




【基本信息】
论文标题:Iterative Learning of Human Behavior for Adaptive Gait Pattern Adjustment of a Powered Exoskeleton
发表期刊:IEEE Transactions on Robotics (TRO)
发表时间:2022年2月7日
【访问链接】
论文:https://ieeexplore.ieee.org/document/9705479
【科学问题】
对于康复外骨骼机器人来说,步行辅助大多是通过给定的预定义步态轨迹来控制的,因为对于完全性脊髓损伤的人来说,下肢的运动功能完全丧失,既没有办法采集患者自己的步态轨迹,也无法使用肌电传感器采集肌电运动信号(EMG) 来获得运动意图。同时,由于患者的感觉功能丧失,其下肢在运动过程中无法感受温度、力和皮肤接触情况,导致无法获得运动的反馈信号。
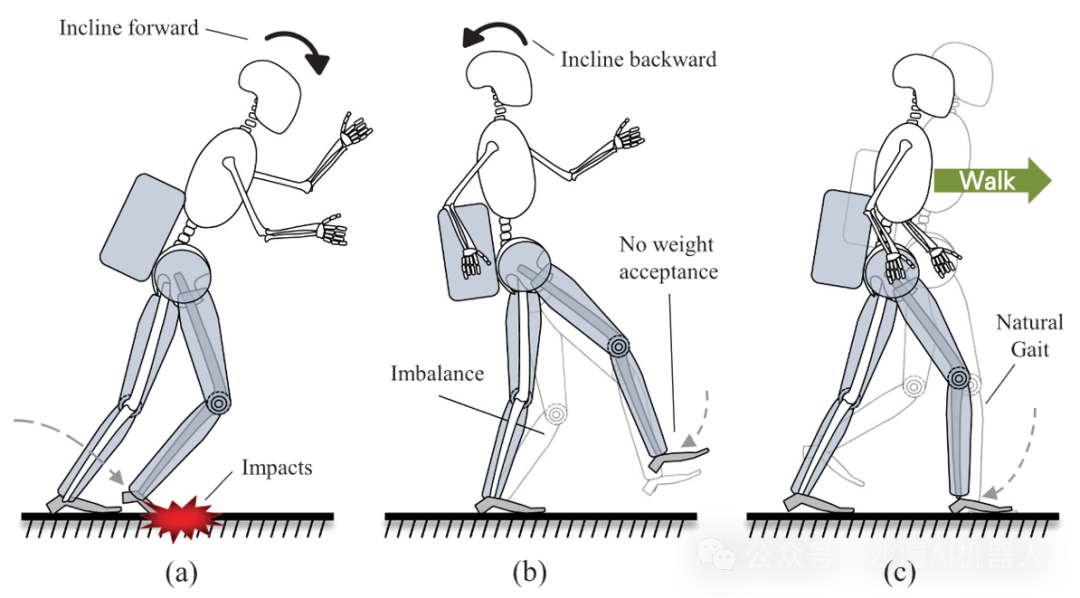
然而,预定义的步态模式导致的一个重要问题就是运动过程相对固定,缺少对运动状态(尤其是运动姿态)的自适应过程。例如:身体前倾会导致过早地接触地面(如图(a)所示),脚在摆动时碰撞到了地面;身体向后倾斜导致延迟接触地面(如图(b)所示),摆动腿会在悬空的情况下切换为支撑状态。
 解决这个问题的一种方法是对步态轨迹进行参数化,即为每个关节轨迹定义一个可参数调整的数学函数。
解决这个问题的一种方法是对步态轨迹进行参数化,即为每个关节轨迹定义一个可参数调整的数学函数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











