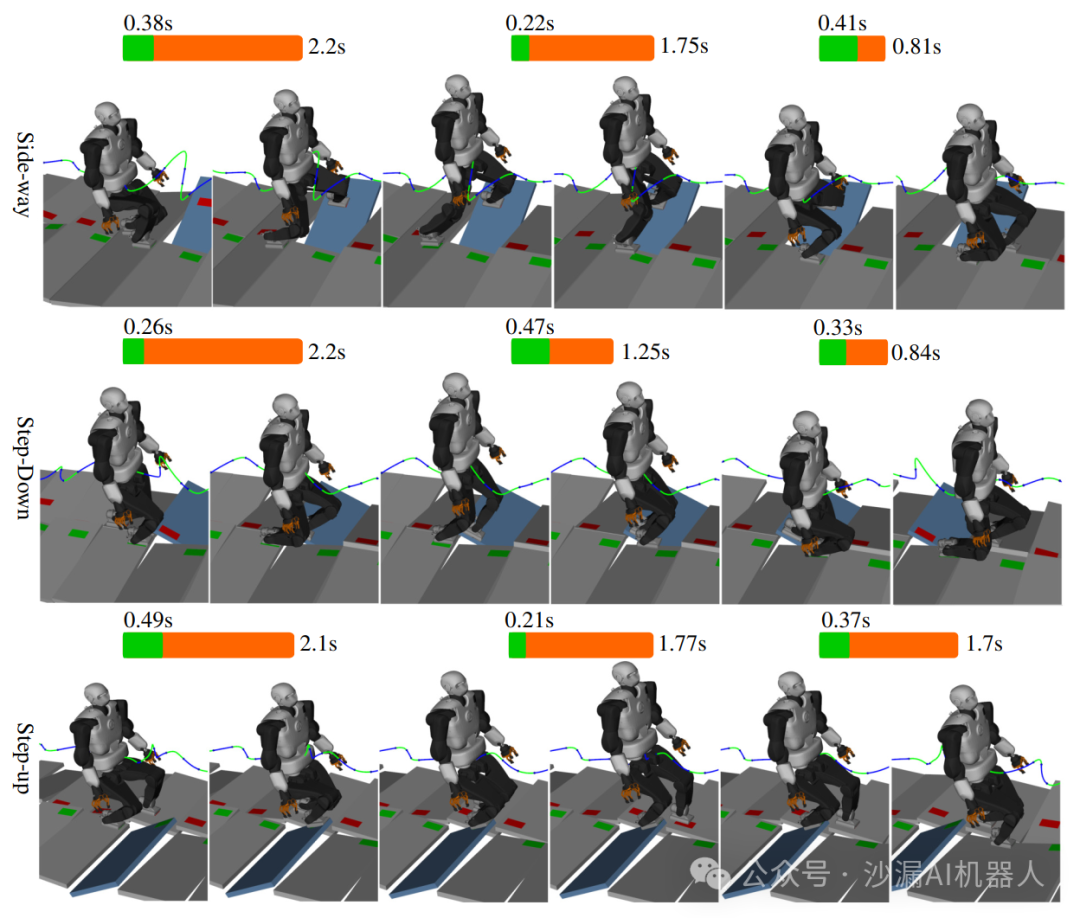
在中等坡度地形中,根据离线和在线环境中的序列成功率和周期成功率来评估每个RHP的性能(计算能否收敛)。如果所选的RHP框架可以计算该序列中所有周期的运动规划,就说明该序列成功,定义每个序列最多包含28个周期。此外,仿真实验中还列出了各种RHP方法的平均计算时间。


在大坡度地形中,机器人无法保持静态稳定性,必须动态穿越地形。定义每个序列从前瞻视界内捕获大坡度时的周期开始,并在机器人离开大坡度时的周期结束。对比过程与中等坡度地形的情况相同,以此来证明计算性能的优越性。
最终结果表明,多保真RHP通过放宽预测视界内的模型精度可以实现在线计算,局部引导RHP在缩短规划周期的情况下实现了最佳的在线收敛率。
论文视频如下:


















 8142
8142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











