




一、C++的第一个程序
C++兼容C语言绝大多数语法,所以C语言实现的hello world依旧可以运行,C++中需要把定义文件代码后缀改为.cpp,VS编译器看到的是.cpp就会调用C++编译器编译,Linux下要用g++编译,不再是gcc。
当然,C++也有一套自己的输入和输出,严格来说C++版本的hello world应该这么写:
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
int main()
{
cout << "hello world" << endl;
return 0;
}
这里出现了许多我们之前没见过的词,比如std,cout,endl,namespace。下面来依次讲解。
二、命名空间
2.1 namespace的引入
在C/C++中,变量、函数和后面要学习到的类都是大量存在的,这些变量、函数和类的名称都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的就是对标识符的名称进行本地化,以避免命名冲突或名字污染,关键字namespace的出现就是针对这种问题的。
我们现在来看下面这个程序:
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
int rand = 10;
int main()
{
printf("%d\n", rand);
return 0;
}
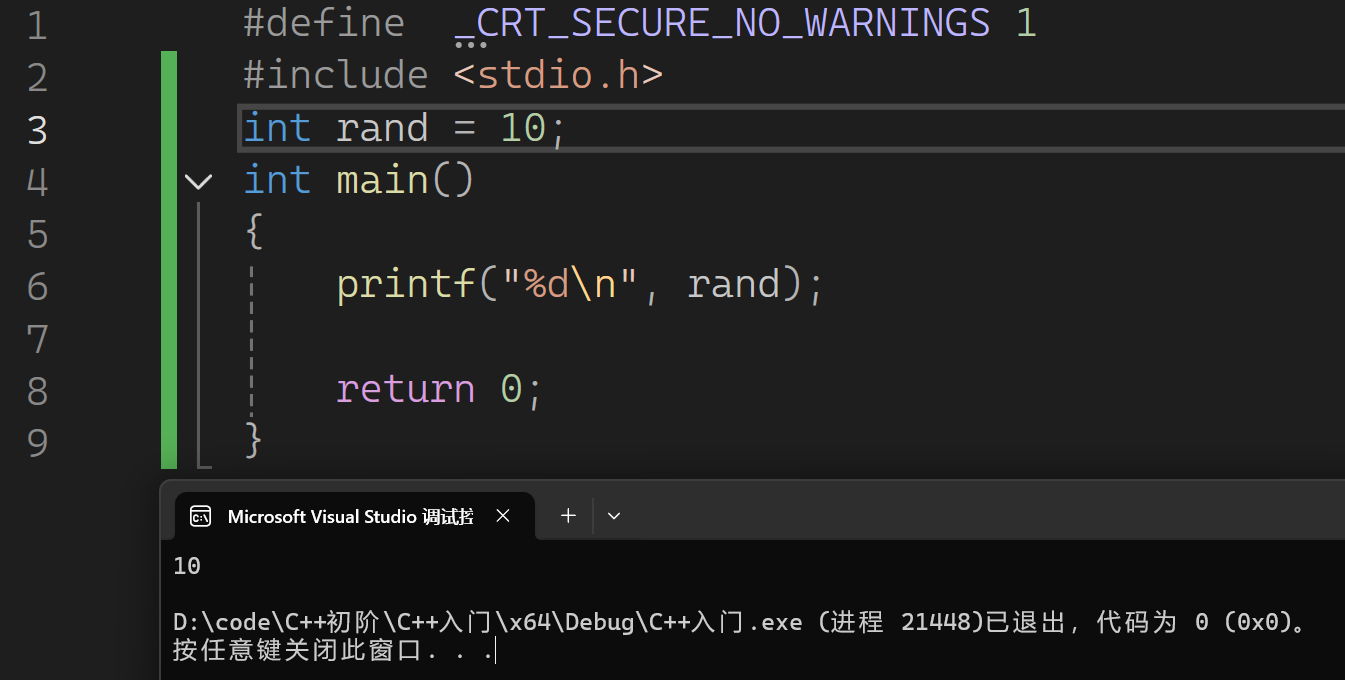
这个程序目前看似没有任何问题,但如果我们再加一个头文件之后就不一样了。
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
int rand = 10;
int main()
{
printf("%d\n", rand);
return 0;
}

C语言项目中,类似上面程序这样的命名冲突是普遍存在的问题,而C++引入namespace就是为了更好地解决这样的问题。
2.2 namespace的定义
定义命名空间,需要使用到关键字namespace,后面跟命名空间的名字,然后接一对{}即可。{}中为命名空间的成员,命名空间可以定义变量、函数、类型等等。
namespace本质上是定义出一个域,这个域和全局域各自独立,不同的域可以定义同名的变量,所以下面代码中的rand就不存在冲突了。
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
namespace zyc
{
int rand = 10;
int Add(int x, int y)
{
return x + y;
}
struct Node
{
int data;
struct Node* next;
};
}
int main()
{
printf("%d\n", zyc::rand);
return 0;
}
C++中域有函数局部域、全局域、命名空间域、类域。域影响的是编译时语法查找一个变量/函数/类型出处的逻辑,所以有了域隔离,名字冲突就解决了。没有指定域,先局部找再全局找;有指定域,直接去这个域找。局部域和全局域除了会影响编译的查找逻辑,还会影响变量的生命周期,而命名空间域和类域不影响变量的生命周期。
1、namespace只能定义在全局,可以嵌套定义
2、项目工程中多文件中定义的同名namespace会认为是一个namespace,不会冲突
3、C++标准库都放在一个叫std(standard)的命名空间中
2.3 namespace的使用
编译查找一个变量的声明/定义时,默认只会在局部或者全局查找,不会到命名空间里面去查找。所以我们要使用命名空间中定义的变量/函数,有三种方式:
1、指定命名空间访问(项目中推荐这种方式)
std::cout << "hello world" << std::endl;
2、using将命名空间中某个成员展开(项目中经常访问的成员推荐使用)
using std::cout;
3、展开命名空间中的全部成员(项目中不推荐,日常练习程序为了方便可以使用)
using namespace std;
三、C++的输入&输出
头文件<iostream>是Input and Output Stream的缩写,是标准的输入、输出流库,定义了标准的输入输出对象。std::cin是 istream 类的对象,std::cout是 ostream 类的对象,std::endl是一个函数,相当于插入一个换行字符并刷新缓冲区。<<是流插入运算符,>>是流提取运算符,C++的输入输出可以自动识别变量类型(本质是通过函数重载来实现的,这个后面会说到),最重要的是C++的流可以更好地支持自定义类型对象的输入输出。
注:在IO需求较高的地方(比如部分大量输入的算法竞赛题中)加上以下三行代码可以提高IO效率
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
四、缺省参数
缺省参数就是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,缺省参数分为全缺省和半缺省参数(有时把缺省参数也叫默认参数)。
#include <iostream>
using namespace std;
void Func(int a = 10)
{
cout << a << endl;
}
int main()
{
Func();
Func(20);
return 0;
}

全缺省就是全部形参给缺省值,半缺省就是部分形参给缺省值。C++规定半缺省参数必须从右往左依次连续缺省,不能跳跃间隔给缺省值。带缺省参数的函数调用,C++规定必须从左往右依次给实参,不能跳跃给实参。当函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值。


五、函数重载
C++支持在同一作用域中出现同名函数,但要求这些同名函数的形参不同,可以是参数个数不同或者类型不同。但是C语言不支持同一作用域中出现同名函数的。返回值不同不能作为重载条件,因为调用时无法区分。
//1.参数类型不同
int Add(int x, int y)
{ }
double Add(double x,double y)
{ }
//2.参数个数不同
void f()
{ }
void f(int a)
{ }
//3.参数类型顺序不同
void f(int a,char b)
{ }
void f(char b,int a)
{ }
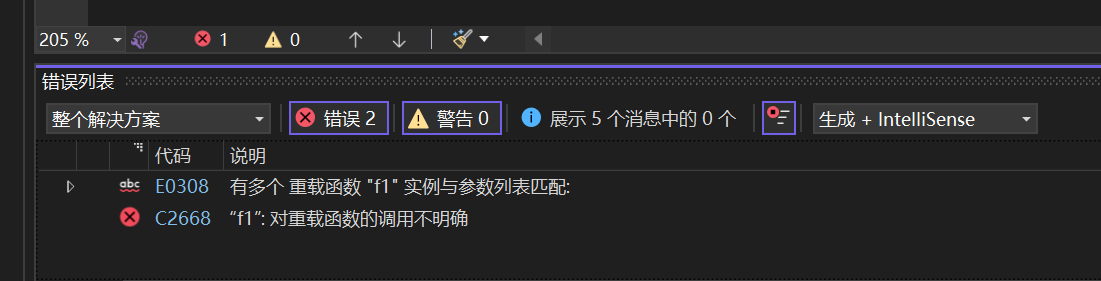
注:下面代码中的两个函数能构成重载,但是在调用f()时会报错,因为存在歧义,编译器不知道该调用谁。
void f1()
{
cout << "f1()" << endl;
}
void f1(int a = 10)
{
cout << "f1(int a)" << endl;
}
int main()
{
f1();
return 0;
}

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









