




 本文深入解析最小二乘法原理及其在多元线性回归中的应用,通过PyTorch实例展示如何求解权重矩阵,比较MSE、MAE及Smooth L1损失函数,并演示Linear类的使用。
本文深入解析最小二乘法原理及其在多元线性回归中的应用,通过PyTorch实例展示如何求解权重矩阵,比较MSE、MAE及Smooth L1损失函数,并演示Linear类的使用。
最小二乘法求解
什么是最小二乘法?
如何理解最小二乘法?
我们假设对如下线性关系进行求解:
Y
=
W
X
Y=WX
Y=WX
例如:
已知X和Y矩阵:
X 4 ∗ 2 = [ x 00 x 01 x 10 x 11 x 20 x 21 x 30 x 31 ] X^{4*2}=\begin{bmatrix}x_{00}&x_{01}\\x_{10}&x_{11}\\x_{20}&x_{21}\\x_{30}&x_{31}\end{bmatrix} X4∗2=⎣⎢⎢⎡x00x10x20x30x01x11x21x31⎦⎥⎥⎤ 和 Y 4 ∗ 1 = [ y 0 y 1 y 2 y 3 ] Y^{4*1}=\begin{bmatrix} y_0\\y_1\\y_2\\y_3\end{bmatrix} Y4∗1=⎣⎢⎢⎡y0y1y2y3⎦⎥⎥⎤
求解得到W矩阵:
W 2 ∗ 1 = [ w 0 w 1 ] W^{2*1}=\begin{bmatrix}w_0\\w_1\end{bmatrix} W2∗1=[w0w1]
import torch
x=torch.tensor([[1,1,1],[2,2,1],[3,4,1],[4,2,1],[5,4,1]],dtype=torch.float32)
y = torch.tensor([-10,12,14,16,18],dtype=torch.float32)
wr,_=torch.lstsq(y, x) # _ 废弃变量承接的是QR分解结果,用于对最小二乘法进一步分析
w=wr[:3] #[0][1][2]表示三个parameters的值,后面[3][4]表示残差量,他们的平方和是MSE的值
print(w)
输出:
tensor([[ 4.6667],
[ 2.2222],
[-9.7778]])
多元线性回归
实际上,就是求多个单线性回归,只是合并在一个矩阵里面运算。
import torch
#多个因变量
x = torch.tensor([[1, 1, 1], [2, 3, 1],[3, 5, 1], [4, 2, 1], [5, 4, 1]],dtype=torch.float32)
y = torch.tensor([[-10, -3], [12, 14], [14, 12], [16, 16], [18, 16]],dtype=torch.float32)
wr, _ = torch.lstsq(y, x)
w = wr[:3, :]
print(w)
输出:
tensor([[ 4.6667, 3.3333],
[ 2.6667, 1.3333],
[-12.0000, -3.0000]])
MSE损失,平滑 l 1 l_1 l1 范数损失,MAE损失
向量范数:
p-范数
∣
∣
x
∣
∣
p
=
(
∑
i
=
1
N
∣
x
∣
p
)
1
p
||x||_p=(\sum^N_{i=1}|x|^p)^\frac{1}{p}
∣∣x∣∣p=(i=1∑N∣x∣p)p1
三种损失:
- MSE损失(Mean squared error):均方误差 (最小二乘法就是要让MSE最小)
我们称为 l 2 l o s s l_2loss l2loss
l ( W ; X , Y ) = 1 n ∣ ∣ Y − X ∗ W ∣ ∣ 2 2 = ∑ i = 0 n − 1 ( y i − x [ i , : ] W ) 2 l(W;X,Y)=\frac{1}{n}||Y-X*W||_2^2=\sum_{i=0}^{n-1}(y_i-x[i,:]W)^2 l(W;X,Y)=n1∣∣Y−X∗W∣∣22=i=0∑n−1(yi−x[i,:]W)2 - MAE损失(Mean absolute deviance):平均偏差
我们称为 l 1 l o s s l_1loss l1loss
Z是我们预测结果,Y是标签
l ( Z , Y ) = 1 n ∑ i = 0 n − 1 ∣ Z − Y ∣ l(Z,Y)=\frac{1}{n}\sum_{i=0}^{n-1}|Z-Y| l(Z,Y)=n1i=0∑n−1∣Z−Y∣ - Smooth
l
1
l_1
l1 loss:平滑
l
1
l_1
l1 范数损失
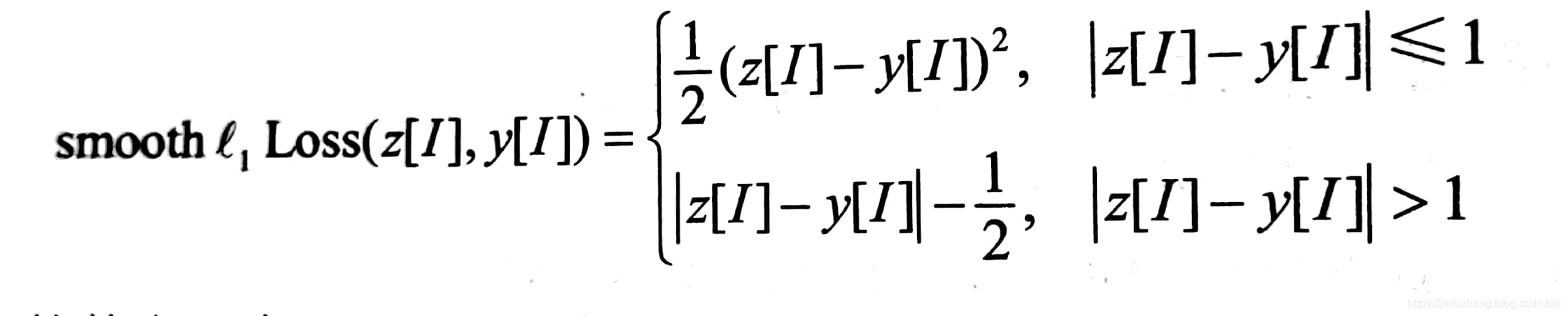
三种损失的图像区别
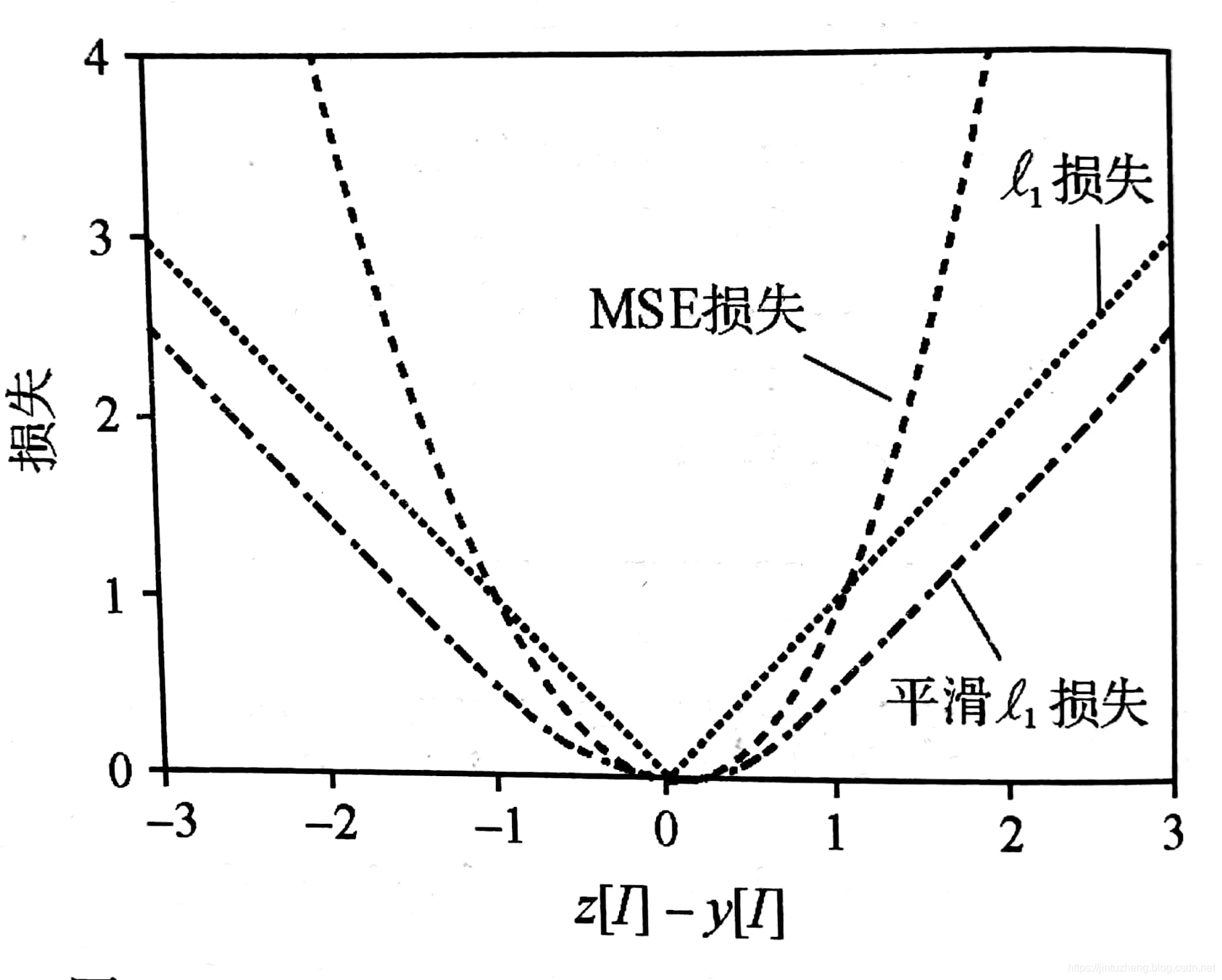
- MSE损失在个别元素差别较大对整体影响大,但计算简单,最常用。
- l1 loss 能够克服个别元素较大对整体带来的影响,但数据的微小变化会导致最优权值的跳变。
- smooth l1 loss 则是结合两者优点有所权衡,但计算量最大。
torch.nn的损失类:
| 损失 | Pytorch 的 torch.nn类 |
|---|---|
| MSE | torch.nn.MSELoss |
| l1 loss | torch.nn.L1Loss |
| smooth l1 loss | torch.nn.SmoothL1Loss |
为什么我们需要用损失类来解决?不直接想前面那样子用torch.lstsq函数解?
因为我们更多时候面临的数据量巨大无法一次载入内存。但即使是lstsq函数内部也是遵循这样的原则:先求损失,再求损失梯度,并据此进行迭代W的值。
这里示例用Adam算法求解最小二乘法的权重:
import torch
import torch.nn
import torch.optim
x = torch.tensor([[1., 1., 1.], [2., 3., 1.],[3., 5., 1.], [4., 2., 1.], [5., 4., 1.]])
y = torch.tensor([-10., 12., 14., 16., 18.])
w = torch.zeros(3, requires_grad=True)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam([w,],)
for step in range(30001):
if step:
optimizer.zero_grad()
loss.backward()
optimizer.step()
pred = torch.mv(x, w) # 矩阵和向量相乘
loss = criterion(pred, y)
if step % 1000 == 0:
print('step = {}, loss = {:g}, W = {}, grad = {}'.format(step, loss, w.tolist(),w.grad))
输出:
step = 0, loss = 204, W = [0.0, 0.0, 0.0], grad = None
step = 1000, loss = 86.8401, W = [0.863132655620575, 0.8542490005493164, 0.8209308981895447], grad = tensor([-43.0341, -39.0519, -8.0636])
step = 2000, loss = 53.6289, W = [1.443850040435791, 1.394601583480835, 1.1897929906845093], grad = tensor([-17.2224, -13.3208, -0.5948])
step = 3000, loss = 47.505, W = [1.7840827703475952, 1.6343560218811035, 0.9572442770004272], grad = tensor([-6.3248, -2.6239, 2.4238])
step = 4000, loss = 44.2888, W = [2.031564950942993, 1.7021596431732178, 0.256304532289505], grad = tensor([-3.7258, -0.3842, 2.9149])
step = 5000, loss = 40.8731, W = [2.305197238922119, 1.7125364542007446, -0.6180321574211121], grad = tensor([-2.7440, 0.0713, 2.8704])
step = 6000, loss = 37.5372, W = [2.6193671226501465, 1.6853392124176025, -1.5441280603408813], grad = tensor([-1.9327, 0.2000, 2.7401])
step = 7000, loss = 34.5258, W = [2.950958728790283, 1.635908603668213, -2.4787142276763916], grad = tensor([-1.2337, 0.1370, 2.5640])
step = 8000, loss = 31.9455, W = [3.259427785873413, 1.6028962135314941, -3.4061665534973145], grad = tensor([-0.6721, 0.0154, 2.3618])
step = 9000, loss = 29.7652, W = [3.5038464069366455, 1.6267777681350708, -4.3211588859558105], grad = tensor([-0.3070, -0.0609, 2.1417])
step = 10000, loss = 27.9001, W = [3.678380012512207, 1.713074803352356, -5.2205023765563965], grad = tensor([-0.1373, -0.0678, 1.9080])
step = 11000, loss = 26.3032, W = [3.8159337043762207, 1.8293808698654175, -6.101877689361572], grad = tensor([-0.0731, -0.0462, 1.6684])
step = 12000, loss = 24.9573, W = [3.942659854888916, 1.9499529600143433, -6.963371276855469], grad = tensor([-0.0427, -0.0281, 1.4292])
step = 13000, loss = 23.8511, W = [4.0643534660339355, 2.068524122238159, -7.801889419555664], grad = tensor([-0.0251, -0.0167, 1.1937])
step = 14000, loss = 22.9731, W = [4.181187152862549, 2.183582067489624, -8.612066268920898], grad = tensor([-0.0146, -0.0098, 0.9647])
step = 15000, loss = 22.31, W = [4.292291641235352, 2.293663501739502, -9.385353088378906], grad = tensor([-0.0084, -0.0057, 0.7452])
step = 16000, loss = 21.8445, W = [4.395955562591553, 2.3967199325561523, -10.108356475830078], grad = tensor([-0.0047, -0.0032, 0.5395])
step = 17000, loss = 21.553, W = [4.489279270172119, 2.4896857738494873, -10.760062217712402], grad = tensor([-0.0025, -0.0017, 0.3538])
step = 18000, loss = 21.4017, W = [4.567684173583984, 2.5678787231445312, -11.307973861694336], grad = tensor([-0.0012, -0.0008, 0.1976])
step = 19000, loss = 21.3455, W = [4.624871730804443, 2.6249473094940186, -11.707764625549316], grad = tensor([-0.0005, -0.0003, 0.0835])
step = 20000, loss = 21.3341, W = [4.655962944030762, 2.6559815406799316, -11.925154685974121], grad = tensor([-1.1551e-04, -7.9155e-05, 2.1393e-02])
step = 21000, loss = 21.3333, W = [4.665531158447266, 2.6655335426330566, -11.992058753967285], grad = tensor([-2.2531e-05, -1.7643e-05, 2.2699e-03])
step = 22000, loss = 21.3333, W = [4.666637897491455, 2.666637420654297, -11.999798774719238], grad = tensor([-1.7881e-06, -3.3379e-06, 5.6744e-05])
step = 23000, loss = 21.3333, W = [4.666657447814941, 2.6666581630706787, -11.999942779541016], grad = tensor([1.7524e-05, 1.7643e-05, 2.1100e-05])
step = 24000, loss = 21.3333, W = [4.666661739349365, 2.666660785675049, -11.999999046325684], grad = tensor([1.6928e-04, 1.7262e-04, 4.9591e-05])
step = 25000, loss = 21.3333, W = [4.66666841506958, 2.666668176651001, -12.0], grad = tensor([-1.4079e-04, -1.4257e-04, -4.0174e-05])
step = 26000, loss = 21.3333, W = [4.666660308837891, 2.6666598320007324, -12.000000953674316], grad = tensor([1.8811e-04, 1.8787e-04, 5.3167e-05])
step = 27000, loss = 21.3333, W = [4.6666646003723145, 2.6666643619537354, -11.999999046325684], grad = tensor([7.9155e-05, 7.9155e-05, 2.3365e-05])
step = 28000, loss = 21.3333, W = [4.666690349578857, 2.6666908264160156, -11.999999046325684], grad = tensor([0.0009, 0.0009, 0.0003])
step = 29000, loss = 21.3333, W = [4.666670799255371, 2.6666712760925293, -11.999999046325684], grad = tensor([-1.5616e-04, -1.5450e-04, -4.4584e-05])
step = 30000, loss = 21.3333, W = [4.666664123535156, 2.6666646003723145, -12.0], grad = tensor([-7.2241e-05, -7.1526e-05, -2.0742e-05])
Linear 类的使用
除了我们手动使用torch.mv函数进行相乘,我们还可以利用nn.Linear类实现。
对于Linear类,我们需要传入两个参数:第一个输入的自变量个数,第二个是因变量的个数。它的本意是,每个神经元有几个输入,这一层有几个神经元,,因为默认一个神经元一个输出。
除此之外,还有一个bias参数(bool)
bias = True :
y
=
x
1
w
1
+
x
2
w
2
+
x
3
w
3
+
.
.
.
+
x
m
w
m
+
w
m
+
1
y=x_1w_1+x_2w_2+x_3w_3+...+x_mw_m+w_{m+1}
y=x1w1+x2w2+x3w3+...+xmwm+wm+1
bias = False:
y
=
x
1
w
1
+
x
2
w
2
+
x
3
w
3
+
.
.
.
+
x
m
w
m
y=x_1w_1+x_2w_2+x_3w_3+...+x_mw_m
y=x1w1+x2w2+x3w3+...+xmwm
Linear 类有个 parameters() 函数成员,是结果生成器,每当内部的next函数被执行一次,里面的weights 和 bias 数值就会更新,我们只要给外界指定了结果就能直接接收了。
示例:利用 Linear 类实现线性回归:
import torch
########################################
#利用 Linear 类实现线性回归
x=torch.tensor([[1,1,1],[2,2,1],[3,4,1],[4,2,1],[5,4,1]],dtype=torch.float32)
y = torch.tensor([-10,12,14,16,18],dtype=torch.float32)
fc = torch.nn.Linear(3,1)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(fc.parameters())
weights,bias=fc.parameters()
pred=fc(x)
loss=criterion(pred,y)
for step in range(30001):
if step:
optimizer.zero_grad()
loss.backward()
optimizer.step()
pred=fc(x)
loss=criterion(pred,y)
if step % 1000 == 0:
print('step = {}, loss = {:g}, weights = {}, bias={}'.format(step, loss, weights[0, :].tolist(), bias.item()))
输出
step = 0, loss = 193.874, weights = [0.38213568925857544, -0.40109238028526306, -0.14789709448814392], bias=0.5723434686660767
step = 1000, loss = 120.656, weights = [1.1427322626113892, 0.3667737543582916, 0.6569845676422119], bias=1.3772251605987549
step = 2000, loss = 112.086, weights = [1.3835484981536865, 0.6448845267295837, 1.110307216644287], bias=1.83054780960083
step = 3000, loss = 110.591, weights = [1.292934775352478, 0.6336179375648499, 1.4574298858642578], bias=2.177670955657959
step = 4000, loss = 108.878, weights = [1.1011700630187988, 0.5585920810699463, 1.8989448547363281], bias=2.6191890239715576
step = 5000, loss = 107.111, weights = [0.8608409762382507, 0.466567724943161, 2.4456398487091064], bias=3.1658849716186523
step = 6000, loss = 105.635, weights = [0.5994001030921936, 0.36727017164230347, 3.0431745052337646], bias=3.7634196281433105
step = 7000, loss = 104.659, weights = [0.3544449806213379, 0.2649811804294586, 3.6210107803344727], bias=4.3412556648254395
step = 8000, loss = 104.177, weights = [0.16444911062717438, 0.1609525829553604, 4.108903408050537], bias=4.82914924621582
step = 9000, loss = 104.024, weights = [0.05249306559562683, 0.06887698918581009, 4.443802833557129], bias=5.164048671722412
step = 10000, loss = 104.001, weights = [0.009231429547071457, 0.015371127985417843, 4.600464820861816], bias=5.3207106590271
step = 11000, loss = 104, weights = [0.0006004637689329684, 0.0011296847369521856, 4.637117385864258], bias=5.357363224029541
step = 12000, loss = 104, weights = [8.76963349583093e-06, 1.5454570529982448e-05, 4.639837741851807], bias=5.36008358001709
step = 13000, loss = 104, weights = [6.007428510201862e-06, 8.366786460101139e-06, 4.639853477478027], bias=5.3600993156433105
step = 14000, loss = 104, weights = [3.82147891286877e-06, 5.0581907089508604e-06, 4.639862537384033], bias=5.360108375549316
step = 15000, loss = 104, weights = [2.1233911411400186e-06, 2.659172650965047e-06, 4.639869213104248], bias=5.360115051269531
step = 16000, loss = 104, weights = [1.3202105719756219e-06, 1.8029232933258754e-06, 4.639872074127197], bias=5.3601179122924805
step = 17000, loss = 104, weights = [7.157319714679033e-07, 1.3055079080004361e-06, 4.63987398147583], bias=5.360119819641113
step = 18000, loss = 104, weights = [3.6656513202615315e-07, 3.462513973317982e-07, 4.639875888824463], bias=5.360121726989746
step = 19000, loss = 104, weights = [2.108283752022544e-07, 4.332337084633764e-07, 4.639876365661621], bias=5.360122203826904
step = 20000, loss = 104, weights = [2.795711395719991e-07, 4.1905320813384606e-07, 4.6398773193359375], bias=5.360123157501221
step = 21000, loss = 104, weights = [2.7763746857090155e-09, -2.6510065254115034e-08, 4.639876842498779], bias=5.3601226806640625
step = 22000, loss = 104, weights = [1.1970545529038645e-05, 1.2440341379260644e-05, 4.639882564544678], bias=5.360128402709961
step = 23000, loss = 104, weights = [6.127560027380241e-06, 6.4404575823573396e-06, 4.639881134033203], bias=5.360126972198486
step = 24000, loss = 104, weights = [6.289257726166397e-05, 6.323700654320419e-05, 4.6399312019348145], bias=5.360177040100098
step = 25000, loss = 104, weights = [5.212790711084381e-06, 5.289592081680894e-06, 4.6398820877075195], bias=5.360127925872803
step = 26000, loss = 104, weights = [2.4486057554895524e-06, 2.5491758606221993e-06, 4.63987922668457], bias=5.3601250648498535
step = 27000, loss = 104, weights = [-6.5130179791594855e-06, -6.914664936630288e-06, 4.6398701667785645], bias=5.360116004943848
step = 28000, loss = 104, weights = [-3.768058149944409e-07, -8.895321457202954e-07, 4.639875888824463], bias=5.360121726989746
step = 29000, loss = 104, weights = [-1.0150426987820538e-06, -7.554278909083223e-07, 4.639875888824463], bias=5.360121726989746
step = 30000, loss = 104, weights = [-1.664670435275184e-06, -1.7965732013180968e-06, 4.639875411987305], bias=5.360121250152588

















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









