







论文:Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
本文翻译自论文: 迈向高效的生成式大语言模型服务:从算法到系统的调查
发表时间: 世界标准时间 2023 年 12 月 23 日星期六 11:57:53
1. 简介
我们提供深入的分析,涵盖一系列解决方案,从尖端算法修改到系统设计的突破性变化。该调查旨在全面了解高效LLM服务的现状和未来方向,为研究人员和从业者克服有效LLM部署的障碍提供宝贵的见解,从而重塑人工智能的未来。
LLMs前所未有的成功也带来了一些挑战,最值得注意的是,它们在服务期间的强大计算要求。巨大的模型尺寸和复杂性,加上对大量计算资源的需求,阻碍了它们在现实应用中的广泛部署。这些模型的资源密集型性质引起了人们对能源消耗、可扩展性和可访问性的担忧,阻碍了它们在没有像大公司这样丰富的计算资源的更广泛的社区中采用。
对研究界为应对这一挑战而提出的现有多方面策略进行了详尽的探索。我们对整个解决方案进行了深入研究,从算法创新到新颖的系统架构,所有这些都旨在优化大型语言模型的推理过程。
1.1 目标
全面概述LLM服务和推理的最新进展。我们将根据现有技术的基本方法对现有技术进行系统回顾和分类,突出它们的优点和局限性。该调查将涵盖广泛的方法,包括解码算法、架构设计、模型压缩、低位量化、并行计算、内存管理、请求调度和内核优化。
1.2 结构
-
第2部分介绍了LLM服务的背景信息。
-
第3节包括我们对高效LLM服务的现有方法的分类,并从两个方面重新审视这些相关工作:
-
第4节中列出了一些具有代表性的LLM服务框架,进行了分析。
-
第5节讨论LLM服务系统的基准。
-
第6节阐明了本次调查与其他相关文献之间的联系。
-
第7节中提出了一些有希望的探索方向,以提高生成式LLM服务效率,以激励未来的研究。
2. 背景
2.1 transform结构的LLM
2.2 GPU和其它加速器
除了 GPU 之外,还探索了用于LLM部署的大量硬件平台,包括 CPU(Shen 等人,2023;int,2023)、移动和边缘设备(Dettmers 等人,2023b)、ASIC(Peng 等人,2023b;int,2023)、ASIC(Peng 等人,2023b;int,2023)。 Zhou 等人,2022c),以及 TPU 等专用加速器(Jouppi 等人,2023), FPGA (Yemme 和 Garani, 2023 年)以及来自不同制造商的其他新兴 AI 芯片(例如 Apple M2 Ultra(Lai 等人,2023 年)、AWS Inferentia (aws, 2023 年) 、SambaNova (sam, 2023 年) 、Cerebras(Dey 等人) al, 2023),Graphcore IPU (gra, 2023 ) )。
这项调查主要强调了以 GPU 使用为基础的研究
2.3 LLM inference
2.4 挑战
- 性能
- 高效的大型语言模型推理需要实现低延迟和快速响应时间,特别是在聊天机器人、虚拟助手和交互式系统等实时应用程序中。平衡模型复杂性与推理速度是一项关键挑战,需要优化算法和系统架构,以在不影响准确性的情况下最大限度地缩短响应时间。
- 内存占用和模型大小
- 由于大型语言模型的大小和包含的大量参数,因此需要大量的内存。在内存受限的设备上部署此类模型提出了挑战,需要开发有效的模型压缩技术和系统优化,以在不牺牲性能的情况下减少内存占用。
- 可扩展性和吞吐量
- 推理系统在生产环境中经常面临不同级别的请求负载。确保可扩展性和高吞吐量以有效处理多个并发请求需要并行计算、请求调度和其他系统级优化,以便跨资源有效分配计算工作负载。
- 硬件兼容性和加速
- 有效利用硬件资源对于大型语言模型推理至关重要。使LLM模型适应不同的硬件平台和架构,包括 CPU、GPU 和专用加速器,需要硬件感知的算法设计和优化,以充分发挥底层硬件的潜力。
- 准确性和效率之间的权衡
- 优化LLM推理的效率有时可能涉及模型准确性的权衡。在模型大小、计算复杂性和性能之间取得适当的平衡是一项具有挑战性的任务,需要仔细考虑和评估各种算法和系统级技术。
3. 分类
提高LLM服务效率的努力大致可以分为算法创新和系统优化两类,下面将分别进行讨论。
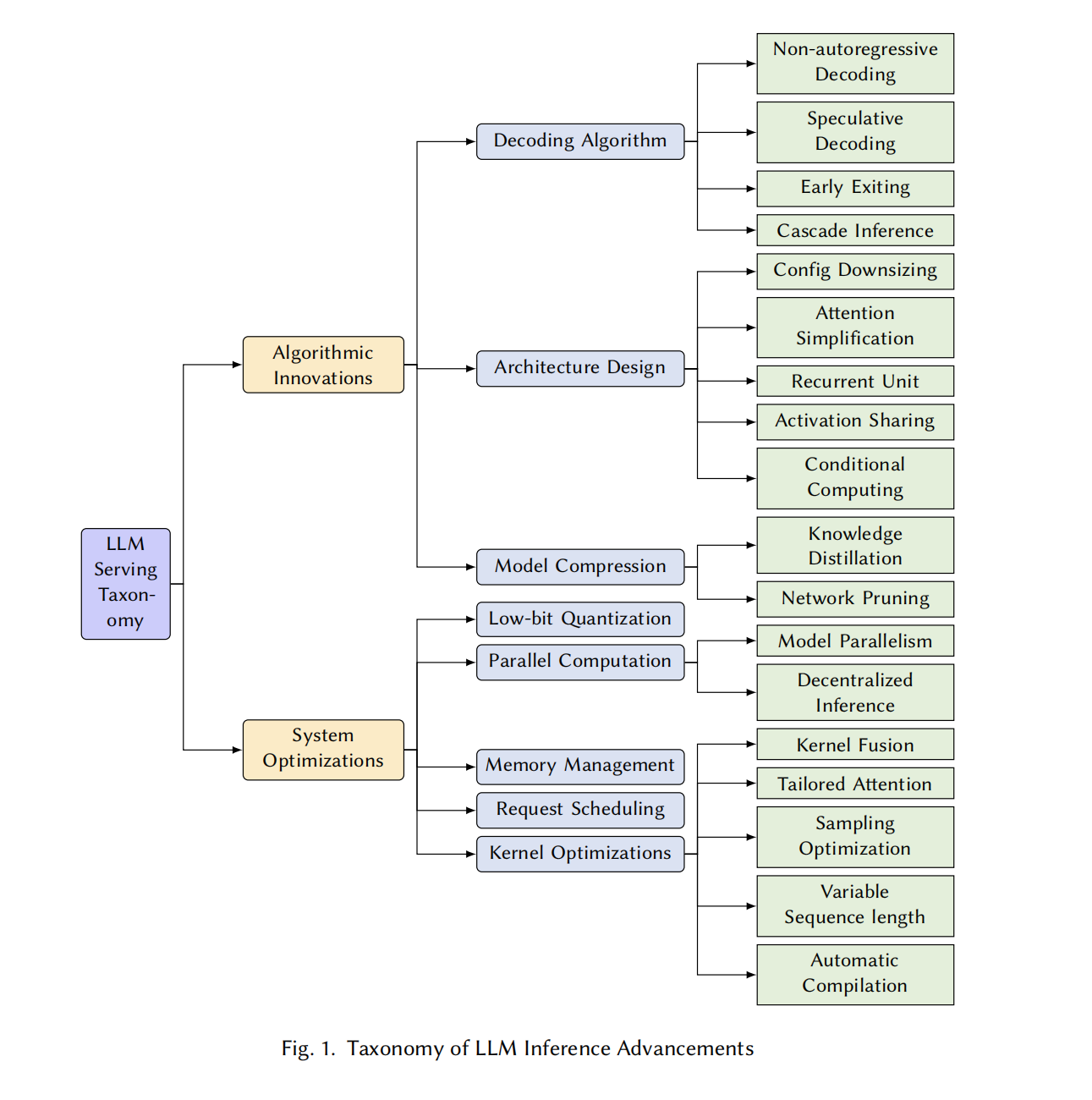
3.1 算法创新
优化语言模型推理效率而提出的各种算法和技术进行了全面分析。这些工作旨在通过算法改进来解决大规模 Transformer 模型的本机性能缺陷。
3.1.1 Decoding Algo
回顾如图2所示的新颖解码算法,这些算法优化了LLMs的推理过程。这些算法寻求降低计算复杂度并提高生成任务期间语言模型推理的整体效率。
- Non-autoregressive decoding
- 非自回归解码。现有LLMs的一个主要限制是默认的自回归解码机制,该机制会一一顺序生成输出令牌。为了解决这个问题,一个代表性的工作是放弃自回归生成范式并并行解码输出标记。非自回归解码(Gu et al, 2018;Guo et al, 2019b;Ghazvininejad et al, 2019)首次提出用于机器翻译加速,通过在解码过程中打破单词依赖性并假设一定程度的条件独立性。为了缓解翻译质量的下降,一些后续研究,如半自回归解码(Ghazvininejad et al, 2020),进一步扩展这些非自回归方法,通过对输出依赖关系进行建模来达到自回归模型质量(Gu and Kong, 2021; Zhan 等人,2023)或迭代地细化输出令牌(Lee 等人,2018)。块式并行解码(Stern 等人,2018)将单个前馈层插入到基础LLM中,以并行预测多个未来位置,然后退回到由基础模型验证的最长前缀。然而,这些方法需要昂贵的成本来重现具有新依赖项的新LLM或调整原始LLM的部分层,而这并不总是可能的。最近的一些努力致力于在一个解码步骤中生成多个令牌,而无需对模型进行任何训练或修改。并行解码(Santilli 等人,2023)将贪婪自回归解码重新构建为可并行求解的非线性方程系统,利用 Jacobi 和 Gauss-Seidel 定点迭代方法进行快速推理。 有人提出对非自回归翻译进行彻底的调查(Xiao 等人,2023b),以总结该方向的最新进展。到目前为止,由于没有意识到输出标记之间的条件依赖性,尽管解码速度有所提高,但大多数非自回归方法的输出质量仍然不如自回归方法可靠。
- Speculative decoding.
- 推测性解码。
- Early exiting
- 提早退出
- Cascade inference
- 级联推理
3.1.2 Architecture Design
架构设计上的优化
-
Configuration downsizing
- 配置缩小:为了降低LLM推理的计算成本,一种直接的方法是缩小模型配置,例如使用浅层编码器(Goyal et al, 2020;Modarressi et al, 2022)或解码器(Kasai et al, 2020) 、权重共享和词汇量缩减(Shi 和 Knight,2017)。然而,减少模型参数的数量也会影响下游任务的性能。
-
Attention simplification:
-
注意力简化:与自注意力计算相关的一项突出挑战是计算复杂性 𝒪(L2) ,与输入序列长度成二次方缩放 L 。人们提出了许多 Transformer 变体(Tay 等人,2023)来将标准注意力简化为非常长序列任务的更有效替代方案,例如稀疏化(Zaheer 等人,2020)、核化(Katharopoulos 等人,2020)和分解(Wang 等人,2020a)。最近,有一种趋势是借用先前注意力简化方法的思想,将它们概括和组合,以缩短上下文并减少 KV 缓存的大小以及注意力复杂度,同时解码质量略有下降(例如,滑动窗口注意力(Jiang 等人,2023a;Zhang 等人,2023c)、基于哈希的注意力(Pagliardini 等人,2023)、扩张注意力(Ding 等人, 2023))。这些方法的一类是上下文压缩,通过将上下文压缩为更少的软令牌(例如,替换为摘要令牌(Chevalier 等人,2023)或地标令牌(Mohtashami 和 Jaggi,2023),利用额外的自动编码器方案(Liu 等人,2023) 2023c;Ge 等人,2023a)) 或根据不同的重要性指导直接删除或改写不重要的上下文标记(Li 等人) al, 2023a;Jiang et al, 2023b;Mu et al, 2023;Fei et al, 2023)(或称为语义压缩)。例如,自适应稀疏注意力(Anagnostidis et al, 2023)采用基于学习的方法来动态消除每个标记的无信息上下文标记。剪刀手(Liu et al, 2023a)和 H 2 O (Zhang et al, 2023d) 选择一些可能对未来解码过程产生重大影响的重要令牌并保存其 KV 缓存。 StreamingLLM (Xiao et al, 2023a) 评估初始标记并通过滑动窗口维护它们,这也类似于之前的工作 (Beltagy et al, 2020)。 FastGen(Ge et al, 2023b)允许不同的注意力头自适应地采用不同的强调模式。表 1 说明了四种代表性方法及其应用的稀疏注意力模式。然而,由于上下文不完整,这些方法在注意力分布更复杂的实际工作负载中可能会面临不可避免的信息丢失。
-
Activation sharing
- 激活共享:另一个方向是共享中间激活以提高注意力计算效率。注意力共享方法(Xiao et al, 2019; Wu et al, 2022; Li et al, 2021)观察不同层注意力矩阵分布之间的相似性,并重用这些注意力矩阵以降低计算成本。多查询注意力(MQA)(Shazeer,2019)使不同的头共享一组键和值,以减少增量推理中的内存带宽要求。组查询注意力(GQA)(Ainslie 等人,2023)将单组键和值的限制放宽为多个组,并且每个组与一组查询相结合。它们已被最近的几位公共LLMs成功采用,并展示了其卓越的性能,包括基于 MQA 的模型,例如 Falcon(ZXhang 等人,2023)、PaLM(Chowdhery 等人,2022)、ChatGLM2-6B(cha,2023)和基于 GQA 的模型,如 LLaMA-2(Touvron 等人,2023)和 Mistral-7B(Jiang 等人, 2023a)。
-
Conditional computing:
- 条件计算:稀疏激活的专家混合 (MoE)(Shazeer 等人,2017;Csordás 等人,2023)范例将模型的容量划分为各种“专家”,这些“专家”是较小的神经网络,每个专家专门研究不同的子集。数据。它允许系统根据某些路由机制仅针对给定输入调用必要的专家(Fedus 等人,2022;Lepikhin 等人,2020;Nie 等人,2021;Roller 等人,2021;Zhou 等人,2022a; Santos 等人,2023),而不是对整个大规模模型进行计算,从而提高计算和内存效率(Du 等人, 2022)。例如,TaskMoE(Kudugunta 等人,2021)表明,与令牌级对应物相比,任务级路由能够提高模型的容量,同时提高推理吞吐量。随着LLMs的不断发展,教育部架构脱颖而出,成为确保未来LLMs的可扩展性和效率的有前途的途径。同时,MoE的动态特性也要求分布式通信进行特殊的系统优化(He et al, 2022; Nie et al, 2023; Rajbhandari et al, 2022; Hwang et al, 2023; Li et al, 2023b; Huang)等人,2023)和 GPU 内核实现(Gale 等人,2023;Zheng 等人,2023a)以促进MoE 推理效率。
-
Recurrent unit
-
循环单元:尽管循环神经网络 (RNN)(例如 LSTM(Sak 等人,2014))往往难以捕获序列中的长期依赖性(Khandelwal 等人,2018),但仍然有几种使用循环单元的方法取代 Transformer 模块并在推理过程中实现线性计算和内存复杂度,例如 RWKV (Peng et al, 2023a) 和 RetNet (Sun et al, 2023a)。具体来说,与之前的方法不同,这些最近的探索主要建立在线性注意力(即线性 Transformer(Katharopoulos 等人,2020)、Attention Free Transformer(Zhai 等人,2021))表示的基础上。改革开放后,他们克服了困难 𝒪(L2) 通过使用线性递归单元对令牌之间的交互进行建模来解决注意力瓶颈(例如,状态空间模型(Gu et al, 2021; Mehta et al, 2022; Fu et al, 2022; Gu and Dao, 2023),LRU(Orvieto et al, 2023)),更容易维护可并行的训练属性。他们的设计还由各种位置编码模块(Su 等人,2021)、指数衰减机制(Oliva 等人,2017)和一堆 token-wise 非线性 MLP(Yu 等人,2022b;Tolstikhin 等人, 2021)或 GLU(Dauphin 等人,2017)来提高模型表示能力。最近,他们在模型性能和计算效率方面都显示出了有希望的结果。然而,循环单元能否成功取代LLMs的 Transformer 仍然是一个悬而未决的问题(即,特别是对于长序列)。
3.1.3 Model Compression
模型压缩
- 知识蒸馏
- 知识蒸馏:其中一项工作是知识蒸馏,它在大型教师模型的监督下训练小型学生模型。之前在这个方向上的大多数方法都在探索白盒蒸馏(Sanh et al, 2019; Sun et al, 2019; Jiao et al, 2020; Wang et al, 2020b; Gu et al, 2023),这需要访问整个教师模型参数。由于基于 API 的LLM服务(例如 ChatGPT)的出现,一些黑盒蒸馏模型引起了广泛关注,例如 Alpaca(Taori 等人,2023)、Vicuna(Chiang 等人,2023)、WizardLM(Xu)等人,2023c)等等(Peng 等人,2023c;Zhu 等人,2023a)。与原始的LLMs (例如 GPT-4(OpenAI,2023))相比,这些模型通常具有较少的模型参数,但在各种下游任务上表现出了良好的性能。
- 网络剪枝
- 网络剪枝:网络剪枝方法(Sanh et al, 2020; Michel et al, 2019; Sanh et al, 2020)在过去几年中得到了广泛的研究,但并非所有方法都可以直接应用于LLMs 。必须考虑与再训练相关的潜在过高的计算成本,并评估修剪是否会根据底层系统的实现在推理效率方面产生明显的收益。最近的一些方法(Ma 等人,2023;Santacroce 等人,2023;Fan 等人,2019;Kurtic 等人,2023)在LLMs上应用结构修剪方法,删除整个结构化LLM组件,从而促进高效的 GPU 加速。例如,Deja Vu (Liu et al, 2023f) 在上下文稀疏假设的指导下切断了特定的注意力头和 MLP 参数,而不修改预先训练的模型。非结构化方法也取得了一些最新进展(Frantar 和 Alistarh,2023;Xu 等人,2023a;Sun 等人,2023b;Valicenti 等人,2023;Belcak 和 Wattenhofer,2023),通常可以实现 50-60% 的稀疏度LLM压缩。值得注意的是,它们可以进一步推广到半结构化 N:M 稀疏性(即 2:4 和 4:8)(Mishra 等人,2021),从而通过 NVIDIA 稀疏张量核心的加速实现显着的推理加速。 LoSparse (Li et al, 2023d) 和 DSFormer (Chand et al, 2023) 使用低秩分解通过小型密集和稀疏半结构化矩阵来近似模型权重。 Flash- LLM (Xia 等人,2023)通过为使用张量核心的非结构化修剪提供内存高效的 SpMM 实现来放宽这一要求。 PowerInfer (Song et al, 2023) 假设这些稀疏激活的神经元的倾斜访问,并提出了 GPU-CPU 混合推理引擎,使 GPU 和 CPU 处理不同的神经元。
3.2 系统优化
3.2.1 low-bit quantization
低比特量化
3.2.2 Parallel computation
并行计算
- 模型并行
- 模型并行性:大多数模型并行性方法首先是为了大规模DNN 的分布式训练而提出的,特别是基于Transformer 的模型。例如,张量模型并行性(Shoeybi 等人,2019)(TP)将模型层(例如注意力、FFN)从内部维度(例如头部、隐藏层)拆分为多个部分,并将每个层部署在单独的设备上(例如,图形处理器)。它可以通过并行计算显着降低推理延迟,广泛应用于同一台机器内的多个GPU,尤其是具有高速NVLink连接的场景。 PaLM 推理(Pope 等人,2023)通过涉及 2D 张量并行性(Van De Geijn 和 Watts,1997)扩展了大规模 Transformer 推理上的 TP,并声称大型集群(超过 256 个设备)的理论通信复杂性较低。对于只有一个键和值的多查询注意力,它进一步涉及到混合张量分区策略的数据并行性。管道模型并行性(Narayanan 等人,2021)(PP)跨多个设备按顺序排列模型层。每个设备负责一个由多个连续模型层组成的管道阶段。虽然 PP 可以显着增加每单位时间处理的输入数量(吞吐量),但它并不会像 TP 那样本质上减少处理单个输入从开始到结束所需的时间(延迟)。序列并行(SP)有各种不同的设计和实现,但其LLM推理的关键思想是通过沿序列长度维度将长序列的处理拆分到多个 GPU 上来分配计算和存储负载(Liu 等人,2023g)。 不同的并行技术会带来不同程度的通信开销和计算延迟(Isaev 等人,2023)。为了实现最佳性能和资源利用,自动并行性已通过先前的分布式训练方法得到了广泛研究(例如,Alpa(Zheng 等人,2022)、FlexFlow(Jia 等人,2019b;Unger 等人,2022)、Galvatron(Miao)等人,2023b))。通过替换其成本模型以适应 Transformer 模型(Narayanan 等人,2023)的自回归推理的可预测运行时间,可以轻松地将以前的自动搜索算法(例如动态规划、整数线性规划)应用于LLM服务(例如、AlpaServe(Li 等人,2023e)、FlexFlow-Serve(fle,2023a)、SpotServe(Miao 等人, 2024)) 并确定最有效的并行策略,无需人工干预。还有一些方法(Aminabadi 等人,2022;Sheng 等人,2023b;Miao 等人,2023a;Alizadeh 等人,2023;Guo 等人,2023)使卸载技术能够使用更大但更慢的内存(例如 CPU DRAM) )除了有限的设备内存(例如GPU DRAM)之外,还可以保存模型参数和KV缓存。
- 分散推理
- 分散式推理:该方法涉及模型和数据并行性的组合,其中多个分散式自愿节点协作处理数据并推断输出。这种方法在硬件资源地理分布的场景中特别有用。受众包计算的启发,Petals(Borzunov 等人,2022)使用互联网上的协作商用 GPU 提供 BLOOM-176B 模型。去中心化推理为解锁被忽视的消费级 GPU 来运行LLMs开辟了新方向,但也面临着一些实际挑战,例如设备异构性(Jiang 等人,2023d)、有限的计算和内存容量、低带宽网络( Borzunov 等人,2023),容错和隐私保护(Tang 等人,2023)。
3.2.3 Memory management
内存管理
高效的内存管理仍然是LLM服务中面临的首要挑战,特别是考虑到 transform 架构固有的内存密集型特性。随着对长序列推理的需求不断增长,与模型权重和其他激活所需的工作空间相比,KV 缓存的内存占用成为主要优化目标。随着KV高速缓冲存储器在增量解码期间动态且不可预测地增长和收缩,简单的方法(例如,FasterTransformer)使用最大序列长度假设来预分配连续的存储器块。它严重浪费内存:
1)具有不同请求长度的输入批次和
2)并行生成多个输出序列的复杂解码场景(例如,波束搜索、并行解码)。
vLLM(Kwon 等人,2023)提出了分页注意力机制,将 KV 缓存划分为不连续的内存块,并显着提高批量大小和吞吐量。
SpecInfer (Miao et al, 2023a) 提出了树关注和*深度优先树遍历,*以消除共享相同前缀的多个输出序列的冗余 KV 缓存分配。
LightLLM (lig, 2023 )采用更细粒度的令牌级内存管理机制来进一步减少内存使用。然而,这种碎片内存管理机制的开销带来了新的挑战。特别是对于采用其他优化来提高批处理大小的情况,这些细粒度内存管理方法可能只能提供边际吞吐量优势,同时大大增加推理延迟。 显然, LLM推理中的内存减少与其他算法创新和系统级优化密切相关。虽然有些可能适用于特定的工作负载,但它们可能会相互抵消,导致整体性能下降。在LLM推理系统的内存效率和计算性能之间取得适当的平衡仍然是该领域的一个开放且紧迫的挑战。
3.2.4 Request scheduling
请求调度
有效调度传入的推理请求对于优化LLM服务至关重要。本节回顾了请求调度算法,这些算法可以最大限度地提高资源利用率,保证响应时间在延迟服务级别目标(SLO)内,并有效地处理变化的请求负载。 LLM服务的请求调度与通用 ML 服务技术具有共同点,因为两者都旨在有效管理传入请求并优化资源利用率。这些常见方面包括动态批处理(Ali 等人,2020)、抢占(Han 等人,2022)、优先级(Ng 等人,2023)、交换(Bai 等人,2020)、模型选择(Gunasekaran 等人,2022) 、成本效率(Zhang et al,2019)、负载平衡和资源分配(Weng et al,2022)。然而,由于其独特的特点, LLM服务也带来了独特的挑战,例如海量模型大小、迭代自回归解码机制、未知变量输出长度和上下文信息的状态管理。
3.2.5 内核优化
- 内核融合
- 内核融合:为了减少内核启动和内存访问的开销,内核融合被以前的DNN 框架和编译器广泛采用。由于LLM推理不需要后向计算,因此存在更多的内核融合机会。几种当代的 Transformer 推理引擎(例如,FasterTransformer(fas,2021)、TenTrans(Wu 等人,2021)、TurboTransformers(Fang 等人,2021)、LightSeq(Wang 等人,2020c)、ByteTransformer(Zhai 等人,2023) )和编译器(例如 Welder (Shi et al, 2023))建议融合1) 具有相同形状的 GEMM(例如,查询、键和值的三个线性变换),2) 添加其他非 GEMM 内核的偏差,例如残差连接、层归一化和激活函数(例如 ReLU)。其中,融合多头注意力核的优化已被广泛探索,并将在以下方面进行讨论。
- 定制注意力
- 定制注意力:为了使注意力操作在GPU上高效运行,专门针对注意力计算定制或剪裁GPU内核至关重要。例如,cuDNN 提供了融合多头注意力内核 API(cud,2023)。与此同时,一些实现已经开源,以提高性能。由于特殊的自回归解码机制,这些可以大致分为两类。一个是第一次迭代(即初始/预填充/上下文/提示阶段),它并行处理来自输入提示的所有标记。例如,xFormers(Lefaudeux 等人,2022)将在线 softmax 技巧(Rabe 和 Staats,2021;Milakov 和 Gimelshein,2018;Choi 等人,2022)扩展到使用 CUTLASS(cut,2023)的整个注意力计算。另一种是用于以下迭代(即增量/解码/生成阶段),并且内核每次迭代仅生成一个输出令牌。对于自回归解码,常见的做法是保存先前计算的键和值,以便在生成新令牌时只需要单个查询来计算,而不是重新运行整个序列。该领域优化的主要方向是最大化线程占用并最小化设备上高带宽内存(HBM)访问(即使用共享内存或寄存器(Chen et al, 2021a))。它们通常在批量大小和头数维度上进行并行化(例如,FasterTransformer)以分配工作负载。有些通过将 KV 缓存划分为块来进一步实现序列长度维度的并行化,但最终需要减少块方式的结果,例如 FlashDecoding(Tri Dao,[n. d.])。 随后的工作 FlashDecoding++(Hong 等人,2023)通过引入预先已知的统一最大值来消除部分 softmax 的同步。为了更好地利用线程,需要根据工作负载选择合适的并行维度。
- 采样优化
- 采样优化:采样算法的选择可以极大地影响LLM生成质量。默认的贪婪采样总是选择概率最高的标记。并行采样技术(例如波束搜索)通过在每次迭代中维持固定数量(即波束宽度)的最高得分序列来有效地解码近似最优序列。各种随机抽样技术(例如,top- k (Fan 等人,2018),顶- p (Holtzman 等人,2019)、温度控制(Keskar 等人,2019))已被提议引入随机性以实现更多样化的输出。然而,他们仍然面临着一些实际的系统挑战。一是冗余KV缓存增加的内存压力(第3.2.3节),二是LLM词汇量大(数万)带来的采样效率问题。例如,LightSeq(Wang et al, 2020c)提供了一种高效的分层实现,将词汇表划分为 k 组,使用一些 GPU 指令检索每个组内的候选者,然后对这些候选者重新排名以获得最高的 k 代币。
- 可变序列长度
- 可变序列长度: LLM推理的另一个独特挑战是序列的输入长度和输出长度可能不同,而后者是事先未知的。加速推理的一种方法是一次处理一批中的多个序列(第 3.2.4 节)。然而,当一批序列的输入长度可变时,通常使用填充来使它们都具有相同的长度以进行批处理,从而浪费计算和内存资源。为了缓解其中一些低效率问题,可以采用各种策略。打包技术(pac,2020;Zhai et al,2023)将序列存储到连续的内存空间中,无需填充,仅在注意计算之前解包。 Ragged 张量(Fegade 等人,2022)进一步支持使用编译器生成的内核进行最小填充的计算。将序列分入较小的计算粒度(例如,块(Du 等人,2023))也是减少填充令牌的内存使用的可能解决方案。由于初始阶段和增量阶段的混合执行,分桶输入提示(Agrawal et al, 2023)也给内存管理和请求调度带来了新的挑战(§ 3.2.4)。
- 自动编译
- 多数现有的LLM推理系统都利用供应商特定的库作为后端,例如cuBLAS、cuDNN 和CUTLASS,它们提供优化的内核实现。为了进一步提高推理效率,他们还努力在 NVIDIA GPU 上针对特定LLM算子(例如注意力)优化手动编写的内核。尽管有这些工作,使用自动化 DNN 编译器的趋势仍然存在,例如 TVM(即 Unity(Sampson 等人,2022)、Relax(Lai 等人,2023)和 TensorIR(Feng 等人,2023;Ye 等人) ,2023)),MLIR(Katel 等人,2022),JAX(Frostig 等人,2018),OpenAI Triton (Tillet 等人,2019)、TASO(Jia 等人,2019a)和 TorchInductor(Wu,2023)。编译方法可以帮助发现潜在的更高效的算子实现(例如,表达式推导(Zheng et al, 2023b)),更重要的是,有助于适应替代硬件平台,包括移动和边缘设备、CPU、深度学习加速器和其他类型GPU(例如 AMD GPU 和 Apple M2 Ultra)。
4. 软件框架
- 支持张量并行,以实现多 GPU 推理并提高系统性能
- 部分系统学习Orca并实现迭代级调度
- 我们研究了这些系统的注意力内核,并分别在初始阶段和增量阶段介绍了它们的实现。对于初始阶段,他们通常采用批量通用矩阵乘法(GEMM)方法(例如,cuBLAS、torch、Relay),并且有些利用在线 softmax 技巧来减少 HBM 访问(例如,Flash-attention、xFormers)。增量阶段更具挑战性,因为每个令牌生成方案导致计算强度较低。为了提高 GPU 利用率,FasterTransformer 手动将注意力计算(例如,线性投影、位置偏差、点积、softmax 等)融合到单个高性能内核模板中,并涉及多种内核优化技术,例如使用分片内存进行缓存、用于缩减、半矩阵乘法和累加 (HMMA) 的扭曲洗牌指令,具有张量核心和多精度支持。 FlexFlow-Serve 支持推测性解码,并提供基于树的并行解码内核,以零内存冗余和最大线程并行性验证来自多个序列(即来自多个小模型或不同波束或并行采样)的推测令牌。 vLLM 通过将 KV 缓存分区为页面来扩展 FasterTransformer 的融合多头注意力 (MHA) 内核,以消除冗余内存使用,特别是对于并行采样场景。 LightLLM 采取了后续方法,将 KV 缓存划分为更细粒度的 token-wise 部分。
5. benchmark
略
6. 与其他论文的关系
-
在主题上最接近探索更通用的 Transformer 模型和特定领域加速器的设计
- url: https://arxiv.org/abs/2302.14017
-
模型压缩相关论文
- https://arxiv.org/abs/2008.05221
- https://arxiv.org/abs/2209.00099
- https://arxiv.org/abs/2308.07633
-
模型量化
- https://arxiv.org/abs/2303.08302
- https://arxiv.org/abs/2103.13630
-
理解LLM
- https://arxiv.org/abs/2308.04945
- https://arxiv.org/abs/2307.06908
7. 未来方向
略
8. 结论
高效的LLM服务是实现先进人工智能技术民主化的基本一步。这项调查旨在为研究人员、从业者和开发人员提供对现有方法的全面了解,使他们能够在现实环境中部署LLMs时做出明智的决策。通过整合算法和系统的最新研究成果,本调查论文希望在追求高效的LLM服务解决方案方面加快进展并促进创新。


















 2457
2457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











