




1.DeepSeek惊喜连连
当我们还沉浸在大模型的价格杀手、开源之光DeepSeek-V3的惊喜中,DeepSeek于2025年1月20日又再一次让我们吃了一惊,发布了DeepSeek-R1,性能直接对标OpenAI o1,是全球唯一一个可以与其较劲的大模型。此次发布的DeepSeek-R1还是将模型权重一并开源,有实力就是豪横!
2.DeepSeek-R1榜单分析
按老套路,我们先来看一下模型效果。先看一看官网公开的榜单:

图片来源于DeepSeek官网
我们发现,DeepSeek-R1极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版(满血版)。
顺便介绍一下图中的几个测试榜单:
AIME 2024 AI Mathematical Olympiad
AIME 2024 是一项专注于数学问题解决能力的AI竞赛,旨在评估模型在复杂数学问题上的表现。参赛模型需要解决高难度的数学题目,通常涉及代数、几何、数论和组合数学等领域。
评估内容: 模型需要展示出对数学概念的深刻理解和创造性解决问题的能力。
意义: 该榜单反映了模型在高级数学推理和问题解决方面的能力,是衡量AI数学能力的重要指标。
Codeforces在线编程竞赛平台
Codeforces 是一个著名的在线编程竞赛平台,定期举办算法竞赛。AI模型在该平台上的表现展示了其在算法设计、代码实现和优化方面的能力。
评估内容: 模型需要解决各种算法问题,包括动态规划、图论、数据结构等,并在有限时间内提交正确的代码。
意义: Codeforces 榜单反映了模型在编程竞赛中的实际表现,是衡量AI编程和算法能力的重要参考。
GPQA Diamond通用问题回答基准
GPQA Diamond 是一个高难度的通用问题回答基准,旨在评估模型在广泛领域的知识深度和推理能力。问题涵盖科学、人文、技术等多个领域,且难度较高。
评估内容: 模型需要展示出跨学科的知识储备和复杂的推理能力,能够回答需要深入理解和分析的问题。
意义: 该榜单反映了模型在广泛知识领域中的综合能力,是衡量AI通用智能的重要指标。
MMLU Massive Multitask Language Understanding
MMLU 是一个多任务语言理解基准,涵盖了57个不同的任务领域,包括人文、社会科学、STEM(科学、技术、工程和数学)等。该基准旨在评估模型在多个领域的知识和理解能力。
评估内容: 模型需要在广泛的学科领域中回答多项选择题,展示其跨领域的知识掌握和推理能力。
意义: MMLU 是衡量模型在多样化任务上的综合表现的重要基准,反映了模型的广泛知识覆盖和语言理解能力。
SWE-Bench Verified
SWE-Bench Verified 是一个专注于软件工程任务的基准,评估模型在实际软件开发环境中的表现。任务包括代码修复、功能实现、代码优化等。
评估内容: 模型需要展示出在实际软件开发中的能力,包括代码理解、错误修复、功能实现等。
意义: 该榜单反映了模型在软件工程实践中的实际应用能力,是衡量AI在编程和软件开发领域表现的重要指标。
有人说,现在的大模型评测榜单已经泛滥了,很多大模型在刷榜单,有一个权威的榜单,我们也看一下,LiveBench。LiveBench 实打实的大有来头,它是由图灵奖得主、Meta 首席 AI 科学家杨立昆(Yann LeCun)联合 Abacus.AI、纽约大学等机构推出的大模型测评基准。简单来说,经常对着当今由 OpenAI 引领的大模型技术路线一通抨击的杨立昆牵头做了一个对刷榜行为异常警觉的大模型评测基准——而就是这样一个十分严苛的榜单LiveBench 包括数学、推理、编程、语言理解、指令遵循和数据分析在内的多个复杂维度对模型进行评估。之所以名字里有个「live」,就是因为这个榜单采用了新颖的数据来源并保持每月更新,这杜绝了大模型通过预训练和微调作弊的可能性。LiveBench 也被行业内誉为「世界上第一个不可玩弄的 LLM 基准测试」,官网上明晃晃地写着「A Challenging,Contamination-Free LLM Benchmark」。我们看一看最新的榜单情况:

图片来源于livebench.ai
我们可以看到DeepSeek-R1已经仅次于OpenAI o1正式版,较一个月之前,已经全面超超了Gemini。此次DeepSeek还特别蒸馏了一些小模型,相当于DeepSeek-R1是老师,把功力传给开源的Qwen1.5B、Llama 8B等开源模型(架构未变,只是把知识压缩进去),形成了多个版本的蒸馏模型,大模型能力强是王道,只有大模型能力强,蒸馏出的小模型才会好。各蒸馏版本性能测试结果如下:

图片来源于DeepSeek官网
蒸馏出的32B 和 70B 模型在多项能力上远远超过了 GPT-4o、Claude 3.5 Sonnet 和 QwQ-32B,并逼近 o1-mini企业级应用通常选32B参数量大模型,感兴趣的小伙伴可以上手一测。
3.DeepSeek-R1技术分析
DeepSeek-R1的技术报告下载地址如下:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf。
在DeepSeek-R1之前,其实还有一个DeepSeek-R1 Zero中间模型,都是基于DeepSeek-V3进行的微调。

有了有监督微调,R1在逻辑、编程、写作等方面表现更好。与基模型V3不同的地方是在训练过程与训练数据。这些大模型本地化部署仍然至少要求1000G的显存。当然我们可以先玩一下蒸馏出的来小参数量模型,例如1.5B。
英伟达高级研究科学家 Jim Fan第一时间阅读这份技术报告后进行了解读:

我通过DeepSeek-V3将上述英文翻译一下:
我们生活在一个时间线上,一家非美国公司正在延续 OpenAI 的原始使命——真正开放、前沿的研究,赋能所有人。这听起来毫无道理。而最有趣的结果或许是最有可能发生的。
DeepSeek-R1 不仅开源了一系列模型,还公开了所有的训练秘诀。他们可能是第一个显示 RL(强化学习)飞轮发挥主要作用、持续增长的 OSS 项目。
影响可以通过『内部实现了 ASI』或『草莓计划』等神话名称来实现。也可以通过简单地转储原始算法和 matplotlib 学习曲线来产生影响。
3.1训练过程
DeepSeek-R1 的训练过程分为多个阶段,结合了强化学习(RL,即Reinforcement Learning)、监督微调(SFT)和蒸馏(Distillation)等技术,旨在提升模型在复杂推理任务中的表现。以下是其训练过程的主要步骤:
(1)DeepSeek-R1-Zero:纯强化学习训练
目标:探索在没有监督数据的情况下,通过纯强化学习(可以简单理解为模型自己训练自己)提升模型的推理能力。
方法:使用 DeepSeek-V3-Base 作为基础模型,采用 GRPO群组相对策略优化(Group Relative Policy Optimization)作为强化学习框架,直接对模型进行大规模强化学习训练。
结果:DeepSeek-R1-Zero 在推理任务中表现出色,尤其是在数学和编程任务上,Pass@1 分数显著提升(如 AIME 2024 从 15.6% 提升到 71.0%)。然而,模型存在可读性差、语言混合等问题。
(2)DeepSeek-R1:冷启动与多阶段训练
冷启动:为了解决 DeepSeek-R1-Zero 的可读性问题,DeepSeek-R1 引入了冷启动数据,即通过少量高质量的推理数据对模型进行初步微调。
多阶段训练:
第一阶段:使用冷启动数据对 DeepSeek-V3-Base 进行微调。
第二阶段:进行推理导向的强化学习,进一步提升模型的推理能力。
第三阶段:通过拒绝采样生成新的 SFT 数据,并结合来自 DeepSeek-V3 的监督数据(如写作、事实问答等)进行多轮微调。
第四阶段:进行全面的强化学习,涵盖所有场景的提示(prompts),以进一步对齐人类偏好。
结果:DeepSeek-R1 在多个推理任务上表现优异,性能与 OpenAI-o1-1217 相当。
(3)蒸馏:将推理能力迁移到小模型
目标:将 DeepSeek-R1 的推理能力迁移到更小的模型上,以提升小模型的推理表现。
方法:使用 DeepSeek-R1 生成的推理数据对 Qwen 和 Llama 系列的小模型进行蒸馏。
结果:蒸馏后的小模型在推理任务上表现优异,部分模型甚至超越了 OpenAI-o1-mini。
3.2技术优势
DeepSeek-R1 在训练过程中展现了多项技术优势,主要体现在以下几个方面:
(1)纯强化学习的成功应用
-
DeepSeek-R1-Zero 是首个通过纯强化学习(无需监督微调)成功提升推理能力的模型。这一突破表明,强化学习可以独立驱动模型在复杂推理任务上的自我进化。
-
模型在训练过程中自然涌现出多种强大的推理行为,如自我验证、反思和生成长链推理(Chain-of-Thought, CoT)。
(2)冷启动与多阶段训练的优化
-
通过引入冷启动数据,DeepSeek-R1 解决了 DeepSeek-R1-Zero 的可读性问题,并进一步提升了推理性能。
-
多阶段训练策略(冷启动、强化学习、拒绝采样、监督微调)使得模型能够在推理任务和通用任务上都表现出色。
(3)蒸馏技术的有效性
-
DeepSeek-R1 通过蒸馏技术将推理能力迁移到小模型上,显著提升了小模型在推理任务上的表现。例如,DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上的表现超越了 QwQ-32B-Preview。
-
蒸馏后的模型在多个推理基准上表现优异,证明了推理模式可以从大模型有效迁移到小模型。
(4)在多个基准上的优异表现
-
DeepSeek-R1 在多个推理基准(如 AIME 2024、MATH-500、Codeforces 等)上表现优异,尤其是在数学和编程任务上,性能与 OpenAI-o1-1217 相当。
-
在知识型任务(如 MMLU、GPQA Diamond)和长上下文理解任务(如 FRAMES)上,DeepSeek-R1 也展现了强大的能力。
3.3存在的不足
尽管 DeepSeek-R1 在多个方面表现出色,但仍存在一些不足之处:
(1)语言混合问题
DeepSeek-R1 在处理非英语或非中文的查询时,可能会出现语言混合问题。例如,模型可能会在推理过程中混合使用英语和其他语言,导致输出不够连贯。
(2)对提示(prompt)的敏感性
模型对提示的敏感性较高,尤其是在少样本提示(few-shot prompting)的情况下,性能可能会下降。建议用户在使用时采用零样本提示(zero-shot prompting)以获得最佳效果。
(3)软件工程任务的改进空间
由于软件工程任务的评估时间较长,影响了强化学习的效率,DeepSeek-R1 在软件工程任务上的表现提升有限。未来的版本计划通过拒绝采样或异步评估来改进这一问题。
(4)通用能力的不足
尽管 DeepSeek-R1 在推理任务上表现出色,但在一些通用任务(如函数调用、多轮对话、复杂角色扮演等)上的能力仍不如 DeepSeek-V3。未来的研究计划通过长链推理(CoT)来增强这些领域的能力。
(5)蒸馏与强化学习的权衡
虽然蒸馏技术在小模型上取得了显著的效果,但直接通过大规模强化学习训练小模型的性能提升有限。这表明,蒸馏技术在提升小模型推理能力方面更为经济和有效,但进一步提升智能边界仍需更强大的基础模型和大规模强化学习。
DeepSeek-R1 通过纯强化学习、冷启动、多阶段训练和蒸馏技术,成功提升了模型在复杂推理任务上的表现,并在多个基准上取得了优异的成绩。其技术优势主要体现在纯强化学习的成功应用、冷启动与多阶段训练的优化、以及蒸馏技术的有效性。然而,模型仍存在语言混合、提示敏感性、软件工程任务改进空间等不足。未来的研究将致力于解决这些问题,进一步提升模型的通用能力和推理性能。
4.DeepSeek-R1使用方法
还是如何DeepSeek-V3的使用方法一样,登录DeepSeek官网https://www.deepseek.com/或官方App使用,但是要想使用DeepSeek-R1,需要打开“深度思考”模式,这样才可调用最新版 DeepSeek-R1 。
4.1在线问答调用方法
本示例测一个问题(人类最终的结局是怎样的?)分别用普通模模式(DeepSeek -V3)和深度思考模式(DeepSeek-R1)来问,看一下效果:
首先是普通模式,DeepSeek-V3的回答如下:
我感觉上边的回答已经非常不错了,各方面基本都说到了。但我还是测一下深度思考模式:

DeepSeek-R1感觉在自言自语,喃喃出了一大段提示词,这其实是它在展示完整的思考过程,后边再按这个提示词来完善之前的回答,最终的回答效果如下:
可以看出来,这次思考的深度确实更进一步了,提到了具体的生物技术如基因编辑,纳米技术泛滥、全球升温2°C、冻土甲烷大释放、海洋环流停滞、可控核聚变、光速传播“人类数据包”等技术细节.
4.2API调用方法
DeepSeek-R1 也同步上线了 API,对用户开放思维链输出,通过设置 model='deepseek-reasoner' 即可调用。参考官网的在线文档https://api-docs.deepseek.com/zh-cn/,进行API的调用,同国内大多数大模型一样,DeepSeek也是按照OpenAI的接口格式来组织API的,以便现在已经用了OpenAI的客户后边可以平滑迁移。

使用 DeepSeek API 之前,请先 创建 API 密钥。提供CURL、PYTHON、GO、NODEJS、RUBY、CSHARP、PHP、JAVA、POWERSHELL丰富的API接口。
4.3私有化部署DeepSeek-R1-Distill-Qwen-1.5B
DeepSeek系列模型下载地址如下:https://huggingface.co/deepseek-ai?continueFlag=f18057c998f54575cb0608a591c993fb,由于资源有限,我们本次只下载最小参数量只有1.5B的DeepSeek-R1-Distill-Qwen-1.5B。下载地址:
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/tree/main。

将上图中全部文件一一下载。自己有GPU卡的同学可以用自己的卡,在本机VSCODE中操作,没有的话可以向算力提供商租用,有一些有免费试用或赠送活动,这里我们选择在九章云极的智算操作系统Alaya NeW(本质是提供在线的vscode及算力资源调度等功能)中借助其算力资源进行DeepSeek-R1-Distill-Qwen-1.5B的部署。
第一步,通过链接https://www.alayanew.com/注册、登录后开通大模型训练工具LM Lab。

点击访问,在新开页面上点击“新建项目”按钮:
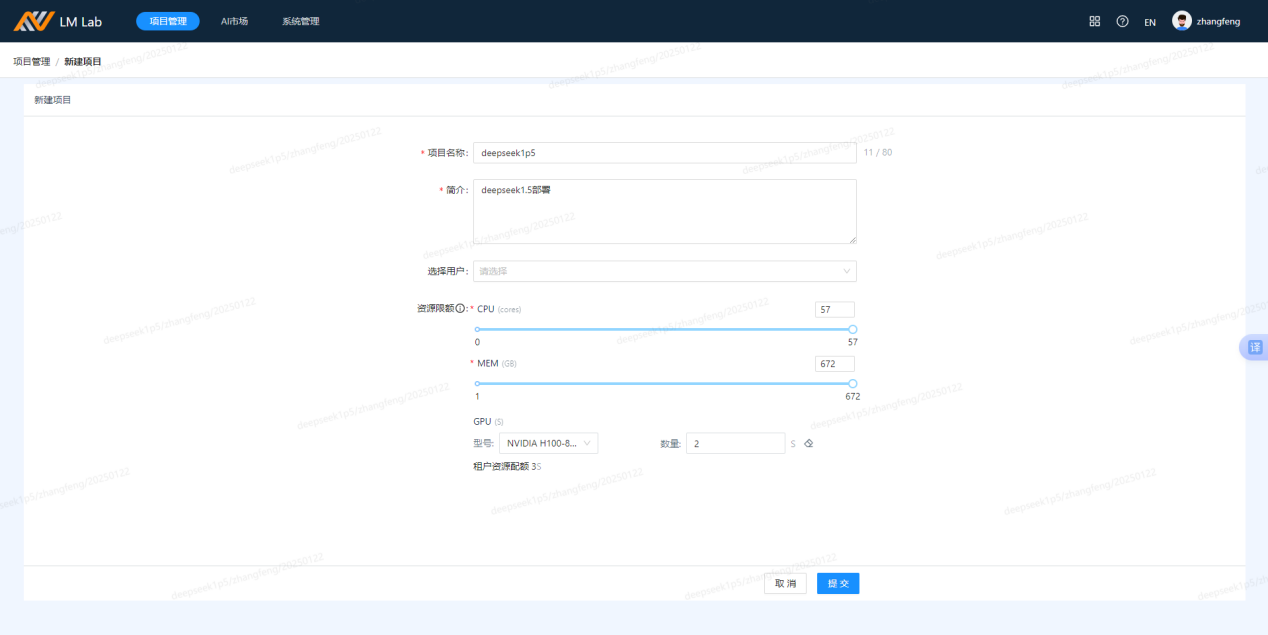
新建编码环境workshop,取名为sw_deepseek,点击确认:

等待新建完成后,点击“启动”链接,启动workshop,选一块H100的GPU即可:

点击“编码”进入到我们熟悉的Web Vscode编码环境:
上传模型文件,为了省事,且模型文件不算大,我们直接在web vscode中上传模型文件。新建了一个目录deepseek1.5,然后将之前下载的模型文件上传至此目录。

安装vllm工具:通过在终端输入pip install vllm进行安装:

如果上述方法找不到源,则通过以下方式安装:
pip install https://vllm-wheels.s3.us-west-2.amazonaws.com/nightly/vllm-1.0.0.dev-cp38-abi3-manylinux1_x86_64.whl,也可以先通过you-get下载vllm-1.0.0.dev-cp38-abi3-manylinux1_x86_64.whl后,再通过pip install vllm-1.0.0.dev-cp38-abi3-manylinux1_x86_64.whl进行安装。

接下来启动大模型,我们采用vllm方案来启动,将vllm serve 命令中的模型名称替换为本地模型文件的路径。例如,如果你的模型文件存放在 /path/to/local/model 目录下,可以运行以下命令:
vllm serve /path/to/local/model --tensor-parallel-size 1 --max-model-len 32768 --enforce-eager
其中tensor-parallel-size 1表示一块GPU,如果有两块GPU,可以将并行度设为2,依此类推。确保 /path/to/local/model 目录中包含以下文件:config.json、pytorch_model.bin(或其他模型权重文件)、tokenizer.json(或其他分词器文件)。

测试一下效果:新建一个py文件,输入以下代码:
import requests
url = "http://localhost:8000/v1/completions"
headers = {"Content-Type": "application/json"}
data = {
"model": "/opt/aps/workdir/deepseekr11p5",
"prompt": "你好,你是哪个大模型呀?",
"max_tokens": 50
}
response = requests.post(url, headers=headers, json=data)
print(response.json())

至此,已经成功部署并测试成功。
5API 及定价
API and Price
DeepSeek-R1 API 服务定价为每百万输入 tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出 tokens 16 元。相较OpenAI o1百万输入110元,百万输出则入438元。DeepSeek-R1的价格不到OpenAI o1的1/50,在整个业界目前是最便宜的,就收点算力的钱。


















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









