 Spring AI与智能聊天机器人开发
Spring AI与智能聊天机器人开发





目录
1. Spring AI 概述
认识AI:
AI, ⼈⼯智能(Artificial Intelligence) , 是指通过计算机系统模拟⼈类智能的技术, 通过这种技术, 他可以实现⼈类的认知和思维活动, 从⽽可以完成许多复杂的任务, ⽐如学习, 推理决策等. 本质就是通过算法和数据, 让机器具备类⼈能⼒.
随着科技的发展, AI 已逐渐成为我们⽣活的⼀部分, 在现代社会中的应⽤已经变得越来越⼴泛. 在⽇常⽣活和⼯作中, 也能感受到AI给我们带来的便利性, 以及对我们⽣活的影响.
• 医疗领域: 可以利⽤AI技术来分析医学影像识别病灶
• ⾦融领域: 可以利⽤AI技术来⽣成投资话术和组合策略, 以及⻛险管理, 欺诈检测, 信⽤评估等.
• 制造业: 通过AI图像识别检查产品缺陷, 使⽤AI监测设备运⾏数据, 进⾏预测性维护
• 交通领域: 通过AI技术, 融合传感器数据实现智能驾驶, 路径规划优化驾驶路线.
• 教育领域: 利⽤AI学情分析定制学习路线, 提升教学效率.
• ......
⼈⼯智能技术的发展已经成为了推动社会进步的重要⼒量, 未来AI技术的应⽤将会更加⼴泛.
思考题: AI 是否等同于 ⼈⼯智能
AI 是⼈⼯智能的英⽂缩写, 从这个⻆度来看, AI等同于⼈⼯智能.
在⽇常表达中, AI 和⼈⼯智能⼜是有⼀点区别的. AI 通常指通过计算机程序模拟⼈类智能, 使计算机能够像⼈类⼀样具备处理, 理解和学习能⼒. ⼈⼯智能是指通过⼈⼯制造出具有⼈类智能的实体, ⽐如机器⼈. 从这个⻆度来看的话, ⼈⼯智能更注重实体的制造和控制.
AI的发展简史:
⼈⼯智能(AI)并⾮近年来突然出现的技术奇迹, 实际上它的思想萌芽可以追溯到上世纪40年代. 就像⼀棵⼤树的⽣⻓需要经历种⼦、幼苗到枝繁叶茂的过程, AI的发展也经历了多个关键阶段:
1. 萌芽期 (1940s-1950s)
• 1943年 :⻨卡洛克-⽪茨神经元模型(⾸个⽤数学模拟神经元的理论)
• 1950年 :图灵发表《计算机器与智能》, 提出"图灵测试"(定义机器智能标准)
2. ⻩⾦时代 (1956-1970s)
• 1956年 :达特茅斯会议 (约翰·⻨卡锡⾸次提出"⼈⼯智能"术语)
• 1966年 :ELIZA聊天机器⼈ (⾸个模拟⼼理治疗的对话系统)
• 1968年 :斯坦福国际研究所开发Shakey机器⼈ (⾸个具备感知和⾏动能⼒的⾃主机器⼈)
3. 复兴期 (1980s-2000s)
• 1980年 :XCON专家系统 (DEC公司⽤于配置计算机的商业化成功案例)
• 1997年 :IBM深蓝击败国际象棋世界冠军 (⾸次在复杂策略游戏战胜⼈类)
• 2006年 :杰弗⾥·⾟顿提出深度学习理论 (开启神经⽹络新时代)
4. 爆发期 (2010s-⾄今)
• 2012年 :AlexNet在ImageNet竞赛夺冠 (验证深度学习图像识别潜⼒)
• 2016年 :AlphaGo战胜李世⽯ (引发全球AI热潮)
• 2022年 :ChatGPT发布 (⽣成式AI普及化⾥程碑)
• 2025年: DeepSeek-R1发布
每个阶段的突破都建⽴在前⼈积累之上, 正如计算机科学家Alan Kay所说:"预测未来的最好⽅式, 就是发明它."
参考: ⼀⽂概览⼈⼯智能(AI)发展历程
Spring AI 是什么?
2025年 5⽉20⽇ Spring AI官⽅宣布1.0 GA (General Availability) 版本正式发布, 这是Spring 官⽅推出的⾸个稳定版⼈⼯智能(AI)集成框架. 旨在帮助 Java/Spring 开发者更便捷地在企业级应⽤中集成 AI 能⼒ (如⼤语⾔模型、机器学习、向量数据库、图像⽣成等). 它的发布标志着 Spring ⽣态正式进⼊ AI 时代, 为 Java 开发者提供了标准化的 AI 开发⼯具链, AI 技术正式进⼊ Spring ⽣态的核⼼⼯具链.
官⽹地址: Spring AI
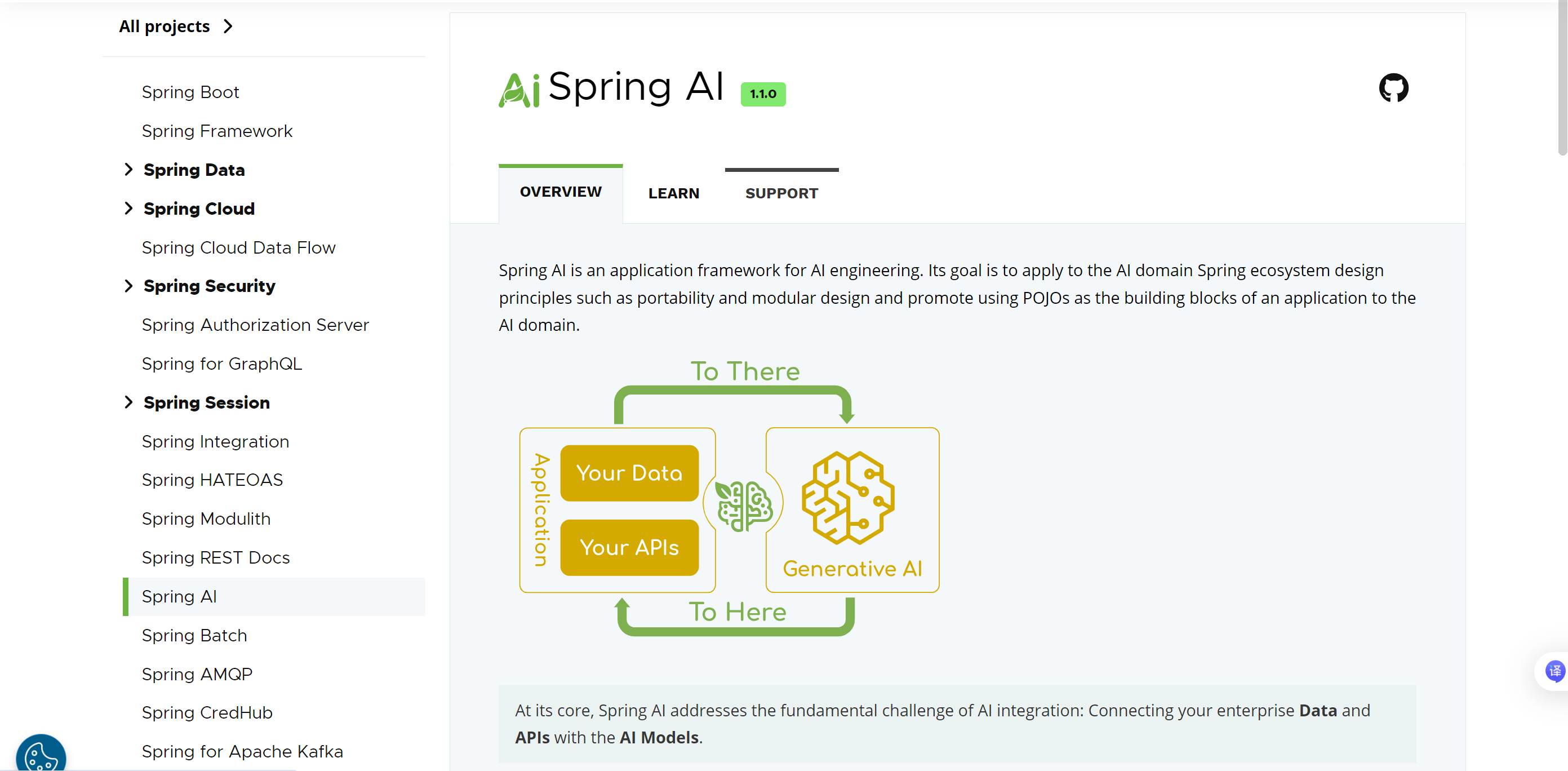
Spring AI 是⼀个AI⼯程领域的应⽤框架, 它的⽬标是将 Spring ⽣态系统的设计原则 (如可移植性和模块化设计) 应⽤于 AI 领域, 并促进使⽤POJO作为AI领域应⽤程序的构建块.
Spring AI 提供以下功能:
• ⽀持主要的AI模型提供商, ⽐如 Anthropic、OpenAI、Microsoft、Amazon、Google 和 Ollama,⽀持的模型种类也⾮常多, ⽐如: 聊天模型, 嵌⼊模型, 图像模型, ⾳频模型, 内容审核等.
• 跨 AI 提供商的可移植 API ⽀持. ⽀持聊天 (Chat) , ⽂本到图像 (text-to-image) 和嵌⼊(Embedding) 模型的统⼀接⼝, 同时提供同步和流式 API 选项. ⽀持访问模型特定功能.
总之, Spring AI 为 ⾮AI专家的开发者也能快速调⽤⼤语⾔模型, 提供了构建 AI 应⽤的基础抽象层, 允许开发⼈员通过极少的代码修改即可轻松替换组件. 简化集成AI功能的应⽤程序开发, 避免不必要的复杂性.
2. 术语介绍
模型
模型旨在处理和⽣成信息的算法, 通常模仿⼈类的认知功能. 通过从⼤型数据集中学习模式和洞察, 这些模型可以进⾏预测、⽣成⽂本、图像或其他输出, 从⽽增强各个⾏业的各种应⽤. ⽐如ChatGPT、⽂⼼⼀⾔、通义千问等等. 每种模型能⼒不同, 适合的任务也不同.
可以简单理解为模型是⼀个"超级加⼯⼚", 这个⼯⼚是经过特殊训练的, 训练师给它看了海量的例⼦(数据), 并告诉它该怎么做. 通过看这些例⼦, 它⾃⼰摸索出了⼀套规则, 学会了完成某个"特定任务". 模型就是⼀套学到的"规则"或者"模式",它能根据你给的东西, 产⽣你想要的东西.
我们给的东西就称之为: 输⼊ 模型产出的结果, 就称之为输出
Spring AI 的作⽤ 就是让我们在 Java/Spring 应⽤中, 能⾮常⽅便地:
• 选择不同的 模型
• 构造和发送 输⼊ (Prompt).
• 接收并处理 输出 (AI 的响应)
LLM
LLM(Large Language Model), ⼤语⾔模型, 也称⼤型语⾔模型, 是⼈⼯智能模型中专⻔处理⽂本的⼀种类型, 属于语⾔模型的范畴. LLM的特点是规模庞⼤, 包含数⼗亿的参数, 在⼤量的⽂本数据上进⾏训练, 学习语⾔数据中的复杂模式, 旨在理解和⽣成⼈类语⾔. 可以执⾏⼴泛的任务, 包括⽂本总结、翻译、情感分析等.
简单介绍⼏种⽬前主流的⼤语⾔模型 (LLM) :
• GPT-5(OpenAI)
◦ ⽀持 128K⻓上下⽂ , 在多轮复杂推理、创意写作中表现突出
• DeepSeek R1(深度求索)
◦ 开源, 专注于逻辑推理与数学求解, ⽀持128K⻓上下⽂和多语⾔ (20+语⾔) , 在科技领域表现突出
• Qwen2.5-72B-Instruct (阿⾥巴巴)
◦ 通义千问开源模型家族重要成员, 擅⻓代码⽣成结构化数据 (如JSON) 处理⻆⾊扮演对话等, 尤其适合企业级复杂任务, ⽀持包括中⽂英⽂法语等29种语⾔
• Gemini 2.5 Pro (Google)
◦ 多模态融合标杆 , ⽀持图像/代码/⽂本混合输⼊, 适合跨模态任务 (如图⽂⽣成、技术⽂档解析)
提⽰词
提⽰词是⽤⼾或系统提供给⼤语⾔模型 (LLM) 的指令或⽂本 , ⽤于引导模型⽣成特定输出. 可以理解为模型的输⼊, ⽆论是⼀个单词、⼀个问题、⼀段描述, 还是结构化指令, 都可视为提⽰词.
提⽰词最初是为引导⼤语⾔模型 (如GPT、Claude等) ⽽设计的, 但其核⼼逻辑(通过结构化输⼊控制输出) 可泛化到许多其他场景.
⽐如多模态系统的混合输⼊, 当⼤模型处理图像、⾳频时, ⾃然语⾔提⽰词需与其他模态数据协同输⼊, 输⼊设计草图+⽂字, 提⽰词为: "⽣成⽹⻚前端代码"
从⼯程视觉来看, 提⽰词分为⽤⼾提⽰词和系统提⽰词
| 类型 | 定义 | 核⼼功能 | ⽰例 |
| ⽤⼾提⽰词 | 由终端⽤⼾直接输⼊, 触发单次任务 | 传达即时需求 (如提问、创作指令) | ⽤⼾输⼊:"总结这篇论⽂的核⼼观点" |
| 系统提⽰词 | 由开发者预设, 嵌⼊系统后端 | 定义模型⻆⾊、⾏为规范、知识边界 | 预设:"你是⼀名严谨的学术助⼿, 回答需引⽤权威⽂献" |
系统提⽰词如同"操作系统", 持续影响所有交互 (如⻆⾊设定、安全过滤), ⽤⼾提⽰词如同"操作指令", 驱动单次任务执⾏ (如⽣成报告、翻译⽂本) .
词元(Tokens)
词元是⼤语⾔模型 (LLM) 处理⽂本时的最⼩语义单位. ⽤于将⽂本拆解为模型可理解的离散单元.
如同乐⾼积⽊是搭建模型的基础, Tokens 是语⾔模型处理信息的"原⼦"
词元通过分词器将⽂本拆分⽽来, 不同模型的分词规则不同, 同⼀个词在不同模型中可能被拆分成不同词元.
模型的上下⽂窗⼝ (如128K) 实际是词元数量限制, API收费通常按词元数计费(词元=⾦钱), 词元数越多, 计算耗时和内存占⽤越⾼. 所以在使⽤时, 应尽量避免冗余词(如请, 谢谢)
https://cloud.tencent.com/developer/news/2468793
3. Spring AI 快速⼊⻔
环境要求
• JDK
◦ 最低要求 : JDK 17+ (Spring Boot 3.x 强制要求)
◦ 推荐版本 :
▪ JDK 21 (2023年 LTS 版本, ⽀持虚拟线程/分代 ZGC, 性能提升显著)
▪ JDK 17 (旧项⽬过渡⽅案)
• Spring Boot
◦ 最低要求 : Spring Boot 3.2+ (Spring AI 1.0.0 起强制依赖)
◦ 推荐版本 :
▪ Spring Boot 3.4.x (最新稳定版, 优化企业级特性)
▪ Spring Boot 3.3.x (部分旧项⽬兼容⽅案)
准备⼯作:
DeepSeek介绍:
DeepSeek (深度求索) 是由杭州深度求索⼈⼯智能基础技术研究有限公司推出的⼈⼯智能品牌, 专注于⼤语⾔模型 (LLM) 及相关技术的研发与应⽤. ⾃2023年成⽴以来, 凭借前沿技术架构与开源策略迅速崛起, 成为全球AI领域的重要⼒量.
DeepSeek 以开源和⾼效推理为核⼼竞争⼒, 主要模型包括:
• DeepSeek-R 系列 (如 R1) : 专注复杂推理的模型, 数学、代码能⼒突出, ⽀持深度思考模式 (⾼智能推理状态)
DeepSeek-R1于2025年1⽉发布, 并同步开源模型权重, 性能逼近OpenAI o1, 推理成本仅为⼏⼗分之⼀, 登顶全球多国应⽤商店下载榜 , 在美区下载榜上超越了ChatGPT.
• DeepSeek-V 系列(如V2, V3): 通⽤语⾔模型, ⽀持⽂本⽣成、多轮对话等任务, 性能对标 GPT-4Turbo4.
DeepSeek V2模型因在中⽂综合能⼒评测中的出⾊表现, 且以极低的推理成本引发⾏业关注, 被称为"AI界的拼多多".
• DeepSeek-Coder:专注于代码⽣成与补全, ⽀持多语⾔编程 (Python, Java等) , 强化学习优化, 训练成本仅为同类模型的 1/30.
DeepSeek的特点:
• 完全开源:模型代码、权重公开, 兼容 OpenAI API 接⼝
• 极致性价⽐:推理成本仅为同类模型的 1/7 (如对⽐ Llama3-70B) , 训练成本低⾄ 560 万美元 (仅为⾏业平均的 1/3) .
DeepSeek 作为国产⼤模型的标杆产品, 其⾼性能与易⽤性吸引⼤量企业进⾏技术整合(涉及领域覆盖通信, 能源, ⾦融, 汽⻋, 科技等). 我们可以通过 Spring AI 框架快速实现 DeepSeek 的能⼒接⼊, 显著降低 AI 集成⻔槛.
申请DeepSeek API Keys
在DeepSeek官⽹平台, 创建API Key
1. 点击 [API开放平台], 进⼊API开放平台, 注册⽤⼾
2. 注册之后, ⾃⾏充值 充值前需要先进⾏实名认证
3. 创建API Keys
💡 API key 仅在创建时可⻅可复制, 请妥善保存. 不要与他⼈共享你的 API key, 或将其暴露在浏览器或其他客⼾端代码中
4. DeepSeek API⽂档
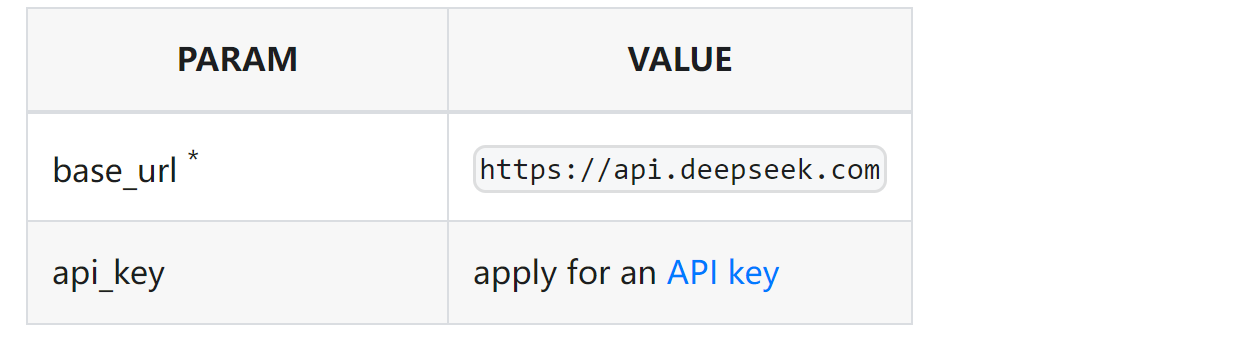
参考: ⾸次调⽤ API | DeepSeek API Docs
Spring AI 的 openai starter 本质上是通过 RestTemplate 发送请求.
项⽬初始化
创建⽗⼯程
1. 创建⼀个空的Maven项⽬, 删除所有代码, 只保留pom.xml
⽬录结构:

2. 完善pom⽂件
添加依赖, 声明⽗⼯程的打包⽅式为pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>spring-ai-project</artifactId>
<version>1.0-SNAPSHOT</version>
<modules>
<module>spring-ai-demo</module>
</modules>
<!-- 声明⽗⼯程的打包⽅式为pom -->
<packaging>pom</packaging>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
</properties>
<!-- 完善依赖 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
</project>创建⼦项⽬
声明项⽬依赖 和 项⽬构建插件
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>添加Spring AI BOM
1. 依赖说明
• ⾥程碑版本-使⽤ Maven Central
从1.0.0-M6 版本开始, 发布版本已在 Maven Central 提供. 我们在构建时⽆需任何改动.
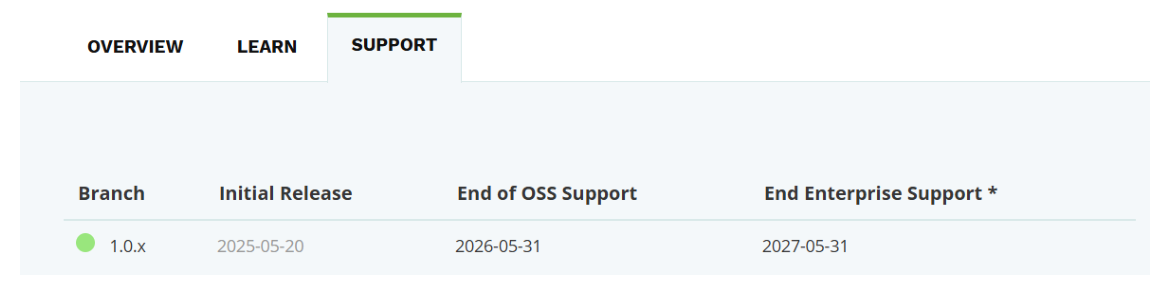
• Snapshot 版本 - 添加 Snapshot 仓库
要使⽤ Snapshot 版本(以及 1.0.0-M6 之前的⾥程碑版本), 需要在构建⽂件中添加以下 Snapshot 仓库
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>当在 Maven 中使⽤ Spring AI Snapshot 版本时, 需要注意Maven 镜像配置. 如果在 settings.xml中配置了如下所⽰的镜像:
<mirror>
<id>my-mirror</id>
<mirrorOf>*</mirrorOf>
<url>https://my-company-repository.com/maven</url>
</mirror>通配符 * 将把所有仓库请求重定向到设置的镜像, 从⽽阻⽌访问 Spring Snapshot 仓库. 可以通过修改 mirrorOf 配置以排除 Spring 仓库.
<mirror>
<id>my-mirror</id>
<mirrorOf>*,!spring-snapshots,!central-portal-snapshots</mirrorOf>
<url>https://my-company-repository.com/maven</url>
</mirror>这个配置允许 Maven 直接访问 Spring Snapshot 仓库, 同时仍使⽤你设置的镜像获取其他依赖项.
2. 依赖管理
Spring AI 提供了⼀个物料清单(BOM), ⾥⾯声明了给定Spring AI版本所使⽤的依赖项的推荐版本. 它只包含依赖管理, 不包含插件声明或对 Spring 或 Spring Boot 的直接引⽤. 可以通过Parent继承, 也可以通过 dependencyManagement 导⼊.
添加BOM 到项⽬中
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-M6</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>BOM (Bill of Materials) 的核⼼概念是通过集中式版本管理解决依赖冲突问题, 其本质是特殊的 POM ⽂件.
通过 <dependencyManagement> 定义⼀组相互兼容的依赖版本集合, 本⾝不包含代码实现. BOM 维护⽅确保清单内所有依赖版本经过兼容性验证, 避免开发者在多模块项⽬中⼿动协调版本冲突.
完善代码
• 启动类
@SpringBootApplication
public class SpringAIApplication {
public static void main(String[] args) {
SpringApplication.run(SpringAIApplication.class,args);
}
}• 创建配置⽂件 application.yml
spring:
application:
name: spring-ai-demo接⼊DeepSeek
Spring AI ⽣态专⻔为OpenAI及兼容API服务(如DeepSeek)设计了Starter spring-ai-openaispring-boot-starter , ⽤于快速集成⼤语⾔模型能⼒到 Spring Boot 应⽤中.
核⼼价值包括:
• 简化配置:⾃动封装 OpenAI API 的请求/响应等逻辑
• 统⼀接⼝:提供 ChatClient 等标准化接⼝, ⽀持⽆缝切换不同模型提供商
• Spring ⽣态集成:与 Spring Boot 的⾃动配置、依赖注⼊等特性深度整合
添加依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>配置API密钥
在applicaition.yml中配置
spring:
application:
name: spring-ai-demo
ai:
openai:
api-key:
base-url: https://api.deepseek.com
chat:
options:
model: deepseek-chat
temperature: 0.7在DeepSeek开放平台申请的API key
spring.ai.openai.chat.options.temperature: 默认值0.8. ⽤于控制⽣成补全内容的多样性. 值越⾼, 输出越随机, 值越低, 结果越集中和确定. 不建议在同⼀个补全请求中同时修改 temperature 和 top_p, 因为这两个设置的交互作⽤难以预测.
deepseek-chat 模型指向 DeepSeek-V3-0324, 通过指定 model='deepseek-chat' 调⽤.
deepseek-reasoner 模型指向 DeepSeek-R1-0528, 通过指定 model='deepseekreasoner' 调⽤.
更多配置项参考:Chat Properties
对应翻译: DeepSeek Chat :: Spring AI 参考 - Spring 框架
编写接⼝
Spring AI已经集成了OpenAI的API, 因此我们不需要实现向OpenAI发送请求和接收响应的交互程序了,Spring AI已经实现了这⼀内容, 我们只需要通过调⽤Spring AI为我们提供的接⼝即可.
@RestController
@RequestMapping("/ds")
public class DeepSeekChatController {
@Autowired
private OpenAiChatModel openAiChatModel;
@GetMapping("/chat")
public String generate(String message){
return openAiChatModel.call(message);
}
}测试
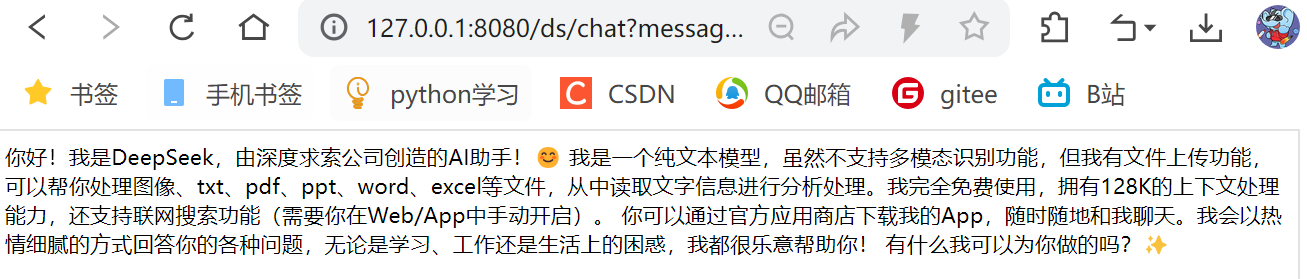
访问接⼝: http://127.0.0.1:8080/ds/chat?message=你是谁
接⼊ChatGPT
OpenAI 是⼀个⼈⼯智能研究实验室和公司, 致⼒于推动⼈⼯智能技术的安全发展和普惠应⽤. ChatGPT 是 OpenAI 开发并发布的核⼼产品之⼀ , 是基于其⾃研的 GPT 系列模型构建的对话式 AI 应⽤. Spring AI ⽀持 OpenAI 的各种 AI 语⾔模型.
准备⼯作
⾸先需要使⽤OpenAI创建⼀个API来访问ChatGPT模型
1. 注册账号 Open AI 注册⻚⾯
2. 创建API keys
访问 API Keys ⻚⾯, 创建API Keys
复制⽣成的API key, 并保存, 后续⽆法查
添加依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>配置API 密钥
使⽤OpenAI 官⽅Key的时候, 不需要配置baseUrl
需要保证你的本地环境可以访问 https://api.openai.com
spring:
ai:
openai:
api-key: your-api-keysbase-url 默认为 https://api.openai.com 使⽤模型为 GPT-3.5
编写接⼝
1. 编写接⼝
@RestController
@RequestMapping("/openai")
public class OpenAIChatController {
@Autowired
private OpenAiChatModel openAiChatModel;
@GetMapping("/chat")
public String generate(String message){
return openAiChatModel.call(message);
}
}
2. 配置系统属性
本地开发时, 即使配置了代理, 有时候也⽆法让你的Spring AI应⽤正常请求api, 这通常是代理软件⽆法让你的整个系统实现全局代理造成的, 你只需要在启动类中加⼊下述代码即可
System.setProperty("http.proxyHost","127.0.0.1"); //修改为你代理服务器的IP
System.setProperty("https.proxyHost","127.0.0.1");
System.setProperty("http.proxyPort","7897"); // 修改为你代理软件的端⼝
System.setProperty("https.proxyPort","7897"); // 同理测试
访问接⼝: http://127.0.0.1:8080/openai/chat?message=你是谁
💡 OpenAI 和DeepSeek 使⽤的接⼝⼀致, 区别只是配置和上⽹⽅式, 学习时, 掌握其中⼀个即可.
4. Spring AI-聊天模型
Spring AI 的聊天模型, 通过标准化的接⼝设计, 使开发⼈员可以将AI模型的聊天功能集成到应⽤程序中. 它利⽤预先训练的语⾔模型, 例如 GPT (Generative Pre-trained Transformer), 以⾃然语⾔⽣成类似⼈类的响应.
API 的⼯作原理通常是向 AI 模型发送提⽰或部分对话, 然后 AI 模型根据其训练数据和对⾃然语⾔模式的理解⽣成响应. 然后, 把响应将返回给应⽤程序, 应⽤程序可以将其呈现给⽤⼾或将其⽤于进⼀步处理.
在Spring AI框架中, ChatModel和ChatClient是构建对话式AI应⽤的两⼤核⼼接⼝. 上⾯我们使⽤了ChatModel完成了与AI模型的交互, 接下来我们对这两个接⼝分别进⾏介绍.
ChatClient
ChatClient 是 Spring AI 框架中封装复杂交互流程的⾼阶 API 接⼝ , 旨在简化开发者与⼤语⾔模型 (如 GPT、通义千问等) 的集成过程. ChatClient 提供了与 AI 模型通信的 Fluent API, 它⽀持同步和反应式 (Reactive) 编程模型, 将与 LLM 及其他组件交互的复杂性进⾏封装, 给⽤⼾提供开箱即⽤的服务.ChatClient是基于ChatModel的封装 Fluent API流畅接口,链式调用
实现简单对话
根据⽤⼾输⼊的消息, 进⾏响应.
为了⽅便测试, 我们使⽤deepseek来给⼤家演⽰.
1. 创建ChatClient, 并注⼊
使⽤ ChatClient.Builder 来创建ChatClient 对象.
private ChatClient chatClient;
// 通过构造方法注入ChatClient
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
//设置系统提示词
.defaultSystem("你是JQQ,你是智能AI助手,主要是回答相关编程问题")
.build();
}2. 使⽤ChatClient
@GetMapping("/call")
String generation(String userInput) {
return this.chatClient.prompt()
//用户输入(用户提示词)
.user(userInput)
//调用大模型
.call()
//返回响应
.content();
}把⽤⼾输⼊的内容设置为⽤⼾消息的内容, call ⽅法向 AI 模型发送请求, content ⽅法以字符串
的形式返回 AI 模型的响应.
3. 测试
访问接⼝: http://127.0.0.1:8080/chat/call?userInput=你是谁
⻆⾊预设
我们应⽤程序接⼊DeepSeek之后, 也可以设置⾃⼰智能助⼿的名字, ⽐如问⼩⽩
1. 配置⻆⾊
在Spring AI的 ChatClient.Builder 中, defaultSystem() ⽅法⽤于设置AI模型的默认系统消息 (System Message) , 它会作为对话的基础⻆⾊设定或初始指令. 通过ChatClient.Builder链式调⽤设置后, 该⽅法定义的⽂本会作为系统消息注⼊到每次对话的上下⽂中, ⽤于引导AI的回复⻛格或⾝份设定.
我们通过 defaultSystem 来配置系统⻆⾊
private ChatClient chatClient;
// 通过构造方法注入ChatClient
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
//设置系统提示词
.defaultSystem("你是JQQ,你是智能AI助手,主要是回答相关编程问题")
.build();
}为了⽅便在其他地⽅也可以使⽤, 可以把chatClient 单独定义
@Configuration
public class ChatClientConfiguration {
@Bean
public ChatClient chatClient(ChatClient.Builder chatClientBuilder) {
return chatClientBuilder
//设置系统提示词
.defaultSystem("你是JQQ,你是智能AI助手,主要是回答相关编程问题")
//记录所有经过Advisors的日志,对所有的请求进行设置,也可以加到调用中,那么就只会对那个接口的调用起作用,和提示词类似
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
}2. 编写Controller
@RestController
@RequestMapping("/chat")
public class ChatClientController {
@Autowired
private ChatClient chatClient;
@GetMapping("/call")
String generation(String userInput) {
return this.chatClient.prompt()
//用户输入(用户提示词)
.user(userInput)
//调用大模型
.call()
//返回响应
.content();
}
}3. 测试
访问接⼝: http://127.0.0.1:8080/chat/call?userInput=你是谁
结构化输出
如果您想从 LLM 接收结构化输出, Spring AI⽀持将 ChatModel/ChatClient ⽅法的返回类型从 String 更改为其他类型.
通过 entity() ⽅法将模型输出转为⾃定义实体, 需确保输出格式符合JSON规范.
1. 需求
通过Spring AI 来⽣成菜单
2. 编写代码
借助JDK16提供的新关键词 record 来定义⼀个实体类
// 定义结构
record Recipe(String dish, List<String> ingredients){}
//结构化输出
@RequestMapping("/entity")
public String entity(String userInput){
Recipe recipe = chatClient.prompt()
.user(String.format("请帮我生成%s的食谱", userInput))
.call()
.entity(Recipe.class);
return recipe.toString();
}3. 测试
访问接⼝: http://127.0.0.1:8080/chat/entity?userInput=回锅⾁
访问接⼝: http://127.0.0.1:8080/chat/entity?userInput=西红柿炖⽜腩
实现流式输出
⽤⼾和⼤模型进⾏交互时, 由于⼤模型⼀次输出内容较多, 等待全部内容⽣成完毕会导致⽤⼾等待时间过⻓, 这对⽤⼾的体验⾮常不友好. 可以采⽤流式输出的⽅式(例如ChatGPT和DeepSeek逐字显⽰回答).
1. 流式输出介绍
⼤模型流式输出(Streaming Output)是通过逐步⽣成内容⽽⾮⼀次性返回完整结果的技术. Spring AI 使⽤ ChatClient 的 stream() ⽅法⽣成 Flux<String> 流, 适⽤于需要更轻量级客⼾端控制
的场景.
• 适合场景: 实时对话, 代码补全, ⻓⽂本⽣成.
2. 代码实现
//流式输出,但是返回是乱码,需要设置编码格式
@GetMapping(value = "/stream",produces = "text/html;charset=utf-8")
public Flux<String> stream(String userInput) {
return this.chatClient.prompt()
//用户输入(用户提示词)
.user(userInput)
//调用大模型
.stream()
//返回响应
.content();
}3. 测试
访问: http://127.0.0.1:8080/chat/stream?userInput=你是谁
打印⽇志
Spring AI 借助Advisors 来实现⽇志打印的功能.
Advisors介绍
Spring AI中的Advisors是介于⽤⼾请求与AI模型之间的中间件组件, 它的核⼼功能就是对请求进⾏拦截过滤和增强, 帮助我们在API调⽤前后解决各种问题, 例如调⽤前参数如何构建, 调⽤后结果如何处理.
Spring AI 中的 Advisors 是基于 AOP思想实现的, 在具体实现上进⾏了领域适配. 其设计核⼼借鉴了 Spring AOP 的拦截机制, 各个Advisor以链式结构运⾏, 序列中的每个Advisor都有机会对传⼊的请求和传出的响应进⾏处理. 这种链式处理机制确保了每个Advisor可以在请求和响应流中添加⾃⼰的逻辑, 从⽽实现更灵活和可定制的功能.
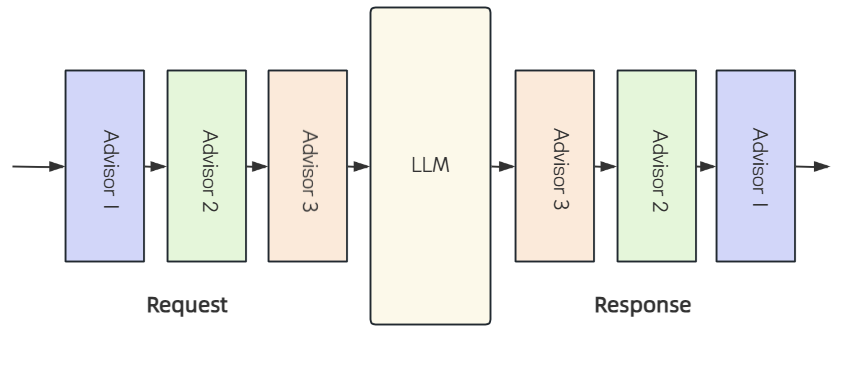
应⽤场景:
• 敏感词过滤
• 建⽴聊天历史
• 对话上下⽂管理
SimpleLoggerAdvisor
Spring AI 内置了⼀些Advisor, SimpleLoggerAdvisor 作为其中之⼀, 主要功能是记录⽇志. 使⽤⾮常简单, 开发⼈员只需把它添加到Advisor链中, 即可⾃动记录所有经过该Advisor的聊天请求和响应, 并且开发⼈员可以对其进⾏配置, ⽐如⽇志级别和⽇志格式.
1. 添加 SimpleLoggerAdvisor 到 Advisor链中
可以通过 defaultAdvisors ⽅法 来设置, 通过这种⽅式设置的Advisor会作⽤于ChatClient发起的
每⼀次对话
@Configuration
public class ChatClientConfiguration {
@Bean
public ChatClient chatClient(ChatClient.Builder chatClientBuilder) {
return chatClientBuilder
//设置系统提示词
.defaultSystem("你是JQQ,你是智能AI助手,主要是回答相关编程问题")
//记录所有经过Advisors的日志,对所有的请求进行设置,也可以加到调用中,那么就只会对那个接口的调用起作用,和提示词类似
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
}也可以为每⼀次的对话设置advisor. 如果default也设置了同⼀类型的Advisor, 那么对话级别的优先级⾼于default.
@GetMapping("/call")
public String generation(String userInput) {
return this.chatClient.prompt()
//⽤⼾输⼊的信息
.user(userInput)
.advisors(new SimpleLoggerAdvisor())
//请求⼤模型
.call()
//返回⽂本
.content();
}2. 配置⽇志级别
logging:
pattern:
console: "%d{HH:mm:ss.SSS} %c %M %L [%thread] %m%n"
file: "%d{HH:mm:ss.SSS} %c %M %L [%thread] %m%n"
level:
org.springframework.ai.chat.client.advisor: debug3. 测试, 观察⽇志
流式编程
SSE协议介绍
HTTP协议本⾝设计为⽆状态的请求-响应模式, 严格来说, 是⽆法做到服务器主动推送消息到客⼾端, 但通过Server-Sent Events (服务器发送事件, 简称SSE)技术可实现流式传输,允许服务器主动向浏览器推送数据流.
也就是说, 服务器向客⼾端声明, 接下来要发送的是流消息(streaming), 这时客⼾端不会关闭连接, 会⼀直等待服务器发送过来新的数据流.
SSE(Server-Sent Events)是⼀种基于 HTTP 的轻量级实时通信协议, 浏览器通过内置的EventSource API接收并处理这些实时事件.
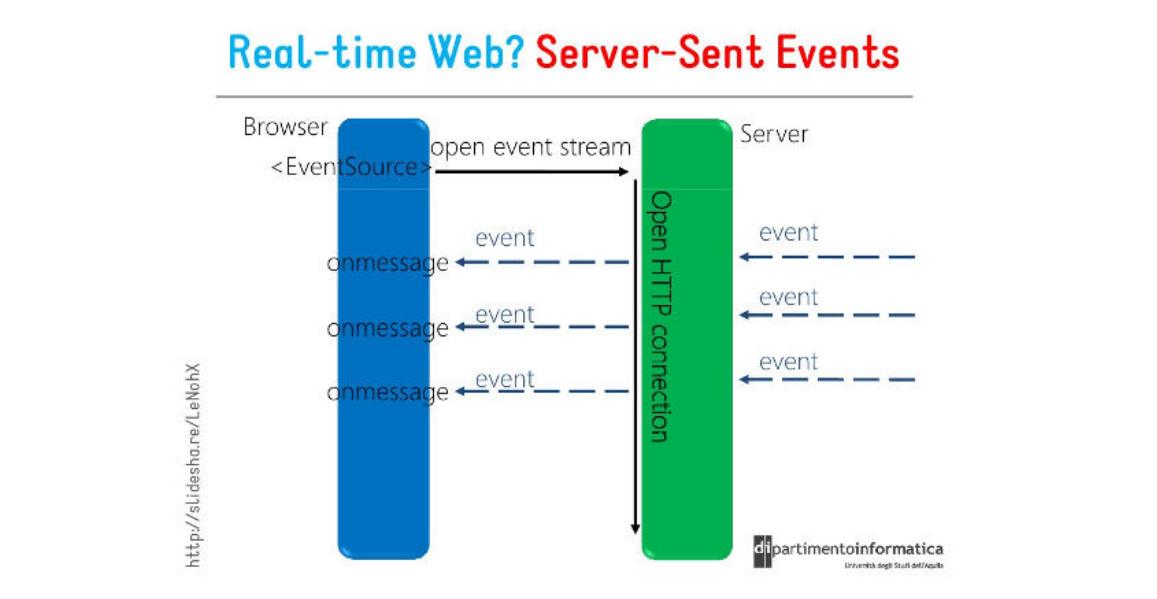
核⼼特点
• 基于 HTTP 协议
复⽤标准 HTTP/HTTPS 协议, ⽆需额外端⼝或协议, 兼容性好且易于部署
• 单向通信机制
SSE 仅⽀持服务器向客⼾端的单向数据推送,客⼾端通过普通 HTTP 请求建⽴连接后,服务器可持续发送数据流,但客⼾端⽆法通过同⼀连接向服务器发送数据.
• ⾃动重连机制
⽀持断线重连, 连接中断时,浏览器会⾃动尝试重新连接(⽀持 retry 字段指定重连间隔)
• ⾃定义消息类型
客⼾端发起请求后, 服务器保持连接开放, 响应头设置 Content-Type: text/event-stream , 标识为事件流格式, 持续推送事件流.
数据格式
服务端向浏览器发送SSE数据, 需要设置必要的HTTP头信息
Content-Type: text/event-stream;charset=utf-8
Connection: keep-alive每⼀次发送的消息, 由若⼲个message组成, 每个message之间由 \n\n 分隔, 每个message内部由若⼲⾏组成, 每⼀⾏都是如下格式
[field]: value\nField 可以取值为:
• data[必需]: 数据内容
• event[⾮必需]: 表⽰⾃定义的事件类型,默认是message事件
• id[⾮必需]:数据标识符, 相当于每⼀条数据的编号
• retry[⾮必需]: 指定浏览器重新发起连接的时间间隔
除此之外, 还可以有冒号 : 开头的⾏, 表⽰注释.
数据⽰例:
event: foo\n
data: a foo event\n\n
data: an unnamed event\n\n
event: end\n
data: a bar event\n\n服务端实现
@RequestMapping("/data")
public void data(HttpServletResponse response) throws IOException, InterruptedException {
// 每发20次就断开了,但是sse会申请重连然后求重新发
System.out.println("发起请求:data");
response.setContentType("text/event-stream;charset=utf-8");
PrintWriter writer = response.getWriter();
for (int i = 0; i < 20; i++) {
String s = "data: "+ new Date() + "\n\n";
writer.write(s);
writer.flush();
Thread.sleep(1000L);
}
}客⼾端API
<div id ="sse"></div>
<script>
let eventSource = new EventSource("/sse/stream")
eventSource.onmessage = function(event){
document.getElementById("sse").innerHTML = event.data;
}
// 自定义事件
// eventSource.addEventListener("foo",(event)=>{
// document.getElementById("sse").innerHTML = event.data;
// });
// eventSource.addEventListener("end",(event)=>{
// eventSource.close();
// });
</script>Spring 中SSE实现
Spring 4.2 开始就已经⽀持SSE,从Spring 5开始我们可以使⽤WebFlux 更优雅的实现SSE协议. Flux是WebFlux的核⼼API.
可以把Flux想象成⼀条传送带
• 异步传送 :数据像快递包裹⼀样逐个到达, 不⽤等全部到⻬
• 灵活加⼯ :⽀持中途修改数据 (如过滤/转换)
• 弹性控制 :接收⽅可以调速 (背压机制)
快速使⽤
Flux的流程分为三个步骤:
1. 创建Flux
创建⼀个Flux数据流, 并有数据源.
2. 处理数据
使⽤操作符对数据进⾏处理
3. 订阅数据
订阅Flux来消费数据, 触发数据的流动 ⽰例:
public class FluxDemoTest {
public static void main(String[] args) throws InterruptedException {
//创建flux流 delayElements延迟发射
Flux<String> flux = Flux.just("Apple","Banana","Cherry","Pear").delayElements(Duration.ofSeconds(1));
//处理flux流 map可以处理元素
//subscribe订阅数据
//当我们进⾏订阅时, Flux数据才会流动
flux.map(String::toUpperCase).map(s->s+"-1").subscribe(System.out::println);
Thread.sleep(5000);
}
}创建Flux
使⽤Flux.just(...) 创建⼀个包含指定元素的Flux
Flux<String> fruitFlux = Flux.just("Apple", "Banana", "Cherry");也有其他的创建⽅式, ⽐如 fromIterable 和 range
//从集合 (如 List、Set) 创建
Flux.fromIterable(Arrays.asList(1, 2, 3))
//⽣成 1~5的Flux
Flux.range(1, 5)处理数据
fruitFlux.map(String::toUpperCase) // 将每个字符串转为⼤写
.filter(s -> s.startsWith("A")); //筛选出以A开头的元素常⻅的操作符:
| 操作 | 作⽤ | ⽰例代码⽚段 |
| map() | 元素⼀对⼀转换 | .map(String::toUpperCase) |
| filter() | 条件过滤 | .filter(s -> s.length() > 5) |
| take() | 限制元素数量 | .take(2) // 只取前2个元素 |
| merge() | 合并多个Flux(不保证顺序) | Flux.merge(Flux.just("A"), Flux.just("B")) |
| concat() | 顺序拼接多个 Flux (保证顺序) | Flux.concat(Flux.just("A"), Flux.just("B")) |
| delayElements | 延迟元素发射 | .delayElements(Duration.ofSeconds(1)) |
订阅数据
当我们进⾏订阅时, Flux数据才会流动
Flux<String> fruitFlux = Flux.just("Apple", "Banana", "Cherry");
Flux<String> newFlux = fruitFlux.map(String::toUpperCase) // 将每个字符串转为⼤写
.filter(s -> s.startsWith("A"));//筛选出以A开头的元素
newFlux.subscribe(System.out::println);流式响应接⼝
需求: 每隔⼀秒向客⼾端输出当前时间.
@RequestMapping(value = "/stream",produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> stream(){
return Flux.interval(Duration.ofSeconds(1)).map(s->new Date().toString());
}代码块
let eventSource = new EventSource("/sse/stream")
eventSource.onmessage = function(event){
document.getElementById("sse").innerHTML = event.data;
}ChatModel
上⾯介绍了ChatClient接⼝的使⽤, 接下来看下ChatModel.
概述
在⼊⻔案例中, 我们使⽤的就是ChatModel
@RestController
@RequestMapping("/ds")
public class DeepSeekChatController {
@Autowired
private OpenAiChatModel openAiChatModel;
@GetMapping("/chat")
public String generate(String message){
return openAiChatModel.call(message);
}
}以下是ChatModel的定义
public interface ChatModel extends Model<Prompt, ChatResponse>, StreamingChatModel {
default String call(String message) {
Prompt prompt = new Prompt(new UserMessage(message));
Generation generation = this.call(prompt).getResult();
return generation != null ? generation.getOutput().getText() : "";
}
default String call(Message... messages) {
Prompt prompt = new Prompt(Arrays.asList(messages));
Generation generation = this.call(prompt).getResult();
return generation != null ? generation.getOutput().getText() : "";
}
ChatResponse call(Prompt prompt);
default ChatOptions getDefaultOptions() {
return ChatOptions.builder().build();
}
default Flux<ChatResponse> stream(Prompt prompt) {
throw new UnsupportedOperationException("streaming is not supported");
}
}
ChatModel 是Spring AI 构建对话应⽤的核⼼接⼝, 它抽象了应⽤与模型交互的过程, 包括使⽤ Prompt 作为输⼊, 使⽤ ChatResponse 作为输出等. ChatModel 的⼯作原理是接收 Prompt 或部分对话作为输⼊, 将输⼊发送给后端⼤模型, 模型根据其训练数据和对⾃然语⾔的理解⽣成对话响应, 应⽤程序可以将响应呈现给⽤⼾或⽤于进⼀步处理
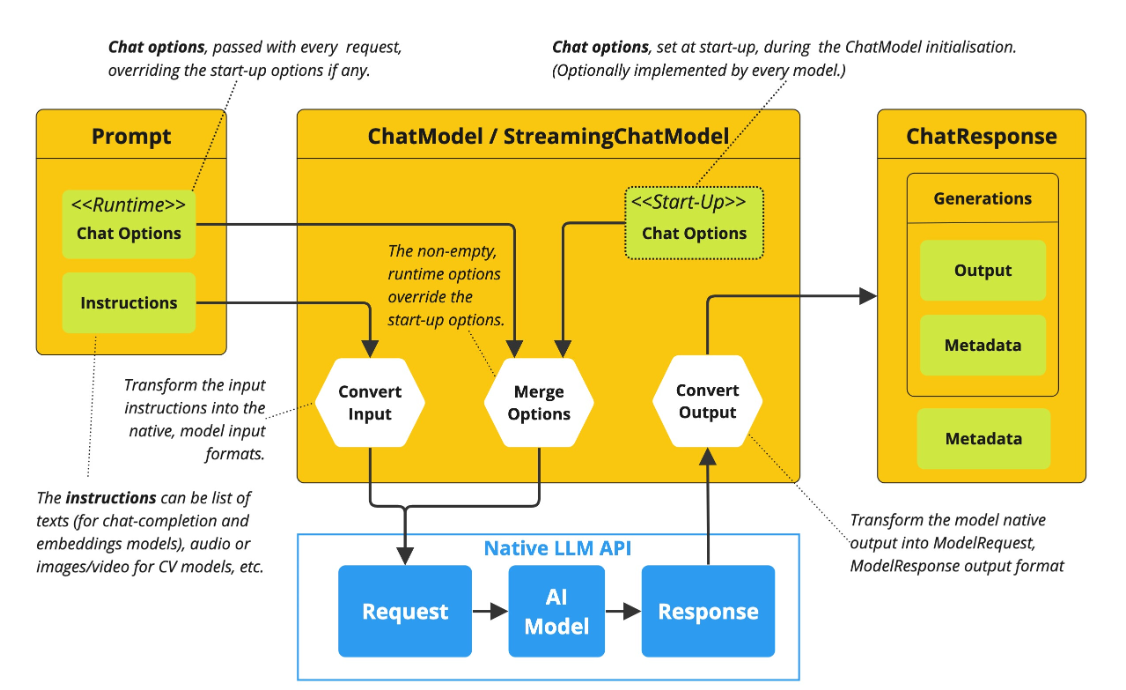
String call(String message) ⽅法就是对 message进⾏了封装, 简化了ChatModel 的初始化使⽤, 避免了更复杂的Prompt输⼊和ChatResponse输出, 本质上调⽤的依然是 ChatResponsecall(Prompt prompt)
default String call(String message) {
Prompt prompt = new Prompt(new UserMessage(message));
Generation generation = this.call(prompt).getResult();
return generation != null ? generation.getOutput().getText() : "";
}ChatClient 本质上也是基于ChatModel 进⾏的封装和增强.
public interface ChatClient {
static ChatClient create(ChatModel chatModel) {
return create(chatModel, ObservationRegistry.NOOP);
}
static ChatClient create(ChatModel chatModel, ObservationRegistry observationRegistry) {
return create(chatModel, observationRegistry, null);
}
static Builder builder(ChatModel chatModel) {
return builder(chatModel, ObservationRegistry.NOOP, null);
}
}实现简单对话
在⼊⻔案例⾥, 我们使⽤了ChatModel的 String call(String message) 和⼤模型进⾏了交互, 接下来我们看下 ChatResponse call(Prompt prompt) 的使⽤.
• 编写代码
@RequestMapping("/chatByPrompt")
public String chatByPrompt(String message){
Prompt prompt = new Prompt(message);
ChatResponse response = chatModel.call(prompt);
return response.getResult().getOutput().getText();
}• 测试
接⼝: http://127.0.0.1:8080/ds/callByPrompt?message=祝满意
⻆⾊预设
在 Spring AI 中, ChatModel ⽀持通过 Prompt 预设⻆⾊ , 这是引导模型输出特定⻛格或专业内容的核⼼技术⼿段.
1. 编写代码
在Prompt 中通过 System Message 明确设定⻆⾊⾝份
@RequestMapping("/role")
public String role(String message){
SystemMessage systemMessage = new SystemMessage("你是JQQ,你是智能AI助手,主要是回答相关编程问题");
UserMessage userMessage = new UserMessage(message);
Prompt prompt = new Prompt(systemMessage,userMessage);
ChatResponse response = chatModel.call(prompt);
return response.getResult().getOutput().getText();
}2. 测试
实现流式输出
ChatModel 也提供了stream ⽅法来实现流式输出
@RequestMapping(value = "/stream",produces = "text/html;charset=utf-8")
public Flux<String> stream(String message){
Prompt prompt = new Prompt(message);
Flux<ChatResponse> response = chatModel.stream(prompt);
return response.map(s->s.getResult().getOutput().getText().toString());
}ChatClient 和ChatModel区别
ChatClient 和ChatModel 是Spring AI 框架提供的与⼤语⾔模型(LLM)交互的两⼤核⼼接⼝. 但⼆者设计理念和适⽤场景不太⼀样.
• ChatModel 是Spring AI 框架中的底层接⼝, 直接与具体的⼤语⾔模型 (如通义千问、OpenAI) 交互,提供基础的 call 和 stream ⽅法, 开发者需⼿动处理提⽰词组装、参数配置和响应解析等细节,在使⽤上相对更加灵活.
ChatResponse response = openAiChatModel.call(new Prompt(message));
return response.getResult().getOutput().getText();• ChatClient 对ChatModel进⾏了封装, 相⽐如ChatModel 原⼦类API,ChatClient屏蔽了与AI⼤模型
的交互的复杂性, 它⾃动集成提⽰词管理、响应格式化、结构化输出映射等能⼒, 提⾼了开发效率.
Recipe recipe = this.chatClient.prompt()
//⽤⼾输⼊的信息
.user(String.format("请帮我⽣成%s的⻝谱", userInput))
//请求⼤模型
.call()
//返回⽂本
.entity(Recipe.class);能⼒对⽐:
| 维度 | ChatModel | ChatClient |
| 交互⽅式 | ⼿动构建Prompt, 解析响应 | 链式API, ⾃动封装请求与响应 |
| 结构化输出 | ⼿动解析⽂本 | ⽀持 .entity(Class) ⾃动映射POJO |
| 扩展能⼒ | 依赖外部组件 | 内置Advisor机制, 提供更⾼级的功能, 如提供上下⽂记忆, RAG等功能 |
| 适合场景 | 适合需要精细控制模型参数的场景, ⽐如模型实验, 参数调优等定制需求 | 适合快速构建AI服务, 如带记忆的客服系统 |
5. 本地⼤模型部署
随着⼤语⾔模型 (LLM) 的⼴泛应⽤, 如何⾼效部署和推理模型成为开发者关注的核⼼问题, 常⻅的部署⽅案有云服务部署和本地部署.
部署⽅案对⽐
云服务部署, 在云服务平台的机器上部署⼤模型, 本地部署则是指在本地机器上进⾏部署⼤模型.
| 维度 | 云部署 | 本地部署 |
| 费⽤ | 前期成本低, ⻓期成本⾼ | 前期成本⾼, ⻓期成本低 |
| 维护 | 简单 | 复杂 |
| 弹性扩展 | 简单 | 复杂, 定制性⾼ |
| ⽹络 | 依赖⽹络, 全球访问 | 不依赖⽹络 |
| 数据安全 | 隐私性差 | 数据安全 |
常⻅云服务平台介绍
如果不需要对模型进⾏训练, 微调, 仅仅是想使⽤预调好的⼤模型进⾏应⽤开发, 很多模型提供商也提供了开放API, ⽐如上⾯讲的DeepSeek和ChatGPT, 直接调⽤他们的API即可.
国内很多知名的云服务平台提供了⼤模型的私有部署功能(提供预置模型库, 不同⼚商预置的模型库也不同), 可以按任务需求选择基础版本或者微调版本, 甚⾄还提供了这些模型的API开放平台, ⽆需部署就可以访问.
| 云平台 | 公司 | 地址 |
| 阿⾥百炼 | 阿⾥巴巴 | https://bailian.console.aliyun.com/ |
| 千帆平台 | 百度 | https://cloud.baidu.com/product-s/qianfan_home |
| 腾讯TI平台 | 腾讯 | https://cloud.tencent.com/product/ti |
| 华为昇腾云 | 华为 | https://www.huaweicloud.com/product/ecs/ascend.html |
本地部署
⼤模型本地部署, 就是把⼤模型部署到我们本地的机器上. 由于⼤模型的参数很多, 使⽤普通⽅法部署⼤模型很不友好, 所以诞⽣了⼀些本地部署的框架/⼯具来帮助我们部署⼤模型.
常⻅的本地部署框架/⼯具有:
• Transformers
• vLLM
• llama.cpp
• Ollama
• LM Studio
• ......
这些⾥⾯, 操作⽐较简单的⼀种⽅案就是使⽤Ollama.
下载并安装Ollama
Ollama 是⼀款专为本地部署和运⾏⼤型语⾔模型 (LLM) 设计的开源⼯具, 旨在简化⼤型语⾔模型 (LLM) 的安装、运⾏和管理. 它⽀持多种开源模型(如qwen、deepseek、LLaMA), 并提供简单的 API 接⼝, ⽅便开发者调⽤, 适合开发者和企业快速搭建私有化 AI 服务.
Ollama 官⽹: https://ollama.ai
1. 下载Ollama
2. 安装Ollama
下载完成之后, ⼀步⼀步安装即可
3. 验证
安装完成后, Ollama默认会启动. 访问: http://127.0.0.1:11434
或者使⽤cmd 访问 ollama --version
拉取模型
Ollama可以管理和部署模型, 我们使⽤之前, 需要先拉取模型
• 修改模型存储路径
模型默认安装在C盘个⼈⽬录下 C:\Users\XXX\.ollama , 可以修改ollama的模型存储路径, 使得
每次下载的模型都在指定的⽬录下. 有以下两种⽅式
1. 配置系统环境变量
变量名: OLLAMA_MODELS
变量值: ${⾃定义路径}
2. 通过Ollama 界⾯来进⾏设置
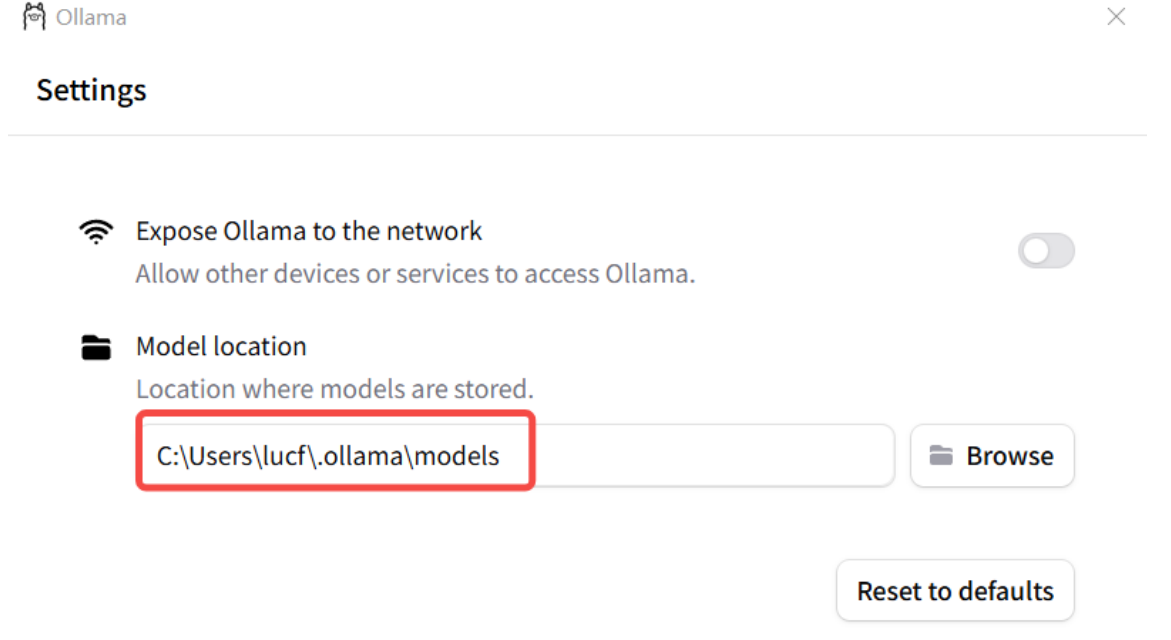
设置完成后, 重启 Ollama
• 拉取模型
查找模型: https://ollama.com/search
以 DeepSeek-R1 为例, DeepSeek-R1 是⼀系列开放推理模型, 其性能接近 O3 和 Gemini 2.5 Pro
等领先模型.
DeepSeek-R1 DeepSeek-R1 有不同的版本, 我们需要根据⾃⼰机器的配置及需求来选择相应的版本.分为 1.5b , 7b , 8b 等, "b" 是 "Billion" (⼗亿) 的缩写, 代表模型的 参数量级. 671b 表⽰ "满⾎"版本, 其他版本称为"蒸馏"版本.
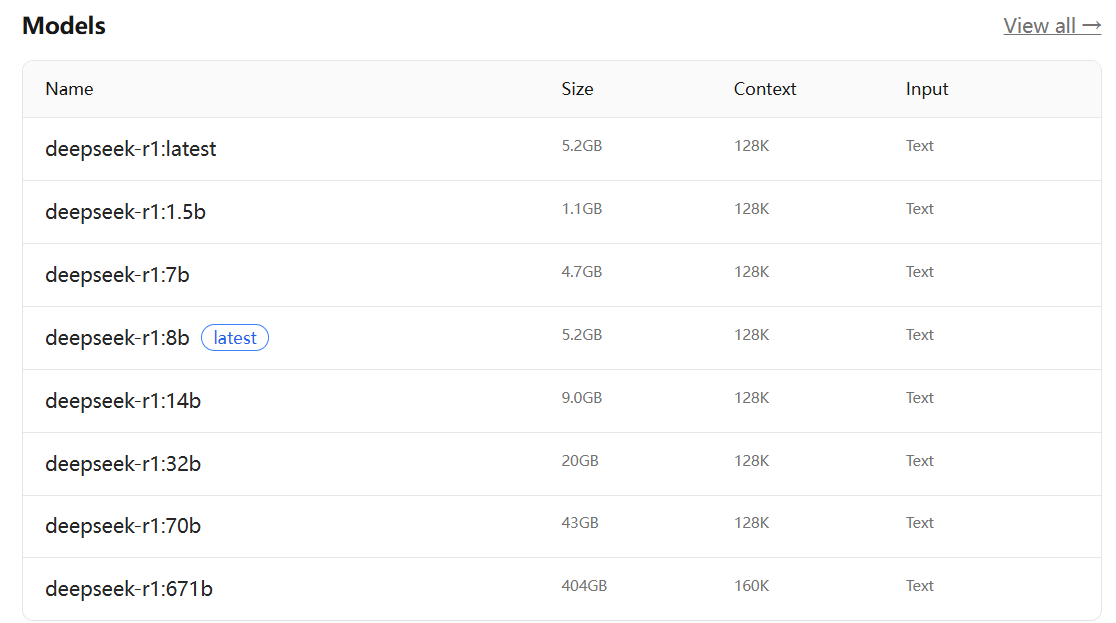
参数越多 → 模型"知识量"越⼤ → 处理复杂任务的能⼒越强, 硬件需求也越⾼.
根据需求及电脑配置, 选择合适的模型版本, 以 1.5b 为例
ollama run deepseek-r1:1.5b下载完成之后, 就会出现命令⾏, 可以通过命令⾏和AI模型对话

Spring AI接⼊服务
创建项⽬
创建模块 spring-ollama-demo , 完善pom⽂件和启动类
• pom⽂件
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
• 启动类
@SpringBootApplication
public class SpringAIOllamaApplication {
public static void main(String[] args) {
SpringApplication.run(SpringAIOllamaApplication.class,args);
}
}添加依赖
添加Spring AI 和Ollama的依赖
Spring AI
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-M6</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>Ollama
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>配置⽂件
application.yml
server:
port: 8081
spring:
application:
name: spring-ai-ollama-demo
ai:
ollama:
base-url: http://localhost:11434
chat:
model: deepseek-r1:1.5b
logging:
pattern:
console: "%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"
file: "%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"简单对话
OllamaController.java
@RequestMapping("/ollama")
@RestController
public class OllamaController {
@Autowired
private OllamaChatModel ollamaChatModel;
@RequestMapping("/chat")
public String chat(String message){
return ollamaChatModel.call(message);
}
}接⼝测试: http://127.0.0.1:8081/ollama/chat?message=你是谁
流式响应
编写接⼝
@RequestMapping(value = "/stream",produces = "text/html;charset=utf-8")
public Flux<String> stream(String message){
return ollamaChatModel.stream(message);
}接⼝测试: http://127.0.0.1:8081/ollama/stream?message=你是谁
封装成ChatClient
封装成Client
@Configuration
public class CommonConfiguration {
@Bean
public ChatClient chatClient(OllamaChatModel model){
return ChatClient
.builder(model)
.defaultSystem("你叫JQQ, 是⼀款智能机器⼈, 来解决\n" +
"学⽣在学习Java过程中遇到的⼀些问题~")
.build();
}
}编写接⼝
@RequestMapping("/chat")
@RestController
public class ChatClientController {
private final ChatClient chatClient;
public ChatClientController(ChatClient chatClient){
this.chatClient = chatClient;
}
@RequestMapping("/role")
public String role(String prompt){
return chatClient.prompt().user(prompt).call().content();
}
}6. Spring AI Alibaba
Spring AI Alibaba概述
随着⽣成式 AI 的快速发展, 基于 AI 开发框架构建 AI 应⽤的诉求迅速增⻓, 涌现出了包括 LangChain、LlamaIndex 等开发框架, 它们为 Python 开发者提供了⽅便的 API 抽象. 但这些开发框架对于国内习惯了 Spring 开发范式的 Java 开发者⽽⾔, 并⾮⼗分友好和丝滑. 因此, 我们基于 Spring AI 发布并快速演进 Spring AI Alibaba, 通过提供⼀种⽅便的 API 抽象, 帮助 Java 开发者简化 AI 应⽤的开发, ⼀步迈⼊ AI 原⽣时代.
引⽤⾃: 重磅发布!AI 驱动的 Java 开发框架:Spring AI Alibaba
Spring AI Alibaba 开源项⽬基于 Spring AI 构建, 是阿⾥云通义系列模型及服务在 Java AI 应⽤开发领域的最佳实践, 提供⾼层次的 AI API 抽象与云原⽣基础设施集成⽅案, 帮助开发者快速构建 AI 应⽤.
如果你在⽤阿⾥云的其他服务, Spring AI Alibaba 能很好对接, 天然⽣态整合, 少折腾.
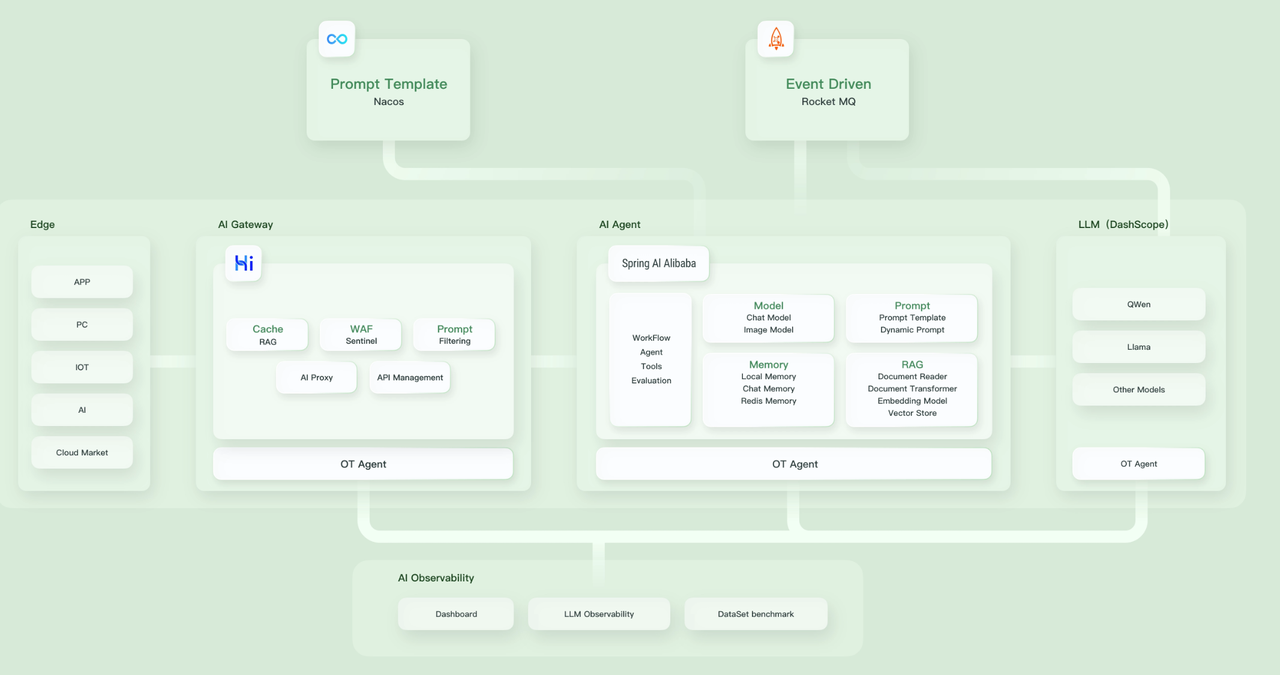
Spring AI Alibaba 作为开发 AI 应⽤程序的基础框架, 定义了以下抽象概念与 API, 并提供了 API 与通义系列模型的适配.
• 开发复杂 AI 应⽤的⾼阶抽象 Fluent API — ChatClient
• 提供多种⼤模型服务对接能⼒, 包括主流开源与阿⾥云通义⼤模型服务 (百炼) 等
• ⽀持的模型类型包括聊天、⽂⽣图、⾳频转录、⽂⽣语⾳等
• ⽀持同步和流式 API, 在保持应⽤层 API 不变的情况下⽀持灵活切换底层模型服务, ⽀持特定模型的定制化能⼒ (参数传递)
• ⽀持 Structured Output, 即将 AI 模型输出映射到 POJOs
• ⽀持⽮量数据库存储与检索
• ⽀持函数调⽤ Function Calling
• ⽀持构建 AI Agent 所需要的⼯具调⽤和对话内存记忆能⼒
• ⽀持 RAG 开发模式, 包括离线⽂档处理如 DocumentReader、Splitter、Embedding、VectorStore 等, ⽀持 Retrieve 检索
快速上⼿
Spring AI Alibaba 实现了与阿⾥云通义模型的完整适配, 接下来, 我们将学习如何使⽤ Spring AI Alibaba 基于通义模型服务进⾏智能聊天.
因为 Spring AI Alibaba 基于 Spring Boot 3.x 开发, 因此本地 JDK 版本要求为 17 及以上
申请阿⾥云百炼平台API-KEY
阿⾥云的⼤模型服务平台百炼是⼀站式的⼤模型开发及应⽤构建平台. 我们可以借助百炼平台, 调⽤⼤模型, 与⼤模型对话, 实现内容创作, 摘要⽣成等.
当我们需要通过API或SDK⽅式调⽤⼤模型及应⽤时, 需要获取⼀个合法的 API-KEY 并设置 AI_DASHSCOPE_API_KEY 环境变量
可参考:如何获取API Key_⼤模型服务平台百炼(Model Studio)-阿⾥云帮助中⼼
1. 开通阿⾥百炼的模型服务
访问阿⾥云百炼平台 ⼤模型服务平台百炼控制台
登录后, 开通模型服务.
⾸次开通阿⾥云百炼时, 平台会⾃动发放各模型的新⼈专属免费额度.
开通阿⾥云百炼不会产⽣费⽤, 仅模型调⽤ (超出免费额度后) 、模型部署、模型调优模型会产⽣相应计费
如果开通服务时提⽰"您尚未进⾏实名认证", 请先进⾏实名认证.

2. 获取API Key
前往API-Key⻚⾯, 在我的⻚签 下单击创建我的API-KEY

在创建新的API-KEY弹窗中, 选择API Key归属的业务空间, 填写描述信息, 并单击确定.
学习阶段使⽤默认业务空间即可.
描述:建议填写具有实际意义的内容, 以便准确识别API Key的⽤途

创建项⽬
创建项⽬参考: 快速开始-阿⾥云Spring AI Alibaba官⽹官⽹
- pom文件
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>@SpringBootApplication
public class AlibabaApplicationDemo {
public static void main(String[] args) {
SpringApplication.run(AlibabaApplicationDemo.class, args);
}
}添加依赖
需要在项⽬中添加 spring-ai-alibaba-starter 依赖, 它将通过 Spring Boot ⾃动装配机制初始化与阿⾥云通义⼤模型通信的 ChatClient、ChatModel 相关实例.
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>1.0.0-M6.1</version>
</dependency>或者
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.0.0.2</version>
</dependency>配置⽂件
在配置⽂件中添加阿⾥百炼平台申请的API Key
server:
port: 8082
spring:
application:
name: spring-alibaba-demo
ai:
dashscope:
api-key: sk-XXXXXX
logging:
pattern:
console: "%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"
file: "%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"简单对话
在Controller中注⼊ChatClient, Bean就具备与AI⼤模型智能对话的能⼒了.
@RestController
@RequestMapping("/ali")
public class AliController {
private static final String DEFAULT_PROMPT = "你是⼀个博学的智能聊天助⼿, 请根据⽤⼾提问回答!";
private final ChatClient dashScopeChatClient;
public AliController(ChatClient.Builder chatClientBuilder) {
this.dashScopeChatClient = chatClientBuilder
.defaultSystem(DEFAULT_PROMPT)
// 实现 Logger 的 Advisor
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
@GetMapping("/chat")
public String chat(String message) {
return dashScopeChatClient.prompt(message).call().content();
}
}测试
访问接⼝: http://127.0.0.1:8082/ali/chat?message=你来⾃哪个公司
ChatClient
Spring AI Alibaba 是基于Spring AI 进⾏构建的. 所以Spring AI ChatClient具备的功能, Spring AI Alibaba ⼤多也具备, ⽐如流式响应, 返回实体类等
具体参考: Chat Client-阿⾥云Spring AI Alibaba官⽹官⽹
流式响应
@GetMapping(value = "/stream",produces = "text/html;charset=utf-8")
public Flux<String> stream(String message) {
return chatClient.prompt(message).stream().content();
}返回实体类
record ActorFilms(String actor, List<String> movies) {}
@GetMapping(value = "/entity",produces = "text/html;charset=utf-8")
public String entity(String actor) {
ActorFilms actorFilms = chatClient.prompt()
.user(String.format("帮我生成演员%s的作品",actor))
.call()
.entity(ActorFilms.class);
return actorFilms.toString();
}设置默认的System Message
@Configuration
public class ChatClientConfiguration {
@Bean
ChatClient chatClient(ChatClient.Builder builder){
return builder.defaultSystem("你叫JQQ")
.build();
}
}在上⾯ builder.defaultSystem() 创建 ChatClient 的时, 还可以选择使⽤模板, 有机会在每次调⽤前修改请求参数.
@Configuration
public class ChatClientConfiguration {
@Bean
ChatClient chatClient(ChatClient.Builder builder){
return builder.defaultSystem("请你给我回答问题时, 前⾯带⼀个 {word}")
.build();
}
} @RequestMapping("/chat")
public String chat(String message,String words){
return dashScopeChatClient.prompt(message)
.system(sp->sp.param("word",words))
.call()
.content();
}测试接⼝: http://127.0.0.1:8082/ali/chat?message=你来⾃哪&words=asas
其他默认设置
除了 defaultSystem 之外, 还可以在 ChatClient.Builder 上指定其他默认提⽰.
• defaultOptions(ChatOptions chatOptions):传⼊ ChatOptions 类中定义的可移植选项或特定于模型实现的如 DashScopeChatOptions 选项. 有关特定于模型的ChatOptions实现的更多信息, 请参阅 JavaDocs.
• defaultFunction(String name, String description, java.util.function.Function<I, O> function):name ⽤于在⽤⼾⽂本中引⽤该函数, description解释该函数的⽤途并帮助 AI 模型选择正确的函数以获得准确的响应, 参数 function 是模型将在必要时执⾏的 Java 函数实例.
• defaultFunctions(String... functionNames):应⽤程序上下⽂中定义的 java.util.Function 的bean 名称.
• defaultUser(String text)、defaultUser(Resource text)、defaultUser(Consumer<UserSpec>userSpecConsumer) 这些⽅法允许您定义⽤⼾消息输⼊, Consumer<UserSpec>允许您使⽤lambda 指定⽤⼾消息输⼊和任何默认参数.
• defaultAdvisors(RequestResponseAdvisor... advisor):Advisors 允许修改⽤于创建 Prompt 的数据, QuestionAnswerAdvisor 实现通过在 Prompt 中附加与⽤⼾⽂本相关的上下⽂信息来实现Retrieval Augmented Generation 模式.
• defaultAdvisors(Consumer<AdvisorSpec> advisorSpecConsumer):此⽅法允许您定义⼀个Consumer 并使⽤ AdvisorSpec 配置多个 Advisor, Advisor 可以修改⽤于创建 Prompt 的最终数据, Consumer<AdvisorSpec> 允许您指定 lambda 来添加 Advisor 例如 QuestionAnswerAdvisor可以在运⾏时使⽤ ChatClient 提供的不带 default 前缀的相应⽅法覆盖这些默认值.
• options(ChatOptions chatOptions)
• function(String name, String description, java.util.function.Function<I, O> function)
• functions(String... functionNames)
• user(String text) 、 user(Resource text) 、 user(Consumer<UserSpec>userSpecConsumer)
• advisors(RequestResponseAdvisor... advisor)
• advisors(Consumer<AdvisorSpec> advisorSpecConsumer)
多模态
多模态介绍
多模态性指模型同时理解和处理⽂本、图像、⾳频及其他数据格式等多源信息的能⼒.
⼈类通过多模态数据输⼊并⾏处理知识. 我们的学习⽅式和体验都是多模态的 — 不只有视觉、听觉或⽂本的单⼀感知.
机器学习往往专注于处理单⼀模态的专⽤模型. 例如, 我们开发⾳频模型⽤于⽂本转语⾳或语⾳转⽂本任务, 开发计算机视觉模型⽤于⽬标检测和分类等任务.
然⽽, 新⼀代多模态⼤语⾔模型正在兴起. 例如 OpenAI 的GPT-4o、Google 的Vertex AI Gemini 1.5、Anthropic 的 Claude3, 以及开源模型 Llama3.2、LLaVA 和 BakLLaVA, 都能接受⽂本、图像、⾳频和视频等多种输⼊, 并通过整合这些输⼊⽣成⽂本响应.
想象⼀下⼈类是怎么认识世界的?
• 看 :你能看到⻛景、⼈脸、⽂字、颜⾊ (视觉)
• 听 :你能听到说话声、⾳乐、⻦叫、汽⻋轰鸣 (听觉)
• 闻 :你能闻到花⾹、饭菜⾹ (嗅觉)
• 尝 :你能尝出酸甜苦辣咸 (味觉)
• 摸 :你能感觉到冷热、软硬、粗糙光滑 (触觉)
• 说/写 :你能⽤语⾔描述你的想法 (语⾔)
这些不同的⽅式 (看、听、闻、尝、摸、说) , 每⼀种就是⼀种"模态" (Modality) . "多模态" (Multimodal) 的意思就是:同时使⽤多种不同的"模态"来理解和表达信息 类⽐到⼈⼯智能
1. 传统AI : 器官"单⼀"的机器⼈
a. 聊天机器⼈: 只处理⽂字, 看不懂图, 听不懂语⾳
b. 语⾳助⼿: 只能听你说话, 回答或执⾏命令, 看不懂图⽚什么意思
2. 多模态AI: 同时具备"看", "读", "听", "说"(甚⾄更多)两种及以上的能⼒, 并把这些信息融合起来理解.
a. 看图说话: 给他⼀张照⽚, 他可以理解图⽚内容, 并使⽤⽂字/语⾳描述出来
b. 图⽂结合问答: 给他⼀张照⽚和⼀些关于图⽚的问题, 他能够结合图⽚和问题进⾏回答
参考: 多模态 API
多模态实现
我们借助阿⾥云来完成多模态的案例
1. 引⼊依赖
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.0.0.2</version>
</dependency>2. 配置⽂件
spring:
ai:
dashscope:
api-key: sk-
chat:
options:
model: qwen-vl-max-latest
multi-model: true #是否启用多模态3. 简单⽰例以视觉理解为例
@RestController
@RequestMapping("/multi")
public class MultiModelController {
private final ChatClient chatClient;
public MultiModelController(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@RequestMapping("/image")
public String image(String prompt) throws Exception {
String url = "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg";
List<Media> mediaList = List.of(new Media(MimeTypeUtils.IMAGE_JPEG,new URI(url).toURL().toURI()));
UserMessage userMessage = UserMessage.builder().text(prompt).media(mediaList).build();
return this.chatClient.prompt(new Prompt(userMessage)).call().content();
}
}
7. 智能聊天机器⼈
项⽬介绍
背景&⽬标
随着⼈⼯智能技术的快速发展和⼤模型开源趋势的兴起, 智能聊天机器⼈在客服、知识问答、⽣活助⼿等领域得到了⼴泛应⽤. Deepseek作为优秀的开源⼤模型框架, 为开发者提供了强⼤的基础能⼒. 当前市场上已有多个基于Deepseek的AI应⽤案例, 我们接下来模仿这些应⽤来实现⼀个智能聊天机器⼈, 提升⽤⼾交互体验.
产品⽬标:
• 提供流畅, ⾃然的对话体验
• ⽀持多轮对话及上下⽂理解
• 能够回答常⻅问题
• 记录和管理⽤⼾历史对话
核⼼功能
1. 对话
• ⽀持⽤⼾与机器⼈进⾏⽂本对话
• 实时响应⽤⼾输⼊, 输出⾃然语⾔回复
2. 多轮对话
• 能够理解和处理多轮对话, 保持上下⽂连续性
• ⽀持基于上下⽂的智能应答
3. 历史记录
• ⾃动保存⽤⼾与机器⼈的对话历史
• ⽀持⽤⼾查看历史对话内容
界⾯设计
在码云中获取
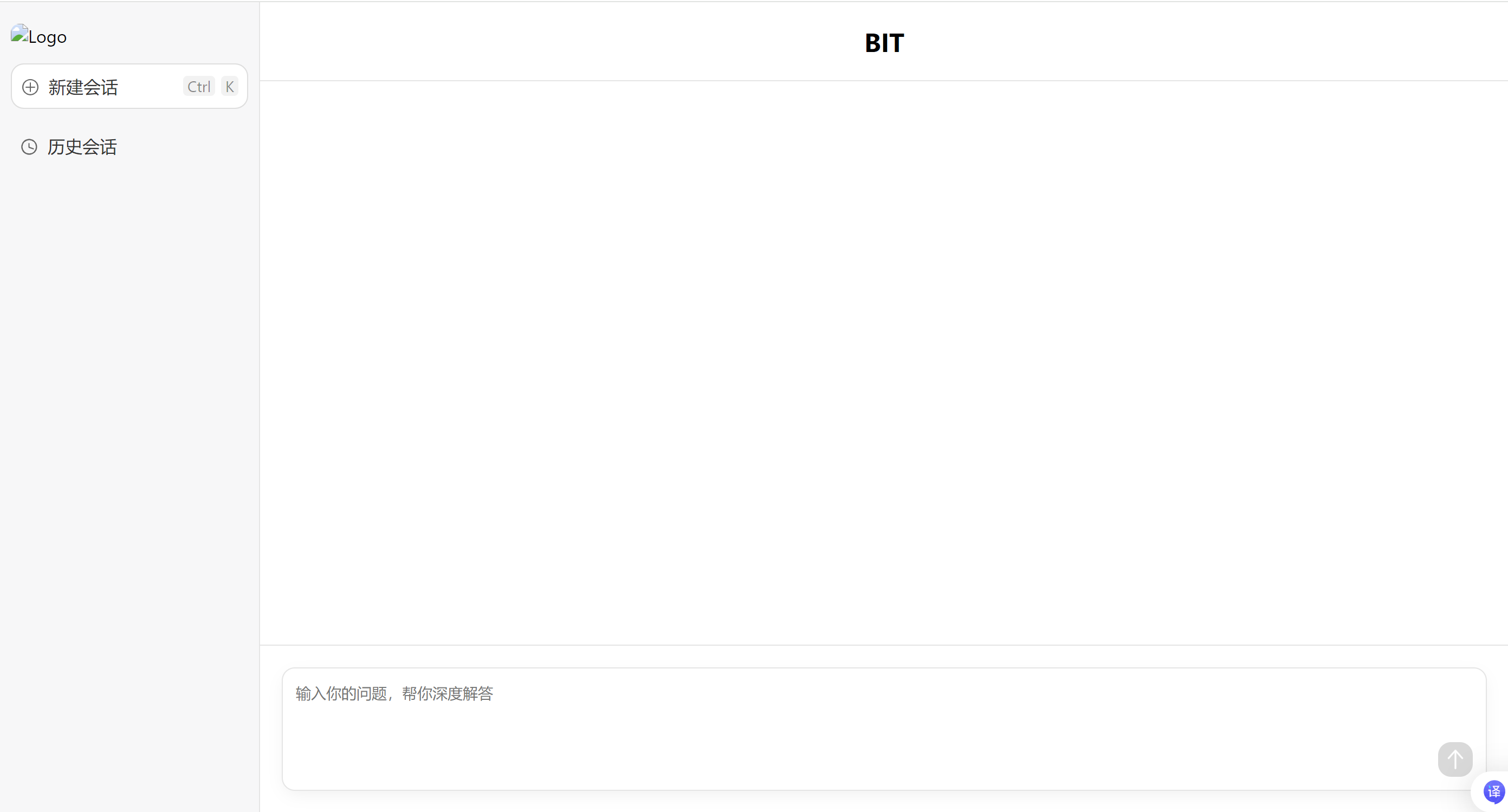
搭建环境
部署本地模型
安装Ollama, 部署模型
此处可根据⾃⼰情况, 选择Deepseek开放API, 或者使⽤阿⾥巴巴百炼平台
本地机器由于配置较低, 响应内容质量相对较差
创建项⽬
创建项⽬: spring-chat-bot
pom⽂件和启动类
• pom⽂件
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-M6</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>• 启动类
@SpringBootApplication
public class SpringChatBotApplication {
public static void main(String[] args) {
SpringApplication.run(SpringChatBotApplication.class,args);
}
}添加配置⽂件
server:
port: 8080
spring:
application:
name: spring-chat-bot
ai:
ollama:
base-url: http://127.0.0.1:11434
chat:
model: deepseek-r1:1.5b
logging:
pattern:
console: "%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"
file: "%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"
level:
org.springframework.ai.chat.client.advisor: debug简单对话
定义接⼝

代码实现
1. 配置Client
@Configuration
public class CommonChatClientConfiguration {
@Bean
public ChatClient ollamaChatClient(OllamaChatModel chatModel){
return ChatClient.builder(chatModel)
.defaultSystem("你是JQQ,你是智能AI助手,擅长Java编程知识,主要工作室解决学生在学习过程中的问题")
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
}2. 流式返回
@RestController
@RequestMapping("/chat")
public class ChatController {
private final ChatClient chatClient;
public ChatController(ChatClient ollamaChatClient) {
this.chatClient = ollamaChatClient;
}
@RequestMapping(value = "/stream",produces = "text/html;charset=utf-8")
public Flux<String> stream(String prompt){
return chatClient.prompt()
.user(prompt)
.stream()
.content();
}
}对话记忆
我们当前实现的会话功能是没有记忆能⼒的, 也就是多轮会话之间是没有关系的. 这会⽐较影响⽤⼾的体验.
"⼤模型的对话记忆"这⼀概念, 指的是模型在与⽤⼾进⾏交互式对话过程中, 能够追踪、理解并利⽤先前对话上下⽂的能⼒. 此机制使得⼤模型不仅能够响应即时的输⼊请求, 还能基于之前的交流内容能够在对话中记住先前的对话内容, 并根据这些信息进⾏后续的响应.
模型演⽰
⼤模型本⾝是不具备记忆能⼒的, 要想让⼤模型记住之前的聊天内容, 需要把之前的聊天内容与新的提⽰词⼀起发给⼤模型.
以 阿⾥百炼平台-通义千问Plus进⾏演⽰
1. 输⼊系统消息(SystemMessage) 和⽤⼾消息(UserMessage) 之后, 点击执⾏
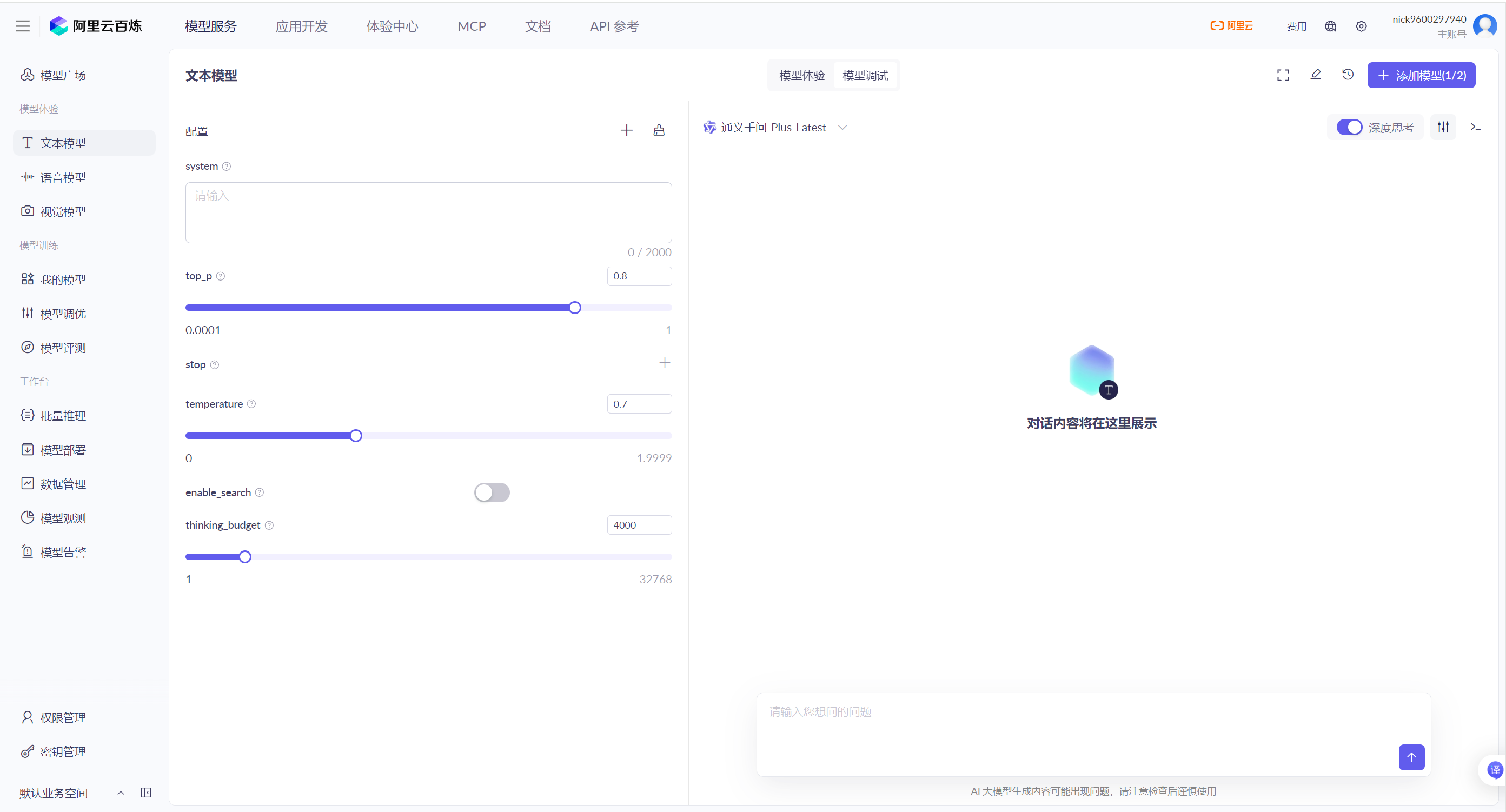
2. 右侧返回了模型的响应, 并且把模型的响应放在了assistant模块
Spring AI ⻆⾊消息类型
在对话系统 (尤其是⼤语⾔模型应⽤) 中, SystemMessage、UserMessage 和 AssistantMessage 是三种核⼼⻆⾊消息类型, ⽤于构建上下⽂感知的对话框架.
• SystemMessage: 系统消息, 通常由系统设定或初始化时提供, ⽤于设定对话的背景、⻆⾊、⾏为准则等. 它不是⽤⼾或助⼿发出的, ⽽是系统层⾯的指令或上下⽂信息. 例如, 在对话开始前, 系统消息可以设定助⼿的⻆⾊:"你是⼀个乐于助⼈的助⼿, ⽤中⽂回答问题. "
• UserMessage: ⽤⼾消息, 即由⽤⼾输⼊的内容. 在对话中, ⽤⼾的问题或语句都属于此类.
• AssistantMessage: 助⼿消息, 即由助⼿ (通常是AI模型) ⽣成并返回给⽤⼾的响应.
在技术实现上, 不同框架或库可能会采⽤不同的命名, 但核⼼思想⼀致. 例如, 在OpenAI的API中, 消息以⻆⾊ (role) 字段区分, 包括"system"、"user"、"assistant".
在多轮对话中, AssistantMessage 与 UserMessage 交替排列形成时序链, 使模型能通过注意⼒机制理解当前问题的前置语境 (短期记忆) .
3. 再次和⼤模型对话, 会发现⼤模型具备之前的记忆
4. 删除UserMessage 和 AssistantMessage , 发现⼤模型不具备记忆能⼒
Chat Memory
⼤型语⾔模型 (LLM) 是⽆状态的, 也就是它们不会保留有关以前交互的信息. 当开发⼈员希望在多个交互中维护上下⽂或状态时, 这可能是⼀个限制. 为了解决这个问题, Spring AI 提供了对话内存功能, 定义了ChatMemory接⼝, 允许开发⼈员在与 LLM 的多次交互中存储和检索信息.
public interface ChatMemory {
void add(String conversationId, List<Message> messages);
List<Message> get(String conversationId, int lastN);
void clear(String conversationId);1. add(String conversationId, List<Message> messages)
说明: 将单条或多条对话消息 (如⽤⼾输⼊或AI回复) 添加到指定会话的记忆库中 参数:
◦ conversationId: 区分不同会话的唯⼀标识
◦ Messages: 可包含 UserMessage/AssistantMessage 等类型
2. List<Message> get(String conversationId, int lastN)
说明: 根据会话标识, 获取历史消息
参数:
◦ conversationId: 会话唯⼀标识
◦ lastN 参数表⽰从指定会话中获取的最新消息数量
3. clear(String conversationId)
说明: 清空指定会话的记忆存储 参数:
◦ conversationId: 会话唯⼀标识
Spring AI 会⾃动配置ChatMemory , 开发⼈员可以直接在应⽤程序中使⽤这个 bean, Spring AI 提供了默认实现 InMemoryChatMemory , 不需要开发⼈员显⽰的调⽤记录每⼀轮的对话历史.
默认情况下, ChatMemory 使⽤内存来存储消息, 开发⼈员可以根据⾃⼰的需求, 去配置不同的存储库, ⽐如Cassandra、JDBC 或 Neo4j.
@Autowired
ChatMemory chatMemory;关于Chat Memory, Spring AI 和Spring AI alibaba都有实现, 感兴趣可以参考: 聊天记忆, 对话记忆
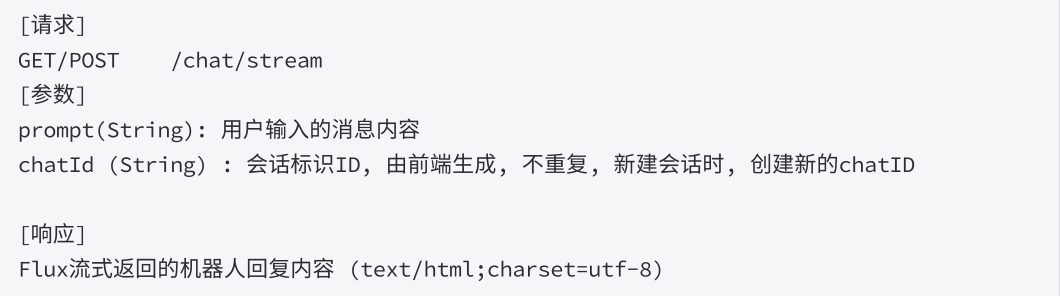
修改接⼝
代码实现
1. 定义会话存储⽅式
定义ChatMemory, 并把ChatMemory注⼊到ChatClient
@Bean
public ChatMemory chatMemory(){
return new InMemoryChatMemory();
}2. 配置会话记忆
也就是把ChatMemory注⼊到ChatClient
@Bean
public ChatClient ollamaChatClient(OllamaChatModel chatModel, ChatMemory chatMemory){
return ChatClient.builder(chatModel)
.defaultSystem("你是JQQ,你是智能AI助手,擅长Java编程知识,主要工作室解决学生在学习过程中的问题")
.defaultAdvisors(new SimpleLoggerAdvisor(),new MessageChatMemoryAdvisor(chatMemory))
.build();
}3. 传递ChatId
向模型发送请求时, 传递ChatId
@RequestMapping(value = "/stream",produces = "text/html;charset=utf-8")
public Flux<String> stream(String prompt,String chatId){
return chatClient.prompt()
.user(prompt)
.advisors(spec->spec.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY,chatId))
.stream()
.content();
}接⼝测试
第⼀次请求: http://127.0.0.1:8080/chat/stream?prompt=我叫⼩花&chatId=123456
第⼆次请求: http://127.0.0.1:8080/chat/stream?prompt=我是谁&chatId=123456
对话历史
ChatMemory 提供了get接⼝, 可以根据会话ID, 获取会话记录. 我们可以定义⼀个List, 来存储会话ID的列表, 然后再根据会话ID获取会话记录.
定义会话存储接⼝
定义ChatInfo 存储会话记录
@Data
public class ChatInfo {
private String title;
private String chatId;
public ChatInfo(String title, String chatId) {
this.title = title==null?"无标题":title.length()>15?title.substring(0,15):title;
this.chatId = chatId;
}
}public interface ChatHistotyRepository {
/**
* 保存会话记录
*/
void save(String prompt,String chatId);
/**
* 获取会话ID列表
* @return 会话ID列表
*/
List<ChatInfo> getChats();
/**
* 删除会话ID
* @param chatId chatID
*/
void clearChatId(String chatId);
}实现类
public class MemoryChatHistoryRepository implements ChatHistotyRepository{
private final Map<String ,String> chatHistory = new LinkedHashMap<>();
@Override
public void save(String prompt, String chatId) {
chatHistory.put(chatId,prompt);
}
@Override
public List<ChatInfo> getChats() {
return chatHistory.entrySet().stream()
.map(entry->new ChatInfo(entry.getValue(),entry.getKey()))
.collect(Collectors.toList());
}
@Override
public void clearChatId(String chatId) {
chatHistory.remove(chatId);
}
}存储会话
@Autowired
private ChatHistoryRepository chatHistoryRepository;
@RequestMapping(value = "/stream",produces = "text/html;charset=utf-8")
public Flux<String> stream(String prompt,String chatId){
log.info("prompt:{},charId:{}",prompt,chatId);
//保存会话
chatHistoryRepository.save(prompt,chatId);
return chatClient.prompt()
.user(prompt)
.advisors(spec->spec.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY,chatId))
.stream()
.content();
}获取会话列表
/**
* 获取会话列表
*/
@RequestMapping("/getChatIds")
public List<ChatInfo> getChatIds(){
return chatHistoryRepository.getChats();
}获取会话记录
分析
根据会话ID, 从ChatMemory中获取会话记录
List<Message> messages = chatMemory.get(chatId,20);需要把Message 进⾏转换
@Data
public class MessageV0 {
private String role;
private String content;
public MessageV0(Message message) {
switch (message.getMessageType()){
case USER -> {role = "user";break;}
case ASSISTANT -> {role = "assistant";break;}
case SYSTEM -> {role = "system";break;}
case TOOL -> {role = "tool";break;}
}
this.content = message.getText();
}
} /**
* 获取会话记录
*/
@RequestMapping("/getChatHistory")
public List<MessageV0> getChatHistory(String chatId){
log.info("获取会话信息,chatId:{}",chatId);
List<Message> messages = chatMemory.get(chatId,20);
return messages.stream().map(MessageV0::new).collect(Collectors.toList());
}删除会话记录
/**
* 删除会话
* @param chatId
* @return
*/
@RequestMapping("/deleteChat")
public Boolean deleteChat(String chatId){
log.info("删除会话,chatId:{}",chatId);
try{
chatHistoryRepository.clearChatId(chatId);
chatMemory.clear(chatId);
}catch (Exception e){
log.error("删除会话失败,chatId:{}",chatId);
return false;
}
return true;
}切换DeepSeek开放API
添加依赖和配置
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>spring:
ai:
openai:
api-key: sk
base-url: https://api.deepseek.com
chat:
options:
model: deepseek-chat
temperature: 0.7定义Client
@Bean
public ChatClient deepseekChatClient(OpenAiChatModel chatModel, ChatMemory chatMemory){
return ChatClient.builder(chatModel)
// .defaultSystem("你是JQQ,你是智能AI助手,擅长Java编程知识,主要工作室解决学生在学习过程中的问题")
.defaultAdvisors(new SimpleLoggerAdvisor(),new MessageChatMemoryAdvisor(chatMemory))
.build();
}使⽤Client
public ChatController(ChatClient deepseekChatClient) {
this.chatClient = deepseekChatClient;
}
















 2105
2105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









