



整体情况
结合业务数据验证DeepseekR1论文中提到的DeepseekR1核心关键点,包括强化学习(GRPO)、推理能力的蒸馏、SFT+COT(Inference Scaling Laws)验证。
实验环境及数据
模型:Qwen2.5-0.5B-Instruct
场景:sql生成。
数据:数千样本
算力:一张A100卡
SFT 与 RL
SFT与RL本质相同,都是监督学习,只是sft有明确的标签,而RL只有明确的 reward。对于LLM领域,sft 做的是NTP任务,RL是通过reward来调整NTP。也就是说在定义损失函数时角度不同。甚至对齐任务时也可以直接SFT。不过RL能基于规则去调整分布,而SFT则是黑盒调整。比如RL能用最终答案或分步推理来指引调整,SFT则不行。
强化学习
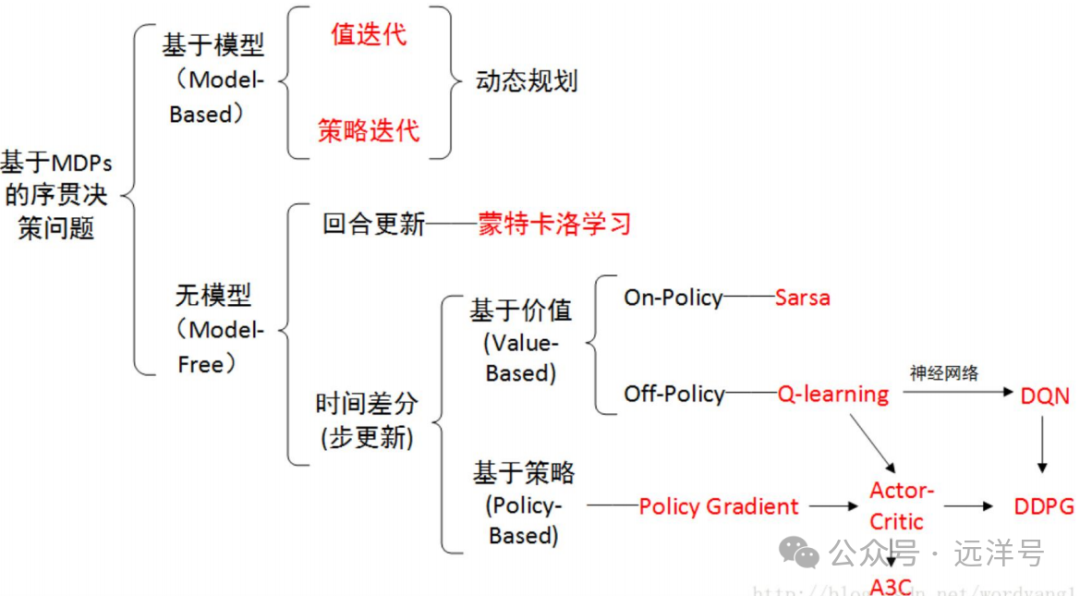
基于价值:学习状态或状态-动作的价值函数(如Q值、V值),通过价值函数推导最优策略。 基于策略:直接优化策略函数(Policy),即状态到动作的映射,通过梯度上升最大化期望累积奖励。 PPO和GRPO都是基于策略。
PPO 原理介绍
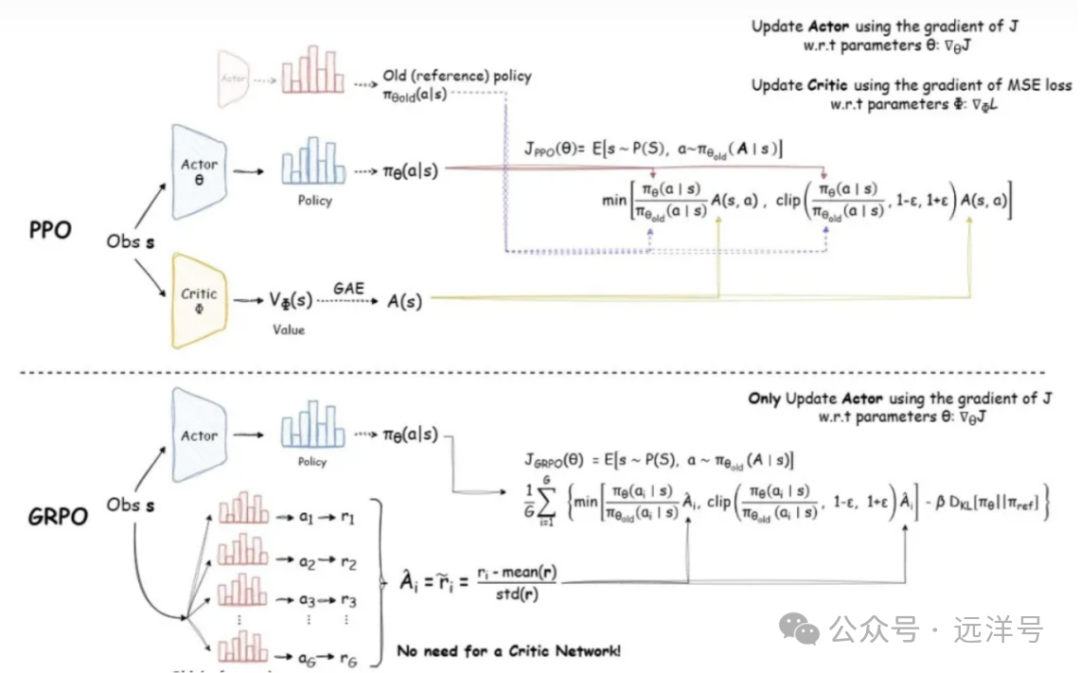
PPO:Actor-Critic结构,涉及策略、价值函数、奖励模型和参考模型。
LLM为给定的prompt生成多个response(时序=多个状态-动作转换过程)。
奖励模型给每个response分配reward(直接把整个时序的reward进行更新不稳定方差大激励不到位)。
使用GAE计算优势(advantages),GAE定义了某状态s下policy采取某个动作a比平均水平好多少,计算需要引入critic预测仅给出部分状态的最终奖励,涉及计算整个时序的平均奖励。GAE中计算时需要当前状态对考虑奖励的影响,极端情况分为全步长和单步长,有一个λ衰变控制对未来的影响。
根据目标函数来更新优化LLM。
更新critic(值函数)以更好地预测给定部分响应的奖励。
Clip与min防止更新过度。图中没写KL,但一般也会用,通过参考模型约束policy偏离。
GRPO原理介绍
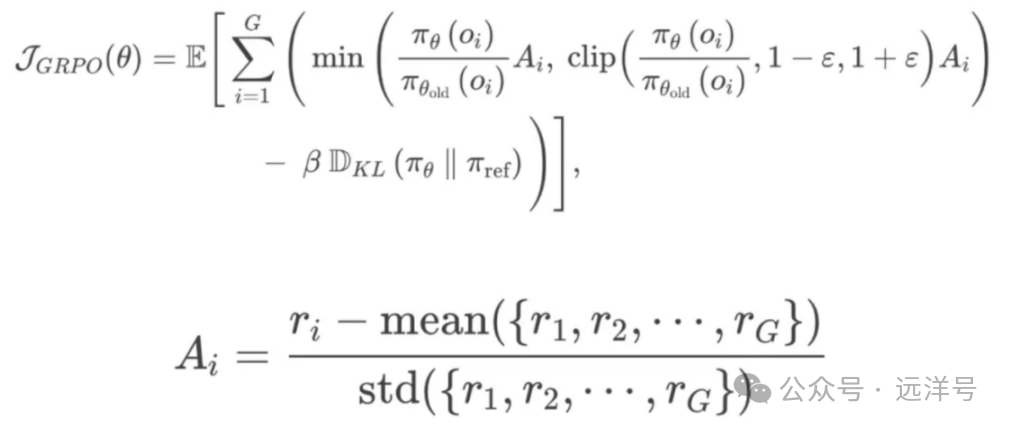
将PPO中的Critic(价值函数)去掉了,它的大小与 Actor 一样,成本高。
GAE计算优势时不使用Critic,而是直接采样N个response,将这些输出的平均奖励当作baseline。
更多AI原理
更多AI概念、算法原理、机器学习、深度学习及大模型原理讲解,可以参考我的书《炉边夜话——深入浅出话AI》。
GRPO 微调
目标是通过强化学习让模型学习到我们定义的格式去做生成,包括有推理过程、包含的列和最终的sql。
<reasoning>
...
</reasoning>
<columns>
...
</columns>
<sql>
...
</sql>
第一步,我们人工设定好各种规则,如果是业务上的则需要提出业务规则,GRPO强化学习与SFT微调最大的不同就是要定义奖励函数。这里定义了准确性奖励、格式奖励和select语句奖励。也就是说如果符合这些规则就会得到奖励。

第二步,构建GRPO训练器并将所有奖励函数传入进行开始训练。可以看到随着训练的进行,奖励不断增加。
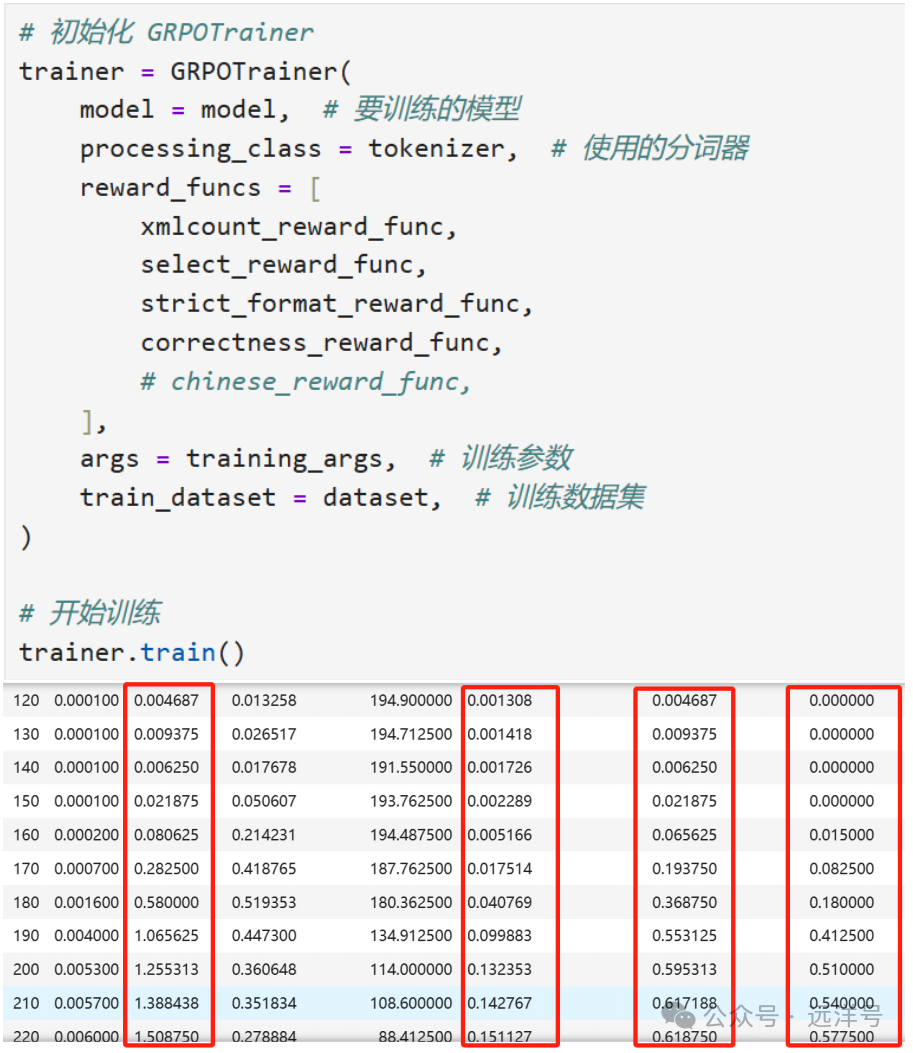
最终看看1000步后完整的奖励趋势,可以看到大概训练到两百多步时奖励基本达到最高的附近,后面基本都在附近。原始的模型基本不遵守,到后面训练完成后基本都遵守这个输出,并且生成的sql质量也提升很多。
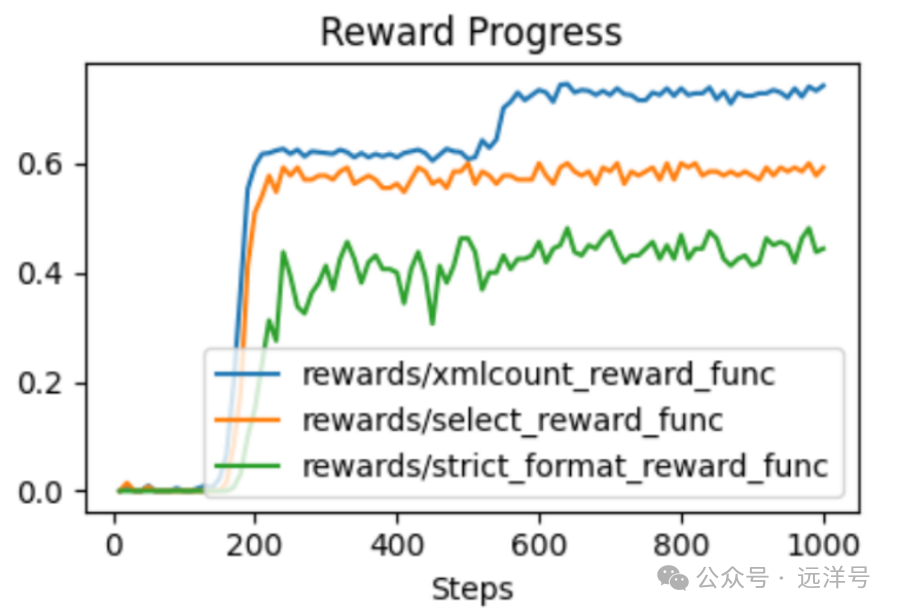
另外,准确性奖励比较难定义,因为同样的查询语句有各种各样的sql写法,所以这里只匹配了参考答案不太适合,所以想了方法将生成的sql与参考答案发给deepseek进行判断是否等效。这个方法能有效解决,实际上就是将deepseek作为老师去蒸馏他的sql生成能力。
推理能力的蒸馏
实际上就是说要将类似deepseekR1的推理过程附加到传统的LLM上。
第一步,将1000条数据发送给deepseek生成相应的推理及答案,如下表。这里我自己定义了......格式,分别存放推理及答案。

定好相关提示词开始训练,训练300步后loss基本收敛。

用sql生成相关的指令时则会按照......方式推理,而如果其它问题,比如“你好”则按照原来的应答方式。实验证明通过生成的推理过程样本能够直接SFT微调原来的LLM模型,并且能按自定义的推理格式进行。也就是将老师模型生成推理过程样本后对LLM做SFT微调就能实现推理能力的蒸馏,另外要全面推理也需要有全场景的数据样本。
<reasoning>
要列出高于平均年龄的歌手的所有歌名,我们需要执行以下步骤:
1. 首先,我们需要计算所有歌手的平均年龄。这可以通过对`singer`表中
的`age`字段使用`AVG()`函数来实现。
2. 接下来,我们需要筛选出年龄大于平均年龄的歌手。这可以通过在
`WHERE`子句中使用子查询来实现,子查询返回平均年龄。
3. 最后,我们需要从`singer`表中选择这些歌手的`song name`字段。
综上所述,SQL查询将首先计算平均年龄,然后筛选出年龄大于平均年龄的歌手,并返回他们的歌名。
</reasoning>
<sql>
SELECT `song name`\nFROM `singer`\nWHERE `age` > (SELECT AVG(`age`) FROM `singer`);
</sql>SFT+COT(Inference Scaling Laws)
在sql生成的场景中,通过0.5B千问模型能很明显看到增加了推理过程的SFT微调后的模型能更好的生成sql。比如对于“按歌手年龄从最大到最小,显示每个歌手的姓名、国家、年龄。”指令,没增加推理前产生下面错误的生成,而有推理框架后则能正确生成。Inference Scaling Laws的方向是业内后面发展的主要方向。
SFT+GRPO领域微调新范式
通过以上DeepseekR1关键点复现及验证,发现实际上SFT与GRPO是可以结合起来的,sft更多是数据驱动的黑盒优化,而GRPO则是有明确规则时的优化方式。实际上两种优化方式在后面实际场景都能结合起来使用。
以sql生成为例。首先通过大量收集和生成的样本做SFT,然后再根据生产反馈回来的错误样本,总结一些业务或通用型的规则,再用GRPO对SFT微调后的模型进行二次优化。

















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









