






 本文介绍了一种基于RGB-DSLAM的视觉里程计实现方法,详细阐述了特征点匹配、ICP算法应用及相机内外参数的计算过程,并提供了图像畸变校正的代码示例。
本文介绍了一种基于RGB-DSLAM的视觉里程计实现方法,详细阐述了特征点匹配、ICP算法应用及相机内外参数的计算过程,并提供了图像畸变校正的代码示例。
此博客记录我的slam学习之旅,近几天目标为实现基于RGB-D SLAM的视觉里程计。主要参考资料为高博的《视觉SLAM十四讲:从理论到实践》及高博的博客https://www.cnblogs.com/gaoxiang12/。
首先实现一个不考虑任何实际问题的视觉里程计,根据RGB图像及对应的深度图像恢复出相邻两帧图像间的R,T(也就是运动相机的位置姿态),帧与帧之间的运动关系最后构成相机的运动轨迹。大致思路分为如下几个步骤:
(1)在图像上选取特征点,进行图像间的特征点匹配。
(2)根据特征匹配的结果(3D-3D),利用ICP算法恢复出相机的位置姿态(以第一帧的相机坐标系为参考坐标系)
(3)两两帧间的运动估计完成,再进行帧与帧之间的连接,最后连接成整体的轨迹了。
(ps:把视觉里程计写的这么简单也是没谁了。。。。。实际的情况比这复杂很多)
补充一点基本数学知识:(这里只考虑小孔成像模型,实际还有几种其他摄像机模型)
(本人使用opencv 3.1,ubuntu 16.04(在虚拟机上运行))
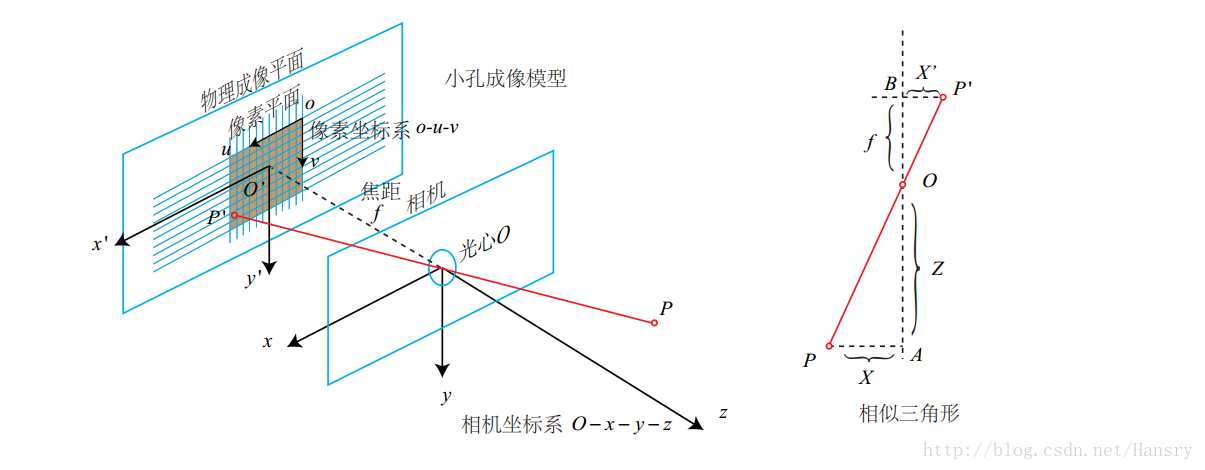
相机与图像的坐标系
(1)相机坐标系
(2)图像坐标系
(3)像素坐标系
由图可知,设空间点P在相机坐标系的坐标为P[x,y,z],通过相机光心投影到图像坐标系中P/(x/,y/),根据相似三角形原理(如上图所示)可知,
(ps:由于第一次写博客,不会使用公式编辑插件,所以在草稿本上写放的照片)
为了简化模型,将成像平面放到相机前方,可以得到对应公式,不过在相机图像中,我们得到的是像素,我们设物理成像平面坐标系上固定着一个像素坐标系,p/对应像素坐标p(u,v)

图像成像坐标系与像素坐标系之间相差了一个缩放和平移,设在u轴上被缩放了a倍,按原点平移了cx,在v轴缩放了B倍,按原点平移了cy,即可得上述公式
为了易于表达,将左侧公式写成齐次坐标形式,其中K为相机内参矩阵,一般工厂会标定好相机内参,但很多时候需要我们进行标定,标定工具主要有基于Opencv和matlab的,目前已经很成熟了
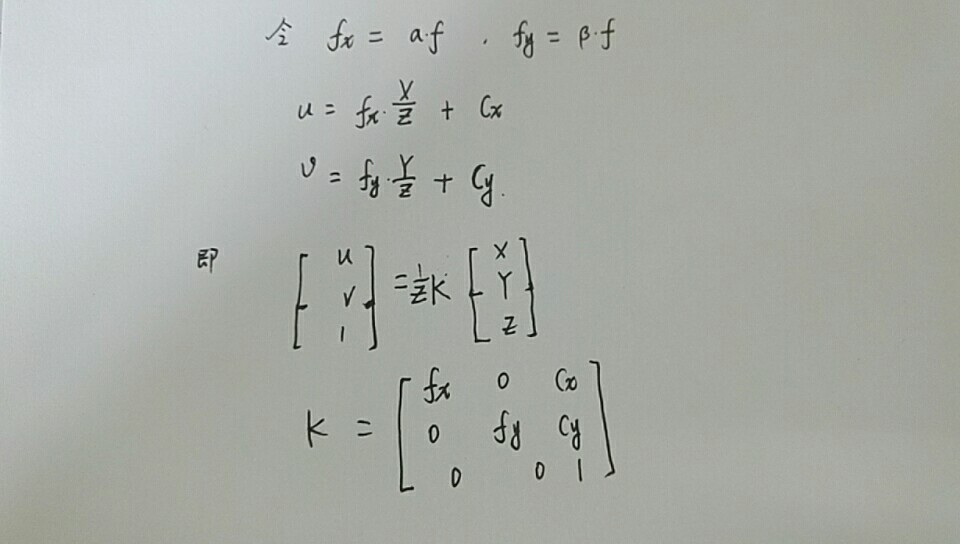
有相机内参自然有相机外参,上面假定的空间点p的坐标是在相机坐标系下的,那么如何根据世界坐标系下的p点计算得到像素坐标下对应的点?

因为都是齐次坐标,所以可以写成上述公式。
下面贴一段代码表达像素坐标与相机坐标之间的关系:
以下是2d-3d的转换代码:
添加CMakeLists.txt
#设定最小版本 CMAKE_MINIMUM_REQUIRED(VERSION 2.8) #设定工程名 PROJECT(2D) # 添加c++ 11标准支持 set( CMAKE_CXX_FLAGS "-std=c++11" ) #找到opencv库 FIND_PACKAGE(OpenCV REQUIRED) # 添加头文件 include_directories( ${OpenCV_INCLUDE_DIRS} ) ADD_EXECUTABLE(2D 2d.cpp) # 链接OpenCV库 target_link_libraries( 2D ${OpenCV_LIBS}
以下是2d转换为3d坐标的代码
// // Created by xl on 18-5-4. //此程序为将图像像素坐标转为相机坐标系,原图像为一张RGB图像和一张对应的深度图 //opencv库 #include <opencv2/core/core.hpp> #include <opencv2/highgui/highgui.hpp> //c++库 #include <iostream> using namespace std; using namespace cv; int main(int argc,char **argv) { Mat rgb=imread("rgb.png",0); Mat depth=imread("depth.png",-1);//-1表示对原数据不做任何修改 double scale=1000;//scale表示深度图的缩放因子,一般为1000 /*Mat K; K=(Mat_<double>(3,3)<<518.0,0,325.5,0,518.0,253.5,0,0,1);*///定义相机内参K,也可以采用这种方式 // 相机内参 const double camera_factor = 1000; const double camera_cx = 325.5; const double camera_cy = 253.5; const double camera_fx = 518.0; const double camera_fy = 519.0; vector<Point3f> pts_3d;//定义三维点 for(int m=0;m<depth.rows;m++) { for(int n=0;n<depth.cols;n++){ ushort d=depth.ptr<unsigned short>(m)[n]; if(d==0) continue;//如果d=0,则被认为是坏点 double dd=d/scale; pts_3d.push_back(Point3f((m-camera_cx)*dd/camera_fx,(n-camera_cy)*dd/camera_fy,dd)); } } }
既然讲到图像了,那就顺便提一下图像畸变吧。
为了呈现更好的成像效果,我们会在相机前方加上透镜,透镜的加入会对成像过程中光线的传播产生新的影响。
畸变的形式一般为两种:
(1)径向畸变:由透镜形状引起的畸变,径向畸变又可以分为枕形畸变和桶形畸变。
(2)切向畸变:在组装过程中,透镜和成像平面不能严格平行产生切向畸变
对于切向畸变,无论哪个形式,都可以用一个多项式函数来描述畸变前后的变化,可以用与距中心的距离有关的二次及高次多项式函数进行纠正。
对于切向畸变,也可以使用两个参数来纠正。(具体公式见下图)

注意:x,y为归一化平面的坐标,r也是距归一化中心点的距离。
所以给出一个空间点位置P(X,Y,Z),我们可以求出其在带有畸变的相机上像素坐标。

(ps:对了,之前没有讲到归一化坐标,这里的归一化坐标其实就是相机坐标系下的坐标值(x,y,z)转换到z=1的平面上,原来的坐标转为(x/z,y/z,1))
接下来到了我们的实践环节了,给你一张带有畸变的图像,如何把它纠正转为去畸变的照片??
问题描述:
input:畸变后的图像(因为相机原因,可能拍出来的照片里面的物体是斜的),上面提到的畸变参数
output:畸变前的图像。
(ps:最开始我接触这个问题的时候,当时也不明白该怎么求,后来看了网上的博客,才弄懂了。)
其实这个问题的核心是畸变后的坐标与畸变前的坐标,它们两处坐标的灰度值是相同的,这里要求出畸变前的图像,其实就是求出畸变前图像的一个点坐标p,对应的畸变图像的坐标是多少,找到p点对应到畸变图像上的坐标值,再把畸变图像的坐标值的灰度值赋给畸变前的坐标p,所有的图像是一个个像素组成的,遍历所有图像这就可以了。。。所以这个问题的求解可以分为以下步骤

(注意:这里还有一个隐藏问题,像素点(u,v)经过畸变后在畸变图像的坐标值不一定为整数,但是在像素坐标里一定要是整数的啊,比如在原始图像(1,1)畸变后就可能变成了(1.2,1.3),这样显然是不行的,这就需要对畸变坐标作插值处理,我们这里先不讨论插值的问题,对畸变坐标取整进行(ps:这样真的是太暴力了啊 。。。。))
(还有个问题:我们这里讨论的是灰度图像,当然也可以考虑RGB图像,其实原理是一样的,只要每个坐标计算三个RGB值就行了,这里以灰度图为例)
下面就是代码示例了:
#include <iostream> #include <opencv2/core/core.hpp> #include <opencv2/features2d/features2d.hpp> #include <opencv2/highgui/highgui.hpp> #include <opencv2/calib3d/calib3d.hpp> usingnamespace std; usingnamespace cv; int main(int argc, char **argv) { // 畸变参数,这里只考虑k1,k2,这里需要你知道参数。 double k1,k2,p1,p2; //相机内参矩阵 double fx,fy,cx,cy; Mat K; K=(Mat_double<3,3><<fx,0,cx,0,fy,cy,0,0,1); Mat image = imread(“test.png”,0); // 这里填写你的路径,0表示将图像转换为灰度图 Mat image1 = Mat(image.rows, image.cols, CV_8UC1); // 设置去畸变以后的图 // u,v为畸变前图像的像素坐标,v为列,u为行 for (int v= 0; v < image.rows; v++) for (int u = 0; u < image.cols; u++) { double x=(u-cx)/fx; double y=(v-cy)/fy;//这里的x,y为归一化后的坐标 double r=pow(x,2)+pow(y,2);//r为距中心点的距离的平方,之所以是平方,是因为方便,没有调用开根号,注意也是归一化平面上的 double x1=x*(1+k1*r+k2*pow(r,2))+2*p1*x*y+p2*(r+2*x*x); double y1=y*(1+k1*r+k2*pow(r,2))+p1*(r+2*y*y)+2*p2*x*y;//x1,y1为畸变图像上的归一化坐标 double u1=fx*x1+cx; double v1=fy*y1+cy;//u1,v1为畸变图像上的像素坐标 // 最后一步灰度值相等,而且需要对畸变图像的像素坐标取整,这里的方法很粗暴,直接int if (u1= 0 && v1>=0 && u1< image.cols && v1<image.rows) { image1.at<uchar>(v, u) = image.at<uchar>((int) v1, (int) u1); } else { image1.at<uchar>(v, u) = 255;//对于超出坐标范围,赋灰度值为255 } } // 画图去畸变后图像 imshow("image1", image1); imshow("image ", image); cv::waitKey(); return0; }
(ps:代码写得可能不够规范,请原谅啊,哈哈,因为中英文字符问题调了半天)
好了,这次主要介绍相机图像的问题了,下一节将记录特征点检测匹配的问题了。。
如果有人看到我的博客,欢迎大家一起交流啊,,,,(写的这么烂估计没有人看吧。。。。。)
我的邮箱:1439741774@qq.com18:21:24

















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









