






三大框架:1.springAI 2.LangChain4j 3Jlama
两大技能:RAG(检索增强生成)和 Fine-tuning(微调)
LangChain4j应用场景
在java项目中使用LangChain4j
添加依赖
如果你使用的是 Maven 项目,在 pom.xml 里添加以下依赖:
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-openai</artifactId>
<version>0.23.0</version>
</dependency>
</dependencies>配置 OpenAI API 密钥
你需要设置 OpenAI 的 API 密钥,可以通过环境变量或者代码中直接设置,这里采用环境变量的方式。在运行程序前设置环境变量:
编写示例代码
import dev.langchain4j.chain.ConversationalRetrievalChain;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentLoader;
import dev.langchain4j.data.document.splitter.CharacterTextSplitter;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.embedding.OpenAiEmbeddingModel;
import dev.langchain4j.model.input.Prompt;
import dev.langchain4j.model.input.PromptTemplate;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.retriever.EmbeddingStoreRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import java.io.File;
import java.util.List;
import static dev.langchain4j.model.openai.OpenAiModelName.GPT_3_5_TURBO;
public class LangChain4jExample {
public static void main(String[] args) {
// 创建 OpenAI 聊天模型
OpenAiChatModel chatModel = OpenAiChatModel.withApiKey(System.getenv("OPENAI_API_KEY"));
// 创建 OpenAI 嵌入模型
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.withApiKey(System.getenv("OPENAI_API_KEY"));
// 创建嵌入存储
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
// 加载文档
Document document = DocumentLoader.load(new File("path/to/your/document.txt"));
// 分割文档为文本片段
List<TextSegment> segments = new CharacterTextSplitter().split(document);
// 为每个文本片段生成嵌入向量并存储
for (TextSegment segment : segments) {
embeddingStore.add(embeddingModel.embed(segment).content(), segment);
}
// 创建检索器
EmbeddingStoreRetriever<TextSegment> retriever = EmbeddingStoreRetriever.from(embeddingStore, embeddingModel);
// 创建对话式检索链
ConversationalRetrievalChain chain = ConversationalRetrievalChain.builder()
.chatLanguageModel(chatModel)
.retriever(retriever)
.promptTemplate(PromptTemplate.from("根据以下文档回答问题:{documents}\n问题:{question}"))
.build();
// 定义问题
String question = "文档里提到了哪些关键信息?";
// 执行链并获取答案
String answer = chain.execute(question);
// 输出答案
System.out.println("问题:" + question);
System.out.println("答案:" + answer);
}
}
代码解释
- 模型创建:通过
OpenAiChatModel和OpenAiEmbeddingModel创建与 OpenAI 交互的聊天模型和嵌入模型。 - 文档处理:加载本地文档,将其分割成文本片段,并为每个片段生成嵌入向量存储到
InMemoryEmbeddingStore中。 - 检索器创建:使用嵌入存储和嵌入模型创建检索器,用于根据问题检索相关的文本片段。
- 对话式检索链:构建
ConversationalRetrievalChain,结合聊天模型、检索器和提示模板来处理问题。 - 问题解答:执行链并传入问题,获取答案并输出。
Jlama的应用场景
Jlama为Java开发者打开了一扇通往AI世界的大门,其应用场景非常广泛:
智能客服系统:利用Jlama可以快速构建基于LLM的智能客服系统,提供24/7的自动化客户支持。
内容生成:在新闻、广告、社交媒体等领域,Jlama可以协助生成高质量的文本内容。
代码辅助:集成到IDE中,为程序员提供智能代码补全、注释生成等功能。
数据分析:在大数据处理中,利用LLM进行自然语言查询和数据解释。
教育科技:开发智能辅导系统,为学生提供个性化的学习体验。
金融科技:用于风险评估、市场分析、智能投顾等场景。
在Java项目中使用Jlama
将Jlama集成到Java项目中非常简单。首先,需要在Maven配置文件中添加以下依赖:
<dependency>
<groupId>com.github.tjake</groupId>
<artifactId>jlama-core</artifactId>
<version>${jlama.version}</version>
</dependency>
<dependency>
<groupId>com.github.tjake</groupId>
<artifactId>jlama-native</artifactId>
<classifier>${os.detected.name}-${os.detected.arch}</classifier>
<version>${jlama.version}</version>
</dependency>
然后,可以使用以下代码示例来加载模型并生成文本:
import com.github.tjake.jlama.model.LlamaModel;
import com.github.tjake.jlama.sampling.SamplingParameters;
import com.github.tjake.jlama.sampling.SamplingResult;
import com.github.tjake.jlama.tokenizer.Tokenizer;
import java.io.IOException;
import java.nio.file.Paths;
public class JLamaExample {
public static void main(String[] args) {
try {
// 加载模型和分词器
String modelPath = "path/to/your/llama/model.bin"; // 替换为实际的模型文件路径
LlamaModel model = LlamaModel.load(Paths.get(modelPath));
Tokenizer tokenizer = model.getTokenizer();
// 定义输入文本
String inputText = "介绍一下中国的长城";
// 对输入文本进行分词
int[] inputTokens = tokenizer.encode(inputText);
// 配置采样参数
SamplingParameters samplingParameters = new SamplingParameters();
samplingParameters.setTemperature(0.8f);
samplingParameters.setTopK(40);
samplingParameters.setTopP(0.95);
samplingParameters.setMaxTokens(128);
// 生成文本
SamplingResult result = model.sample(inputTokens, samplingParameters);
// 解码生成的文本
String outputText = tokenizer.decode(result.getTokens());
// 输出结果
System.out.println("生成的文本: " + outputText);
// 关闭模型
model.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
代码解释
- 模型加载:使用
LlamaModel.load方法加载 Llama 模型文件,需要将modelPath替换为实际的模型文件路径。 - 分词:通过
model.getTokenizer()获取分词器,使用tokenizer.encode方法将输入文本转换为令牌数组。 - 采样参数配置:
SamplingParameters类用于配置文本生成的参数,如温度(temperature)、topK、topP和最大生成令牌数(maxTokens)。 - 文本生成:调用
model.sample方法根据输入令牌和采样参数生成文本。 - 解码:使用
tokenizer.decode方法将生成的令牌数组转换为文本。
另一种写法
public void sample() throws IOException {
String model = "tjake/TinyLlama-1.1B-Chat-v1.0-Jlama-Q4";
String workingDirectory = "./models";
String prompt = "What is the best season to plant avocados?";
File localModelPath = SafeTensorSupport.maybeDownloadModel(workingDirectory, model);
AbstractModel m = ModelSupport.loadModel(localModelPath, DType.F32, DType.I8);
if (m.promptSupport().isPresent()) {
prompt = m.promptSupport().get().newBuilder()
.addSystemMessage("You are a helpful chatbot who writes short responses.")
.addUserMessage(prompt)
.build();
}
System.out.println("Prompt: " + prompt + "\n");
GenerateResponse r = m.generate(UUID.randomUUID(), prompt, 0.7f, 256, false, (s, f) -> System.out.print(s));
System.out.println(r.toString());
}Deep Java Library (DJL)应用场景
进行图像分类
在Java项目中使用DJL
添加 DJL 依赖
在 pom.xml 文件中添加 DJL 的依赖项。
<dependencies>
<!-- DJL API -->
<dependency>
<groupId>ai.djl</groupId>
<artifactId>api</artifactId>
<version>0.19.0</version>
</dependency>
<!-- PyTorch Engine -->
<dependency>
<groupId>ai.djl.pytorch</groupId>
<artifactId>pytorch-engine</artifactId>
<version>0.19.0</version>
</dependency>
<!-- NDArray for tensor operations -->
<dependency>
<groupId>ai.djl.ndarray</groupId>
<artifactId>ndarray</artifactId>
<version>0.19.0</version>
</dependency>
<!-- Image processing -->
<dependency>
<groupId>ai.djl.basicmodelzoo</groupId>
<artifactId>basic-model-zoo</artifactId>
<version>0.19.0</version>
</dependency>
<!-- Native libraries for PyTorch -->
<dependency>
<groupId>ai.djl.pytorch</groupId>
<artifactId>pytorch-native-auto</artifactId>
<version>1.10.0</version>
</dependency>
</dependencies>
3. 创建图像分类服务
创建一个服务类来处理图像分类逻辑
import ai.djl.Model;
import ai.djl.inference.Predictor;
import ai.djl.modality.cv.Image;
import ai.djl.modality.cv.ImageFactory;
import ai.djl.modality.cv.transform.Resize;
import ai.djl.modality.cv.transform.ToTensor;
import ai.djl.repository.zoo.Criteria;
import ai.djl.repository.zoo.ZooModel;
import ai.djl.translate.Pipeline;
import ai.djl.translate.TranslateException;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.StandardCopyOption;
@Service
public class ImageClassificationService {
private final Model model;
public ImageClassificationService() throws IOException {
// 定义模型的准则
Criteria<Image, String> criteria = Criteria.builder()
.setTypes(Image.class, String.class)
.optApplication(ai.djl.modality.cv.Application.IMAGE_CLASSIFICATION)
.optModelName("resnet18_v1")
.optEngine("PyTorch")
.optProgress(new ProgressBar())
.build();
// 加载模型
model = criteria.loadModel();
}
public String classifyImage(MultipartFile file) throws IOException, TranslateException {
// 将文件保存到临时位置
Path tempFile = Files.createTempFile("image", ".jpg");
Files.copy(file.getInputStream(), tempFile, StandardCopyOption.REPLACE_EXISTING);
// 加载图像
Image img = ImageFactory.getInstance().fromFile(tempFile);
// 预处理图像
Pipeline pipeline = new Pipeline();
pipeline.add(new Resize(224, 224));
pipeline.add(new ToTensor());
// 创建预测器
try (Predictor<Image, String> predictor = model.newPredictor()) {
// 进行预测
String result = predictor.predict(img);
// 删除临时文件
Files.delete(tempFile);
return result;
}
}
}
解释代码:
Criteria: 用于定义模型的准则,包括模型的类型、应用领域、模型名称、引擎等。
ZooModel: 从模型库中加载模型。
Predictor: 用于进行预测。
ImageFactory: 用于加载图像。
Pipeline: 用于定义图像预处理步骤,如调整大小和转换为张量。
Translator: 用于定义输入和输出的转换逻辑
4. 创建控制器
创建一个控制器类来处理 HTTP 请求。
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
@RestController
@RequestMapping("/api/classify")
public class ImageClassificationController {
private final ImageClassificationService imageClassificationService;
public ImageClassificationController(ImageClassificationService imageClassificationService) {
this.imageClassificationService = imageClassificationService;
}
@PostMapping
public ResponseEntity<String> classifyImage(@RequestParam("file") MultipartFile file) {
try {
String result = imageClassificationService.classifyImage(file);
return ResponseEntity.ok(result);
} catch (IOException | TranslateException e) {
return ResponseEntity.badRequest().body("Error classifying image: " + e.getMessage());
}
}
}
5. 启动应用程序
创建一个主类来启动 Spring Boot 应用程序。
POST /api/classify
Content-Type: multipart/form-data
Form Data:
file: (选择一个图像文件)
如果一切正常,你应该会收到图像的分类结果。
其他值得关注的Java AI框架
训练模型框架 deeplearning4j
处理步骤
- 数据处理:
- 定义数据模式
Schema,用于描述数据的结构。 - 使用
TransformProcess对数据进行转换,例如将分类标签转换为整数。 - 使用
CSVRecordReader读取 CSV 文件,并使用RecordReaderDataSetIterator创建数据集迭代器。
- 定义数据模式
- 神经网络配置:
- 使用
NeuralNetConfiguration配置神经网络的基本参数,如随机种子、权重初始化方法和优化器。 - 添加隐藏层和输出层,分别使用
DenseLayer和OutputLayer。
- 使用
- 模型训练:
- 创建
MultiLayerNetwork实例并初始化。 - 使用
fit方法对模型进行训练,训练多个轮次(numEpochs)。
- 创建
- 模型预测:
- 从数据集中获取测试数据,调用
output方法进行预测,并输出预测结果。
- 从数据集中获取测试数据,调用
RAG和微调的优点:
- 检索器能够快速访问广泛和最新的外部数据;
- 微调能够深度定制模型以适应专业领域;
- 生成器则结合外部上下文和微调后的领域知识来生成响应。
检索增强生成通过整合信息检索系统,能够根据上下文从外部资源中检索相关信息,这些信息补充LLM的输入,使其输出基于可靠来源的事实。RAG在开放领域问答和知识密集型任务中表现良好。(Retrieval-Augmented Generation, RAG)
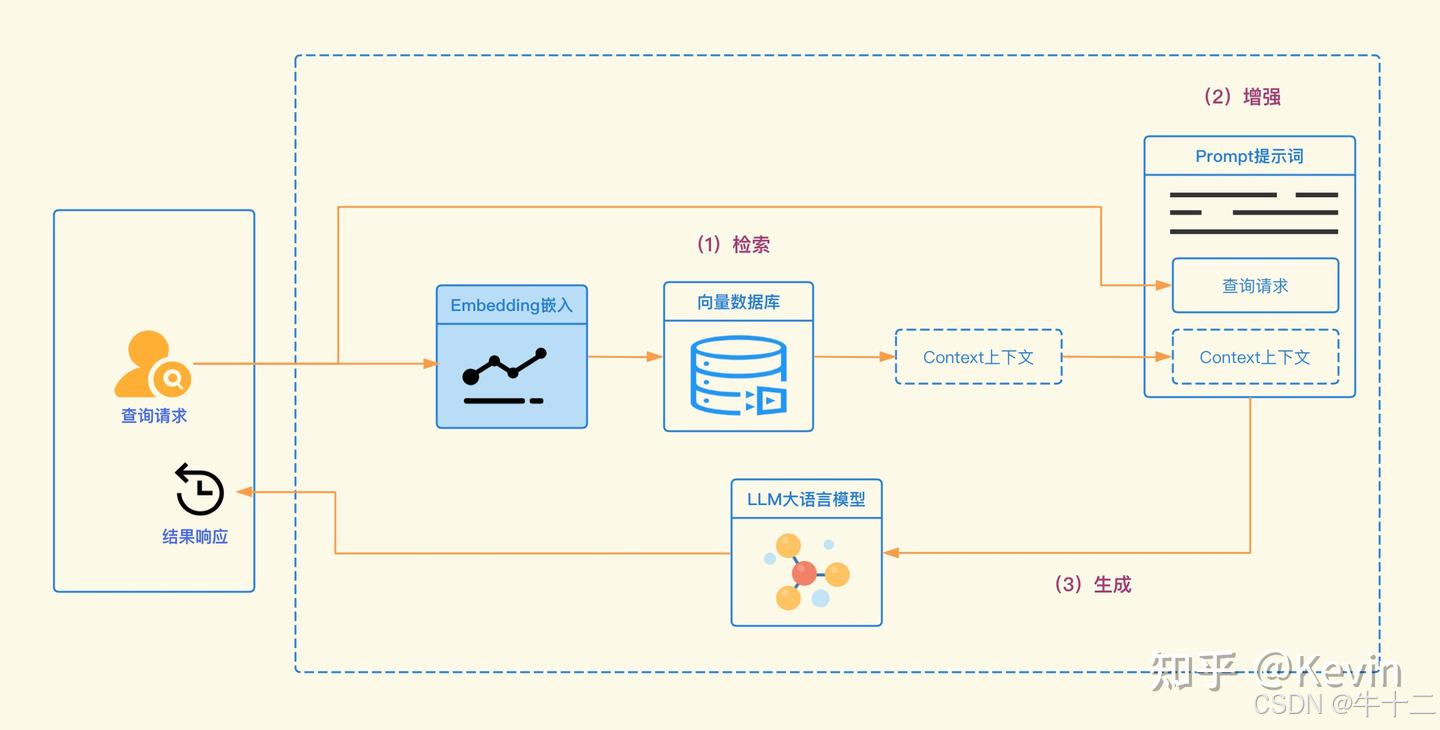
具体参考https://zhuanlan.zhihu.com/p/688138789
特定领域微调则通过在特定领域数据上调整LLM参数来实现模型专门化,使模型学习到相关的知识和语言模式,显著提升相关任务表现。
特定领域微调的应用场景
- 生物医学:在科学和医学数据上进行微调,使LLM能够帮助完成回答问题、文献分析,甚至医学编码等任务。
- 计算机科学:在代码库和文档上进行微调,帮助LLM提升代码生成、文档理解,以及开发工具支持。
- 金融:在金融新闻、报告和分析上进行微调,提高了LLM在股票预测、风险评估和财务报告生成等方面的能力。
- 法律:在法律文件和案例法上进行微调,使LLM能够协助进行法律研究、合同分析,甚至起草法律文件。

















 5527
5527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









