







(四)Python
4.1字符串
(1)字符串使用
var1 = 'Hello World!'
var2 = "Python Runoob"
print "var1[0]: ", var1[0]
print "var2[1:5]: ", var2[1:5]以上实例执行结果:
var1[0]: H
var2[1:5]: ytho(2)字符串连接
#!/usr/bin/python
# -*- coding: UTF-8 -*-
var1 = 'Hello World!'
print "输出 :- ", var1[:6] + 'Runoob!'(3)转义字符
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \' | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 |
| \xyy | 十六进制数,以 \x 开头,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
(4)字符串运算符
下表实例变量 a 值为字符串 "Hello",b 变量值为 "Python":
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | >>>a + b 'HelloPython' |
| * | 重复输出字符串 | >>>a * 2 'HelloHello' |
| [] | 通过索引获取字符串中字符 | >>>a[1] 'e' |
| [ : ] | 截取字符串中的一部分 | >>>a[1:4] 'ell' |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | >>>"H" in a True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | >>>"M" not in a True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | >>>print r'\n' \n >>> print R'\n' \n |
#!/usr/bin/python
# -*- coding: UTF-8 -*-
a = "Hello"
b = "Python"
print "a + b 输出结果:", a + b
print "a * 2 输出结果:", a * 2
print "a[1] 输出结果:", a[1]
print "a[1:4] 输出结果:", a[1:4]
if( "H" in a) :
print "H 在变量 a 中"
else :
print "H 不在变量 a 中"
if( "M" not in a) :
print "M 不在变量 a 中"
else :
print "M 在变量 a 中"
print r'\n'
print R'\n'以上程序执行结果为:
a + b 输出结果: HelloPython
a * 2 输出结果: HelloHello
a[1] 输出结果: e
a[1:4] 输出结果: ell
H 在变量 a 中
M 不在变量 a 中
\n
\n(4)字符串格式化
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %F 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| <sp> | 在正数前面显示空格 |
| # | 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') |
| 0 | 显示的数字前面填充'0'而不是默认的空格 |
| % | '%%'输出一个单一的'%' |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
(5)三引号
Python 中三引号可以将复杂的字符串进行赋值。
Python 三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
三引号的语法是一对连续的单引号或者双引号(通常都是成对的用)。
>>> hi = '''hi
there'''
>>> hi # repr()
'hi\nthere'
>>> print hi # str()
hi
there 4.2 列表(List)
(1)访问列表值
使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5, 6, 7 ]
print "list1[0]: ", list1[0]
print "list2[1:5]: ", list2[1:5]以上实例输出结果:
list1[0]: physics
list2[1:5]: [2, 3, 4, 5](2)更新列表
#!/usr/bin/python
# -*- coding: UTF-8 -*-
list = [] ## 空列表
list.append('Google') ## 使用 append() 添加元素
list.append('Runoob')
print list注意:我们会在接下来的章节讨论append()方法的使用
以上实例输出结果:
['Google', 'Runoob'](3)删除列表
#!/usr/bin/python
list1 = ['physics', 'chemistry', 1997, 2000]
print list1
del list1[2]
print "After deleting value at index 2 : "
print list1以上实例输出结果:
['physics', 'chemistry', 1997, 2000]
After deleting value at index 2 :
['physics', 'chemistry', 2000](4)列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print x, | 1 2 3 | 迭代 |
(5)列表截取
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'Taobao' | 读取列表中第三个元素 |
| L[-2] | 'Runoob' | 读取列表中倒数第二个元素 |
| L[1:] | ['Runoob', 'Taobao'] | 从第二个元素开始截取列表 |
(6)列表函数&方法
| 序号 | 函数 |
|---|---|
| 1 | cmp(list1, list2) 比较两个列表的元素 |
| 2 | len(list) 列表元素个数 |
| 3 | max(list) 返回列表元素最大值 |
| 4 | min(list) 返回列表元素最小值 |
| 5 | list(seq) 将元组转换为列表 |
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False) 对原列表进行排序 |
4.3 元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
tup1 = ('physics', 'chemistry', 1997, 2000)
tup2 = (1, 2, 3, 4, 5 )
tup3 = "a", "b", "c", "d"(1)访问元组
#!/usr/bin/python
tup1 = ('physics', 'chemistry', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7 )
print "tup1[0]: ", tup1[0]
print "tup2[1:5]: ", tup2[1:5]以上实例输出结果:
tup1[0]: physics
tup2[1:5]: (2, 3, 4, 5)(2)修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的。
# tup1[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2
print tup3以上实例输出结果:
(12, 34.56, 'abc', 'xyz')(3)删除元组
#!/usr/bin/python
tup = ('physics', 'chemistry', 1997, 2000)
print tup
del tup
print "After deleting tup : "
print tup以上实例元组被删除后,输出变量会有异常信息,输出如下所示:
('physics', 'chemistry', 1997, 2000)
After deleting tup :
Traceback (most recent call last):
File "test.py", line 9, in <module>
print tup
NameError: name 'tup' is not defined(4)元组运算符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | 计算元素个数 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| ('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
| 3 in (1, 2, 3) | True | 元素是否存在 |
| for x in (1, 2, 3): print x, | 1 2 3 | 迭代 |
(5)元组截取
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素,如下所示:
元组:
L = ('spam', 'Spam', 'SPAM!')| Python 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'SPAM!' | 读取第三个元素 |
| L[-2] | 'Spam' | 反向读取,读取倒数第二个元素 |
| L[1:] | ('Spam', 'SPAM!') | 截取元素 |
(6)无关闭分隔符
任意无符号的对象,以逗号隔开,默认为元组,如下实例:
#!/usr/bin/python
print 'abc', -4.24e93, 18+6.6j, 'xyz'
x, y = 1, 2
print "Value of x , y : ", x,y以上实例运行结果:
abc -4.24e+93 (18+6.6j) xyz
Value of x , y : 1 2(7)元组内置函数
| 序号 | 方法及描述 |
|---|---|
| 1 | cmp(tuple1, tuple2) 比较两个元组元素。 |
| 2 | len(tuple) 计算元组元素个数。 |
| 3 | max(tuple) 返回元组中元素最大值。 |
| 4 | min(tuple) 返回元组中元素最小值。 |
| 5 | tuple(seq) 将列表转换为元组。 |
4.4 字典(Dictionary)
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }(1)特点
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
(2)访问字典里的值
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print "dict['Name']: ", dict['Name']
print "dict['Age']: ", dict['Age']以上实例输出结果:
dict['Name']: Zara
dict['Age']: 7(3)修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
dict['Age'] = 8 # 更新
dict['School'] = "RUNOOB" # 添加
print "dict['Age']: ", dict['Age']
print "dict['School']: ", dict['School']以上实例输出结果:
dict['Age']: 8
dict['School']: RUNOOB(4)删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。
显示删除一个字典用del命令,如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
del dict['Name'] # 删除键是'Name'的条目
dict.clear() # 清空字典所有条目
del dict # 删除字典
print "dict['Age']: ", dict['Age']
print "dict['School']: ", dict['School']但这会引发一个异常,因为用del后字典不再存在。
(5)字典键的特性
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Name': 'Manni'}
print "dict['Name']: ", dict['Name']2)键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行,如下实例:
#!/usr/bin/python
dict = {['Name']: 'Zara', 'Age': 7}
print "dict['Name']: ", dict['Name']以上实例输出结果:
Traceback (most recent call last):
File "test.py", line 3, in <module>
dict = {['Name']: 'Zara', 'Age': 7}
TypeError: list objects are unhashable(6)字典内置函数&方法
| 序号 | 函数及描述 |
|---|---|
| 1 | cmp(dict1, dict2) 比较两个字典元素。 |
| 2 | len(dict) 计算字典元素个数,即键的总数。 |
| 3 | str(dict) 输出字典可打印的字符串表示。 |
| 4 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 |
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys(seq[, val]) 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
| 5 | dict.has_key(key) 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | dict.keys() 以列表返回一个字典所有的键 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 以列表返回字典中的所有值 |
| 11 | pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 返回并删除字典中的最后一对键和值。 |
4.5 没有指针、枚举、结构体、共同体
(五)Java
5.1数组
(1)声明组数
下面是这两种语法的代码示例:
dataType[] arrayRefVar; // 首选的方法
或
dataType arrayRefVar[]; // 效果相同,但不是首选方法(2)创建数组
Java语言使用new操作符来创建数组,语法如下:
arrayRefVar = new dataType[arraySize];上面的语法语句做了两件事:
- 一、使用 dataType[arraySize] 创建了一个数组。
- 二、把新创建的数组的引用赋值给变量 arrayRefVar。
数组变量的声明,和创建数组可以用一条语句完成,如下所示:
dataType[] arrayRefVar = new dataType[arraySize];另外,你还可以使用如下的方式创建数组。
dataType[] arrayRefVar = {value0, value1, ..., valuek};数组的元素是通过索引访问的。数组索引从 0 开始,所以索引值从 0 到 arrayRefVar.length-1。
public class TestArray {
public static void main(String[] args) {
// 数组大小
int size = 10;
// 定义数组
double[] myList = new double[size];
myList[0] = 5.6;
myList[1] = 4.5;
myList[2] = 3.3;
myList[3] = 13.2;
myList[4] = 4.0;
myList[5] = 34.33;
myList[6] = 34.0;
myList[7] = 45.45;
myList[8] = 99.993;
myList[9] = 11123;
// 计算所有元素的总和
double total = 0;
for (int i = 0; i < size; i++) {
total += myList[i];
}
System.out.println("总和为: " + total);
}
}以上实例输出结果为:
总和为: 11367.373下面的图片描绘了数组 myList。这里 myList 数组里有 10 个 double 元素,它的下标从 0 到 9。

(3)创建、初始化和操纵数组
public class TestArray {
public static void main(String[] args) {
double[] myList = {1.9, 2.9, 3.4, 3.5};
// 打印所有数组元素
for (int i = 0; i < myList.length; i++) {
System.out.println(myList[i] + " ");
}
// 计算所有元素的总和
double total = 0;
for (int i = 0; i < myList.length; i++) {
total += myList[i];
}
System.out.println("Total is " + total);
// 查找最大元素
double max = myList[0];
for (int i = 1; i < myList.length; i++) {
if (myList[i] > max) max = myList[i];
}
System.out.println("Max is " + max);
}
}以上实例编译运行结果如下:
1.9
2.9
3.4
3.5
Total is 11.7
Max is 3.5(4)For-Each 循环
public class TestArray {
public static void main(String[] args) {
double[] myList = {1.9, 2.9, 3.4, 3.5};
// 打印所有数组元素
for (double element: myList) {
System.out.println(element);
}
}
}以上实例编译运行结果如下:
1.9
2.9
3.4
3.5(5)数组作为函数的参数
public static void printArray(int[] array) {
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] + " ");
}
}下面例子调用 printArray 方法打印出 3,1,2,6,4 和 2:
printArray(new int[]{3, 1, 2, 6, 4, 2});(6)数组作为函数的返回值
public static int[] reverse(int[] list) {
int[] result = new int[list.length];
for (int i = 0, j = result.length - 1; i < list.length; i++, j--) {
result[j] = list[i];
}
return result;
}(7)多维数组
String s[][] = new String[2][];
s[0] = new String[2];
s[1] = new String[3];
s[0][0] = new String("Good");
s[0][1] = new String("Luck");
s[1][0] = new String("to");
s[1][1] = new String("you");
s[1][2] = new String("!");s[0]=new String[2] 和 s[1]=new String[3] 是为最高维分配引用空间,也就是为最高维限制其能保存数据的最长的长度,然后再为其每个数组元素单独分配空间 s0=new String("Good") 等操作。
(8)Arrays 类
java.util.Arrays 类能方便地操作数组,它提供的所有方法都是静态的。
具有以下功能:
- 给数组赋值:通过 fill 方法。
- 对数组排序:通过 sort 方法,按升序。
- 比较数组:通过 equals 方法比较数组中元素值是否相等。
- 查找数组元素:通过 binarySearch 方法能对排序好的数组进行二分查找法操作。
具体说明请查看下表:
| 序号 | 方法和说明 |
|---|---|
| 1 | public static int binarySearch(Object[] a, Object key) 用二分查找算法在给定数组中搜索给定值的对象(Byte,Int,double等)。数组在调用前必须排序好的。如果查找值包含在数组中,则返回搜索键的索引;否则返回 (-(插入点) - 1)。 |
| 2 | public static boolean equals(long[] a, long[] a2) 如果两个指定的 long 型数组彼此相等,则返回 true。如果两个数组包含相同数量的元素,并且两个数组中的所有相应元素对都是相等的,则认为这两个数组是相等的。换句话说,如果两个数组以相同顺序包含相同的元素,则两个数组是相等的。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。 |
| 3 | public static void fill(int[] a, int val) 将指定的 int 值分配给指定 int 型数组指定范围中的每个元素。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。 |
| 4 | public static void sort(Object[] a) 对指定对象数组根据其元素的自然顺序进行升序排列。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。 |
5.2 字符串
字符串广泛应用 在 Java 编程中,在 Java 中字符串属于对象,Java 提供了 String 类来创建和操作字符串。
(1)创建
String 创建的字符串存储在公共池中,而 new 创建的字符串对象在堆上:
String s1 = "Runoob"; // String 直接创建
String s2 = "Runoob"; // String 直接创建
String s3 = s1; // 相同引用
String s4 = new String("Runoob"); // String 对象创建
String s5 = new String("Runoob"); // String 对象创建
(2) 字符串长度
public class StringDemo {
public static void main(String args[]) {
String site = "www.runoob.com";
int len = site.length();
System.out.println( "教程网址长度 : " + len );
}
}以上实例编译运行结果如下:
教程网址长度 : 14(3)连接字符串
String 类提供了连接两个字符串的方法:
string1.concat(string2);更常用的是使用'+'操作符来连接字符串,如:
"Hello," + " runoob" + "!"结果如下:
"Hello, runoob!"(4)创建格式化字符串
我们知道输出格式化数字可以使用 printf() 和 format() 方法。
String 类使用静态方法 format() 返回一个String 对象而不是 PrintStream 对象。
String 类的静态方法 format() 能用来创建可复用的格式化字符串,而不仅仅是用于一次打印输出。
System.out.printf("浮点型变量的值为 " +
"%f, 整型变量的值为 " +
" %d, 字符串变量的值为 " +
"is %s", floatVar, intVar, stringVar);你也可以这样写:
String fs;
fs = String.format("浮点型变量的值为 " +
"%f, 整型变量的值为 " +
" %d, 字符串变量的值为 " +
" %s", floatVar, intVar, stringVar);(4)对字符串进行修改
当对字符串进行修改的时候,需要使用 StringBuffer 和 StringBuilder 类。
和 String 类不同的是,StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象。

在使用 StringBuffer 类时,每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象,所以如果需要对字符串进行修改推荐使用 StringBuffer。
由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。
public class RunoobTest{
public static void main(String args[]){
StringBuilder sb = new StringBuilder(10);
sb.append("Runoob..");
System.out.println(sb);
sb.append("!");
System.out.println(sb);
sb.insert(8, "Java");
System.out.println(sb);
sb.delete(5,8);
System.out.println(sb);
}
}以上实例编译运行结果如下:
Runoob..
Runoob..!
Runoob..Java!
RunooJava!
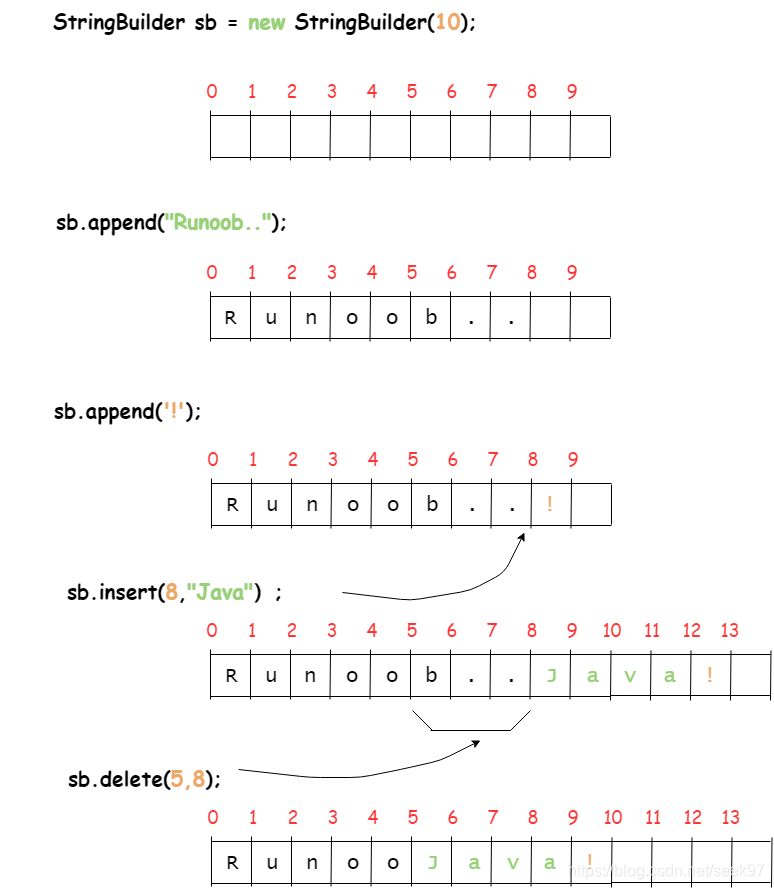
然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。
public class Test{
public static void main(String args[]){
StringBuffer sBuffer = new StringBuffer("教程官网:");
sBuffer.append("www");
sBuffer.append(".runoob");
sBuffer.append(".com");
System.out.println(sBuffer);
}
}以下是 StringBuffer 类支持的主要方法:
| 序号 | 方法描述 |
|---|---|
| 1 | public StringBuffer append(String s) 将指定的字符串追加到此字符序列。 |
| 2 | public StringBuffer reverse() 将此字符序列用其反转形式取代。 |
| 3 | public delete(int start, int end) 移除此序列的子字符串中的字符。 |
| 4 | public insert(int offset, int i) 将 int 参数的字符串表示形式插入此序列中。 |
| 5 | insert(int offset, String str) 将 str 参数的字符串插入此序列中。 |
| 6 | replace(int start, int end, String str) 使用给定 String 中的字符替换此序列的子字符串中的字符。 |
5.3 枚举(和C语言一致)
Java 枚举是一个特殊的类,一般表示一组常量,比如一年的 4 个季节,一个年的 12 个月份,一个星期的 7 天,方向有东南西北等。
Java 枚举类使用 enum 关键字来定义,各个常量使用逗号 , 来分割。
(1)在类外部定义枚举
enum Color
{
RED, GREEN, BLUE;
}
public class Test
{
// 执行输出结果
public static void main(String[] args)
{
Color c1 = Color.RED;
System.out.println(c1);
}
}执行以上代码输出结果为:
RED
注意:它的输出与C不一样,C输出的是枚举的具体值,而Java输出的的枚举的成员名。
(2)内部类中使用枚举
public class Test
{
enum Color
{
RED, GREEN, BLUE;
}
// 执行输出结果
public static void main(String[] args)
{
Color c1 = Color.RED;
System.out.println(c1);
}
}每个枚举都是通过 Class 在内部实现的,且所有的枚举值都是 public static final 的。
(3)迭代枚举元素
enum Color
{
RED, GREEN, BLUE;
}
public class MyClass {
public static void main(String[] args) {
for (Color myVar : Color.values()) {
System.out.println(myVar);
}
}
}(4)在 switch 中使用枚举类
enum Color
{
RED, GREEN, BLUE;
}
public class MyClass {
public static void main(String[] args) {
Color myVar = Color.BLUE;
switch(myVar) {
case RED:
System.out.println("红色");
break;
case GREEN:
System.out.println("绿色");
break;
case BLUE:
System.out.println("蓝色");
break;
}
}
}(6)values(), ordinal() 和 valueOf() 方法
- values() 返回枚举类中所有的值。
- ordinal()方法可以找到每个枚举常量的索引,就像数组索引一样。
- valueOf()方法返回指定字符串值的枚举常量。
enum Color
{
RED, GREEN, BLUE;
}
public class Test
{
public static void main(String[] args)
{
// 调用 values()
Color[] arr = Color.values();
// 迭代枚举
for (Color col : arr)
{
// 查看索引
System.out.println(col + " at index " + col.ordinal());
}
// 使用 valueOf() 返回枚举常量,不存在的会报错 IllegalArgumentException
System.out.println(Color.valueOf("RED"));
// System.out.println(Color.valueOf("WHITE"));
}
}执行以上代码输出结果为:
RED at index 0
GREEN at index 1
BLUE at index 2
RED(7)枚举类成员
枚举跟普通类一样可以用自己的变量、方法和构造函数,构造函数只能使用 private 访问修饰符,所以外部无法调用。
枚举既可以包含具体方法,也可以包含抽象方法。 如果枚举类具有抽象方法,则枚举类的每个实例都必须实现它。
enum Color
{
RED, GREEN, BLUE;
// 构造函数
private Color()
{
System.out.println("Constructor called for : " + this.toString());
}
public void colorInfo()
{
System.out.println("Universal Color");
}
}
public class Test
{
// 输出
public static void main(String[] args)
{
Color c1 = Color.RED;
System.out.println(c1);
c1.colorInfo();
}
}执行以上代码输出结果为:
Constructor called for : RED
Constructor called for : GREEN
Constructor called for : BLUE
RED
Universal Color

















 1271
1271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











