




目录
随着微服务⽣态碎⽚化(Spring Cloud Netflix逐步退役,Alibaba/Consul等⽅案崛起),企业技术栈呈现多⽣态并存趋势,开发者需掌握灵活选型能⼒。云原⽣时代,企业对微服务的要求从"基础可⽤"升级为"⽣产就绪"(监控、事务、安全),导致开发者⾯对混合架构时⽆从下⼿.
在第⼀版的博客中,我们已经学习了Eureka、Nacos、Spring Cloud LoadBalancer、OpenFeign和Spring Cloud Gateway组件,这些组件为微服务架构提供了服务注册与发现、负载均衡、服务调⽤和API⽹关等功能, 这篇旨在通过进⼀步掌握更多的组件和技术,多技术栈对⽐,培养开发者根据业务选型、解决实际问题的能⼒, 以应对更复杂的业务场景和挑战.
现状分析
橙⾊表⽰现在只维护, 不进⾏新特性开发
| 相关组件分类 | 相关组件 | 已学内容 | 备注 |
|---|---|---|---|
| 服务注册 / 发现 | Eureka Nacos Consul | Eureka, Nacos | |
| 服务调用 | OpenFeign Feign | OpenFeign | OpenFeign 是 Feign 的升级,无需讲 Feign |
| 配置中心 | SpringCloudConfig Nacos consul | Nacos | |
| 服务网关 | SpringCloudGateway Zuul | SpringCloudGateway | Zuul 推荐 Spring Cloud 2020 之前版本使用,已被弃用,无需再学 |
| 负载均衡 | SpringCloud LoadBalance Ribbon | SpringCloud LoadBalance | Ribbon 已被弃用,无需再学 |
| 服务熔断和降级 | Netflix Hystrix Alibaba Sentinel | Hystrix 推荐 Spring Cloud2020 之前版本,已弃用,不再学 | |
| 分布式事务 | Alibaba Seata Hmily | ||
| 服务链路追踪 | Zipkin + Sleuth SkyWalking Cat | Zipkin 和 Cat 对代码有侵入.SkyWalking 属于社区顶级项目,活跃度较高 | |
| 分布式消息 | RocketMQ RabbitMQ Kafka |
选择这些组件进行介绍:
1. SpringCloud Config(分布式配置)
2. Consul(服务注册/发现, 配置中⼼)
3. Alibaba Sentinel(服务熔断降级)
4. Alibaba Seata(分布式事务)
5. SkyWalking(服务链路追踪与监控)
1. Spring Cloud Config 介绍
基本介绍:
在微服务架构中, 每个微服务⼀般都有⾃⼰的配置⽂件, ⽐如数据库连接, Redis, MQ等相关配置. 在不同的环境下, 这些配置都会不同. 如果每个服务⾃⾏管理这些配置, 容易导致以下问题
1. 维护成本⾼: 每次配置修改, 都需要重新部署服务.
2. 版本问题: 同⼀个应⽤的不同实例, 需要使⽤同⼀个版本, 逐⼀部署, 可能会导致版本不⼀致的问题.
3. 安全问题: ⼀些敏感配置(如数据库密码) 可能会泄露, 缺乏安全的管理⼿段.
4. ......
所以, 就有了配置中⼼. 可以让我们对项⽬的配置进⾏集中管理.
Spring Cloud Config 是 Spring Cloud 家族中较早的配置中⼼, Spring Cloud Config 是分布式系统中,为服务端和客⼾端解决配置管理的⽅案. 它提供了集中化的配置管理, 使得在不同环境(开发, 测试, ⽣产) 中管理应⽤程序配置变得更加简单和⼀致. 它⽀持配置的动态刷新, 允许在不重启应⽤的情况下更新配置, 提⾼了系统的灵活性和响应速度.
核⼼概念:
Spring Cloud Config 是⼀个分布式配置管理系统, 它主要包括以下⼏个⽅⾯:
1. Config Server(配置服务器)
Config Server 是⼀个配置管理服务器, 负责从各种后端存储(如Git、SVN、本地⽂件系统等)中拉取
配置信息, 并提供REST API供客⼾端使⽤.
2. Config Client(配置客⼾端)
Config Client 是应⽤程序中⼀个组件, 它允许应⽤程序通过Config Client连接到Config Server并动
态获取配置信息. 客⼾端可以根据环境, 服务名等动态选择对应的配置⽂件.
3. 版本控制集成
Spring Cloud Config 默认使⽤Git作为配置存储的后端, 这样可以利⽤Git的版本控制功能来管理配
置⽂件的版本. 每个环境对应⼀个特定的版本, 可以通过切换版本号来⾃动获取对应环境下的配置.
2. Config Server:
搭建Config Server的⽅式很简单, Spring Cloud Config Server是⼀个标准的Spring Boot应⽤程序, 通过引⼊相应的依赖和注解即可快速启动.
主要分为以下⼏步:
1. 创建项⽬
2. 添加依赖
3. 启⽤Config Server
4. 完善配置
5. 初始化Git仓库
创建⼀个SpringBoot 项⽬:
为了⽅便代码管理, 在 spring-cloud-demo 这个⼯程的基础上来进⾏开发.
a. 创建空Maven项⽬config-server
b. 完善pom
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>c. 添加启动类
@SpringBootApplication
public class ConfigServerApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigServerApplication.class, args);
}
}添加依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>启⽤config server:
在启动类添加注解 @EnableConfigServer
@SpringBootApplication
@EnableConfigServer
public class ConfigServerApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigServerApplication.class,args);
}
}完善配置:
server:
port: 7071
spring:
application:
name: config-server # 应⽤名称
cloud:
config:
server:
git:
uri: https://gitee.com/downwork50/config-server.git #配置⽂件Git 地址
default-label: master #配置⽂件分⽀
search-paths: config #配置⽂件所在根⽬录初始化Git仓库:
1. 创建git仓库(github或者gitee都可以)

2. 上传配置信息
config/config-server-dev.yml
data:
env: config-dev
user:
username: config-dev
password: config-devconfig/config-server-prod.yml
data:
env: config-prod
user:
username: config-prod
password: config-prod测试:
Spring Cloud Config 有它的⼀套访问规则,我们通过这套规则在浏览器上直接访问就可以。
• /{application}/{profile}[/{label}]
• /{application}-{profile}.yml
• /{label}/{application}-{profile}.yml
• /{application}-{profile}.properties
• /{label}/{application}-{profile}.properties
• {application}: 表⽰微服务的名称, 对应于配置中的 spring.application.name 属性.
• {profile}: 表⽰当前环境的配置⽂件, 如dev, test, prod等, 对应于 spring.profiles.active
属性.
• {label}: 表⽰Git仓库中的分⽀, 标签或提交ID. 这个参数是可选的, 如果省略, 默认会使⽤ master
分⽀. {label} 对于回滚到以前的配置版本⾮常有⽤.
基于以上规则, 我们可以访问以下地址, 如果可以正常返回数据,则说明配置中⼼服务端⼀切正常
http://127.0.0.1:7071/config-server/dev
http://127.0.0.1:7071/config-server/prod
http://127.0.0.1:7071/config-server-dev.yml
http://127.0.0.1:7071/config-server-prod.yml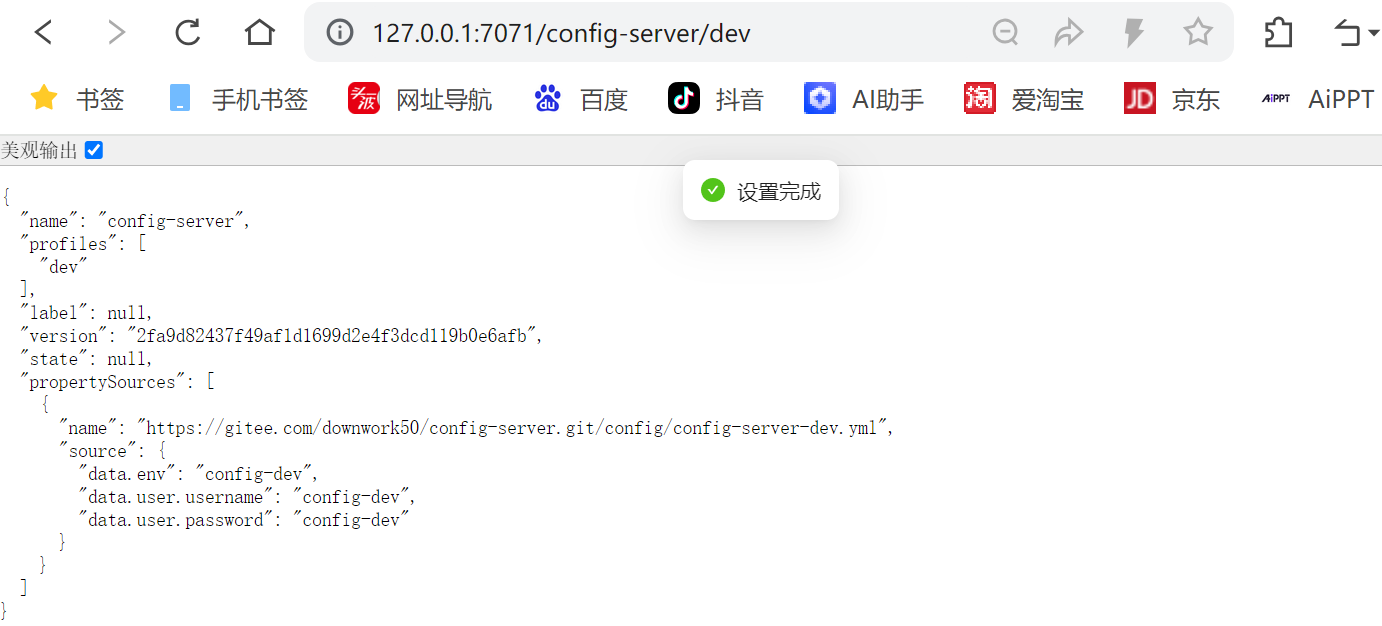
修改search-paths, 可以观看到结果发⽣变化
3. Config Client
Config Client 简单来说, 就是应⽤程序连接到Config Server并动态获取配置信息. 客⼾端的配置相对简单, 只需引⼊相关依赖并配置好配置服务端的地址.
配置管理
在git仓库添加配置
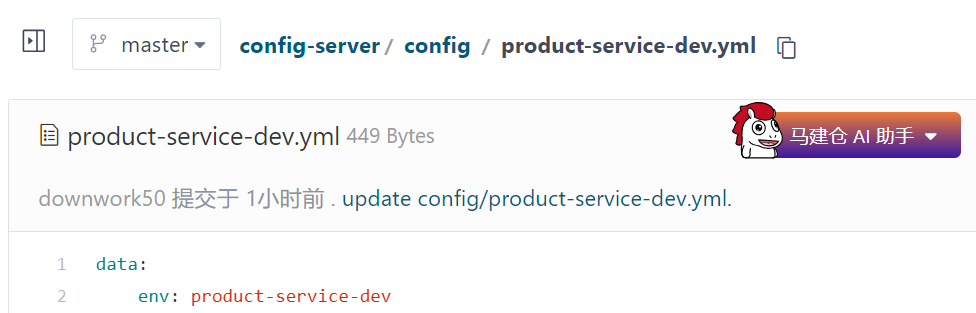
product-service-dev.yml
data:
env: product-service-devproduct-service-prod.yml
data:
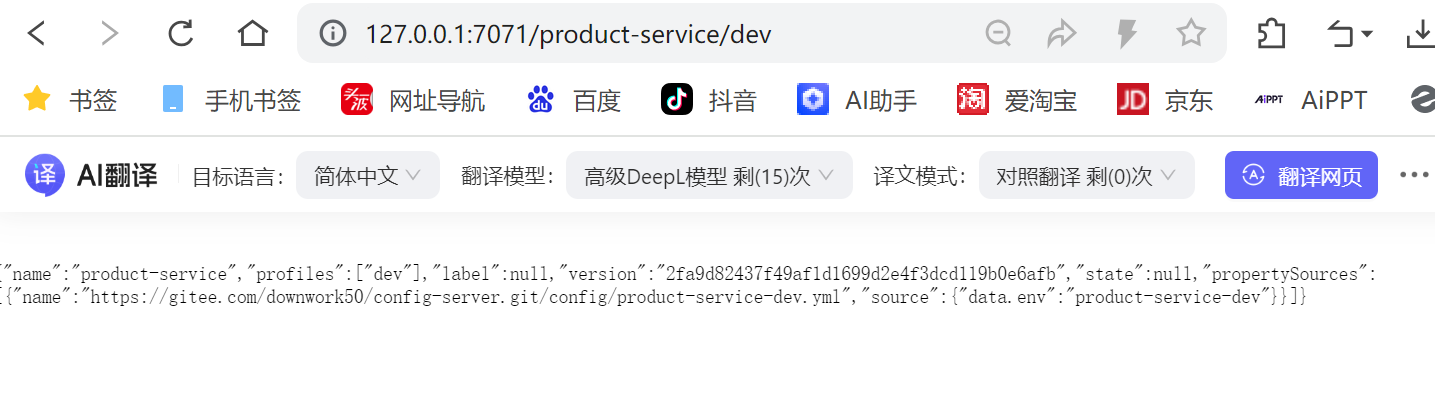
env: product-service-prod重启Config Server, 访问http://127.0.0.1:7071/product-service-dev.yml, 观察配置是否设置成功
添加依赖:
Spring Cloud 会创建⼀个 Bootstrap Context , 作为Spring 应⽤"Application Context" 的⽗上下⽂. 在Spring应⽤启动的初始化阶段, Bootstrap Context 负责从外部源(如Consul)加载配置属性并解析配置.
所以除了添加 spring-cloud-starter-config 依赖之外, 还需要加⼊依赖 spring-cloud-starter-bootstrap 来实现
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>配置⽂件
Bootstrap属性具有⾼优先级, 也就是说在 bootstrap.yml 或 bootstrap.properties 中定义的配置会优先于 application.yml 或 application.properties 中的配置.
bootstrap.yml 主要⽤于配置应⽤启动时所需的外部依赖和环境, ⽽ application.yml ⽤于业务逻辑相关的配置(如数据库连接等)
bootstrap.yml
spring:
profiles:
active: dev
application:
name: product-service
cloud:
config:
uri: http://127.0.0.1:7071 # 指定配置服务端的地址也可以通过 spring.cloud.config.profile: dev 来指定⽂件. 如果同时存在, 以spring.profiles.active 配置为主.
读取配置
写测试接⼝
@RestController
@RequestMapping("/config")
public class ConfigController {
@Value("${data.env}")
private String env;
@RequestMapping("/getEnv")
public String getEnv(){
return "data.env: "+env;
}
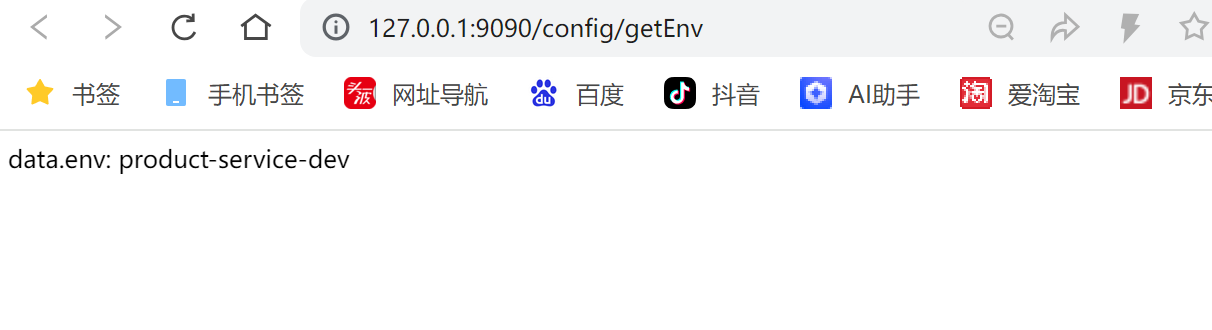
}启动服务, 测试接⼝
http://127.0.0.1:9090/config/getEnv
多平台配置⽀持:
bootstrap.yml
spring:
profiles:
active: dev
application:
name: product-service
#配置的多平台,多环境
---
spring:
config:
activate:
on-profile: dev
cloud:
config:
uri: http://127.0.0.1:7071 # 指定配置服务端的地址
---
spring:
config:
activate:
on-profile: prod
cloud:
config:
uri: http://127.0.0.1:7071修改 spring.profiles.active的值, 观察配置结果变化
4. 配置中⼼⾃动刷新
Spring Cloud Config 在项⽬启动时加载配置内容这⼀机制, 导致了它存在⼀个缺陷, 修改配置⽂件内容后, 不会⾃动刷新. ⽐如上⾯的项⽬, 当服务启动之后, 我们修改github上的配置, 新的配置并不会被加载.
Spring Cloud Config提供了⼀个刷新机制, 但是需要我们主动触发.
接下来看下如何操作.
添加依赖
⾃动刷新机制, 需要借助 Actuator提供的功能, 所以需要添加 spring-boot-starter-actuator依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>spring-boot-starter-actuator 是 Spring Boot 提供的⼀个强⼤的监控和管理⼯具,它允许开发者查看和管理 Spring Boot 应⽤的各种运⾏时指标和状态.核⼼功能有健康检查, 收集和展⽰应⽤程序的运⾏指标, 以及端⼝配置
/actuator/refresh 端点是 Spring Cloud Actuator 提供的⼀个功能, 它允许在运⾏时动态刷新Spring Cloud Config 客⼾端的配置.
添加 @RefreshScope
@RefreshScope
@RestController
@RequestMapping("/config")
public class ConfigController {
@Value("${data.env}")
private String env;
@RequestMapping("/getEnv")
public String getEnv(){
return "data.env: "+env;
}
}开启端点
在application.yml开启端点
#需要开启的端点, 这⾥主要⽤到的是refresh端点, 只开启这⼀个就可以, 为了⽅便, 可以开启所有端点, 除了shutdown端点
management:
endpoint:
shutdown:
enabled: false
endpoints:
web:
exposure:
include: "*"⼿动刷新
启动服务, 访问 http://127.0.0.1:9090/config/getEnv
修改配置后, 发现配置并不能⽴即⽣效
需要⼿动调⽤⼀下接⼝ http://127.0.0.1:9090/actuator/refresh (POST请求)动态刷新 Spring Cloud
Config 客⼾端的配置 (客⼾端服务接⼝)
再次访问, 发现配置发⽣变化.
添加Webhook (了解)
虽然上述操作可以让我们的配置得到⽣效, 但是每次修改都需要⼿动访问refresh接⼝, 这样也很不⽅便.Gitee 提供了⼀种 webhook 的⽅式, 当有代码变更的时候, 会调⽤我们设置的地址,来实现我们想达到的⽬的.
GitHub 也有类似的配置
选择配置的仓库, 点击 管理 -> WebHooks -> 添加webHook
此处的URL需要为⼀个域名, 在没有公⽹和域名的情况下, 我们可以采⽤内⽹穿透的技术, 暴露给外⽹
实现内⽹穿透, 常⻅的⽅法是使⽤第三⽅⼯具或服务. 如ngrok, cpolar
cpolar操作: https://dashboard.cpolar.com/get-started
ngrok操作: https://ngrok.com/
具体操作可参考:2⾏代码将你的本地服务暴露在公⽹!-阿⾥云开发者社区
链接失效的话, 可以⾃⾏搜索.
Filter 介绍:
webhook发送post的时候会携带其他的信息, 可以通过过滤器把对应的多余信息去掉.
在Web开发中, 过滤器(Filter)和拦截器(Interceptor)都是处理请求和响应的组件,但它们在框架中的
作⽤和使⽤场景有所不同.
⼆者区别如下:
1. 过滤器是Java Servlet规范的⼀部分,这意味着任何遵循该规范的Web服务器(如Tomcat、
Jetty等)都可以使⽤过滤器, 拦截器是特定于框架的.
2. 过滤器在请求到达Servlet之前和响应发送回客⼾端之后都可以进⾏处理, 拦截器主要在请求到达
控制器(Controller)之前和之后处理, 但不在响应发送回客⼾端之后处理.
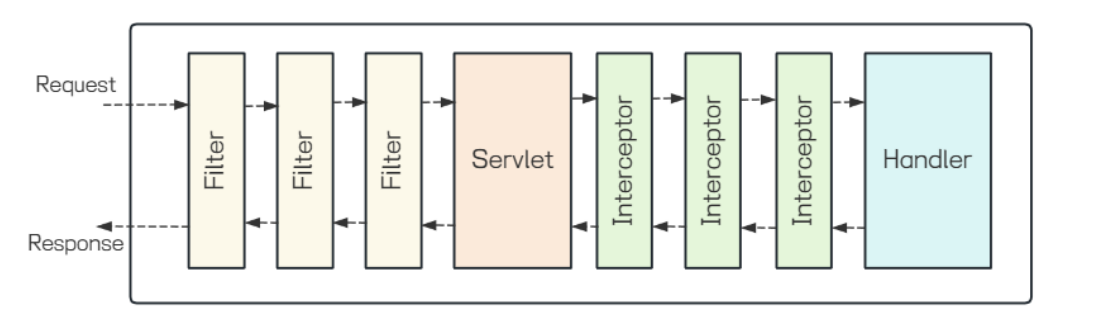
3. 过滤器可以应⽤于所有的请求, 包括静态资源和动态资源, 拦截器通常只作⽤于动态资源,即那些由框架的控制器处理的请求.
4. 过滤器通过实现 javax.servlet.Filter 接⼝来创建, 拦截器通过实现特定框架的接⼝(如
Spring的 HandlerInterceptor )来创建.
过滤器和拦截器在Spring Boot中的核⼼区别在于执⾏时机, 应⽤场景及使⽤便捷性. 过滤器适合系统级通⽤逻辑处理(如数据压缩、编码设置),⽽拦截器位于控制器层⾯, 更适合业务逻辑扩展(如权限校验, ⽇志记录), 虽然看起来很复杂, 但是过滤器和拦截器的设计初衷是将请求的前置处理和响应的后置处理从业务代码中分离出来, 作为通⽤处理逻辑供开发者扩展实现. 本质都是处理请求参数或者响应结果. 在实际开发中,选择使⽤过滤器还是拦截器通常取决于具体的框架和需求.
通过过滤器把请求中对应的多余信息去掉.
启动程序, 通过修改配置⽂件, 发现应⽤程序中的配置可以得到实时更新.
5. Spring Cloud Bus ⾃动刷新
问题:
启动多个服务, 修改配置, 会发现只有⼀个配置webHook刷新url的服务⽣效, 如果需要其他服务⽣效,需要再调⽤其他服务的刷新接⼝.
1. 启动多个服务
2. 修改配置⽂件
3. 测试多个服务获取配置⽂件的内容
结果发现只有配置webHook刷新url的服务⽣效, 如果需要其他服务⽣效, 需要再调⽤其他服务的刷新接⼝.
解决办法
如果服务⽐较多, 需要每个服务都调⽤⼀次才能⽣效,可以借助SpringCloudBus来解决.
Spring Cloud Bus 是Spring Cloud体系中的⼀个组件, 主要⽤于在集群环境中传播分布式系统的配置变更, 以及提供事件驱动的通信机制. Spring Cloud Bus 核⼼原理其实就是利⽤消息队列做⼴播,所以要先有个消息队列, ⽬前Spring Cloud Bus ⽀持两种消息代理:RabbitMQ和Kafka.
我们采⽤RabbitMQ实现.
RabbitMQ在之前的博客章节中已经给⼤家介绍, 此处不再单独介绍.
添加配置
spring:
rabbitmq:
host: 152.136.172.144
port: 5672
username: jqq
password: Jqq200506,
virtual-host: blog修改为对应的IP, 账号,密码和vhost
添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</artifactId>
</dependency>刷新配置
启动服务, 修改配置, 刷新任⼀节点.
http://localhost:9090/actuator/busrefresh post⽅法
所有节点全部⽣效了
webHook刷新的url可以修改为 /actuator/busrefresh
6. Spring Cloud Config 加密解密
介绍:
在微服务开发中, 配置⽂件可能包含⼀些敏感信息, ⽐如数据库密码, API密码等, 直接明⽂存储这些信息在配置⽂件中是⾮常危险的, 尤其是当配置⽂件存储在版本控制系统(如Git)中时. 这时候我们就需要对这些敏感信息进⾏加密.
针对这个问题, Spring Cloud Config提供了对属性进⾏加密解密的功能, 以保护配置⽂件中的敏感数据不被泄露.
⽐如这个配置:
data:
password:
'{cipher}edf62f27bc6dbc7655f1acb810003eef2004d0e4bc0a3bc193b451cdd7b5648d'密码算法分类
密码算法主要分为三类: 对称密码算法, ⾮对称密码算法, 摘要算法
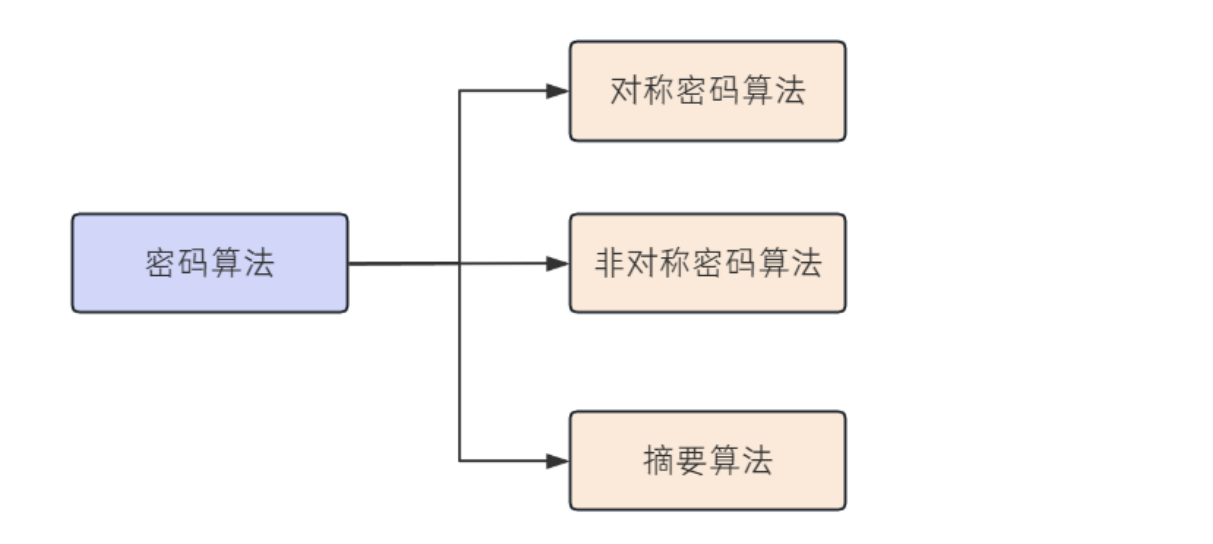
1. 对称密码算法 是指加密秘钥和解密秘钥相同的密码算法. 常⻅的对称密码算法有: AES, DES, 3DES,RC4, RC5, RC6 等.
2. ⾮对称密码算法 是指加密秘钥和解密秘钥不同的密码算法. 该算法使⽤⼀个秘钥进⾏加密, ⽤另外⼀个秘钥进⾏解密.
◦ 加密秘钥可以公开,⼜称为 公钥
◦ 解密秘钥必须保密,⼜称为 私钥
常⻅的⾮对称密码算法有: RSA, DSA, ECDSA, ECC 等
3. 摘要算法 是指把任意⻓度的输⼊消息数据转化为固定⻓度的输出数据的⼀种密码算法. 摘要算法是不可逆的, 也就是⽆法解密. 通常⽤来检验数据的完整性的重要技术, 即对数据进⾏哈希计算然后⽐较摘要值, 判断是否⼀致. 常⻅的摘要算法有: MD5, SHA系列(SHA1, SHA2等), CRC(CRC8,CRC16,CRC32)
对称加密
检查加密环境
1. 下载jar包
Java 中提供了⼀套⽤于实现加密, 密钥⽣成等功能的包 JCE(Java Cryptography Extension), 这些包提供了对称, ⾮对称等加密⽀持, 但是默认的 JCE 是⼀个有限⻓度的 JCE, 我们需要到 Oracle 官⽹去下载⼀个不限⻓度的 JCE .
下载地址: https://www.oracle.com/java/technologies/javase-jce8-downloads.html
也可以从课件资料中获取
下载之后, 共有3个⽂件

我们需要将 local_policy.jar 和 US_export_policy.jar 两个⽂件复制到
$JAVA_HOME/jre/lib/security ⽬录下, 如果之前⽬录存在同名jar包, 则覆盖即可.
2. 添加配置
在Config Server服务中添加bootstrap.yml⽂件, 设置密钥
对称加密密钥
encrypt:
key: jqq3. 添加bootstrap依赖
config server v3.0.0以上时, bootstrap.yml⽂件不会加载, 需要引⼊bootstrap相关的依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>4. 测试
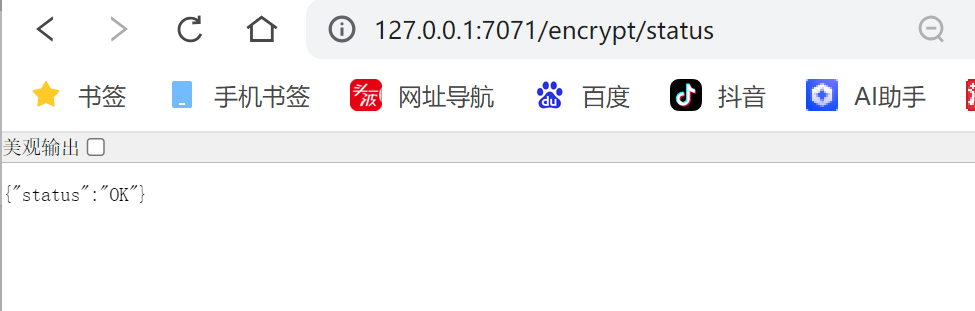
访问: http://127.0.0.1:7071/encrypt/status
7071为 Config Server的端⼝, 需要改为⾃⼰对应的端⼝号
出现以下结果, 就表⽰我们的加密环境配置是正确的
5. 常⻅问题
◦ 访问时出现"The encryption algorithm is not strong enough"
原因是未配置密钥
◦ 访问时出现"java.lang.UnsupportedOperationException: No encryption for
FailsafeTextEncryptor."
原因是未添加 spring-cloud-starter-bootstrap 依赖
加密解密演⽰:
加密环境准备完成之后, 就可以尝试访问下 /encrypt 和 /decrypt 来使⽤加密解密功能
源码实现在: EncryptionController
通过cmd, 来观察加密解密

也可以通过postman来观察加密解密 加密:
加密解密案例实现
通过Config Server 可以对数据进⾏加密, 那么在Config Client中, 就可以使⽤加密后的数据进⾏传输了. 把加密后的数据, 更新到git配置⽂件中, 并在加密结果前添加 {cipher} , 如果远程属性源包含加密的内容(以 {cipher} 开头), 则将其解密, 通过Http发送给客⼾端.
1. 修改配置
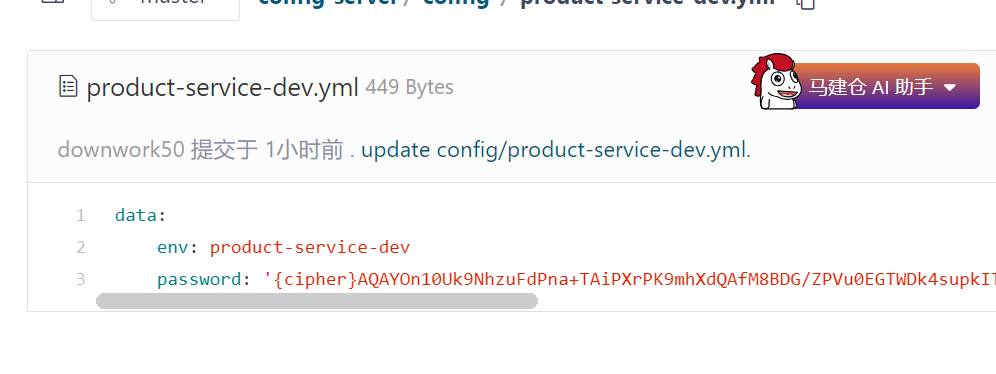
2. 读取配置
在ConfigController 添加代码
@RefreshScope
@RestController
@RequestMapping("/config")
public class ConfigController {
@Value("${data.env}")
private String env;
@Value("${data.password}")
private String password;
@RequestMapping("/getEnv")
public String getEnv(){
return "data.env: "+env;
}
@RequestMapping("/getPassword")
public String getPassword(){
return "data.password: "+password;
}
}3. 测试
访问接⼝: http://127.0.0.1:9090/config/getPassword
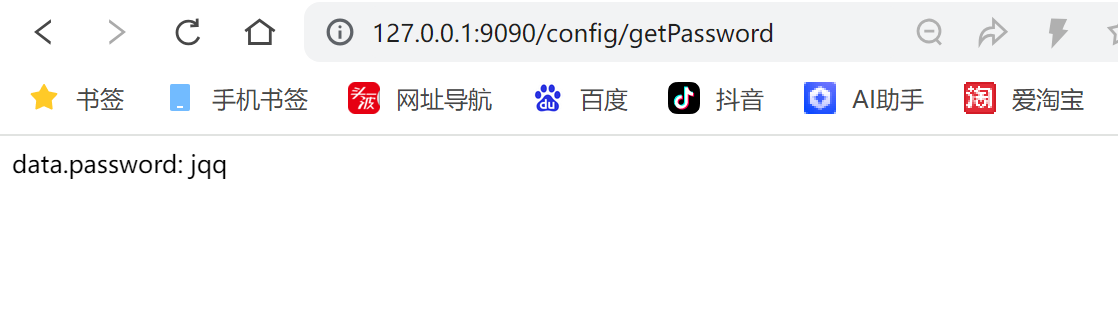
发现客⼾端已完成解密操作
⾮对称加密:
Spring Cloud Config 不仅可以使⽤对称性加密, 也可以使⽤⾮对称性加密(⽐如 RSA 密钥对)。虽然⾮对称性加密的密钥⽣成与配置相对复杂⼀些, 但是它具有更⾼的安全性.
⽣成密钥
⾮对称加密要求我们先⽣成密钥对, 密钥的⽣成我们可以使⽤ JDK 中⾃带的 keytool.
keytool 是⼀个 Java ⾃带的数字证书管理⼯具 , keytool 将密钥(key)和证书 (certificates)存在⼀个称为 keystore 的⽂件中. 它的位置在: %JAVA_HOME%\bin\keytool.exe , 可以直接使⽤cmd来调⽤
打开cmd, 输⼊命令:
keytool -genkeypair -keystore D:/config-server.keystore -alias config-server
-keyalg RSA -keypass config -storepass config-genkeypair 表⽰⽣成密钥对
-alias 表⽰ keystore 关联的别名
-keyalg 表⽰指定密钥⽣成的算法
-keystore 指定密钥库的位置和名称
-keypass -storepass : 密钥库⼝令和密钥⼝令
执⾏过程中, 其它的信息可以输⼊也可以直接回⻋表⽰ Unknown , ⾃⼰做练习⽆所谓, 实际开发中还是建议如实填写. 命令执⾏完成后, 在D盘 路径下就会⽣成⼀个名为 config-server.keystore 的⽂件
执⾏结果如下:
加密解密演⽰:
1. ⽣成密钥之后, 把密钥⽂件放在Config Server中
2. 添加⾮对称加密的相关配置
bootstrap.yml
需要注掉对称加密时的相关配置
非对称加密配置
encrypt:
key-store:
location: config-server.keystore 文件路径
alias: config-server 密钥别名
password: config storepass密钥仓库
secret: config keypass用来保护生成密钥对中的密钥3. 启动Config Server
加密解密的观察和对称加密⼀样, 可以通过cmd观察, 也可以通过postman观察
cmd

Postman 加密:
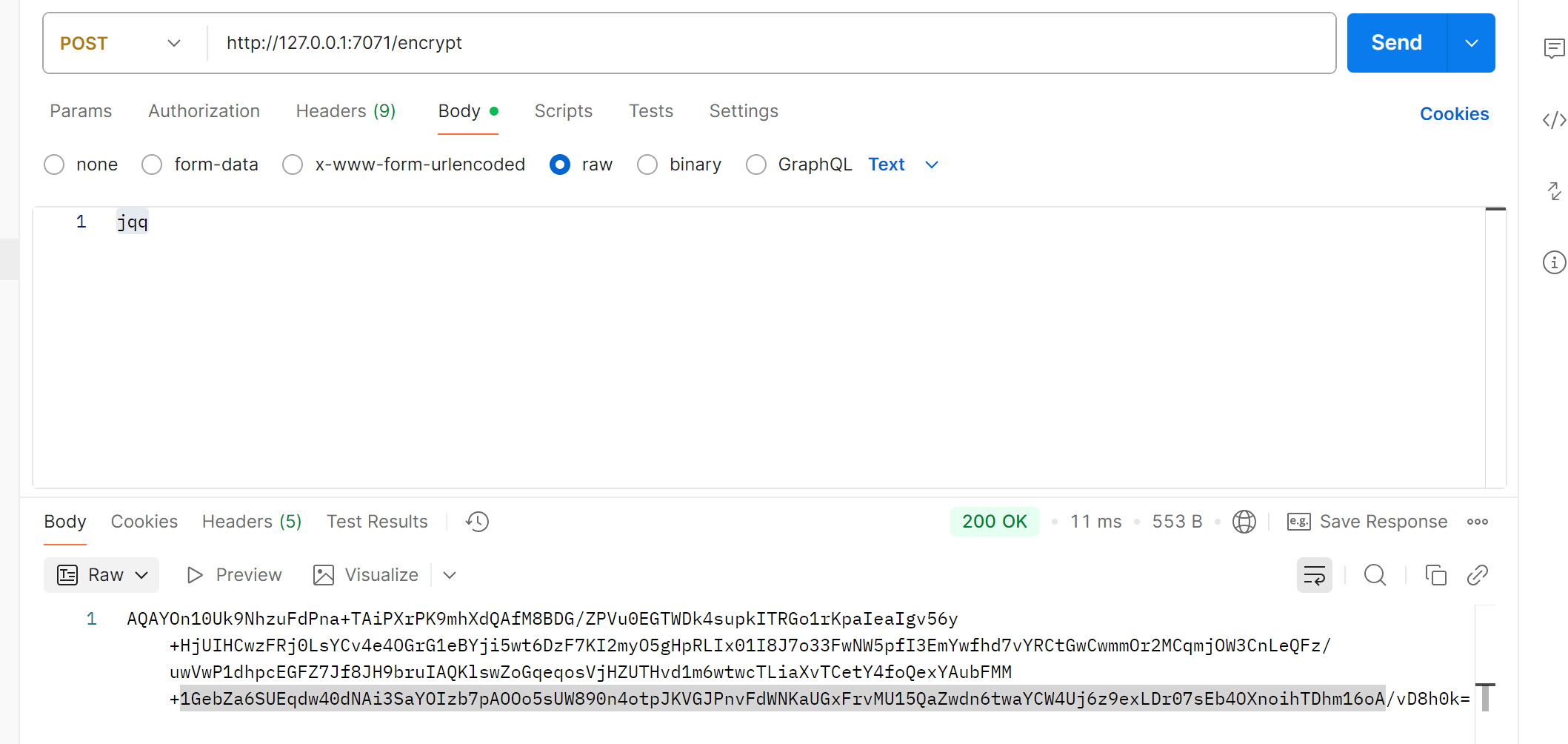
加密解密案例实现:
对于Config Client ⽽⾔, 对称加密和⾮对称加密的使⽤也是⼀样的.
修改配置为⾮对称加密后的密⽂
访问接⼝:http://127.0.0.1:9090/config/getPassword
1. Consul 介绍:
服务注册/服务发现, 除了前⾯讲述的Eureka和Nacos, 还有⼀个⽐较流⾏的组件, 叫Consul.
Consul 是HashiCorp开发的⼀款开源的组件, 主要⽤于服务发现、配置管理和分布式系统的健康检查. 它的主要功能包括:
• 服务注册/发现:服务在启动时向Consul注册, 并在需要时, 向Consul查询其他服务的地址和状态
• 健康检查:Consul提供了健康检查机制, 确保只有健康的服务实例对外提供服务, 防⽌服务转发到故障的服务
• 配置管理: Consul提供了⼀个Key/Value存储系统, ⽤于存储配置数据和其他需要共享的信息.
• 服务分段:Consul⽀持服务分段, 允许你创建隔离的环境, 例如开发, 测试和⽣产环境.
Consul和Nacos区别:
| 功能 | Consul | Nacos |
| 服务注册/发现 | ⽀持 DNS 和 HTTP API | ⽀持 DNS 和 HTTP API |
| 健康检查 | 服务端主动探测(如 HTTP/TCP 检查) | 客⼾端主动上报⼼跳(被动检查) + 服务端主动探测 |
| 配置管理 | 基于 Key-Value 存储,功能较基础 | 专⽤配置中⼼,⽀持动态推送、版本管理、灰度发布 |
| ⼀致性协议 | 基于 Raft 算法的强⼀致性(CP 模型) | 默认 AP(⾼可⽤)模式,可切换为 CP(强⼀致)模式 |
| 性能 | Consul在强⼀致性场景下更可靠,但性能可能有所牺牲 | 吞吐量上更⾼,尤其是处理⼤量实例时 |
2. Consul 安装
下载Consul:
下载地址: developer.hashicorp.com
根据⾃⼰需求, 下载相应的安装包(Linux系统不⽤下载)
安装Consul:
Windows
1. 解压之后, ⾥⾯是⼀个exe⽂件, 使⽤cmd进⼊到该⽬录,输⼊ .\consul.exe --version
.\consul.exe --version如果正确显⽰版本, 则说明下载正确

2. 启动consul
.\consul.exe agent -dev
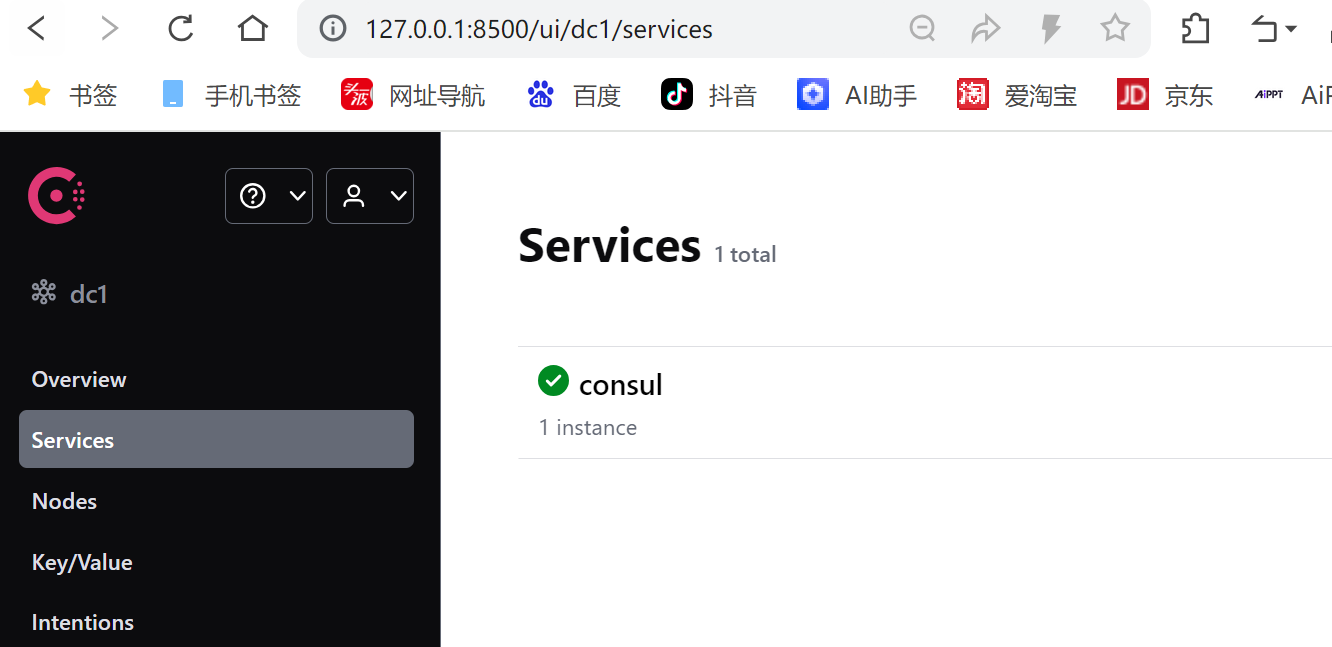
3. 访问Consul http://127.0.0.1:8500/
显⽰如下界⾯, 即表⽰启动成功
4. 配置环境变量(可选)
配置consul的环境变量, 在任意位置通过cmd打开consul
配置之后, 在任意路径下就可以打开consul了
Linux
1. 选择相应的系统, 以Ubuntu为例
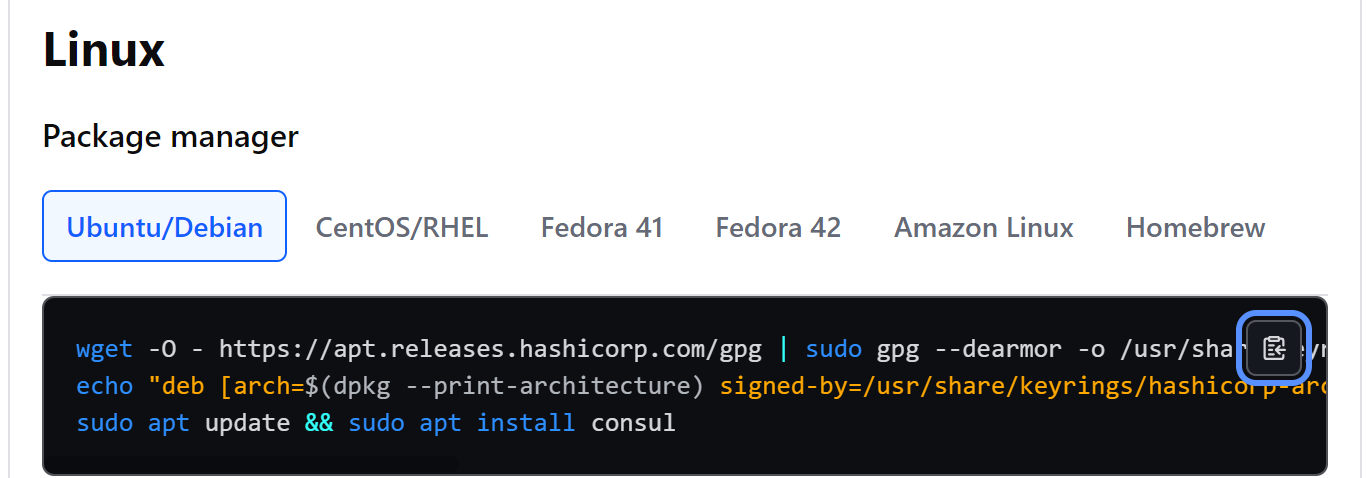
2. 分别执⾏命令
wget -O - https://apt.releases.hashicorp.com/gpg | sudo gpg --dearmor -o
/usr/share/keyrings/hashicorp-archive-keyring.gpg
echo "deb [arch=$(dpkg --print-architecture) signedby=/usr/share/keyrings/hashicorp-archive-keyring.gpg]
https://apt.releases.hashicorp.com $(lsb_release -cs) main" | sudo tee
/etc/apt/sources.list.d/hashicorp.list
sudo apt update && sudo apt install consul3. 确认版本
consul -v4. 启动Consul
nohup consul agent -dev -client 0.0.0.0 -ui &5. 开通端⼝号8500, 访问Consul
http://47.108.157.13:8500/
6. 其他命令
停⽌consul服务
consul leave
卸载consul软件包
sudo apt-get remove consul
sudo apt-get autoremove consul
清理残留⽂件
sudo apt-get autoclean3. 服务注册/服务发现
Consul提供了服务注册和服务发现的功能. 还是以之前的订单服务和商品服务代码为例.
参考: Service Discovery with Consul
添加依赖
Consul ⽀持健康检查, 以确保只有健康的服务实例可被发现, Consul 使⽤了actuator提供服务的健康检查, 所以除了consul之外, 还需要引⼊actuator的依赖
<!--consul依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>添加配置
spring:
application:
name: product-service
cloud:
consul:
host: 127.0.0.1
port: 8500
discovery:
service-name: product-servicespring.cloud.consul.discovery.service-name 可以省略, 默认的服务名称为${spring.application.name}
添加注解 @EnableDiscoveryClient
在主启动类添加注解 @EnableDiscoveryClient
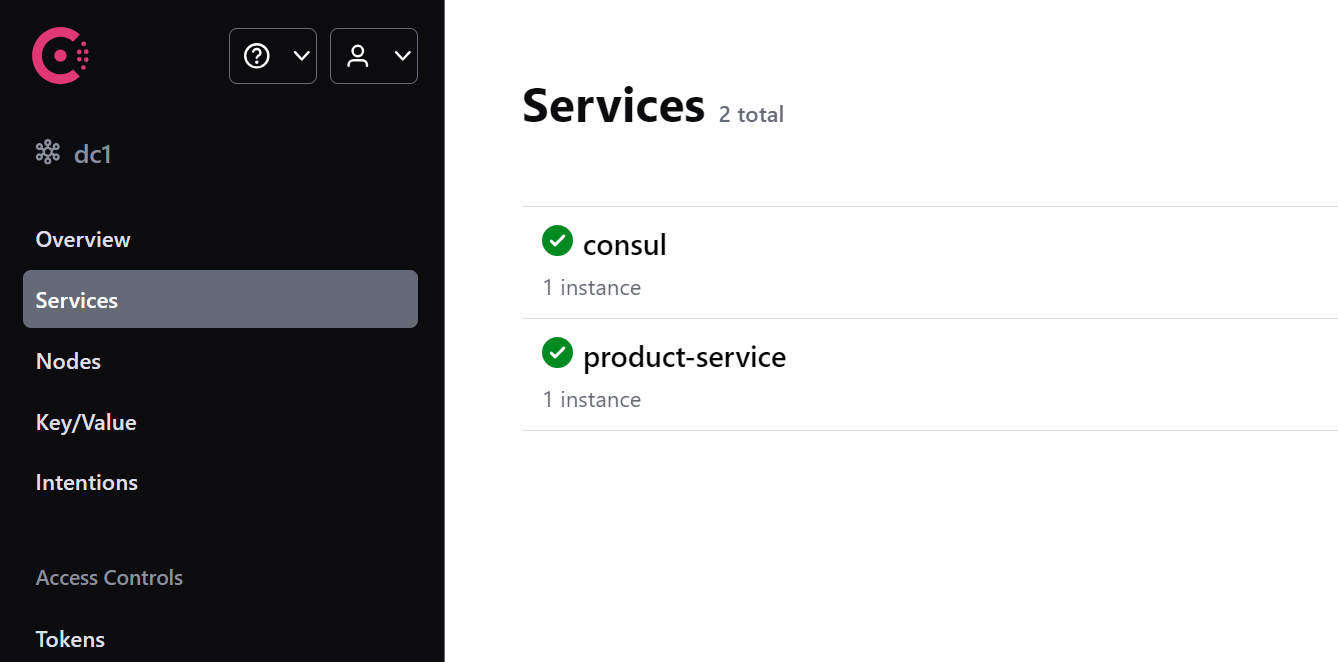
启动服务:
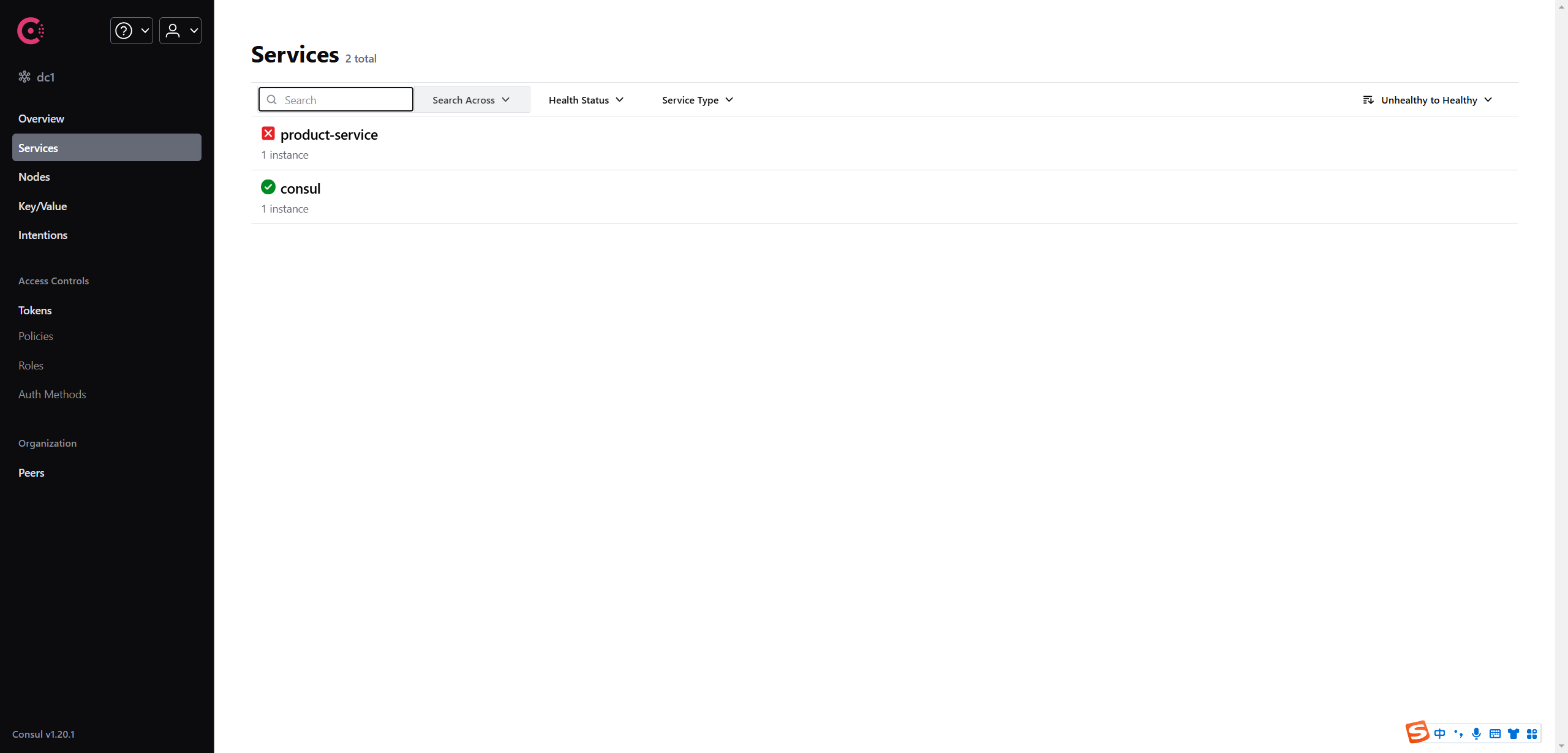
启动服务, 观察Consul, 发现product-service已经注册成功
如果不添加 spring-boot-starter-actuator 依赖, 界⾯如下显⽰:
4. 服务配置和刷新
Consul除了服务注册和发现之外, 还可以作为配置中⼼. 服务的配置信息存储在Consul中, 服务从Consul获取配置信息.
Consul 提供了⼀个键值存储(KV Store)⽤于存储服务配置和其他元数据. 是Spring Cloud Config的替代⽅案, 在特殊的"bootstrap"阶段, 配置被加载到Spring 环境中. 默认情况下, 配置存储在 /config ⽂件夹中. 根据应⽤程序的名称和激活的配置⽂件, 会创建多个 PropertySource 实例. 当前配置在应⽤程序启动时读取, 向/refresh发送HTTP POST请求将导致配置重新加载. Config Watch也会⾃动检测变化并重新加载应⽤程序上下⽂.
Consul provides a Key/Value Store for storing configuration and other metadata. Spring Cloud Consul Config is an alternative to the Config Server and Client. Configuration is loaded into the Spring Environment during the special "bootstrap" phase. Configuration is stored in the
/config folder by default. Multiple PropertySource instances are created based on the application’s name and the active profiles that mimics the Spring Cloud Config order of resolving properties.
Configuration is currently read on startup of the application. Sending a HTTP POST to /refresh will cause the configuration to be reloaded. Config Watch will also automatically detect changes and reload the application context.
摘⾃: Distributed Configuration with Consul
初始化配置
1. 创建⽬录
使⽤ Consul 作为配置中⼼, 我们需要创建⽬录, 把配置信息存储⾄ Consul.
点击菜单 Key/Value -> Create 按钮 -> 创建 config/ 基本⽬录
可以把config理解为配置⽂件所在的最外层⽂件夹(⽂件夹以 / 结尾 ).
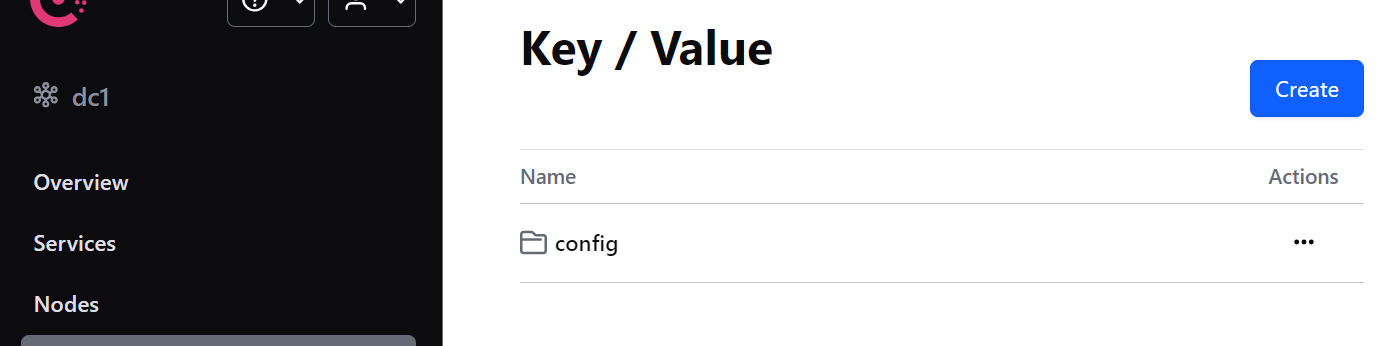
2. 创建应⽤⽬录
点击 config 进⼊⽂件夹, 再点击 Create 按钮
创建 product-service/ 应⽤⽬录,存储对应微服务应⽤的 default 环境配置信息
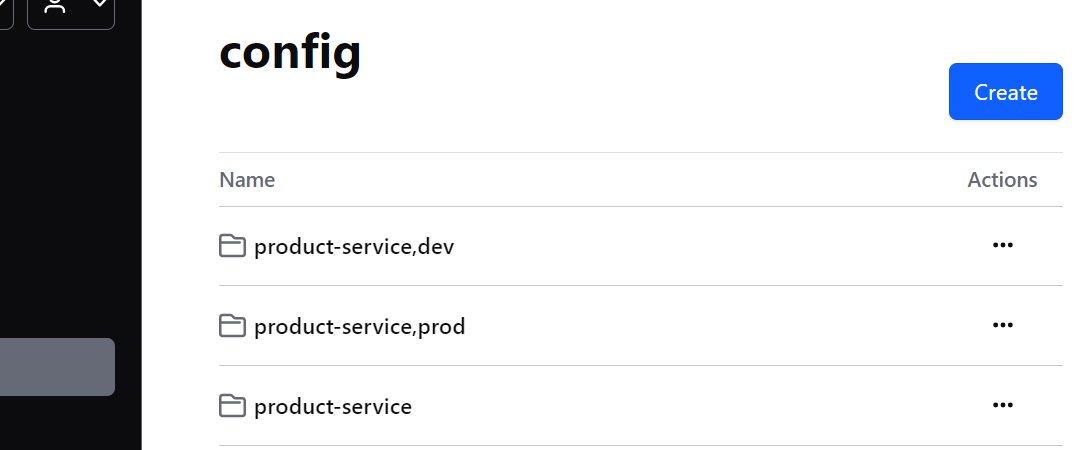
如果我们的项⽬有多个环境; default, dev, prod, 就在 config ⽬录下创建对应的多环境⽬录
• config/product-service/ 对应使⽤ config 前缀的, 名称为 product-service 的应⽤
• config/product-service,dev/ 对应使⽤ config 前缀的, 名称为 product-service, 且启⽤dev profile 的应⽤
• config/product-service,prod/ 对应使⽤ config 前缀的, 名称为 product-service, 且启⽤prod profile 的应⽤
默认情况下, 配置的路径前缀是 /config
3. 添加配置信息
在product-service下创建⽂件
填写key: data 填写value:
service-name: product-service-default
output:
info: "jqq-default"同样的, 依次在 config/product-service,dev/ 和 config/product-service,prod/下创建相应的⽂件, 并修改配置⽂件内容.
⽐如dev:
service-name: product-service-dev
output:
info: "jqq-dev"项⽬配置
1. 添加依赖
Spring Cloud 会创建⼀个 Bootstrap Context , 作为Spring 应⽤"Application Context" 的⽗上下
⽂. 在Spring应⽤启动的初始化阶段, Bootstrap Context 负责从外部源(如Consul)加载配置
属性并解析配置.
所以除了添加 spring-cloud-starter-consul-config 依赖之外, 还需要加⼊依赖 spring-
cloud-starter-bootstrap 来实现
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>配置⽂件
Bootstrap属性具有⾼优先级, 也就是说在 bootstrap.yml 或 bootstrap.properties 中定义的配置会优先于 application.yml 或 application.properties 中的配置.
bootstrap.yml 主要⽤于配置应⽤启动时所需的外部依赖和环境, ⽽ application.yml ⽤于业务逻辑相关的配置(如数据库连接等)
bootstrap.yml
spring:
application:
name: product-service
profiles:
active: dev
cloud:
consul:
host: 127.0.0.1
port: 8500
config:
format: YAML在 Spring 启动的 bootstrap 阶段会通过 Consul 去获取 key = config/product-service/data 对应的 value
对应value格式为 yaml
测试
@RestController
@RequestMapping("/consul")
public class ConsulController {
@Value("${service-name}")
private String serviceName;
@Value("${output.info}")
private String outputInfo;
@RequestMapping("getConsulConfig")
public String getConsulConfig(){
return String.format("从consul中获取配置信息,service-name:%s,outputInfo:%s",serviceName,outputInfo);
}
}
启动服务, 测试接⼝: http://127.0.0.1:9090/consul/getConfigByConsul

设置 spring.profiles.active , 再次观察运⾏结果.
spring.profiles.active=dev
动态刷新
Consul⽀持动态刷新配置, 在配置类上添加 @RefreshScope 注解, 可以标记需要动态刷新的Bean. 当接收到刷新事件时,这些Bean会重新加载最新的配置.
//动态刷新,只针对修改,不针对新增
@RefreshScope
@RestController
@RequestMapping("/consul")
public class ConsulController {
...
}尝试修改相应的配置⽂件, 访问接⼝, 观察配置是否得到了更新.
Consul会对配置更新进⾏检查, 跟服务器上⾯的配置⽂件的版本进⾏⽐较, 如果版本不⼀致, 则调⽤Spring的刷新事件, 触发事件刷新, 否则代表配置没有变化.
默认的检查频率为 1000 单位毫秒, 可以通过 spring.cloud.consul.config.watch.delay 配置.
Consul的动态刷新功能使得配置变更⽆需重启应⽤程序,⼤⼤提⾼了运维效率和系统的灵活性
其他配置
config/application配置
默认情况下, 配置的路径前缀是 /config , 不同的 application 和 profile 对应不同的配置路径, 例如对应应⽤ "product-service" 和 "dev" profile 的配置, 会涉及以下路径
config/product-service,dev/
config/product-service/
config/application,dev/
config/application/这个列表从上往下分别对应的配置优先级从⾼到低, 优先级⾼的同样配置项会覆盖优先级低的配置项.
• config/application/ 全局公共配置, 对应使⽤ config 前缀的所有应⽤
• config/application,dev/ 全局dev公共配置, 对应使⽤ config 前缀的所有, 且启⽤ dev profile 的应⽤
• config/product-service/ 对应使⽤ config 前缀的, 名称为 product-service 的应⽤
• config/product-service,dev/ 对应使⽤ config 前缀的, 名称为 product-service, 且启⽤ dev profile 的应⽤
1. 添加config/application/配置
service-name: default-application
output:
info: application 2. 对order-service添加相应的依赖和配置
bootstrap.yml和ConsulController.java 同 product-service
3.测试
启动order-service, 访问http://127.0.0.1:8080/consul/getConfigByConsul, 可以读取到config/application/相关的配置信息
bootstrap.yml更多配置
spring:
cloud:
consul:
host: 127.0.0.1
port: 8500
config:
# 是否启⽤配置中⼼,默认值 true 开启
enabled: true
# 设置配置的基本⽂件夹,默认值 config 可以理解为配置⽂件所在的最外层⽂件夹
prefix: config
# 配置环境分隔符,默认值 "," 和 default-context 配置项搭配
# 例如应⽤ product-service 分别有环境 default, dev, prod
# 需在 config ⽂件夹下创建 product-service, product-service-dev,
product-service-prod ⽂件夹即可
profile-separator: '-'
# 指定配置格式为 yaml
format: YAML
# Consul 的 Key/Values 中的 Key, Value 对应整个配置⽂件
data-key: productConfig
# 以上配置可以理解为:加载 config/product-service/ ⽂件夹下 Key 为
productConfig 的 Value 对应的配置信息
watch:
# 是否开启⾃动刷新,默认值 true 开启
enabled: true
# 刷新频率,单位:毫秒,默认值 1000
delay: 10005. Consul 配置持久化
通过上⾯, 我们了解了Consul的配置和动态刷新, 但是当我们重启Consul时, 会发现Consul存储的数据都会丢失了, 这与我们的启动命令有关
Consul常⻅启动命令
consul agent [options]• -dev 开发模式, 关闭所有持久化选项, ⽤于快速开启consul代理
• -server:以服务器模式启动 Consul 代理.
• -client:以客⼾端模式启动 Consul 代理.
• -ui:启⽤ Consul 的 Web ⽤⼾界⾯.
• -bootstrap-expect:设置期望加⼊的服务器节点数, ⽤于初始化集群.
• -data-dir:指定数据存储⽬录
开发模式( -dev )主要⽤于快速启动单节点 Consul 环境, 适⽤于开发和测试, 不适⽤于⽣产环境,因为它不会持久化任何状态. ⽽服务器模式(-server)和客⼾端模式(-client)则更多地⽤于⽣产环境, 以构建⼀个完整的 Consul 集群.
服务器模式是 Consul 集群的核⼼, 负责处理集群的管理和数据存储. 客⼾端模式更轻量级, 主要⽤于服务发现和健康检查, 不参与集群的管理和数据存储.
学习了这些命令之后, 我们可以指定Consul数据的存储⽬录
consul agent -server -bootstrap-expect 1 -ui -datadir=D:\soft\consul_data\mydata使⽤上述命令启动Consul, 会发现数据进⾏了持久化.
Alibaba Sentinel:
1. 初识熔断和限流
在互联⽹应⽤中, 会有很多突发性的⾼并发访问场景, ⽐如618, 双11⼤促, 秒杀等, 这些场景的特点是访问量会突增,远远超出系统所能处理的并发数, 如果系统没有有效的保护机制, 所有流量都进⼊服务器, 很可能造成服务器宕机, 从⽽造成巨⼤损失.
为了保证系统的稳定性和可⽤性, 采取⼀定的系统保护策略变得⾄关重要. 其中, 服务限流和服务熔断是两种常⻅的策略.
熔断
服务熔断机制类似于电⼒系统中的保险丝, 当电流超过保险丝的承载能⼒时, 保险丝会熔断以保护电路不受损害. 在分布式系统中, 服务间依赖⾮常常⻅, 当某个服务不可⽤时, 如果没有有效的隔离措施, 故障可能会迅速扩散到整个系统, 导致系统雪崩.
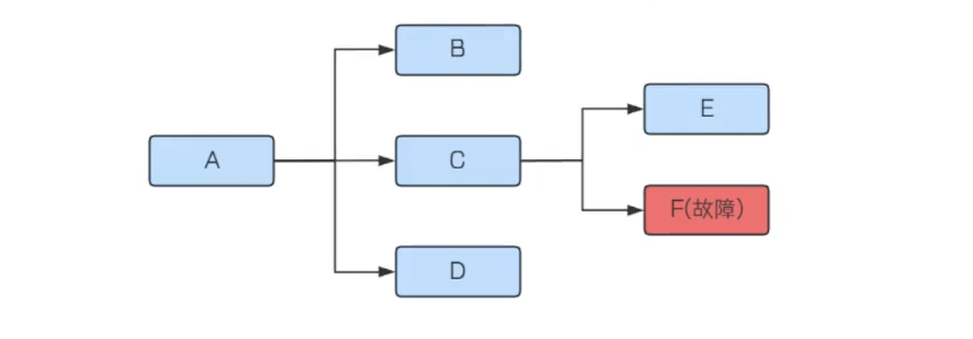
如上图, 当F发⽣了故障不能及时响应, C调⽤F时, 只能阻塞等待, 直到超时. 如果流量⽐较⼤, 每个请求都等到超时才进⾏响应, 那么系统C的线程资源很快就会被耗尽不能对外提供服务了(处理完成后, 才会释放资源).
服务熔断机制就是解决这个问题的. 服务熔断是指当某个服务⽆法正常为服务调⽤者提供服务时, ⽐如请求超时, 服务异常等, 为了防⽌整个系统出现雪崩效应, 暂时将出现故障的接⼝隔离出来, 断绝与外部接⼝的联系, 当触发熔断之后, 后续⼀段时间内该服务调⽤者的请求都会直接失败(⽆需等待到超时), 直到⽬标服务恢复正常.应对故障
熔断机制能够在服务故障时及时切断调⽤链, 防⽌故障扩散, 减少对故障服务的资源消耗, 保护系统资源不被耗尽, 从⽽保护系统的整体稳定性和可⽤性.
限流
限流, 就是限制流量的意思,应对高负载。
在⽇常⽣活中, 限流可以类⽐为控制进⼊某个区域或者参与某个活动的⼈数.
⽐如, ⼀个餐厅为了保证顾客的⽤餐体验, 会限制同时⽤餐的⼈数. ⼀个景区为了避免过度拥挤, 会限制每天的游客数量等.
景区限流通知
在互联⽹应⽤中, 限流可以确保服务器能够处理的请求数量在合理范围内, 避免因请求过多导致服务响应慢或失败.可以保证⽤⼾在⾼流量时段仍然能够获得快速响应, 提升⽤⼾体验.
在餐厅中, 如果顾客过多, 服务员可能⽆法及时为每位顾客提供服务, 导致服务质量下降. 限流可以确保每位顾客都能得到满意的服务.
2. Sentinel介绍:
Sentinel 是由阿⾥巴巴开源的⼀个⾯向分布式、多语⾔异构化服务架构的流量治理组件. 主要以流量为切⼊点,从流量路由、流量控制、流量整形、熔断降级、系统⾃适应过载保护、热点流量防护等多个维度来帮助开发者保障微服务的稳定性.
Sentinel的特性:
1. 丰富的应⽤场景
阿⾥巴巴 10 年双⼗⼀积累的丰富流量场景,包括秒杀、双⼗⼀零点持续洪峰、热点商品探测、预热、消息队列削峰填⾕等多样化的场景
2. 易于使⽤, 快速接⼊
简单易⽤, 开源⽣态⼴泛, 针对 Dubbo、Spring Cloud、gRPC、Zuul、Reactor、Quarkus 等框架只需要引⼊适配模块即可快速接⼊.
3. 多样化的流量控制
资源粒度、调⽤关系、指标类型、控制效果等多维度的流量控制4. 可视化的监控和规则管理
4.可视化的监控和管理规则
Sentinel提供了简单易⽤的 Sentinel 控制台, 开发者可以在控制台中看到接⼊的应⽤流量, 以及配置限流规则等.
Sentinel组成:
Sentinel分为两个部分
1. 核⼼库(Java 客⼾端),SDK: 不依赖任何框架/库, 能够运⾏于所有 Java 运⾏时环境, 同时对 Dubbo / Spring Cloud 等框架也有较好的⽀持.
2. 控制台(Dashboard) 基于 Spring Boot 开发, 打包后可以直接运⾏, 不需要额外的 Tomcat 等应⽤容器.
Sentinel Dashboard下载和部署
Sentinel 官⽅提供了⼀个轻量级的开源控制台, ⽅便我们观察和操作.
1. 下载
下载地址: https://github.com/alibaba/Sentinel/releases
2. 启动Sentinel Dashboard
把下载的jar放在⼀个⽬录下, 通过cmd 启动jar 使⽤cmd, 启动命令
java -jar .\sentinel-dashboard-1.8.8.jar访问: http://127.0.0.1:8080
默认⽤⼾名和密码都是: sentinel
修改端⼝号和账号密码
java -jar -Dserver.port=8100 -Dsentinel.dashboard.auth.username=admin -Dsentinel.dashboard.auth.password=admin -Dserver.servlet.session.timeout=1440m sentinel-dashboard.jar用户可以通过如下参数进行配置:
-Dsentinel.dashboard.auth.username=sentinel用于指定控制台的登录用户名为sentinel;-Dsentinel.dashboard.auth.password=123456用于指定控制台的登录密码为123456;如果省略这两个参数,默认用户和密码均为sentinel;-Dserver.servlet.session.timeout=7200用于指定 Spring Boot 服务端 session 的过期时间,如7200表示 7200 秒;60m表示 60 分钟,默认为 30 分钟;
同样也可以直接在 Spring properties 文件中进行配置。
更多配置参考: https://sentinelguard.io/zh-cn/docs/dashboard.html #控制台配置项模块
3. Sentinel 快速上⼿
官方文档地址:https://sentinelguard.io/zh-cn/docs/dashboard.html
Sentinel 的核⼼功能是流量控制和熔断降级, 我们先看看看如何使⽤Sentinel核⼼库来实现限流. 使⽤Sentinel核⼼库来实现限流, 主要分以下⼏个步骤:
1. 添加依赖
2. 定义资源
3. 定义限流规则
4. 检验规则是否⽣效
接下来通过⼀个简单的案例, 来演⽰⼀下Sentinel限流.
1. 创建空的maven项⽬
2. 添加依赖
添加Sentinel核⼼库
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.8.6</version>
</dependency>3. 定义资源
资源是 Sentinel 的关键概念, 被Sentinel监控的每个接⼝就是⼀个资源. 它可以是 Java 应⽤程序中的任何内容, 例如, 由应⽤程序提供的服务, 或由应⽤程序调⽤的其它应⽤提供的服务, 甚⾄可以是⼀段代码.
限流, 熔断等都是针对资源来设置的
private static void test(int i) {
try(Entry entry = SphU.entry("resourceName")){
//业务逻辑处理
System.out.println("执⾏test⽅法"+ i);
} catch (BlockException e) {
//处理限流时的逻辑
System.out.println("触发限流.." +i );
}
}在test⽅法中, 通过使⽤Sentinel 中的 SphU.entry("resourceName") 定义⼀个资源, ⽅便后续配置流控规则.
它表⽰当请求进⼊test⽅法时, 需要进⾏限流判断, 如果抛出BlockException 异常, 则表⽰触发了限流.
4. 针对该资源定义限流规则
对资源 resourceName 设置QPS不超过10.
private static void initFlowRules(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("HelloWorld");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// Set limit QPS to 20.
rule.setCount(20);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}针对资源 resourceName 设置限流规则.
• resource : 资源名称
• Grade: 限流阈值类型. QPS模式(1) 或并发线程数模式(0)
1. RuleConstant.FLOW_GRADE_QPS : 默认的流量控制阈值类型, 表⽰每秒请求次数(QPS).当设置 grade 为 RuleConstant.FLOW_GRADE_QPS 时, Sentinel会根据设置的QPS值来控制流量.
2. RuleConstant.FLOW_GRADE_THREAD :并发线程数. 当设置 grade 为RuleConstant.FLOW_GRADE_THREAD 时, Sentinel会根据设置的并发线程数来控制流量.
• count: 限流阈值
5. 调⽤资源, 校验规则是否⽣效
public static void main(String[] args) {
initFlowRules();
for (int i = 0; i < 30; i++) {
test(i);
}
}调⽤20次, 观察运⾏结果:
hello world0
hello world1
hello world2
hello world3
hello world4
hello world5
hello world6
hello world7
hello world8
hello world9
hello world10
hello world11
hello world12
hello world13
hello world14
hello world15
hello world16
hello world17
hello world18
hello world19
blocked!20
blocked!21
blocked!22
blocked!23
blocked!24
blocked!25
blocked!26
blocked!27
blocked!28
blocked!29通过⽇志可以观察, 当QPS超过20时, 请求就会被拒绝.
4. Spring Cloud 集成Sentinel
项⽬准备
使⽤Spring Cloud Gataway开发之后的项⽬
(这个项⽬包含服务注册/发现, 服务调⽤, 负载均衡等)
添加依赖
以order-service来演⽰
<!--sentinel的依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>配置sentinel控制台
spring:
cloud:
sentinel:
transport:
dashboard: 127.0.0.1:8100 sentinel控制台地址
client-ip: 127.0.0.1 连接本地Sentinel 可以不配置, 连接服务器Sentinel 需
要配置⼀下client-ip访问任意接⼝, 触发sentinel监控
访问任意接⼝, 触发sentinel监控
http://127.0.0.1:8080/order/1
也可以观察服务的簇点链路
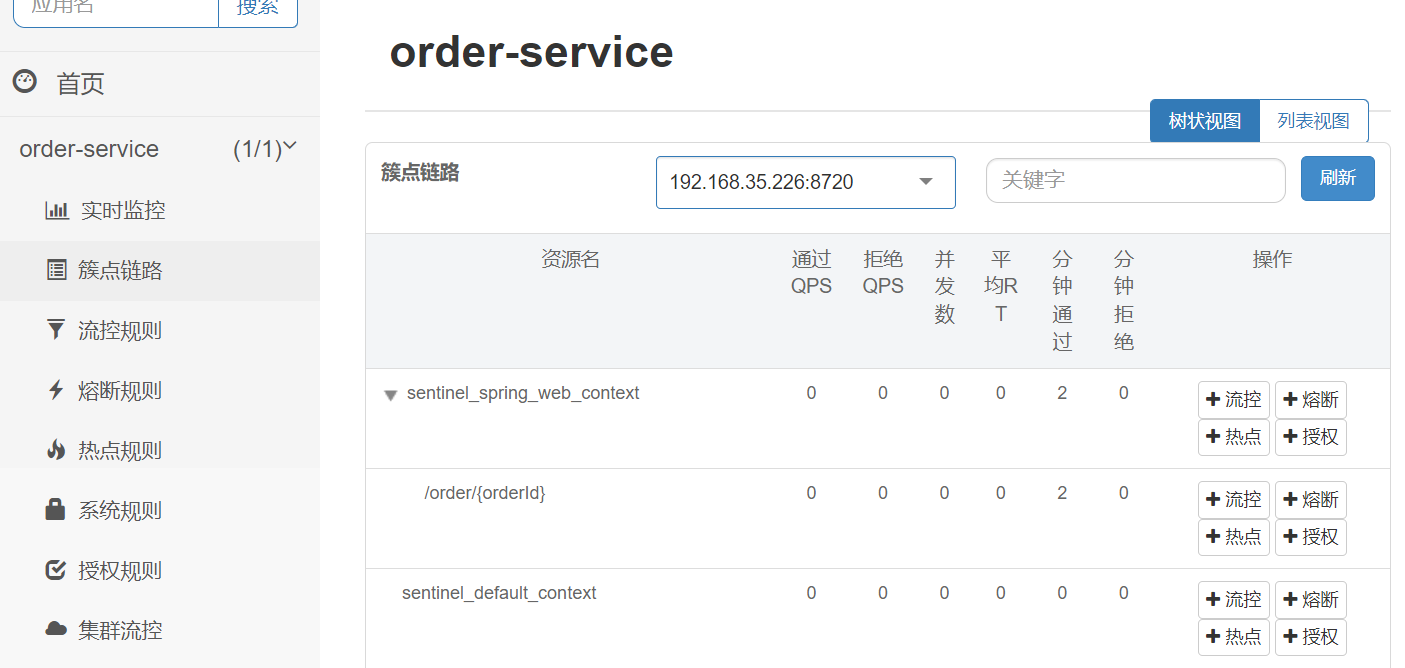
簇点链路: 是指在微服务架构中, 请求从进⼊服务到处理完成所经过的完整调⽤链路. 当请求进⼊服务时, ⾸先会访问DispatcherServlet, 然后进⼊Controller, Service, Mapper, 这样的⼀个调⽤链就叫做簇点链路.
默认情况下, Sentinel starter会为Spring MVC的所有HTTP服务提供限流埋点, 所以如果只想对HTTP服务进⾏限流, 那么只需要添加依赖即可, 不需要修改任何代码. 如果想要对特定的⽅法进⾏限流或者降级, 则可以⾃定义资源来实现.
流控, 熔断等都是针对簇点链路中的资源来设置的, 因此我们可以点击对应资源后⾯的按钮来设置规则:
• 流控:流量控制
• 熔断:服务熔断
• 热点:热点参数限流, 是限流的⼀种
• 授权:请求的权限控制
5. 流量控制
配置流控规则
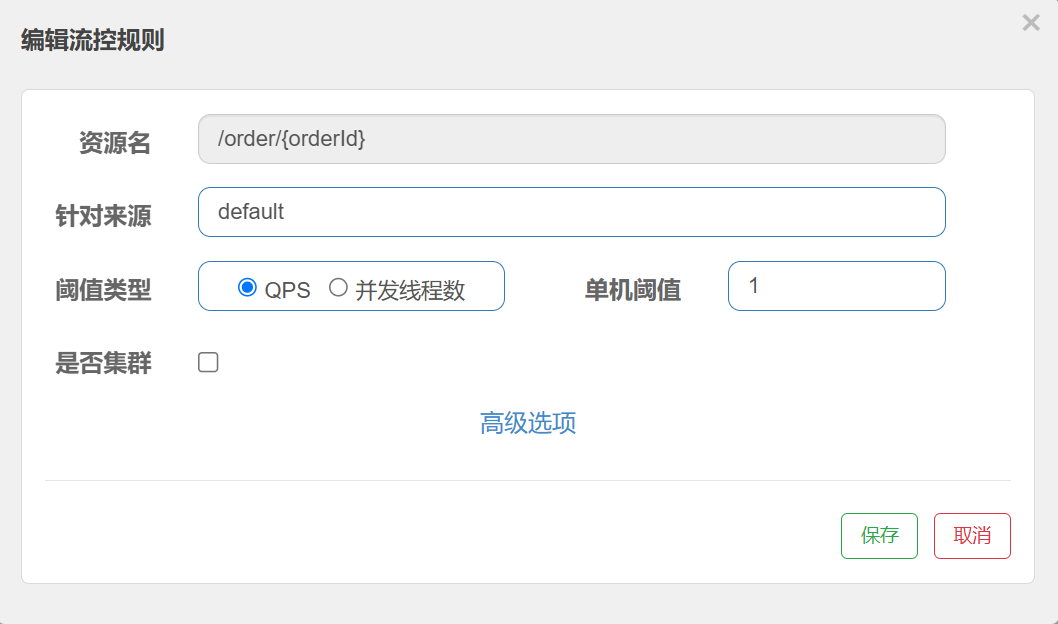
点击资源右边的按钮[流控] 进⾏流量控制配置
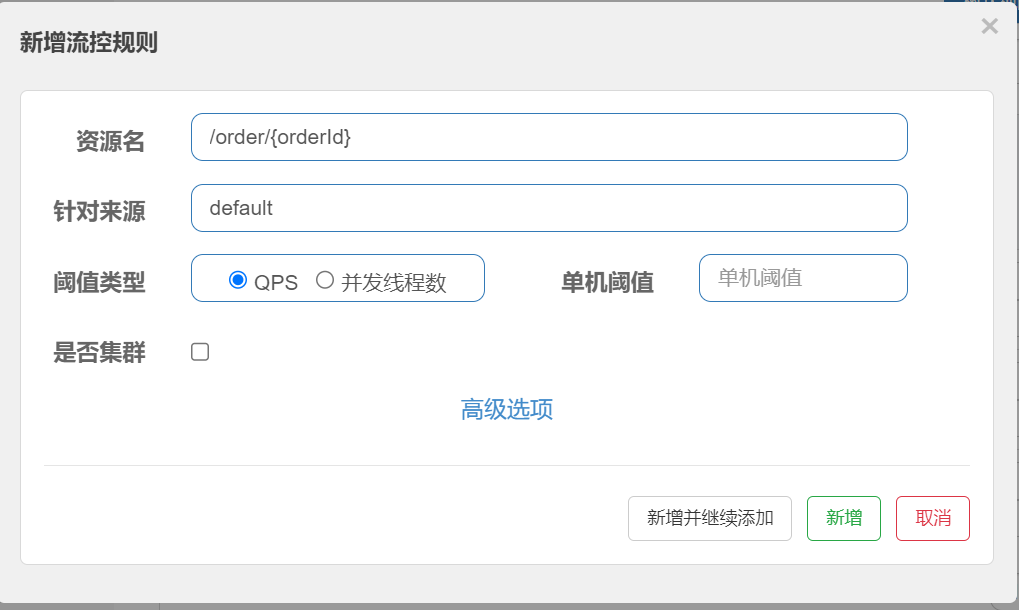
配置阈值为1, 即每秒只允许1次请求, 超出的请求会被拦截并报错.
测试接⼝, 快速请求多次:\
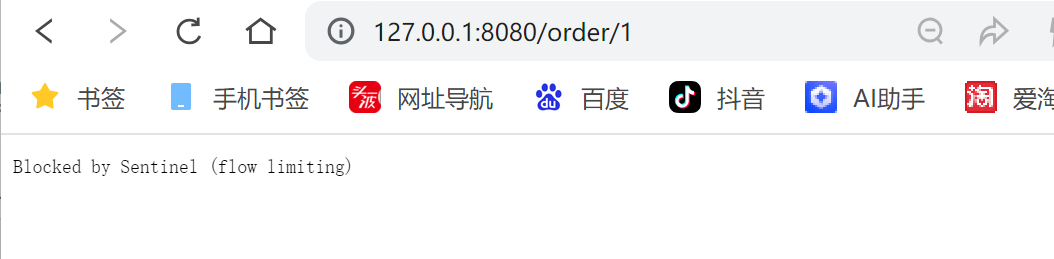
也可以使⽤Jmeter来测试.
JMeter简单介绍参考:
1. 下载
Apache JMeter 是 Apache 组织基于 Java 开发的压⼒测试⼯具,⽤于对软件做性能测试 Apache JMeter官⽹下载地址:http://jmeter.apache.org/download_jmeter.cgi

2. 安装JMeter
环境要求

解压
解压后⽬录如下
打开JMeter
⽅式⼀:点击bat⽂件
⽅式⼆:命令⾏启动(推荐)
1. 添加JMeter系统环境变量

2. 打开cmd, 输⼊jmeter
即可启动jmeter程序
 JMeter基础配置
JMeter基础配置
• 修改字体为中⽂
在jmeter的bin⽬录下,修改jmeter.properties⽂件中的内容:language=zh_CN
3. JMeter基本使⽤流程
1. 启动JMeter
2. 在"测试计划"下添加"线程组"

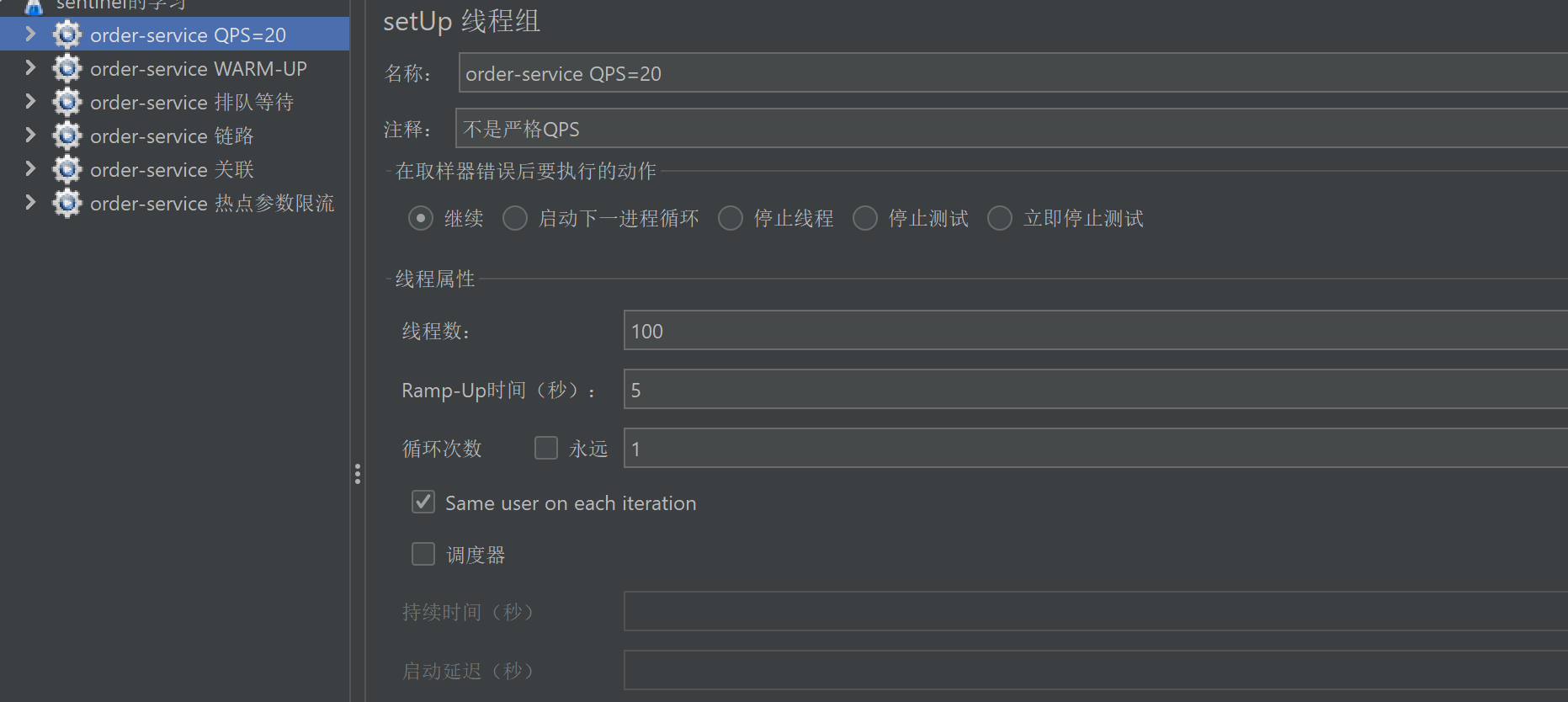
线程数:可以把⼀个线程理解为⼀个测试⽤⼾, 设置发送的请求次数
Ramp-up时间(秒):设置测试运⾏时间,单位为秒
循环次数:
◦ 配置指定次数:控制脚本循环执⾏的次数
◦ 配置循环永远
▪ 需要调度器配置使⽤
▪ 运⾏时间:脚本执⾏时间
▪ 延迟启动时间:脚本等待指定时间才能运⾏
3. 在"线程组"下添加"HTTP"取样器
4. 填写“HTTP请求”的相关请求数据
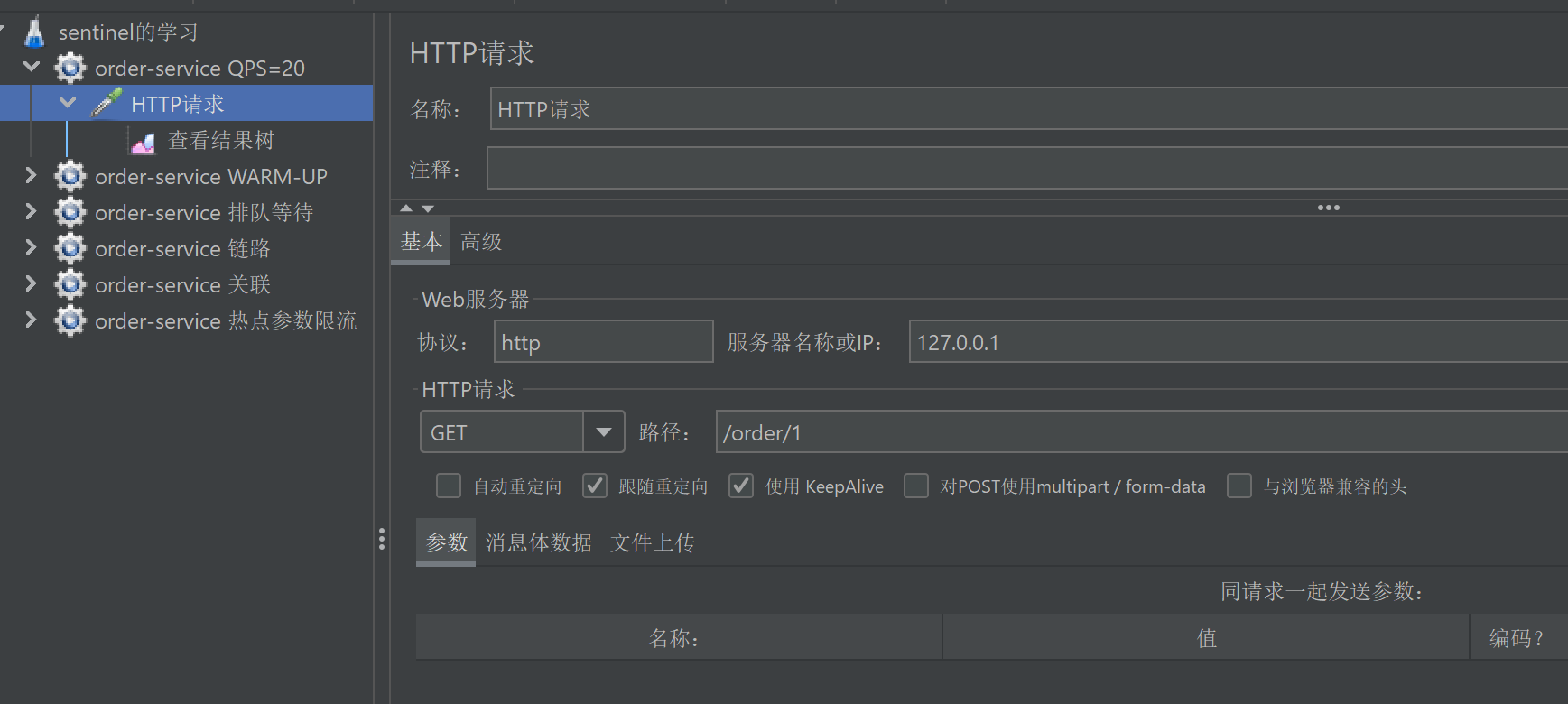
添加必需的配置:
http协议 http主机名/IP 端⼝号
请求⽅法
路径(⽬录+参数)
内容编码(默认的ISO国际标准,但对中⽂⽀持不友好,可以使⽤utf-8)
参数
◦ 参数可以拼在路径⾥,也可以写在参数中
◦ POST参数要放到消息体数据中{wd:test}
5. 在"线程组"下添加"查看结果树"监听器
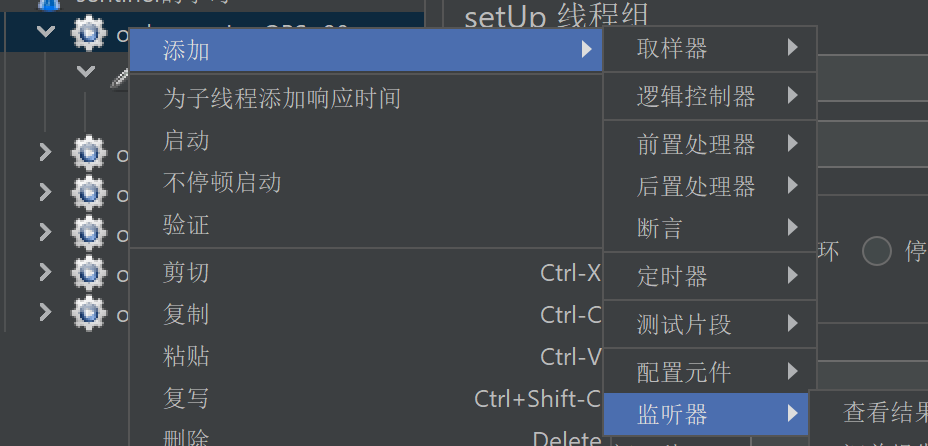
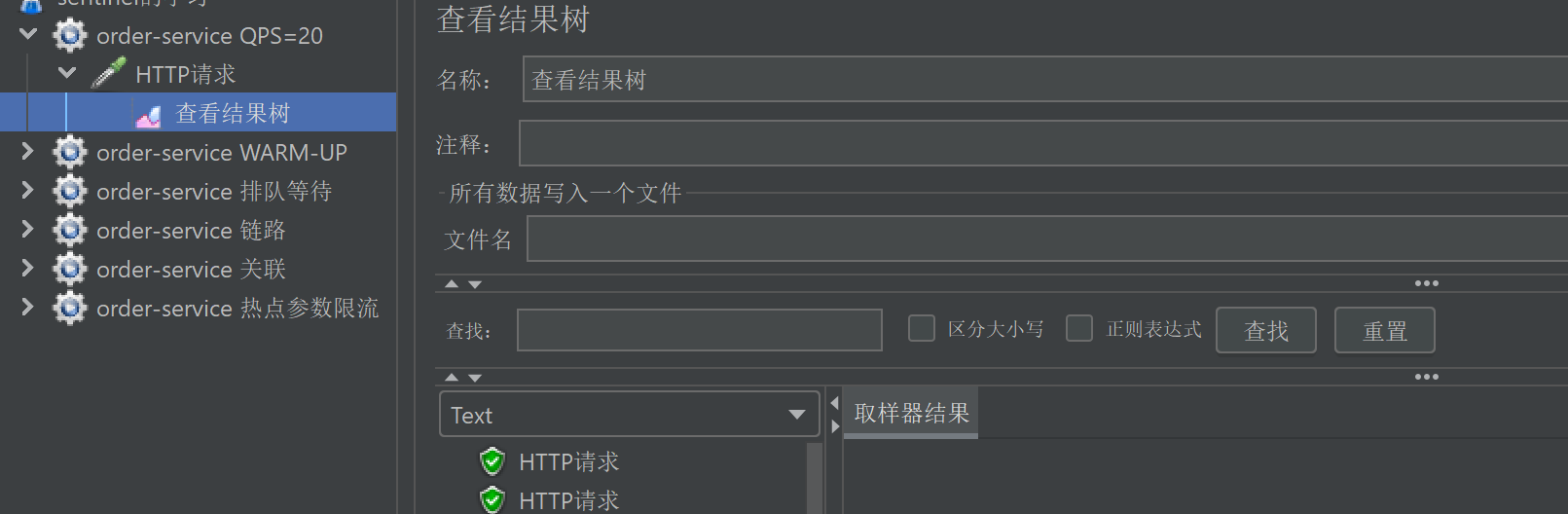
6. 点击"启动"按钮运⾏,查看接⼝测试结果
---------------------------------------------------------------------------------------------------------------------------------
设置流控规则: 单机阈值为15
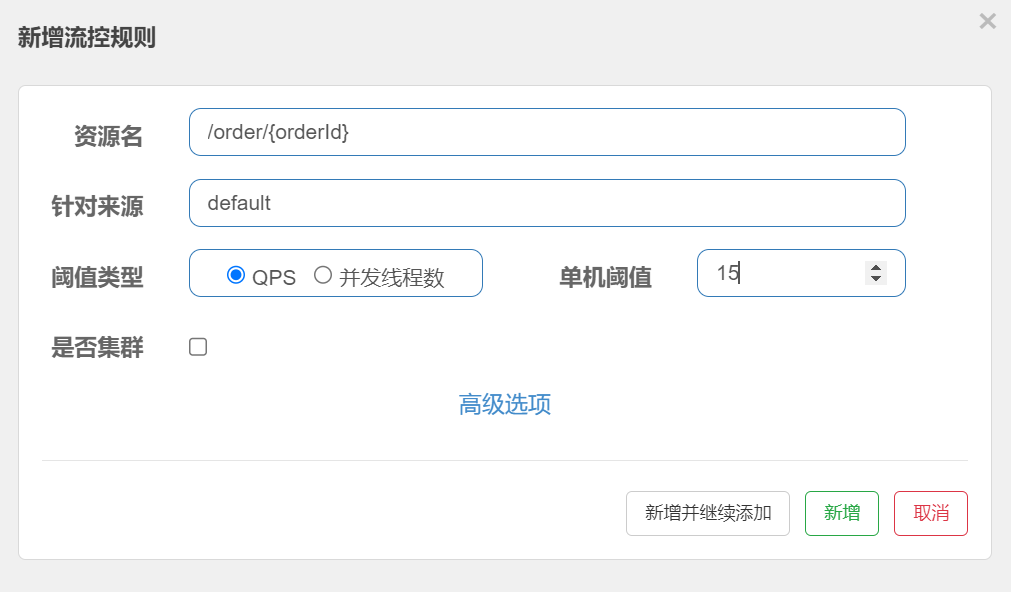
创建测试任务
5秒发送100个请求
启动, 查看结果
注意: 不要点击菜单中的执⾏按钮来运⾏
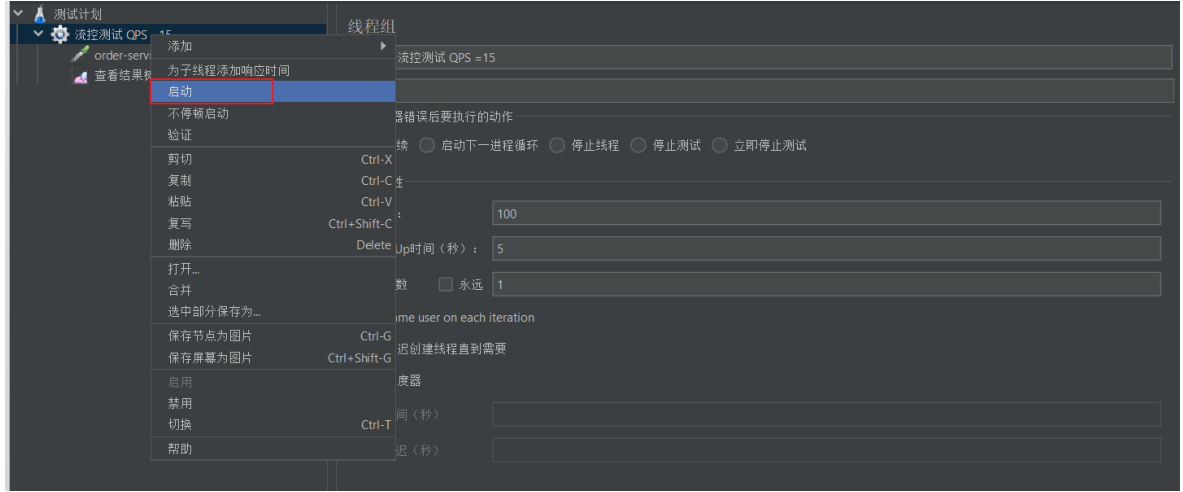
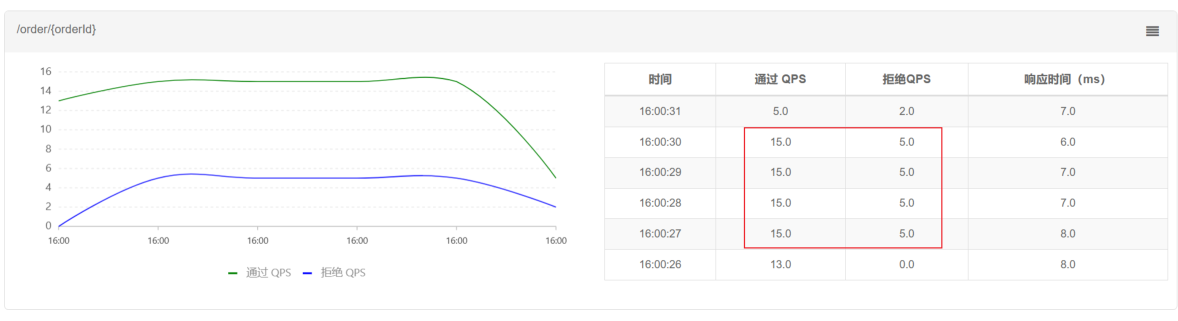
查看结果树, 发现发送的请求中每次有15个成功, 5个被拒绝 对于失败的数据, 显⽰Blocked By Sentinel(flow limiting)
从Sentinel dashboard 也可以看到
基于QPS/并发数的流量控制
流量控制主要有两种统计类型: ⼀种是统计线程数, 另外⼀种则是统计 QPS

并发线程数
线程数限流⽤于保护业务线程数不被耗尽.
⽐如A调⽤B, ⽽B服务因为某种原因导致服务不稳定或者响应延迟, 那么对于A服务来说, 它的吞吐量会下降, 也意味着占⽤更多的线程(线程阻塞之后⼀直末释放),极端情况下会造成线程池耗尽. 针对这种问题, 业内有使⽤隔离的⽅案,⽐如通过不同业务逻辑使⽤不同线程池来隔离业务⾃⾝之间的资源争抢(线程池隔离), 或者使⽤信号量来控制同时请求的个数(信号量隔离)。这种隔离⽅案虽然能够控制线程数量, 但⽆法控制请求排队时间. 当请求过多时排队也是⽆益的, 直接拒绝能够迅速降低系统压⼒. 如果超出阈值,新的请求会被⽴即拒绝.
QPS流量控制
当 QPS 超过某个阈值的时候, 则进⾏流量控制.
流量控制的⼿段分为三种: 快速失败, Warm Up, 排队等待.
流控效果
流量超过配置的阈值时, 会采⽤流量控制, 流量控制的⼿段分为三种:

对应对应 FlowRule 中的 controlBehavior 字段.
取值分别为:
• 快速失败( RuleConstant.CONTROL_BEHAVIOR_DEFAULT )
• Warm Up( RuleConstant.CONTROL_BEHAVIOR_WARM_UP )
• 排队等待( RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER )

快速失败
快速失败, 也就是直接拒绝, 对应 RuleConstant.CONTROL_BEHAVIOR_DEFAULT . 该⽅式是默认的流量控制⽅式,当QPS超过任意规则的阈值后,新的请求就会被⽴即拒绝,拒绝⽅式为抛出FlowException 。这种⽅式适⽤于对系统处理能⼒确切已知的情况下,⽐如通过压测确定了系统的准确⽔位.
上⾯的例⼦, 使⽤的就是快速失败.
Warm Up
Warm up, 对应 RuleConstant.CONTROL_BEHAVIOR_WARM_UP . Warm Up 也叫预热模式. 阈值⼀般是⼀个微服务能承受的最⼤QPS, 但是⼀个服务刚刚启动时, ⼀切资源尚未初始化, 如果直接将QPS跑到最⼤值, 可能导致服务瞬间宕机.
该⽅式主要⽤于系统⻓期处于低⽔位的情况下,当流量突然增加时, 直接把系统拉升到⾼⽔位可能瞬间把系统压垮的, 通过"冷启动",让通过的流量缓慢增加,在⼀定时间内逐渐增加到阈值上限,给冷系统⼀个预热的时间,避免冷系统被压垮的情况.
通常冷启动的过程系统允许通过的 QPS 曲线如下图所⽰:
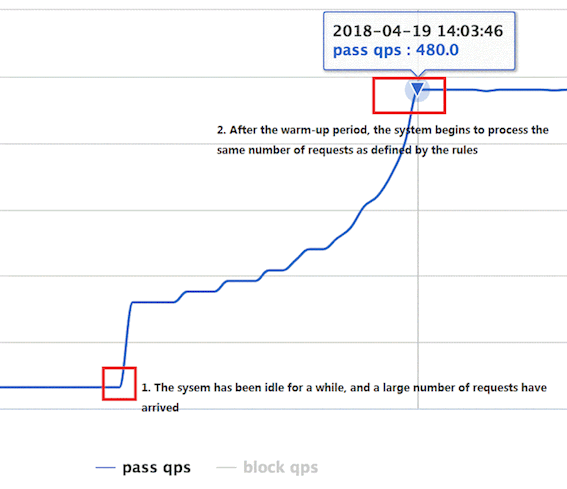
例如,设置QPS的阈值为10, 预热时间为5秒, 那么会在在5秒后逐渐增⻓到10.
设置流控规则
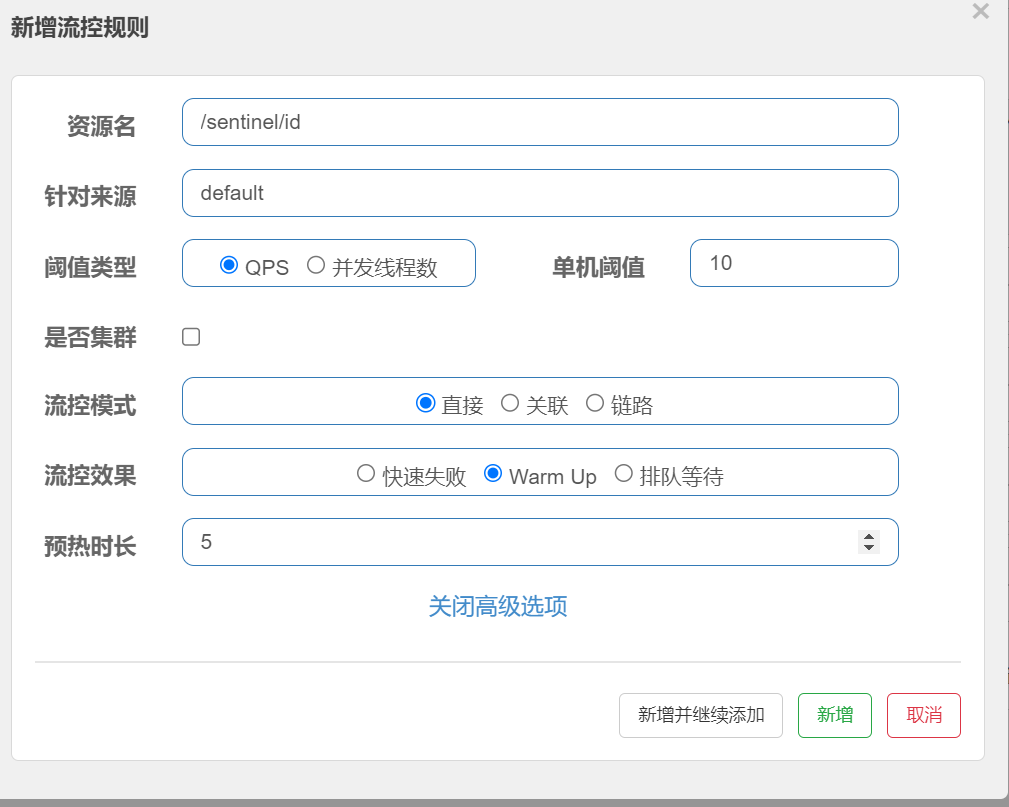
单机阈值设置为10, Warm Up 模式, 预热时⻓为5s 可以理解为系统在5s后单机阈值逐渐增⻓到10
创建测试任务
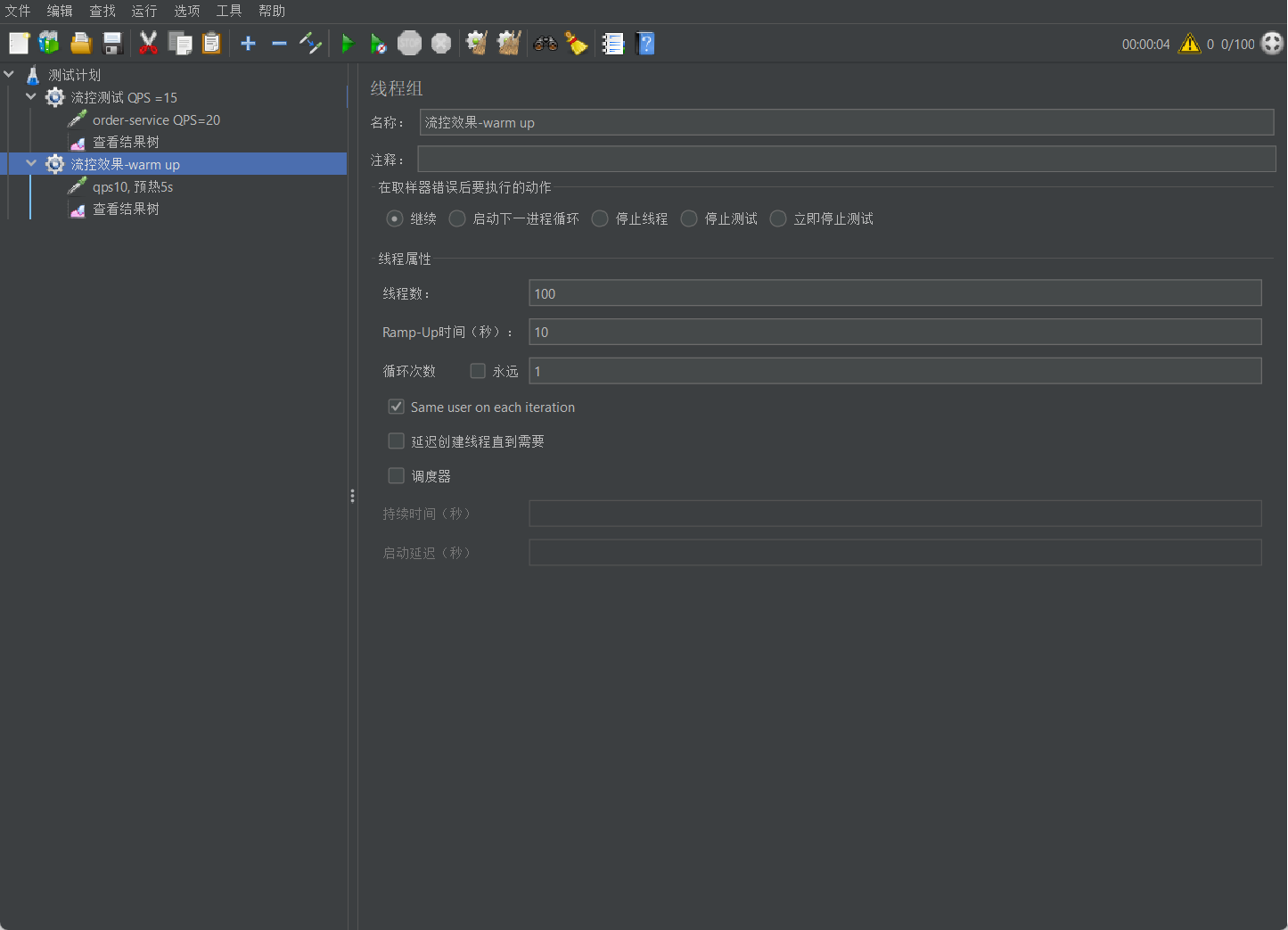
10s, QPS =10
观察测试结果
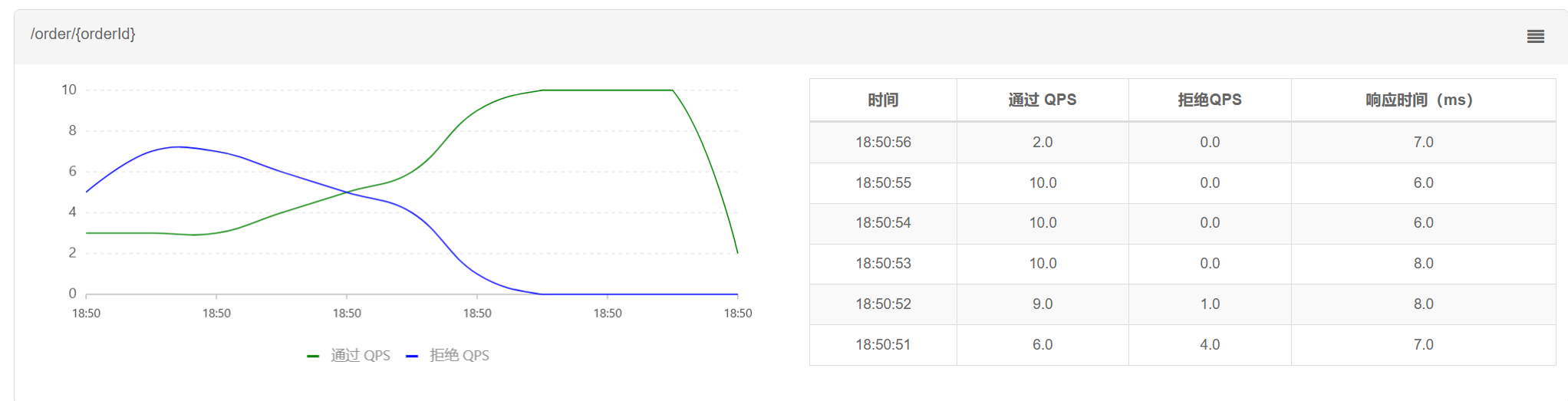
刚刚启动时, ⼤部分请求失败, 继续往下看, 会发现通过的请求逐渐增多, 最终QPS=10全部通过
请求阈值初始值是 maxThreshold / coldFactor, 持续指定时⻓后, 逐渐提⾼到maxThreshold值, coldFactor的默认值是3.
如上⾯配置, 设置QPS的maxThreshold为10, 预热时间为5秒, 那么初始阈值就是 10/3 , 也就是3, 然后在5秒后增⻓到10.
从Sentinel Dashboard上也可以看出来
排队等待
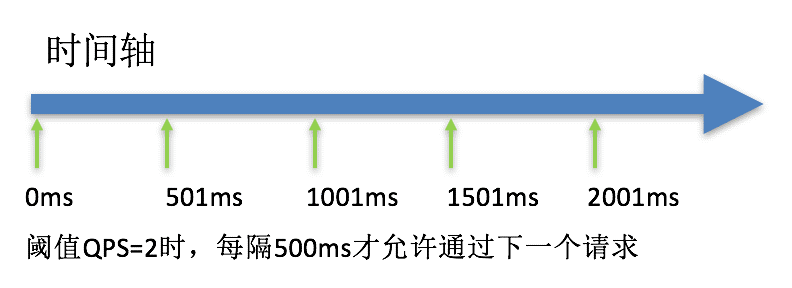
排队等待, 对应 RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER . 这种⽅式严格控制了请求通过的间隔时间,也即是让请求以均匀的速度通过. 可以理解为让所有请求进⼊⼀个队列中, 然后按照阈值允许的时间间隔依次执⾏. 后⾯的请求必须等待前⾯执⾏完成, 直到超时. 该⽅式的作⽤如下图所⽰:
这种⽅式主要⽤于处理间隔性突发的流量, 例如消息队列.
想象⼀下这样的场景, 在某⼀秒有⼤量的请求到来, ⽽接下来的⼏秒则处于空闲状态, 我们希望系统能够在接下来的空闲期间逐渐处理这些请求, ⽽不是在第⼀秒直接拒绝多余的请求.
接下来通过案例来理解排队等待.
设置流控规则
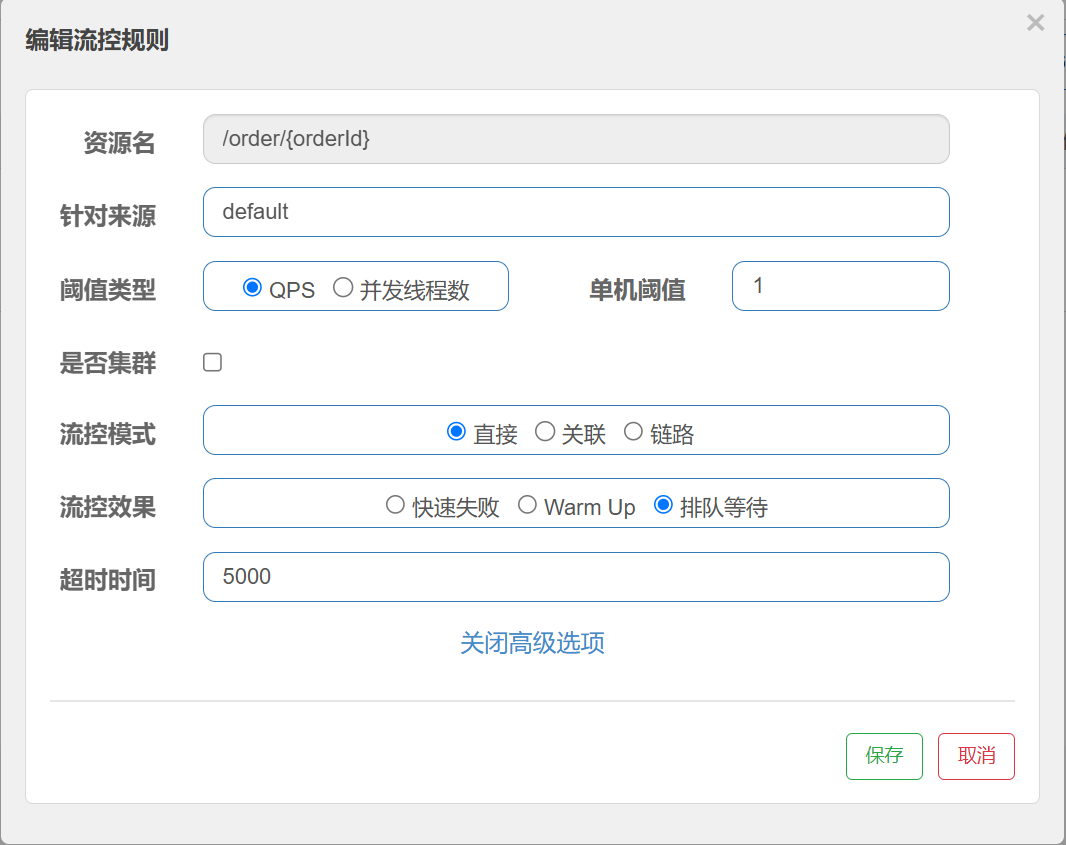
超时时间也就是请求等待时⻓.
⽐如阈值为1, 那么每秒执⾏⼀个请求. 超时时间为5s. 现在⼀下⼦来了10个请求, 那么:
第3个请求的 等待时⻓为: 100 * (3-1) = 2000ms
第6个请求的 等待时⻓为: 100 * (6-1) = 5000ms
也就是说, 同⼀时间发起10个请求, 那么会通过6个, 拒绝4个.
创建测试任务
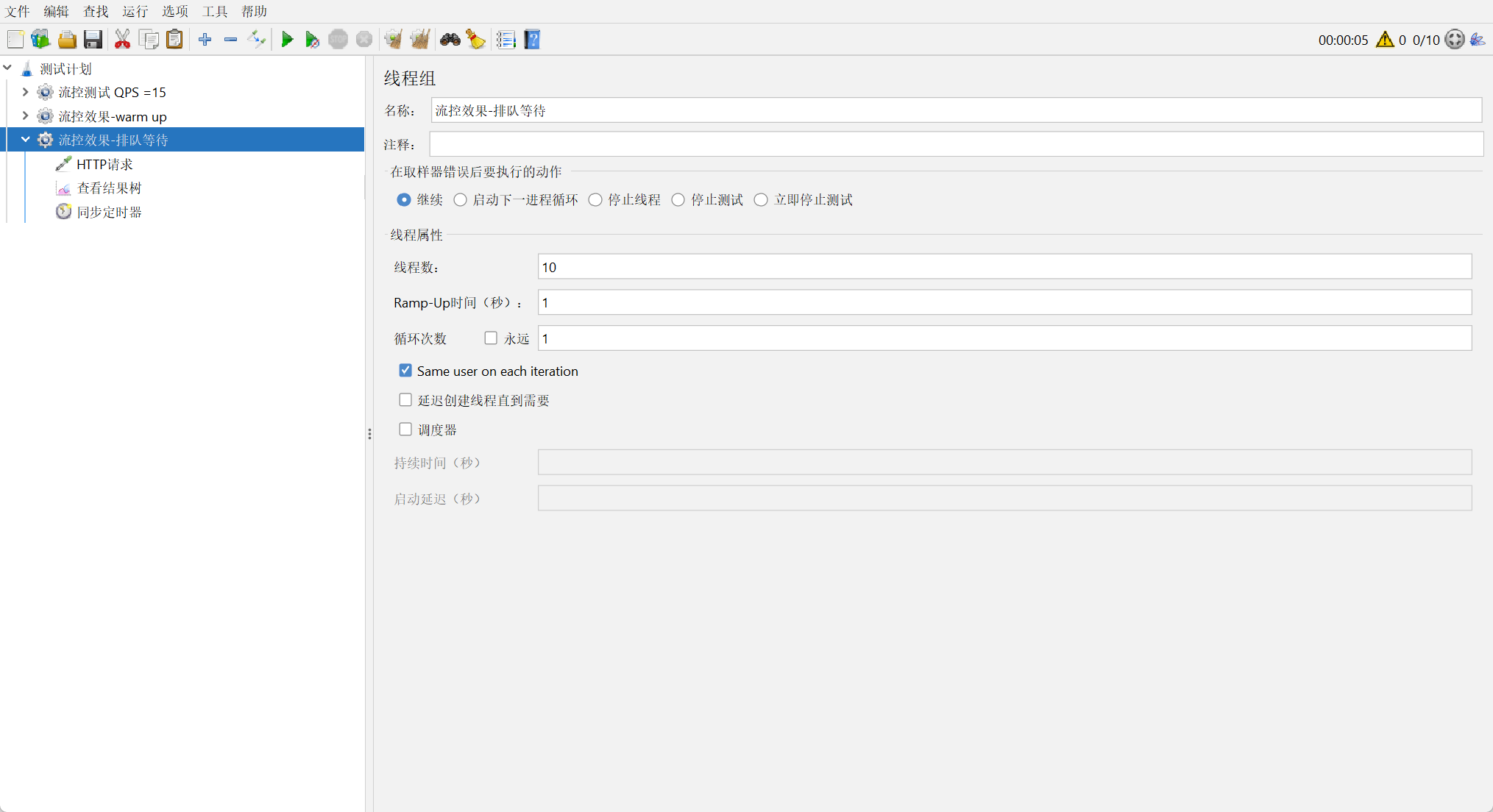
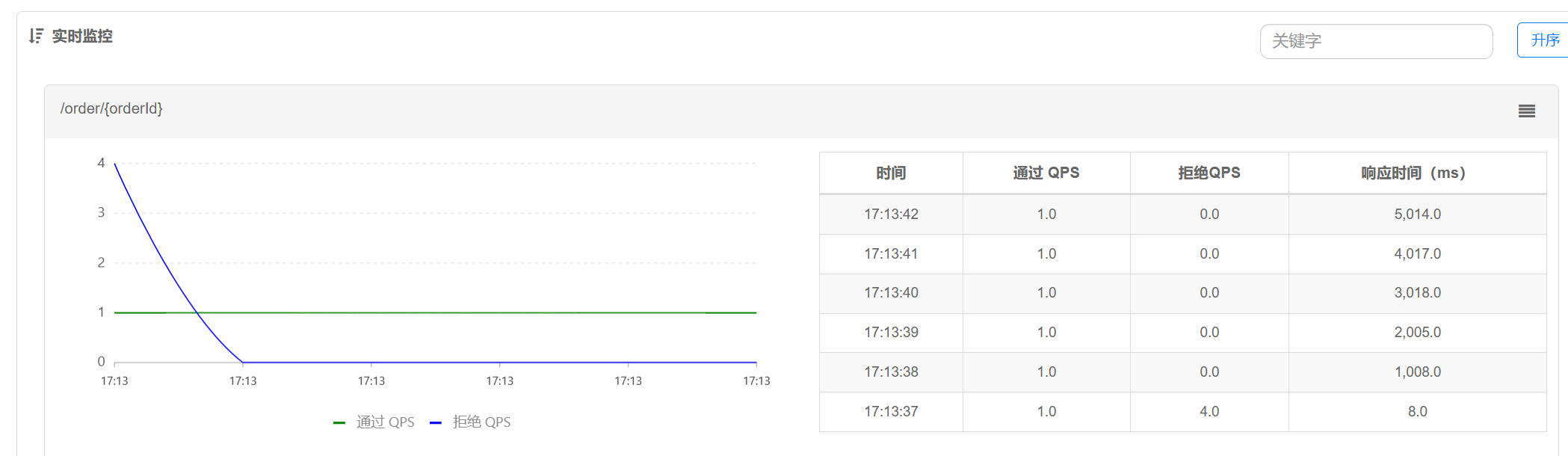
观察测试结果
通过结果树可以看出来, 10个请求, 每秒通过⼀个, 共通过了6个, 从Sentinel的监控图上也可以看出来
因为受制因素⽐较多, 界⾯并不⼀定严格对应得上, 观察⼤概效果即可.
可以看到第⼀秒拒绝4个, 后续⼀秒通过⼀个(通过JMeter同步任务, 10个请求是同时发出的, 并⾮⼀秒发送⼀个)
也可以看到响应时间, 请求由于排队等待, 响应时间也越来越⻓
流控模式
在添加限流规则时, 点击⾼级选项, 可以发现流控模式分为三种: 直接, 关联, 链路,
调⽤关系包括调⽤⽅, 被调⽤⽅. ⽅法⼜可能会调⽤其它⽅法, 形成⼀个调⽤链路的层次关系. Sentinel记录资源之间的调⽤链路, 这些资源通过调⽤关系, 相互之间构成⼀棵调⽤树.
⼀棵典型的调⽤树如下图所⽰:
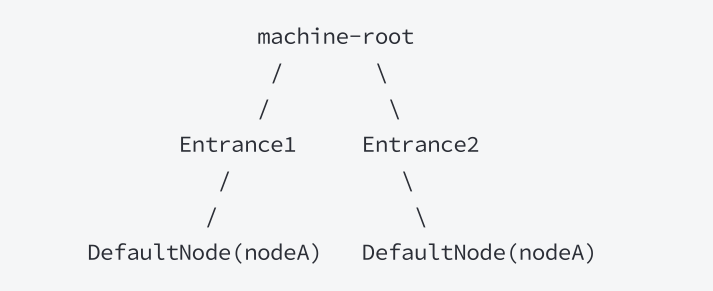
Sentinel根据这些调⽤关系, 建⽴不同资源间的调⽤关系, 并记录每个资源的实时统计信息. 有了调⽤链路的统计信息,我们可以衍⽣出多种流量控制⼿段.
根据调⽤⽅限流
也就是上述流控模式中的: [直接]
这是默认的流量控制⽅式. 当QPS超过任意规则的阈值后, 对当前资源直接限流.
针对来源:
default : 表⽰不区分调⽤者, 来⾃任何调⽤者的请求都将进⾏限流统计. 如果这个资源名的调⽤总和超过了这条规则定义的阈值,则触发限流.
根据调⽤链路⼊⼝限流
也就是上述流控模式中的: [链路]
链路限流是指: 统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
为了⽅便演⽰, 我们需要先构建链路. 假设有两条请求链路:
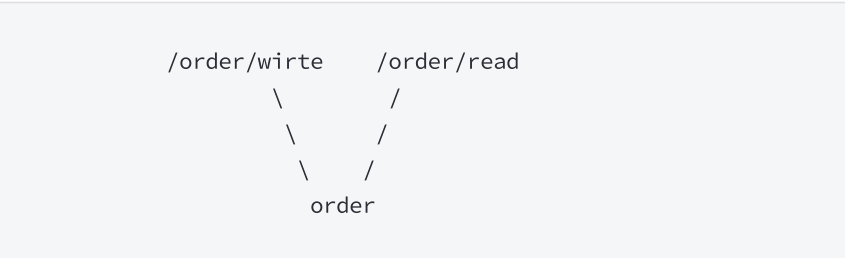
构建链路
添加Http接⼝
Http接⼝是Sentinel默认监控的资源, 不需要额外配置
@RequestMapping("/write")
public String write(){
System.out.println("写操作");
orderService.queryOrder();
return "写操作";
}
@RequestMapping("/read")
public String read(){
System.out.println("读操作");
orderService.queryOrder();
return "读操作";
}上述两个接⼝调⽤共同⽅法queryOrderInfo, 这个不属于Sentinel默认监控的资源, 通过 @SentinelResource 来定义资源
@SentinelResource("queryOrder")
public void queryOrder(){
System.out.println("查询订单信息");
return;
}重启服务, 访问两个路径 观察簇点链路
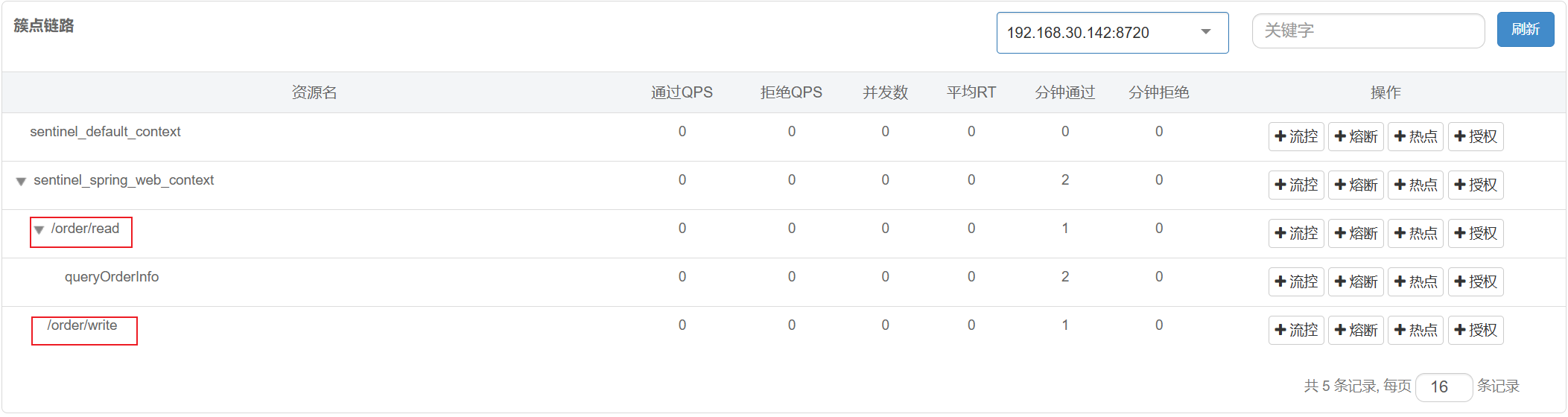
发现看不到 /order/write -> queryOrderInfo 这条链路
链路模式中, 是对不同来源的两个链路做监控. 但是sentinel默认会给进⼊SpringMVC的所有请求设置同⼀个root资源, 会导致链路模式失效. 我们需要关闭这种对SpringMVC的资源聚合, 修改配置如下:
spring:
cloud:
sentinel:
transport:
dashboard: 127.0.0.1:8100 sentinel控制台地址
web-context-unify: false 关闭context整合重启服务, 访问 /order/wirte 和 /order/read , 查看簇点链路, 出现了新的资源
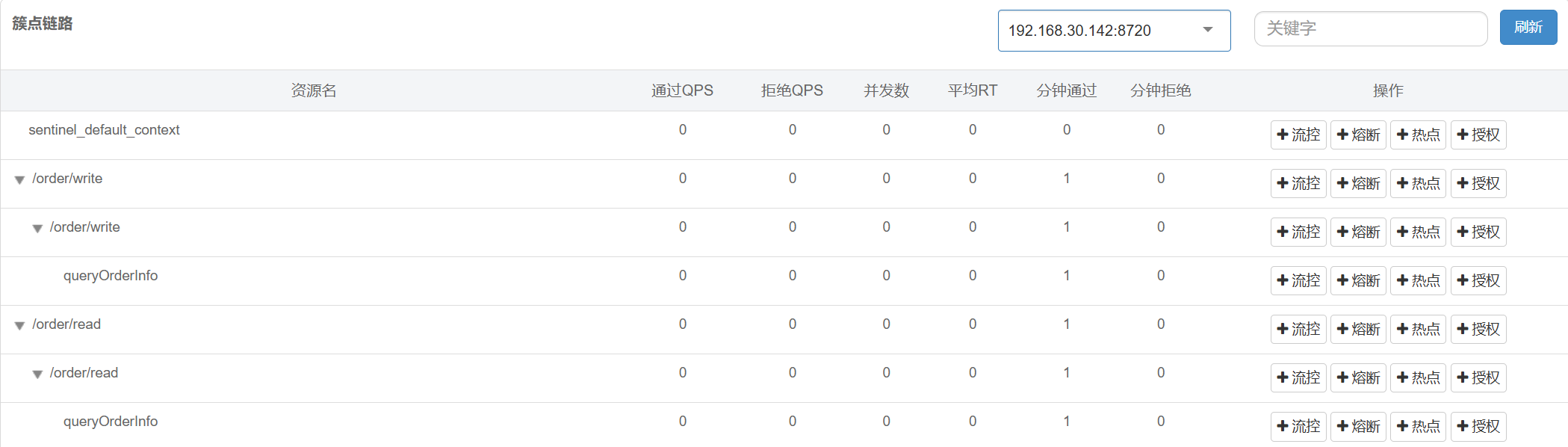
设置流控规则
针对资源添加链路流控规则
只针对⼊⼝资源为 /order/write 的请求进⾏限流
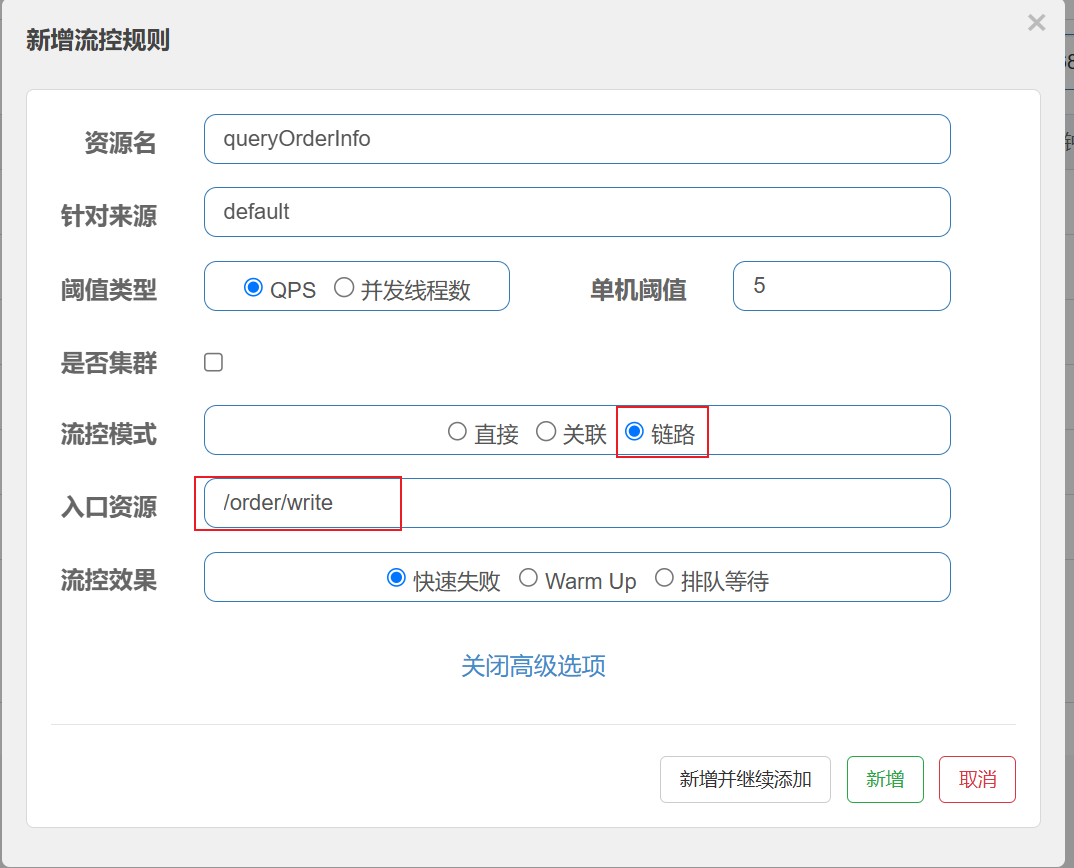
创建测试任务
创建线程组, 添加两个HTTP取样器, 分别对应接⼝为 /order/wirte 和 /order/read
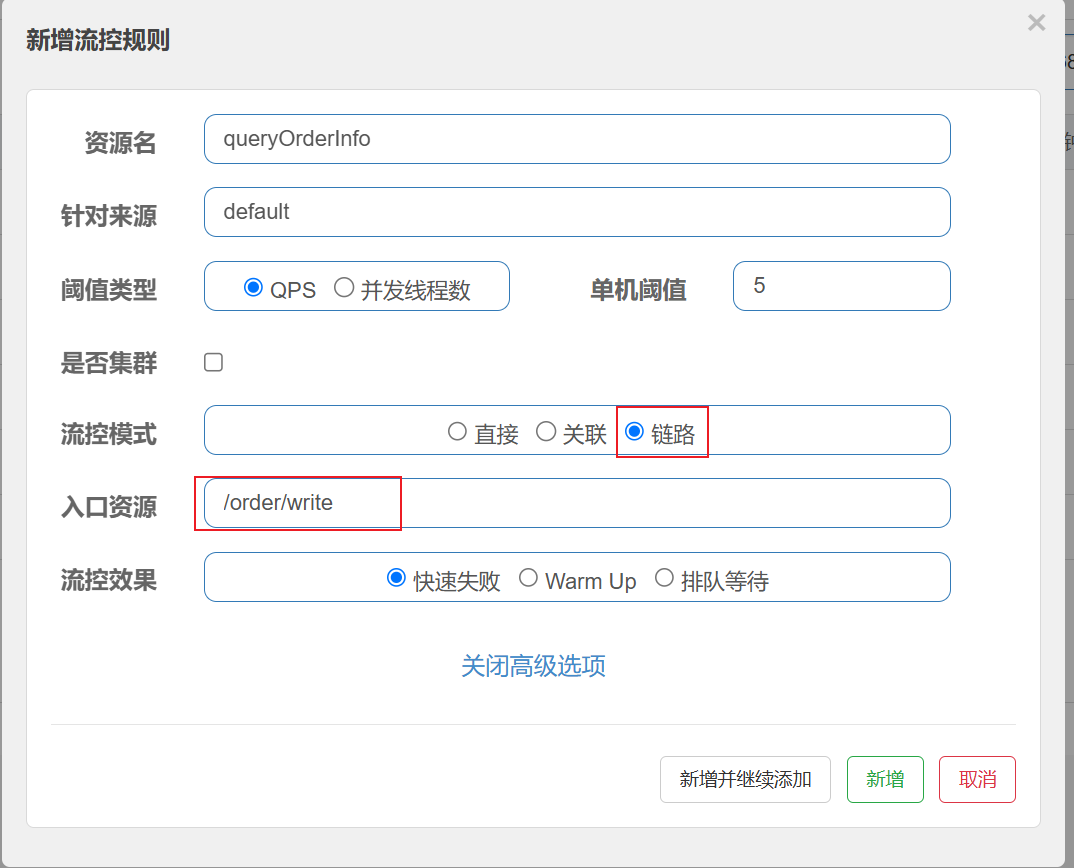
观察测试结果
同时发起请求, 发现write接⼝被限流了, read接⼝未限流
具有关系的资源流量控制
也就是上述流控模式中的: [关联]
当两个资源之间具有资源争抢或者依赖关系的时候, 这两个资源便具有了关联.
关联限流就是 统计与当前资源相关的另⼀个资源, 触发阈值时, 对当前资源限流.
⽐如对数据库同⼀个字段的读操作和写操作存在争抢, 读的速度过⾼会影响写的速度, 写的速度过⾼会影响读的速度. 如果放任读写操作争抢资源, 则争抢本⾝带来的开销会降低整体的吞吐量. 可使⽤关联限流来避免具有关联关系的资源之间过度的争抢.
⽐如, /order/wirte 和 /order/read 这两个资源分别代表数据库读写, 我们可以给 /order/read 设置限流规则来达到写优先的⽬的, 这样当写库操作过于频繁时, 读数据的请求会被限流.
设置流控规则
当 /order/wirte 资源访问量触发阈值时, 就会对 /order/read 资源限流,避免影响 /order/wirte 资源
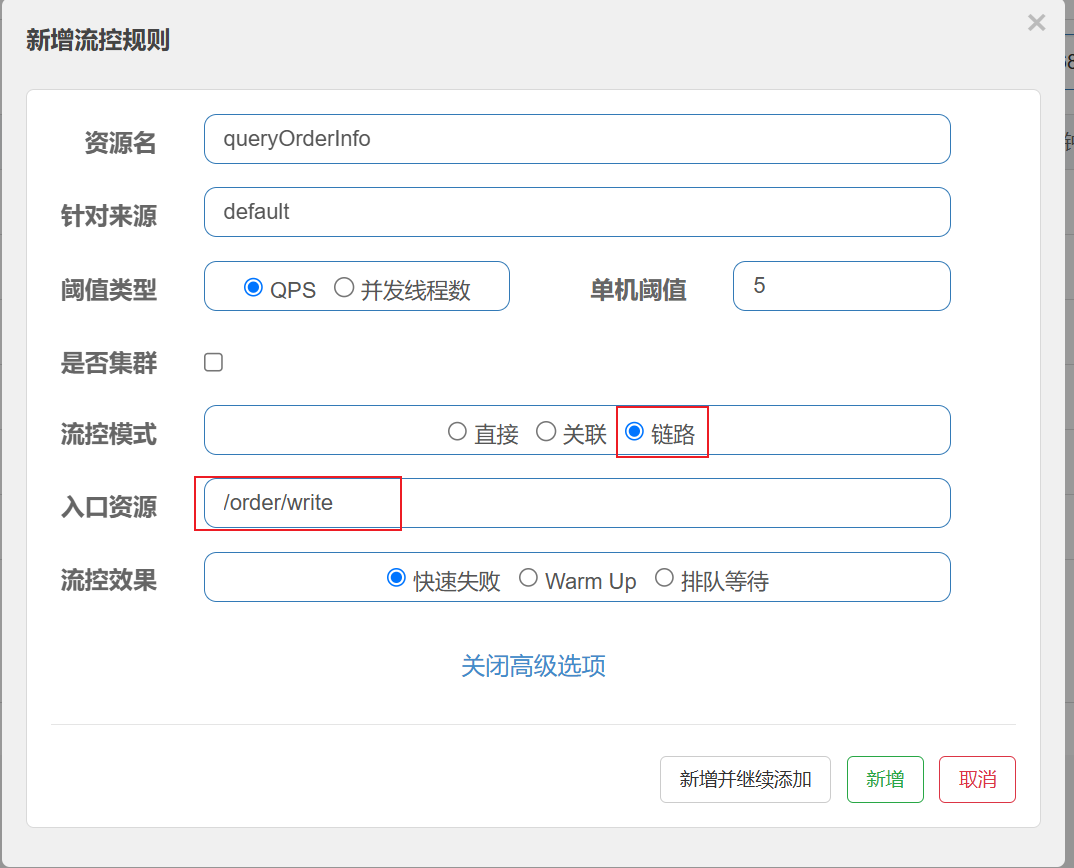
应⽤场景:
• 在数据库操作中, 读操作和写操作可能会争抢资源(如锁). 通过关联模式, 可以限制读操作的频率, 以避免对写操作造成过⼤的影响.
• 订单服务可能依赖于库存服务, 如果库存服务的请求量过⼤, 可以通过关联模式限制订单服务的请求量.
创建测试任务
创建线程组, 添加两个HTTP取样器, 分别对应接⼝为 /order/wirte 和 /order/read
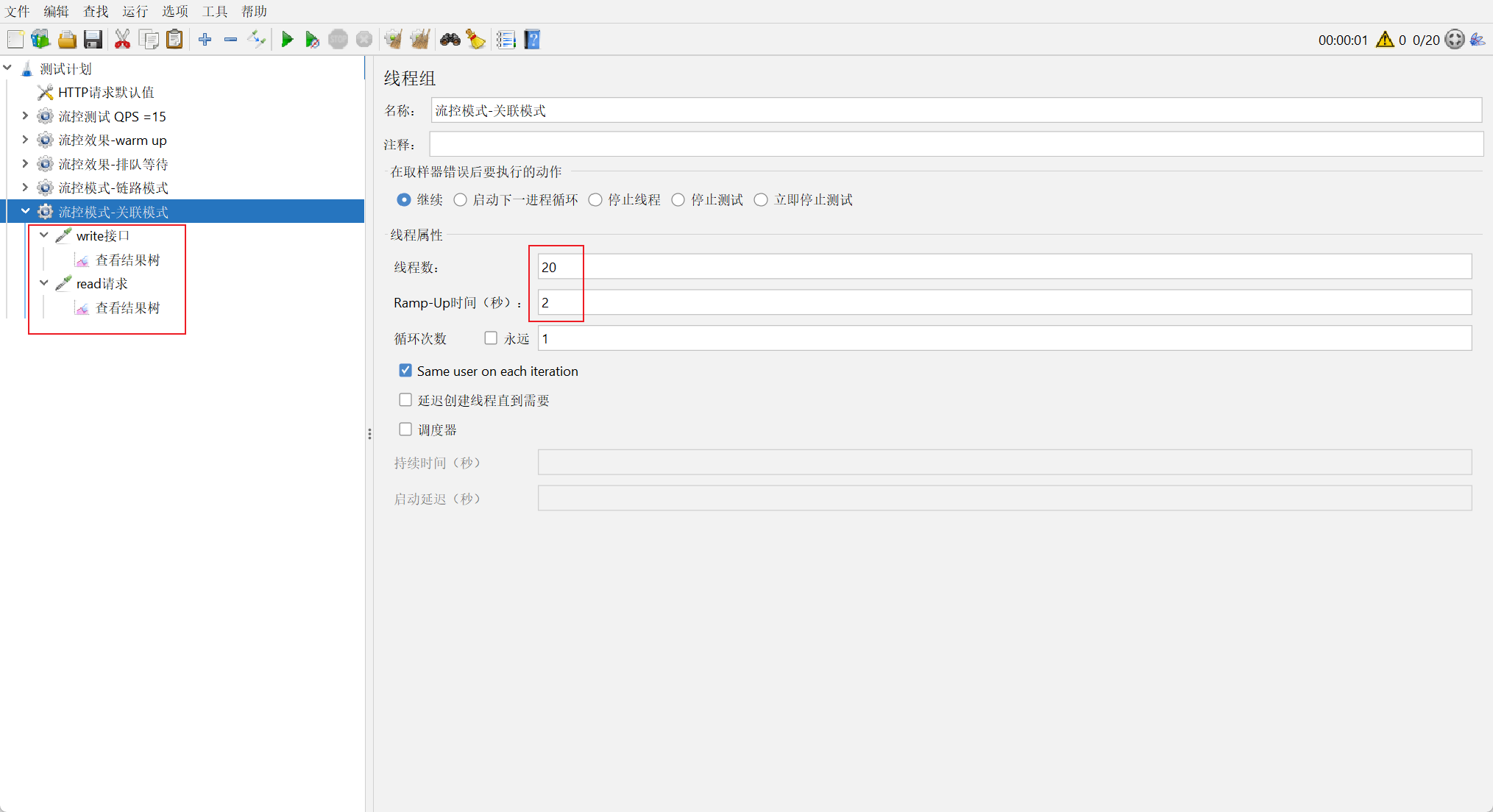
观察测试结果
write接⼝达到设置的阈值时, 为了保证write接⼝的正常运⾏, 对read接⼝进⾏了关联限流.
6. 热点参数限流
热点即经常访问的数据.
在上⾯的配置中, 对⼀个接⼝进⾏限流, 所有的请求参数⼀视同仁, 只要达到阈值, 就⼀起限流.
热点参数限流会统计传⼊参数中的热点参数, 并根据配置的限流阈值与模式, 对包含热点参数的资源调⽤进⾏限流. 热点参数限流可以看做是⼀种特殊的流量控制, 仅对包含热点参数的资源调⽤⽣效.
热点参数限流配置
定义资源
热点参数限流对默认的Spring MVC 资源⽆效, 在资源上需要加 @SentinelResource
@SentinelResource("/sentinel/id")
@RequestMapping("/{orderId}")
public OrderInfo getOrderById(@PathVariable("orderId") Integer orderId){
return orderService.selectOrderById(orderId);
}设置热点参数限流
在需要进⾏热点参数限流的资源后⾯, 点击 [+热点]
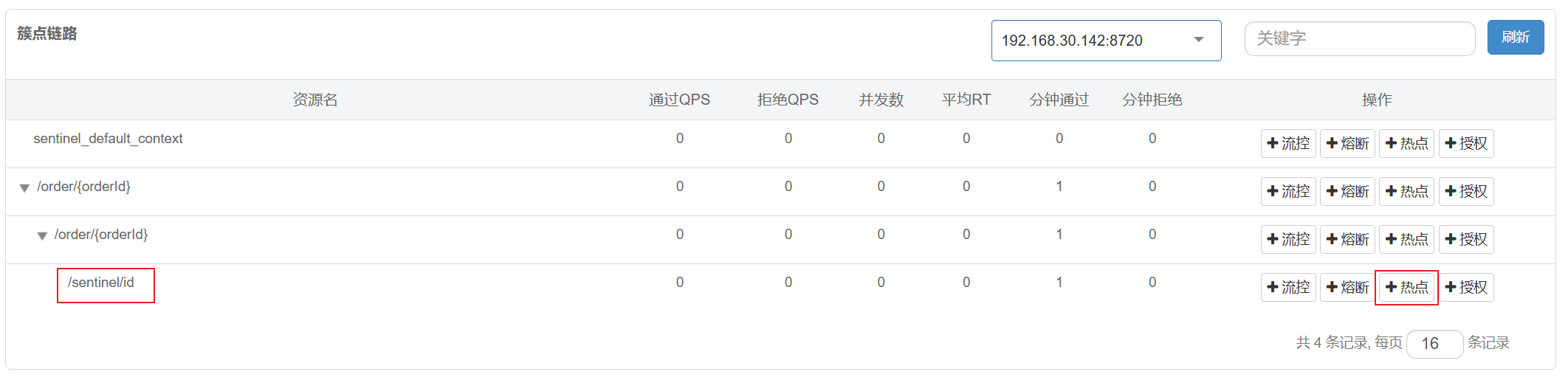
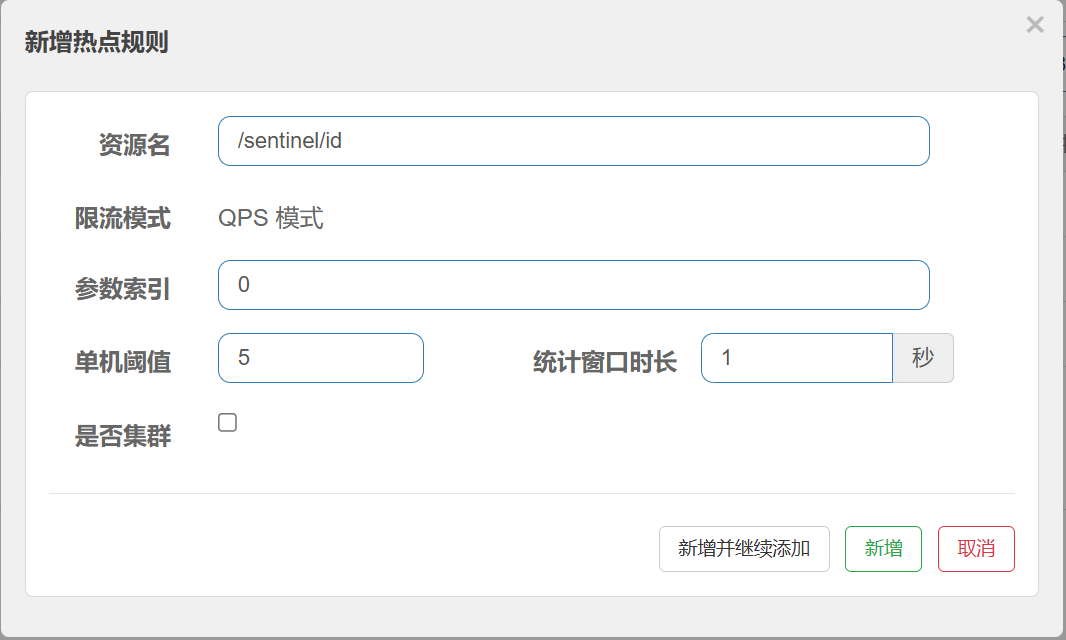
对 /sentinel/id 这个资源的0号参数(第⼀个参数)做统计,每1秒相同参数值的请求数不能超过5 参数索引: 资源热点参数的索引, 从0开始.
创建测试任务
添加三个取样器, 参数分别设置为1, 2, 3, QPS为10
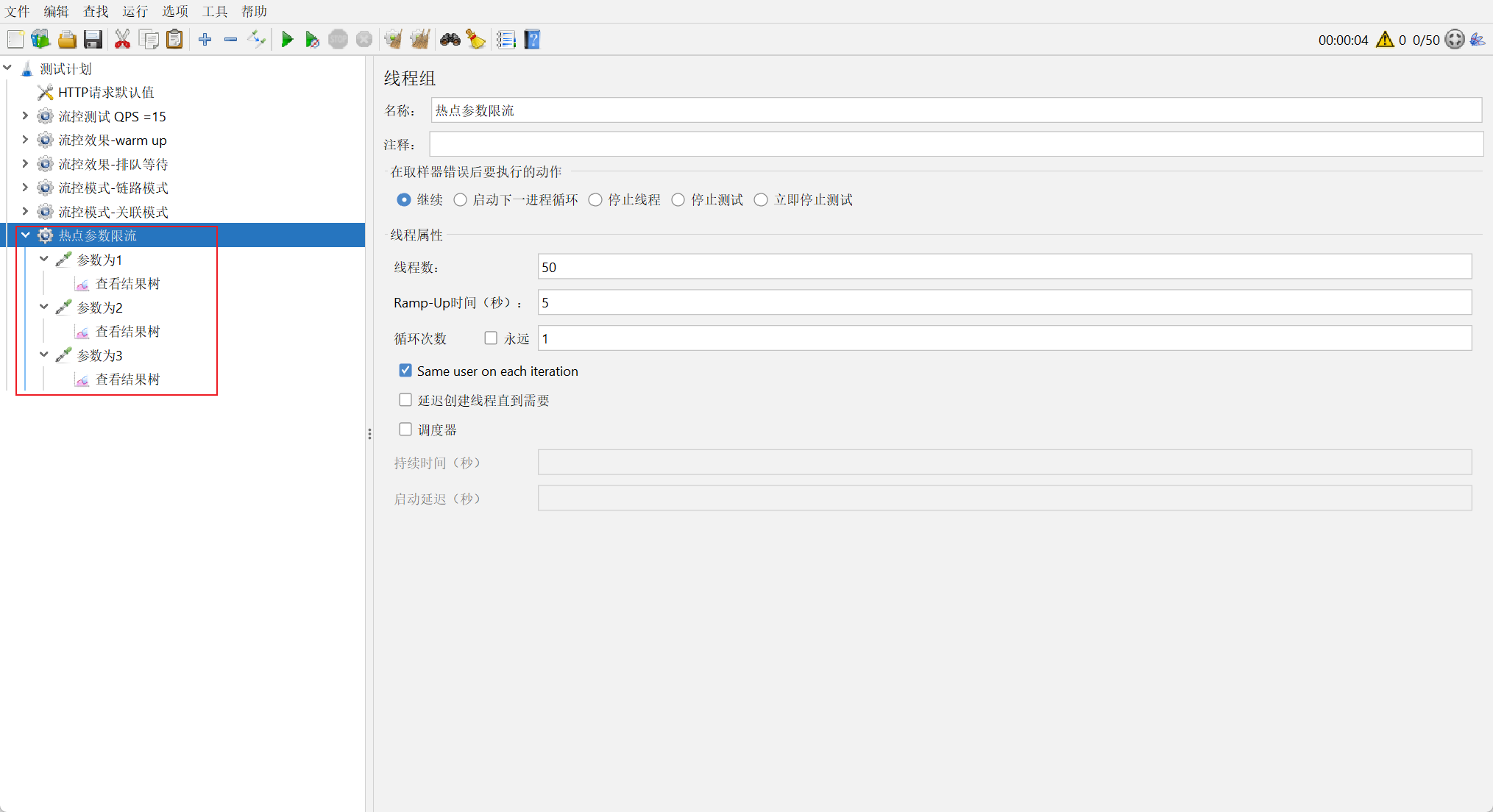
观察测试结果
参数分别为1, 2, 3 的请求, 阈值达到5后, 就被限流了
和上⾯的流控差异是: 热点参数限流是以资源的参数值为维度来统计的, 流控是以资源名称为维度来进⾏统计的
参数例外项
上述的热点参数配置中, 所有的参数⼀视同仁, QPS都被限定为5, 但是在⼀些场景下, 我们希望可以对某些热点参数进⾏单独限流.
但是在⼀些场景下, 有⼀些热点商品, ⽐如排名⽐较靠前的, 访问次数⽐较多, 我们希望可以对这个热点商品进⾏单独限流, 让他的阈值⾼⼀些或者低⼀些, 就需要使⽤到热点参数限流规则⾥⾯的⾼级选项了.
编辑热点规则
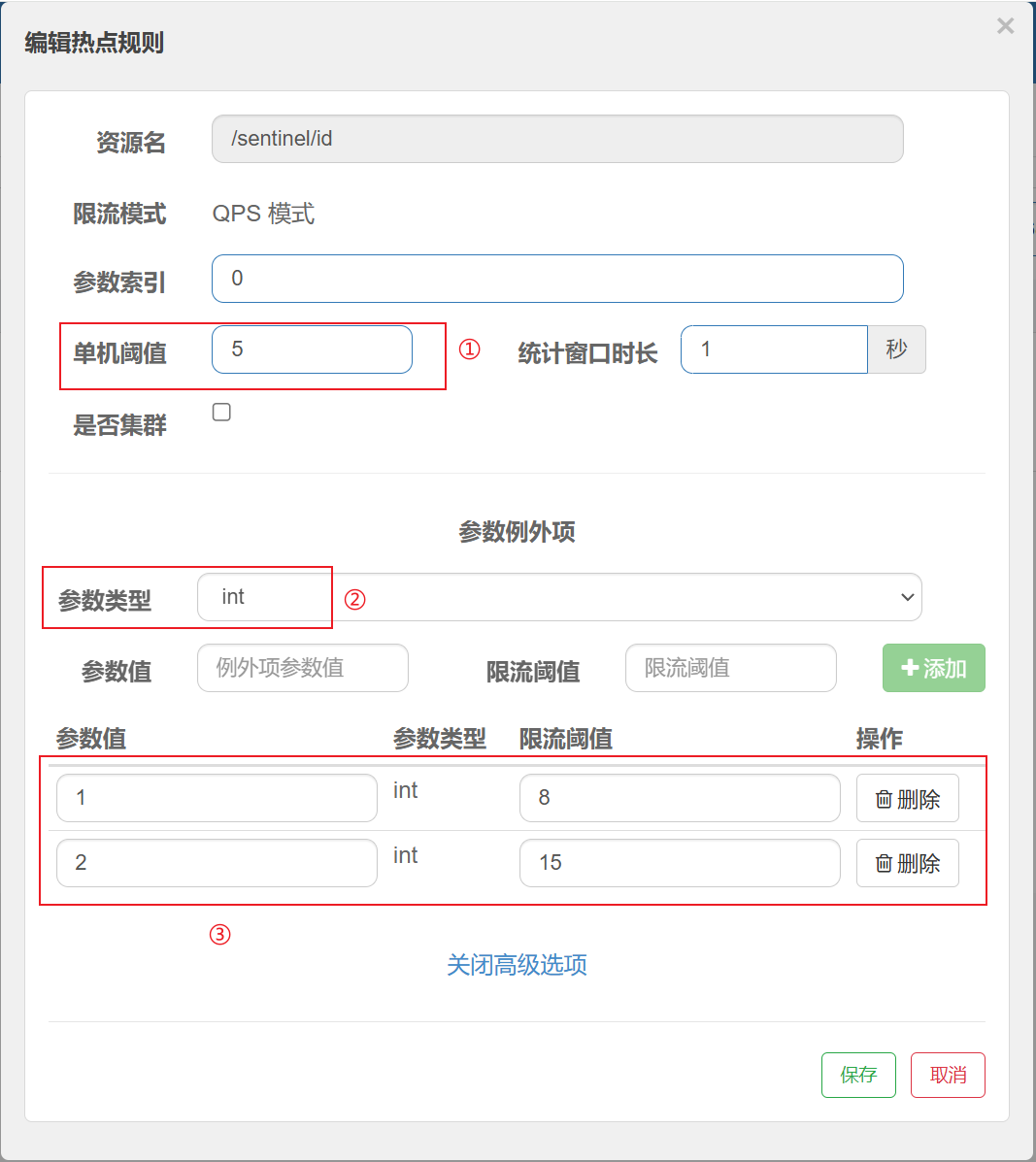
配置说明:
单机阈值: 对第⼀个参数的值进⾏统计, 当相同值参数阈值超过5时, 进⾏限流
参数例外项: 针对⼀些特殊的参数, 进⾏单独设置
参数类型: 热点参数的类型, 只⽀持 int, double, String, long, float, char, byte
参数值: 特殊的参数值
限流阈值: 对这个参数进⾏额外的阈值设置
上述配置表⽰: 参数1的QPS限流阈值为8, 参数2的限流阈值为15, 其他的参数为5
创建设置任务
和上述⼀样
对每个请求发起请求QPS=10(不严格)
参数为1: 阈值设置为8, 每秒2个请求限流
参数为2: 阈值设置为15, 不限流
参数为3: 未额外设置, 每秒5个请求限流参数1和参数2的例外参数设置成功.
7. 限流算法
我们学习了使⽤Sentinel完成服务的限流, 要实现服务限流, 最重要的就是限流算法, 下⾯来简单介绍下常⻅的限流实现算法.
计数器算法
计数器算法, 也叫固定窗⼝限流算法, 这是⼀种⽐较简单的限流实现算法.
⾸先维护⼀个计数器, 在指定周期内, 累加访问次数, 当访问次数达到设定的阈值时, 触发限流策略, 当进⼊下⼀个时间周期时, 将访问次数清零. 这个时间周期, 就可以理解为⼀个窗⼝, 计数器记录这个窗⼝接收请求的次数.
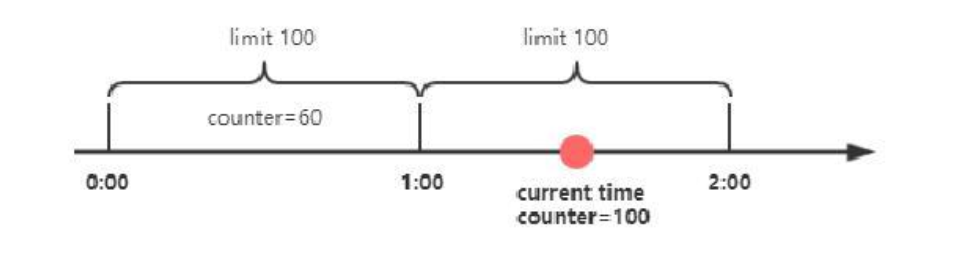
如图所⽰: 限定了⼀分钟能够处理的请求数为100, 在第⼀个⼀分钟内, 共请求了60次. 第⼆个⼀分钟, counter⼜从0开始计数, 在⼀分半钟时,已经达到了最⼤限流的阈值, 这个时候后续的所有请求都会被拒绝.
这种算法可以⽤在短信发送的频次限制上, ⽐如限制同⼀个⽤⼾⼀分钟之内触发短信发送的次数.
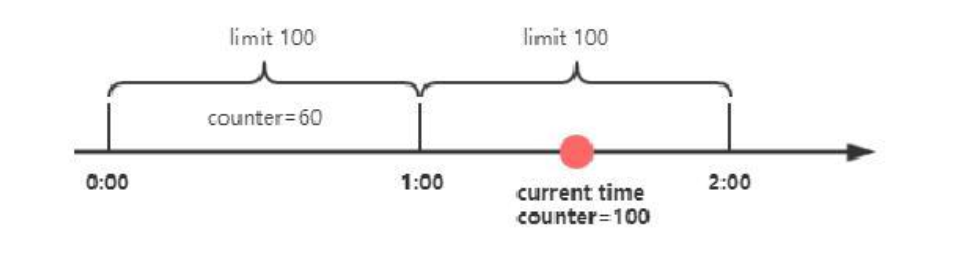
这种算法存在⼀个临界问题, 如图所⽰, 在第⼀分钟的0:58和第⼆分钟的1:02这个时间段内, 分别发出了100个请求, 整体来看就会出现4秒内总的请求量达到200, 超出了设置的每分钟100的阈值.
滑动窗⼝算法
为了解决计数器算法带来的临界问题, 所以引⼊了滑动窗⼝算法. 滑动窗⼝是⼀种流量控制技术, 在TCP⽹络通信协议中, 就采⽤了滑动窗⼝算法来解决⽹络拥塞的情况.
简单来说, 滑动窗⼝算法的原理是在固定窗⼝中分割出多个⼩时间窗⼝, 分别在每个⼩时间窗⼝中记录访问次数,然后根据时间将窗⼝往前滑动并删除过期的⼩时间窗⼝. 最终只需要统计滑动窗⼝范围内的所有⼩时间窗⼝总的计数即可.
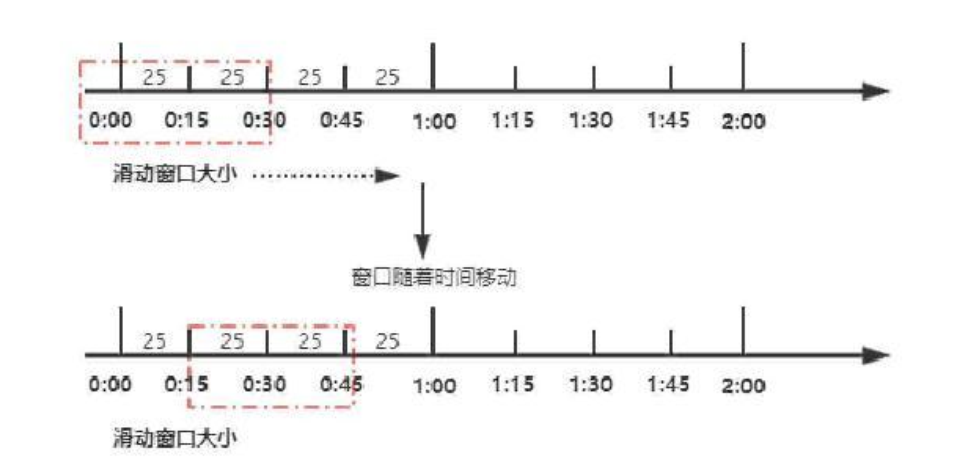
如图所⽰, 我们将⼀分钟拆分为4个⼩时间窗⼝, 每个⼩时间窗⼝最多能够处理25个请求. 并且通过虚线框表⽰滑动窗⼝的⼤⼩(当前窗⼝的⼤⼩是2, 也就是在这个窗⼝内最多能够处理50个请求). 同时滑动窗⼝会随着时间往前移动, ⽐如前⾯15s结束之后, 窗⼝会滑动到15s~45s这个范围, 然后在新的窗⼝中重新统计数据. 这种⽅式很好地解决了固定窗⼝算法的临界值问题.
Sentinel就是采⽤滑动窗⼝算法来实现限流的.
漏桶算法
漏桶算法⾯对限流, 就更加的柔和, 不存在直接的粗暴拒绝. 漏桶限流算法的主要作⽤是控制数据注⼊⽹络的速度, 平滑⽹络上的突发流量.
它的原理很简单, 可以认为就是注⽔漏⽔的过程, 往漏桶中以任意速率流⼊⽔, 以固定的速率流出⽔. 当⽔超过桶的容量时, 会被溢出, 也就是被丢弃. 因为桶容量是不变的, 保证了整体的速率.
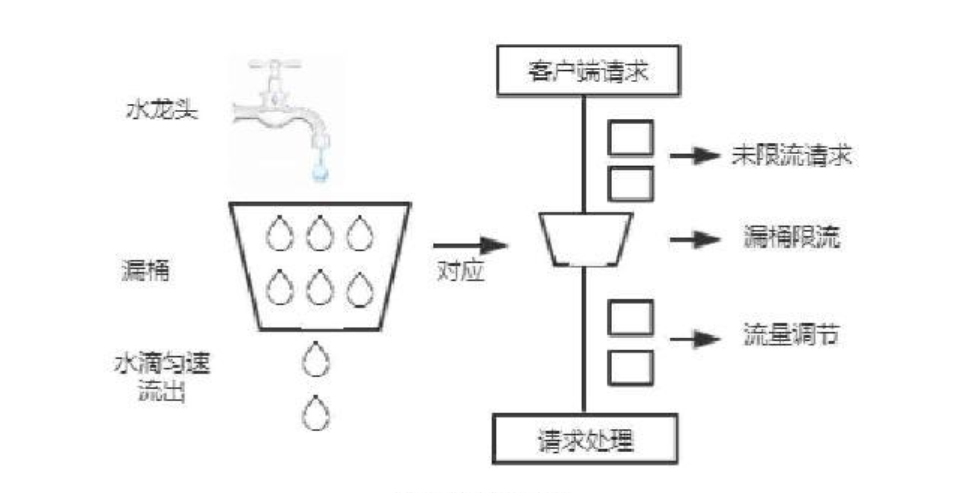
如图所⽰: 在漏桶算法内部同样维护⼀个容器, 这个容器会以恒定速度出⽔, 不管上⾯的⽔流速度多快, 漏桶⽔滴的流出速度始终保持不变. 实际上消息中间件就使⽤了漏桶限流的思想, 不管⽣产者的请求量有多⼤, 消息的处理能⼒取决于消费者.
漏桶算法的原理, 也就决定着, 使⽤漏桶算法会有以下缺点:
1. ⽆法处理突发流量: 漏桶算法以固定的速率处理请求, 当流量突然增加时, ⽆法快速响应和处理这些请求. 超出漏桶容量的请求会被丢弃, 这可能导致⽤⼾体验下降.
2. 可能导致请求延迟: 由于漏桶的流出速率是固定的, 即使在流量较⼩的情况下, 请求也需要排队等待处理, 这可能导致请求的响应时间变⻓.
这些缺点使得漏桶算法在某些需要快速响应或处理突发流量的场景中可能不是最佳选择, 其他限流算法如令牌桶算法可能更适合处理复杂多变的流量场景.
令牌桶算法
令牌桶是⽹络流量整形和速率限制中最常使⽤的⼀种算法. 对于每⼀个请求, 都需要从令牌桶中获得⼀个令牌, 如果没有获得令牌, 则触发限流策略.
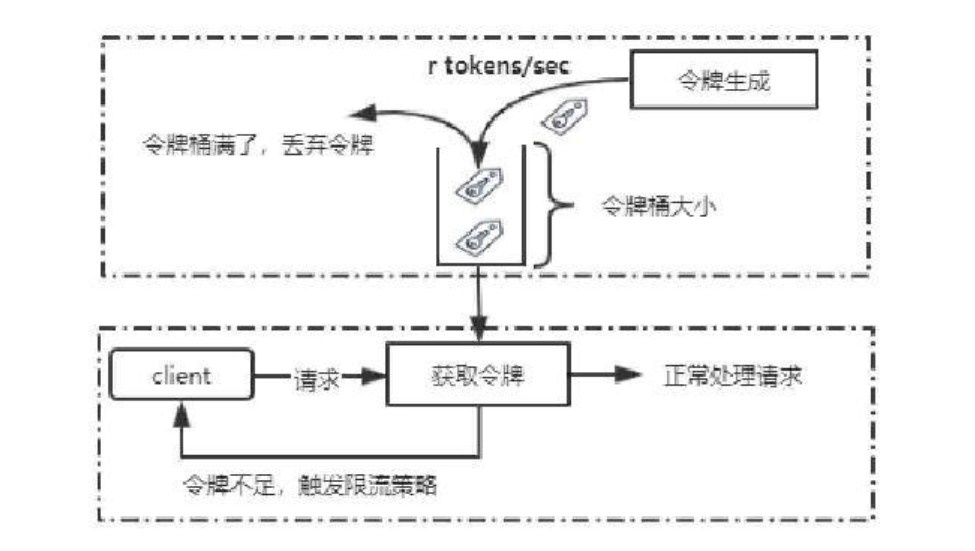
如图所⽰,系统会以⼀个恒定速度往固定容量的令牌桶中放⼊令牌, 如果此时有客⼾端请求过来, 则需要先从令牌桶中拿到令牌以获得访问资格.
假设令牌⽣成速度是每秒10个, 也就等同于QPS=10, 在请求获取令牌的时候, 会存在三种情况:
1. 请求速度 > 令牌⽣成速度: 令牌会很快被取完, 后续再进来的请求会被限流.
2. 请求速度 = 令牌⽣成速度: 流量处于平稳状态.
3. 请求速度 < 令牌⽣成速度: 说明系统的并发数不⾼, 请求能被正常处理.
由于令牌桶有固定的⼤⼩, 当请求速度⼩于令牌⽣成速度时, 令牌桶会被填满. 所以令牌桶能够处理突发流量. 也就是在短时间内新增的流量系统能够正常处理, 这是令牌桶的特性。
Spring Cloud Gateway的RequestRateLimiter Filter默认使⽤了RedisRateLimiter的限流实现, 就是采⽤令牌桶算法实现限流功能.

漏桶限流算法和令牌桶限流算法的实现原理相差不⼤, 最⼤的区别是漏桶⽆法处理短时间内的突发流量, 漏桶限流算法是⼀种恒定速度的限流算法.
8. 熔断降级
除了流量控制以外, 对调⽤链路中不稳定的资源进⾏熔断降级也是保障⾼可⽤的重要措施之⼀.
⼀个服务常常会调⽤别的模块, 可能是另⼀个远程服务, 数据库, 或者第三⽅ API 等. 例如: ⽀付的时候, 可能需要远程调⽤银联提供的 API. 查询某个商品的价格, 可能需要进⾏数据库查询.
如上图, 当F发⽣了故障不能及时响应, C调⽤F时, 只能阻塞等待, 直到超时. 如果流量⽐较⼤, 每个请求都等到超时才进⾏响应, 那么系统C的线程资源很快就会被耗尽不能对外提供服务了(处理完成后, 才会释放资源).
现代微服务架构都是分布式的, 由⾮常多的服务组成. 不同服务之间相互调⽤, 组成复杂的调⽤链路. 复杂链路上的某⼀环不稳定, 就可能会层层级联, 最终导致整个链路都不可⽤. 因此我们需要对不稳定的弱依赖服务调⽤进⾏熔断, 暂时切断不稳定调⽤, 避免局部不稳定因素导致整体的雪崩.
熔断降级作为保护⾃⾝的⼿段,通常在客⼾端(调⽤端)进⾏配置. Sentinel 提供了三种熔断策略: 慢调⽤, 异常⽐例, 异常数
• 慢调⽤⽐例 ( SLOW_REQUEST_RATIO ):需要设置允许的慢调⽤ RT(即最⼤的响应时间), 请求的响应时间⼤于该值则统计为慢调⽤. 在指定时间内, 如果请求数量 > 设定的最⼩数量, 且慢调⽤⽐例> 设定的阈值, 则触发熔断
• 异常⽐例 ( ERROR_RATIO ):指定时间内, 请求数量 > 设置的最⼩数量, 且异常⽐例⼤于阈值, 则触发熔断
• 异常数 ( ERROR_COUNT ): 指定时间内, 异常数⽬超过阈值后, 则触发熔断.
状态机
熔断的思路是由断路器 (或者叫熔断器) 统计服务调⽤的慢请求⽐例, 异常⽐例等, 如果超过阈值, 则熔断该服务, 也就是拦截对该服务的请求, 当服务恢复时, 断路器会放⾏访问该服务的请求.
断路器控制熔断和放⾏是通过状态机来完成的
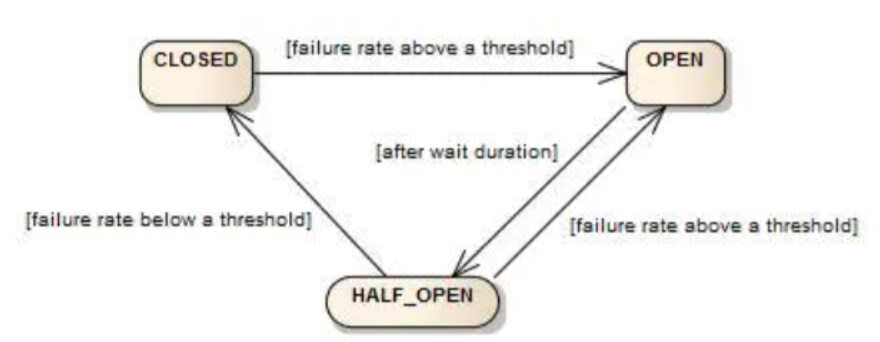
状态机有三个状态:
• Closed: 关闭状态, 所有请求都会通过断路器, 并开始统计慢请求⽐例, 异常⽐例, 超过阈值则切换到open状态.
• Open: 打开状态,服务调⽤被熔断. 这时所有访问被熔断服务的请求都会被拒绝.
• Half-open: 半开状态, 当经过⼀段时间后, 断路器会从Open状态切换到Half-open状态, 这时会有⼀定数量的请求被放⼊, 根据这些请求的失败率来判断后续操作.
◦ 失败率低于阈值:切换到closed状态
◦ 失败率超过阈值:切换到open状态
慢调⽤⽐例
慢调⽤⽐例: 需要设置允许的慢调⽤RT, 也就是最⼤响应时间.
当统计时⻓内请求数⽬ > 设置的最⼩请求数⽬, 并且慢调⽤的⽐例⼤于阈值, 则接下来的熔断时⻓内请求会⾃动被熔断. 经过熔断时⻓后熔断器会进⼊探测恢复状态(HALF-OPEN 状态), 若接下来的⼀个请求响应时间⼩于设置的慢调⽤ RT 则结束熔断, 若⼤于设置的慢调⽤ RT 则会再次被熔断.
模拟慢调⽤
模拟product-service慢响应
@RequestMapping("/{productId}")
public ProductInfo getProduct(@PathVariable("productId") Integer productId){
try {
long time = new Random().nextInt(20)+50;//随即休眠50-70ms
Thread.sleep(time);
return productService.selectProductById(productId);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}定义资源
在order-service中定义资源, ⽅便做熔断处理
@SentinelResource("selectOrderById")
public OrderInfo selectOrderById(Integer orderId){
OrderInfo orderInfo = orderMapper.selectOrderById(orderId);
ProductInfo productInfo = productApi.getProductInfo(orderInfo.getProductId());
orderInfo.setProductInfo(productInfo);
return orderInfo;
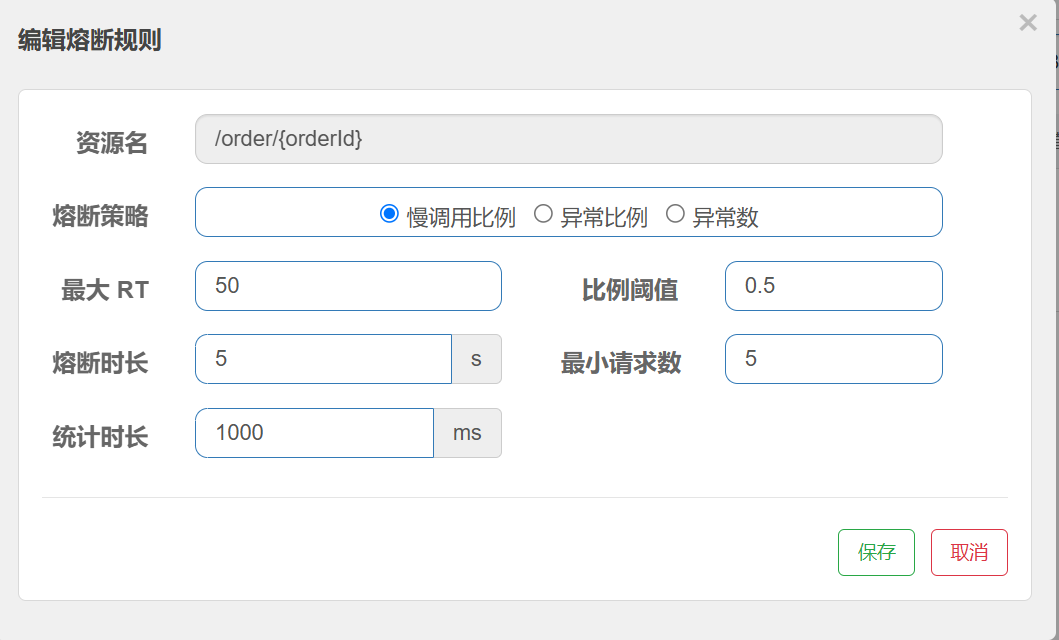
}配置熔断规则
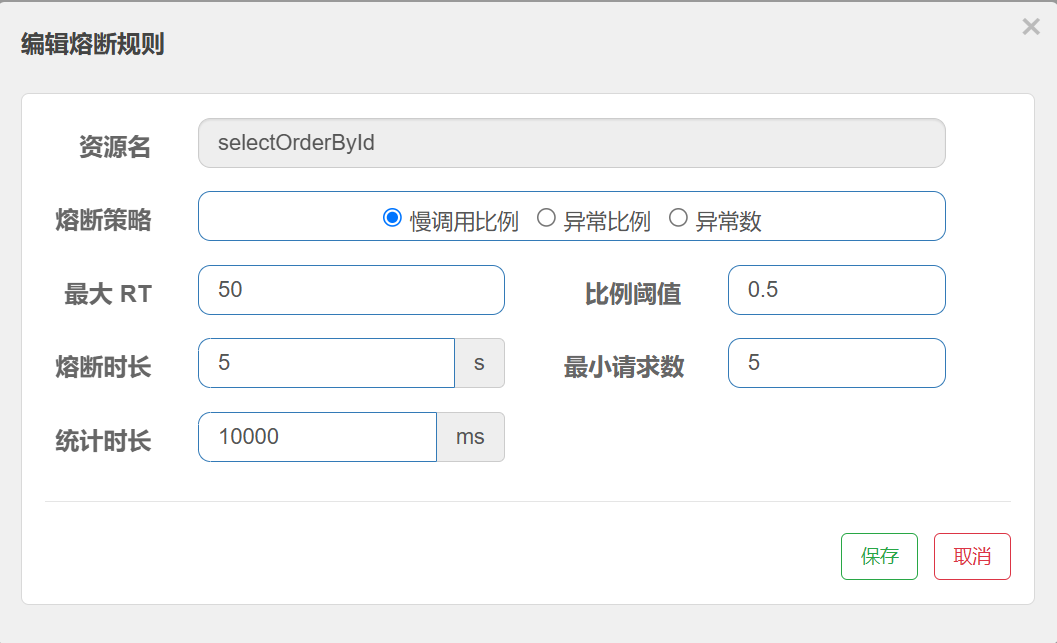
最⼤RT: 最⼤响应时间
⽐例阈值: 慢调⽤⽐例阈值
上述配置表⽰: 超过50ms的调⽤是慢调⽤, 统计最近10000内的请求, 如果请求量超过5次, 并且慢调⽤⽐例不低于0.5, 则触发熔断. 熔断时⻓为5s, 然后进⼊half-open状态, 放⾏⼀次请求做测试.
验证熔断结果:
使⽤JMeter或者浏览器快速请求(QPS要求不⾼, 可以⾃⼰点)
降级
当调⽤失败后, 业务直接报错, 给⽤⼾体验不太好, 应该返回⽤⼾⼀个友好提⽰或者默认结果, 这个就是降级.
⽐如获取⽤⼾信息时, 照⽚获取失败, 返回⼀个默认的头像.
当商品详情⻚的某些⾮核⼼信息(如⽤⼾评价, 相关推荐)加载失败时, 仍然能够显⽰商品的基本信息, 确保⽤⼾可以完成购买流程.
通常有以下⽅式:
1. 捕获异常, 根据异常进⾏降级逻辑处理
2. 通过FallbackFactory, 对远程调⽤的异常做处理.
第⼀种⽅式更通⽤, 适合各种场景, 第⼆种⽅式需要远程调⽤的服务进⾏处理. 这两种⽅式在服务开发中经常搭配着使⽤
捕获异常
对资源代码进⾏异常捕获, 当发⽣熔断时, 返回空对象
降级是对⾮核⼼依赖进⾏降级. 此处只为举例.
@SentinelResource("/sentinel/id")
@RequestMapping("/{orderId}")
public OrderInfo getOrderById(@PathVariable("orderId") Integer orderId){
//第一种熔断降级,利用捕获异常
try{
OrderInfo orderInfo = orderService.selectOrderById(orderId);
return orderInfo;
}catch (UndeclaredThrowableException e){
log.error("获取订单失败");
return new OrderInfo();
}
}验证结果:
当发⽣熔断时, 接⼝返回空对象

FallbackFactory
FallbackFactory 是⼀个在微服务架构中⽤于实现服务降级的接⼝, 当远程服务调⽤失败或超时,
FallbackFactory 会根据提供的异常信息创建⼀个降级处理实例, 以替代原服务调⽤. 并且可以根
据错误类型, 返回不同的降级响应.
定义降级逻辑
在product-api 定义降级处理类
@Slf4j
public class ProductFallbackFactory implements FallbackFactory<ProductApi> {
@Override
public ProductApi create(Throwable cause) {
return new ProductApi() {
@Override
public ProductInfo getProductInfo(Integer productId) {
log.error("获取商品失败");
return new ProductInfo();
}
@Override
public String p1(Integer id) {
log.error("p1 请求失败");
return "p1 请求失败";
}
@Override
public String p2(Integer id, String name) {
log.error("p2 请求失败");
return "p2 请求失败";
}
@Override
public String p3(ProductInfo productInfo) {
log.error("p3 请求失败");
return "p3 请求失败";
}
@Override
public String p4(ProductInfo productInfo) {
log.error("p4 请求失败");
return "p4 请求失败";
}
};
}
}
product-api上配置fallbackFactory
@FeignClient(value = "product-service",path = "/product",fallbackFactory = ProductFallbackFactory.class)
public interface ProductApi {
}public class DefaultFeignConfiguration {
@Bean
public ProductFallbackFactory productFallbackFactory(){
return new ProductFallbackFactory();
}
}在调⽤⽅order-service上设置配置⽂件
@EnableFeignClients(clients = {ProductApi.class},defaultConfiguration = DefaultFeignConfiguration.class)
@SpringBootApplication
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class,args);
}
}在order-service修改配置, 开启 feign 对 Sentinel 功能
feign:
sentinel:
enabled: true #开启feign对sentinel的支持配置熔断规则
重启服务, 访问⼀次接⼝, 然后查看Sentinel控制台, 可以在簇点链路上看到远程调⽤的资源
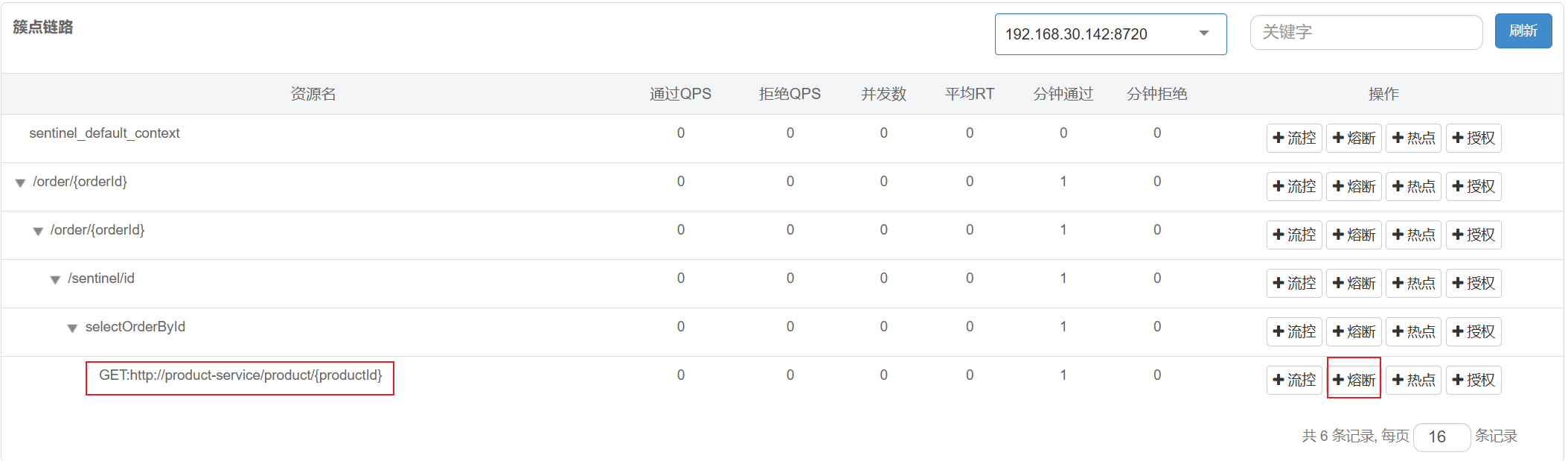
配置熔断规则
验证熔断结果
快速访问接⼝, 触发熔断, 会发现远程返回的内容为FallbackFactory设置的接⼝内容.

验证限流结果
当触发限流时, 也会执⾏FallbackFactory预设的逻辑
删除熔断配置, 添加限流配置(防⽌⼲扰, 判断不出是触发限流还是熔断).
会发现当限流时, 也会返回预设的降级逻辑.

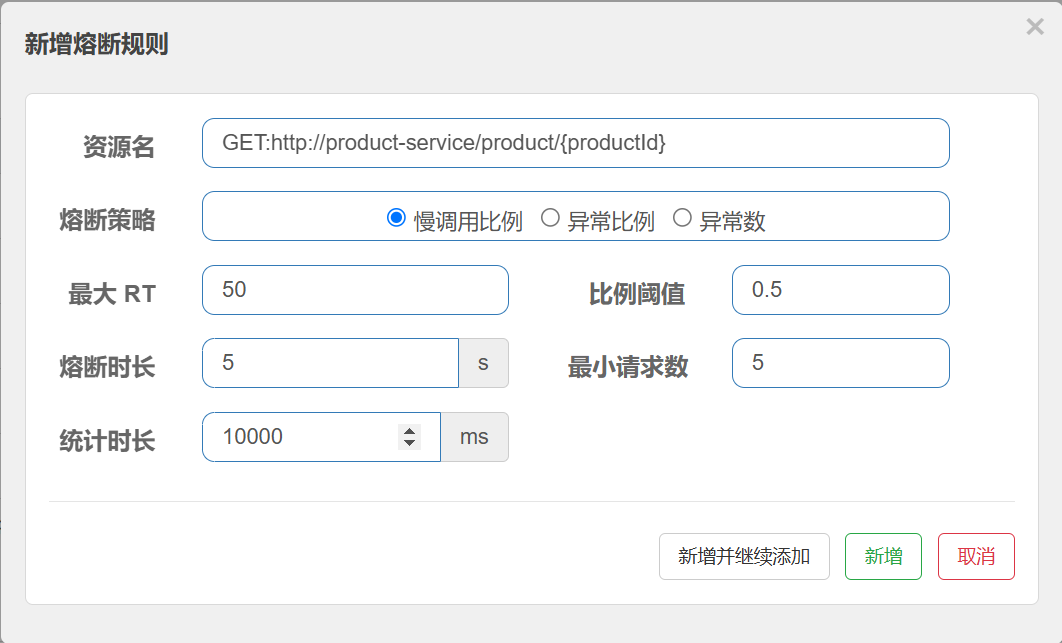
异常⽐例
异常⽐例 ( ERROR_RATIO ):统计单位时⻓( statIntervalMs )内, 请求数⽬ ⼤于 最⼩请求数⽬, 并且异常的⽐例⼤于阈值, 则触发熔断. 经过熔断时⻓后熔断器会进⼊探测恢复状态(HALF-OPEN 状态), 若接下来的⼀个请求成功完成(没有错误)则结束熔断, 否则会再次被熔断.
模拟异常
@RequestMapping("/{productId}")
public ProductInfo getProduct(@PathVariable("productId") Integer productId) throws InterruptedException {
if(productId == 1001){
Thread.sleep(60);
return productService.selectProductById(productId);
}else if (productId == 1002){
throw new RuntimeException("发生异常");
}else {
return productService.selectProductById(productId);
}
}配置熔断规则
统计最近10000ms内的请求, 如果请求量超过5次,并且异常⽐例不低于0.5, 则触发熔断.
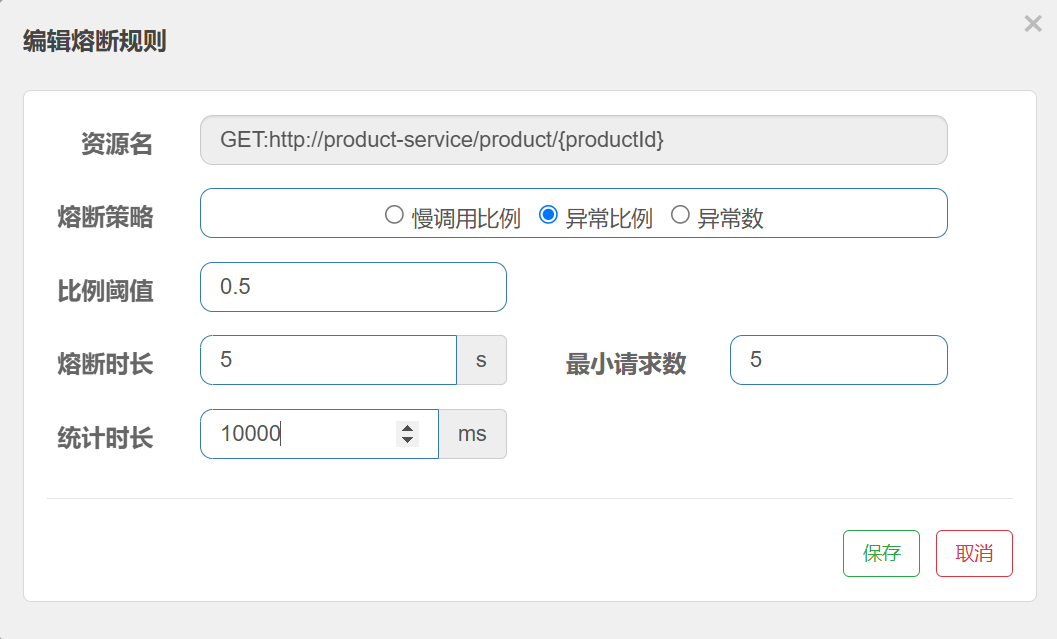
验证熔断结果
未触发熔断
快速多次请求: http://127.0.0.1:8080/order/1, (对应产品ID 1001)⼀直不会熔断
⼀次请求: http://127.0.0.1:8080/order/2, (对应产品ID 1002), 出现异常, ⾛降级逻辑.
再请求 http://127.0.0.1:8080/order/1, 正常返回.
触发熔断
快速多次请求 http://127.0.0.1:8080/order/2, 异常⽐例达到阈值, 触发熔断.
再请求 http://127.0.0.1:8080/order/1, ⾛降级逻辑.
异常数
异常数 ( ERROR_COUNT ):统计单位时⻓内的异常数⽬, 超过阈值之后, 触发熔断. 经过熔断时⻓后熔断器会进⼊探测恢复状态(HALF-OPEN 状态),若接下来的⼀个请求成功完成(没有错误)则结束熔断,否则会再次被熔断.
异常数和异常⽐例⽐较相似
熔断规则配置如下:
统计最近10000ms内的请求, 如果请求量超过5次,并且异常数⼤于, 则触发熔断.
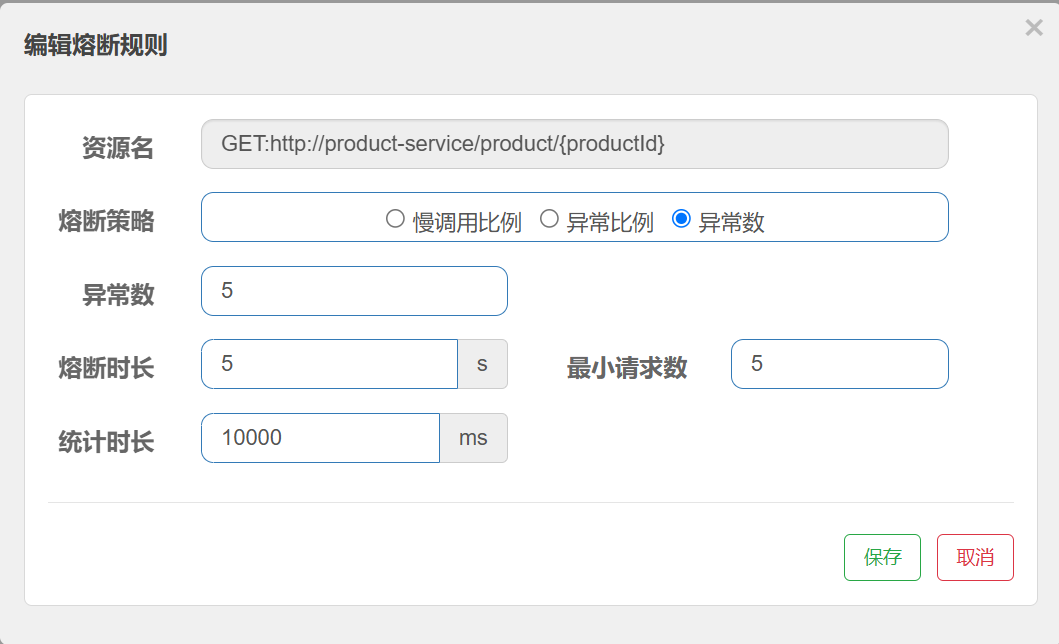
9. 授权规则
存在问题:
⽬前订单项⽬, 直接就可以通过浏览器访问, 获取订单的信息, 这样很不安全.
解决⽅案:
微服务架构中, 许多系统包含敏感信息, 如个⼈⾝份信息, 财务数据, 商业机密等. 只有经过验证或者授权的⽤⼾才可以访问这些数据. ⽐如在医疗系统中, 只有授权的医⽣和护⼠可以查看患者的病历.
授权规则是对请求者的⾝份进⾏判断, 决定是否允许该请求访问特定资源.
Sentinel提供了两种授权模式:⽩名单和⿊名单
• ⽩名单:请求来源位于⽩名单内的调⽤者才允许访问.
• ⿊名单:请求来源位于⿊名单内的调⽤者不允许访问,其余请求通过.
Sentinel根据来源来进⾏判断, 所以调⽤⽅需要设置来源, 被调⽤⽅需要获取来源
Sentinel进⾏授权管理, 主要分以下⼏步
1. 服务端(被调⽤⽅)获取来源
2. 客⼾端(调⽤⽅)设置来源
3. 配置授权规则, 即⿊⽩名单
服务端(被调⽤⽅)获取来源
服务端也就是order-service项⽬.
Sentinel是通过 RequestOriginParser 这个接⼝的 parseOrigin 来获取请求的来源的.
在服务端中实现RequestOriginParser这个接⼝即可
定义请求来源放在Header中, key为origin(⾃定义)
@Configuration
public class HeaderOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest httpServletRequest) {
//获取来源
String origin = httpServletRequest.getHeader("origin");
if(!StringUtils.hasLength(origin)){
return "default";
}
return origin;
}
}客⼾端(调⽤⽅)设置来源
也就是gateway项⽬
可以通过AddRequestHeader Filter设置Header
spring:
cloud:
gateway:
default-filters:
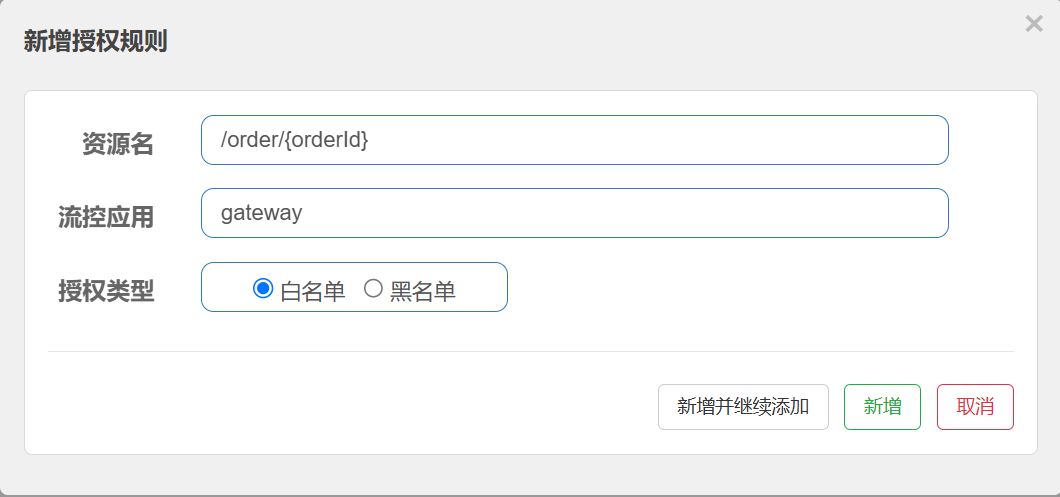
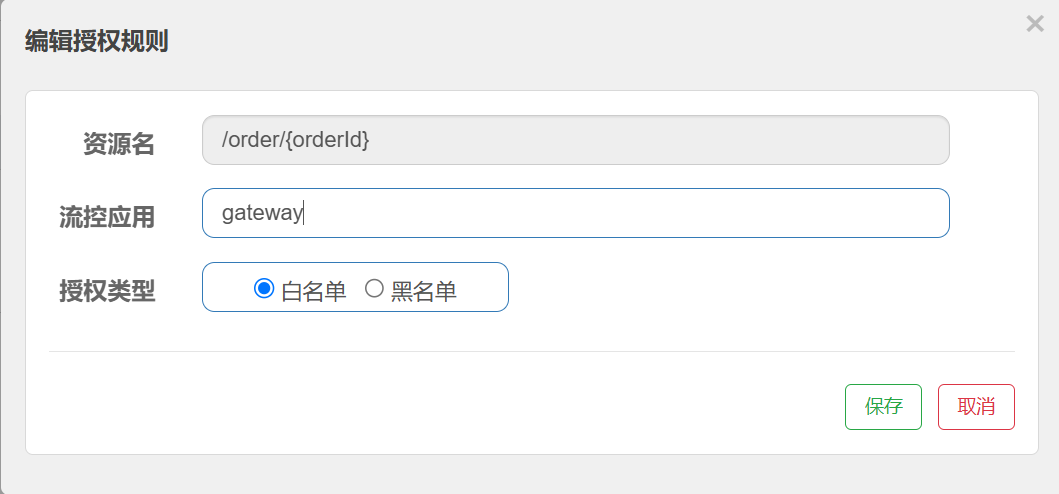
- AddRequestHeader=origin,gateway配置授权规则
对order-service的资源配置授权规则
流控应⽤: 即配置对应的⽩/⿊名单, 多个应⽤使⽤英⽂逗号分割.
以下配置表⽰, 来源为gateway的放⾏通过.
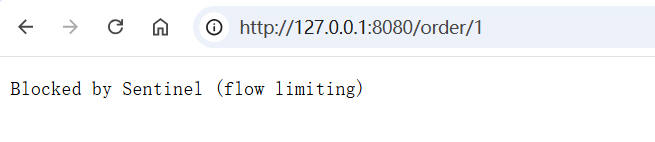
验证授权规则
使⽤浏览器访问 http://127.0.0.1:8080/order/1
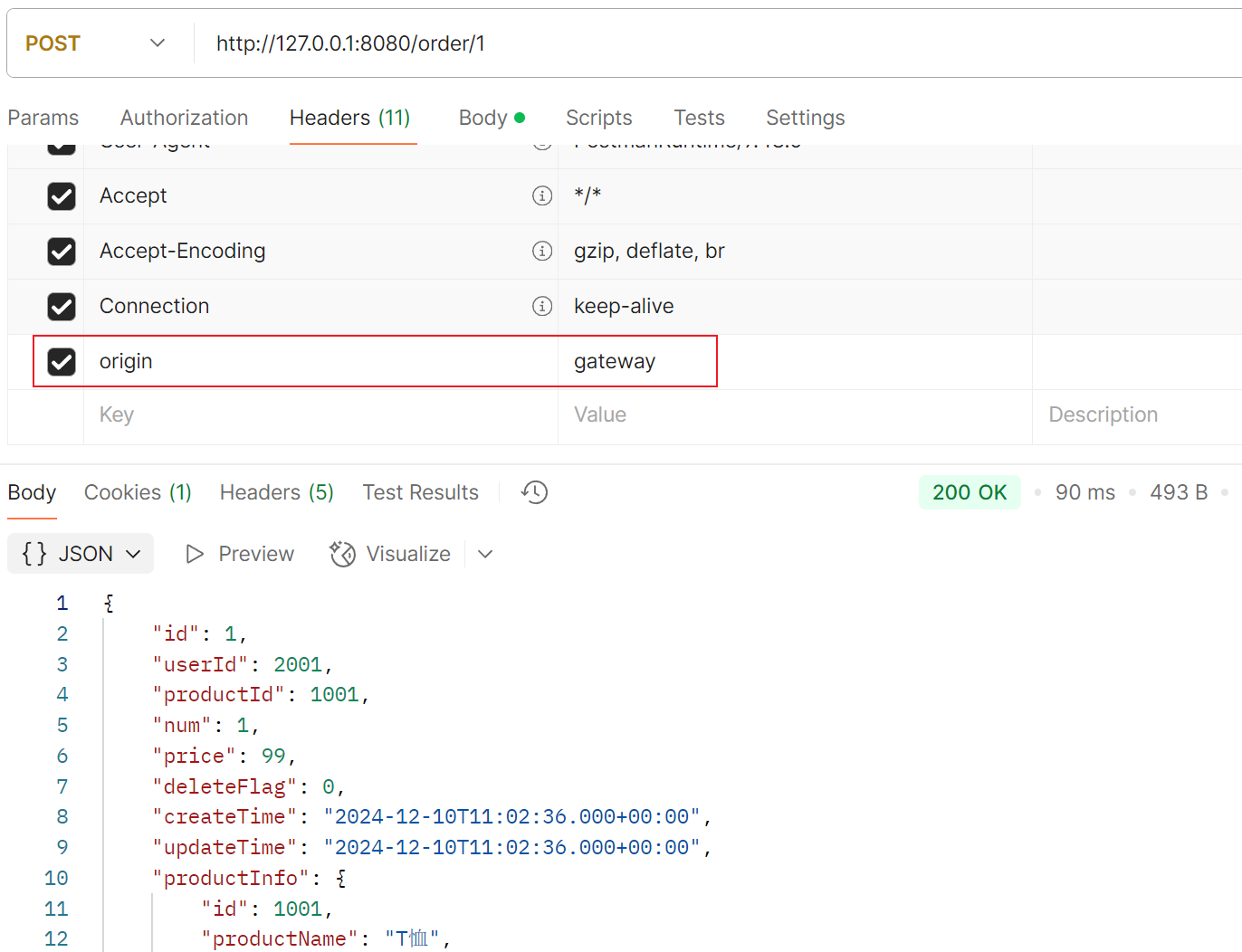
使⽤⽹关访问

使⽤postman, 添加header也可以访问通过
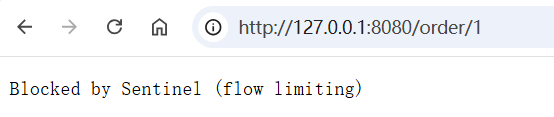
10. 定义异常返回结果
我们发现, 上⾯授权未通过时, 和限流返回的结果是⼀样的
这个返回结果不是很友好, ⽽且调⽤⽅分辨不出来异常原因
Sentinel提供了⼀个接⼝ BlockExceptionHandler , ⽤于⾃定义处理 BlockException 异常. 当请求被 Sentinel 限流、降级或授权拒绝时, 会抛出 BlockException . 通过实现 BlockExceptionHandler 接⼝, 可以定义统⼀的异常处理逻辑, 返回更友好的错误信息或执⾏特定的降级操作.
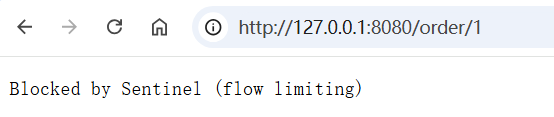
默认处理
Sentinel 默认提供了⼀个 DefaultBlockExceptionHandler 实现类, 当请求被阻塞时, 会返回⼀个简单的字符串提⽰"Blocked by Sentinel (flow limiting)"(不同版本可能会不⼀样).
public class DefaultBlockExceptionHandler implements BlockExceptionHandler {
public DefaultBlockExceptionHandler() {
}
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
response.setStatus(429);
PrintWriter out = response.getWriter();
out.print("Blocked by Sentinel (flow limiting)");
out.flush();
out.close();
}
}这也就是我们看到的界⾯
⾃定义处理
异常处理
我们如果需要修改这个提⽰, 为⽤⼾提供更好的体验, 通常需要⾃定义 BlockExceptionHandler .
@Component
public class SentinelExceptionHandle implements BlockExceptionHandler {
@Override
public void handle(HttpServletRequest httpServletRequest, HttpServletResponse response, BlockException e) throws Exception {
response.setContentType("text/html;charset=utf-8");
PrintWriter out = response.getWriter();
int status = 429;
String msg = "Blocked by Sentinel (flow limiting)";
if(e instanceof AuthorityException){
msg = "授权失败,请联系服务端进行配置";
status = 401;
}else if(e instanceof DegradeException){
msg = "发生降级";
}else if(e instanceof FlowException){
msg = "出发限流规则,请联系服务端进行配置";
} else if (e instanceof ParamFlowException) {
msg = "出发热点限流规则,请联系服务端进行配置";
}
response.setStatus(status);
out.print(msg);
out.flush();
out.close();
}
}验证结果
发⽣限流时
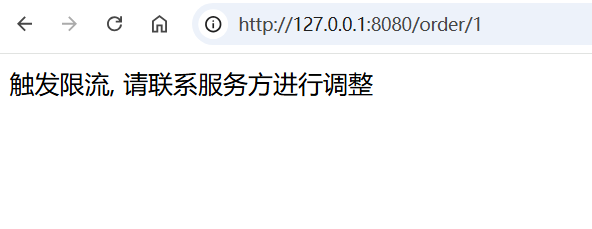
发⽣降级时
发⽣授权异常时
使⽤ @SentinelResource 注解
除了全局的 BlockExceptionHandler ,还可以在⽅法上使⽤ @SentinelResource 注解来指定特定的异常处理⽅法.
上⾯异常的处理, 相对⽐较统⼀, 如果我们希望给⼀些资源进⾏特殊的定义, 就可以使⽤
@SentinelResource 的 blockHandler/blockHandlerClass 属性.
参考: annotation-support | Sentinel
blockHandler
代码如下:
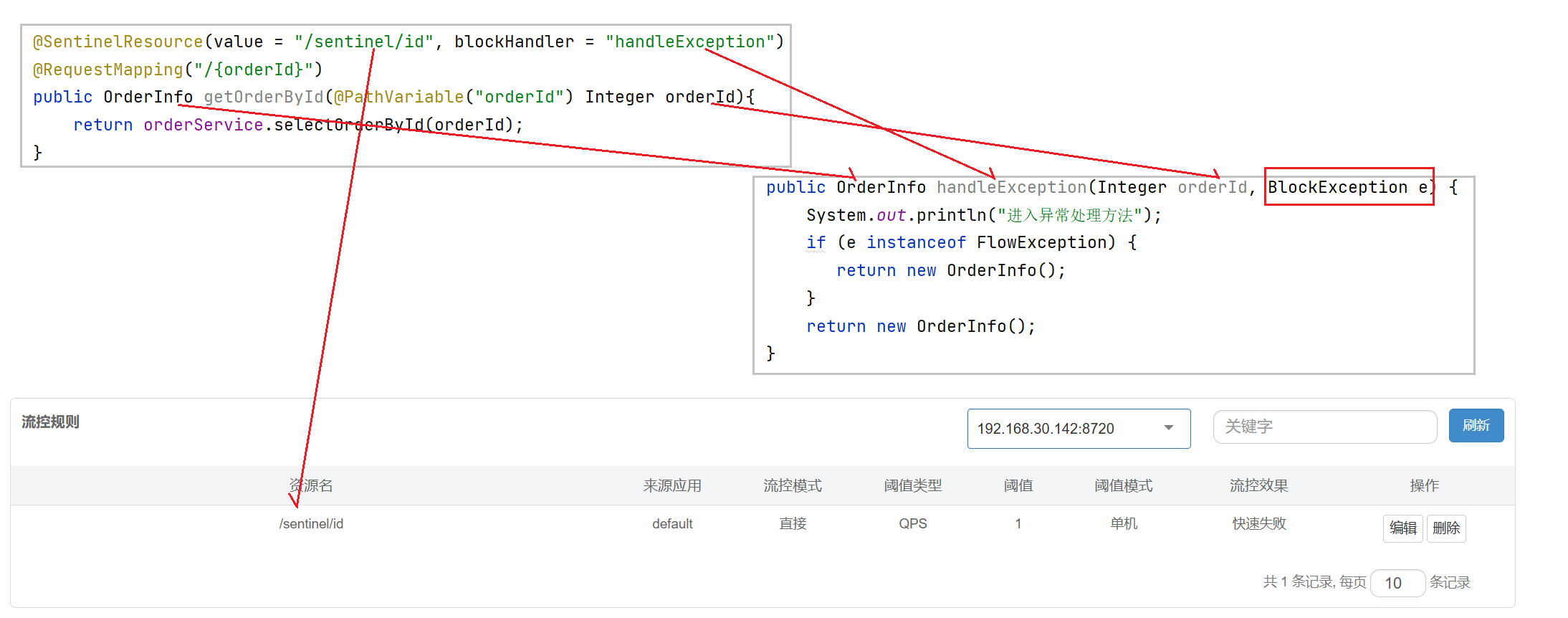
@SentinelResource(value = "/sentinel/id", blockHandler ="handleException")
@RequestMapping("/{orderId}")
public OrderInfo getOrderById(@PathVariable("orderId") Integer orderId){
return orderService.selectOrderById(orderId);
}
public OrderInfo handleException(Integer orderId, BlockException e) {
System.out.println("进⼊异常处理⽅法");
if (e instanceof FlowException) {
return new OrderInfo();
}
return new OrderInfo();
}blockHandler /blockHandlerClass:blockHandler 对应处理 BlockException 的函数名称. blockHandler 函数访问范围需要是 public , 返回类型需要与原⽅法相匹配, 参数类型需要和原⽅法相匹配并且最后加⼀个额外的参数, 类型为 BlockException . blockHandler 函数默认需要和原⽅法在同⼀个类中。若希望使⽤其他类的函数,则可以指定 blockHandlerclass 为对应的类的 class 对象,注意对应的函数必须为 static 函数,否则⽆法解析.
使⽤中注意事项:
1. 处理⽅法必须与受保护资源在同⼀个类中
2. 处理⽅法的修饰符必须为 public
3. 处理⽅法的参数列表必须和受保护资源相同, 并在最后加上 BlockException e 接收异常
4. 处理⽅法的返回值必须和受保护资源相同
5. 如果使⽤ blockHandlerClass 属性,处理⽅法必须是 public static 的
6. 限流规则⾥的资源名必须和@SentinelResource注解声明的资源⼀致
blockHandlerClass
代码如下:
@SentinelResource(value = "/sentinel/id",blockHandlerClass = ExceptionHandlerUtil.class, blockHandler ="handleException")
@RequestMapping("/{orderId}")
public OrderInfo getOrderById(@PathVariable("orderId") Integer orderId){
return orderService.selectOrderById(orderId);
}处理类
public class ExceptionHandlerUtil {
public static OrderInfo handleException(Integer orderId, BlockException e)
{
System.out.println("进⼊异常处理⽅法");
if (e instanceof FlowException) {
return new OrderInfo();
}
return new OrderInfo();
}
}注意事项 参考 blockHandler
11. 规则管理及推送
前⾯中, 发现了⼀个问题, 就是服务重启后, 之前设定的规则就会消失. 这是因为Sentinel 默认是将这些管理规则保存在内存中, 在⽣产环境中, 这个问题是不可接受的. 规则的丢失会导致系统失去流量控制和保护机制.
⽣产环境中, Sentinel需要规则持久化, sentinel-core 提供 API 和扩展接⼝来接收信息. 开发者需要根据⾃⼰的环境, 选取⼀个可靠的推送规则⽅式. 同时, 规则最好在控制台中集中管理.
关于规则持久化, Sentinel也给出了⼀些建议. 参考官⽅⽂档: 在⽣产环境中使⽤ Sentinel
⼀般来说,规则的推送有下⾯三种模式:
| 推送模式 | 说明 | 优点 | 缺点 |
| 原始模式 | API 将规则推送⾄客⼾端并直接更新到内存中,扩展写数据源(WritableDataSource) | 简单,⽆任何依赖 | 不保证⼀致性;规则保存在内存中,重启即消失。严重不建议⽤于⽣产环境 |
| Pull 模式 | 扩展写数据源(WritableDataSource), 客⼾端主动向某个规则管理中⼼定期轮询拉取规则,这个规则中⼼可以是 RDBMS、⽂件 等 | 简单,⽆任何依赖;规则持久化 | 不保证⼀致性;实时性不保证,拉取过于频繁也可能会有性能问题。 |
| Push 模式 | 扩展读数据源(ReadableDataSource),规则中⼼统⼀推送,客⼾端通过注册监听器的⽅式时刻监听变化,⽐如使⽤ Nacos、Zookeeper 等配置中⼼。这种⽅式有更好的实时性和⼀致性保证。⽣产环境下⼀般采⽤ push 模式的数据源。 | 规则持久化;⼀致性;快速 | 引⼊第三⽅依赖 |
原始模式
如果不做任何修改,Dashboard 的推送规则⽅式是通过 API 将规则推送⾄客⼾端并直接更新到内存中.
这种做法的好处是简单,⽆依赖;坏处是应⽤重启规则就会消失,仅⽤于简单测试,不能⽤于⽣产环境
Pull模式
pull 模式的数据源(如本地⽂件、RDBMS 等)⼀般是可写⼊的. 使⽤时需要在客⼾端注册数据源:将对应的读数据源注册⾄对应的 RuleManager,将写数据源注册⾄ transport 的 WritableDataSourceRegistry 中
以本地⽂件数据源为例:
1. 注册数据源
public class FileDataSourceInit implements InitFunc {
@Override
public void init() throws Exception {
String ruleDir = System.getProperty("user.home") +
"/sentinel/rules/orderService";
String flowRulePath = ruleDir + "/flow-rule.json";
mkdirIfNotExist(ruleDir);
createFileIfNotExist(flowRulePath);
// 注册⼀个可读数据源,⽤来定时读取本地的json⽂件,更新到规则缓存中
// 流控规则
ReadableDataSource<String, List<FlowRule>> ds = new
FileRefreshableDataSource<>(
flowRulePath, source -> JSON.parseObject(source, new
TypeReference<List<FlowRule>>() {})
);
// 将可读数据源注册⾄FlowRuleManager
// 这样当规则⽂件发⽣变化时,就会更新规则到内存
FlowRuleManager.register2Property(ds.getProperty());
WritableDataSource<List<FlowRule>> flowRuleWDS = new
FileWritableDataSource<>(
flowRulePath,
this::encodeJson
);
// 将可写数据源注册⾄transport模块的WritableDataSourceRegistry中
// 这样收到控制台推送的规则时,Sentinel会先更新到内存,然后将规则写⼊到⽂件中
WritableDataSourceRegistry.registerFlowDataSource(flowRuleWDS);
}
private <T> String encodeJson(T t) {
return JSON.toJSONString(t);
}
private void mkdirIfNotExist(String filePath) throws IOException {
File file = new File(filePath);
if (!file.exists()) {
file.mkdirs();
}
}
private void createFileIfNotExist(String filePath) throws IOException {
File file = new File(filePath);
if (!file.exists()) {
file.createNewFile();
}
}
}2. 在resources下创建META-INF/services⽬录,并创建⽂件:com.alibaba.csp.sentinel.init.InitFunc, 写本地数据源的路径
org.example.sentinel.FileDataSourceInit3. 重启服务, 设置流控, 会发现流控规则同步到指定的⽂件中.
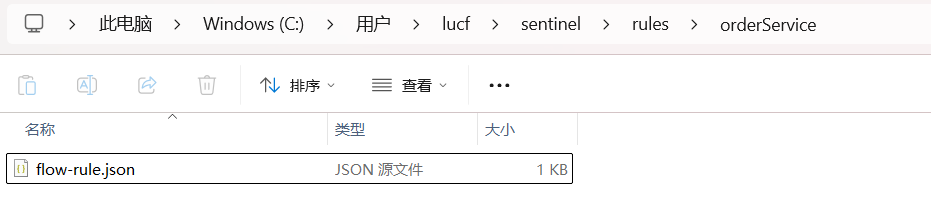
4. 再次重启服务, 规则依然保存(需要请求⼀下, 规则才可以看到)
5. 修改配置⽂件, 可以看到控制台也得到了更新.
配置⽂件说明:
[
{
// 资源名
"resource": "/test",
// 针对来源,若为 default 则不区分调⽤来源
"limitApp": "default",
// 限流阈值类型(1:QPS;0:并发线程数)
"grade": 1,
// 阈值
"count": 1,
// 是否是集群模式
"clusterMode": false,
// 流控效果(0:快速失败;1:Warm Up(预热模式);2:排队等待)
"controlBehavior": 0,
// 流控模式(0:直接;1:关联;2:链路)
"strategy": 0,
// 预热时间(秒,预热模式需要此参数)
"warmUpPeriodSec": 10,
// 超时时间(排队等待模式需要此参数)
"maxQueueingTimeMs": 500,
// 关联资源、⼊⼝资源(关联、链路模式)
"refResource": "rrr"
}
]本地⽂件数据源会定时轮询⽂件的变更,读取规则。这样我们既可以在应⽤本地直接修改⽂件来更新规则,也可以通过 Sentinel 控制台推送规则。以本地⽂件数据源为例,推送过程如下图所⽰:
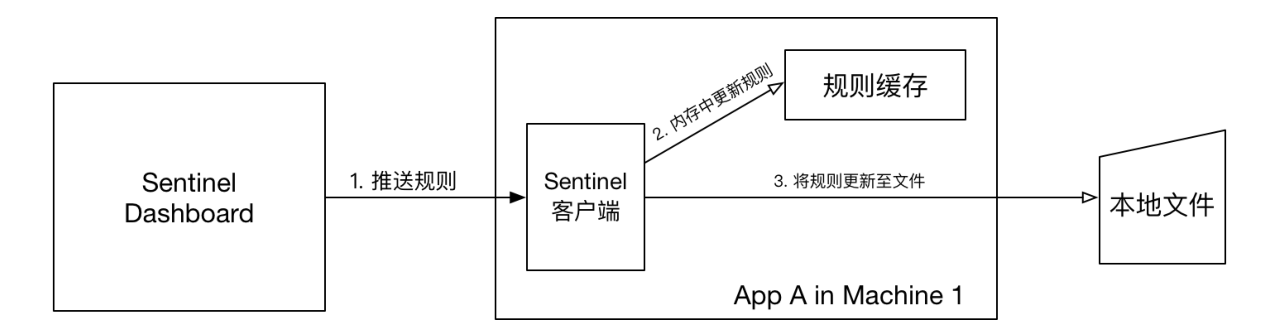
⾸先 Sentinel 控制台通过 API 将规则推送⾄客⼾端并更新到内存中,接着注册的写数据源会将新的规则保存到本地的⽂件中。使⽤ pull 模式的数据源时⼀般不需要对 Sentinel 控制台进⾏改造。
这种实现⽅法好处是简单,不引⼊新的依赖,坏处是⽆法保证监控数据的⼀致性。
Push模式
⽣产环境下⼀般更常⽤的是 push 模式的数据源. 对于 push 模式的数据源,如远程配置中⼼(ZooKeeper, Nacos, Apollo等等),推送的操作不应由 Sentinel 客⼾端进⾏,⽽应该经控制台统⼀进⾏管理,直接进⾏推送,数据源仅负责获取配置中⼼推送的配置并更新到本地。因此推送规则正确做法应该是 配置中⼼控制台/Sentinel 控制台 → 配置中⼼ → Sentinel 数据源 → Sentinel,⽽不是经 Sentinel 数据源推送⾄配置中⼼。这样的流程就⾮常清晰了:
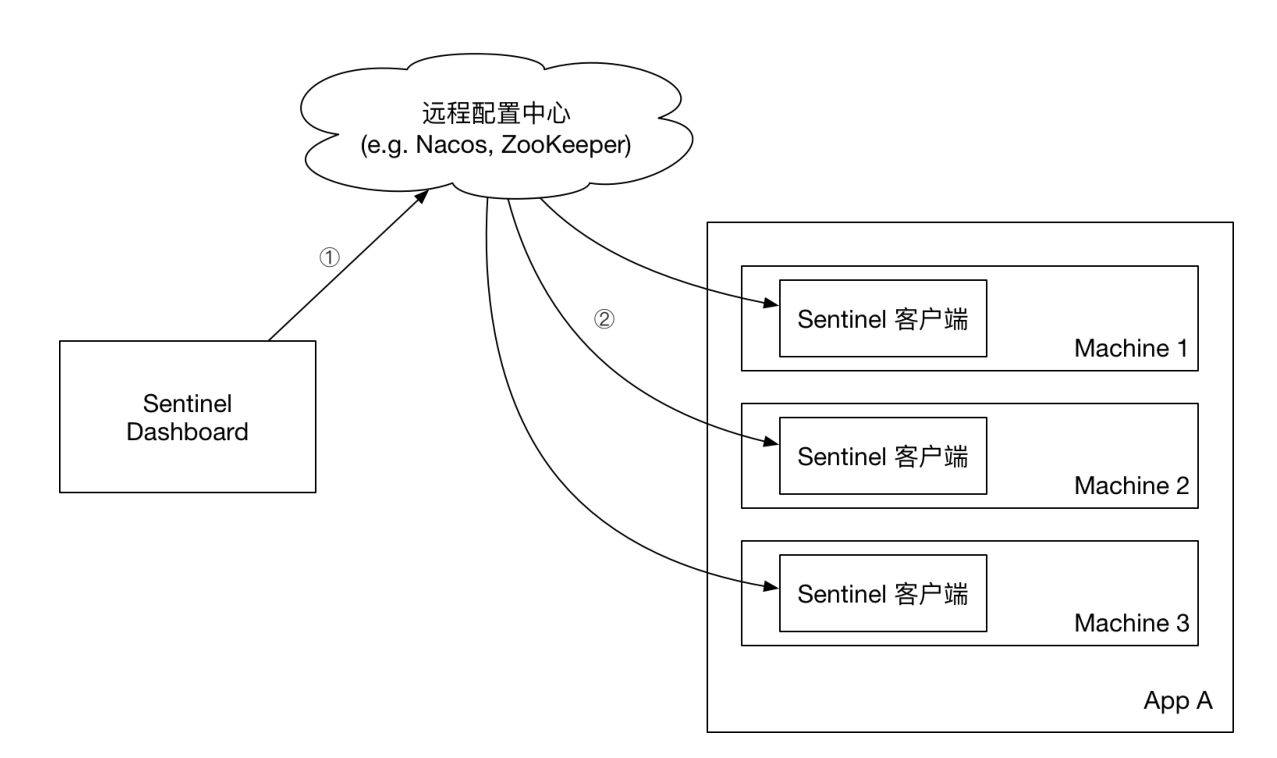
Sentinel官⽅提供了ZooKeeper, Redis, Nacos, Apollo, etcd 等的动态数据源实现, 参考: dynamicrule-configuration | Sentinel
接下来以Nacos为例来讲解.
参考官⽅案例: Sentinel/sentinel-extension/sentinel-datasource-nacos at master · alibaba/Sentinel
Nacos官⽅⽀持
依然是借助 Sentinel 的 InitFunc SPI 扩展接⼝. 只需要实现⾃⼰的 InitFunc 接⼝,在 init
⽅法中编写注册数据源的逻辑.
添加依赖
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>注册数据源
public class NacosDataSourceInit implements InitFunc {
@Override
public void init() throws Exception {
// remoteAddress 代表 Nacos 服务端的地址
// groupId 和 dataId 对应 Nacos 中相应配置
final String remoteAddress = "152.136.172.144:10020";
final String groupId = "SENTINEL_GROUP";
final String dataId = "order-service-flow-rule";
ReadableDataSource<String, List<FlowRule>> flowRuleDataSource = new NacosDataSource<>(remoteAddress, groupId, dataId,
source -> JSON.parseObject(source, new TypeReference<List<FlowRule>>() {}));
FlowRuleManager.register2Property(flowRuleDataSource.getProperty());
}
}配置数据源路径
在resources下创建META-INF/services⽬录,并创建⽂件:com.alibaba.csp.sentinel.init.InitFunc, 写本地数据源的路径
com.bite.order.sentinel.NacosDataSourceInit配置Nacos
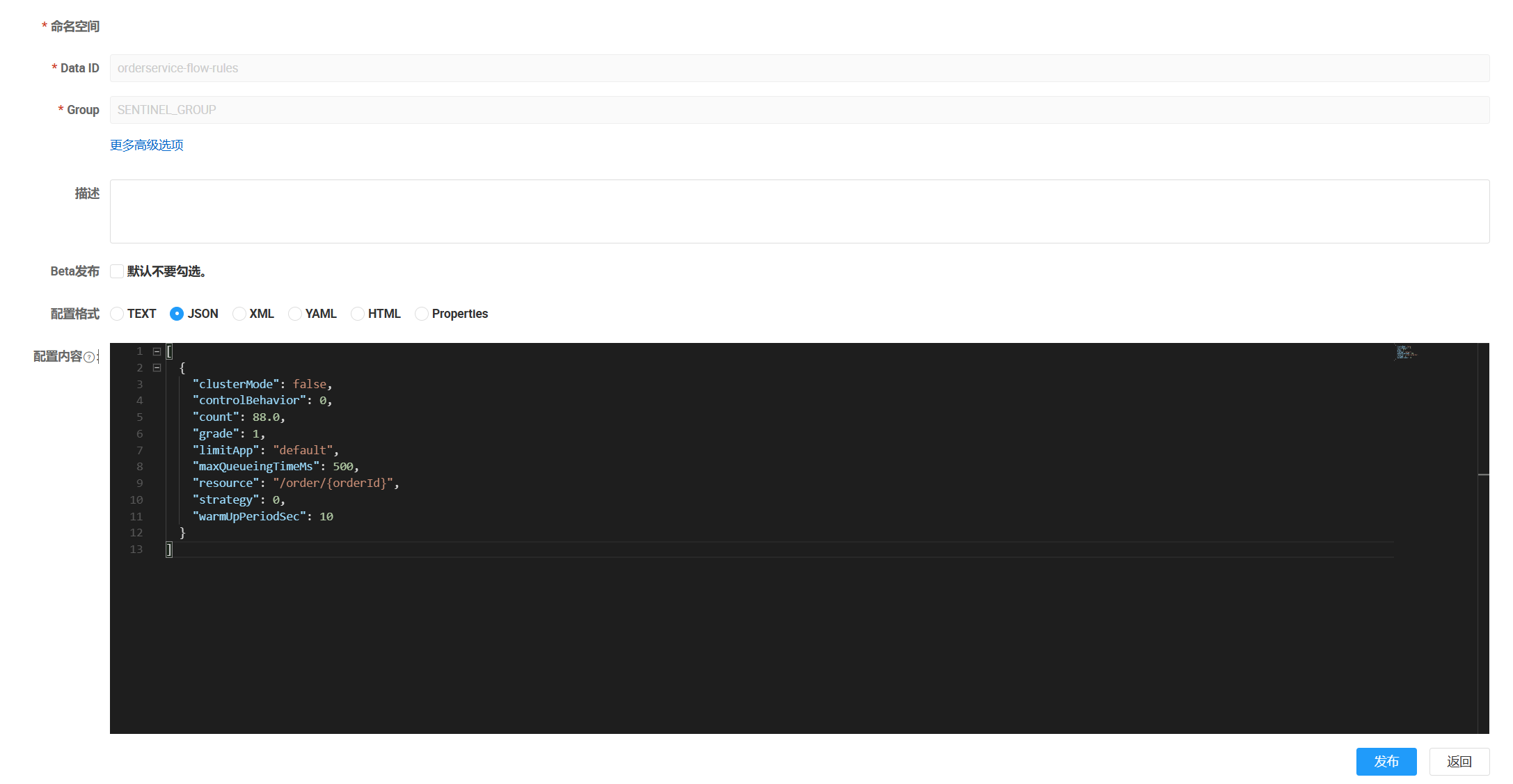
配置内容:
[
{
"clusterMode": false,
"controlBehavior": 0,
"count": 20,
"grade": 1,
"limitApp": "default",
"maxQueueingTimeMs": 500,
"resource": "/order/{orderId}",
"strategy": 0,
"warmUpPeriodSec": 10
}
]验证结果
重启服务, 会发现Sentinel Dashboard已经从nacos获取规则配置信息了.
1. 修改Nacos⽂件, 发现Sentinel Dashboard 会及时更新
2. 通过Sentinel Dashboard修改规则, 发现Nacos配置⽂件并没有同步更新.
Sentinel集成Nacos持久化
上述我们发现, Nacos修改的内容会及时同步到Sentinel DashBoard, 但是Sentinel DashBoard更新的内容, 并不会同步到Nacos, 这在⽣产环境中, 也是不⽅便使⽤的. 所以我们需要修改Sentinel的源码, 让其⽀持双向通讯.
源码改造
源码改造的过程有些复杂, 但难度不⼤
1. 下载Sentinel源码
下载地址:https://github.com/alibaba/Sentinel/releases
2. 修改pom⽂件
解压, 使⽤idea打开, 修改pom⽂件
在sentinel-dashboard源码的pom⽂件中, nacos的依赖默认的scope是test, 只能在测试时使⽤
<!-- for Nacos rule publisher sample -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
<!-- <scope>test</scope>-->
</dependency>注掉 <scope>test</scope>
3. 添加Nacos⽀持
sentinel-dashboard 的 test 包下, 已经编写了对nacos的⽀持
接下来把 com.alibaba.csp.sentinel.dashboard.rule.nacos ⽂件复制到 src/main/java/com.alibaba.csp.sentinel.dashboard.rule ⽬录下
4. 修改Nacos配置
修改NacosConfig
从配置中读取, 或者直接写死地址
@Configuration
public class NacosConfig {
@Value("${sentinel.nacos.addr}")
private String nacosAddr;
@Bean
public Converter<List<FlowRuleEntity>, String> flowRuleEntityEncoder() {
return JSON::toJSONString;
}
@Bean
public Converter<String, List<FlowRuleEntity>> flowRuleEntityDecoder() {
return s -> JSON.parseArray(s, FlowRuleEntity.class);
}
@Bean
public ConfigService nacosConfigService() throws Exception {
return ConfigFactory.createConfigService(nacosAddr);
}
}在 sentinel-dashboard 的 application.properties 中添加nacos地址配置: IP地址改为⾃⼰nacos的地址
sentinel.nacos.addr=152.136.172.144:100205. 配置Nacos数据源
开启 Controller 层操作 Nacos 的开关
代码位于:
com.alibaba.csp.sentinel.dashboard.controller.v2.FlowControllerV2
修改后代码如下:
@Autowired
@Qualifier("flowRuleNacosProvider")
private DynamicRuleProvider<List<FlowRuleEntity>> ruleProvider;
@Autowired
@Qualifier("flowRuleNacosPublisher")
private DynamicRulePublisher<List<FlowRuleEntity>> rulePublisher;
6. 修改前端⻚⾯
前端共3处修改
• 修改src/main/webapp/resources/app/scripts/directives/sidebar/sidebar.html
将该部分注释打开

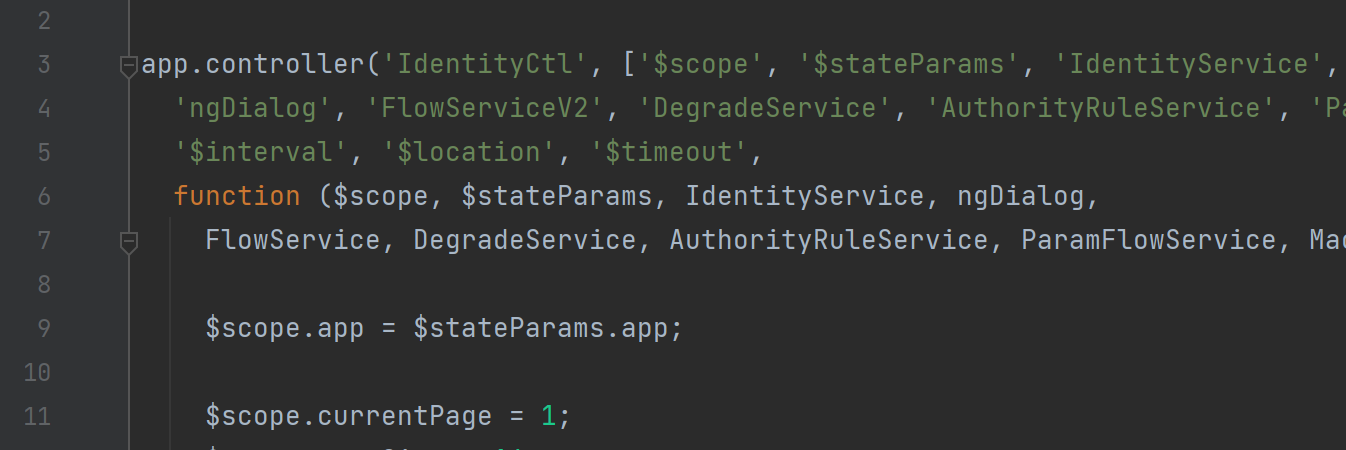
• 修改 src/main/webapp/resources/app/scripts/controllers/identity.js
⼤概第4⾏左右, 修改 FlowServiceV1 -> FlowServiceV2
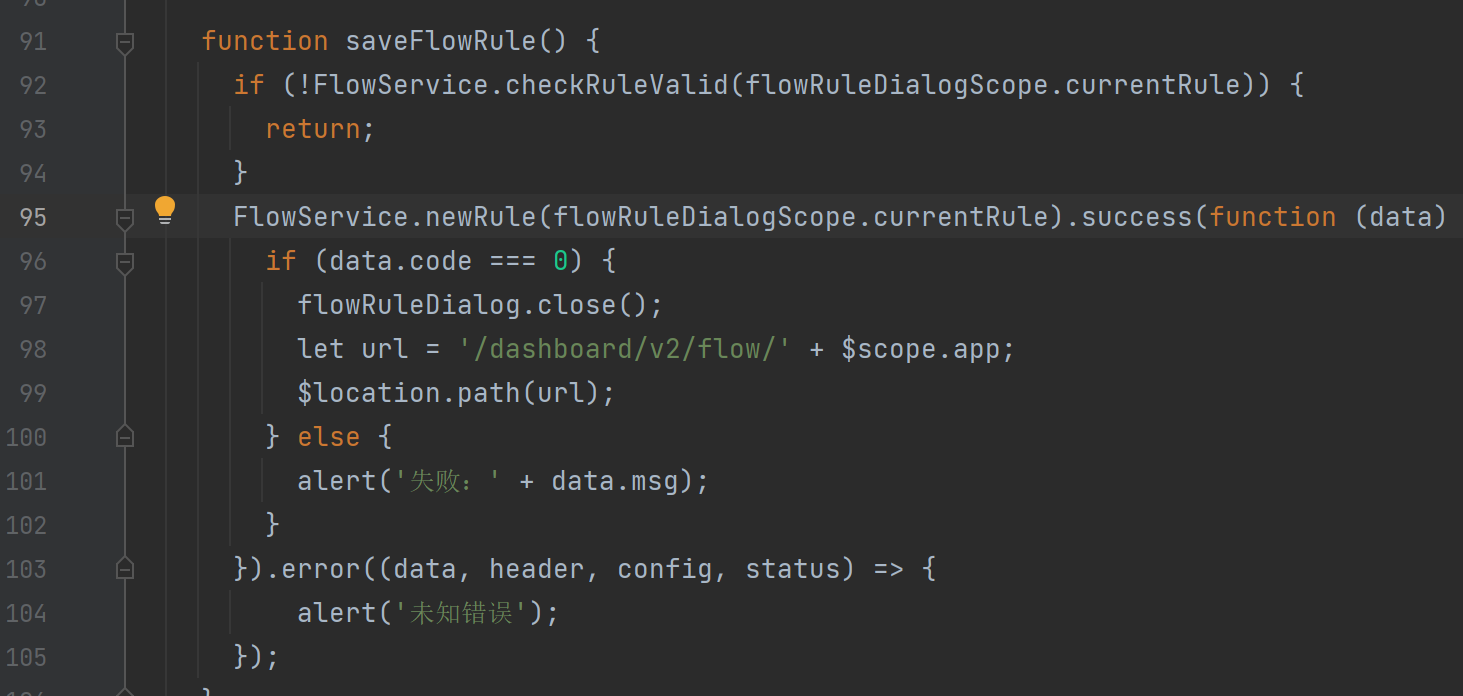
• 搜索"/dashboard/flow/", ⼤概98⾏左右
修改 /dashboard/flow/ -> /dashboard/v2/flow/
修改 identity.js ⽂件主要是在 Sentinel Dashboard上点击资源的"流控"按钮, 添加规则后将信息同步给 Nacos.
7. 重新打包, 启动
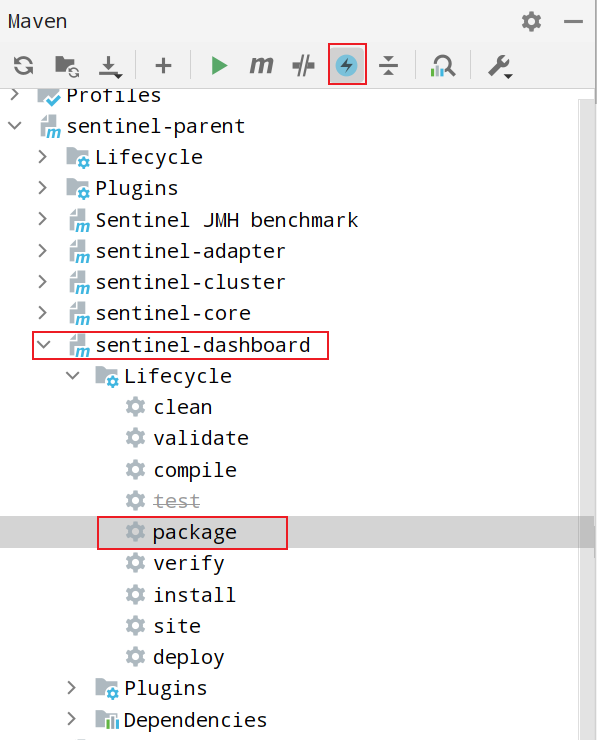
上⾯的操作完成之后, 重新编译打包, 需要跳过单元测试
启动⽅式和官⽅⼀样
java -jar sentinel-dashboard.jar也可以添加参数
java -jar -Dserver.port=8100 -Dsentinel.dashboard.auth.username=admin - Dsentinel.dashboard.auth.password=admin sentinel-dashboard.jar启动完成后, 需要清理缓存并刷新⻚⾯ctrl+shif+delete
配置Nacos
修改order-service 服务, 让其监听Nacos的规则配置
1. 引⼊依赖
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>2. 配置Nacos地址
spring:
application:
name: order-service
profiles:
active: @profile.name@
cloud:
#开启nacos的负载均衡策略
loadbalancer:
nacos:
enabled: true
nacos:
discovery:
server-addr: 152.136.172.144:10020
sentinel:
transport:
dashboard: 127.0.0.1:8100 #sentinel控制台地址
web-context-unify: false #关闭context整合
datasource:
flow-rules: #流控规则
nacos:
server-addr: 152.136.172.144:10020
dataId: order-service-flow-rules
groupId: SENTINEL_GROUP
rule-type: flow3. 验证
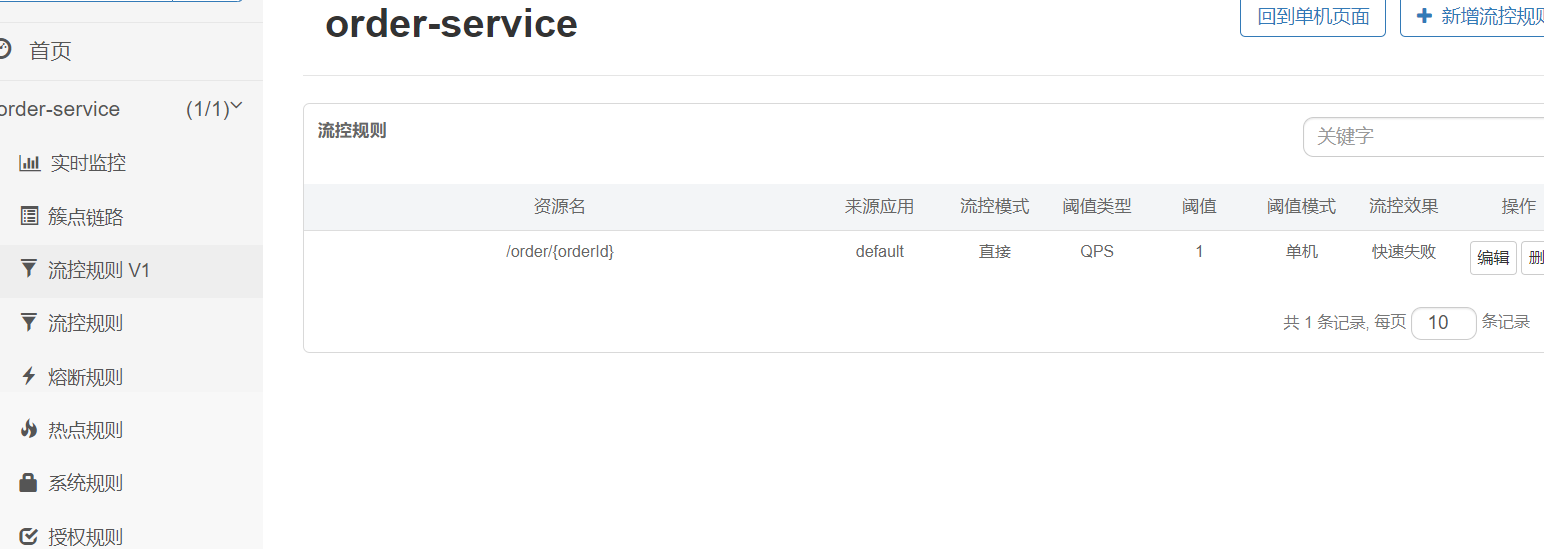
重启服务, 通过Sentinel Dashboard设置流控规则, 观察Nacos变化
Nacos同步更新
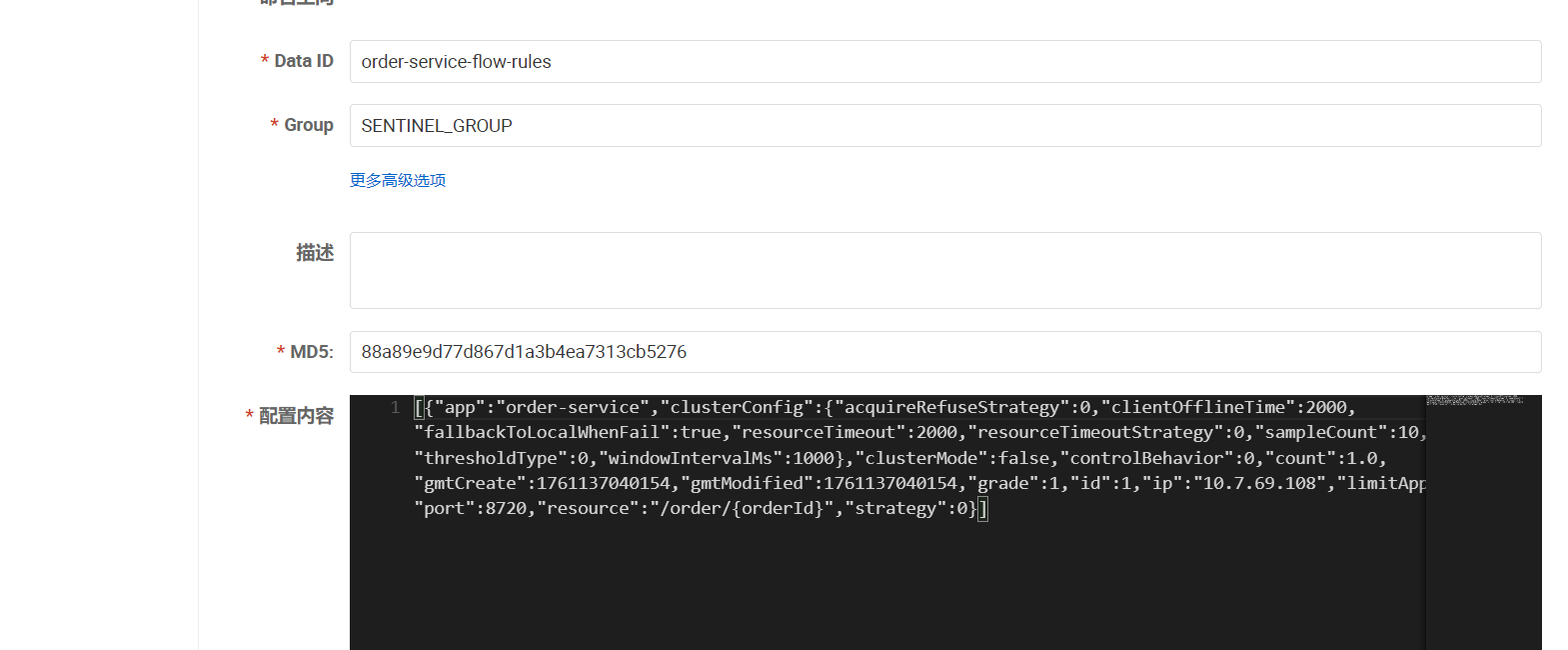
修改Nacos配置, 观察Sentinel Dashboard也进⾏了同步更新.
1. Seata 介绍
Seata 是⼀款开源的分布式事务解决⽅案, 致⼒于提供⾼性能和简单易⽤的分布式事务服务. Seata 将为⽤⼾提供了 AT、TCC、SAGA 和 XA 事务模式, 为⽤⼾打造⼀站式的分布式解决⽅案.
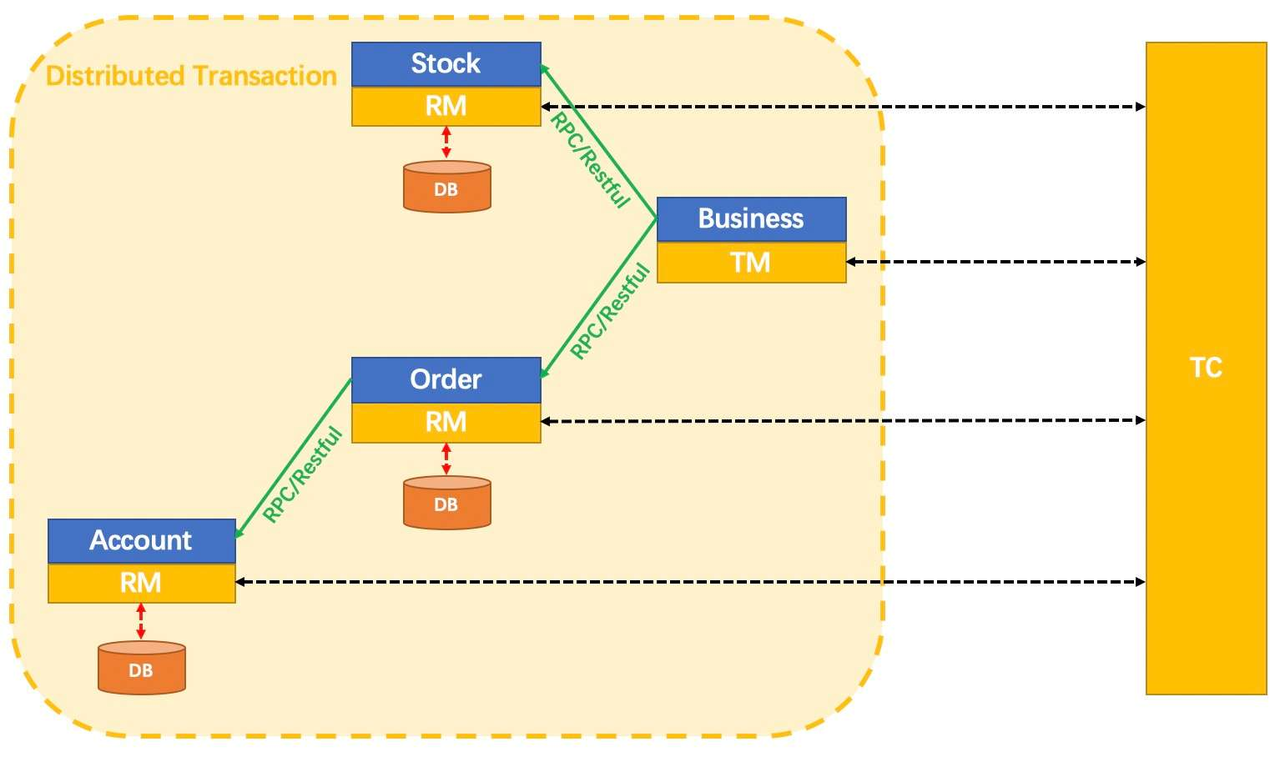
2. 什么是分布式事务
回顾事务
事务这个概念, 我们并不是第⼀次接触了. 提到事务这个概念, ⼤家第⼀想到的应该就是数据库的事务.
所谓的数据库事务是指把⼀组SQL语句打包成为⼀个整体, 在这组SQL的执⾏过程中, 要么全部成功, 要么全部失败.
事务必须满⾜ACID特性: Atomicity (原⼦性), Consistency (⼀致性), Isolation (隔离性)和 Durability (持久性)
• Atomicity (原⼦性):⼀个事务中的所有操作, 要么全部成功, 要么全部失败, 不会出现只执⾏了⼀半的情况, 如果事务在执⾏过程中发⽣错误, 会回滚 ( Rollback ) 到事务开始前的状态, 就像这个事务从来没有执⾏过⼀样 .
• Consistency (⼀致性):在事务开始之前和事务结束以后, 数据库的完整性不会被破坏. 这表⽰写⼊的数据必须完全符合所有的预设规则, 包括数据的精度、关联性以及关于事务执⾏过程中服务器崩溃后如何恢复 .
• Isolation (隔离性):数据库允许多个并发事务同时对数据进⾏读写和修改, 隔离性可以防⽌多个事务并发执⾏时由于交叉执⾏⽽导致数据的不⼀致. 事务可以指定不同的隔离级别, 以权衡在不同的应⽤场景下数据库性能和安全 .
• Durability (持久性):事务处理结束后, 对数据的修改将永久的写⼊存储介质, 即便系统故障也不会丢失.
以上是针对单库多表的情况事务所要满⾜的特性.
分布式事务
在微服务架构下, 随着业务服务的拆分及数据库的拆分会存在如下图所⽰的场景, 订单和库存分别拆分成了两个独⽴的数据库, 当客⼾端发起⼀个下单操作时, 需要在订单服务对应的数据库中创建订单, 同时需要调⽤库存服务完成商品库存的扣减.
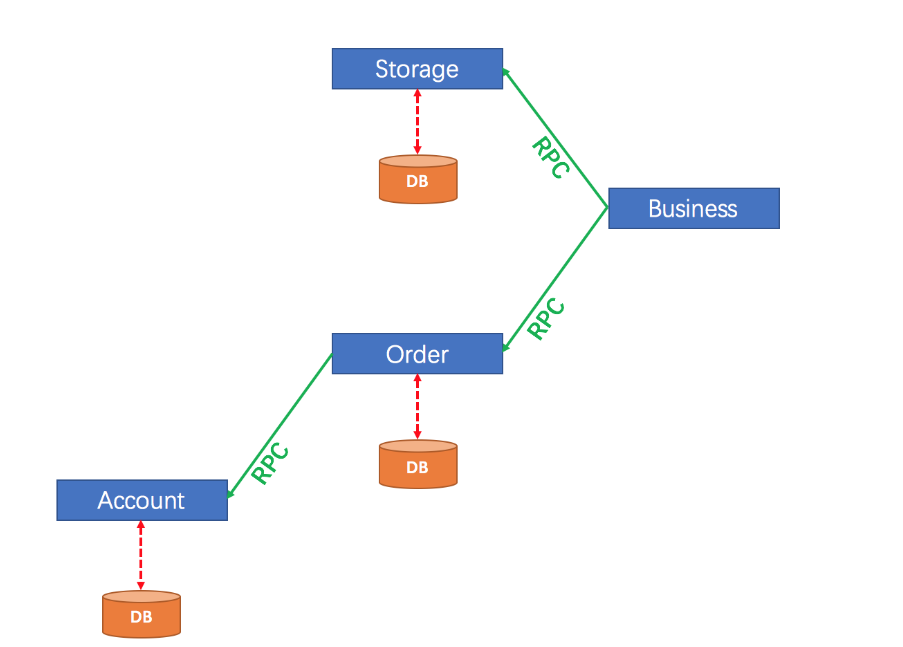
分布式事务是指在分布式系统中, 为了保证数据的⼀致性和完整性, 对多个节点上的数据进⾏操作的事务. 当⼀个事务涉及到多个不同的数据库、服务或应⽤实例时, 就构成了分布式事务.
⽐如上图, 订单服务的数据操作和库存服务的数据操作保持⼀致(同时成功或同时失败), 就是分布式事务的范畴.简单来说就是分布式数据⼀致性问题, 也就是如何在分布式场景中保证多个节点数据的⼀致性.
3. 分布式事务问题演⽰
我们先来看分布式事务存在的问题.
项⽬搭建
上图中项⽬架构有些复杂, 我们稍作修改, 也可以演⽰分布式事务的问题. ⽤⼾下订单后, 调⽤库存服务扣减库存和⽤⼾服务扣减余额.
步骤:
1. 创建数据库,
由于使⽤了SQL的CHECK约束, 要求MySQL版本为8.X
CREATE DATABASE IF NOT EXISTS seata_test;
use seata_test;
DROP TABLE IF EXISTS `storage_tbl`;
CREATE TABLE `storage_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`commodity_code` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT 0,
PRIMARY KEY (`id`),
UNIQUE KEY (`commodity_code`),
CONSTRAINT `count_chk` CHECK (`count` >= 0)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `order_tbl`;
CREATE TABLE `order_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`commodity_code` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT 0,
`money` int(11) DEFAULT 0,
PRIMARY KEY (`id`),
CONSTRAINT `count_chk_2` CHECK (`count` >= 0),
CONSTRAINT `money_chk` CHECK (`money` >= 0)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `account_tbl`;
CREATE TABLE `account_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`money` int(11) DEFAULT 0,
PRIMARY KEY (`id`),
CONSTRAINT `money_chk_2` CHECK (`money` >= 0)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 数据
INSERT INTO `storage_tbl` VALUES (1, '2001', 160);
INSERT INTO `storage_tbl` VALUES (2, '2002', 1000);
INSERT INTO `storage_tbl` VALUES (3, '2003', 500);
INSERT INTO `storage_tbl` VALUES (4, '2004', 400);
INSERT INTO `storage_tbl` VALUES (5, '2005', 600);
INSERT INTO `account_tbl` VALUES (1, '1001', 800);
INSERT INTO `account_tbl` VALUES (2, '1002', 2000);
INSERT INTO `account_tbl` VALUES (3, '1003', 1400);
INSERT INTO `account_tbl` VALUES (4, '1004', 2800);
INSERT INTO `account_tbl` VALUES (5, '1005', 3000);2.微服务前提:
微服务结构如下:
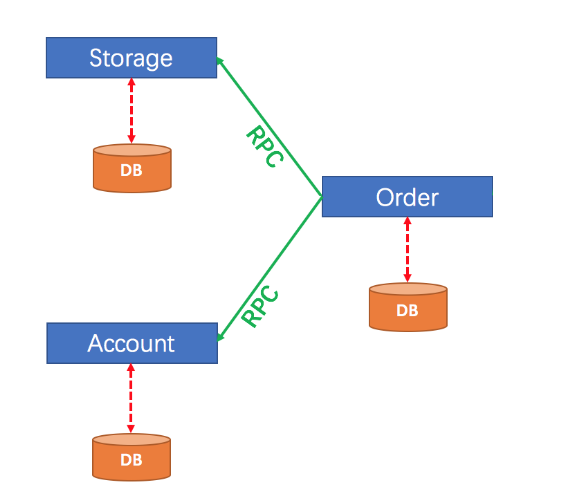
服务说明如下:
◦ account-service : ⽤⼾服务, 管理⽤⼾的资⾦账⼾. 提供扣减余额的接⼝
◦ storage-service : 库存服务, 管理商品库存. 提供扣减库存的接⼝
◦ order-service : 订单服务, 负责管理订单. 创建订单时, 会调⽤ account-service 和 storage-service
3. 修改配置⽂件
修改mysql账号密码, nacos地址(三个项⽬的⽂件均需修改).
spring:
application:
name: order-service
datasource:
url: jdbc:mysql://127.0.0.1:3306/seata_test?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false
username: root
password: "123456"
driver-class-name: com.mysql.cj.jdbc.Driver
cloud:
nacos:
discovery:
server-addr: 152.136.172.144:100204. 启动三个服务, 测试服务接⼝是否正常.
问题演⽰
当库存充⾜, 余额不⾜时, 会发现余额扣减失败, 但是库存和订单均不会回滚, 这就是分布式事务问题 创建订单
请求发⽣异常:
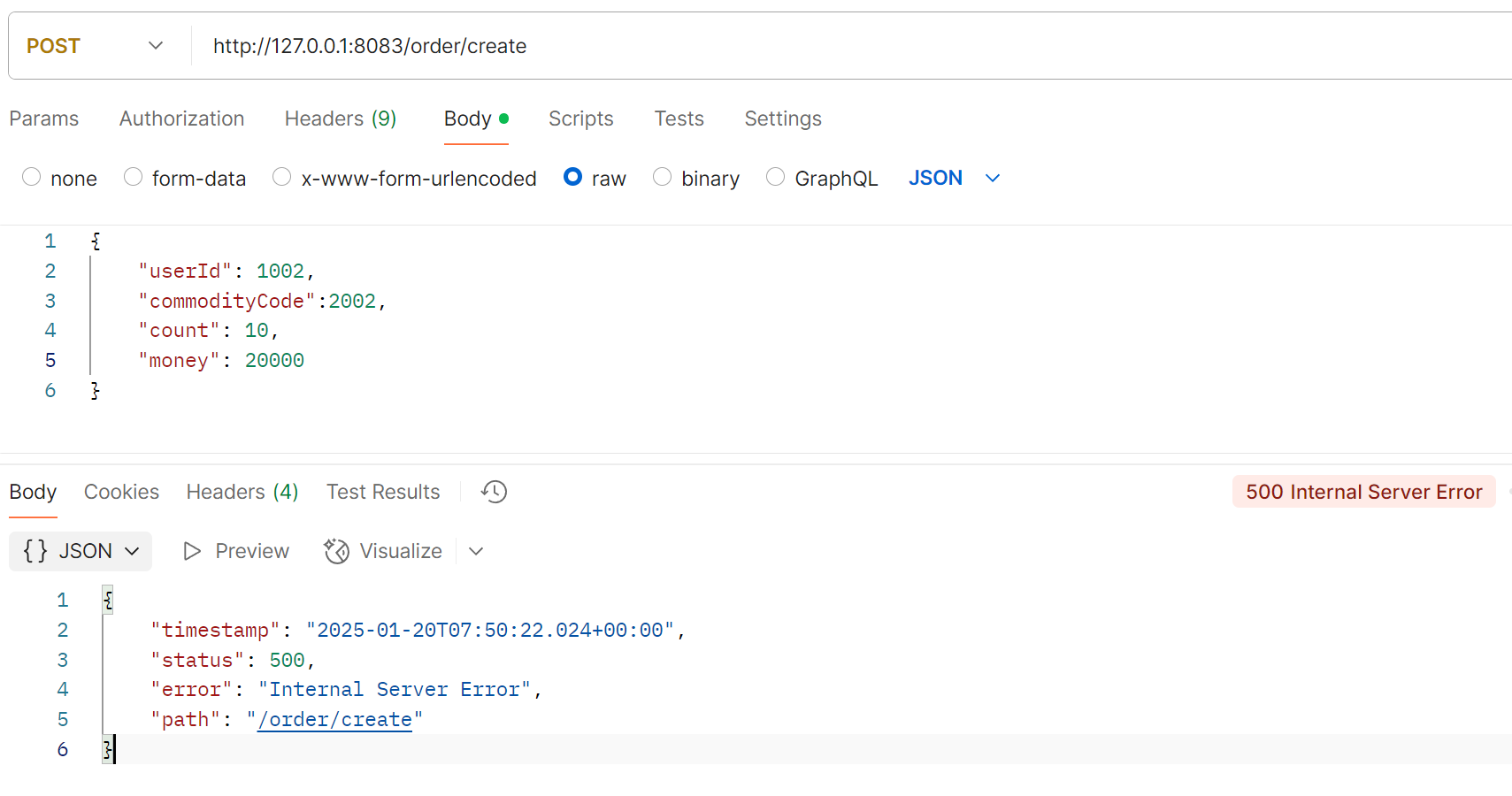
观察执⾏前后数据库变化:

库存扣减成功, 但是扣减余额时, 因为余额不⾜, 发⽣异常, 库存也并没有得到回滚, 这就是分布式事务问题.
4. 分布式事务问题的理论模型
分布式事务问题也叫分布式数据⼀致性问题. 简单来说就是如何在分布式场景中保证多个节点数据的⼀致性. 分布式事务产⽣的核⼼原因在于存储资源的分布性, ⽐如多个数据库, 或者MySQL和Redis两种不同存储设备的数据⼀致性等. 在实际应⽤中, 我们应该尽可能地从设计层⾯去避免分布式事务的问题, 因为任何⼀种解决⽅案都会增加系统的复杂度. 接下来我们了解⼀下分布式事务问题的常⻅解决⽅案.
我们需要先了解⼀些相关的基础理论.
CAP理论
在之前博客的注册中⼼阶段, 有CAP理论, 此处简单回顾.
CAP 理论是分布式系统设计中最基础, 也是最为关键的理论.
• ⼀致性(Consistency) CAP理论中的⼀致性, 指的是强⼀致性. 所有节点在同⼀时间具有相同的数据
• 可⽤性(Availability) 保证每个请求都有响应(响应结果可能不对)
• 分区容错性(Partition Tolerance) 当出现⽹络分区后, 系统仍然能够对外提供服务
CAP 理论告诉我们: ⼀个分布式系统不可能同时满⾜数据⼀致性, 服务可⽤性和分区容错性这三个基本需求, 最多只能同时满⾜其中的两个.
在分布式系统中, 系统间的⽹络不能100%保证健康, 服务⼜必须对外保证服务. 因此Partition Tolerance不可避免. 那就只能在C和A中选择⼀个. 也就是CP或者AP架构
正常情况:
⽹络异常:
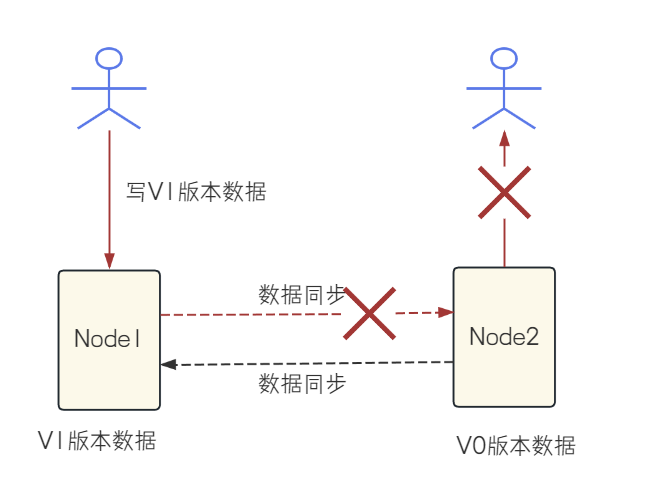
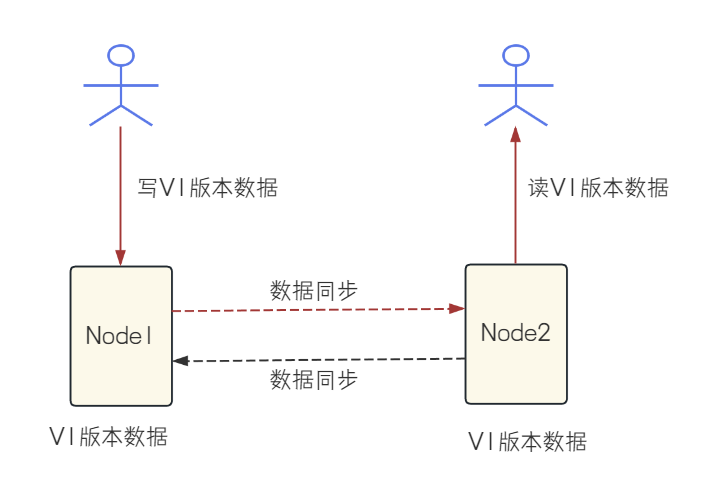
CP架构: 为了保证分布式系统对外的数据⼀致性, 于是选择不返回任何数据
AP架构: 为了保证分布式系统的可⽤性, 节点2返回V0版本的数据(即使这个数据不正确)
BASE理论
BASE理论是由于CAP中⼀致性和可⽤性不可兼得⽽衍⽣出来的⼀种新的思想, BASE理论的核⼼思想是通过牺牲数据的强⼀致性来获得⾼可⽤性.
它有如下三个特性:
• Basically Available (基本可⽤): 分布式系统在出现故障时, 允许损失⼀部分功能的可⽤性,保证核⼼功能的可⽤
• Soft state (软状态): 允许系统中的数据存在中间状态, 也就是允许系统中不同节点的数据副本之间的同步存在延时, 这个状态不影响系统的可⽤性
• Eventually Consistent (最终⼀致性): 中间状态的数据在经过⼀段时间之后, 会达到⼀个最终的数据⼀致性
BASE理论不要求数据的强⼀致, ⽽是允许数据在⼀段时间内是不⼀致的, 但是数据最终会在某个时间点实现⼀致. 在互联⽹产品中, ⼤部分都会采⽤BASE理论来实现数据的⼀致, 因为产品的可⽤性对于⽤⼾来说更加重要.
⽐如上述订单的创建. 不需要同步等待库存服务和⽤⼾服务的执⾏结果. 它们各⾃执⾏并提交事务, 如果库存服务和⽤⼾服务其中⼀个失败, 则采⽤⼀定的措施(⽐如回滚)保证数据的最终⼀致性.
与CAP理论的对⽐
CAP理论指出: ⼀个分布式系统不可能同时满⾜⼀致性 (C ) 、可⽤性 (A ) 和分区容错性 (P ) 这三个特性. BASE理论则是CAP理论的补充, 通过放宽对⼀致性的严格要求, 换取系统更⾼的可⽤性和灵活性.
BASE理论的核⼼思想是: 如果不是必须的话, 不推荐使⽤事务或强⼀致性, ⿎励可⽤性和性能优先. 允许在牺牲⼀定⼀致性的前提下获得更⾼的可⽤性.
X/Open 分布式事务模型
X/Open 是⼀个组织, X/Open DTP ( Distributed Transaction Process Reference Model) 是X/Open这个组织定义的⼀套分布式事务的标准. 这个标准提出了使⽤两阶段提交(2PC,Two-Phase-Commit) 来保证分布式事务的完整性.
这套标准主要定义了实现分布式事务的规范和API, 具体的实现则交给相应的⼚商来实现.
相关⽂档: DTP 参考模型: https://pubs.opengroup.org/onlinepubs/9294999599/toc.pdf
X/Open DTP参考模型包含三种⻆⾊:
• AP: Application, 应⽤程序.
• RM: Resource Manager, 资源管理器, ⽐如数据库. 应⽤程序可以通过资源管理器对相应的资源进⾏有效的控制
• TM: Transaction Manager, 事务管理器, ⼀般指事务协调者, 负责协调和管理各个⼦事务, 可以理解为管理RM.
在分布式系统中, 会有多个节点, 每⼀个节点都能够明确的知道⾃⼰在进⾏事务操作过程中的结果是成功或失败, 但⽆法直接获取到其他分布式节点的操作结果, 因此, 当⼀个事务操作需要跨越多个分布式节点的时候, 为了保证事务处理的ACID特性, 就需要引⼊⼀个"协调者"的组件来统⼀调度所有分布式节点的执⾏逻辑, 这些被调度的节点则称为"参与者", 协调者负责调度参与者的⾏为, 并最终决定这些参与者是否要把事务真正进⾏提交.
TM就是"协调者", RM就是"参与者"
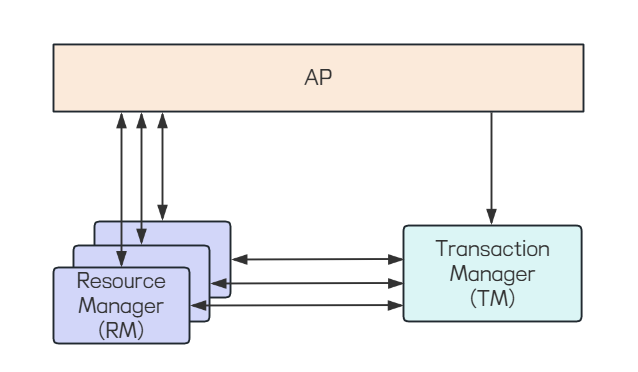
上图简单介绍
1. 应⽤程序(AP) 通过资源管理器操作多个资源.
2. 应⽤程序通过TM提供的接⼝, 定义事务边界
3. TM和RM交换事务信息(执⾏成功或失败).
TM和RM之间的事务控制, 是基于XA协议来完成的, 并且提出了分布式事务的规范⸺XA协议, 该协议主要定义了 (全局 ) 事务管理器和 (局部 ) 资源管理器之间的接⼝
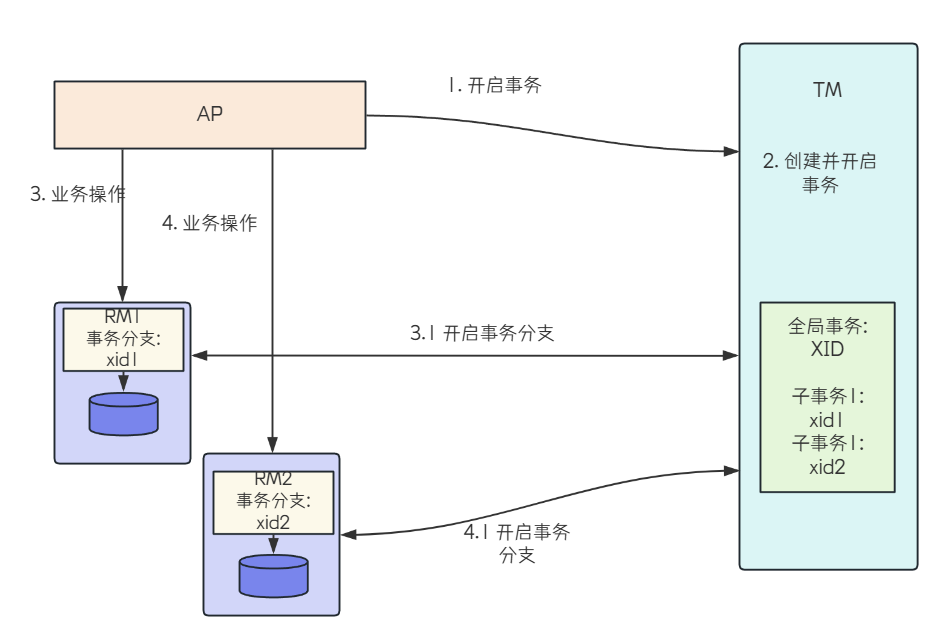
X/Open DTP模型的执⾏流程:
1. 配置TM, 把多个RM注册到TM
2. AP从TM管理的RM中获取连接, ⽐如JDBC连接
3. AP向TM发起⼀个全局事务, ⽣成全局事务ID(XID), XID会通知各个RM
4. AP通过第⼆步获得的连接直接操作RM完成数据操作. AP在每次操作时会把XID传递给RM
5. AP结束全局事务, TM会通知各个RM全局事务结束. 根据各个RM的事务执⾏结果, 执⾏提交或者回滚操作
参考下图:
两阶段提交
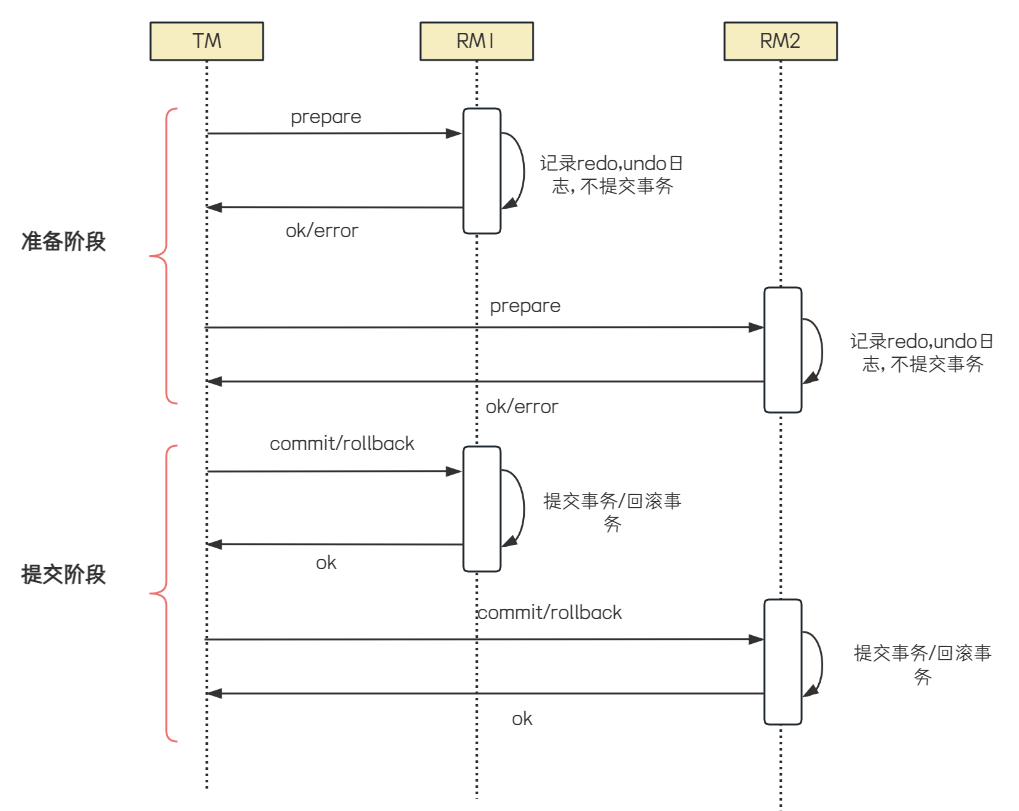
X/Open DTP 标准提出了使⽤两阶段提交(2PC, Two-Phase-Commit) 来保证分布式事务的完整性,在上图中也有体现. TM对多个RM事务的管理, 就会涉及两个阶段的提交. 第⼀个阶段是事务的准备阶段,第⼆个是事务的提交或者回滚阶段.
1. 准备阶段 (Prepare Phase )
◦ 协调者发送准备请求: 协调者向所有参与者发送 prepare 请求, 询问它们是否准备好提交事务.这个请求包含了事务的详细信息, 要求参与者对事务进⾏预处理, 并准备好回滚或提交事务所需的所有资源.
◦ 参与者响应准备请求: 参与者在收到 prepare 请求后, 会执⾏事务操作, 但不提交. 如果参与者成功执⾏了事务操作, 它会将事务的执⾏结果和准备状态记录在本地⽇志中, 并向协调者发送ready 消息, 表⽰已经准备好提交事务 .如果执⾏失败或⽆法准备, 则向协调者发送 abort 消息.
2. 提交阶段 (Commit Phase )
◦ 协调者根据准备阶段的反馈进⾏决策:协调者收到所有参与者的响应后, 会根据反馈结果做出决策. 如果所有参与者都返回 ready , 则协调者决定提交事务. 如果有任何⼀个参与者返回abort , 则协调者决定回滚事务.
◦ 协调者发送提交或回滚请求:
▪ 提交事务:如果协调者决定提交事务, 它会向所有参与者发送 commit 请求. 参与者在收到commit 请求后, 会正式提交事务, 并释放所有资源, 然后向协调者发送 ack 消息, 表⽰事务
已成功提交.
▪ 回滚事务:如果协调者决定回滚事务, 它会向所有参与者发送 rollback 请求. 参与者在收到 rollback 请求后, 会回滚事务, 并释放所有资源, 然后向协调者发送 ack 消息, 表⽰事务已成功回滚.
两阶段提交把⼀个事务的处理过程分为准备和提交/回滚两个阶段, 采⽤简单的⽅式来解决分布式事务的问题, 但是这个过程中, 存在以下缺点:
1. 阻塞问题: 两个阶段都是事务阻塞型的, 对于每⼀个指令都需要有明确的响应, 如果在这个过程中,TM宕机或者⽹络出现故障, 则会⼀直处于阻塞状态. ⽐如第⼀阶段完成后TM宕机或⽹络出现故障了,此时RM会⼀直阻塞, ⽆法进⾏其他操作. 所以3PC针对此问题, 加⼊了timeout机制.
2. 资源占⽤: 参与者在收到准备请求后, 会锁定相关资源以保证事务的原⼦性. 在整个两阶段提交过程中, 这些资源⼀直被锁定, 直到事务提交或回滚完成. 这会导致资源利⽤率降低, 其他事务可能因⽆法获取所需资源⽽等待.
3. 数据不⼀致: 第⼆阶段中, TM向所有的RM发送commit请求, 由于局部⽹络异常, 导致只有⼀部分RM收到了commit请求, 这些RM节点执⾏commit操作, 没有收到commit请求的节点由于事务⽆法提交, 出现数据不⼀致的情况
相应也存在以下优点
• 保证事务的原⼦性:2PC通过两个阶段的严格控制, 确保了事务要么全部提交, 要么全部回滚, 从⽽保证了事务的原⼦性.
• 实现相对简单:相⽐于其他分布式事务协议, 2PC的实现相对简单, 易于理解和实现.
三阶段提交
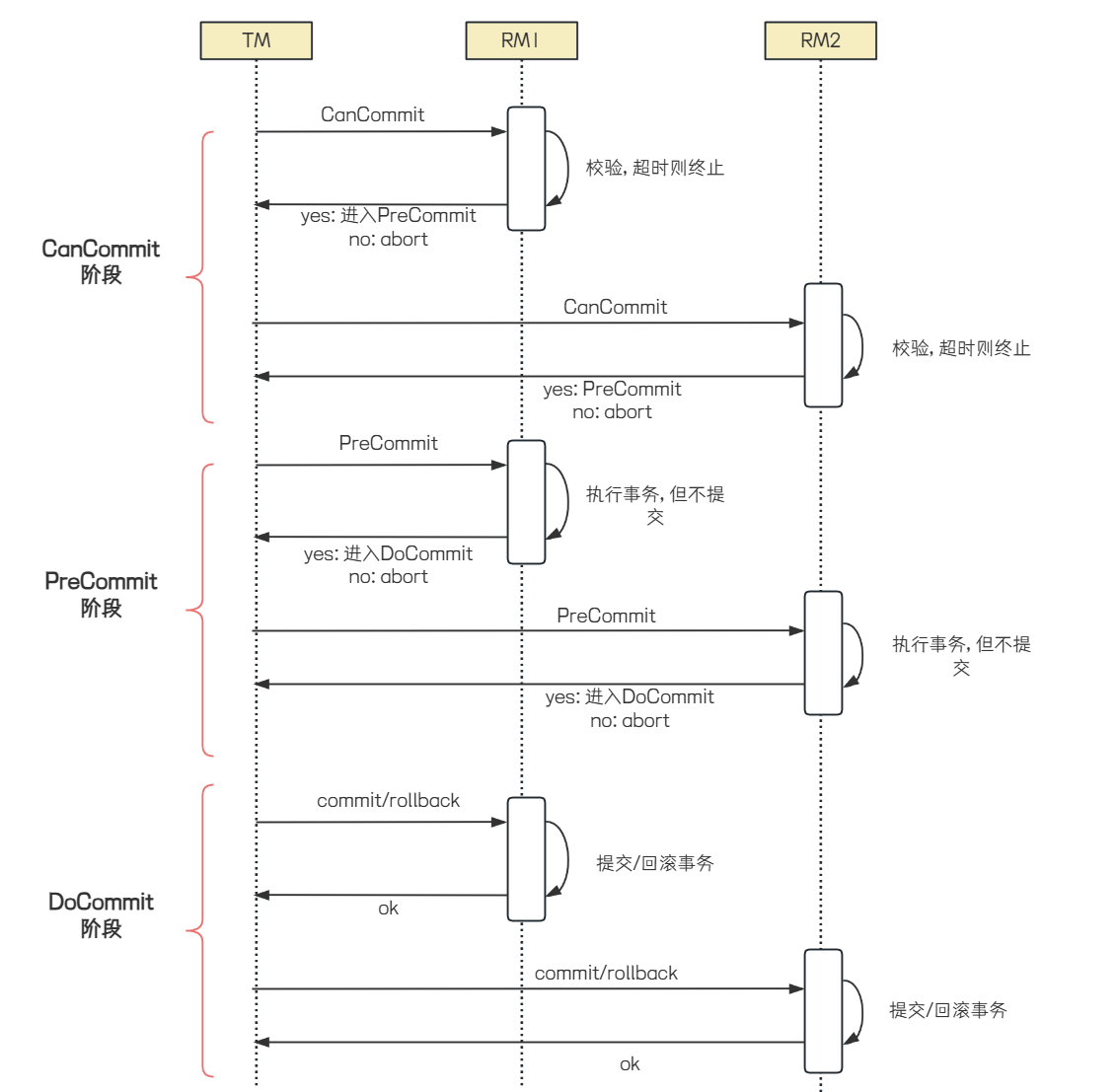
3PC(Three-Phase-Commit), 是2PC的改进版本, 共分为 CanCommit , PreCommit 和 DoCommit三个阶段.
1. CanCommit阶段
◦ 协调者发起请求: 协调者向所有参与者发送 CanCommit 请求, 询问它们是否可以执⾏事务提交操作. 此阶段不涉及实际的数据修改, 只是确认每个参与者是否有⾜够的资源和条件来完成事务.
◦ 参与者响应: 参与者根据⾃⾝情况返回Yes或No. 如果所有参与者都返回Yes, 则进⼊PreCommit阶段.
2. PreCommit阶段
◦ 协调者发送PreCommit请求: 协调者向所有参与者发送 PreCommit 请求, 询问是否可以进⾏事务的预提交操作.
◦ 参与者准备事务: 参与者执⾏事务操作, 并将事务执⾏结果和准备状态 (Yes/No ) 发送给协调者.参与者会记录预提交⽇志, 并确保这些⽇志是持久化的.
◦ 协调者收集反馈并决策: 如果所有参与者都返回Yes, 则进⼊DoCommit阶段. 如果有任何⼀个参与者返回No或超时未响应, 协调者会发送 abort 请求, 通知所有参与者回滚事务.
3. DoCommit阶段
◦ 协调者发送DoCommit请求: 协调者向所有参与者发送 DoCommit 请求, 指⽰它们正式提交事
务.
◦ 参与者执⾏提交: 参与者收到 DoCommit 请求后, 执⾏事务提交操作, 并向协调者发送 Ack 消
息, 表⽰事务已提交.
◦ 超时机制: 如果参与者在等待 DoCommit 请求时超时, 会默认执⾏提交操作.
优点
• 减少阻塞: 3PC通过引⼊超时机制, 减少了2PC中的阻塞问题. 避免了资源被永久锁定.
• 增强容错能⼒: 即使协调者在DoCommit阶段之前出现故障, 参与者也可以基于其预提交的状态⾃主决定继续提交或回滚事务, 从⽽减少了对协调者的依赖.
缺点
• 实现复杂度⾼:3PC的实现⽐2PC更复杂, 增加了系统的开发和维护成本.
• 数据不⼀致⻛险:在某些情况下, 如⽹络分区, 参与者在收到 PreCommit 消息后, 如果⽹络出现故障, 协调者和参与者⽆法进⾏后续通信, 参与者在超时后可能会⾃⾏提交事务, 导致数据不⼀致.
TCC事务
TCC (Try-Confirm-Cancel ) 是⼀种分布式事务解决⽅案, 是由Pat Helland在2007年发表的论⽂《Life beyond Distributed Transactions: An Apostate’s Opinion》中提出. TCC事务相对于传统两阶段, 其特征在于它不依赖资源管理器(RM)对XA的⽀持, ⽽是通过对 (由业务系统提供的 ) 业务逻辑的接⼝调⽤来实现分布式事务.
TCC 通过将事务操作拆分为三个阶段:
1. Try阶段:尝试执⾏业务操作, 完成所有业务检查, 并预留必要的业务资源. 这个阶段不真正执⾏事务, 只是进⾏资源的预占.
2. Confirm阶段: 如果所有参与者在Try阶段都成功, 那么进⼊Confirm阶段, 正式完成操作, 使⽤之前预留的资源.
3. Cancel阶段:如果任何⼀个参与者在Try阶段失败, 那么进⼊Cancel阶段, 所有参与者回滚在Try阶段执⾏的操作, 释放预留的资源.
TCC事务属于两阶段提交思想的变体, 它在设计上借鉴了两阶段提交的核⼼理念, 第⼀阶段通过Try进⾏准备⼯作, 第⼆阶段Confirm/Cancel表⽰Try阶段操作的确认和回滚.
在主业务⽅法中, 会先调⽤业务服务对外提供的 Try ⽅法来做资源预留, 如果业务服务 Try ⽅法处理
都正常, TCC事务协调器就会调⽤ Confirm ⽅法对预留资源进⾏实际应⽤. 否则就会调⽤各个服务的Cancel ⽅法进⾏回滚, 从⽽保证数据的⼀致性.
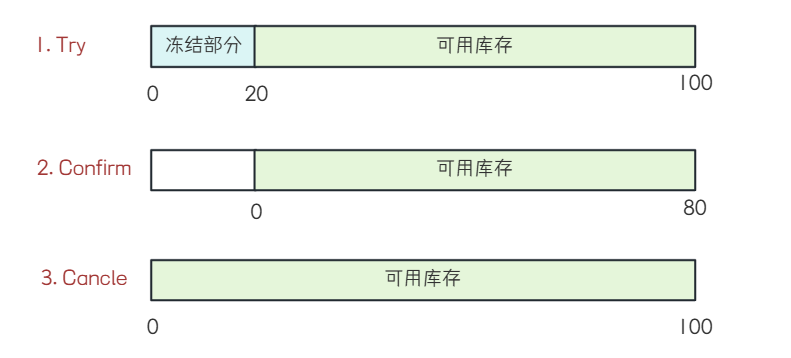
⽐如"库存扣减""操作, 当前商品库存数量为100, 本次购买20个
Try阶段: 对库存数量进⾏冻结.
Confirm阶段: 把Try阶段冻结的库存数量进⾏实际的扣减
Cancle阶段: 把Try阶段冻结的库存数量进⾏解冻.
优点
• ⽆需依赖第三⽅中间件或数据库来实现分布式事务, 降低了系统复杂度和成本
• ⽆需锁定全局资源, 提⾼了系统的并发性能和可⽤性
• 适⽤于各种类型的业务场景, 只要能够定义出清晰的Try、Confirm和Cancel逻辑
缺点:
• 需要开发⼈员⼿动编写三个阶段的业务逻辑, 并保证其正确性和⼀致性, 增加了开发难度和维护成本
• 需要考虑各种异常情况和边界情况, 并提供相应的补偿策略和重试机制, 增加了系统复杂度和⻛险
5. 初识Seata
了解了常⻅分布式事务问题的理论模型之后, 我们再来学习seata是如何解决分布式事务问题的.
Seata术语介绍
• TC (Transaction Coordinator) - 事务协调者
维护全局和分⽀事务的状态, 驱动全局事务提交或回滚.
• TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务.
• RM (Resource Manager) - 资源管理器
管理分⽀事务处理的资源, 与TC交谈以注册分⽀事务和报告分⽀事务的状态, 并驱动分⽀事务提交或回滚
Seata下载和部署
1. Seata下载&解压
下载地址: Seata Java Download | Apache Seata
下载完成之后, 进⾏解压, ⽬录结构如下:

• seata-namingserver: Seata 原⽣的注册中⼼
操作可参考 Seata Namingserver 注册中⼼ | Apache Seata
• seata-server : Seata 的事务协调服务端, 负责全局事务的协调和管理
bin: 运⾏脚本
• seata-server.sh: Linux系统下启动Seata服务的脚本. 通过执⾏该脚本并传⼊相应参数, 即可启动Seata服务. 如 sh ./bin/seata-server.sh -m nio -p 8091
• seata-server.bat:Windows系统下启动Seata服务的脚本. 双击即可启动Seata服务.
conf: 配置⽂件
• ⽤于配置Seata服务的⼀些⾼级参数,如存储模式、数据库连接信息等
lib: 依赖库
script: ⼀些脚本⽂件.⽐如与配置中⼼相关的脚本, 数据库相关的脚本, 如建表语句等.
2. 修改配置
Seata⽀持多种配置中⼼
• nacos
• consul
• apollo
• etcd
• zookeeper
• file (读本地⽂件, 包含conf、properties、yml配置⽂件的⽀持)
配置中⼼可以说是⼀个"⼤货仓",内部放置着各种配置⽂件,你可以通过⾃⼰所需进⾏获取配置加载到对应的客⼾端.⽐如Seata Client端(TM,RM),Seata Server(TC),会去读取全局事务开关,事务会话存储模式等信息.
此处我们使⽤Nacos来作为Seata的配置中⼼, 参考: Nacos 配置中⼼ | Apache Seata
修改 /seata-server/conf/application.yml 中seata相关的配置
配置内容参考: /seata-server/conf/application.example.yml
server:
port: 7091
spring:
application:
name: seata-server
logging:
config: classpath:logback-spring.xml
file:
path: ${log.home:${user.home}/logs/seata}
extend:
logstash-appender:
destination: 127.0.0.1:4560
kafka-appender:
bootstrap-servers: 127.0.0.1:9092
topic: logback_to_logstash
console:
user:
username: seata
password: seata
seata:
config:
# support: nacos, consul, apollo, zk, etcd3
type: nacos
nacos:
server-addr: 152.136.172.144:10020
namespace:
group: SEATA_GROUP
registry:
# support: nacos, eureka, redis, zk, consul, etcd3, sofa
type: nacos
nacos:
application: seata-server
server-addr: 152.136.172.144:10020
group: SEATA_GROUP
store:
# support: file 、 db 、 redis 、 raft
mode: db
db:
datasource: druid
db-type: mysql
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/seata?rewriteBatchedStatements=true
user: root
password: "123456"
min-conn: 10
max-conn: 100
global-table: global_table
branch-table: branch_table
lock-table: lock_table
distributed-lock-table: distributed_lock
vgroup-table: vgroup_table
query-limit: 1000
max-wait: 5000
# server:
# service-port: 8091 #If not configured, the default is '${server.port} + 1000'
security:
secretKey: SeataSecretKey0c382ef121d778043159209298fd40bf3850a017
tokenValidityInMilliseconds: 1800000
csrf-ignore-urls: /metadata/v1/**
ignore:
urls: /,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.jpeg,/**/*.ico,/api/v1/auth/login,/version.json,/health,/error,/vgroup/v1/**3. 修改Seata存储模式
Server端存储模式(store.mode) ⽀持file, db, redis, raft
• file模式为单机模式, 全局事务会话信息内存中读写并异步(默认)持久化本地⽂件root.data, 性能较⾼;
• db模式为⾼可⽤模式, 全局事务会话信息通过db共享, 相应性能差些.
如果使⽤file模式, ⽆需改动, 直接启动即可, 本课程讲解使⽤DB的启动步骤.
3.1 初始化数据库
全局事务会话信息由3块内容构成, 全局事务-->分⽀事务-->全局锁,对应表global_table、branch_table、lock_table.
创建数据库seata
CREATE DATABASE IF NOT EXISTS seata;建表语句在: /seata-server/script/server/db/mysql.sql
3.2 修改store.mode
修改 /seata-server/conf/application.yml 中 store.mode 相关的配置
配置内容参考: /seata-server/conf/application.example.yml ,将其db相关配置复制⾄application.yml,进⾏修改store.db相关属性
4. 启动Seata
4.1 Windows
双击 /seata-server/bin/seata-server.bat
访问 http://127.0.0.1:7091/, ⽤⼾名密码: seata/seata
在Nacos的服务列表中, 也可以观察到seata服务
启动成功后, seata-server就已经注册到nacos注册中⼼了
4.2 Linux
执⾏ /bin/seata-server.sh 并传⼊相应参数即可.
解压⽂件到seata⽬录
tar zxvf apache-seata-2.2.0-incubating-bin.tar.gz -C ../seata
启动seata, 端⼝号为8091
bash ./bin/seata-server.sh -h XX.XX.XX.XX -p 8091
停⽌服务
bash ./bin/seata-server.sh stop开通端⼝号7091, 8091
• 7091:⽤于客⼾端与 Seata Server 的 TCP 通信
• 8091:Seata Server的默认服务端端⼝, ⽤于接收客⼾端的事务请求并进⾏事务管理
访问 http://XX.XX.XX.XX:7091/
观察Nacos服务列表, seata-server就已经注册到nacos注册中⼼了
观察seata-server 的IP地址, 确保为公⽹IP(⾮公⽹IP时, 本地服务器连接时会出问题)
微服务集成Seata
引⼊依赖
在需要的微服务中引⼊seata依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>修改配置⽂件
修改application.yml, 添加seata相关配置 根据配置信息确定TC服务地址信息
seata:
registry: #定义了Seata Server的注册中⼼配置, 微服务根据配置信息去注册中⼼获取tc服务地址
type: nacos #指定注册中⼼的类型
nacos:
application: seata-server #Seata Server在Nacos中的应⽤名称
server-addr: 152.136.172.144:10020 #Nacos服务器地址
group : "SEATA_GROUP" #Seata Server在Nacos中的分组名称
namespace: "" #Nacos的命名空间, 设置为空, 表⽰使⽤默认的命名空间public
tx-service-group: default_tx_group #定义事务服务组的名称
service:
vgroup-mapping:
default_tx_group: default配置讲解
• seata.tx-service-group : 定义了事务服务组的名称, 这⾥设置为default_tx_group . 事务服务组⽤于将Seata Server和Seata Client进⾏分组管理, 确保它们能够正确地发现和通信.
• seata.service.vgroup-mapping.事务分组名 : 定义了Seata Server的服务配置, 事务服务组到Seata Server集群的映射关系, 这⾥将 default_tx_group 映射到 default 集群
• default : Seata Server的集群名称
事务分组介绍参考: 事务分组介绍 | Apache Seata
以上述配置举例:
微服务启动时, 会根据 default_tx_group 查找Seata Server. Seata Server在启动时会注册到Nacos的 SEATA_GROUP 分组中, 应⽤名称为 seata-server , 并映射到 default 集群. 这样,Seata Client可以通过Nacos发现并连接到Seata Server, 进⾏事务协调和管理
6. Seata各事务模式
Seata是⼀款开源的分布式事务解决⽅案, 致⼒于在微服务架构下提供⾼性能和简单易⽤的分布式事务服务. 它提供了多种事务模式, 为开发者提供了⼀站式的分布式事务解决⽅案.
• AT模式
• TCC模式
• Saga模式
• XA模式
XA模式
模式介绍
XA 模式是从 1.2 版本⽀持的事务模式. XA 规范 是 X/Open 组织定义的分布式事务处理标准. Seata XA 模式是利⽤事务资源 (数据库、消息服务等 ) 对 XA 协议的⽀持, 以 XA 协议的机制来管理分⽀事务的⼀种事务模式.
XA实现的原理是基于两阶段提交.
Seata 对原始的XA模式做了简单的封装和改造, 以适应⾃⼰的事务模型, 在 Seata 定义的分布式事务框架内, 利⽤事务资源 (数据库、消息服务等 ) 对 XA 协议的⽀持, 以 XA 协议的机制来管理分⽀事务的⼀种 事务模式.
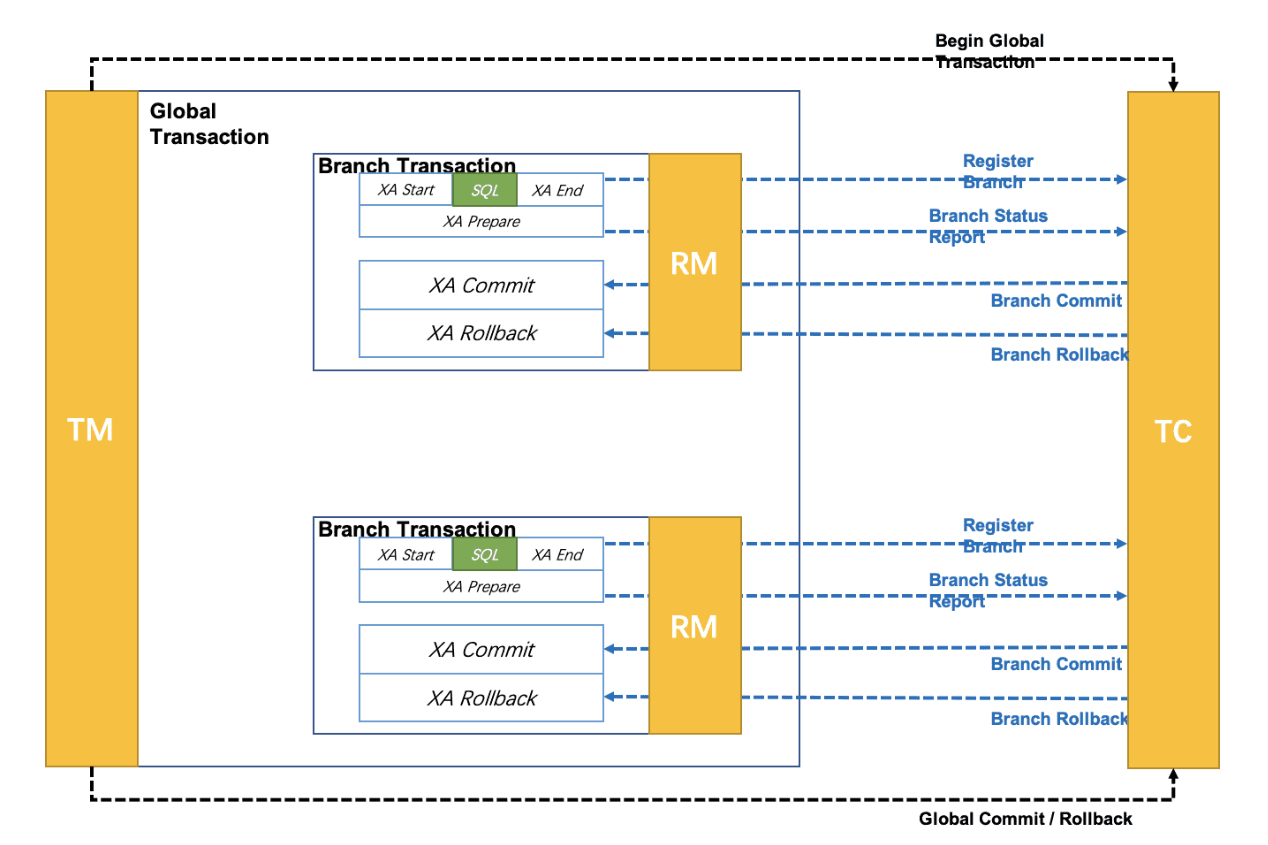
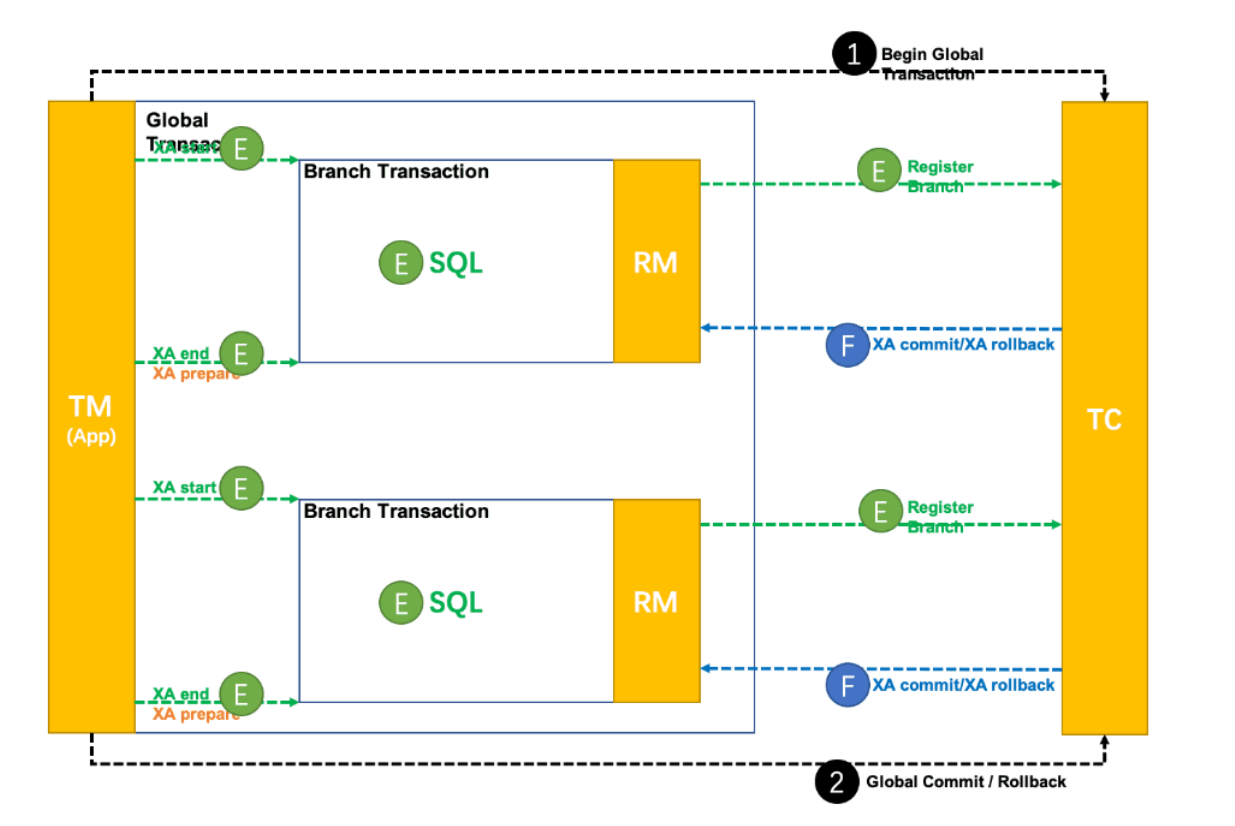
整体机制:
1. 开启事务: 事务管理器 (TM ) 开启⼀个全局事务, 并与事务协调器 (TC ) 建⽴连接, TC返回⼀个全局事务ID (XID ) 给TM
2. 分⽀事务注册与执⾏:资源管理器 (RM ) 收到业务操作请求后, 会向TC注册分⽀事务, 执⾏业务SQL, 并携带XID以保证事务的⼀致性.
• 分⽀事务状态报告:RM执⾏完分⽀事务后, 向TC报告分⽀事务的执⾏状态.
• 事务提交或回滚决策:TM在所有分⽀事务执⾏完毕后, 会通知TC事务结束. TC接收到事务结束通知后, 会检查各分⽀事务的执⾏状态. 如果所有分⽀事务都成功, 则TC通知所有RM提交事务. 如果有任意⼀个分⽀事务失败, 则TC通知所有RM回滚事务.
• 分⽀事务提交或回滚:RM接收到TC的提交或回滚指令后, 执⾏相应的commit或rollback操作.
配置与使⽤
Seata XA 模式使⽤⾮常简单.
1. 在application.yml中配置seata的事务模式.

2. 给发起全局事务的⼊⼝⽅法添加 @GlobalTransactional 注解
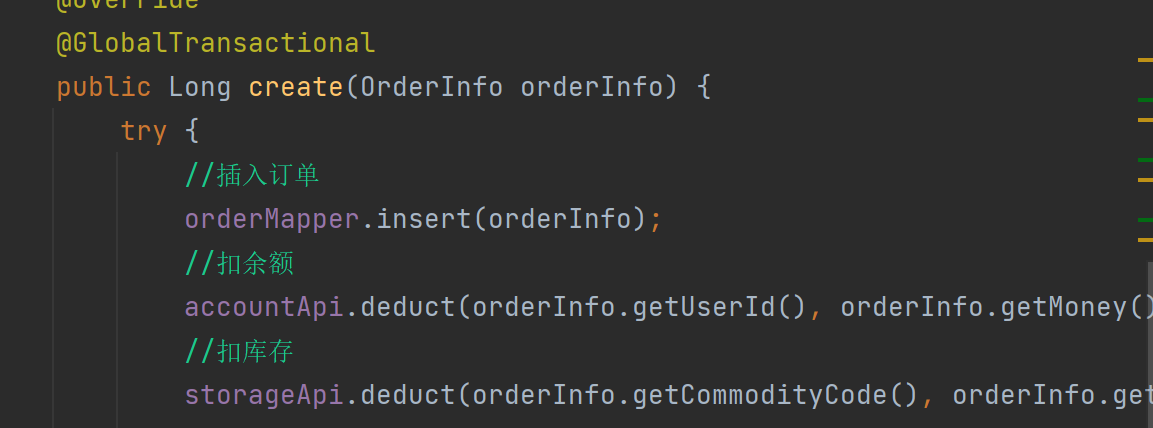
3. 重启服务, 并测试
测试余额不⾜时, 接⼝发⽣错误, 发现事务全部回滚了, 库存服务会有⼀些简单的⽇志
优缺点
优点
◦ 事务强⼀致性:XA模式能够满⾜ACID原则, 确保分布式事务的强⼀致性.
◦ 实现简单且⽆代码侵⼊: 常⽤数据库都⽀持XA协议, 使⽤Seata的XA模式⽆需修改业务代码, 只需进⾏简单的配置即可.
缺点
◦ 性能较差:⼀阶段需要锁定数据库资源, 等待⼆阶段结束才释放, 导致事务资源⻓时间得不到释放, 锁定周期⻓, 从⽽影响性能
◦ 依赖关系型数据库: XA模式依赖数据库实现事务, 对于⼀些⾮关系型数据库或不⽀持XA协议的数据库, ⽆法使⽤.
AT 模式
模式介绍
AT 模式是 Seata 创新的⼀种⾮侵⼊式的分布式事务解决⽅案. Seata 在内部做了对数据库操作的代理层, 我们使⽤ Seata AT 模式时, 实际上⽤的是 Seata ⾃带的数据源代理 DataSourceProxy, Seata 在这层代理中加⼊了很多逻辑, ⽐如插⼊回滚 undo_log ⽇志, 检查全局锁等.
Seata AT模式针对两阶段提交协议的演变:
• ⼀阶段:业务数据和回滚⽇志记录在同⼀个本地事务中提交, 释放本地锁和连接资源.
• ⼆阶段:
◦ 提交异步化, ⾮常快速地完成.
◦ 回滚通过⼀阶段的回滚⽇志进⾏反向补偿.
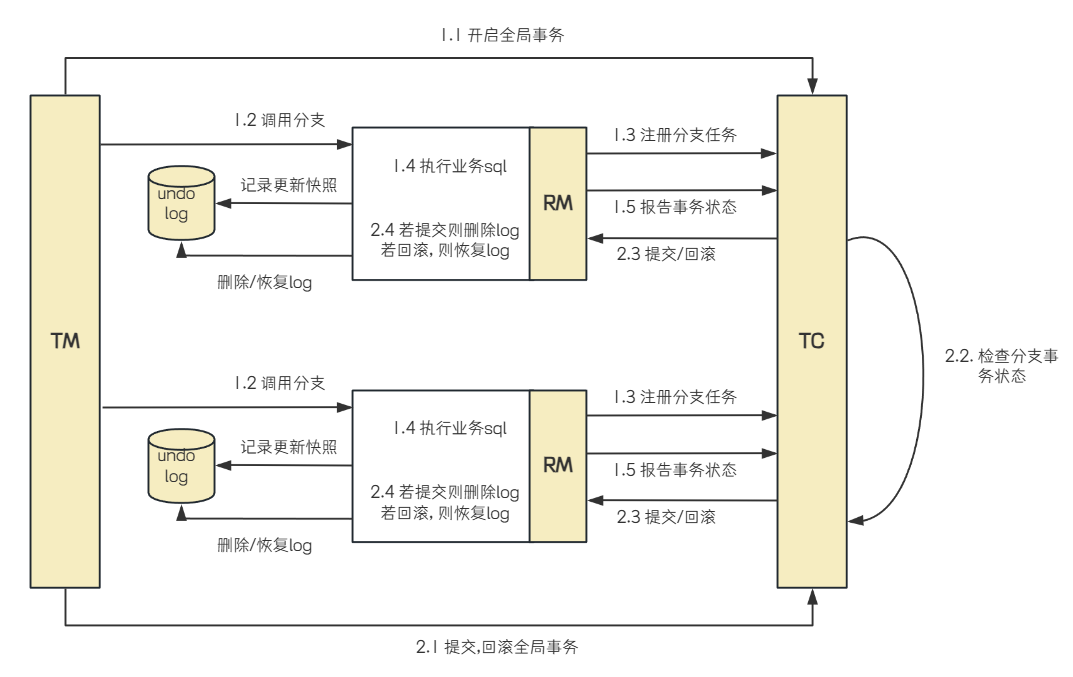
整体机制
• ⼀阶段:
◦ 注册分⽀事务:TM注册全局事务, 资源管理器 (RM ) 向事务协调器 (TC ) 注册分⽀事务
◦ 记录undo_log:RM在执⾏业务SQL操作前, 会先解析SQL语句, 记录SQL更新前的快照和更新后的快照到undo_log⽇志表中. undo_log记录了⾜够的信息, 以便在需要回滚时能够恢复数据.
◦ 执⾏SQL并提交本地事务:RM执⾏业务SQL操作, 并直接提交本地事务, 此时数据会真实地提交到数据库中.
◦ 报告事务状态:RM向TC报告分⽀事务的执⾏状态, 告知其本地事务已提交.
• ⼆阶段:
◦ 提交成功:如果所有分⽀事务都成功, TC会通知RM清理undo_log相关的补偿信息, 完成整个分布式事务的处理.
◦ 提交失败:如果有任意⼀个分⽀事务失败, TC会通知RM进⾏回滚. RM根据undo_log中的补偿信息对数据进⾏反向补偿, 从⽽实现事务的回滚.
读写隔离
写隔离
在多线程并发操作同⼀个数据时, 有可能会出现脏写问题, 如图:
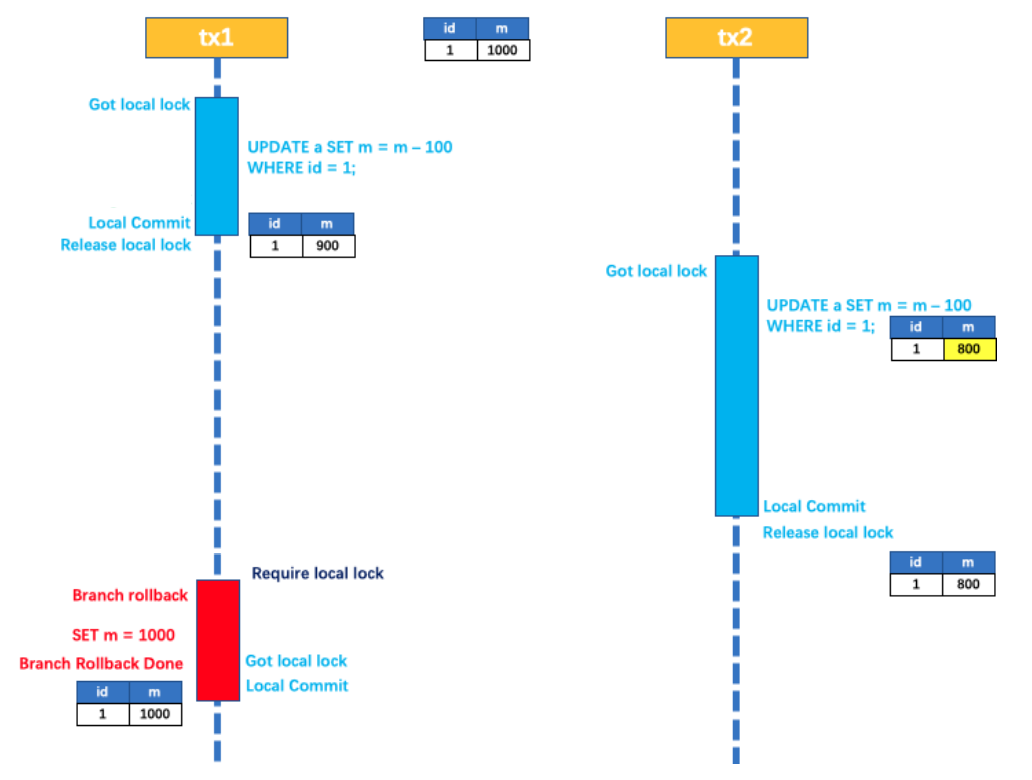
问题: 此时数据库的数据为1000, 那么久丢失了⼀次更新, 出现脏写了.
Seata的AT模式解决思路就是引⼊全局锁的概念, 在释放本地锁之前, 先拿到全局锁, 避免同⼀时刻有另外⼀个事务来操作当前数据.
• ⼀阶段本地事务提交前, 需要确保先拿到 全局锁 .
• 拿不到 全局锁 , 不能提交本地事务.
• 拿 全局锁 的尝试被限制在⼀定范围内, 超出范围将放弃, 并回滚本地事务, 释放本地锁.
以⼀个⽰例来说明:
两个全局事务 tx1 和 tx2, 分别对 a 表的 m 字段进⾏更新操作, m 的初始值 1000.
tx1 先开始, 开启本地事务, 拿到本地锁, 更新操作 m = 1000 - 100 = 900. 本地事务提交前, 先拿到该记录的 全局锁 , 本地提交释放本地锁. tx2 后开始, 开启本地事务, 拿到本地锁, 更新操作 m = 900 - 100 = 800. 本地事务提交前, 尝试拿该记录的 全局锁, tx1 全局提交前, 该记录的全局锁被 tx1 持有, tx2 需要重试等待 全局锁 .
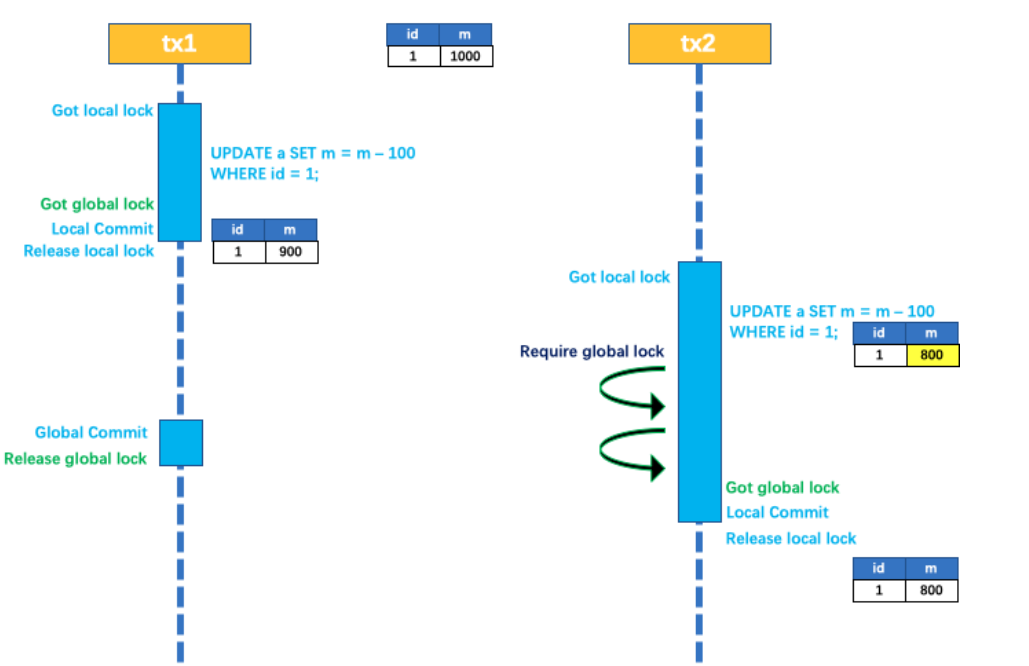
tx1 ⼆阶段全局提交, 释放 全局锁. tx2 拿到 全局锁 提交本地事务
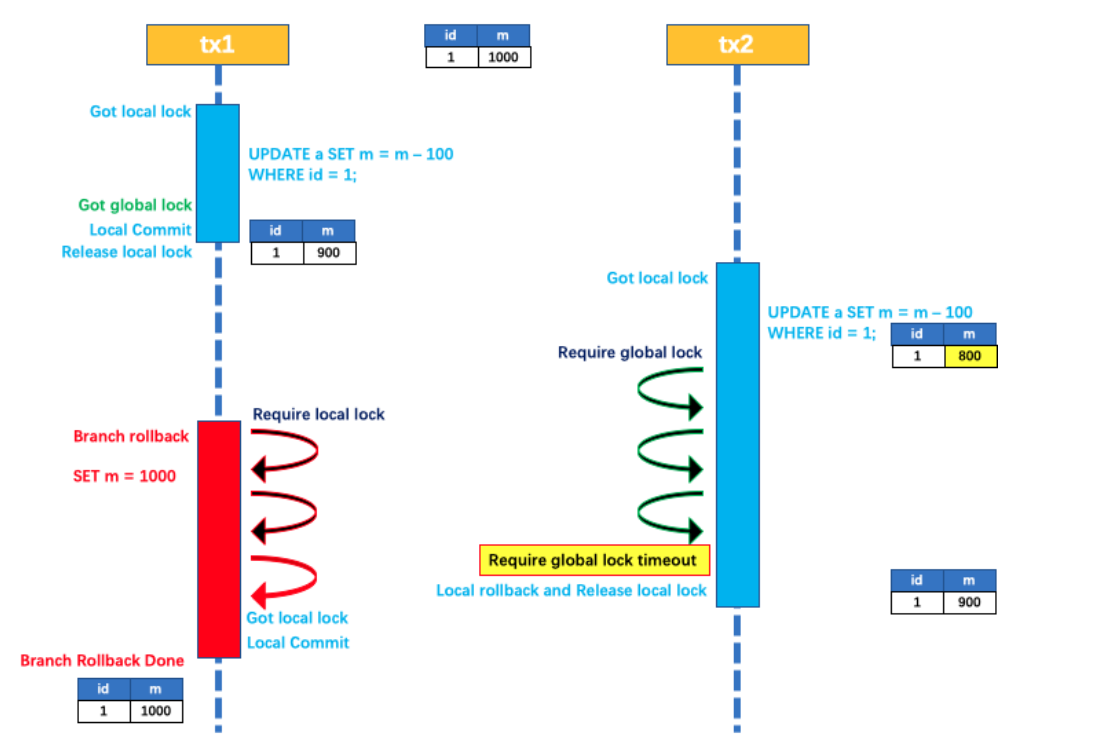
如果 tx1 的⼆阶段全局回滚, 则 tx1 需要重新获取该数据的本地锁, 进⾏反向补偿的更新操作, 实现分⽀的回滚.
此时, 如果 tx2 仍在等待该数据的 全局锁, 同时持有本地锁, 则 tx1 的分⽀回滚会失败. 分⽀的回滚会⼀直重试, 直到 tx2 的 全局锁 等锁超时, 放弃 全局锁 并回滚本地事务释放本地锁, tx1 的分⽀回滚最终成功.
因为整个过程 全局锁 在 tx1 结束前⼀直是被 tx1 持有的, 所以不会发⽣ 脏写 的问题.
读隔离
在数据库本地事务隔离级别 读已提交 (Read Committed ) 或以上的基础上, Seata (AT 模式 ) 的默认全局隔离级别是 读未提交 (Read Uncommitted ) .
如果应⽤在特定场景下, 必需要求全局的 读已提交 , ⽬前 Seata 的⽅式是通过 SELECT FOR UPDATE 语句的代理.
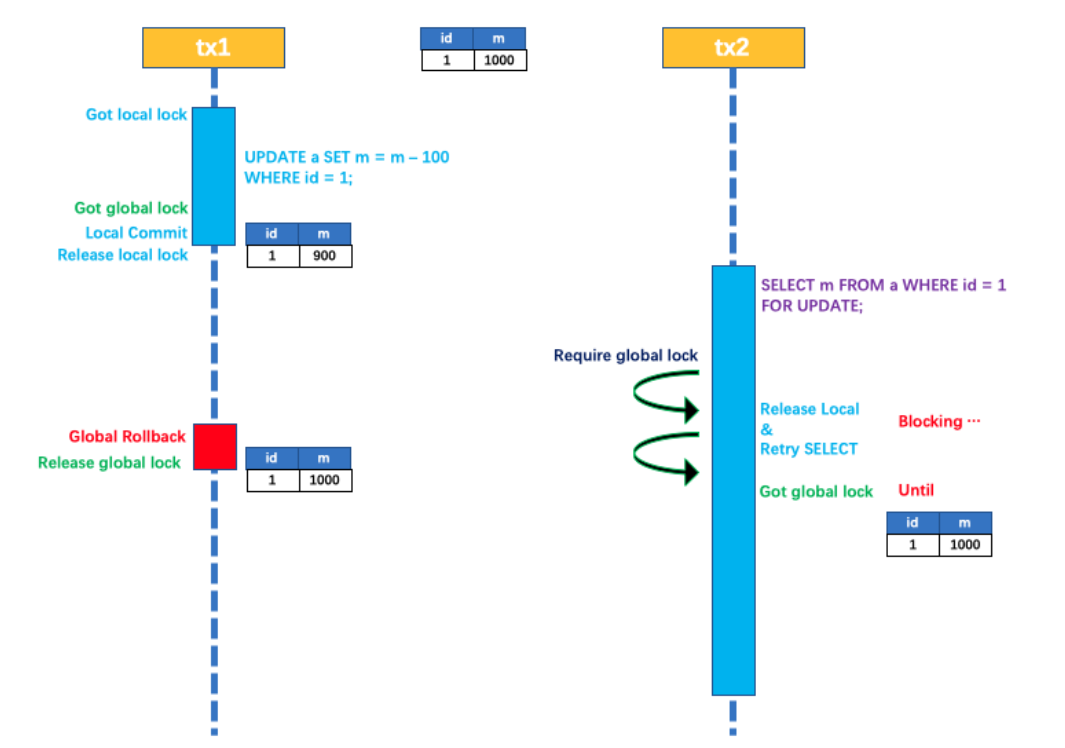
SELECT FOR UPDATE 语句的执⾏会申请 全局锁 , 如果 全局锁 被其他事务持有, 则释放本地锁 (回滚 SELECT FOR UPDATE 语句的本地执⾏ ) 并重试. 这个过程中, 查询是被 block 住的, 直到 全局锁 拿到, 即读取的相关数据是 已提交 的, 才返回.
出于总体性能上的考虑, Seata ⽬前的⽅案并没有对所有 SELECT 语句都进⾏代理, 仅针对 FOR UPDATE 的 SELECT 语句.
⼯作机制
以⼀个⽰例来说明整个 AT 分⽀的⼯作过程. 业务表: product
| Field | Type | Key |
| id | bigint(20) | PRI |
| name | varchar(100) | |
| since | varchar(100) |
AT 分⽀事务的业务逻辑:
update product set name = 'GTS' where name = 'TXC';⼀阶段
过程:
1. 解析 SQL:得到 SQL 的类型 (UPDATE ) , 表 (product ) , 条件 (where name = 'TXC' ) 等相关的信息.
2. 查询前镜像:根据解析得到的条件信息, ⽣成查询语句, 定位数据.
select id, name, since from product where name = 'TXC';得到前镜像:
| id | name | since |
| 1 | TXC | 2014 |
3. 执⾏业务 SQL:更新这条记录的 name 为 'GTS'.
4. 查询后镜像:根据前镜像的结果, 通过 主键 定位数据.
select id, name, since from product where id = 1;得到后镜像:
| id | name | since |
| 1 | GTS | 2014 |
5. 插⼊回滚⽇志:把前后镜像数据以及业务 SQL 相关的信息组成⼀条回滚⽇志记录, 插⼊到 UNDO_LOG 表中.
6. 申请 product 表中, 主键值等于 1 的记录的 全局锁 .
7. 本地事务提交:业务数据的更新和前⾯步骤中⽣成的 UNDO LOG ⼀并提交.
8. 将本地事务提交的结果上报给 TC
⼆阶段-回滚
1. 收到 TC 的分⽀回滚请求, 开启⼀个本地事务, 执⾏如下操作.
2. 通过 XID 和 Branch ID 查找到相应的 UNDO LOG 记录.
3. 数据校验:拿 UNDO LOG 中的后镜与当前数据进⾏⽐较, 如果有不同, 说明数据被当前全局事务之外的动作做了修改. 这种情况, 需要根据配置策略来做处理, 详细的说明在另外的⽂档中介绍.
4. 根据 UNDO LOG 中的前镜像和业务 SQL 的相关信息⽣成并执⾏回滚的语句:
update product set name = 'TXC' where id = 1;5. 提交本地事务. 并把本地事务的执⾏结果 (即分⽀事务回滚的结果 ) 上报给 TC.
⼆阶段-提交
1. 收到 TC 的分⽀提交请求, 把请求放⼊⼀个异步任务的队列中, ⻢上返回提交成功的结果给 TC.
2. 异步任务阶段的分⽀提交请求将异步和批量地删除相应 UNDO LOG 记录.
配置与使⽤
1. 在微服务关联的数据库创建undo_log 表, 建表SQL参考 快速启动 | Apache Seata
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;2. 配置事务模式为AT

3. 测试, 观察⽇志
测试余额充⾜时:
order-service⽇志下, 可以观察到全局事务开启
测试余额不⾜时, 接⼝发⽣错误, 发现事务全部回滚了, 库存服务会有⼀些简单的⽇志
AT和XA的区别
| AT | XA | |
| 实现⽅式 | • 通过记录数据快照 ( undo_log 表 ) 来实现数据的回滚 • 适⽤于⼏乎所有的数据库, 但需要在业务库中创建 undo_log 表. | • 依赖数据库对XA协议的⽀持, 通过XA规范来实现事务的提交和回滚. • 不需要额外的 undo_log 表, 但要求数据库⽀持XA协议 |
| ⼀致性 | 最终⼀致性 在事务的两阶段之间, 数据可能处于中间状态 | 强⼀致性 事务的中间状态对⽤⼾不可⻅ |
| 性能 | 性能较好, ⼀阶段直接提交, 不锁定资源 | 性能较差, ⼀阶段锁定资源, 等待⼆阶段结束才释放 |
| 代码侵⼊ | ⽆代码侵⼊ | ⽆代码侵⼊ |
| 数据库⽀持 | 适⽤于⼏乎所有⽀持SQL的数据库 | 依赖数据库对XA协议的⽀持 |
总结
• 如果业务对性能要求较⾼且可以接受最终⼀致性, 推荐使⽤AT模式.
• 如果业务对数据⼀致性要求极⾼且对性能要求不⾼, 推荐使⽤XA模式, 如银⾏.
TCC模式
模式介绍
TCC 模式是 Seata ⽀持的⼀种由业务⽅细粒度控制的侵⼊式分布式事务解决⽅案, 是继 AT 模式后第⼆种⽀持的事务模式, 最早由蚂蚁⾦服贡献. 其分布式事务模型直接作⽤于服务层, 不依赖底层数据库, 可以灵活选择业务资源的锁定粒度, 减少资源锁持有时间, 可扩展性好, 可以说是为独⽴部署的 SOA 服务⽽设计的.
Seata的全局事务, 整体是 两阶段提交 的模型. 全局事务是由若⼲分⽀事务组成的, 分⽀事务要满⾜ 两阶段提交 的模型要求, 即需要每个分⽀事务都具备⾃⼰的
• ⼀阶段 prepare ⾏为
• ⼆阶段 commit 或 rollback ⾏为
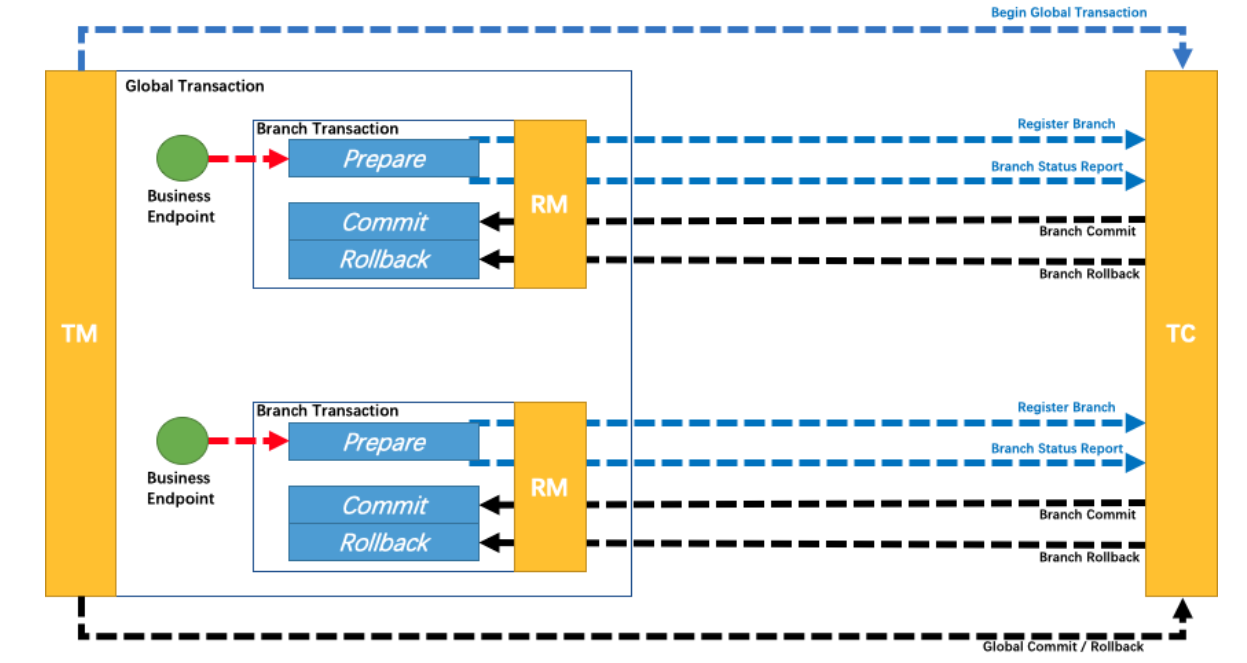
根据两阶段⾏为模式的不同, 将分⽀事务划分为 Automatic Transaction Mode 和 TCC Transaction Mode.
AT 模式和TCC模式⾮常相似, 每阶段都是独⽴事务, 不同的是TCC通过⼈⼯编码来实现数据的恢复. AT 模式基于 ⽀持本地 ACID 事务 的 关系型数据库:
• ⼀阶段 prepare ⾏为:在本地事务中, ⼀并提交业务数据更新和相应回滚⽇志记录.
• ⼆阶段 commit ⾏为:⻢上成功结束, ⾃动 异步批量清理回滚⽇志.
• ⼆阶段 rollback ⾏为:通过回滚⽇志, ⾃动 ⽣成补偿操作, 完成数据回滚.
相应的, TCC 模式, 不依赖于底层数据资源的事务⽀持:
• ⼀阶段 prepare ⾏为:调⽤ ⾃定义 的 prepare 逻辑.
• ⼆阶段 commit ⾏为:调⽤ ⾃定义 的 commit 逻辑.
• ⼆阶段 rollback ⾏为:调⽤ ⾃定义 的 rollback 逻辑.
所谓 TCC 模式, 是指⽀持把 ⾃定义 的分⽀事务纳⼊到全局事务的管理中.
在两阶段提交协议 (2PC, Two Phase Commitment Protocol ) 中, 资源管理器 (RM, resource manager ) 需要提供"准备"、"提交"和"回滚" 3 个操作. ⽽事务管理器 (TM, transaction manager ) 分 2 阶段协调所有资源管理器, 在第⼀阶段询问所有资源管理器"准备"是否成功, 如果所有资源均"准备"成功则在第⼆阶段执⾏所有资源的"提交"操作, 否则在第⼆阶段执⾏所有资源的"回滚"操作, 保证所有资源的最终状态是⼀致的, 要么全部提交要么全部回滚.
资源管理器有很多实现⽅式, 其中 TCC (Try-Confirm-Cancel ) 是资源管理器的⼀种服务化的实现. TCC 是⼀种⽐较成熟的分布式事务解决⽅案, 可⽤于解决跨数据库、跨服务业务操作的数据⼀致性问题. TCC 其 Try、Confirm、Cancel 3 个⽅法均由业务编码实现, 故 TCC 可以被称为是服务化的资源管理器.
TCC 的 Try 操作作为⼀阶段, 负责资源的检查和预留. Confirm 操作作为⼆阶段提交操作, 执⾏真正的业务. Cancel 是⼆阶段回滚操作, 执⾏预留资源的取消, 使资源回到初始状态.
如下图所⽰, ⽤⼾实现 TCC 服务之后, 该 TCC 服务将作为分布式事务的其中⼀个资源, 参与到整个分布式事务中. 事务管理器分 2 阶段协调 TCC 服务, 在第⼀阶段调⽤所有 TCC 服务的 Try ⽅法, 在第⼆阶段执⾏所有 TCC 服务的 Confirm 或者 Cancel ⽅法. 最终所有 TCC 服务要么全部都是提交的, 要么全部都是回滚的.
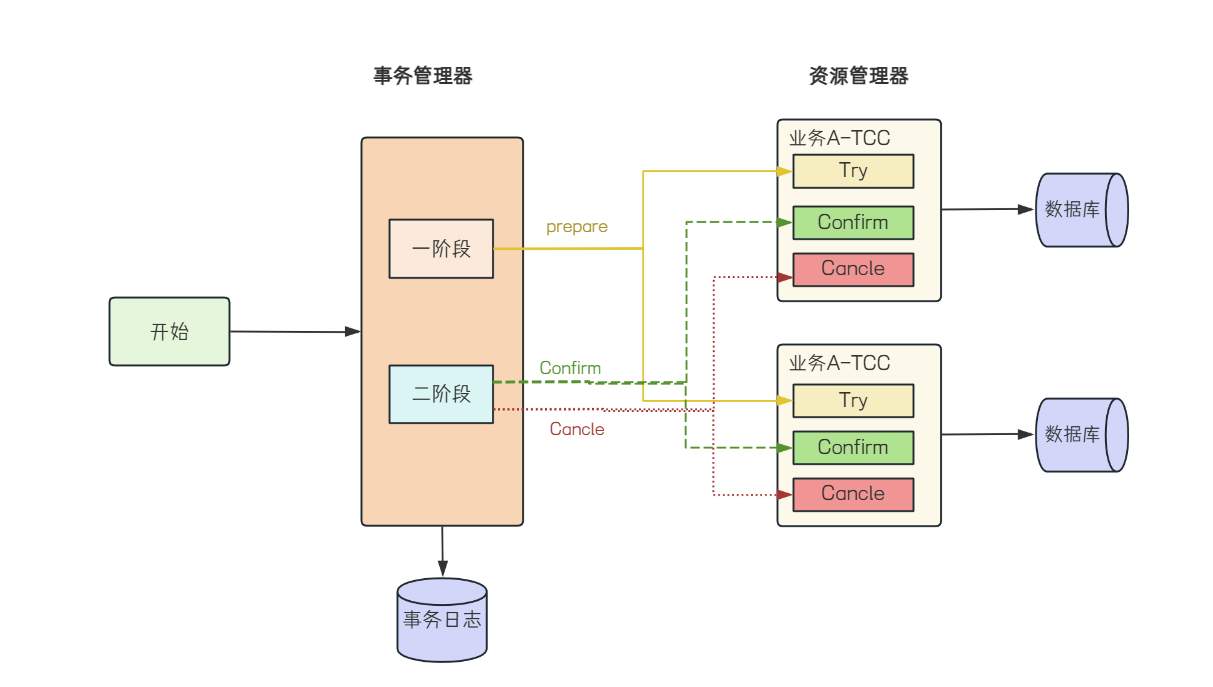
TCC 设计
了解了TCC模式之后, 我们先来使⽤ Seata TCC 模式实现⼀个分布式事务.
业务操作分析
接⼊ TCC 前, 业务操作只需要⼀步就能完成, 但是在接⼊ TCC 之后, 需要考虑如何将其分成 2 阶段完成, 把资源的检查和预留放在⼀阶段的 Try 操作中进⾏, 把真正的业务操作的执⾏放在⼆阶段的 Confirm 操作中进⾏.
我们以库存扣减为例.
下订单之后, 需要扣减相应的库存.
接⼊TCC之前, ⽤⼾通过⼀个SQL
update storage_tbl set count = count - #{count} where commodity_code = # {commodity_code}就可以完成.
接⼊TCC之后, 就需要考虑, 如何将扣库存分成两步完成.
• Try 操作:资源的检查和预留.
在扣库存场景下, Try 操作要做的事情就是先检查 A 商品库存是否⾜够, 再冻结要扣的 20 个 (预留资源 ) . 此阶段不会发⽣真正的扣库存.
• Confirm 操作:执⾏真正业务的提交.
在扣库存场景下, Confirm 阶段⾛的事情就是发⽣真正的扣库存, 把A商品中已经冻结的 30 个库存扣掉.
• Cancel 操作:预留资源的是否释放.
在扣库存场景下, 扣库存操作取消, Cancel 操作执⾏的任务是释放 Try 操作冻结的 20个库存, 使 A 商品回到初始状态.
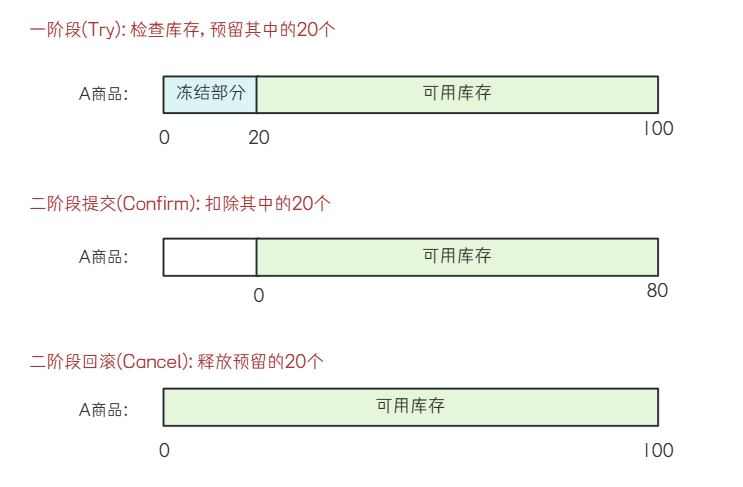
并发控制
⽤⼾在实现 TCC 时, 应当考虑并发性问题, 将锁的粒度降到最低, 以最⼤限度的提⾼分布式事务的并发性.
以下还是以A商品扣库存为例, "A商品 有 100 个库存, 事务 T1 要扣除其中的 20个, 事务 T2 也要扣除 20 个, 出现并发".
在⼀阶段 Try 操作中, 分布式事务 T1 和分布式事务 T2 分别冻结资⾦的那⼀部分资⾦, 相互之间⽆⼲扰. 这样在分布式事务的⼆阶段, ⽆论 T1 是提交还是回滚, 都不会对 T2 产⽣影响, 这样 T1 和 T2 在同⼀笔业务数据上并⾏执⾏.

允许空回滚
如下图所⽰, 事务协调器在调⽤ TCC 服务的⼀阶段 Try 操作时, 可能会出现因为丢包⽽导致的⽹络超时, 此时事务管理器会触发⼆阶段回滚, 调⽤ TCC 服务的 Cancel 操作, ⽽ Cancel 操作调⽤未出现超时.
TCC 服务在未收到 Try 请求的情况下收到 Cancel 请求, 这种场景被称为空回滚. 空回滚在⽣产环境经常出现, ⽤⼾在实现TCC服务时, 应允许空回滚的执⾏, 即收到空回滚时返回成功.
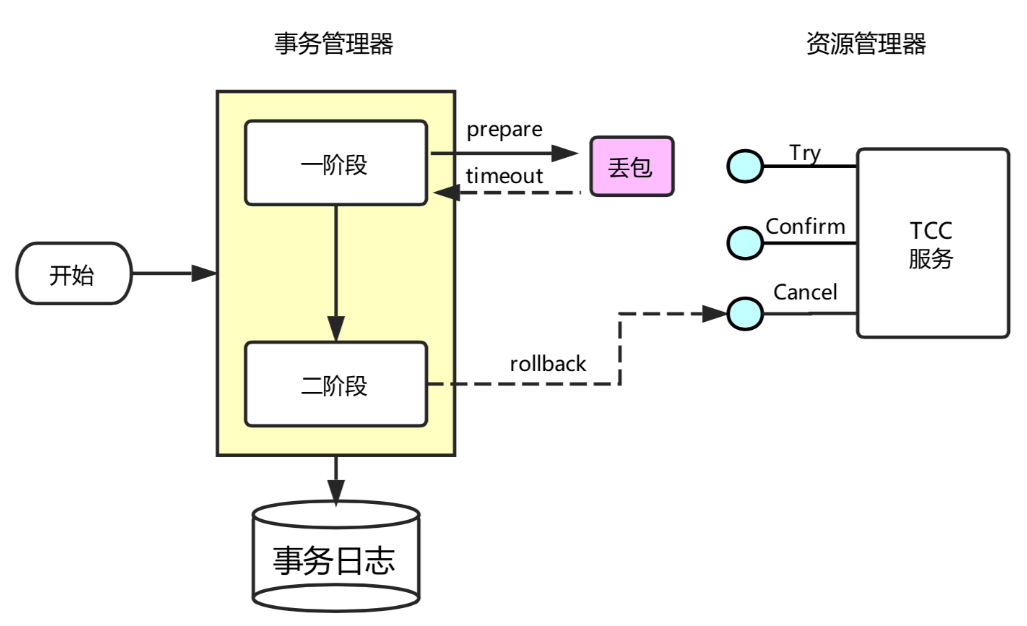
防悬挂控制
如下图所⽰, 事务协调器在调⽤ TCC 服务的⼀阶段 Try 操作时, 可能会出现因⽹络拥堵⽽导致的超时, 此时事务管理器会触发⼆阶段回滚, 调⽤ TCC 服务的 Cancel 操作, Cancel 调⽤未超时. 在此之后, 拥堵在⽹络上的⼀阶段 Try 数据包被 TCC 服务收到, 出现了⼆阶段 Cancel 请求⽐⼀阶段 Try 请求先执⾏的情况, 此 TCC 服务在执⾏晚到的 Try 之后, 将永远不会再收到⼆阶段的 Confirm 或者 Cancel , 造成 TCC 服务悬挂.
⽤⼾在实现 TCC 服务时, 要允许空回滚, 但是要拒绝执⾏空回滚之后 Try 请求, 要避免出现悬挂.
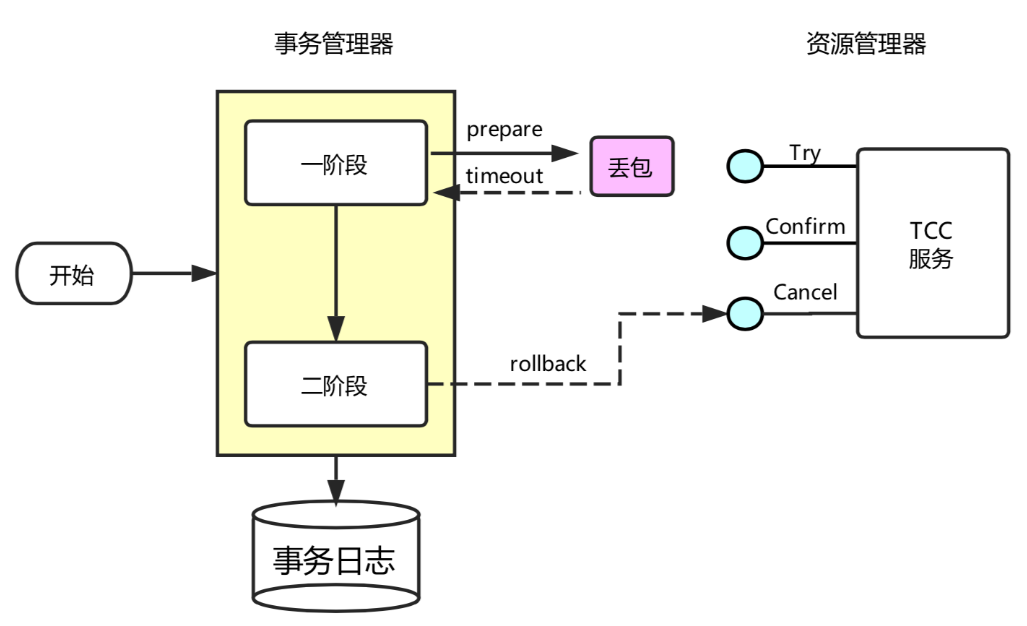
幂等控制
⽆论是⽹络数据包重传, 还是异常事务的补偿执⾏, 都会导致 TCC 服务的 Try、Confirm 或者 Cancel 操作被重复执⾏. ⽤⼾在实现 TCC 服务时, 需要考虑幂等控制, 即 Try、Confirm、Cancel 执⾏⼀次和执⾏多次的业务结果是⼀样的.
Seata解决⽅法
TCC 模式中存在的三⼤问题是幂等、悬挂和空回滚. 在 Seata1.5.1 版本中, 增加了⼀张事务控制表tcc_fence_log,包含事务的 XID 和 BranchID 信息, 来解决这个问题.
CREATE TABLE IF NOT EXISTS `tcc_fence_log`
(
`xid` VARCHAR(128) NOT NULL COMMENT 'global id',
`branch_id` BIGINT NOT NULL COMMENT 'branch id',
`action_name` VARCHAR(64) NOT NULL COMMENT 'action name',
`status` TINYINT NOT NULL COMMENT 'status(tried:1;committed:2;rollbacked:3;suspended:4)',
`gmt_create` DATETIME(3) NOT NULL COMMENT 'create time',
`gmt_modified` DATETIME(3) NOT NULL COMMENT 'update time',
PRIMARY KEY (`xid`, `branch_id`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_status` (`status`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;• 空回滚
在 Try ⽅法执⾏时插⼊⼀条记录, 表⽰⼀阶段执⾏了, 执⾏ Cancel ⽅法时读取这条记录, 如果记录不存在, 说明 Try ⽅法没有执⾏, 以此来避免空回滚
• 悬挂
在 Rollback 阶段, 如果查询到事务控制表中没有记录, 说明Cancle先于Try执⾏了. 因此插⼊⼀条 status=4 状态的记录. 当Try阶段执⾏时, 判断status=4 , 则说明有⼆阶段 Cancel 已执⾏, 并返回 false 以阻⽌⼀阶段 Try ⽅法执⾏成功
• 幂等
在 TCC 事务控制表中增加⼀个记录状态的字段 status, 该字段有 4 个值, 分别为:
a. tried(1) : 表⽰ Try 阶段已经执⾏过
b. committed(2): 表⽰⼆阶段 Commit 已经执⾏完成
c. rollbacked(3): 表⽰⼆阶段 Rollback 已经执⾏完成
d. suspended(4): 表⽰空回滚/悬挂/中⽌状态.
⼆阶段 Confirm/Cancel ⽅法执⾏后, 将状态改为 committed 或 rollbacked 状态. 当重复调⽤⼆阶段Confirm/Cancel ⽅法时, 判断事务状态即可解决幂等问题
TCC实现
以库存服务为例, 实现TCC
创建事务控制表
为了解决幂等, 悬挂和空回滚, Seata1.5.1版本增加了⼀张事务控制表tcc_fence_log,包含事务的 XID 和 BranchID 信息, 来解决这个问题.
在业务数据库中执⾏以下SQL
CREATE TABLE IF NOT EXISTS `tcc_fence_log`
(
`xid` VARCHAR(128) NOT NULL COMMENT 'global id',
`branch_id` BIGINT NOT NULL COMMENT 'branch id',
`action_name` VARCHAR(64) NOT NULL COMMENT 'action name',
`status` TINYINT NOT NULL COMMENT 'status(tried:1;committed:2;rollbacked:3;suspended:4)',
`gmt_create` DATETIME(3) NOT NULL COMMENT 'create time',
`gmt_modified` DATETIME(3) NOT NULL COMMENT 'update time',
PRIMARY KEY (`xid`, `branch_id`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_status` (`status`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;添加冻结字段
为了完成⼀阶段(Try)资源的预检, 以及T2阶段事务的提交或回滚, 需要增加⼀个新的字段, 表⽰冻结部分.
ALTER TABLE storage_tbl ADD COLUMN freeze_count INT(11) unsigned DEFAULT 0 COMMENT '冻结库存';修改相应的实体类
@Data
@TableName("storage_tbl")
public class StorageInfo {
@TableId
private Long id;
private String commodityCode;
private Integer count;
private Integer freezeCount;
}
TCC接⼝定义&实现
TCC的Try、Confirm、Cancel⽅法都需要⾃⼰来实现. 在库存服务中定义TCC接⼝
public interface StorageTccService {
boolean prepare(String commodityCode, Integer count);
boolean commit(BusinessActionContext actionContext);
boolean rollback(BusinessActionContext actionContext);
}TCC接⼝定义实现
@Service
@LocalTCC
@Slf4j
public class StorageTccServiceImpl implements StorageTccService {
// @TwoPhaseBusinessAction 被该注解标识的办法,即为try阶段执行的方法
//commitMethod二阶段commit执行的方法 rollbackMethod:二阶段rollback执行的方法
//useTCCFence = true 使用seata自动处理空回滚,悬挂问题,幂等问题
@Autowired
private StorageMapper storageMapper;
@Override
@TwoPhaseBusinessAction(name = "storageDeduct", commitMethod = "commit",
rollbackMethod = "rollback" , useTCCFence = true)
public boolean prepare(@BusinessActionContextParameter("commodityCode") String commodityCode,
@BusinessActionContextParameter("count") Integer count) {
log.info("一阶段try...");
try {
UpdateWrapper<StorageInfo> updateWrapper = new UpdateWrapper<>();
updateWrapper.lambda().setSql("count = count - "+ count)
.setSql("freeze_count = freeze_count + "+ count)
.eq(StorageInfo::getCommodityCode, commodityCode);
storageMapper.update(updateWrapper);
return true;
} catch (Exception e) {
log.error("扣减库存失败, e:", e);
throw new RuntimeException("扣减库存失败!", e);
}
}
@Override
public boolean commit(BusinessActionContext actionContext) {
log.info("二阶段commit...");
String commodityCode = (String) actionContext.getActionContext("commodityCode");
Integer count = (Integer) actionContext.getActionContext("count");
UpdateWrapper<StorageInfo> updateWrapper = new UpdateWrapper<>();
updateWrapper.lambda().setSql("freeze_count = freeze_count - "+ count)
.eq(StorageInfo::getCommodityCode, commodityCode);
Integer result = storageMapper.update(updateWrapper);
return result==1;
}
@Override
public boolean rollback(BusinessActionContext actionContext) {
log.info("二阶段rollback...");
String commodityCode = (String) actionContext.getActionContext("commodityCode");
Integer count = (Integer) actionContext.getActionContext("count");
UpdateWrapper<StorageInfo> updateWrapper = new UpdateWrapper<>();
updateWrapper.lambda().setSql("freeze_count = freeze_count - "+ count)
.setSql("count = count + "+ count)
.eq(StorageInfo::getCommodityCode, commodityCode);
Integer result = storageMapper.update(updateWrapper);
return result==1;
}
}📌 • 注解@LocalTCC要修饰在实现类上
• 注解@TwoPhaseBusinessAction要修饰在实现类⽅法prepare上, 可以通过BusinessActionContext来传递参数
TCC核⼼注解及参数描述
TCC有两个核⼼注解 @TwoPhaseBusinessAction 和 @LocalTCC , 以及两个重要参数:
BusinessActionContext 和 @BusinessActionContextParameter
• @LocalTCC
@LocalTCC 注解⽤来表⽰实现了⼆阶段提交的本地的TCC接⼝.
• BusinessActionContext
事务上下⽂. 可以使⽤此⼊参在TCC模式下, 在事务上下⽂中, 传递查询参数. 如下属性:
◦ xid 全局事务id
◦ branchId 分⽀事务id
◦ actionName 分⽀资源id, (resource id )
◦ actionContext 业务传递参数Map, 可以通过@BusinessActionContextParameter来标注需要传递的参数
• @BusinessActionContextParameter
⽤此注解标注需要在事务上下⽂中传递的参数. 被此注解修饰的参数, 会被设置在BusinessActionContext中, 可以在commit和rollback阶段中, 可以通过BusinessActionContext的getActionContext⽅法获取传递的业务参数值. 如下:
context.getActionContext("id").toString();• @TwoPhaseBusinessAction
@TwoPhaseBusinessAction 表⽰了当前⽅法使⽤TCC模式管理事务提交, 被@TwoPhaseBusinessAction 所修饰的⽅法便是Try阶段执⾏的逻辑.@TwoPhaseBusinessAction 属性说明:
a. name: 给当前事务注册了⼀个全局唯⼀的的TCC bean name. 如代码⽰例中, name ="storageTccDeduct".
b. commitMethod: 对应TCC模型的⼆阶段Confirm阶段执⾏的⽅法名称
c. commitArgsClasses: commitMethod 默认的参数为BusinessActionContext, 如果需要修改, 需要指定commitArgsClasses
d. rollbackMethod: 对应TCC模型的⼆阶段Cancel执⾏的⽅法名称.
e. rollbackArgsClasses: rollbackMethod默认的参数为BusinessActionContext, 如果需要修改, 需要指定rollbackArgsClasses
f. useTCCFence: 是否启⽤栅栏功能, 主要⽤于解决 TCC 模式下的幂等性、空回滚和悬挂问题. 需要创建事务控制表. 默认为false, 即不启⽤栅栏功能.
更多请参考:API ⽀持 | Apache Seata
实现原理, 参考: 阿⾥ Seata 新版本终于解决了 TCC 模式的幂等、悬挂和空回滚问题 | Apache Seata
优缺点
TCC (Try-Confirm-Cancel ) 模式是⼀种分布式事务解决⽅案, 适⽤于需要⾼性能和强⼀致性的复杂业务场景.
优点:
• 性能⾼: TCC模式没有全局锁, 事务提交和回滚由应⽤代码实现, 资源锁定时间短, 性能较⾼
• 灵活性强: 可以⾃定义Try、Confirm和Cancel逻辑, 适应复杂的业务场景.
• 不依赖数据库事务: 不依赖底层数据库, 能够实现跨数据库、跨应⽤资源管理, 提供更细粒度的控制,可以⽤于⾮事务型数据库
缺点:
• 开发成本⾼: 需要⽤⼾⾃⼰编写Try、Confirm和Cancel接⼝, 增加开发⼯作量
• 适⽤场景有限; 对于复杂业务, 补偿逻辑可能会⾮常复杂, 补偿成本过⾼的业务不适合使⽤TCC模式.
Saga模式
模式介绍
Saga 模式是 SEATA 提供的⻓事务解决⽅案, 在 Saga 模式中, 业务流程中每个参与者都提交本地事务, 当出现某⼀个参与者失败则补偿前⾯已经成功的参与者, ⼀阶段正向服务和⼆阶段补偿服务都由业务开发实现.
如图所⽰, Saga由⼀系列sub-transaction Ti组成, 每个Ti 都有对应的补偿动作Ci,补偿动作⽤于撤销T造成的数据变更结果. 它和TCC相⽐, 少了Try这个预留动作, 每⼀个T操作都真实地影响到数据库.
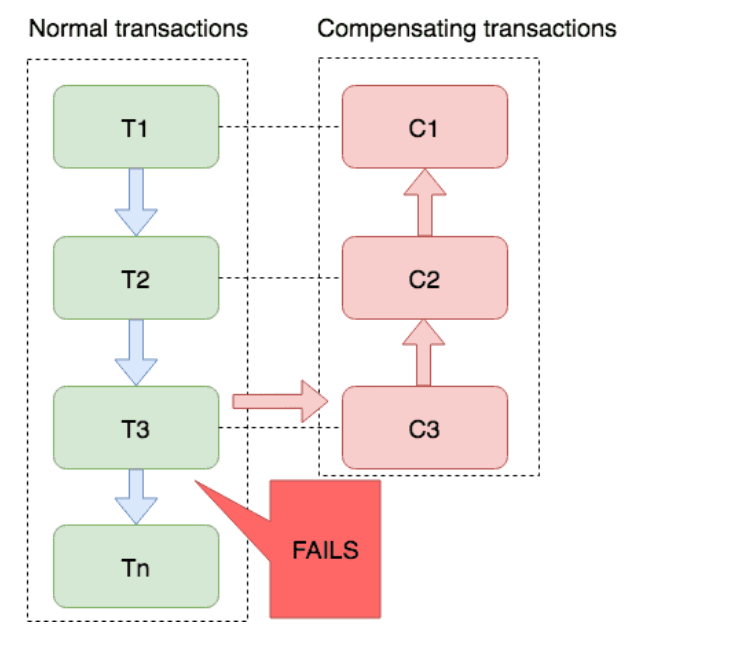
理论基础:Hector & Kenneth 发表论⽂ Sagas (1987 )
适⽤场景及优缺点
适⽤场景:
• 业务流程⻓、业务流程多
• 参与者包含其它公司或遗留系统服务, ⽆法提供 TCC 模式要求的三个接⼝
优势:
• ⼀阶段提交本地事务, ⽆锁, ⾼性能
• 事件驱动架构, 参与者可异步执⾏, ⾼吞吐
• 补偿服务易于实现
缺点:
• 不保证隔离性. ⽐如⽤⼾购买⼀个商品后系统赠送⼀张优惠券, 如果⽤⼾已经把优惠券使⽤了, 那么事务如果出现异常要回滚时就会出现问题.
四种模式对⽐
| XA | AT | TCC | SAGA | |
| 实现⽅式 | • 依赖数据库对XA协议的⽀持, 通过XA规范来实现事务的提交和回滚. • 不需要额外的undo_log 表, 但要求数据库⽀持XA协议 | • 通过记录数据快照 ( undo_log 表 ) 来实现数据的回滚 • 适⽤于⼏乎所有的数据库, 但需要在业务库中创建undo_log 表. | • 开发⼈员⼿动实现Try 、Confirm 、Cancel 三阶段 | • 事件驱动, 每个事务包含正向操作和逆向补偿操作 • 失败时按顺序执⾏逆向补偿 |
| ⼀致性 | 强⼀致性 事务的中间状态对⽤⼾不可⻅ | 最终⼀致性 在事务的两阶段之间, 数据可能处于中间状态 | 最终⼀致性(通过业务实现) | 最终⼀致性 |
| 性能 | 性能较差, ⼀阶段锁定资源, 等待⼆阶段结束才释放 | 性能较好, ⼀阶段直接提交, 不锁定资源 | 较⾼, 但开发成本⾼(需要处理空回滚, 业务悬挂等) | ⾼(⽆锁) 适合⻓事务 |
| 代码侵⼊ | ⽆代码侵⼊ | ⽆代码侵⼊ | 有, 需要⼿动编写三个接⼝ | 有, 需要编写状态机和补偿业务 |
| 数据库⽀持 | 依赖数据库对XA协议的⽀持 | 适⽤于⼏乎所有⽀持SQL的数据库 | 不依赖底层数据库的事务机制 | 不依赖底层数据库的事务机制 |
分布式链路追踪-SkyWalking:
1. 链路追踪介绍:
在分布式系统中, ⼀次请求往往会经过多个服务节点. ⽐如⼀次简单的⽤⼾下单请求, 可能涉及⽹关, 商品服务, 库存服务, ⽀付服务、消息队列等多个环节. 这些服务节点可能是不同团队开发, 部署在不同的服务器上, 甚⾄可能使⽤不同的编程语⾔编写. 在这⼀系列的调⽤中, 可能有串⾏的, 也有并⾏的.
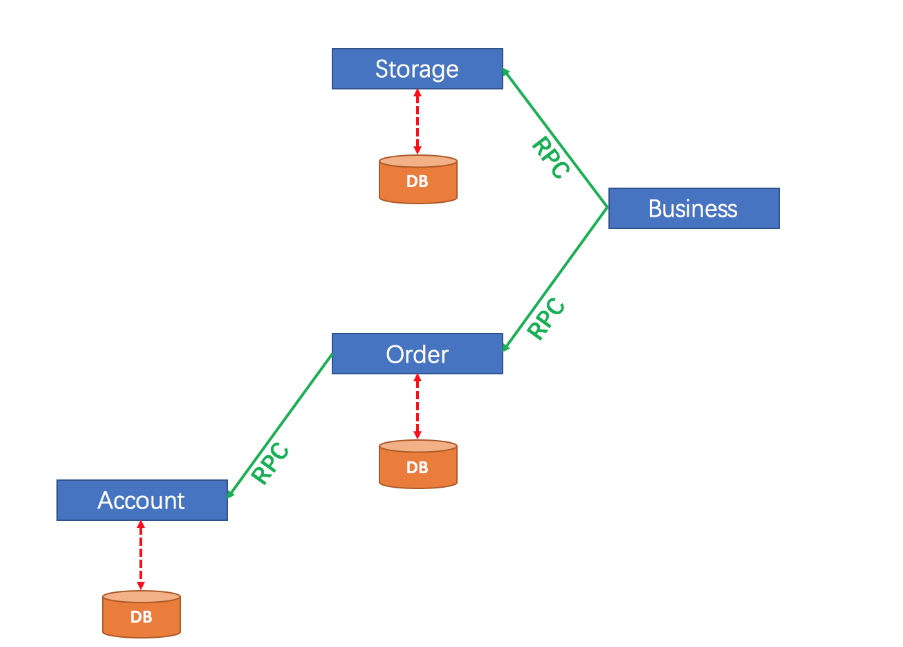
在分布式系统中, 我们可能会遇到⼀些问题, ⽐如:
1. 这个请求经过了哪些服务节点
2. 这些服务节点有什么样的依赖关系
3. 各个服务接⼝的性能是如何的
4. 如何快速的串联整个链路, 并定位问题
这就涉及到了链路追踪.
什么是链路追踪?
链路追踪是分布式系统中跟踪请求全流程的技术, 通过记录请求在多个服务间的流转路径, 耗时, 状态等信息, 形成完整的调⽤链视图. 也就是将⼀次分布式请求的调⽤情况集中进⾏展⽰. 其核⼼是通过唯⼀标识( TraceID )串联跨服务的调⽤单元( Span ),并借助上下⽂传递( Context )实现链路连续性.
核⼼概念
• Trace :代表⼀次完整的请求处理过程, 从请求到响应结束. 由多个 Span 组成
• TraceID: 每个Trace有⼀个唯⼀的 Trace ID来标识, ⽤于关联跨服务的⽇志和监控数据
• Span :Trace的基本单元. 代表请求在单个服务节点上的处理过程(如下单, ⽀付, 数据库查询等), 包含操作名称, 耗时等数据。
链路追踪的作⽤:
在微服务与分布式架构中, 系统复杂度显著提升, 会⾯临较多挑战, 链路追踪在分布式架构中, 有以下作⽤:
1. 保障系统可⽤性与稳定性
分布式系统中, 服务依赖的复杂性使得局部故障可能迅速扩散. 链路追踪⼯具会通过实时采集CPU、内存、请求成功率等指标, 可主动发现异常, 并在达到阈值时触发告警. 帮助团队在⽤⼾感知前介⼊处理,避免系统雪崩.
2. 优化性能与资源利⽤率
链路追踪⼯具通过记录请求的完整调⽤链(Trace), 将每个服务节点的处理耗时可视化. 这种细粒度分析帮助开发者精准识别慢调⽤(如服务 A 的 HTTP 请求耗时占⽐ 80%)并进⾏优化.
3. 提升故障排查效率
传统⽇志排查需在多台服务器间⼈⼯拼接线索, 耗时且易遗漏关键信息. 追踪⼯具为每个请求分配唯⼀Trace ID, 将跨服务的⽇志, 错误信息关联为统⼀视图, 帮助快速定位故障节点(如识别数据库查询超时或第三⽅接⼝异常)
4. 理解服务依赖与拓扑
分布式系统服务依赖关系动态变化, ⼈⼯维护依赖图谱成本⾼, 可以借助链路追踪⼯具⾃动⽣成服务拓扑图, 展⽰服务间调⽤频率与成功率,辅助容量规划与架构治理.
2. 为什么选择SkyWalking:
链路追踪这个技术已经⽐较成熟了, 市⾯上也有很多链路追踪的产品, 接下来介绍⼏种业界主流的链路追踪产品
• Zipkin
• CAT
• SkyWalking
ZipKin:
Zipkin 是由Twitter开发并开源的⼀款分布式链路追踪产品, 基于Google的Dapper论⽂设计, 旨在帮助开发者监控和排查微服务架构中的请求链路问题.
Zipkin早期主要⽤于Twitter内部解决分布式系统调⽤链路可视化难题, 后逐渐被Netflix、阿⾥巴巴等企业采⽤并推⼴. 2015年成为Apache孵化器项⽬, ⽀持多种存储后端(如MySQL, Elasticsearch、内存等)及多语⾔客⼾端. 随着微服务架构普及,Zipkin成为链路追踪领域的标准⼯具之⼀,常与Spring Cloud等⽣态集成.
⽬前GitHub收获17.2K+ Star, 3100+ Forks, 被全球上百家公司采⽤, 覆盖电商, ⾦融, 云计算等多个⾏业. 开源地址: GitHub - openzipkin/zipkin: Zipkin is a distributed tracing system
CAT
CAT(Central Application Tracking)是⼀个⽐较早的分布式监控产品, 是美团点评在2011年底基于 Java 开发的⼀套开源的分布式实时监控系统, ⽬前已经覆盖了美团点评的外卖, 酒旅, 出⾏, ⾦融等核⼼业务线, ⼏乎已经接⼊美团点评的所有核⼼应⽤.
CAT⾃从2014年开源, GitHub收获18.9K+ Star, 5400+ Forks, 被 100+公司企业使⽤,其中不乏携程, 陆⾦所, 猎聘⽹, 平安等业内知名公司.

CAT的原型和理念来源于eBay的CAL系统(CAL是eBay平台的⽇志服务, 主要负责存储⽇志数据, 并提供检索, 聚合, 分析等功能), CAT 不仅增强了CAL的系统核⼼模型, 还添加了丰富的报表.
开源地址: http://github.com/dianping/cat
参考: CAT简介
SkyWalking:
Apache SkyWalking 是由个⼈吴晟(华为开发者)于2015年发起的开源应⽤性能监控(APM)系统, 于2017年进⼊ Apache 孵化器, 成为国内⾸个由个⼈主导进⼊ Apache 的开源项⽬, 并于2019年正式毕业成为 Apache 顶级项⽬, 标志着其技术成熟度与社区认可度达到新⾼度. 其发展轨迹从个⼈项⽬逐步演变为全球顶级的分布式系统监控解决⽅案,背后离不开开源社区的持续贡献(如华为、阿⾥巴巴等企业的⽀持).
SkyWalking 专为微服务及分布式架构设计, 现已成为全球领先的可观测性解决⽅案. 特点是⽀持多种插件,UI功能较强,接⼊端⽆代码侵⼊. ⽬前GitHub收获24.3 K+ Star, 6600+ Forks, 被全球多家知名企业应⽤于⽣产环境.

开源地址: github.com
官⽅⽂档: Apache SkyWalking
资料参考: https://qcon.infoq.cn/2018/beijing/presentation/445
特点对⽐:
| 维度 | Zipkin | CAT | SkyWalking |
| 接⼊复杂度 | 轻量级,集成Spring Cloud Sleuth即可 | 需代码埋点 | 通过Java Agent启动,代码⽆侵⼊ |
| 数据粒度 | 接⼝级 | 代码级(可细化到具体代码块) | ⽅法级(⽀持RPC, HTTP) |
| ⽀持语⾔ | Java, C#, Python,Nodejs, Golang, Ruby, Scala等 | Java, C/C++, Python,Nodejs, Golang等 | Java, Python, Nodejs, PHP, Golang,Ruby等 |
| 调⽤链可视化 | 有 | 有 | 有 |
| 聚合报表 | 少 | ⾮常丰富 | 较丰富 |
| 服务依赖图 | 简单 | 简单 | 好 |
| 告警⽀持 | ⽆ | ⽀持 | ⽀持 |
| 存储机制 | 内存,ES,MySQL等 | mysql(报表),本地⽂件/HDFS(调⽤链) | ES, MySQL, banyandb, PostgreSQL等(最新版本已移除H2存储) |
| 社区⽀持 | ⽂档丰富, 国外主流, 功能迭代较慢 | 社区活跃低, ⽂档⼀般, 主要国内, ⼤⼚使⽤多 | 社区活跃, 更新频繁 |
| 亮点 | 轻量, 部署简单, 适合Spring Cloud微服务快速集成 | 功能全⾯(⽇志采集, 报警, 业务报表), 适合⼤⼚综合监控 | ⾮侵⼊, Apache 背书, 社区活跃 |
| 不⾜ | 报表能⼒弱, 功能单⼀ | 代码侵⼊性⾼, 社区不活跃 | 插件开发⻔槛⾼ |
综上:
Zipkin 适合需要快速搭建链路追踪的中⼩型团队, 对深度监控和业务分析⽀持有限
CAT 适合中⼤企业, 对报表以及监控粒度要求较⾼
SkyWalking 综合实⼒较强, ⽆侵⼊, 多语⾔且性能较优, ⾃⾝包含⽐较丰富的报表及告警⽀持, 并且⽀持插件定制开发(难度较⼤)
3. 术语介绍
APM
APM: Application Performance Monitor, 应⽤性能监控. APM 指通过收集, 分析和可视化应⽤程序的运⾏时数据(如响应时间、吞吐量、错误率等), 帮助开发者和运维团队优化系统性能的技术体系. 上述CAT 和 SkyWalking 就是APM⼯具.
OAP
OAP: Observability Analysis Platform, 观测分析平台.
SkyWalking的架构通常包括三个主要组件: 探针(Agent), 后端(Backend) 和前端(UI). 其中OAP是后端的重要组成部分, 负责接收、处理、存储来⾃探针的可观测性数据,并⽣成聚合指标.
Agent
Agent: 探针. 轻量级数据采集组件, 通过字节码植⼊技术(Bytecode Instrumentation)⽆侵⼊式收集应⽤程序的运⾏时数据. SkyWalking提供了Java, Python, Go, NodeJS, PHP等语⾔的探针
UI
UI: 可视化界⾯.
通过 RESTful API 从 OAP 获取数据, ⽀持图表化展⽰与交互式筛选, 提供 Web 控制台,展⽰服务拓扑、调⽤链路、实时指标、告警信息等.
Metrics
Metrics: 指标, ⽐如服务响应时间, 服务成功率等.
Endpoint
Endpoint: 服务实例中⽤于接收和处理外部请求的具体⼊⼝点,是⽐service更细粒度的监控单元, ⽤于描述服务内部的接⼝或⽅法级别的访问路径.
4. 安装部署
下载安装SkyWalking
下载
官⽅下载地址:https://skywalking.apache.org/downloads/
分别下载:SkyWalking APM(10.2.0) 和 Java Agent(9.4.0)
从8.8.0之后, agent和apm的安装分开了, 需要分开安装apm和agent
🪧 找不到相应版本的话, 可以去历史版本中找
APM 历史版本: https://archive.apache.org/dist/skywalking/
Java Agent 历史版本: https://archive.apache.org/dist/skywalking/java-agent/
解压
• 解压apm, 新建⼀个agent⽂件夹
• 解压agent, 把内容复制到上⼀步创建的agent⽂件夹中
数据库选型及配置
SkyWalking⽀持多种存储选项, 简单介绍以下⼏种
1. H2
⾃ 2015 年以来,H2 ⼀直作为 SkyWalking 的默认存储选项, 旨在简化⽤⼾⾸次安装的体验. 其内存模式为⽤⼾提供了⼀种⽆需额外配置即可本地快速上⼿的⽅式, ⾮常适合学习, 但是在⽣产环境⾮常受限, ⽐如H2 的内存模式通常会在运⾏⼤约 20 分钟后丢失数据, 更糟糕的是,这种⾏为没有任何预警,导致⽆法⻓期使⽤. 所以官⽅从2025年宣布H2 将不再作为存储选项被⽀持. 取⽽代之的是BanyanDB
2. MySQL
Skywalking⼀直⽀持MySQL为存储选项, MySQL对于中⼩规模的数据友好, 部署和运维成本低, 适合已有MySQL基础设施的团队, 但是分库分表复杂度⾼, ⽆法适应千亿级数据的分布式存储需求. 但对时间序列数据的聚合查询效率远低于 ES, 复杂查询易成为瓶颈. 适合学习和测试环境, 或者数据量极⼩的环境.
3. Elasticsearch
在2025年之前, ES⼀直作为官⽅推荐的⽣产环境使⽤的存储选项, ES基于倒排索引和分⽚机制, 擅⻓处理海量时序数据的查询与聚合分析, 可通过集群分⽚应对 PB 级数据存储需求. ⽽且社区⽀持⼴泛, 但是ES的运维成本较⾼, 需要独⽴部署ES集群, 对资源消耗⼤, 使得ES的性价⽐不是很⾼.
4. BanyanDB
BanyanDB脱胎于SkyWalking社区,主要⾯向APM领域, 专为处理 Metrics(指标)、Tracing(追踪)、Logging(⽇志) 三类可观测性数据设计. BanyanDB 专为云原⽣架构设计, 能够处理更⼤的⼯作负载,⽆需担⼼数据丢失,⽽且设置⾮常简单,降低了新⽤⼾的使⽤⻔槛.
作为SkyWalking的原⽣数据库, BanyanDB⽬前还处于⾼速研发的阶段. 随着BanyanDB⼦项⽬的不断发展, SkyWalking官⽅宣布, BanyanDB 0.8已经完全⽣产可⽤, 是⽣产环境的理想选择.
综上:
考虑到ES和BanyanDB具备⼀定的学习成本, 并且作为存储选项, MySQL与其他存储后端(如Elasticsearch)有⼀致的⾏为, 学习阶段的数据量不是很⼤, 我们课堂优先使⽤MySQL来进⾏讲解.
修改配置
修改端⼝号(按需)
SkyWalking UI的默认端⼝号是 8080, 如果和现有进程冲突了, 可以进⾏修改.
修改⽂件: /apache-skywalking-apm-bin/webapp/application.yml
代码块
Skywalking-oap-server 服务(OAP模块的实际运⾏实例)启动后会暴露11800 和12800 两个端⼝
11800: grpc端⼝, 接受SkyWalking Agent 的监控数据
12800: REST API端⼝, 提供 RESTful API 服务, 供 SkyWalking UI 或其他外部系统调⽤, ⽤于查询监控数据.
创建数据库
代码块
CREATE DATABASE skywalking;修改存储后端为MySQL
连接mysql需要在 /apache-skywalking-apm-bin/oap-libs 这个⽬录下放⼊ mysqlconnector-java 的包
修改存储配置
配置⽂件路径: /apache-skywalking-apm-bin/config/application.yml
代码块

修改mysql相关配置:

启动SkyWalking
启动⽂件: /apache-skywalking-apm-bin/bin/startup.bat
双击运⾏
访问: http://127.0.0.1:port/marketplace
port改成上⾯UI设置的端⼝号
显⽰该⻚⾯, 说明启动成功(第⼀次启动需要做很多初始化⼯作, 会⽐较慢)
5. SkyWalking快速开始
服务准备
使⽤前⾯seata组件时的项⽬, 修改项⽬名称即可, 确认所有服务都是正常的.
服务接⼊
以order-service为例
添加启动参数, 通过 -javaagent 参数进⾏配置SkyWalking Agent来跟踪微服务
代码块
-javaagent:D:\soft\apache-skywalking-apm-10.2.0\apache-skywalking-apm-
bin\agent\skywalking-agent.jar
-Dskywalking.agent.service_name=order-service
-Dskywalking.collector.backend_service=127.0.0.1:11800-javaagent: 后⾯换成⾃⼰的路径
-Dskywalking.agent.service_name : 服务名称
-Dskywalking.collector.backend_service : SkyWalking 服务器配置
启动完成之后, 就可以在SkyWalking的UI上看到服务列表了
点击左侧[服务]
同上, 完成其他服务接⼊skywalking
接⼝请求
发起接⼝请求
观察⻚⾯, 会出现⼀些指标
6. UI介绍
⻚⾯指标介绍
服务接⼊Skywalking后, 当有请求时, UI⻚⾯会显⽰服务相关的指标
• Service Apdex:当前服务的评分, 量化⽤⼾对服务性能满意度的标准化指标, 反映⽤⼾体验的质量.
• Service Success Rate: 服务请求成功率
• Service Avg Response Time (ms): 服务平均响应延时(单位ms)
• Service Load (calls / min): 分钟请求数
• Endpoint Success Rate: 当前端点的成功率
• Endpoint Avg Response Time (ms): 端点的平均响应时⻓
• Endpoint Load (calls / min): 每个端点(URL)的请求次数
模拟接⼝
为了⽅便观察, 我们新增⼀个订单查询的接⼝
order-service
OrderController
代码块
@RequestMapping("/query/{orderId}")
public ResponseEntity<OrderInfo> queryOrder(@PathVariable("orderId") Integer orderId) throws InterruptedException {
log.info("查询订单, orderId:{}", orderId);
if(orderId%5==0){
throw new RuntimeException("模拟异常");
}
if(orderId==9){
Thread.sleep(2000+new Random().nextInt(100));
}
OrderInfo orderinfo = orderService.queryOrder(orderId);
return ResponseEntity.status(HttpStatus.OK).body(orderinfo);
}OrderService
代码块
OrderInfo queryById(Integer orderId);OrderServiceImpl
代码块
public OrderInfo queryOrder(Integer orderId) {
log.info("queryOrder,orderId:{}",orderId);
return orderMapper.selectById(orderId);
}观察指标
重启服务, 使⽤JMeter模拟请求, 随机访问上述接⼝
请求路径: /order/query/${__Random(1,20)} 观察UI⻚⾯, 指标会发⽣相应变化
Service
服务概况:
会显⽰接⼊Skywalking的服务, 已经服务的概况
ServiceNames: 服务名称
Load(calls/min): 每分钟访问次数
Success Rate(%): 请求成功率
Latency(ms): 服务请求延迟时间(此处为服务平均响应时间)
Apdex: 当前服务评分
服务详情
告警信息
点击服务名称, 会显⽰相应服务的详情

上⾯是服务告警相关信息, 点击会⾼亮显⽰告警时间段的指标
服务概况
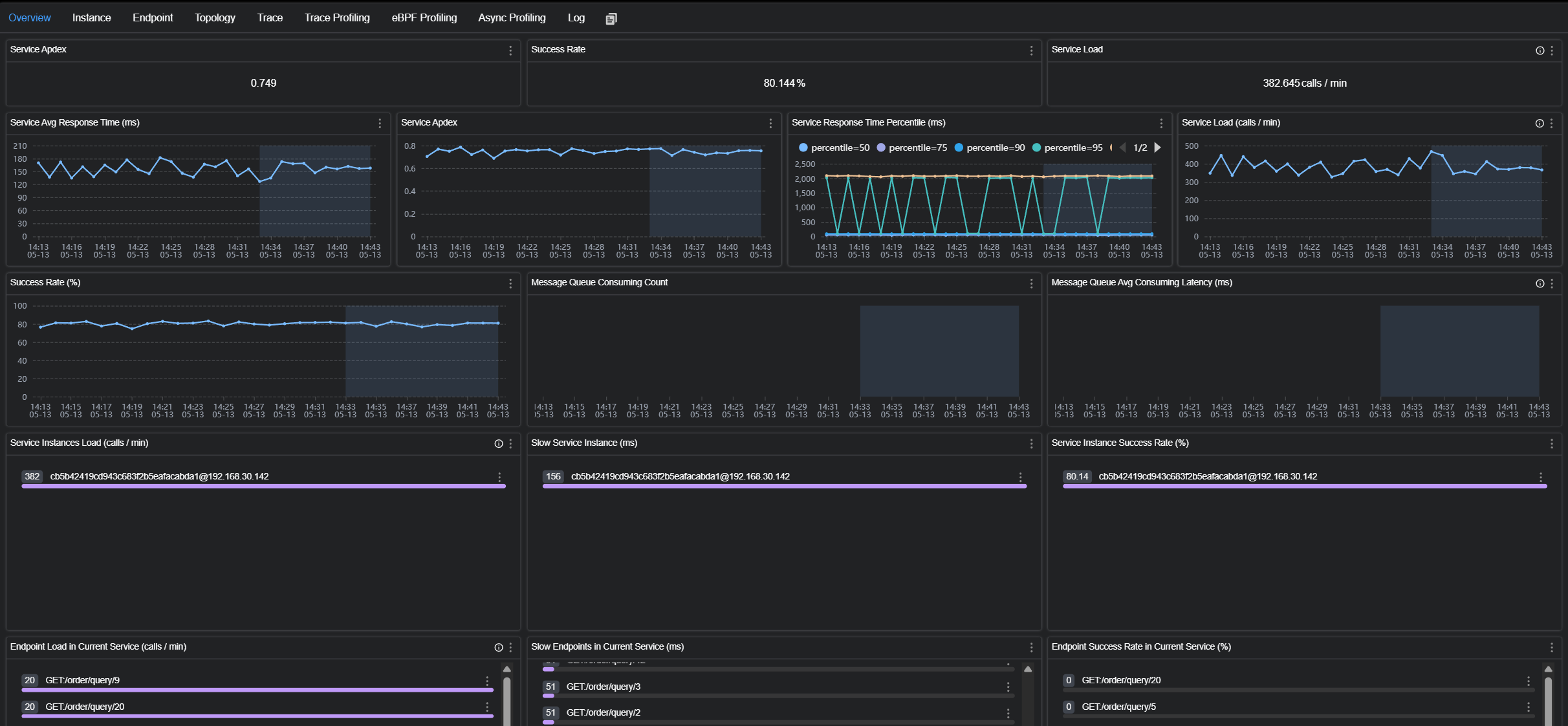
• Service Avg Response Time (ms): 服务平均响应延时(单位ms)
• Service Apdex: 当前服务评分
• Service Response Time Percentile (ms): 服务响应时间百分⽐, 通过分位数(如P99, P95, P90, P75,P50)反映不同⽐例请求的延迟情况. 如P99=300ms 表⽰ 99% 的请求延迟低于300ms
• Service Load (calls / min): 分钟请求数
• Success Rate (%): 分钟请求成功百分⽐
• Message Queue Consuming Count: 消息队列消耗计数
• Message Queue Avg Consuming Latency (ms): 消息队列平均消耗延迟(单位ms)
• Service Instances Load (calls / min): 服务节点每分钟请求次数
• Slow Service Instance (ms): 服务节点的最⼤延时
• Service Instance Success Rate (%): 每个服务实例的请求成功率
• Endpoint Load in Current Service (calls / min): 每个端点(URL)的请求次数
• Slow Endpoints in Current Service (ms): 当前端点(URL)的慢响应时间
• Endpoint Success Rate in Current Service (%): 当前端点(URL)的成功响应请求占⽐
Instance
显⽰所选服务的实例节点
Endpoint
按端点聚合, 显⽰端点的请求次数/成功率/延迟
Topology
显⽰服务的拓扑图
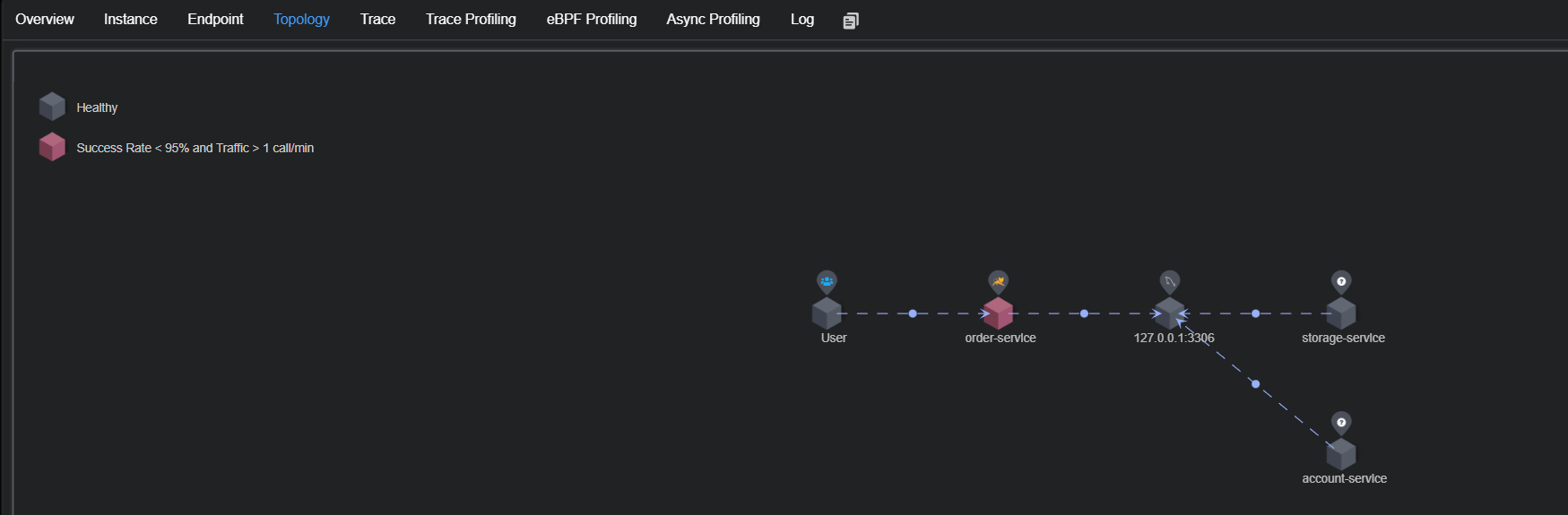
发起创建订单的请求, 拓扑图就会增加新的服务调⽤关系
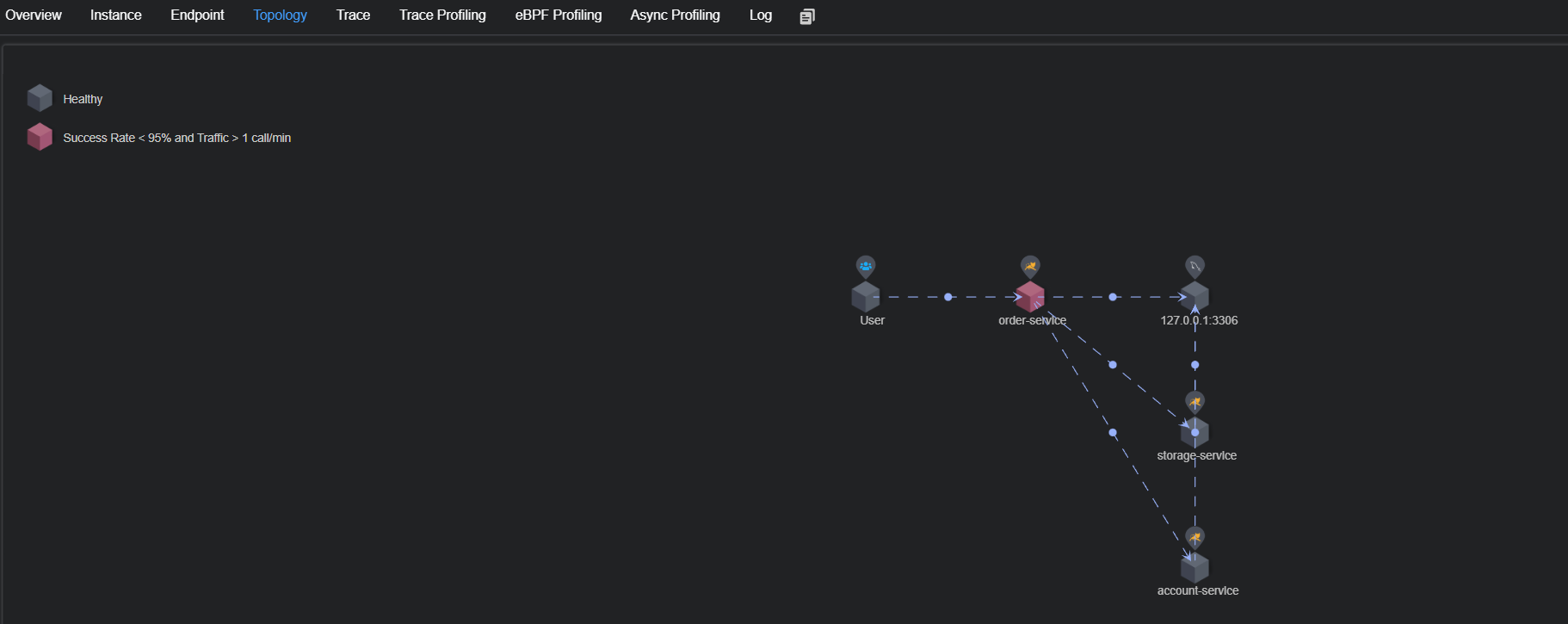
Trace
左侧为端点列表, 蓝⾊表⽰正常请求, 红⾊表⽰异常请求
右侧显⽰请求的追踪链表 , 各个节点的调⽤顺序及时间等
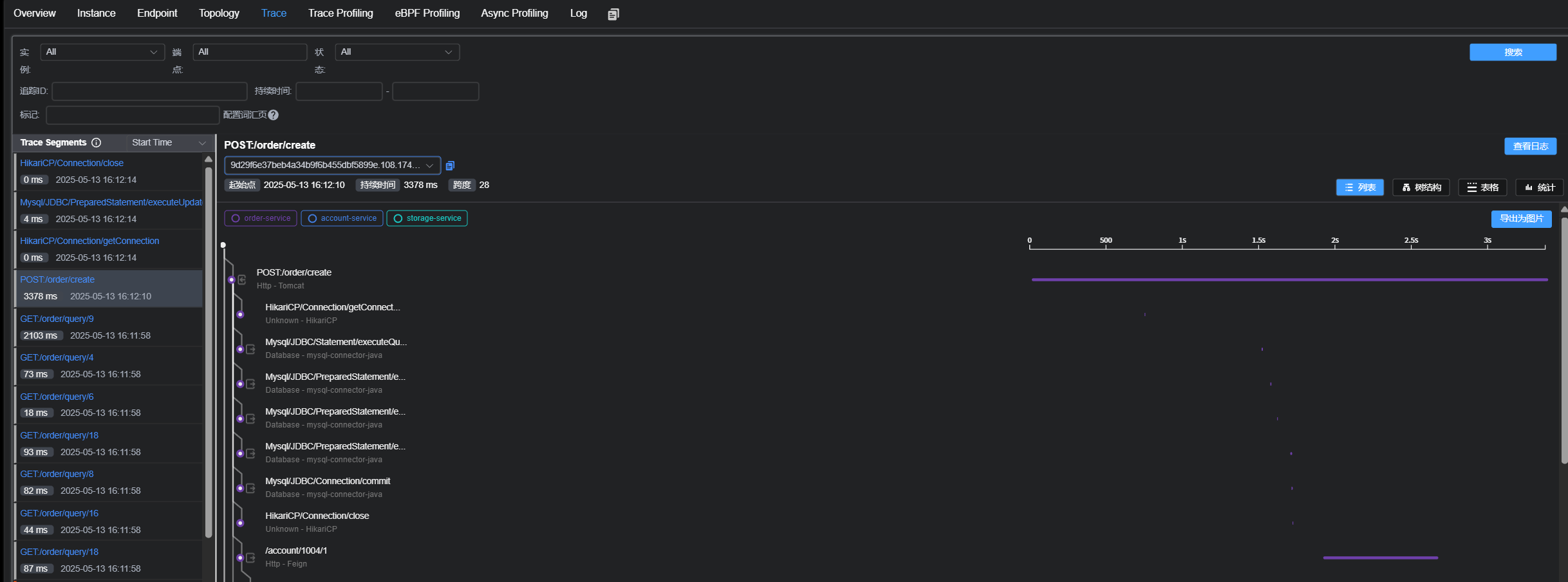
右侧可以切换不同的显⽰格式
这个⻚⾯会显⽰每个中间节点的执⾏时间, 以及执⾏占⽐等, ⽅便我们进⾏性能分析
数据库指标
Skywalking 也会提供数据库相关的监控指标

可以看到数据库的列表, 已经数据库的概况
指标介绍
点击数据库, 可以看到执⾏数据库的详情

• Database Avg Response Time (ms): 数据库平均响应时间
• Database Access Successful Rate (%): 数据库访问成功率
• Database Traffic (calls / min): 数据库流量(每分钟的请求次数)
• Database Access Latency Percentile (ms): 数据库访问延迟(百分位数)
• Slow Statements (ms) : 慢SQL 列表
模拟慢SQL
1. OrderController
代码块
@RequestMapping("/slowSql")
public ResponseEntity<String> slowSql(int time){
log.info("模拟慢SQL, time:{}", time);
orderService.slowSql(time);
return ResponseEntity.status(HttpStatus.OK).body("success");
}2. OrderService
代码块
void selectSleep(int time);3. OrderServiceImpl
代码块
@Override
public void selectSleep(int time) {
orderMapper.selectSleep(time);
}4. OrderMapper
代码块
@Mapper
public interface OrderMapper extends BaseMapper<OrderInfo> {
@Select("select sleep(#{time})")
Integer selectSleep(int time);
}访问接⼝, 测试
http://127.0.0.1:8083/order/slowSql?time=2
也可以通过Jemter来模拟接⼝请求
请求路径: /order/slowSql?time=${__Random(1,5)}

观察⻚⾯, 会显⽰出来慢SQL
7. ⾃定义追踪
Skywalking默认会对接⼝提供追踪, 如果我们希望对项⽬中的业务⽅法进⾏链路追踪, 就需要⾃定义追踪了.
添加依赖
代码块
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-trace</artifactId>
<version>9.4.0</version>
</dependency>添加注解@Trace
在需要监控的⽅法上添加 @Trace 注解, 就会把⽅法加⼊链路追踪⾥, 会⾃动⽣成span并记录⽅法的执⾏耗时及调⽤关系
代码块
@Trace(operationName = "queryOrder")如图所⽰:
@Trace ⽀持⾃定义span名称( operationName )以增强可读性
附加业务信息
在 SkyWalking 中, 可以使⽤ @Tag 或者 @Tags 在⾃定义链路追踪中附加关键业务或上下⽂信息的注解, ⽐如记录参数和返回信息.
在⽅法上使⽤ @Tag 或 @Tags 注解,指定需捕获的数据类型
@Override
@Trace(operationName = "queryOrder")
@Tags({
@Tag(key = "orderId",value = "arg[0]"),
@Tag(key = "orderInfo" , value = "returnedObj")
})
public OrderInfo queryOrder(Integer orderId) {
log.info("queryOrder,orderId:{}",orderId);
return orderMapper.selectById(orderId);
}arg[n]: 表⽰⽅法的第 n 个输⼊参数(从 0 开始).
returnedObj:表⽰⽅法的返回值.
添加之后, 观察span的标记
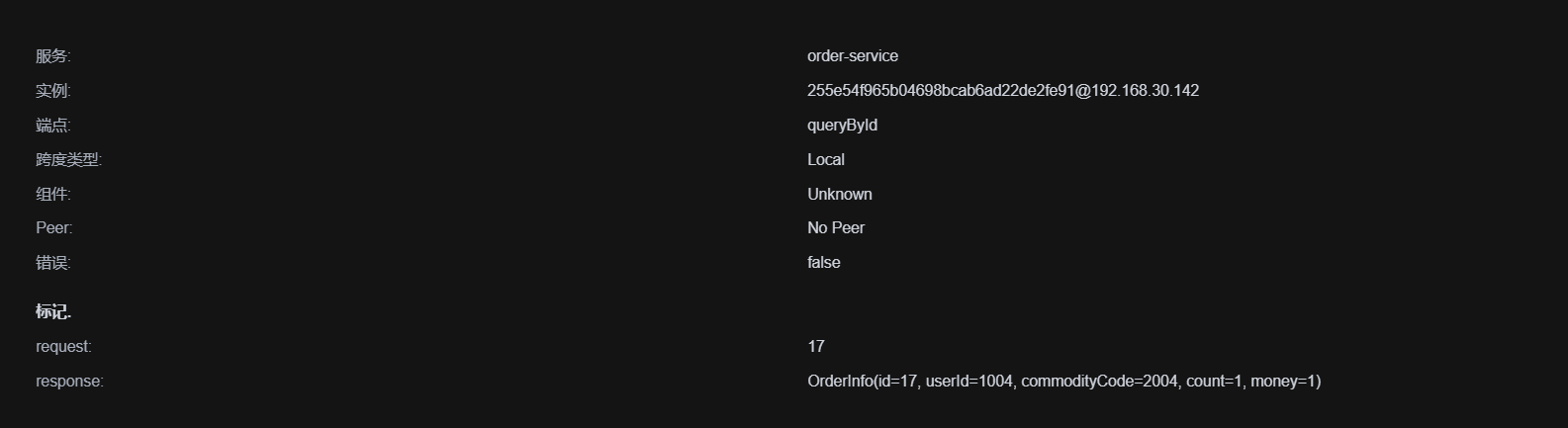
8. 性能剖析
性能剖析功能是⼀种针对分布式系统代码级性能的动态分析技术, SkyWalking 提供了追踪分析的功能, 可以查看请求调⽤链中具体⽅法或者代码块的执⾏耗时, ⽤于快速识别⾼耗时⽅法(如慢SQL查询等), 定位服务调⽤链(Trace)中具体 Span(单个操作节点)的性能问题.
新建任务
端点:需要分析的端点的名称
监控时间: 采集数据的开始时间
监控持续时间: 监控采集多⻓时间
起始监控时间: 多少秒后进⾏采集
监控间隔: 多⻓时间采集⼀次
最⼤采集数: 最⼤采集多少样本
观察剖析结果
发起请求, 观察链路的追踪情况
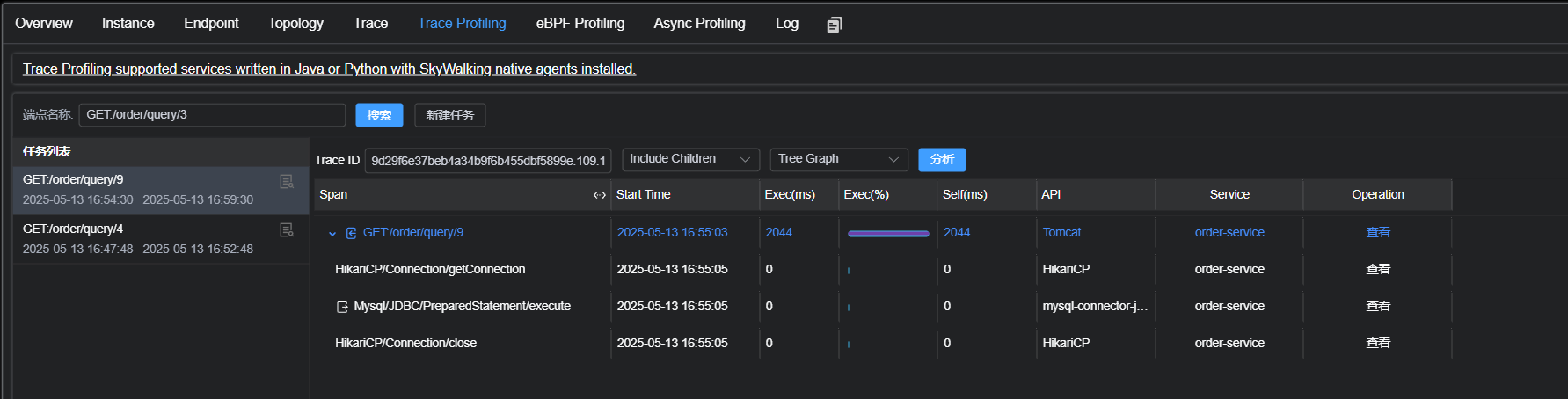
通过这个链路追踪, 可以查看各个span的执⾏时间, 选择需要分析的span, 点击 [分析] 就会出现线程栈信息
在线程栈信息中, 可以看到具体是哪部分代码引起的慢性能
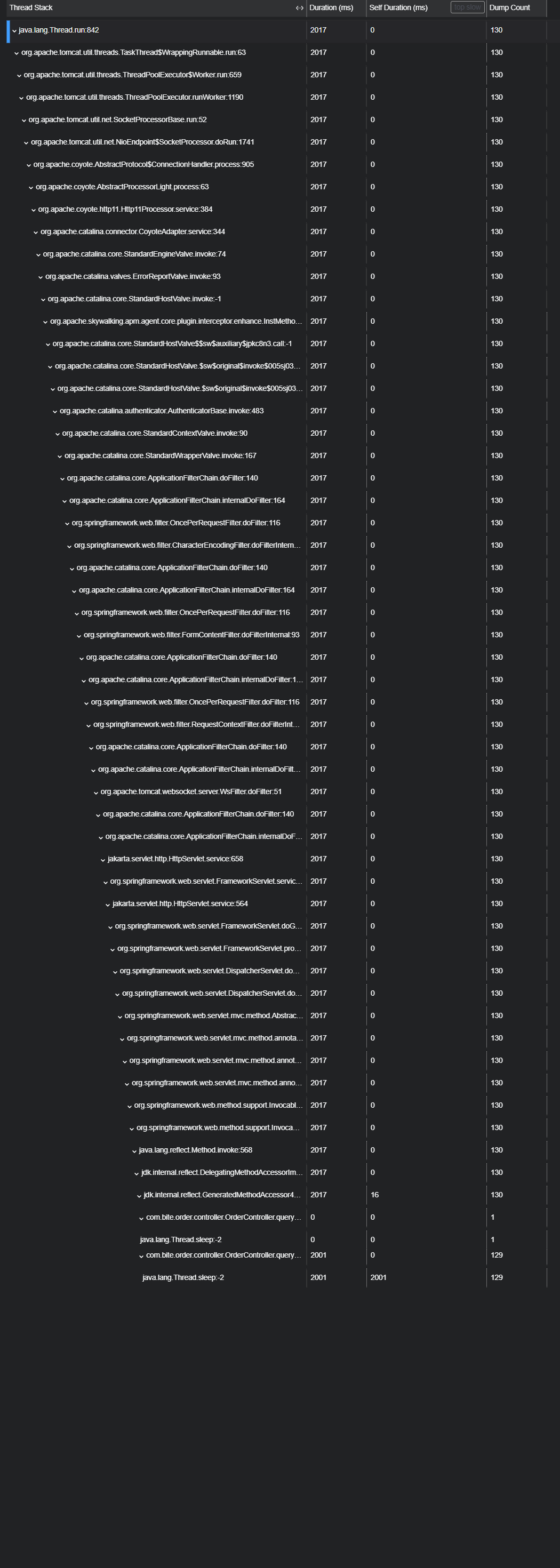
9. ⽇志上传
SkyWalking不仅⽀持链路追踪, 还可以集成⽇志数据, 帮助⽤⼾在⼀个平台上统⼀查看⽇志和追踪信息, 基于 Trace ID 实现⽇志与请求链路的⾃动关联,快速定位故障上下⽂.
配置参考: logback plugin
引⼊依赖
代码块
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-logback-1.x</artifactId>
<version>9.4.0</version>
</dependency>⽇志配置
添加 logback-spring.xml ⽂件
• Logback 框架默认加载的配置⽂件名为 logback.xml , 该名称适⽤于⾮ Spring Boot 应⽤.
• Spring Boot默认会识别logback-spring.xml, 这是Spring Boot推荐的⽅式, 优先级⾼于默认logback.xml, ⽀持 Spring 扩展特性(如 ${spring.profiles.active})
• 若同时存在 logback.xml 和 logback-spring.xml , Spring Boot 优先加载 logbackspring.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<!-- ⽇志格式化, 配置 %tid 占位符 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%tid] [%thread] %-5level %logger{36} -%msg%n</Pattern>
</layout>
</encoder>
</appender>
<!-- 通过grpc把⽇志上报到Skywalking-->
<appender name="grpc-log" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.mdc.TraceIdMDCPatternLogbackLayout">
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{tid}] [%thread] %-5level %logger{36} -%msg%n</Pattern>
</layout>
</encoder>
</appender>
<root level="info">
<appender-ref ref="STDOUT"/>
<appender-ref ref="grpc-log"/>
</root>
</configuration>重启服务, 观察⽇志

观察Skywalking UI的Log选项, 也提供了⽇志查询
可以根据TraceID 进⾏⽇志搜索, 并跳转到具体的追踪⻚⾯
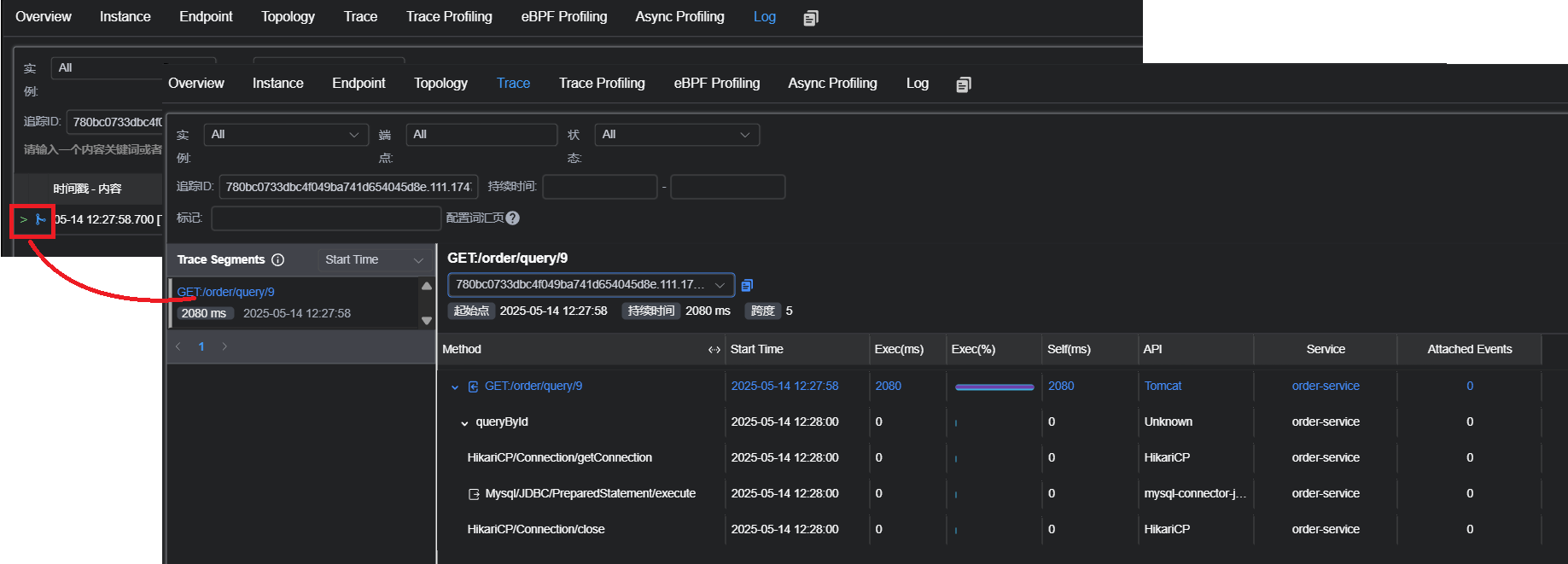
10. 告警管理
除了指标的监测之外, SkyWalking 还提供了告警功能. 当系统出现异常时(如接⼝响应慢, 成功率低), ⾃动触发通知, 帮助研发⼈员或者运维⼈员快速定位问题
类似烟雾报警器, ⼀旦检测到烟雾(系统异常), ⽴刻发出警报声(通知), 提醒你处理⽕灾(解决问题)
点击可以看到告警详情
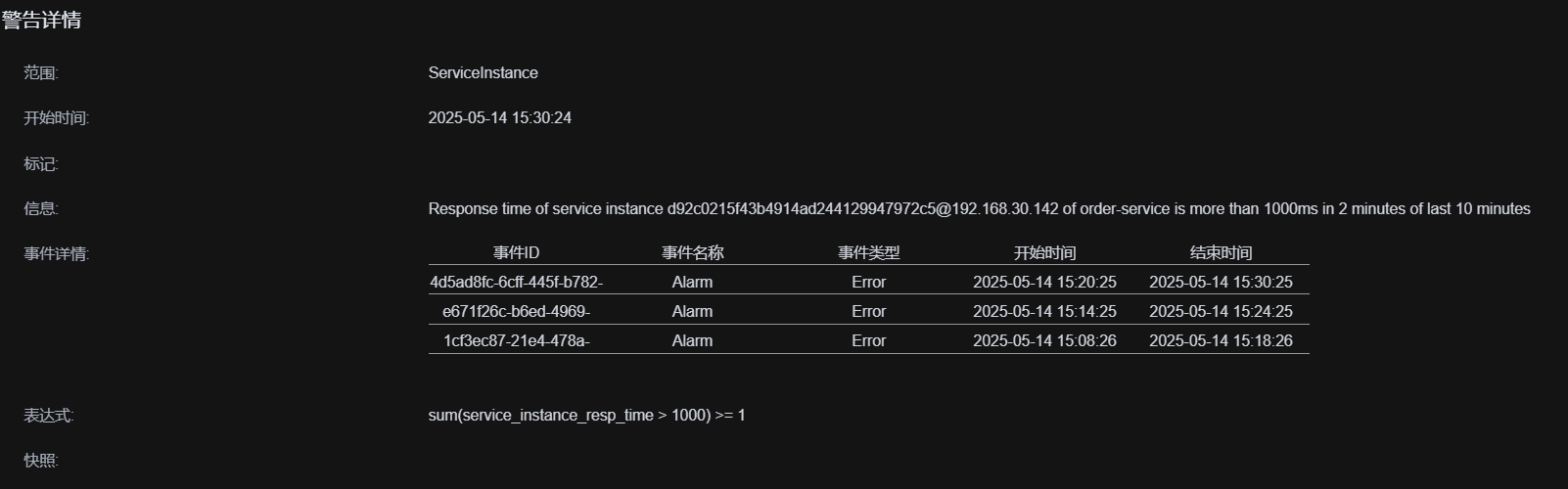
告警规则
SkyWalking 的告警系统预先定义了⼀部分告警规则, 在 config/alarm-settings.yml ⽂件中, ⽤⼾也可以⾃定义告警规则.
参考: https://skywalking.apache.org/docs/main/v10.2.0/en/setup/backend/backend-alarm
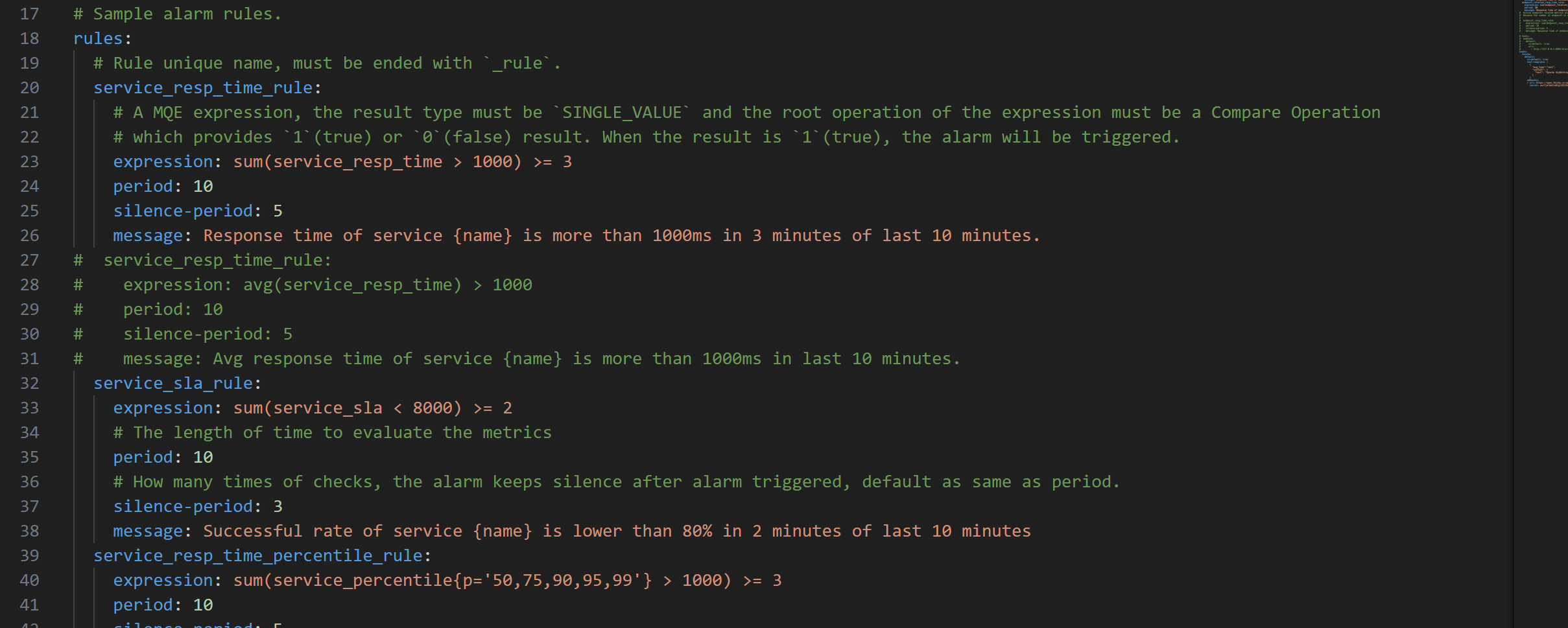
配置说明:
• XXXX_rule: 规则名称, 必须以"_rule" 结尾
• expression:告警表达式, 结果为1时, 触发报警
• period: 告警周期, 评估指标的时间⻓度(以分钟为单位)
• silence-period: 静默期, 在告警触发后, 多⻓时间内不再触发.
在Time-N (TN)触发告警后,在"TN -> TN +period"时间段内保持静默.
默认情况下, 它的⼯作⽅式与period相同. 同⼀告警在⼀个周期内只能触发⼀次
• message: 告警消息
为⽅便起⻅,SkyWalking提供了⼀个默认的alarm-setting.yml, 包括以下规则:
1. 过去 3 分钟内服务平均响应时间超过 1 秒。
2. 最近 2 分钟服务成功率低于 80%。
3. 过去 3 分钟内超过 1 秒的服务响应时间百分位数
4. 服务实例在过去 2 分钟内的平均响应时间超过 1 秒,并且实例名称与正则表达式匹配。
5. 终端节点在过去 2 分钟内的平均响应时间超过 1 秒。
6. 过去 2 分钟内数据库访问平均响应时间超过 1 秒。
7. 终端节点关系 过去 2 分钟内超过 1 秒的平均响应时间。
Webhook
webhook是⼀种允许应⽤程序向外部系统实时推送事件或数据的机制, 通常通过HTTP回调实现, 从⽽实现跨系统⾃动化的信息传递.
核⼼特征:
• 事件驱动: 当预设条件触发时(如告警触发、数据更新), 主动向⽬标 URL 发送 HTTP 请求(通常为POST)
• 轻量级集成 : 接收⽅只需提供⼀个可访问的 HTTP 端点即可接收数据, ⽆需轮询查询
• 灵活扩展 : 适⽤于告警通知, 流程触发, 数据同步等场景
SkyWalking 的 WebHook 实现
SkyWalking 提供了WebHook的⽅式, 主要⽤于告警通知. 其核⼼功能与配置要点如下:
1. 告警触发与推送
当监控指标(如响应时间、错误率等)达到告警规则阈值时, SkyWalking会⽣成告警事件, ⾃动把告警信息封装为JSON格式, 通过HTTP的⽅式发送⾄预设的WebHook接收地址.
JSON 格式定义参考:
List<org.apache.skywalking.oap.server.core.alarm.AlarmMessage>
◦ scopeId、scope: 告警⽬标的监控范围, 参考
org.apache.skywalking.oap.server.core.source.DefaultScopeDefine 中
定义
◦ Name: 告警⽬标的名称,如服务名、端点名等, 参考: Alerting
◦ id0: ⽬标实体的主要ID,通常是数据库中的主键
◦ id1: ⽬标实体的次要ID(可选),⽤于更精确的标识
◦ ruleName: 触发告警的规则名称
◦ alarmMessage: 具体的告警消息内容
◦ startTime: 告警触发的时间戳(毫秒)
◦ 标签: 标签列表,包含与告警相关的附加信息
2. WebHook配置
在 alarm-settings.yml 中定义 WebHook 地址及关联规则
代码块
hooks:
webhook:
default:
is-default: true
urls:
- http://127.0.0.1:8084/alarm/handlerurls 为接收告警的HTTP端点.
3. 典型应⽤场景
◦ 集成第三⽅系统 : 推送告警⾄钉钉, 企业微信、⻜书, 邮箱等协作⼯具.
◦ ⾃动化运维 : 触发运维脚本(如⾃动扩容)或联动故障管理系统.
◦ 数据聚合分析 : 将告警事件转发⾄⼤数据平台进⾏统计分析.
WebHook实践
配置WebHook
配置 alarm-settings.yml , 然后重启
接⼝开发
1. 创建项⽬ alarm-service, ⽤来接收WebHook
2. 核⼼代码
• 配置⽂件
server:
port: 8084
logging:
pattern:
dateformat: HH:mm:ss:SSS• 接收告警信息实体类
对应数据库 alarm_record_XXX表 AlarmMessage
@Data
public class AlarmMessage {
private int scopeId;
private String scope;
private String name;
private String id0;
private String id1;
private String ruleName;
private String alarmMessage;
private List<Tag> tags;
private long startTime;
private transient int period;
private String expression;
class Tag{
private String key;
private String value;
}
}AlarmController
@Slf4j
@RequestMapping("/alarm")
@RestController
public class AlarmController {
@RequestMapping("/handler")
public String handler(@RequestBody List<AlarmMessage> alarmMessages){
log.info("收到报警, alarmMessages:{}", alarmMessages);
return "接收报警成功";
}
}重启服务
3. 使⽤JMeter模拟请求, 触发告警
在SkyWalking UI告警⻚⾯收到告警后, 观察后端⽇志, ⽇志显⽰有收到告警信息
配置邮件告警
SkyWalking的WebHook功能, 会通过HTTP的⽅式, 把告警信息发送⾄预设的WebHook接收地址, 我们可以借此功能在这个接⼝⾥实现发送邮件或者短信等功能, 从⽽达到告警主动通知.
接下来以邮件为例
参考: Spring Boot 发送邮件
1. 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-mail</artifactId>
</dependency>2. 定义邮件配置项
spring:
mail:
# 指定邮件服务器地址
host: smtp.qq.com
# 登录账户
username: 3471714098@qq.com
# 登录密码
password: "<你的密码/授权码>"
# 端口
port: 465
# 默认编码
default-encoding: UTF-8
# 使用的协议
protocol: smtps
# 其他的属性
properties:
personal: "jqq"
"mail.smtp.connectiontimeout": 5000
"mail.smtp.timeout": 3000
"mail.smtp.writetimeout": 5000
"mail.smtp.auth": true
"mail.smtp.starttls.enable": true
"mail.smtp.starttls.required": true3. 定义邮件发送⼯具
@Slf4j
@Configuration
public class Mail {
@Autowired
private JavaMailSender javaMailSender;
@Autowired
private MailProperties mailProperties;
public void sendMail(String content){
try {
// 创建一个邮件消息
MimeMessage message = javaMailSender.createMimeMessage();
// 创建 MimeMessageHelper
MimeMessageHelper helper = new MimeMessageHelper(message, false);
String username = mailProperties.getUsername();
// 发件人邮箱和名称
helper.setFrom(username, mailProperties.getProperties().getOrDefault("personal",username));
// 收件人邮箱
helper.setTo("...");
// 邮件标题
helper.setSubject("Hello");
// 邮件正文,第二个参数表示是否是HTML正文
helper.setText(content, true);
// 发送
javaMailSender.send(message);
}catch (Exception e){
log.error("邮件发送失败,e:",e);
}
}
}4. 发送邮件
@Slf4j
@RestController
@RequestMapping("/alarm")
public class AlarmController {
@Autowired
private Mail mail;
@RequestMapping("/handler")
public String handler(@RequestBody List<AlarmMessage> alarmMessages){
log.info("接受到告警信息:{}",alarmMessages);
mail.sendMail(buildContent(alarmMessages));
return "接收到告警信息";
}
private String buildContent(List<AlarmMessage> alarmMessages) {
StringBuilder builder = new StringBuilder();
builder.append("系统告警: <br/>");
for (AlarmMessage dto : alarmMessages) {
builder.append("scopeId: ").append(dto.getScopeId())
.append("<br/>scope: ").append(dto.getScope())
.append("<br/>⽬标 Scope 的实体名称: ").append(dto.getName())
.append("<br/>Scope 实体的 ID: ").append(dto.getId0())
.append("<br/>告警规则名称: ").append(dto.getRuleName())
.append("<br/>告警消息内容: ").append(dto.getAlarmMessage())
.append("<br/>告警时间: ").append(dto.getStartTime())
.append("<br/><br/>---------------");
}
return builder.toString();
}
}5. 测试
访问请求, 触发报警, 观察发⽣告警时, 邮件是否成功

接⼊⻜书
SkyWalking的WebHook功能, 也集成了第三⽅系统, 可以通过简单的配置, 推送告警⾄Slack, 企业微信, 钉钉, ⻜书等.
接下来⻜书为例, 来演⽰接⼊⻜书
参考: 接⼊⻜书
1. 注册⻜书账号
2. 创建机器⼈
打开⻜书群组 → 点击右上⻆「设置」→「群机器⼈」→「添加机器⼈」→ 选择「⾃定义机器⼈」
配置机器⼈名称, 获取⽣成的 Webhook URL(格式为 https://open.feishu.cn/openapis/bot/v2/hook/xxxxxx )
3. 配置webHook
hooks:
feishu:
default:
is-default: true
text-template: |
{
"msg_type":"text",
"content": {
"text": "Apache SkyWalking Alarm: \n %s."
}
}
webhooks:
- url: https://open.feishu.cn/open-apis/bot/v2/hook/53966bf9-a35a-4c38-b506-a6ee2c5d65d7
secret: asv7jwl6eSlw8Cg13Qt2Gc4. 测试告警推送
模拟请求, 触发告警,观察⻜书收到告警消息


















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









