




作者:种子张:九章云极解决方案专家,从事大数据、人工智能行业18年,现从事智算领域工作,公司主要租赁弹性算力,欢迎大家与我交流,转载请注明出处,关注公号:疯聊AI。
摘要:之前我们写了一篇《开源语音TTS与ASR大模型选型指南(2025最新版)》,里边埋了一个伏笔,就是我们的项目是用的哪个ASR大模型,本篇就给大家解密,并给大家分享详细的部署过程,相信大家在这过程中可以学到很多东西。
一、Faster-whisper介绍
faster-whisper是基于OpenAI的Whisper模型的高效实现,它利用CTranslate2,一个专为Transformer模型设计的快速推理引擎。这种实现不仅提高了语音识别的速度,还优化了内存使用效率。faster-whisper的核心优势在于其能够在保持原有模型准确度的同时,大幅提升处理速度,这使得它在处理大规模语音数据时更加高效。faster-whisper是具有完全的 whsiper 模型参数,且自带 VAD加持的 whisper 版本,该版本使用了 CTranslate2 来重新实现 whsiper 模型,CT2 对 transformer 类网络进行了优化,使模型推理效率更高。 相比于 openai/whisper,该实现在相同准确性下速度提高了 4 倍以上,同时使用的内存更少。faster-whisper的技术优势不仅体现在速度上。它还支持8位量化,这一技术可以在不牺牲太多准确度的情况下,进一步减少模型在CPU和GPU上的内存占用。这使得faster-whisper在资源受限的环境中也能高效运行,如在移动设备或嵌入式系统上。
二、Faster-whisper部署要求
我们在项目主页:https://github.com/SYSTRAN/faster-whisper/tree/master首页(即readme.md文件)了解到,最新版本为faster-whipser1.1.1,它有small,large-v2,large-v3,如果在个人电脑上测试,没有GPU或GPU配置低的请选择small,这里我们为了支持生产环境实用,我们不缺GPU资源,因此部署large-v3版本。部署大模型最重要的是要弄清楚其基础环境,比如操作系统、Python、Pytorch、CUDA、cuDNN(深度神经网络库)的版本,特别是Pytorch、CUDA、cuDNN之间的版本是有对应关系的,我们先要确认这个问题,其它的还好。从官网readme.md查一下要求:
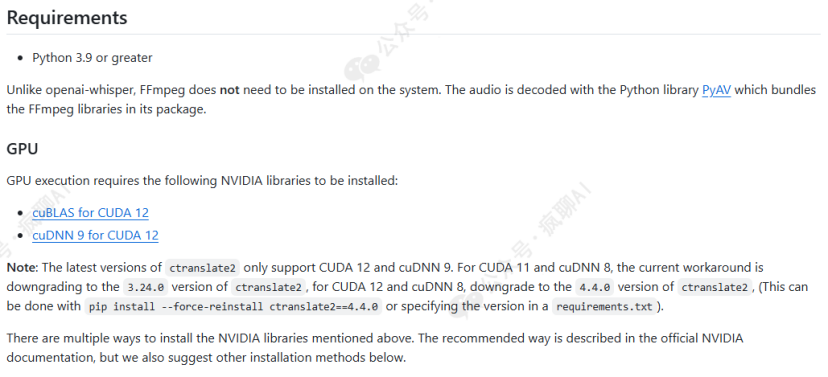
可以看出来要求是CUDA12和cuDNN9。安装方法是:pip install faster-whisper,默认安装最新的1.1.1版本。对了,从上图可以看出来如果我们的CUDA为12和cuDNN8,则需将ctranslate2重新安装成4.4.0版本即可,重装命令如下:
pip install --force-reinstall ctranslate2==4.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple也可以对照requirements.txt文件来评估环境需求。经分析,得出如下要求:
-
ubuntu 20.04.6 LTS (Focal Fossa)
-
python3.10.14
-
CUDA为12和cuDNN8(此项最重要,其它的问题不大,我们采用降级处理)
-
Faster-whisper1.1.1
工具:Vscode+Aladdin、Docker Desktop(本文默认读者已经安装)
相前知识前提:Python、k8s(初级)、linux。
三、相关概念提前了解
-
智算云服务:本质上是租赁GPU资源的服务(当然GPU不能单独运行,需要配套的CPU、内存、存储、网络资源)
-
虚拟化、池化:就是把大量的硬件资源放到一个池子里,大家按需取用,可选配不同配置的资源。
-
弹性容器集群(vks):基于k8s构建的容器集群,vks:virtual kubenetes service。是运行在Kubernetes集群之上的一个轻量级、可嵌套的Kubernetes环境。它模拟了Kubernetes的核心组件和API服务器,为用户提供了一个独立的、隔离的Kubernetes体验。在物理上,它是嵌套在宿主Kubernetes集群中的,但它为用户呈现了一个完整的Kubernetes集群视图。
-
Pod:Kubernetes中的最小可部署单元,它由一个或多个容器组成。这些容器共享存储、网络和生命周期,并且被调度到同一个Worker节点上运行。Pod是Kubernetes进行资源调度和管理的基本单位。
-
Container(容器):容器是Pod的组成部分,它包含了应用程序及其所需的依赖项、运行时环境等。容器通过容器运行时(如Docker)进行管理,它提供了资源隔离和安全性保障。在Kubernetes中,容器通常是以Docker镜像的形式进行分发和部署的。
-
Image(镜像):一个Docker镜像文件,加载副本到内存中运行,仓库里的镜像不受影响,我们也支持修改后再保存为新的镜像文件(这点好用)。
-
PVC:Pod持载的存储,Pod起来后将CPU、GPU、内存等资源拉起,但不会持久化,需要将文件存到PVC上进行持久化。
-
Aladdin:阿拉丁,九章云极提供的Vscode、Pycharm、cursor插件,方便选资源、配置镜像、在GPU上执行代码(当然CPU上运行也是可以的)。
-
Harbor:私有镜像仓库,为了复用相关程序,通常将它们打成镜像,这些镜像可以在Docker Desktop中运行,也可以在K8s下边的Pod中运行。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3540
3540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









