



2025年9月25日哔哩哔哩发布的IndexTTS2版本简介说明是首个具备精确合成时长控制能力的自回归TTS模型,同时支持可控与不可控两种模式。该功能在本次版本中暂未开放。模型实现了高表现力的情感语音合成,通过多输入模态支持情感可控功能。代码库:https://github.com/index-tts/index-tts
实测角色音色模拟的真的挺好。
文档里面有具体的安装步骤,如果在linux上可能出现的问题是cuda与驱动的安装是否缺少。
- 安装git lfs 这个安装或者不安装都可以,我觉得不重要,主要是下载一些音频示例文件,手动一样可以下载。
git lfs install
- 下载git 库文件
git clone https://github.com/index-tts/index-tts.git && cd index-tts
下载库里音频示例文件
git lfs pull
- 安装uv 包管理工具,基本比较简单,附个文章协助安装
https://zhuanlan.zhihu.com/p/689976933
- 安装相关依赖包,推荐指定国内源
uv sync --all-extras --default-index "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple"
- 下载模型文件有两种方式
1) huggingface 下载
uv tool install "huggingface_hub[cli]"
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
2) 通过魔搭下载,这个更加推荐
uv tool install "modelscope"
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints
运行代码时候会通过huggingface额外下载一些语义模型、分词模型,所以要使用代理
export HF_ENDPOINT="https://hf-mirror.com"
- 检查运行模型芯片
uv run webui.py
- 运行模型页面
uv run python webui.py -h
在运行7步骤时候报错,可能是因为安装nvcc、cuda。cuda可以通过‘nvidia-smi’ 指令查看cuda版本和驱动。通过’nvcc --vision‘检查cuda toolkit,如果没有到网站寻找对应版本下载
https://developer.nvidia.com/cuda-toolkit-archive。主要留意本地的nvidia-smi显示的版本,下载的能低于本地版本合适。
我是用的是runfile文件下载后本地安装
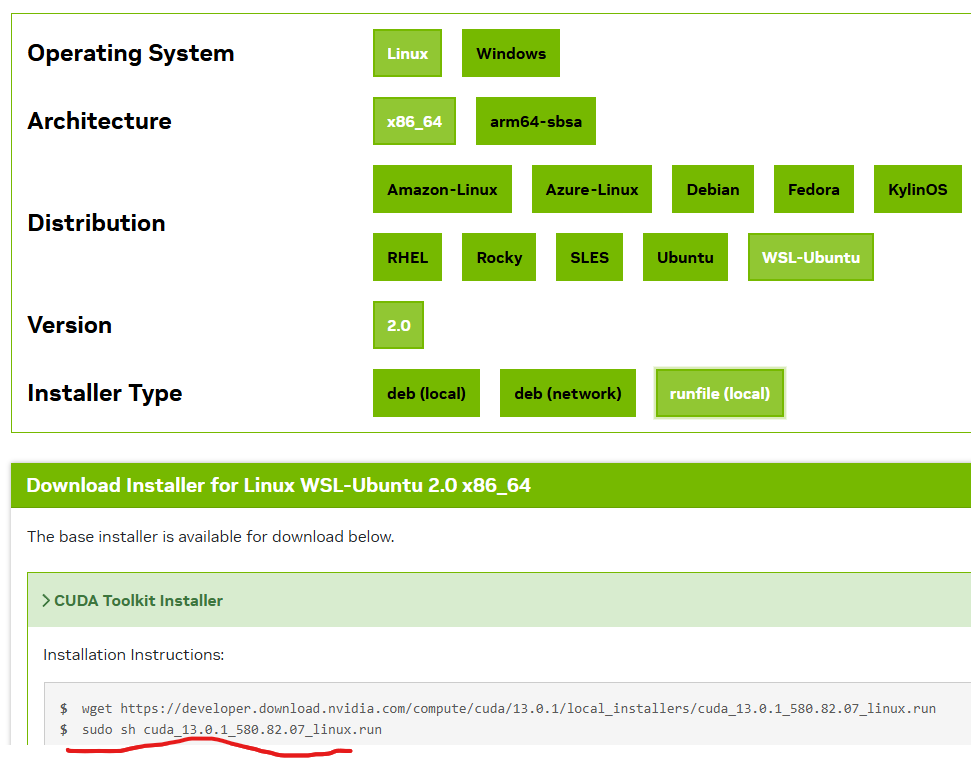
安装第一次失败,后面修改安装指令,附带安装驱动和toolkit
sudo sh cuda_13.0.1_580.82.07_linux.run --driver --toolkit



















 3641
3641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









