



 本文讨论了改进的Softmax实现,避免了中间值转换,以及多标签问题与多分类的区别。介绍了使用线性函数和from_logits处理多分类问题的方法,同时对比了Momentum、RMSprop和Adam等优化算法在减少摆动、自适应学习率方面的优势。
本文讨论了改进的Softmax实现,避免了中间值转换,以及多标签问题与多分类的区别。介绍了使用线性函数和from_logits处理多分类问题的方法,同时对比了Momentum、RMSprop和Adam等优化算法在减少摆动、自适应学习率方面的优势。
Improved implementation of Softmax(多分类问题)

不再直接在dense里面的激活函数设置为softmax,而是一个线性函数,通过from_logits=True消除了中间值的代换,而是直接一步到位:即意味着a不再作为中间值而是直接是z参与运算

逻辑回归也是如此:

多标签问题(区别与Softmax解决的多分类问题)
multi-class就是这个是猫吗,这个是狗吗?是对于预测值Y的分类
multi-label是关于每个图像的关联位置,是对于X的分类
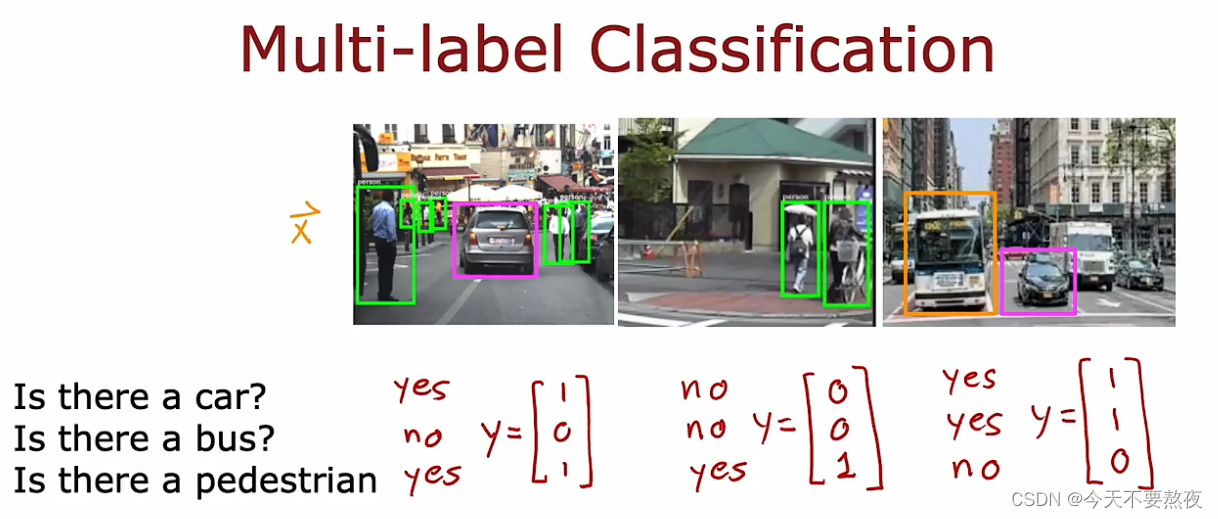
这里得到的Y输出是一个向量(这里是3x1的列向量)而在多分类问题中Y输出得到的是一个数(比如在手写数字识别中Y是0/1/2/3/····/9)
为多标签分类建立神经网络
多标签分类和多分类问题经常会被混淆,这里要明确一下,多标签针对的是X,多分类针对的是Y
方法一:分别使用三个网络解决这三个二分类问题
就是对每个标签分别进行建立logistic regression,去分别判断是否有car、bus或者行人而这样虽然行得通,但其实是不太合理的。
方法二:使用同一个神经网络
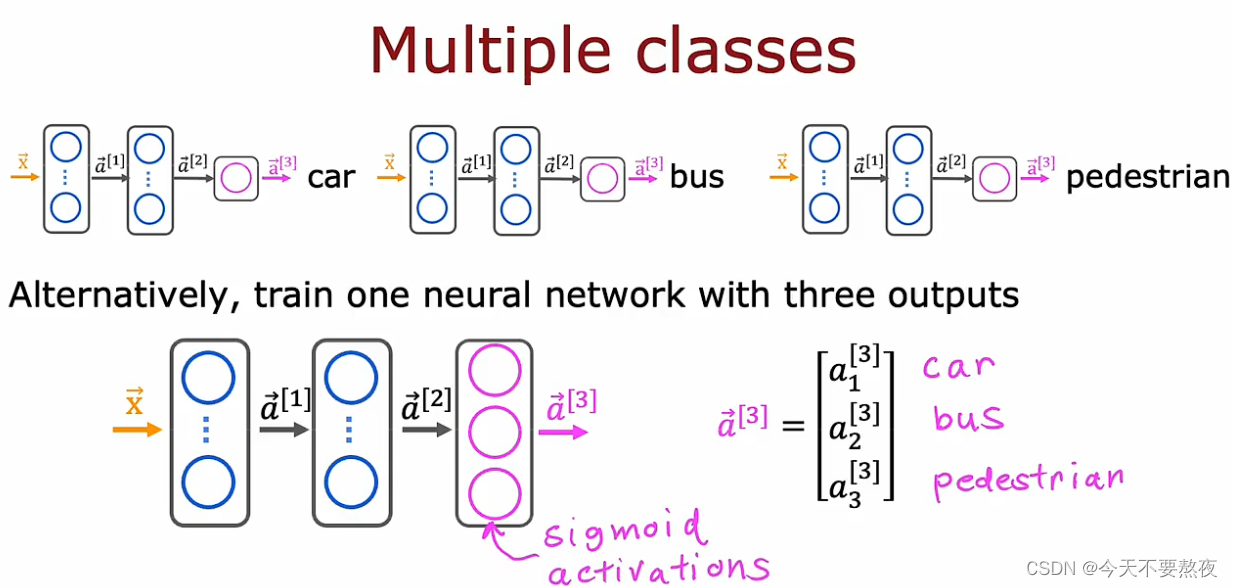
因为这个神经网络其实解决的是三个二分类问题,于是这里在输出层采用的是sigmod激活函数
高级优化算法
用于最小化成本函数的方法,不止有梯度下降(广泛用于线性回归和逻辑回归),这里介绍几种算法去加速训练神经网络的过程,在介绍这些算法前我们需要对指数加权平均(统计学中被称之为指数加权移动平均值)这个概念有个了解:
指数加权平均
Vt将会被近似看成1/(1-β)天的平均温度,β=0.9时也即Vt会被看作10天的平均温度(红色线),β越大在温度变化时适应得就会更缓慢一些(β=0.98绿色线),但当β变小,设为0.5时Vt会被看作2天的平均温度(黄色线),会更快的适应温度变化但是会出现更多的噪声,更可能出现异常值
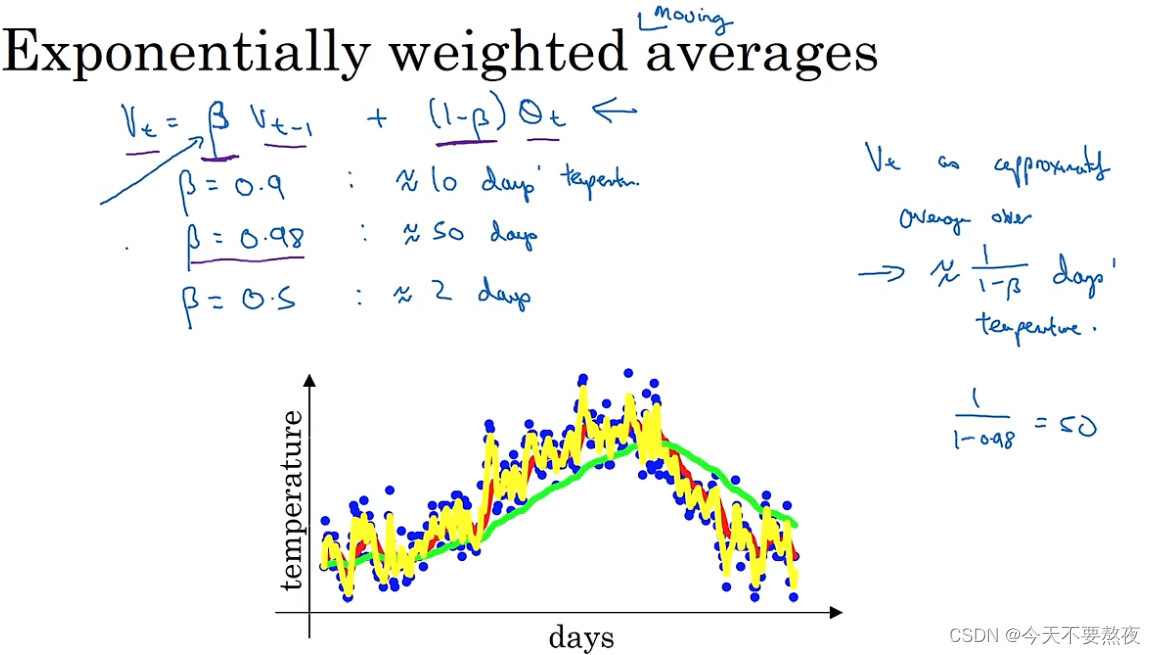
1-epsilon的1/epsilon次方约等于1/e,当β=0.9时,0.9的10次方约等于1/e,所以Vt被看作10天的平均温度(也即1/1-β),这样迭代得去计算最终的v,所占用的空间很小虽然其估算的可能并不准确,因为如果要计算10天的平均温度我们大可以把10天的温度都加起来然后除以10,但这也需要保存10天的温度这样所占据的空间就很大

指数加权平均的偏差修正bias correction
bias correction可以让平均数的计算更加准确,如果不加偏差修正,那么β=0.98得到的应该是紫色线而不是绿色线:
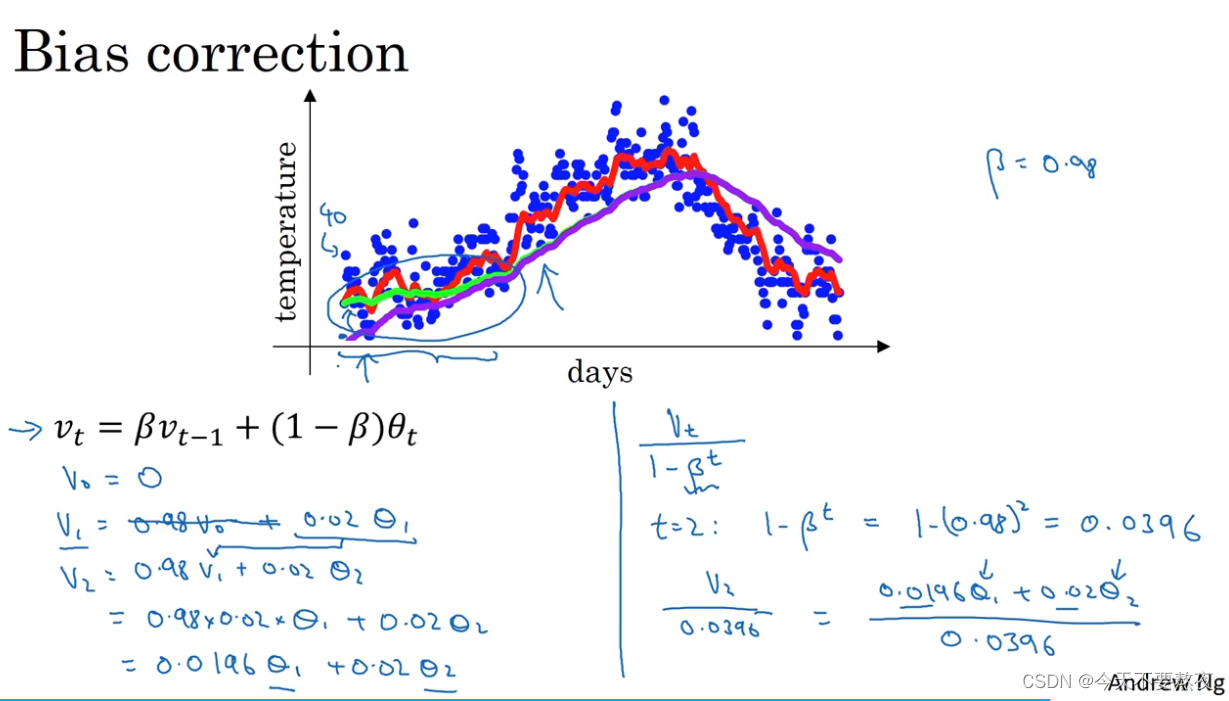
随着t的增加,β的t次方趋近于0,此时的bias correction几乎不起作用,主要针对的是估测的初期,由于β小于1,就会产生v1和v2和温度值偏差很大的现象,紫色在初期偏差很大,进行偏差修正就得到了绿色线,修正了较大的偏差
在机器学习大多数的时候,我们不进行偏差修正,如果我们很重视关心初期的估计那么可以进行bias correction
方法一:Momentum
算法原理

原先的梯度下降batch gradient descent或者是mini-batch gradient descent就像是蓝色的线,逐渐逼近最小值点,但在这过程中表现出了摆动和振荡,此时说明步长很大,若再增加步长容易想到会出现紫色线的这种情况,所以我们想要使得在训练过程中,我们在纵向上的变化小一点,在横轴方向上的变化大一点,这也就是Momentum算法的intuition
最终的效果就会是红色线的样子。
代码实现

超参数α和β,β控制着指数加权平均数最常用的值是0.9,还会有一种表达方式是右边紫色即把1-β弄掉,放在α里面去调整,这样其实不如左边这种带有1-β的形式方便调整β,也更直观。
方法二:RMSprop
这里的平方是对一整个符号的,即微分的平方
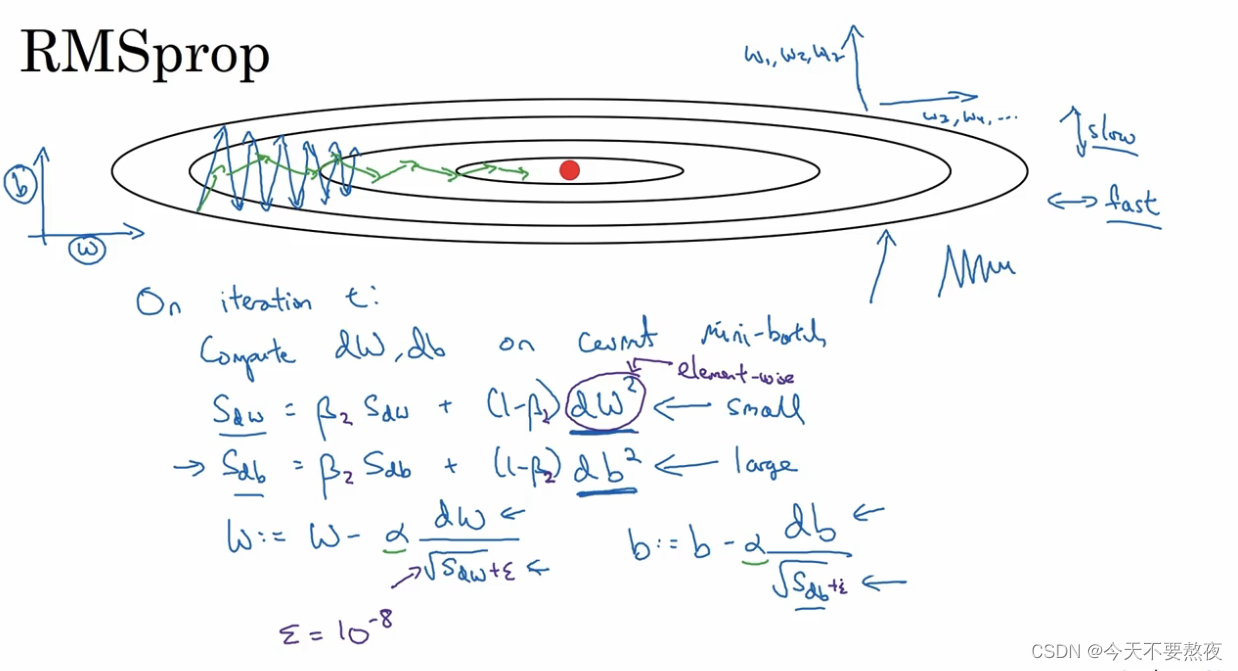
这里我们是想要使得在纵轴上(这里的b方向)的学习慢一些,横轴上的学习快一点(这里的w方向),所以想要使得在分母上的Sdw小一点,Sdb大一点,这样就是的w更新的快,b更新的慢,减缓了纵轴方向的摆动(绿色线),当我们面对高维度参数时,也同样如此。所以RMSprop和Momentum都有相似的特点就是可以消除梯度下降中的摆动,并允许我们可以采用一个更大的学习率,加快学习。
此外为了防止分母为0,这里加一个比较小的epsilon值
方法三:Adam(Adaptive Moment estimation)
算法原理
就是将Momentum和RMSprop结合:并且此处需要进行偏差修正

超参选择

简单的讲:
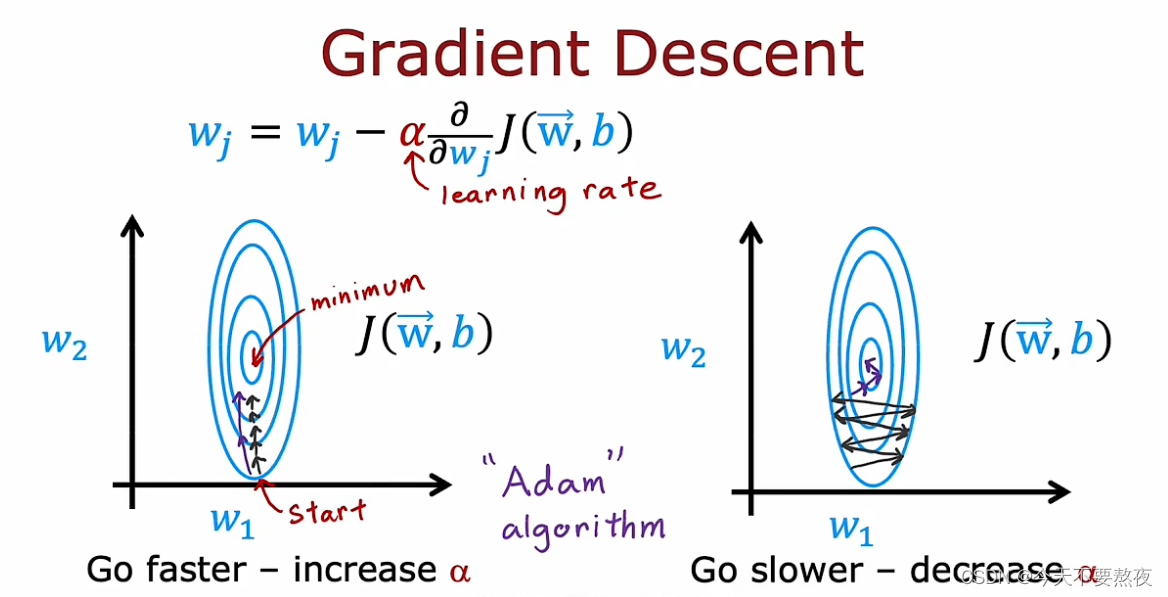
我们希望在梯度下降过程中动态调整学习率即步长,学习慢的时候希望步长大一些,而oscillating即摆动的时候就需要减小步长
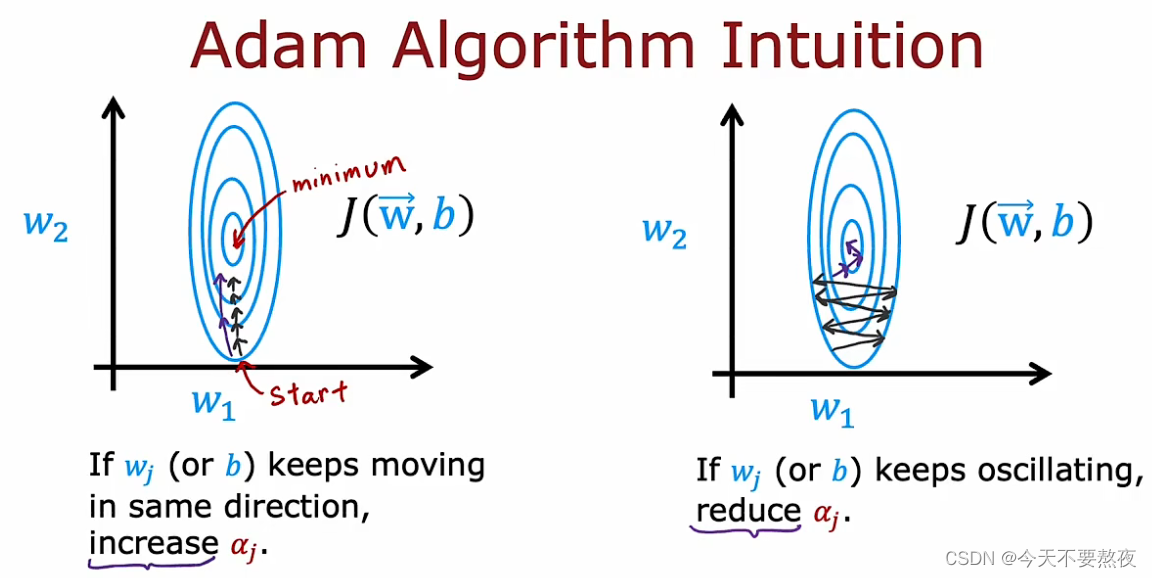
并且Adam算法并没有使用单一的α,而是对于每一个参数都采用一个不同的学习率

代码实现
在model.compile中指定优化方法optimizer为Adam

这里的Adam需要为其设置一个默认的全局学习率,此处设为了10的-3次,我们可以尝试改变(微调)默认学习率的值,使得提供的学习性能更好,但是与之前的梯度下降相比,Adam会自适应调整学习率的值,更加的robust,速度也会更加的快,也成为了从业者们训练神经网络事实上的标准

















 3970
3970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









