




在学习子程序的过程中,看了整个的ppt,也没搞明白一个带有子程序的汇编程序长什么样。
我们先看一个例子,然后分析。
datas segment
w dw 10
h dw 6
turns dw 30
start_x dw 20
start_y dw 20
datas ends
stack segment stack
dw 32 dup(?)
stack ends
code segment
assume cs:code,ds:datas,ss:stack
main proc near
start:
mov ax,datas
mov ds,ax
mov ax,stack
mov ss,ax
mov ah,0
mov al,4 ;图像模式
int 10h
mov cx,turns
loops:
call hor_ver
mov ah,0
int 16h
loop loops
mov ah,0 ;文本模式
mov al,3
int 10h
mov ah,4ch
int 21h
main endp
;打印一个楼梯
hor_ver proc near
push ax
push bx
push cx
push dx
mov cx,w
li:
push cx
mov cx,start_x
mov dx,start_y
mov al,1
mov ah,0ch
int 10h
inc start_x
pop cx
loop li
mov cx,h
ld:
push cx ;写入像素点
mov cx,start_x ;x坐标
mov dx,start_y ;y坐标
mov al,1 ;像素值
mov ah,0ch
int 10h
inc start_y ;y++ 打印竖
pop cx
loop ld
pop dx
pop cx
pop bx
pop ax
ret
hor_ver endp
code ends
end start
基本结构
功能是像素点打印楼梯,随便找的例子没别的意思。
和一般的程序差不多,都是三段segment,code段有assume和数据段绑定。
(如果不是很清楚一个汇编程序的格式,看这篇博客)
两个代码块
不过我们的code段中,出现了两个部分:
main proc near
……
main endp
和
hor_ver proc near
……
hor_ver endp
这两部分就有一点像C的主函数和子函数,我们按照命名就能看出来具体谁是谁了。
一个程序,需要有一个名字(废话),这个是要写在proc和endp前面的,所以一个简单的子程序/或者主程序是这样的:
**proc
**endp
至于这两个谁在上面都无所谓。
near?
但那个near是什么:
NEAR属性(段内近调用)的过程只能被相同代码段的其他程序调用。
FAR属性(段间远调用)的过程可以被相同或不同代码段的程序调用。
如果是有多个代码段,那么我们一定需要far,但如果是段内调用,还是选择near,因为near相对较快。
有两个建议:
- 首先如果是段内调用,其实near还是far的都可以不写……,但是还是写了比较好
- 主程序部分建议定义为far类型,便于返回dos,也就是将我们的主程序
这时,我们的代码长这样:
**proc near ;缺省就是near
**endp
压栈出栈?
为什么调用子程序还需要压栈出栈啊?
因为我们只有这几个寄存器,如果主程序和子程序调用了同一个,如果不保存,那么我们主函数的内容不就没了?(专业一点,这叫保护现场)
这里我们保存的方式还是有几种类型的:
- 压栈出栈,这个是比较简单的。如果使用堆栈法,那么保护恢复一定要在同一个地方
(子程序或者主程序,不能分成两部分) - 存内存,也就是在data数据段中定义变量来存储。
当然了,如果不想管,直接就将四个寄存器都压栈,然后反过来都出栈了就行,
ret&call
ret就是return的缩写,也就是函数的返回部分。
看着似乎没什么,其实本质上人家可是干了很多事。
在调用子程序的部分,我们的cs段寄存器和ip寄存器记录了当前指令的位置,如果有在dos尝试单步调试会发现,在函数返回的过程中,IP寄存器的值是会发生改变的。
所以ret其实就是jmp+pop的操作。
那我们怎么调用?
可以看到,上面的程序中有一个call指令,后面跟着我们的子程序名称,这就是调用了。
call和ret一个将ip寄存器压栈,一个弹出,保证了我们的代码实现。
其实call规范来说是这样的:
call near/far ptr 函数名,如果是far调用需要将cs和ip都进行压栈。
但是我们还是如果缺省就默认为near。
ret的一个骚操作
ret [val],其中val一定是一个正偶数。
啥?是返回值吗?
不是,我们在rer的过程中,我们有一个将ip出栈的操作,正常来说sp指针加2就行了,但是如果是有这个数值,那么我们还需要将sp再加上这个正偶数。

因为是dw类型的堆栈,所以我们的val才需要是正偶数。
另外强调一点,栈顶在高位,也就是我们压栈其实是从高往低。
(可这nm有什么用吗?
比如在子程序中我们将一些数据进行了压栈处理的,但是后面就用不上了,这里我们就可以直接ret,不需要一个个出栈了。
虽然只是修改了指针,而不是出栈,但当我们继续压栈的过程中,是会将数据覆盖掉的,所以还是没有影响的。
start写在哪?
当时就这个头疼了半天。
我们想一下,start是开始程序的标志,汇编和C什么的差不多,都是串行结构,说白了就是一条条执行,所以C从主函数起步,在这里我们也是这样。
start写在主程序的开始,start end在代码段结束。
另外我们的assume是一切代码的前提,只有绑定了才能找到位置,所以assume在code 段的最开始。
参数传递问题
子程序不可能都没有返回值吧,也不可能都没有参数传入吧。
这里我们给几个方法:
- 寄存器法
- 变量法(存内存)
- 堆栈法
- 参数地址指针法
寄存器法
就是将传入传出的参数放在寄存器里面。
主程序:传入不用管,传出视情况保护;
子程序:传入建议保护,传出不能保护和恢复。(保护的不是返回值,而是之前的值,如果恢复了会将返回值覆盖掉!)
堆栈法
就是将传入和传出的参数都压入堆栈中。
因为保存和恢复也在堆栈中,如果处理不好直接翻车,但是能省下内存和寄存器,优缺点都很明显。
比如我们是将传入和传出的参数都放在CX寄存器中,在子程序将ABCX三个寄存器压栈。
主程序调用:
PUSH CX ;堆栈传递入口参数
CALL SQROOT
POP CX ;堆栈返回运算结果
我们一步步来分析:
- 刚进入子程序,参数在栈中,同时我们的返回地址也在(call指令干的活)
- 将三个寄存器压栈
- 我们需要将传入参数放入CX寄存器中,需要将sp指针加8,然后pop到cx中
- 计算返回值(在CX中),将CX压栈(就是那个平方根,白嫖的图)。
- 将sp-8,调整为压栈之前的样子
- 寄存器出栈,ret返回,这样在主程序中我们的栈顶元素就是返回的参数了。

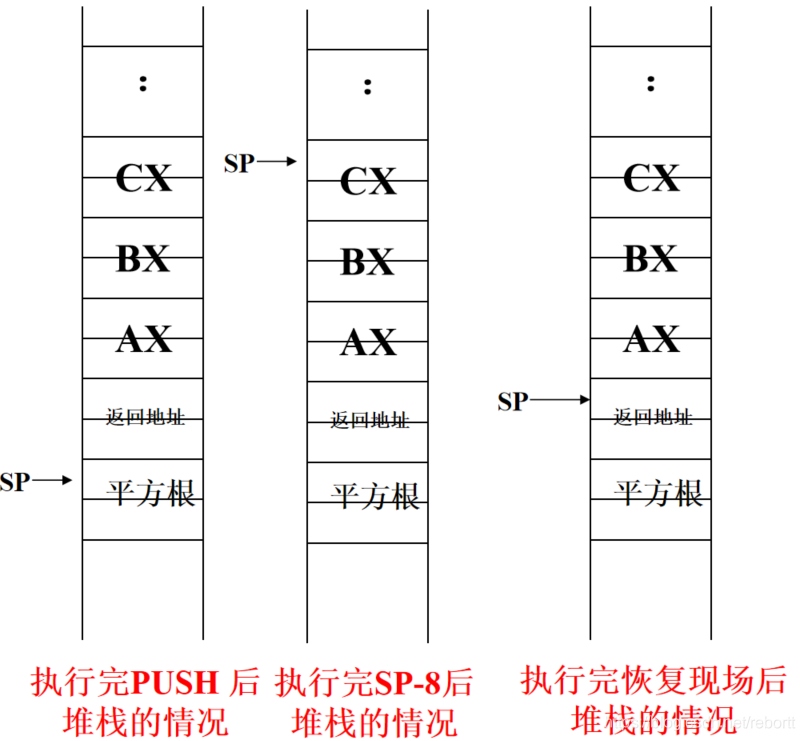
这里我们修改了sp的值,即直接修改栈内指针位置,如果子程序中还需要使用栈,解决办法:
- 继续调整sp指针,不过很麻烦还容易出错;
- 将我们的cx寄存器赋值(传入参数)改为寻址方式: MOV CX, [BP+……],这样会好很多。
参数地址指针法
上面的方式传一个两个数据都行,但如果是多个数据(比如一个数组),如果还是采用之前的方式,尤其是堆栈法,算地址直接爆炸。
所以我们将数组的首地址在主程序中赋值到SI寄存器,将个数赋值到CX寄存器(习惯,不是强行要求的),在子程序直接使用就行,注意子程序中的SI和CX要保护一下。
和寄存器法其实差不多,
注意传数组地址要使用lea指令,非要offset也行,但是这个能叼一点,
另外数组中的元素直接使用[SI]就是了,如果是dw类型,si一次加2,db加1(指元素后移)。
子程序的嵌套问题
就是套娃,比如我们在一个子程序中再调用另一个子程序。
我们要注意,每一次调用都涉及到压栈出栈,即使没有寄存器压栈,也有ip压栈,所以堆栈空间一定要够用,然后就是call 和 ret 一定要玩明白,要保护好寄存器。
主要的部分我们想讲一讲递归的问题,这里以Fibonacci为例。
如果是递归的程序,那么参数传递就一定要是寄存器法或者堆栈法,除非一个递归函数只能延申出一个递归部分,如计算n!,我们调用的过程中函数个数线性增加,否则使用参数法就会爆炸。
和一般的一样,我们也需要有边界条件:
在Fibonacci中,F(1) = F(2) = 1。
剩下的F(n) = F(n-1)+F(n-2)。
(可以想象出,如果我们直接写到最后一层,一共需要传递很多个参数,所以还是堆栈法和寄存器法好一些;另外如果n足够大,堆栈也容易炸掉。)
功能:输入一个不限位数的十进制数,回车后打印fibo的结果。
(可以输入个位数、十位数,非要输入一个百位的也行吧,反正自己电脑受得了再加上bl寄存器大小受得了就行)
DATAS SEGMENT
DATAS ENDS
STACKS SEGMENT
a dw 20 dup(?)
STACKS ENDS
CODES SEGMENT
ASSUME CS:CODES,DS:DATAS,SS:STACKS
fibo proc
;读入al的数据,计算,返回在ax中
push bx
push cx
push dx
cmp al, 1h
je get_out
cmp al, 2h
je get_out ;if(n == 1 || n == 2) return 1;
mov dl, al
sub al, 1h
call fibo
mov bx,ax ;fibo(n-1)
mov al,dl
sub al, 2h
call fibo ;fibo(n-2)
mov cx,ax
mov ax,bx
add ax,cx
pop dx
pop cx
pop bx
ret
get_out:
mov ax, 1h
pop dx
pop cx
pop bx
ret
fibo endp
;打印回车
dpcrlf proc ;过程开始
push ax ;保护寄存器AX和DX
push dx
mov dl,0dh ;显示回车
mov ah,2
int 21h
mov dl,0ah ;显示换行
mov ah,2
int 21h
pop dx ;恢复寄存器DX和AX
pop ax
ret ;子程序返回
dpcrlf endp
;打印空格
printf PROC
push ax
push cx
push dx
mov cl,20h
mov dl,cl
mov ah,2h
int 21h
pop dx
pop cx
pop ax
ret
printf ENDP
;将ax中的16位内容按十进制打印
hex PROC
PUSH AX
PUSH BX
PUSH CX
PUSH DX
PUSHF
XOR CX,CX
MOV BX,10
@DSPAX1:
XOR DX,DX
DIV BX
INC CX
OR DX,30H
PUSH DX
CMP AX,0
JNE @DSPAX1
MOV AH,2
@DISPAX2:
POP DX
INT 21H
LOOP @DISPAX2
MOV DL,32
INT 21H
POPF
POP DX
POP CX
POP BX
POP AX
RET
hex ENDP
main proc
START:
MOV AX,DATAS
MOV DS,AX
xor bl,bl
input:
mov ah,1h
int 21H
cmp al,13 ;换行
jz next ;相等跳出
sub al,30h
mov dl,bl
mov cl,3h
sal bl,cl
sal dl,1 ;乘10
add bl,dl ;存储在bl中
add bl,al
jmp input
next:
mov al,bl
call fibo
;call printf
call hex
MOV AH,4CH
INT 21H
main endp
CODES ENDS
END START
第一个函数是计算Fibonacci的,按照递归的定义来就好了,别忘了两个分支上都要有出栈和ret。
然后中间的间隔方式我给出了两种,一个是换行回车,一个是空格,这里调用了换行。(都是中断调用,没什么可讲的)
我们的十进制转换采用的是除法+压栈实现的。
实现不限位数的输入我们是采用判断回车来实现的,如果没有读到回车就将bl的内容乘十然后加上我们刚刚读入的内容。

















 769
769




 到【灌水乐园】发言
到【灌水乐园】发言







