







 文章探讨了如何解决CNN在捕捉全局表征时的不足,提出Conformer模型,通过结合CNN和transformer的特性,增强全局感知和局部细节处理。作者还介绍了如何将Conformer应用于YOLOv5的Backbone,并提供了实现步骤。
文章探讨了如何解决CNN在捕捉全局表征时的不足,提出Conformer模型,通过结合CNN和transformer的特性,增强全局感知和局部细节处理。作者还介绍了如何将Conformer应用于YOLOv5的Backbone,并提供了实现步骤。
CNN难以捕捉全局表征,这通常对高级计算机视觉任务至关重要。一个直观的解决方案是扩大感受野,但这可能需要更密集但具有破坏性的池化操作。由于自注意力机制和多层感知器(MLP)结构,transformer反映了复杂的空间变换和长距离特征依赖性,构成了全局表示。不幸的是,观察到视觉transformer忽略了局部特征细节,这降低了背景和前景之间的可辨别性。一些改进的视觉转换器提出了一个标记化模块或利用 CNN 特征图作为输入标记来捕获特征相邻信息。然而关于如何将局部特征和全局表示精确地相互嵌入的问题仍然存在。在Conformer中,我们连续将transformer分支的全局上下文馈送到卷积特征图,以加强CNN分支的全局感知能力。 类似地来自CNN分支的局部特征逐渐反馈到patch embedding中,以丰富transformer分支的局部细节,这样的过程构成了相互作用。
Conformer 由一个主干模块、双分支、桥接双分支的 FCU 和用于双分支的两个分类器(一个 fc 层)组成。
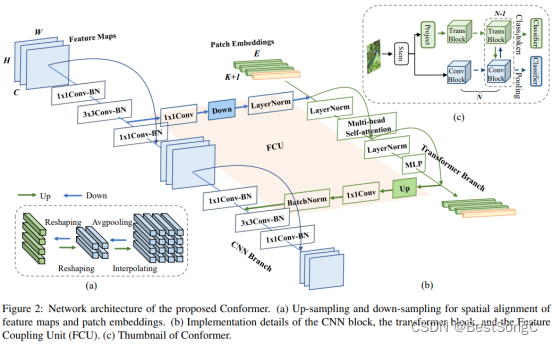
主干模块:主干模块是一个 7×7 卷积,步长为 2,然后是一个 3×3最大池化,步长为 2,用于提取初始局部特征
双分支:CNN 分支和transformer分支分别由N个重复的卷积块和transformer 块组成,这样的并发结构意味着CNN和transformer分支可以分别最大程度地保留局部特征和全局表示。
FCU: FCU 作为桥接模块,将 CNN 分支中的局部特征与transformer分支中的全局表示融合,FCU 从第二个块开始应用,因为两个分支的初始化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









