




一、注意力机制背景:
在Transformer架构中,自注意力(Self-Attention)是核心组件。其基本公式为: 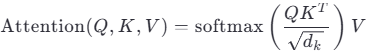 其中:
其中:
Q (Query):查询向量,表示问询量。用于与其他位置的Key交互,计算相似度
K (Key):键向量,用于匹配查询的特征
V (Value):值向量,是最终被加权求和的内容
dk:Key的维度,用于缩放防止梯度爆炸
注意力机制的本质是:通过Q与K的相似性,决定对每个V赋予多大的权重,从而实现“有选择地关注”。
在传统Transformer的自注意力机制中,输入序列中的每个位置(每个词/子词对应的嵌入向量)都会生成自己独立的查询(Query, q)、键(Key, k)和值(Value, v)向量。这是自注意力机制的核心设计之一,但是每个输入位置(token)都生成独立的 q、k、v 向量,也是 Transformer 架构中计算和内存消耗的主要来源之一。每个 token 的嵌入向量(d_model 维)需通过三个独立的线性变换,权重矩阵 W_q, W_k, W_v,每个维度 d_model × d_model。
在大模型注意力机制中,在传统查询 Q 是基础上,为了增强注意力能力与模型表达与优化计算量、显存消耗衍生出了 MHA、MQA、GQA 等多种注意力机制。
传统查询 Q:在注意力机制中,传统查询 Q 是用于表示当前 token 对其他 token 关注度的向量。通过将输入序列经过线性变换得到 Q,再与键向量 K 进行点积运算,得到注意力分数,进而与值向量 V 加权求和,得到最终的注意力输出,以此来确定当前 token 与其他 token 的相关程度,聚焦关键信息。
多头注意力机制(MHA)中的查询:MHA 是 Transformer 架构的核心组件。它将输入向量分别通过多个线性变换层,得到多个查询 Q、键 K 和值 V 矩阵,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









