考虑一下,我们现在想对一棵树进行树链剖分,那么我们首先要知道这棵树的一些信息,比如每一个节点的重儿子是谁,每一个节点的父节点是谁,节点深度,以及每一个节点对应到线段树上的标号也就是这棵树的 d f s dfs dfs序
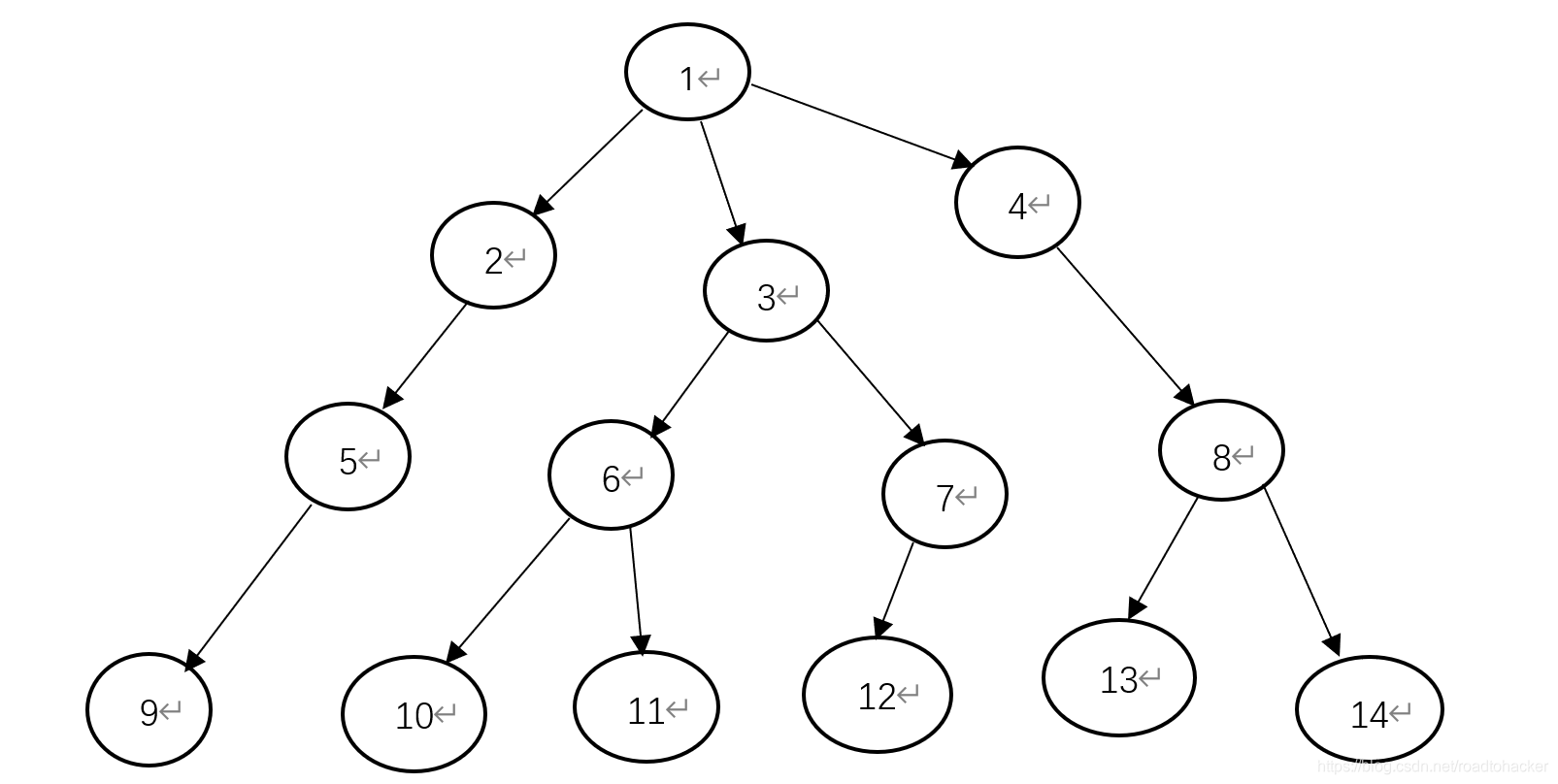
要想得到这些信息,我们需要对这棵树进行搜索,以下图为例
现在的标号是树的节点的序号,而不是线段树维护的序列,所以我们需要把这些序号对应到线段树上去,也就是重写这些序号,这个操作在第二次 d f s dfs dfs中完成
两次搜索
这两次搜索分别处理轻重儿子和线段树标号的问题
dfs1
s z [ i ] sz[i] sz[i]表示 i i i节点的子树节点个数, d e p t h [ i ] depth[i] depth[i]表示 i i i节点的深度, f [ i ] f[i] f[i]表示节点 i i i的父亲节点, s o n [ i ] son[i] son[i]表示 i i i节点的重儿子,进行一次 O ( n ) O(n) O(n)的 d f s dfs dfs,
int son[MAXN];int depth[MAXN];int f[MAXN];int sz[MAXN];voiddfs1(int u,int fa,int dep){
sz[u]=1;
f[u]= fa;
depth[u]= dep;int maxson =-1;for(int i=head[u];~i;i=edge[i].next){
int v = edge[i].to;if(v == fa)continue;dfs1(v, u, dep +1);
sz[u]+= sz[v];if(sz[v]> maxson){
maxson = sz[v];
son[u]= v;}}}
稍微解释一下 m a x s o n maxson maxson,它的意思是当前节点 u u u的可能的重儿子的子树节点数,直到遍历完 u u u的所有儿子,最后确定重儿子到底是谁
dfs2
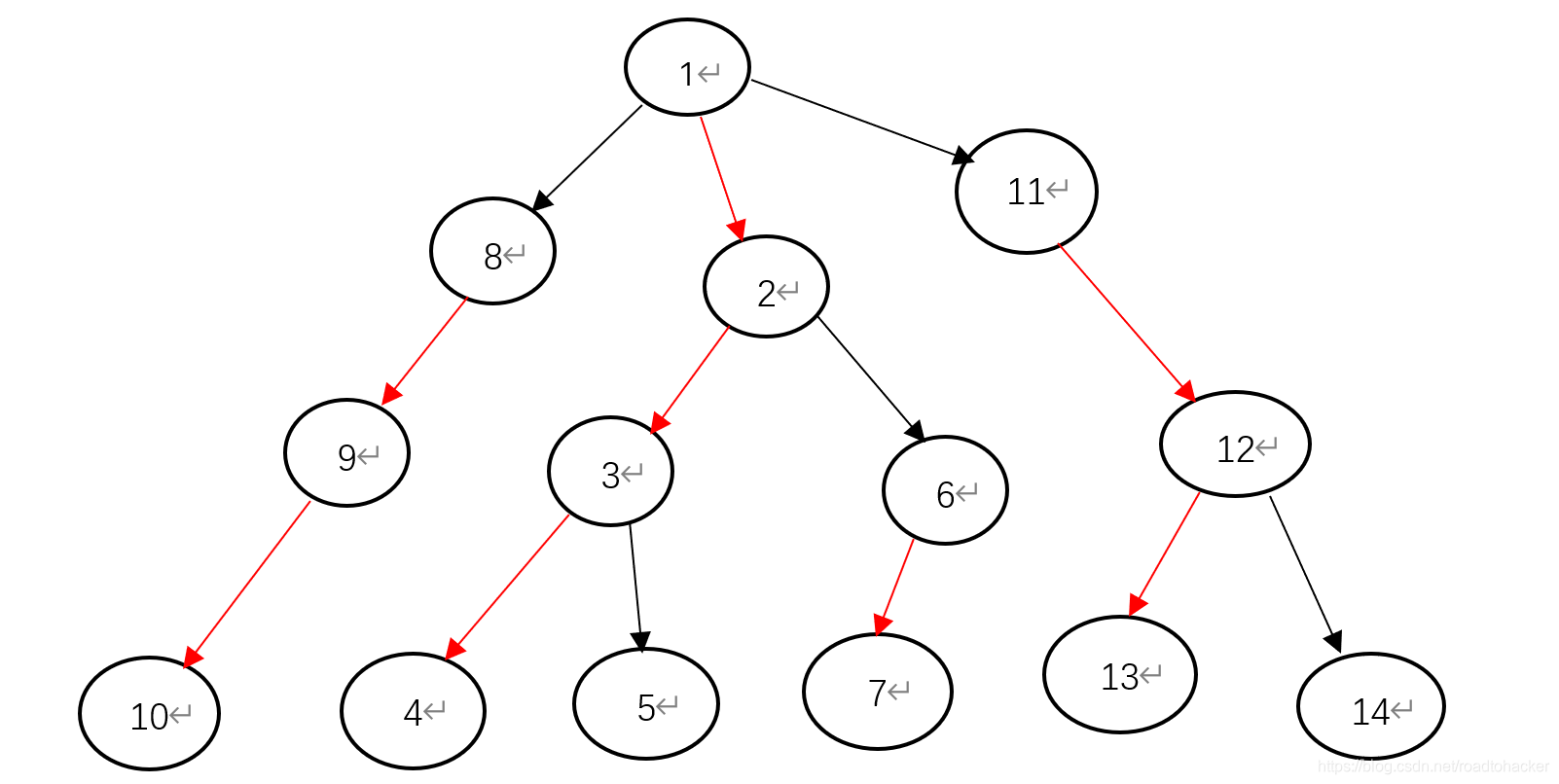
我们得到 d f s 1 dfs1 dfs1中的信息之后,开始 d f s 2 dfs2 dfs2,这一次我们的目的是找重链,并按照轻重链重新给树上的节点标号,如下图
这里面我标记红色的就是重链
那么进行这样的轻重链剖分的好处是什么呢,或者说有什么用
我们可以发现,现在这棵树已经被划分成了若干条重链,一条重链上的序号都是连续的,同一棵子树里面的节点的 d f s dfs dfs序也是连续的,我们就可以利用这个性质来进行线段树的维护
int top[MAXN];int wt[MAXN];int id[MAXN];int Data[MAXN];int dfn;voiddfs2(int u,int topf){
top[u]= topf;
id[u]=++dfn;
wt[dfn]= Data[u];if(!son[u])return;dfs2(son[u], topf);for(int i=head[u];~i;i=edge[i].next){
int v = edge[i].to;if(v == son[u]|| v == f[u])continue;dfs2(v, v);}}
t o p [ i ] top[i] top[i]表示 i i i节点所在重链的顶端节点, i d [ i ] id[i] id[i]表示 i i i号节点经过重新编号之后所对应的号码, d f n dfn dfn为时间戳也就是 d f s dfs dfs序, D a t a [ i ] Data[i] Data[i]表示开始的点权, w t [ i ] wt[i] wt[i]表示经过重新编号之后的点权
程序应该比较好理解,不做解释
线段树维护
首先线段树我们应该是会的,那么新树已经产生了,现在我们想把每一条链都用线段树进行维护,正好维护的是 1 − n 1-n 1−n这么一个区间,因此,我们可以设立如下的线段树结构,并建立一棵线段树





 本文介绍了如何通过轻重链剖分算法将树结构划分为重链,并利用线段树进行高效维护。重点讲解了dfs1和dfs2搜索过程,以及如何利用两次搜索结果构建线段树结构,包括区间操作和倍增思想的应用实例。
本文介绍了如何通过轻重链剖分算法将树结构划分为重链,并利用线段树进行高效维护。重点讲解了dfs1和dfs2搜索过程,以及如何利用两次搜索结果构建线段树结构,包括区间操作和倍增思想的应用实例。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











