




今天先从实操作来讲述采用scrapy来实现对csdn博客的爬取,后续慢慢剖析scrapy爬虫的原理和结构。
1)环境搭建
首先安装scrapy
pip install scrapy其他库依据需要自动进行安装
2)新建项目
scrapy startproject csdn_blog执行完毕后,在该执行目录下,将生成一个名为"csdn_blog"的目录
该目录的结构如下所示

3) 新建爬虫
命令如下:
scrapy genspider csdn_spider www.youkuaiyun.com该命令将在csdn_blog/spiders目录下新建一个csdn_spider.py的文件,
具体内容如下
import scrapy
class CsdnSpiderSpider(scrapy.Spider):
name = 'csdn_spider'
allowed_domains = ['www.youkuaiyun.com']
start_urls = ['http://www.youkuaiyun.com/']
def parse(self, response):
pass
此时起始url为:优快云 - 专业开发者社区
此时,一个初步爬虫工程已经初步创建完毕。
也就是,此时即可运行
scrapy crawl csdn_spider进行爬虫测试验证。
结果将是什么也不会返回。因为此时只是设置了初始url,没有任何处理
2022-04-27 13:32:22 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2022-04-27 13:32:22 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://www.youkuaiyun.com/robots.txt> from <GET http://www.youkuaiyun.com/robots.txt>
2022-04-27 13:32:22 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.youkuaiyun.com/robots.txt> (referer: None)
2022-04-27 13:32:22 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://www.youkuaiyun.com/> from <GET http://www.youkuaiyun.com/>
2022-04-27 13:32:23 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.youkuaiyun.com/> (referer: None)
3)修改起始url
修改上述中csdn_spider.py中的起始url地址为:优快云博客 - 专业IT技术发表平台
4)定位要爬取的数据的链接。
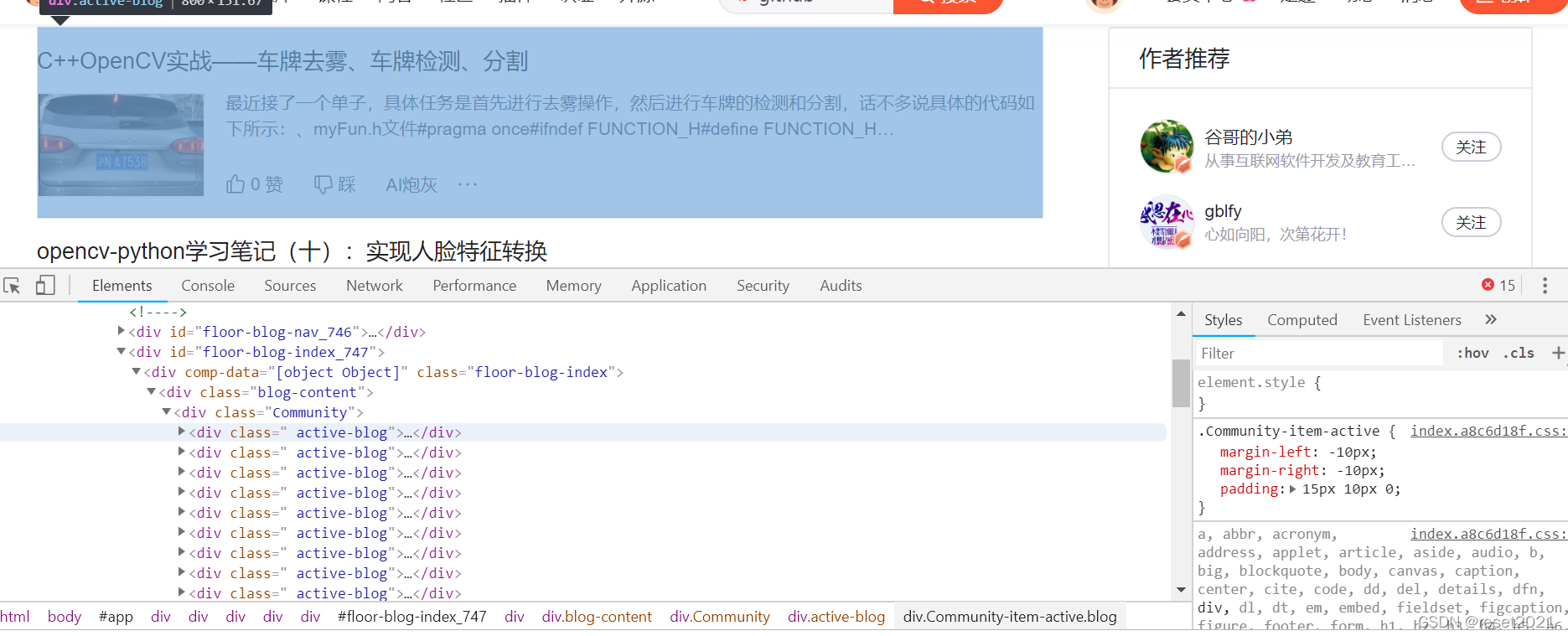
如上图所示,选中要爬取内容,右键点击检查,进入Elements,选中位置,点击右键,选取 Copy->Copy XPath,得到完整的路径
//*[@id="floor-blog-index_747"]/div/div[1]/div[1]/div[5]/div/a/span因为是要爬取本页的所有blog标题与url链接,所以对比两个栏目的差异,将代码修改为
for each in response.xpath("//*[@id='floor-blog-index_747']/div/div[1]/div[1]/div"):通过上述循环来爬取每一个栏目的相关内容。
对要爬取的标题以及url内容进行拆分
for each in response.xpath("//*[@id='floor-blog-index_747']/div/div[1]/div[1]/div"):
item = CsdnBlogItem()
if each.xpath(".//div/a/span/text()") == []:
break
title = each.xpath(".//div/a/span/text()")[0].extract()
print(title)
blog_url = each.xpath(".//div[1]/div/a/@href").extract()[0]
print(blog_url)然后执行命令,即可得到如下打印。
C++比Python快50倍?如何让C++和Python优势互补?(Boost::Python)
https://blog.youkuaiyun.com/FRIGIDWINTER/article/details/124377965
编程实用工具大全(二)(前后端皆可用,不来看看?)
https://blog.youkuaiyun.com/Javascript_tsj/article/details/124384705
看完这五个问题后你真的了解C语言吗?(深度剖析C语言第二期)
https://blog.youkuaiyun.com/qq_59955115/article/details/124232398
计算机网络 --- HTTP协议 和 HTTPS
https://blog.youkuaiyun.com/wwzzzzzzzzzzzzz/article/details/124299957
IDEA各种玩法(开发者必备)
https://blog.youkuaiyun.com/qq_52763385/article/details/124355880
如何在Linux系统上刷抖音
https://blog.youkuaiyun.com/weixin_42350212/article/details/124368382
【力扣刷题笔记】由简到难,模块突破, 你与AC只差一句提示
https://blog.youkuaiyun.com/weixin_44179010/article/details/123847312
我爷爷都看的懂的《栈和队列》,学不会来打我
https://blog.youkuaiyun.com/m0_57025749/article/details/124408260
十道题带你手撕二叉树
https://blog.youkuaiyun.com/m0_57304511/article/details/124403006
植物大战 堆排序——纯C
https://blog.youkuaiyun.com/qq2466200050/article/details/124372452
上课老师讲的经典贪心法问题:哈夫曼编码
https://blog.youkuaiyun.com/m0_64996150/article/details/124271068
【数据结构】八大排序
https://blog.youkuaiyun.com/weixin_61932507/article/details/124302878
网络协议之TCP/IP协议(面试必考内容) - javaEE初阶 - 细节狂魔
https://blog.youkuaiyun.com/DarkAndGrey/article/details/124195991
14个py小游戏 源代码分享
https://blog.youkuaiyun.com/m0_69043821/article/details/124330227
五个拿来就能用的炫酷登录页面
https://blog.youkuaiyun.com/weixin_45660485/article/details/124264181
Windows与网络基础:Windows基本命令-网络相关操作
https://blog.youkuaiyun.com/m0_51456787/article/details/124369258
opencv应用——以图拼图
https://blog.youkuaiyun.com/nameofcsdn/article/details/124357818
【qt+opencv】实现人脸识别打卡系统2.0
https://blog.youkuaiyun.com/qq_40602000/article/details/124416892
微信小程序项目实例——打卡时钟
https://blog.youkuaiyun.com/ws15168689087/article/details/124413017
pyecharts应用:教你如何让数据变成优美的交互式可视化图形
https://blog.youkuaiyun.com/weixin_46211269/article/details/124430865
5)修改items与爬虫主体进行绑定,将item.py中增加相应的属性
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class CsdnBlogItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # blog的名称
blog_url = scrapy.Field() # blog的对应的链接url
pass
将爬取的数据与item进行绑定。
if(title != []):
item['title'] = title
if(blog_url != []):
item['blog_url'] = blog_url
items.append(item)
return items这样,一个爬取csdn博客首页blog 名称与url的工程已经完成。
在执行过程中,还可以将输出打印到对应的json文件中,具体命令如下:
scrapy crawl csdn_spider -o test.jsonjson文件展示如下
1 [
2 {"title": "C++\u6bd4Python\u5feb50\u500d\uff1f\u5982\u4f55\u8ba9C++\u548cPython\u4f18\u52bf\u4e92\u8865\uff1f(Boost::Python
3 {"title": "\u7f16\u7a0b\u5b9e\u7528\u5de5\u5177\u5927\u5168(\u4e8c)\uff08\u524d\u540e\u7aef\u7686\u53ef\u7528\uff0c\u4e0d\u
4 {"title": "\u770b\u5b8c\u8fd9\u4e94\u4e2a\u95ee\u9898\u540e\u4f60\u771f\u7684\u4e86\u89e3C\u8bed\u8a00\u5417\uff1f\uff08\u6
5 {"title": "\u8ba1\u7b97\u673a\u7f51\u7edc --- HTTP\u534f\u8bae \u548c HTTPS", "blog_url": "https://blog.youkuaiyun.com/wwzzzzzzzz
6 {"title": "IDEA\u5404\u79cd\u73a9\u6cd5\uff08\u5f00\u53d1\u8005\u5fc5\u5907\uff09", "blog_url": "https://blog.youkuaiyun.com/qq_5
7 {"title": "\u5982\u4f55\u5728Linux\u7cfb\u7edf\u4e0a\u5237\u6296\u97f3", "blog_url": "https://blog.youkuaiyun.com/weixin_42350212
8 {"title": "\u3010\u529b\u6263\u5237\u9898\u7b14\u8bb0\u3011\u7531\u7b80\u5230\u96be\uff0c\u6a21\u5757\u7a81\u7834\uff0c \u4
9 {"title": "\u6211\u7237\u7237\u90fd\u770b\u7684\u61c2\u7684\u300a\u6808\u548c\u961f\u5217\u300b\uff0c\u5b66\u4e0d\u4f1a\u67
10 {"title": "\u5341\u9053\u9898\u5e26\u4f60\u624b\u6495\u4e8c\u53c9\u6811", "blog_url": "https://blog.youkuaiyun.com/m0_57304511/ar
11 {"title": "\u690d\u7269\u5927\u6218 \u5806\u6392\u5e8f\u2014\u2014\u7eafC", "blog_url": "https://blog.youkuaiyun.com/qq2466200050
12 {"title": "\u4e0a\u8bfe\u8001\u5e08\u8bb2\u7684\u7ecf\u5178\u8d2a\u5fc3\u6cd5\u95ee\u9898\uff1a\u54c8\u592b\u66fc\u7f16\u78
13 {"title": "\u3010\u6570\u636e\u7ed3\u6784\u3011\u516b\u5927\u6392\u5e8f", "blog_url": "https://blog.youkuaiyun.com/weixin_6193250
14 {"title": "\u7f51\u7edc\u534f\u8bae\u4e4bTCP/IP\u534f\u8bae\uff08\u9762\u8bd5\u5fc5\u8003\u5185\u5bb9\uff09 - javaEE\u521d\
15 {"title": "14\u4e2apy\u5c0f\u6e38\u620f \u6e90\u4ee3\u7801\u5206\u4eab", "blog_url": "https://blog.youkuaiyun.com/m0_69043821/art
16 {"title": "\u4e94\u4e2a\u62ff\u6765\u5c31\u80fd\u7528\u7684\u70ab\u9177\u767b\u5f55\u9875\u9762", "blog_url": "https://blog
17 {"title": "Windows\u4e0e\u7f51\u7edc\u57fa\u7840\uff1aWindows\u57fa\u672c\u547d\u4ee4-\u7f51\u7edc\u76f8\u5173\u64cd\u4f5c"
18 {"title": "opencv\u5e94\u7528\u2014\u2014\u4ee5\u56fe\u62fc\u56fe", "blog_url": "https://blog.youkuaiyun.com/nameofcsdn/article/d
19 {"title": "\u3010qt+opencv\u3011\u5b9e\u73b0\u4eba\u8138\u8bc6\u522b\u6253\u5361\u7cfb\u7edf2.0", "blog_url": "https://blog
20 {"title": "\u5fae\u4fe1\u5c0f\u7a0b\u5e8f\u9879\u76ee\u5b9e\u4f8b\u2014\u2014\u6253\u5361\u65f6\u949f", "blog_url": "https:
21 {"title": "pyecharts\u5e94\u7528\uff1a\u6559\u4f60\u5982\u4f55\u8ba9\u6570\u636e\u53d8\u6210\u4f18\u7f8e\u7684\u4ea4\u4e92\
22 ]

















 2085
2085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











