



前言
最近OpenAI扔出来最强推理模型o3,o系列主打推理能力,前段时间发布的o1已经表现出较强的推理能力了。这次不叫o2也是因为这个名字跟欧洲一个运营商重名了。o3聚焦于负责的任务的推理,包括编程、数学的通用智能等。当前还没有正式发布,预计要25年一季度发布,如果效果没夸大将是AI的一个标志性进步。
o3的性能如何
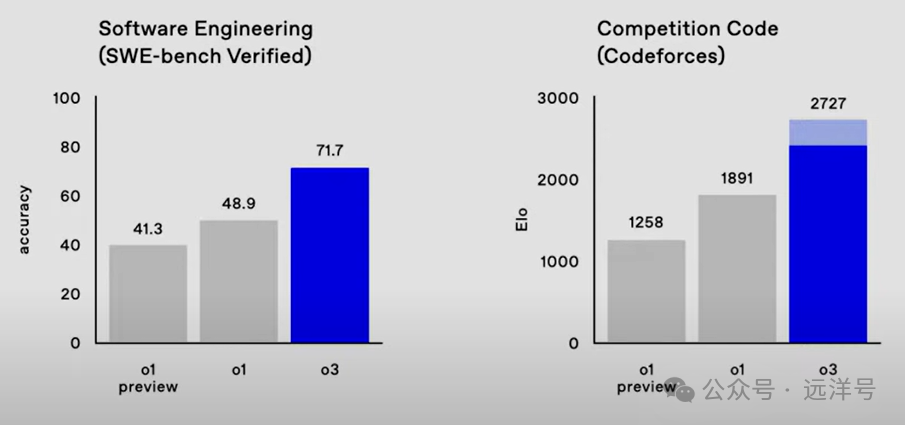
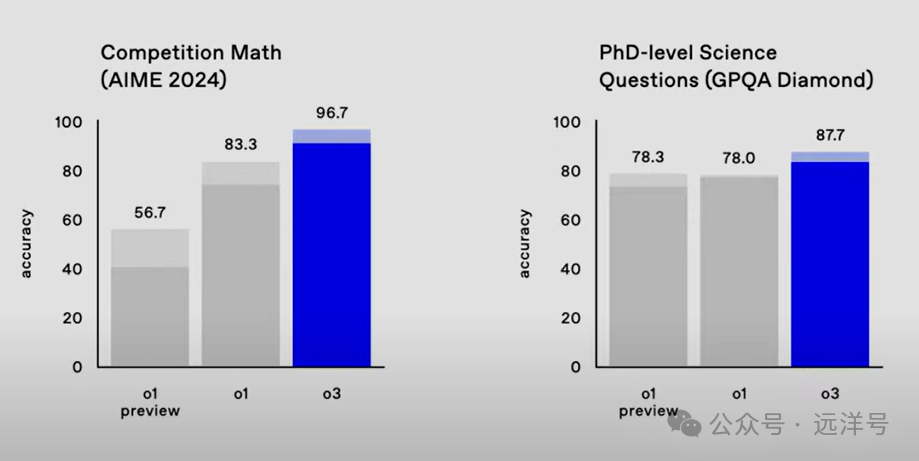
作为OpenAI当前最强推理的模型o3,它在编码、数学和科学问答上相比于o1有了很大的提升。从下面两图可以出详细的对比,上图是两个代码测试基准,相比于o1及o1预览版准确率都有了大幅提升。下图是数学和科学问答,同样也有客观的准确率提升。
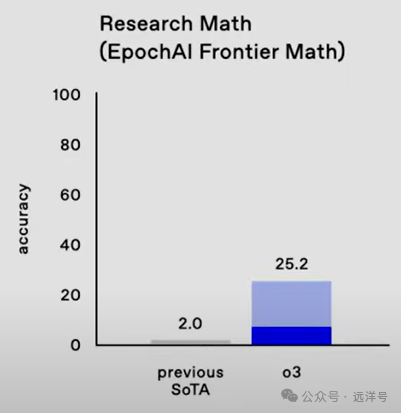
数学上的表现
数学本来被认为是人类智能最高领地,但是现在传统的数学测试基准已经被LLM刷烂了,比如MATH和GSM8K之类的,可以认为基本都被大模型死记硬背住了。所以后来Epoch AI组织了世界数学大师们打造了FrontierMath基准。这里面的题都非常难,连陶哲轩都说需要花很多时间才能做出来。在o3之前各种LLM去做题都很低分,SOTA也才到2%,这次o3提到了25.2%,可以说是超大幅的提升。也就是说o3超越了死记硬背的范式,已经具备一定的抽象推理能力,即使之前没有见过的情况也能思考推理。
ARC-AGI基准
o3主要被吹捧的成就是在ARC-AGI基准的突破,这个测试基准被认为是当前比较权威的用于测试通用人工智能的标准。ARC是抽象与推理语料库的简称,主要是通过少量样例来衡量推理的能力,这些事对于人类来说是比较容易的,但是对于机器来说却很难,之前的LLM都表现得很差。每个任务都需要理解总结后推理,他并不是靠记忆或模式来解决。
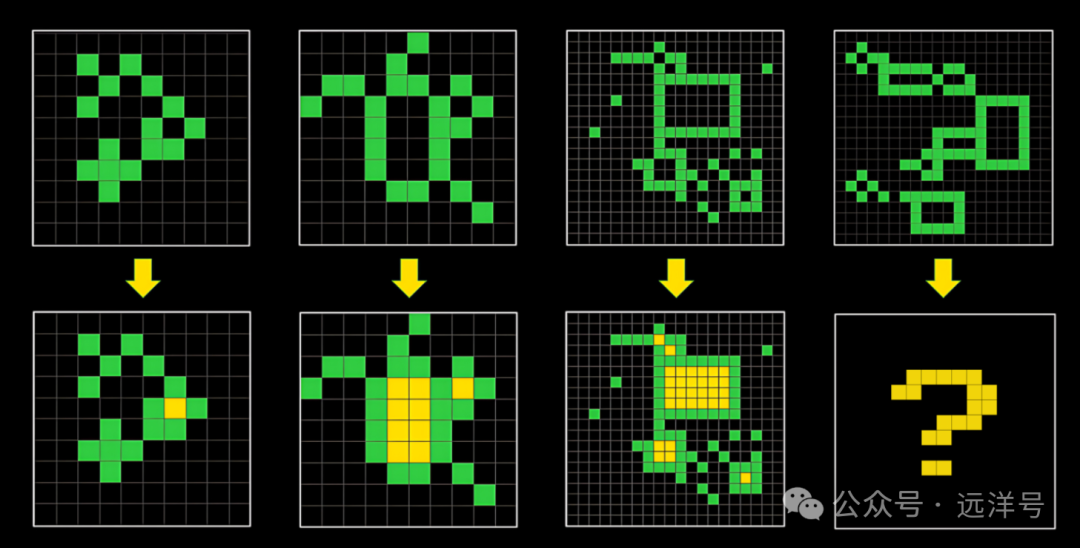
实际上ARC是一个竞赛,ARC-AGI是该竞赛提供的测试基准,详细情况可以去官网看https://arcprize.org。
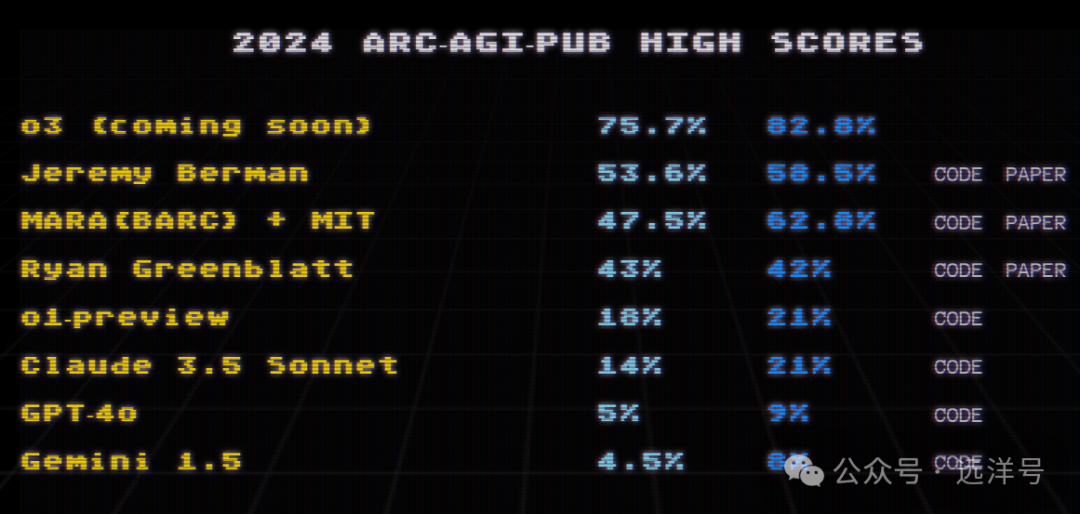
o3在ARC-AGI的表现
o3在ARC-AGI基准表现非常出色,算是一个里程碑进步。在低消耗成本模式下得分为76%,在高消耗成本模式下得分为88%,超过了人类85%的表现。也是第一次有模型能够超过人类的表现。也一定程度表现了o3具有很强的适应新任务的能力,而不是靠死记硬背或暴力计算等方式。
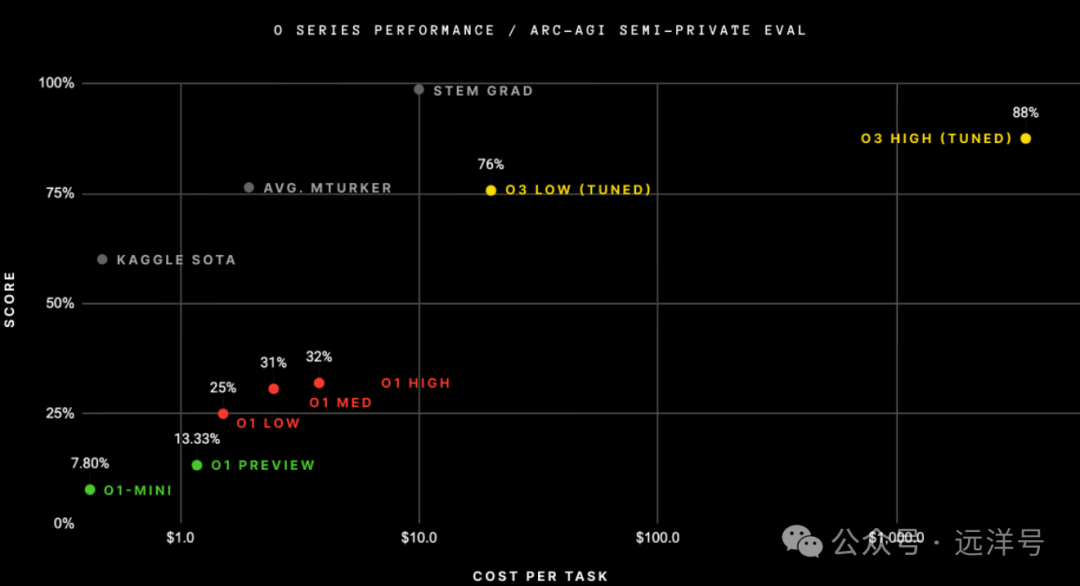

OpenAI的GPT之前花了四年才将ARC-AGI从0%提升到5%,也就是2020年的GPT-3是0%,一直到2024年的GPT-4o才到5%。
与传统LLM对比
传统模型更像是将所有案例都背诵起来,通过“存储-获取-使用”的模式能够实现相关功能,但它对未见过的案例就无能为力。而o3则除了具备传统LLM的知识外,它还能在面对新任务时构建新的程序来执行这个新任务。这个程序是通过COT来描述的,里面包含了解决问题的执行步骤。
理性看待
虽然o3已经验证了模型具有对新任务的适应性,而且这些任务是它从来没见过的,也是LLM所不具备的。但不管怎样ARC-AGI也只是一个测试基准,测试的案例也是人为设定的,只能代表某个方面的能力,而且基准也能不断升级。当前o3测试的基准实际上是ARC-AGI-1,就算取得很好的成绩,那对于升级后的基准可能又表现得很差,比如ARC-AGI-2可能就会让o3从88%降到30%以下。所以只能在一定程度上说明初步具备了通用能力。
此外,推理的成本也非常昂贵,o3低成本模式每个任务要花费20美刀,而高成本的一个任务得数千美刀,计算量是低成本的172倍。所以这个成本是没办法推广的。就好比官方还说他们雇佣别人完成这个任务是5美刀,而o3的低成本模式都得20美刀,更别说高成本模式了。
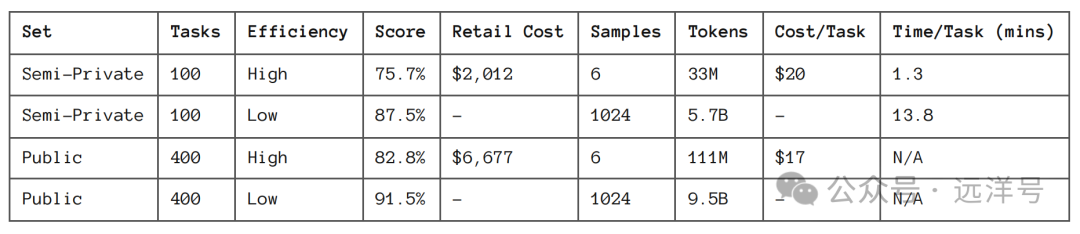
最后,官方也说了,这个基准只是为了引导AI去解决还未解决的问题,而并不能当成是AGI标准测试。通过了这个基准也不代表实现了通用人工智能。o3肯定还不是AGI,它还是会犯很简单的错。

















 4611
4611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









