




目录
一、Python3 概述:为什么学 Python?
Python 由 “龟叔” Guido van Rossum 在 1989 年圣诞节期间编写,初衷是打发无聊时光,却意外成为如今最流行的编程语言之一。它与 C 语言(贴近硬件、追求运行速度)不同,是高层次的解释型、交互式、面向对象脚本语言,核心特点如下:
- 解释型:无需编译,直接运行代码(类似 PHP、Perl);
- 交互式:可在>>>提示符后直接执行代码,即时看到结果;
- 面向对象:支持代码封装在对象中,符合现代编程思想;
- 高可读性:用英文关键字替代复杂标点,语法结构清晰,对初学者友好。
二、第一步:查看 Python 版本
在开始编写代码前,先确认本地 Python 版本。Windows 系统打开 cmd(Win+R输入cmd),执行以下命令:
# 方法1:简洁版本
python -V
# 方法2:完整版本
python --version确保是 Python3.x 版本(Python2 已停止维护)。
三、第一个 Python 程序:Hello World!
学习任何语言,第一个程序几乎都是 “打印 Hello World”。Python 中用print()内置函数实现,它是最常用的内置函数之一,可直接打印对象。
1. 基础用法
# 1. 打印单个字符串
print("Hello World!") # 输出:Hello World!
# 2. 打印多个字符串(逗号分隔,自动加空格)
print("The quick brown fox", "jumps over", "the lazy dog") # 输出:The quick brown fox jumps over the lazy dog
# 3. 打印整数或计算结果
print(300) # 输出:300
print(100 + 200) # 输出:300
print("100 + 200 =", 100 + 200) # 输出:100 + 200 = 300四、输入与输出:和用户交互
除了打印内容,Python 还支持通过input()获取用户输入,再用变量存储。
1. input()获取用户输入
# 提示用户输入名字,并存入name变量
name = input("请输入你的名字:")
# 打印欢迎信息
print("Hello,", name)运行后,终端会显示 “请输入你的名字:”,输入后按回车,会输出Hello, 你的名字。
2. 什么是变量?
变量就像 “容器”,可存储不同类型的数据(字符串、数字等)。比如数学中正方形的边长a:
- 若a=2,面积是a*a=4;
- 若a=3.5,面积是a*a=12.25。
在 Python 中,name就是存储字符串的变量,age可存储整数,非常灵活。
五、Python 数据类型:变量的 “身份标识”
变量能存储不同类型的数据,Python 默认有多种内置数据类型,不同类型支持不同操作。
1. 内置数据类型总览
| 数据类型分类 | 具体类型 | 说明 |
| 文本类型 | str | 字符串(如 "Hello"、"Python") |
| 数值类型 | int | 整数(如 42、-10、0) |
| float | 浮点数(如 3.14、-0.001、2.0) | |
| complex | 复数(如 1+2j,实部 + 虚部,多用于科学计算) | |
| 序列类型 | list | 可变有序序列(如 [1, 2, "apple"],支持增删改) |
| tuple | 不可变有序序列(如 (1, 2, "banana"),创建后无法修改) | |
| range | 不可变整数序列(如 range(5) 等价于 [0,1,2,3,4]) | |
| 映射类型 | dict | 键值对映射(如 {"name": "Alice", "age": 25},通过键找值) |
| 集合类型 | set | 可变无序不重复集合(如 {1, 2, 3},自动去重) |
| frozenset | 不可变无序不重复集合(如 frozenset([1,2]),创建后无法修改) | |
| 布尔类型 | bool | 逻辑值(仅 True 或 False,用于条件判断) |
2. 查看数据类型:type()函数
用type()可快速判断变量的数据类型:
# 定义不同类型的变量
x1 = "Python" # str
x2 = 2024 # int
x3 = 3.14 # float
x4 = [1,2,3] # list
# 查看类型
print(type(x1)) # 输出:<class 'str'>
print(type(x3)) # 输出:<class 'float'>
print(type(x4)) # 输出:<class 'list'>六、Python 运算符:实现数据计算与逻辑判断
运算符是 Python 处理数据的 “工具”,按功能可分为 7 大类,我们结合代码理解核心用法。
1. 算术运算符(数学计算)
| 运算符 | 名称 | 示例 | 结果 | 说明 |
| + | 加法 | 5+3 | 8 | 数字相加 / 字符串拼接 |
| - | 减法 | 10-2 | 8 | 数字相减 |
| * | 乘法 | 4*3 | 12 | 数字相乘 / 序列重复(如"a"*3) |
| / | 除法 | 15/4 | 3.75 | 结果必为浮点数 |
| // | 整除 | 15//4 | 3 | 向下取整(忽略小数) |
| % | 取模 | 15%4 | 3 | 返回余数(常用於判断奇偶) |
| ** | 幂运算 | 2**3 | 8 | 计算指数(2 的 3 次方) |
代码示例:
print(15 // 4) # 输出:3(整除)
print(15 % 4) # 输出:3(取模)
print("Py" * 3) # 输出:PyPyPy(字符串重复)2. 比较运算符(判断大小 / 相等)
| 运算符 | 名称 | 示例 | 结果 |
| == | 等于 | 5==3 | False |
| != | 不等于 | 5!=3 | True |
| > | 大于 | 5>3 | True |
| < | 小于 | 5<3 | False |
| >= | 大于等于 | 5>=5 | True |
| <= | 小于等于 | 5<=3 | False |
代码示例:
age = 18
print(age >= 18) # 输出:True(用于条件判断)3. 逻辑运算符(组合条件)
| 运算符 | 名称 | 示例 | 结果 | 说明 |
| and | 逻辑与 | True and False | False | 全为真才是真 |
| or | 逻辑或 | True or False | True | 一个为真就是真 |
| not | 逻辑非 | not True | False | 取反 |
代码示例:
score = 85
# 判断分数是否在60~100之间
print(score >= 60 and score <= 100) # 输出:True4. 赋值运算符(给变量赋值)
最常用的是=,还有简化写法(如+=、*=):
x = 5 # 基础赋值:x=5
x += 3 # 等价于x = x+3 → x=8
x *= 2 # 等价于x = x*2 → x=16
print(x) # 输出:165. 运算符优先级(避免逻辑错误)
优先级从高到低(关键记住前 3 个):
- 括号 ()(优先计算括号内);
- 幂运算 **;
- 乘除模 *、/、%、//;
- 加减 +、-。
示例:
# 括号改变优先级
print(2 + 3 * 4) # 输出:14(先乘后加)
print((2 + 3) * 4)# 输出:20(先加后乘)七、Python 集合:存储多个数据的 “容器”
Python 有 4 种核心集合类型:列表(List)、元组(Tuple)、集合(Set)、字典(Dictionary),各有特点,适用场景不同。
1. 列表(List):可变有序,允许重复
用[]定义,是最常用的集合类型,支持增删改查。
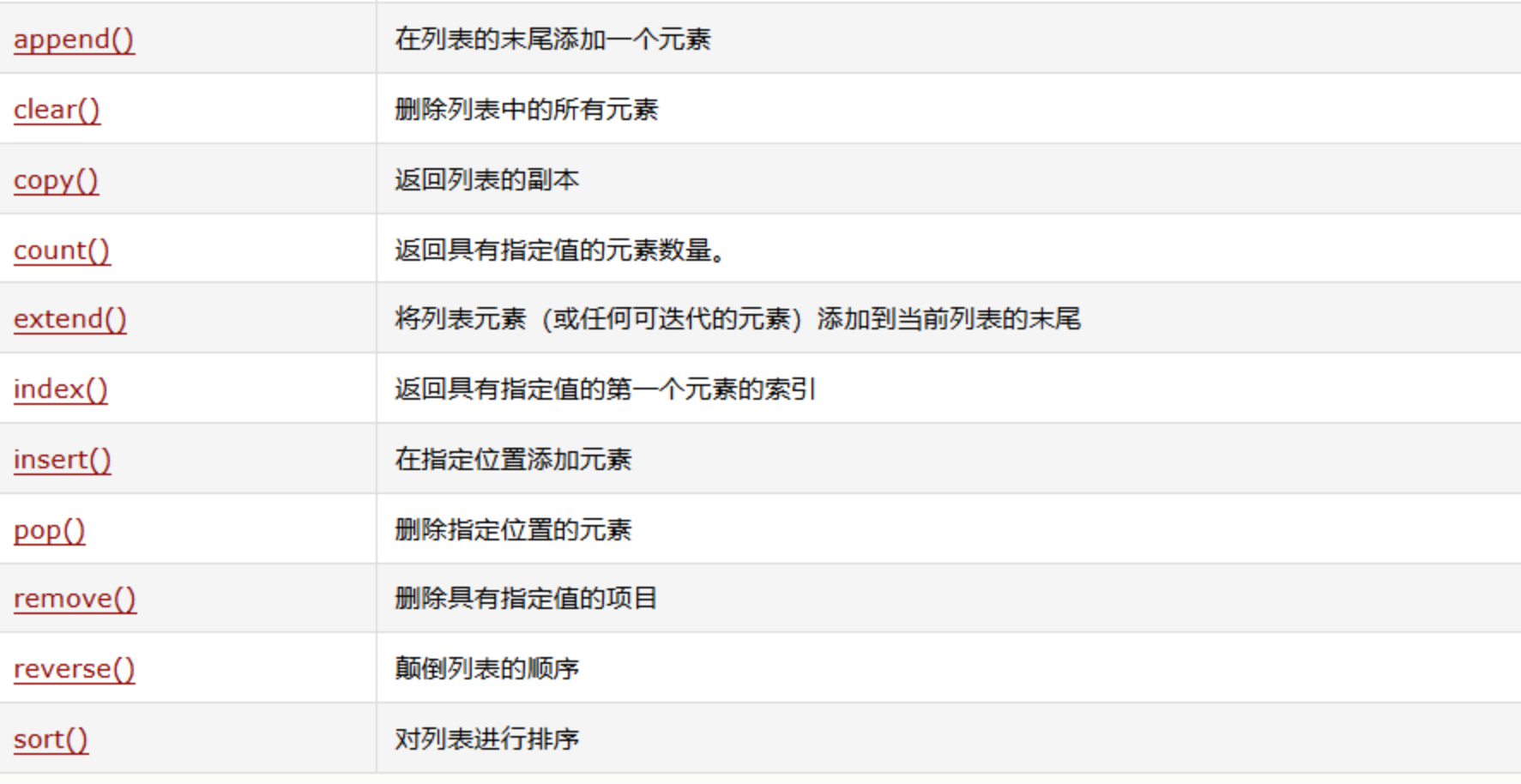
基础操作代码:
1. 创建列表(可混合类型)
fruits = ["apple", "banana", "cherry", 5, 3.14]
print(fruits) 输出:['apple', 'banana', 'cherry', 5, 3.14]
2. 访问元素(索引从0开始,负索引从末尾算)
print(fruits[1]) 输出:banana(第2个元素)
print(fruits[-1]) 输出:3.14(最后1个元素)
3. 切片(获取范围元素)
print(fruits[1:3]) 输出:['banana', 'cherry'](从索引1到2,不包含3)
4. 修改元素
fruits[0] = "mango"
print(fruits) 输出:['mango', 'banana', 'cherry', 5, 3.14]
5. 添加元素
fruits.append("orange") 末尾添加
fruits.insert(2, "grape") 索引2处添加
print(fruits) 输出:['mango', 'banana', 'grape', 'cherry', 5, 3.14, 'orange']
6. 删除元素
fruits.remove("banana") 删除指定值
fruits.pop() 删除末尾元素
del fruits[0] 删除指定索引
print(fruits) 输出:['grape', 'cherry', 5, 3.14]
7. 遍历列表
for fruit in fruits:
print(fruit) 依次打印每个元素2. 元组(Tuple):不可变有序,允许重复
用()定义,一旦创建无法修改(“只读” 列表),适合存储不希望被修改的数据。
 基础操作代码:
基础操作代码:
1. 创建元组(单个元素需加逗号,否则视为普通变量)
t1 = ("apple", "banana", "cherry")
t2 = ("apple",) # 正确:单个元素的元组
t3 = ("apple") # 错误:类型是str
2. 访问元素(和列表一致)
print(t1[1]) # 输出:banana
3. 不可修改(以下代码会报错)
t1[0] = "mango" # TypeError: 'tuple' object does not support item assignment
4. 间接修改:转列表→修改→转元组
t_list = list(t1)
t_list[0] = "mango"
t1 = tuple(t_list)
print(t1) # 输出:('mango', 'banana', 'cherry')3. 集合(Set):可变无序,无重复
用{}定义,自动去重,适合判断元素是否存在、去重等场景。
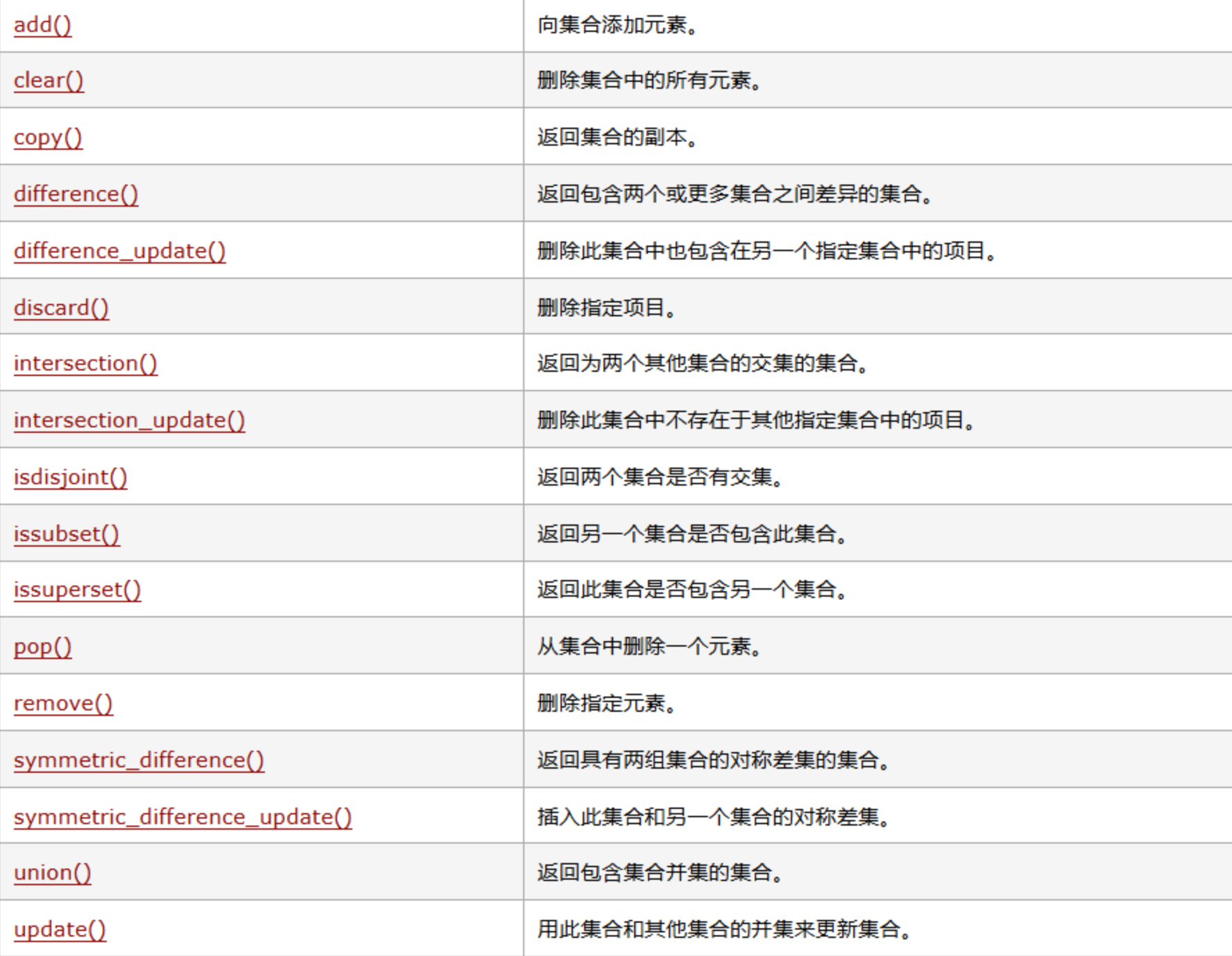 基础操作代码:
基础操作代码:
# 1. 创建集合(自动去重)
s = {"apple", "banana", "cherry", "apple"}
print(s) # 输出:{'apple', 'banana', 'cherry'}(无序,去重)
# 2. 检查元素是否存在
print("banana" in s) # 输出:True
# 3. 添加元素
s.add("orange") # 单个添加
s.update({"grape", "mango"}) # 多个添加
print(s) # 输出:{'apple', 'banana', 'cherry', 'orange', 'grape', 'mango'}
# 4. 删除元素(remove不存在会报错,discard不会)
s.remove("banana")
s.discard("pear") # 无pear,不报错
print(s) # 输出:{'apple', 'cherry', 'orange', 'grape', 'mango'}4. 字典(Dictionary):可变无序,键值对映射
用{key: value}定义,通过 “键” 快速查找 “值”,键唯一,值可重复,是存储结构化数据的首选。
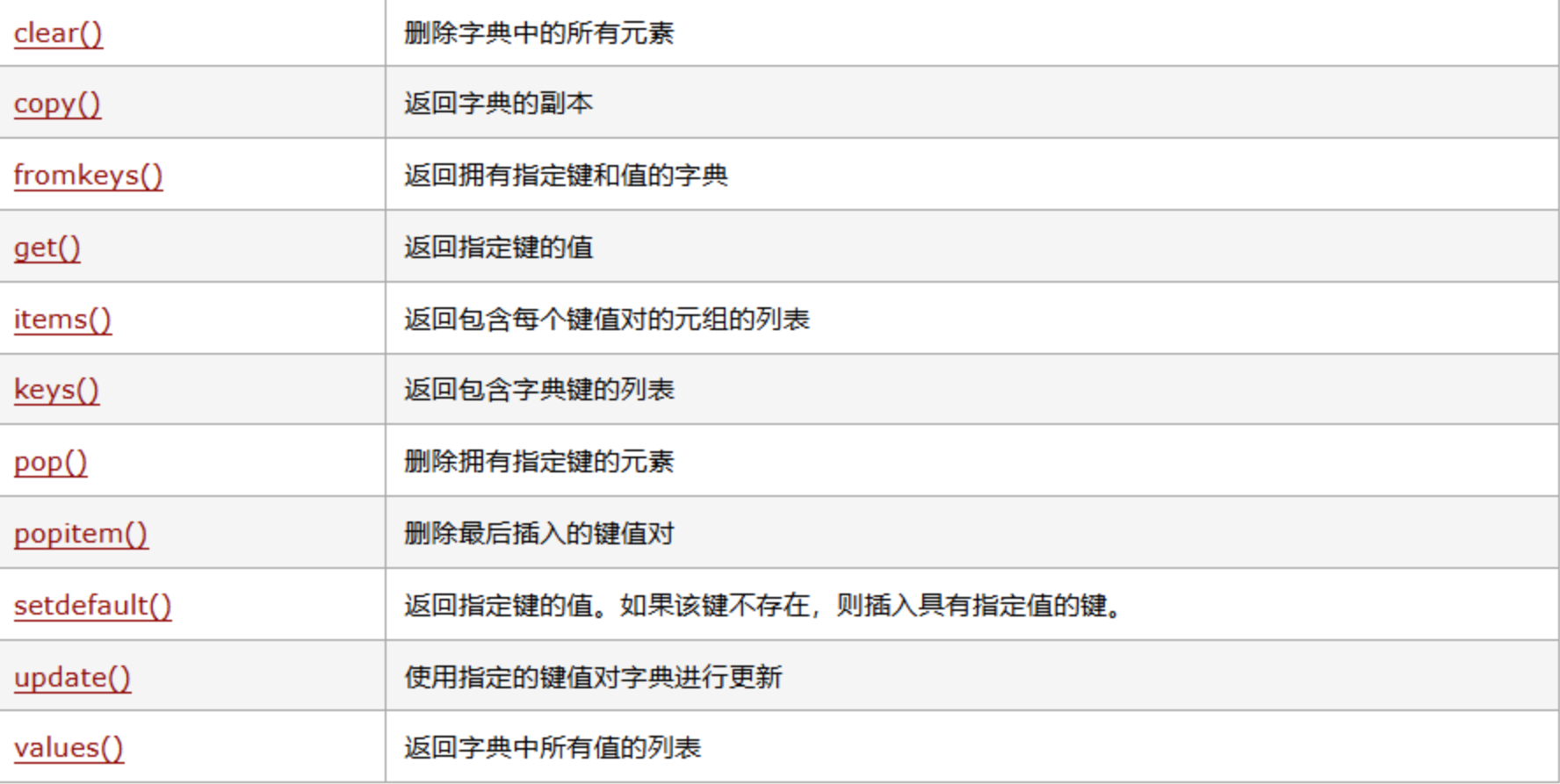
基础操作代码:
# 1. 创建字典
person = {
"name": "Alice",
"age": 25,
"city": "Beijing"
}
print(person) # 输出:{'name': 'Alice', 'age': 25, 'city': 'Beijing'}
# 2. 访问值(通过键名或get())
print(person["name"]) # 输出:Alice
print(person.get("age"))# 输出:25
# 3. 修改值
person["age"] = 26
print(person) # 输出:{'name': 'Alice', 'age': 26, 'city': 'Beijing'}
# 4. 添加键值对
person["job"] = "Engineer"
print(person) # 输出:{'name': 'Alice', 'age': 26, 'city': 'Beijing', 'job': 'Engineer'}
# 5. 遍历字典(键、值、键值对)
for key in person:
print(key) # 打印所有键:name, age, city, job
for value in person.values():
print(value) # 打印所有值:Alice, 26, Beijing, Engineer
for key, value in person.items():
print(f"{key}: {value}") # 打印键值对八、条件判断:让程序 “做选择”
计算机能自动化任务,核心是能做条件判断。Python 用if、elif、else实现,语法依赖缩进(4 个空格)。
代码示例:根据年龄判断录取结果
# 获取用户输入的年龄(注意:input()返回str,需转int)
age = int(input("请输入你的年龄:"))
# 条件判断
if age >= 18:
print("录取成功") # 年龄≥18,执行这里
elif age < 0:
print("输入有误,请输入正确年龄") # 年龄<0,执行这里
else:
print("录取失败") # 其他情况(0≤年龄<18),执行这里关键注意点:
- 条件后必须加冒号 :;
- 缩进决定代码块归属(同一缩进是同一代码块);
- if 从上往下判断,满足一个条件后,后续elif/else不再执行。
九、循环:让程序 “重复做”
当需要重复执行某段代码时,用循环效率更高。Python 有while和for两种循环。
1. while 循环:条件为真就执行
# 示例1:打印1~6
i = 1
while i < 7:
print(i)
i += 1 # 必须更新变量,否则无限循环
# 输出:1 2 3 4 5 6
# 示例2:密码验证(直到输入正确)
password = ""
while password != "123456":
password = input("请输入密码:")
print("密码正确!")2. for 循环:遍历序列(更常用)
# 示例1:遍历列表
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit) # 输出:apple banana cherry
# 示例2:遍历字符串
for char in "Python":
print(char) # 输出:P y t h o n
# 示例3:用range()生成序列(range(起始, 结束, 步长))
for i in range(0, 10, 2):
print(i) # 输出:0 2 4 6 8(步长2,不包含10)
# 示例4:嵌套循环(adj和fruits的所有组合)
adj = ["red", "big", "tasty"]
for a in adj:
for f in fruits:
print(a, f) # 输出:red apple, red banana... tasty cherry3. break 与 continue(控制循环)
- break:立即退出循环;
- continue:跳过当前迭代,进入下一次。
# break示例:i=3时退出
i = 1
while i < 7:
print(i)
if i == 3:
break
i += 1
# 输出:1 2 3
# continue示例:跳过i=3
i = 0
while i < 7:
i += 1
if i == 3:
continue
print(i)
# 输出:1 2 4 5 6 7十、函数:减少重复代码,提高复用性
当一段代码需要多次使用时,封装成函数是最佳选择。比如计算圆的面积,无需每次写πr²,调用函数即可。
1. 定义与调用函数
用def关键字定义函数,语法:def 函数名(参数): 函数体 return 返回值。
# 示例1:计算圆的面积(用numpy的π,需先安装:pip install numpy)
import numpy as np
def circle_area(r):
"""计算圆的面积(r:半径)"""
return np.pi * r ** 2 # 返回面积
# 调用函数
area1 = circle_area(2) # 半径2
area2 = circle_area(5) # 半径5
print(f"半径2的圆面积:{area1:.2f}") # 输出:12.57
print(f"半径5的圆面积:{area2:.2f}") # 输出:78.54
# 示例2:返回多个值(实际返回元组,可拆解)
def move(x, y, step):
"""计算移动后的坐标(x,y:初始坐标,step:步长)"""
nx = x + step
ny = y + step
return nx, ny # 返回两个值
# 拆解返回值
new_x, new_y = move(10, 20, 5)
print(new_x, new_y) # 输出:15 252. 函数参数类型
Python 函数参数灵活,支持多种类型:
- 位置参数:按顺序传递(如circle_area(r)中的r);
- 默认参数:给参数设默认值,调用时可省略(如def power(x, n=2):,n默认 2);
- 可变参数:参数个数可变,用*表示(如def calc(*numbers):,可传任意个数字);
- 关键字参数:用**表示,接收键值对(如def person(name, age, **kw):,可传city="Beijing")。
3. 递归函数:自己调用自己
递归函数是在函数内部调用自身,适合解决有 “重复子问题” 的场景(如阶乘、斐波那契数列)。
# 示例:计算n的阶乘(n! = 1×2×3×...×n)
def fact(n):
if n == 1: # 终止条件(避免无限递归)
return 1
return n * fact(n-1) # 递归调用
print(fact(5)) # 输出:120(5! = 5×4×3×2×1)十一、Lambda 函数:简洁的匿名函数
Lambda 是 “匿名函数”,语法简洁,仅能写一个表达式,适合临时使用的简单函数。
语法与示例
# 语法:lambda 参数: 表达式(自动返回结果)
# 示例1:计算a+10
add10 = lambda a: a + 10
print(add10(5)) # 输出:15
# 示例2:计算a*b
multiply = lambda a, b: a * b
print(multiply(3, 4)) # 输出:12
# 示例3:作为其他函数的参数(常用场景)
def my_func(n):
return lambda a: a * n # 返回Lambda函数
# 创建“翻倍”和“三倍”函数
double = my_func(2)
triple = my_func(3)
print(double(10)) # 输出:20(10×2)
print(triple(10)) # 输出:30(10×3)十二、类与对象:面向对象编程基础
Python 是面向对象语言,“类(Class)” 是对象的 “蓝图”,“对象” 是类的实例(比如 “Person” 是类,“Alice” 是对象)。
1. 创建类与对象
# 1. 定义类(用class关键字)
class Person:
# __init__():构造方法,创建对象时自动执行(初始化属性)
def __init__(self, name, age):
self.name = name # self:当前对象的引用,必写
self.age = age
# 定义对象方法
def say_hello(self):
print(f"Hello, 我是{self.name},今年{self.age}岁")
# 2. 创建对象(实例化类)
p1 = Person("Alice", 25)
p2 = Person("Bob", 30)
# 3. 访问对象属性
print(p1.name) # 输出:Alice
print(p2.age) # 输出:30
# 4. 调用对象方法
p1.say_hello() # 输出:Hello, 我是Alice,今年25岁
p2.say_hello() # 输出:Hello, 我是Bob,今年30岁2. 继承:子类复用父类功能
继承允许子类(派生类)继承父类(基类)的属性和方法,减少重复代码。
# 1. 父类:Person
class Person:
def __init__(self, fname, lname):
self.firstname = fname
self.lastname = lname
def print_name(self):
print(f"{self.firstname} {self.lastname}")
# 2. 子类:Student(继承Person)
class Student(Person):
# 重写__init__(),并调用父类__init__(保留父类功能)
def __init__(self, fname, lname, graduation_year):
super().__init__(fname, lname) # super():引用父类
self.grad_year = graduation_year # 子类新增属性
# 子类新增方法
def welcome(self):
print(f"欢迎{self.firstname} {self.lastname},{self.grad_year}届学生")
# 3. 创建子类对象
s1 = Student("Elon", "Musk", 2024)
# 4. 调用父类方法和子类方法
s1.print_name() # 继承父类方法:输出Elon Musk
s1.welcome() # 子类方法:输出欢迎Elon Musk,2024届学生十三、补充:损失值、梯度下降与模型选择
最后补充一点机器学习相关的基础概念,帮助理解 Python 在数据分析中的应用:
1. 损失值与梯度下降
- 损失值:模型预测值与实际值的差距(如均方误差 MSE),损失值越小,模型越准;
- 梯度下降:通过 “沿损失函数下降最快的方向” 调整模型参数,直到损失值最小(找到最优解),适用于线性回归、神经网络等参数连续、损失可微的模型。
2. 为什么决策树 / 随机森林不用梯度下降?
核心差异在模型本质:
- 梯度下降:依赖 “连续参数” 微调;
- 决策树 / 随机森林:基于 “离散分裂规则”(如判断年龄 > 18),训练核心是 “搜索最优分裂规则”,无连续参数可调整,因此无需梯度下降。
总结
这篇文章覆盖了 Python3 的核心语法:从基础的变量、数据类型,到运算符、集合、条件判断、循环,再到函数、Lambda、类与对象,最后补充了机器学习基础概念。后续可以深入学习数据分析、爬虫、机器学习等方向~

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









