




 本文介绍了如何通过2D图像信息和深度信息转换为3D点云的过程,详细解释了针孔相机模型下,空间点与图像像素坐标之间的转换公式,并给出构建点云的方法。
本文介绍了如何通过2D图像信息和深度信息转换为3D点云的过程,详细解释了针孔相机模型下,空间点与图像像素坐标之间的转换公式,并给出构建点云的方法。
http://www.cnblogs.com/gaoxiang12/p/4652478.html
从上面学习转载
18 // 相机内参 19 const double camera_factor = 1000; 20 const double camera_cx = 325.5; 21 const double camera_cy = 253.5; 22 const double camera_fx = 518.0; 23 const double camera_fy = 519.0;
从2D到3D(数学部分),其实就是从图像信息和深度信息的2d信息转化为点云(3d信息)
上面两个图像给出了机器人外部世界的一个局部的信息。假设这个世界由一个点云来描述:X={x1,…,xn}X={x1,…,xn}. 其中每一个点呢,有 r,g,b,x,y,zr,g,b,x,y,z一共6个分量,表示它们的颜色与空间位置。颜色方面,主要由彩色图像记录; 而空间位置,可以由图像和相机模型、姿态一起计算出来。
对于常规相机,SLAM里使用针孔相机模型(图来自http://www.comp.nus.edu.sg/~cs4243/lecture/camera.pdf ):
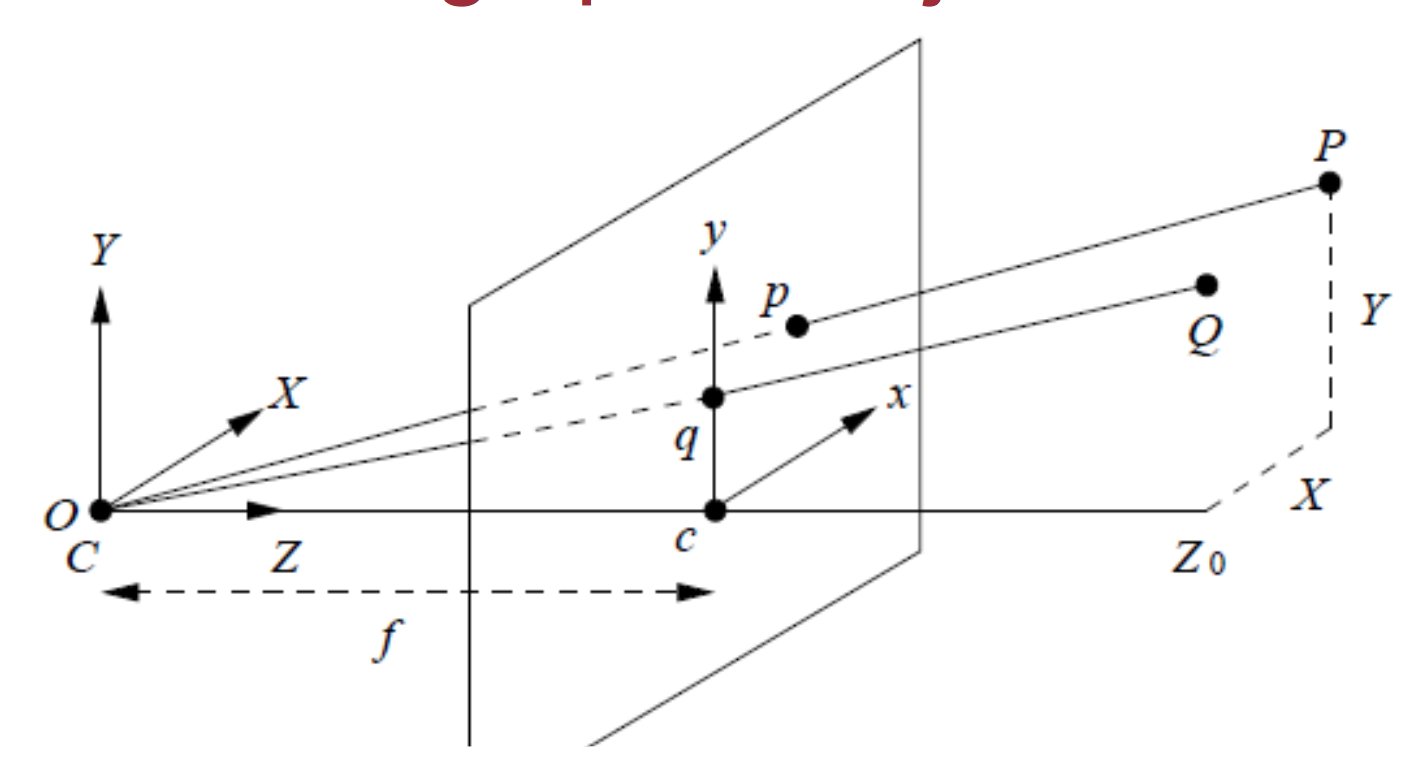
其中,fx,fyfx,fy指相机在x,yx,y两个轴上的焦距,cx,cycx,cy指相机的光圈中心,ss指深度图的缩放因子。
小萝卜:好晕啊!突然冒出这么多个变量!
师兄:别急啊,这已经是很简单的模型了,等你熟悉了就不觉得复杂了。
这个公式是从(x,y,z)(x,y,z)推到(u,v,d)(u,v,d)的。反之,我们也可以把它写成已知(u,v,d)(u,v,d),推导(x,y,z)(x,y,z)的方式。请读者自己推导一下。
不,还是我们来推导吧……公式是这样的:
怎么样,是不是很简单呢?事实上根据这个公式就可以构建点云啦。
通常,我们会把fx,fy,cx,cyfx,fy,cx,cy这四个参数定义为相机的内参矩阵CC,也就是相机做好之后就不会变的参数。相机的内参可以用很多方法来标定,详细的步骤比较繁琐,我们这里就不提了。给定内参之后呢,每个点的空间位置与像素坐标就可以用简单的矩阵模型来描述了:
其中,RR和tt是相机的姿态。RR代表旋转矩阵,tt代表位移矢量。因为我们现在做的是单幅点云,认为相机没有旋转和平移。所以,把RR设成单位矩阵II,把tt设成了零。ss是scaling factor,即深度图里给的数据与实际距离的比例。由于深度图给的都是short (mm单位),ss通常为1000。


















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









